LangChain | LangGraph V1教程
LangChain与LangGraph是构建AI智能体的框架工具。LangChain提供基础组件(如LLM调用、Prompt管理),支持快速搭建AI应用;LangGraph在LangChain基础上扩展了状态管理和流程控制功能,支持复杂工作流(循环、分支等)。两者结合可实现从简单到复杂的智能体开发。安装建议使用uv工具管理依赖,通过.env文件配置环境变量。LangChain支持多种模型提供商集成
什么是LangChain & LangGraph
- LangChain:帮助您快速开始使用任何您选择的模型提供商来构建智能体。
- LangGraph:允许您通过低级别编排、内存和**人工干预支持(human-in-the-loop support)来控制自定义智能体的每一步。您可以使用持久化执行(durable execution)**来管理长时间运行的任务。
关系如下:
| 组件 | 说明 |
|---|---|
| LangChain | 提供基础工具:LLM 调用、Prompt 管理、工具调用(Tool)、记忆、Agent 架构等。是构建 AI 应用的“乐高积木”。 |
| LangGraph | 在 LangChain 基础上扩展了 状态管理 + 图流程控制,支持复杂工作流(如循环、并行、条件分支)。它使用 LangChain 的组件,但提供更高阶的执行模型。 |
| DeepAgent | 是一个基于 LangChain + LangGraph 构建的 智能体框架,用于实现自动化任务代理(例如网页浏览、决策、多步推理)。 |
LangChain有各种开发的组件以及简单,通用的工具和类,底层来自于LangGraph,提供通用智能体开发和逻辑链工作流的智能体开发,而DeepAgent专注构建超复杂智能体。
结构类似于: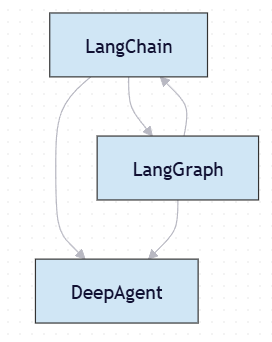
安装langchain
使用pip或uv的形式,建议使用uv,如何安装及使用uv参考:
pip install -U langchain
uv add langchain
LangChain 提供对数百种 LLM 和数千种其他集成的支持。这些集成存在于独立的提供者包中。例如:
# 安装 OpenAI 集成
pip install -U langchain-openai
# 安装 Anthropic 集成
pip install -U langchain-anthropic
# 安装 OpenAI 集成
uv add langchain-openai
# 安装 Anthropic 集成
uv add langchain-anthropic
环境配置
安装管理环境变量的包
# 管理环境变量的包
pip install dotenv
dotenv的使用:
在项目根目录创建.env配置文件以及一个config.py文件,.env文件格式如下:
DEEPSEEK_API_KEY=xxx
DEEPSEEK_BASE_URL=xxx
DEEPSEEK_TEXT_MODEL=xxx
以下是一个简单的config.py示例:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
# LLM配置
# deepseek
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
DEEPSEEK_TEXT_MODEL = os.getenv("DEEPSEEK_TEXT_MODEL")
# 数据库参数
DB_CONFIG = {
"host": os.getenv("DB_HOST"),
"port": os.getenv("DB_PORT"),
"username": os.getenv("DB_USERNAME"),
"password": os.getenv("DB_PASSWORD"),
"database": os.getenv("DB_DATABASE")
}
uv包管理
在项目根目录创建pyproject.toml文件:
[project]
name = "your-project-name"
version = "0.1.0"
requires-python = "你的py版本要求" 例:">=3.11"
dependencies = []
然后运行
uv add requests
如果之前有requirements.txt,使用
uv add -r requirements.txt
使用 uv remove 可以删除依赖项
uv remove requests
需要导入虚拟环境时,也只需要 pyproject.toml 文件,并执行:
uv sync
以上命令会根据 pyproject.toml 自动创建或更新虚拟环境,方便快捷
你可以选择修改uv缓存目录(默认c盘)来消除link-mode警告:
setx UV_CACHE_DIR "D:\Workspace\Environments\VirtualEnvs\UV"
uv cache clean
初识模型
langchain框架提供基础工具:LLM 调用、Prompt 管理、工具调用(Tool)、记忆、Agent 架构等。是构建 AI 应用的“乐高积木”。
智能体可以视作一个能自主使用工具获取知识并处理请求的语言模型,智能体将语言模型与工具结合,创建能够对任务进行推理、决定使用哪些工具并迭代寻求解决方案的系统。
模型是整个智能体的核心,接下来介绍几种常用的创建对话模型的方法:
基础创建
使用统一接口init_chat_model从任何受支持的提供者初始化聊天模型。这是通用的创建一个聊天模型的方法,共有以下参数:
| 参数名 (PARAMETER) | 类型 (TYPE) | 默认值 (DEFAULT) | 描述 (DESCRIPTION) |
|---|---|---|---|
model |
`str | None` | None |
model_provider |
`str | None` | None |
configurable_fields |
`Literal[‘any’] | list[str] | tuple[str, …] |
config_prefix |
`str | None` | None |
**kwargs |
Any |
