强化学习背后的数学魔法:结合马里奥跳格子的案例
本文深入浅出地讲解了强化学习(RL)的数学原理及其算法实现。作者通过训练宠物狗的类比,生动解释了RL的核心概念,包括马尔可夫决策过程、回报函数、策略梯度等关键数学原理。文章详细拆解了4个引理和4个定理,展示了如何将这些数学原理应用于实际算法架构,并以《超级马里奥兄弟》游戏为例,演示了DQN算法的具体实现步骤。最后强调数学是RL架构的基石,并鼓励读者动手实践。全文用通俗易懂的语言将复杂的RL数学原理
嘿,大家好!欢迎来到数据与算法架构提升之路博客,我一个热衷于拆解AI算法背后的数据与架构逻辑的探索者。今天,我们来聊聊强化学习的数学原理。这玩意儿听起来抽象,但其实就像训练宠物狗:通过奖励和惩罚,让它学会新技能。别慌,我会用最接地气的语言解释,避免公式轰炸(必要的会简单标注)。如果你是数据分析师、算法工程师或AI爱好者,这篇文章能帮你从“雾里看花”到“豁然开朗”,理解为什么RL能让AI玩游戏、开车甚至优化工厂生产。
为什么这篇博文值得读?强化学习是当下AI架构的核心——从ChatGPT的决策到自动驾驶的路径规划,全都靠它。读完,你还能在团队会议上自信分享:“我懂了RL的数学骨架!”
1. 开头先介绍关键数学概念:引理与定理概览
在深入RL数学之前,让我们先快速过一遍核心引理和定理。这些是RL的“建筑砖块”,我会用通俗话介绍每个,然后在文章正文中引用并展开。重新编号从基础开始,避免原教材的特定标签。这里我把它们命名为引理1到定理4,便于记忆。
- 引理1(回报递归拆分):回报可以拆成当前奖励加上折扣后的未来回报。这像预算规划:今天花的钱 + 明天打折后的剩余。
- 引理2(回报多步展开):把引理1反复应用,回报变成所有未来奖励的折扣求和。方便计算长期价值,就像Excel里的累加公式。
- 引理3(稳态分布性质):当系统运行久了,状态出现概率稳定下来,用这个概率计算期望值更简单。像流量统计:不用追踪每辆车,只看平均分布。
- 定理1(策略梯度核心):目标函数的梯度可以用状态-动作对的期望表示,指导AI调整策略。核心是“试错后加强好行为”。
- 定理2(带基线策略梯度):在梯度中减去一个状态相关的基线,降低计算噪音,但不影响方向。像信号处理:滤掉干扰,提升精度。
- 定理3(目标函数优势形式):目标函数等价于动作优势的期望,连接策略优化和价值估计。揭示“为什么好动作能脱颖而出”。
