AI的“多巴胺陷阱”:行业领袖警告,炫酷演示正扼杀实质性突破
【摘要】AI行业正陷入追求即时满足的“多巴胺陷阱”,过度优化炫酷演示,忽视了解决根本问题的“真相”追求。行业亟需一场从浮华到务实的深刻变革,回归高质量数据与真实价值创造。
【摘要】AI行业正陷入追求即时满足的“多巴胺陷阱”,过度优化炫酷演示,忽视了解决根本问题的“真相”追求。行业亟需一场从浮华到务实的深刻变革,回归高质量数据与真实价值创造。

引言
人工智能领域正处在一个奇特的十字路口。一方面,技术以前所未有的速度迭代,能力边界每日都在刷新;另一方面,一种深刻的忧虑情绪正在资深从业者中蔓延。Surge AI首席执行官Edwin Chen在近期的公开言论中,将这种忧虑精准地概括为行业正在陷入“多巴胺陷阱”。他警告说,我们投入巨大的人才与算力,并非在构建能治愈癌症、解决贫困的AI,而是在训练模型去追逐廉价的快感,去优化那些转瞬即逝的“AI垃圾”。
这番言论并非危言耸听,它揭示了一个深刻的系统性问题。当前AI的发展路径,在资本、媒体和大众认知的合力推动下,正表现出一种对“炫酷”的过度偏好,而对“实质”的耐心则日渐消磨。本文将深入剖析这一“多巴胺陷阱”的现象、技术根源及其潜在风险,并结合Surge AI等公司的务实探索,探讨AI行业如何才能摆脱浮躁,回归创造长期价值的正确轨道。
🎯 一、AI的“多巴胺陷阱”:现象与技术本质

“多巴胺陷阱”并非一个纯粹的商业或文化现象,它的根源深植于当前主流AI模型的技术实现路径中。理解这一点,是看清整个行业困境的前提。
1.1 核心矛盾:“多巴胺”优化 vs. “真相”追求
这个矛盾是问题的核心。我们需要清晰定义这两个概念在AI语境下的具体含义。
-
“多巴胺”优化 (Dopamine Optimization)
这是一种以即时用户满足感为最高优先级的开发与训练倾向。其产出物通常具备以下特征:-
高娱乐性:能生成有趣的图片、编写俏皮的对话、模仿名人声音。
-
强互动性:能快速响应用户,提供看似个性化的反馈。
-
易于传播:演示效果惊艳,极易在社交媒体上形成病毒式传播。
这些应用能为用户带来短暂的快感和高度的参与感,但它们往往缺乏深度、可靠性与长期价值。它们的设计目标是“好玩”,而不是“正确”或“有用”。
-
-
“真相”追求 (Truth Seeking)
这代表了AI应用的终极目标,即利用技术严谨、可靠地解决现实世界中的根本性问题。其应用场景包括:-
加速科学发现:如AlphaFold预测蛋白质结构,推动新药研发。
-
优化复杂系统:如管理全球供应链、预测气候变化。
-
提升人类福祉:如辅助进行精准医疗诊断、提供高质量的个性化教育。
这些任务要求AI模型具备极高的准确性、鲁棒性、可解释性和事实一致性。它们追求的是“正确”,即便过程和结果可能并不“好玩”。
-
1.2 “陷阱”在模型训练层面的技术体现
“多巴胺陷阱”之所以危险,因为它已经渗透到模型训练的底层机制中,尤其是在基于人类反馈的强化学习(RLHF)流程里。
1.2.1 奖励模型(Reward Model)的内在偏差
RLHF是当前微调大语言模型(LLM)的主流技术。其核心是训练一个奖励模型(RM),用它来评估模型生成的答案质量,并指导主模型进行优化。问题在于,奖励模型的“价值观”完全来自于人类标注者的偏好。
如果标注任务的设计和指令过于侧重于“哪个回答更流畅?”、“哪个更有趣?”、“哪个更像人类?”,那么标注者自然会给那些华而不实、自信满满但可能包含事实错误的回答打高分。久而久之,奖励模型就学会了这种“多巴胺偏好”。
|
训练信号 |
“多巴胺”优化导向 |
“真相”追求导向 |
|---|---|---|
|
人类反馈指令 |
“选择你更喜欢的回答” |
“选择事实最准确、逻辑最严谨的回答” |
|
模型优先行为 |