— | 传递给底层聊天模型 __init__ 方法的额外关键字参数。常见参数包括: • temperature:控制输出随机性 • max_tokens:最大输出 token 数 • timeout:请求超时时间(秒) • max_retries:最大重试次数 • base_url:自定义 API 地址 • rate_limiter:限流器实例 具体支持参数请参考各模型提供商的集成文档。 |
安全提示:若设置
configurable_fields="any",则包括api_key、base_url等敏感字段都可能在运行时被修改,存在安全风险。建议在接收不可信输入时显式指定configurable_fields=(...)。
实际应用中,以下参数是常用的:
- model: 模型名称或 ID(如
gpt-4o、claude-3-5-sonnet-20241022),建议使用带版本的固定标识以确保生产稳定性。 - model_provider: 模型提供商(如
openai、anthropic、google_vertexai),若未在model中通过前缀指定,建议显式设置以避免推断错误。 - temperature: 控制输出随机性
- max_tokens: 最大输出 token 数
- timeout: 请求超时时间(秒),建议设为
30–60,避免因 LLM 服务延迟导致系统阻塞。 - max_retries: 请求失败时的最大重试次数,生产环境推荐
2–3次,平衡容错与延迟。 - base_url: 自定义 API 端点地址,用于私有部署、代理或云平台(如 Azure OpenAI)集成。
- api_key: 访问模型 API 的密钥,应通过安全方式(如环境变量或密钥管理服务)注入,禁止硬编码。
具体可参考模型提供商的需求进行配置,以下以通义为例:
from langchain.chat_models import init_chat_model
from config import QWEN_TEXT_MODEL, QWEN_API_KEY, QWEN_BASE_URL
chat_model = init_chat_model(
model = QWEN_TEXT_MODEL,
api_key = QWEN_API_KEY,
base_url = QWEN_BASE_URL,
model_provider="openai",
max_retries = 3,
timeout = 30,
max_tokens = 8096
)
print(chat_model.invoke("你好,介绍一下你自己"))
截至2025/12/10支持的模型提供商包括:anthropic、huggingface、bedrock、upstage、google_vertexai、openai、fireworks、mistralai、ibm、cohere、xai、google_anthropic_vertex、google_genai、bedrock_converse、perplexity、groq、azure_ai、azure_openai、ollama、deepseek、together
若不清楚当前提供商是否受支持(如qwen),可以测试看看报错model_provider=“qwen”。
使用openai一般就行,几乎所有的模型提供商都兼容OpenAI的API
其他方法
init_chat_model作为最基础的构建模型的方法是通用的,但是在langchain社区提供了许多构建模型的提供商特供方法,如ChatOpenAI,访问以下网址查看所有可用聊天模型:
聊天模型(Chat models) | LangChain 中文文档
这里以deepseek为例
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(
model="...",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# api_key="...",
# other params...
)
提供商提供的集成将包含提供商所支持的更强大的功能以及更方便的使用,如你无需在使用ChatDeepSeek时设置base_url等
对话
必须调用聊天模型以生成输出。主要有三种调用方法,每种方法适用于不同的用例。
Invoke
调用模型的最直接方法是使用 invoke() 传入单个消息或消息列表。
response = model.invoke("为什么鹦鹉有五颜六色的羽毛?")
print(response)
可以传递对话历史,详细内容将在下文讲解
from langchain.messages import HumanMessage, AIMessage, SystemMessage
conversation = [
{"role": "system", "content": "你是一个将英语翻译成法语的有用助手。"},
{"role": "user", "content": "翻译:我喜欢编程。"},
{"role": "assistant", "content": "J'adore la programmation."},
{"role": "user", "content": "翻译:我喜欢构建应用程序。"}
]
response = model.invoke(conversation)
print(response)
Stream
大多数模型可以在生成时流式传输其输出内容,请具体参考提供商文档。通过逐步显示输出,流式传输显著改善了用户体验,尤其是对于较长的响应。
调用 stream() 返回一个迭代器,它在生成时逐块产生输出。您可以使用循环实时处理每个块:
for chunk in model.stream("为什么鹦鹉有五颜六色的羽毛?"):
print(chunk.text, flush=True)
通常,使用循环实时处理每个块:
for chunk in model.stream("天空是什么颜色?"):
for block in chunk.content_blocks:
if block["type"] == "reasoning" and (reasoning := block.get("reasoning")):
print(f"推理:{reasoning}")
elif block["type"] == "tool_call_chunk":
print(f"工具调用块:{block}")
elif block["type"] == "text":
print(f"内容块: {block["text"]}")
else:
...