- 定理4(确定性策略梯度):针对非概率策略,直接对输出求梯度。适合连续动作场景,如机器人手臂控制。
这些概念互相连接,形成RL的数学框架。下面,我们一步步拆解如何应用它们。
2.RL基础:从游戏到现实架构
想象你在设计一个AI玩《超级马里奥》:AI(代理)在关卡(环境)里决策,吃金币(正奖励)避开敌人(负奖励)。RL不是硬编码规则,而是让AI通过数据互动自学最佳路径。
数学模型是马尔可夫决策过程(MDP):
- 状态s:当前场景,如马里奥位置。
- 动作a:选择跳或跑。
- 策略π:决策概率分布。
- 奖励r:反馈分数。
- 折扣γ:未来奖励打折(0<γ<1)。
目标?最大化累计奖励!现在,用上面介绍的引理和定理来实现。
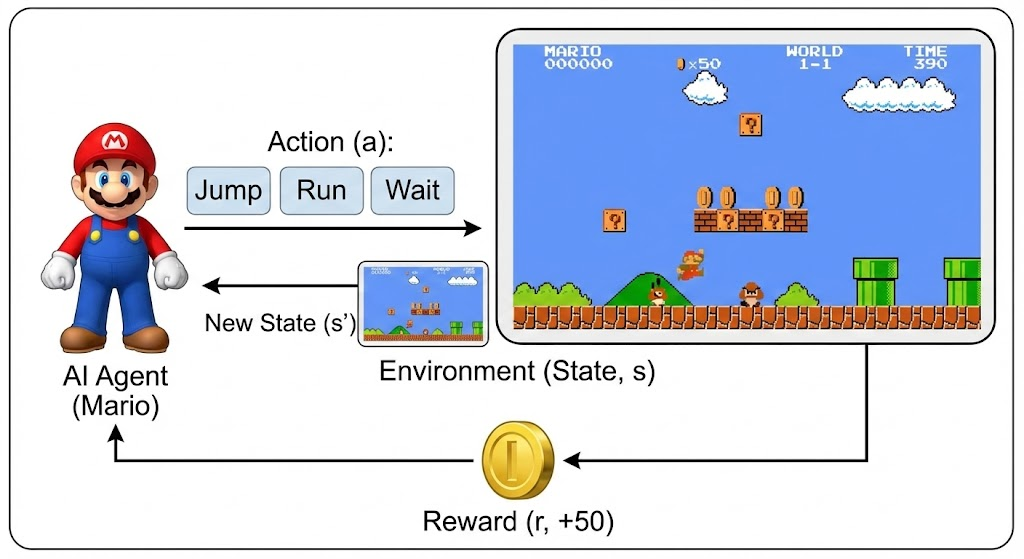
2.1 原理1: 回报的拆解——长远眼光的数学表达
RL强调长期收益,用回报G量化:从现在起,所有未来奖励的折扣和。
引用引理1:G_t = r_t + γ * G_{t+1}。 这把回报递归拆分:当前价值 = 即时反馈 + 打折后的下步价值。为什么?因为未来不确定,但递归让计算可行,就像动态规划里的贝尔曼方程。
进一步,引用引理2:展开后,G_t = r_t + γ r_{t+1} + γ² r_{t+2} + ... 这变成时间差分求和,易于编程实现。在马里奥游戏里:不只吃眼前金币,还算“吃完后会不会多活几秒”。
现实架构:数据中心优化能源时,用这个计算“现在关机 vs 继续跑”的长期成本。
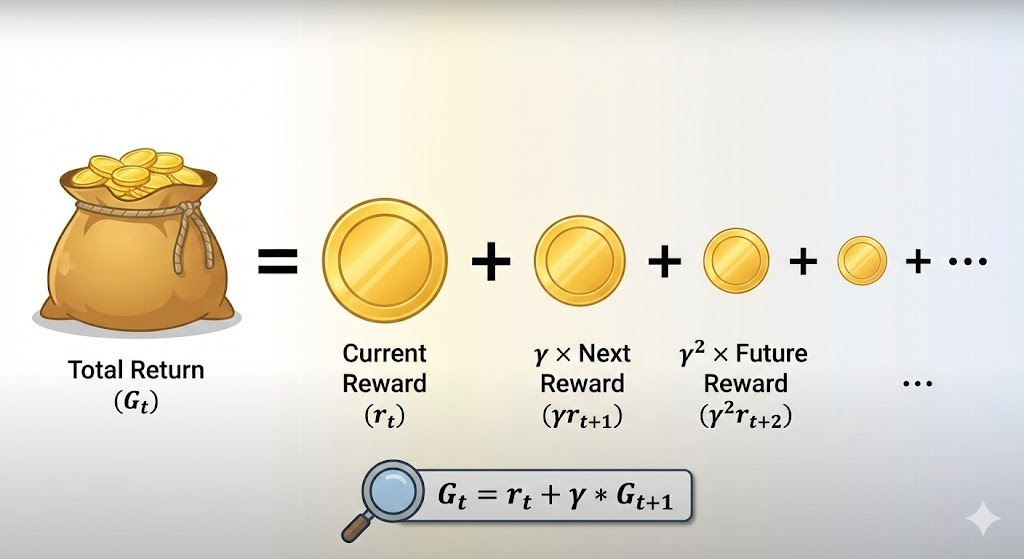
2.2 原理2: 稳态分布——数据稳定的统计魔力
环境动态变化,状态分布会趋于稳定。引用引理3:E[f(s)] ≈ 在稳态分布下的平均f(s)。 这简化计算:不用模拟无限轨迹,只抽样稳态状态求期望。像大数据分析:用样本分布估整体。
在RL架构中,这让训练高效——结合蒙特卡洛采样,快速估计价值。
2.3 原理3: 策略梯度——AI进化的引擎
怎么优化策略π?用梯度上升调整参数θ,使目标J(θ)最大化。J(θ)是平均回报。
引用定理1:∇θ J(θ) = E[∇θ log π(a|s) * Q(s,a)]。 翻译:梯度 = 期望[动作自信对数 * 该动作价值]。好动作(高Q)就强化,坏的弱化。REINFORCE算法基于此,让AI试错进化。
为什么强大?直接优化策略参数,适合神经网络架构。AlphaGo用类似梯度,学会围棋策略。
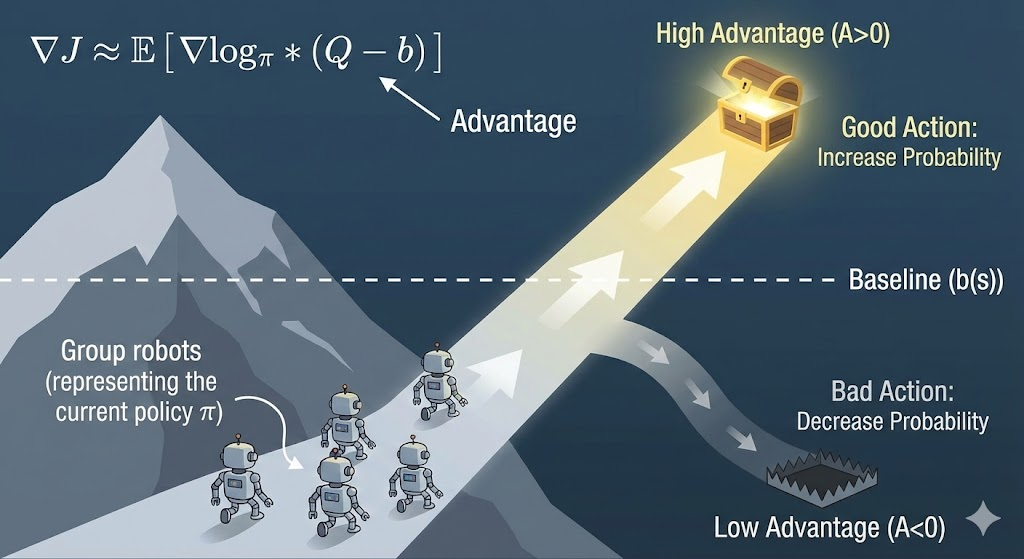
2.4 原理4: 加基线和优势——优化噪音与效率
梯度有时波动大。引用定理2:∇θ J(θ) = E[∇θ log π(a|s) * (Q(s,a) - b(s))]。 基线b(s)是状态平均价值,减噪音不偏方向。像数据清洗:滤掉无关波动。
更进一步,引用定理3:J(θ) = E[A(s,a)],A是优势(Q - V)。 这统一策略和价值:优化 = 让优势动作突出。PPO、TRPO算法用此,训练更稳。
2.5 原理5: 确定性策略——连续世界的精准控制
概率策略不适合所有场景。引用定理4:∇θ J(θ) = E[∇θ π(s) * ∇a Q(s,a)]。 直接对输出a求梯度,无随机采样。DDPG算法应用此,在机器人架构中控制连续动作,如抓取物体。
3. 现实落地:从数学到算法架构
现在来聊聊如何将它们落地到实际算法架构中。以《超级马里奥兄弟》的“跳格子”场景为例,这个经典游戏完美模拟RL挑战:AI需从屏幕像素(状态)中决策跳跃、避敌,吃金币(奖励)并通关。我们用DQN(Deep Q-Network)算法作为方案,它结合价值函数和Q学习,间接实现策略优化。DQN基于贝尔曼方程(类似引理1和2)处理回报,通过Q值隐含策略(连接定理1-3)。
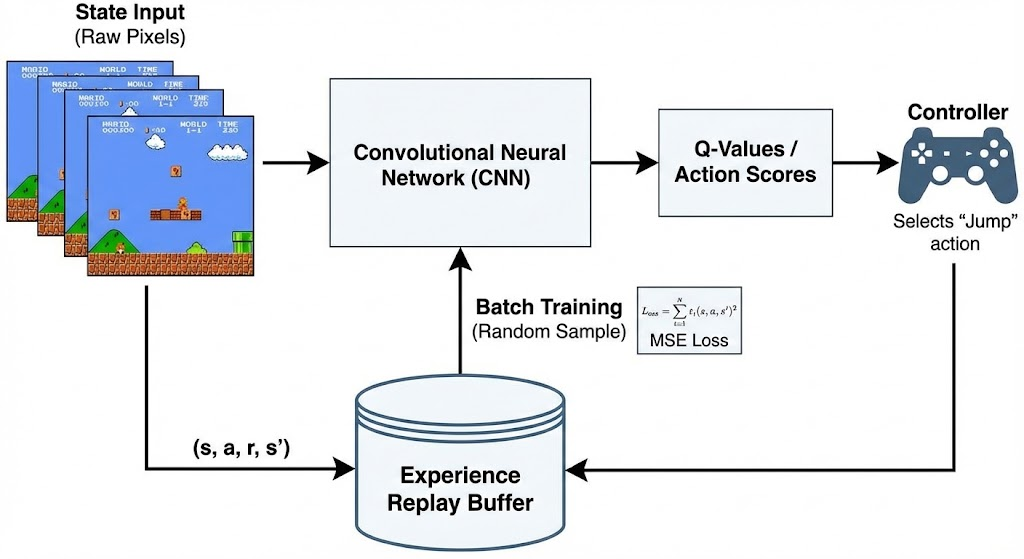
3.1 步骤1: 环境与数学映射
首先,将问题抽象为MDP模型。状态s:游戏屏幕(240x256 RGB图像)。动作a:简化集,如[不动、右走、跳]。奖励r:前进+1、金币+50、死亡-100。折扣γ=0.99。 应用引理1(G_t = r_t + γ * G_{t+1})和引理2(展开为Σ γ^k * r_{t+k})计算长期回报。稳态分布(引理3)通过多局模拟实现。 代码方案:用Gym库安装环境(pip install gym-super-mario-bros)。
import gym_super_mario_bros
from gym_super_mario_bros.actions import simple_movement
env = gym_super_mario_bros.make('SuperMarioBros-v0')
env = JoypadSpace(env, simple_movement) # 动作空间