这在搭建前端页面显示中很有用,比如deepseek的深度思考内容与结果的分别展示。
智能体
智能体将语言模型与工具结合,创建能够对任务进行推理、决定使用哪些工具并迭代寻求解决方案的系统。
create_agent 提供了一个生产就绪的智能体实现。
智能体会一直运行,直到满足停止条件——即模型输出最终结果或达到迭代次数限制。
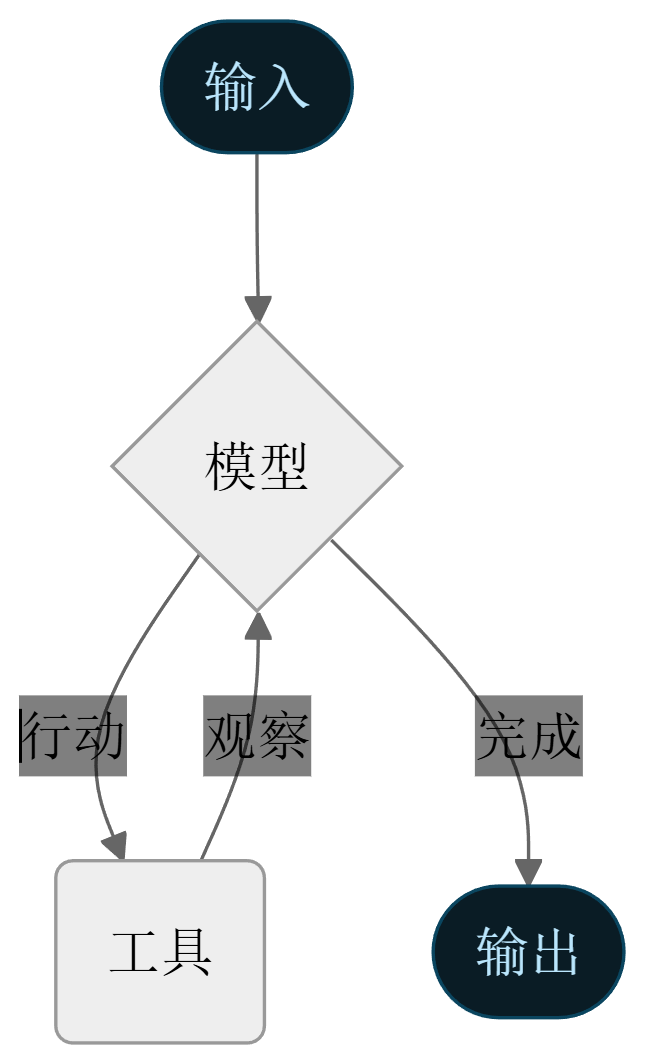
先通过一个实例认识一下智能体的基本构建
from langchain.agents import create_agent
agent = create_agent(
model=basic_model, # 默认模型
tools=tools
)
智能体必须包含model(上文的模型)以及工具(可以为空),这里我们先通过一个示例看看智能体的效果:
from langchain.tools import tool
from langchain.agents import create_agent
@tool
def search(query: str) -> str:
"""搜索信息。"""
return f"结果:{query}"
@tool
def get_weather(location: str) -> str:
"""获取位置的天气信息。"""
return f"{location} 的天气:晴朗,72°F"
agent = create_agent(
model,
tools=[search, get_weather],
system_prompt="你是一个有帮助的助手。请简洁准确。"
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "旧金山天气如何?"}]}
)
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
# 假设 result 是你 Graph 的输出,例如 result = graph.invoke(...)
for message_group in result.values():
for msg in message_group:
if isinstance(msg, HumanMessage):
print(f"👤 用户输入: {msg.content}")
elif isinstance(msg, AIMessage):
# 检查是否有工具调用
if msg.tool_calls:
print("🤖 模型调用了工具:")
for tool_call in msg.tool_calls:
print(f" - 工具名称: {tool_call['name']}")
print(f" 参数: {tool_call['args']}")
print(f" 调用ID: {tool_call['id']}")
else:
# 没有工具调用,说明是最终回复
print(f"💬 模型回复: {msg.content}")
elif isinstance(msg, ToolMessage):
print(f"🔧 工具 '{msg.name}' 返回: {msg.content}")
# 可选:打印 tool_call_id 用于调试
# print(f" (对应调用ID: {msg.tool_call_id})")
else:
# 兜底:打印未知类型消息
print(f"❓ 未知消息类型: {type(msg).__name__} | 内容: {msg}")
结果为:
👤 用户输入: 旧金山天气如何?
🤖 模型调用了工具:
- 工具名称: get_weather
参数: {'location': '旧金山'}
调用ID: call_362a360c22414cf7828fe1
🔧 工具 'get_weather' 返回: 旧金山 的天气:晴朗,72°F
💬 模型回复: 旧金山天气晴朗,温度为72°F。
因此可以看到,当使用create_agent后,会自动帮你创建一个能调用工具的智能体并尝试通过工具解答问题
当然,结合langchain提供的核心组件,我们将能够构建出更加强大的智能体。
接下来将会逐步进入到langGraph并根据需求逐步进行组件讲解。
下一节预告:搭建官方测试环境与langgraph初识
end

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)