state = env.reset() # 初始屏幕3.2 步骤2: 构建DQN架构
DQN用CNN逼近Q(s,a),基于定理1的梯度思想:选max Q动作。引入目标网络作为基线(定理2),优势函数(定理3)隐含在更新中。 Q更新:Q(s,a) ≈ r + γ * max Q'(s',a')(扩展引理1)。损失:MSE最小化误差。 代码:Keras建模型,经验回放deque存储过渡。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense
from collections import deque
import numpy as np
class DQNAgent:
def __init__(self, state_shape=(240,256,3), action_size=7):
self.memory = deque(maxlen=5000)
self.gamma = 0.99
self.model = Sequential([Conv2D(32, (8,8), strides=4, activation='relu', input_shape=state_shape),
# ... (其他层)
Dense(action_size)])
self.target_model = Sequential(...) # 复制模型3.3 步骤3: 训练与优化
用epsilon-greedy探索(随机/贪婪)。每步存储(s,a,r,s',done),采样训练。更新target网络减方差。 代码循环:跑1000 episodes,act()选动作,replay()训练。AI从乱跳到智能避敌。 对于连续动作,可扩展到定理4的DDPG。优化:GPU加速,预处理图像(灰度+帧栈)。
在马里奥方案中,引理1-3处理回报/分布,定理1-4导优化。架构是CNN+双网络+回放,Python让数学落地。
4. 结语:数学是RL架构的基石
我们看到RL数学从回报拆分(引理1-2)、分布简化(引理3)到梯度优化(定理1-4),构建高效AI系统。想实践?用Gym环境写REINFORCE代码试试。
喜欢?点赞、订阅、评论你的疑问!下篇聊RL在大数据架构的应用。保持学习,架构之路无限精彩!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)