生成流畅、自信、迎合用户的文本 |
生成严谨、可验证、承认不确定性的文本 |
|
潜在负面结果 |
幻觉(Hallucination)增多,事实性降低 |
回答可能更保守、枯燥,但可靠性高 |
|
优化目标 |
最大化用户的主观满意度 |
最大化回答的客观正确性 |
这个过程形成了一个闭环。主模型为了从奖励模型那里获得高分,会不断学习如何更好地“取悦”人类,而不是如何更接近“真相”。
1.2.2 公开排行榜(Leaderboard)的误导效应
诸如Chatbot Arena之类的公开排行榜,虽然在一定程度上推动了模型的竞争与进步,但也加剧了“多巴胺陷阱”。这类平台大多采用Elo评级系统,基于用户的匿名投票来对模型进行排序。
用户的投票标准是什么?绝大多数情况下,是即时的、主观的体验。一个能讲笑话、写情诗的模型,在普通用户那里获得“好评”的概率,远高于一个严谨地指出“我无法回答这个问题,因为缺乏足够信息”的模型。
这种机制导致模型开发者将大量工程资源投入到优化排行榜表现上,形成一种“应试教育”。他们研究如何让模型在对话的头几个回合就抓住用户的心,而不是构建一个真正具备深度推理和知识能力的系统。
1.2.3 演示(Demo)驱动的开发文化
在产品层面,一个炫酷的演示视频是获取融资、吸引媒体和赢得内部支持的最快途径。这导致了“演示驱动开发”(Demo-Driven Development)的盛行。工程团队的优先级不再是构建稳定、可靠的后端系统,而是快速实现那些在演示中最亮眼的功能。
这种开发模式的后果是,产品可能拥有一个光鲜的外壳,但内部却极其脆弱。许多备受瞩目的AI产品在发布后迅速“翻车”,正是因为其底层能力远未达到演示所承诺的水平。
🎯 二、炫技背后的驱动力:系统性偏差的根源
AI行业之所以会集体陷入“多巴胺陷阱”,并非个别公司的短视,而是一个由资本、组织和文化共同构成的系统性问题。
2.1 资本叙事与市场压力
风险投资(VC)的运作模式天然倾向于追逐高增长、高回报的项目。在AI领域,这意味着资本更青睐那些能够快速获取用户、形成网络效应、并讲述一个宏大“平台故事”的公司。
-
叙事的重要性:一个能生成逼真视频的AI模型,其故事远比一个能将数据标注错误率降低0.5%的工具更性感,也更容易在投资圈中传播。
-
增长的压力:追求“多巴胺”的应用,如AI社交、AI游戏,更容易实现病毒式增长和高用户粘性,这些是VC衡量成功与否的关键指标。
-
短期主义:解决癌症或气候变化需要漫长的研发周期和巨大的不确定性。相比之下,开发一款娱乐性AI应用,能更快地推向市场并产生现金流。
这种资本偏好,使得创业者不得不将资源向“炫技”倾斜,以求在激烈的融资竞争中生存下来。
2.2 组织惯性与“表演式创新”
在大型科技公司内部,同样存在类似的问题。许多公司的AI战略呈现出一种“为了AI而AI”的倾向。
-
管理层的焦虑:由于担心在AI浪潮中落后,管理层常常会自上而下地推动AI项目,但这些项目往往缺乏与核心业务的深度结合。
-
“创新剧场”:在一些组织中,创新变成了一种“表演”。团队花费大量时间制作精美的内部演示,以向上级展示“我们正在拥抱AI”。这些项目在演示结束后便被束之高阁,从未真正转化为产品价值。
-
KPI的扭曲:如果一个团队的KPI是“本季度上线X个AI功能”,那么团队的重心自然会放在那些容易实现、效果明显的浅层应用上,而不是去啃那些能带来长期价值的硬骨头。
2.3 媒体与公众的认知偏差
媒体和公众对AI的理解,在很大程度上塑造了行业的发展方向。
-
拟人化的偏好:媒体报道和公众讨论更关注那些让AI“更像人”的特性,如流畅的对话、丰富的情感表达。这使得模型在“拟人化”上的投入远超“工具化”。
-
对新奇的追逐:新闻的本质是追逐新奇。一个AI学会了新“才艺”,总能成为头条新闻。而一个AI系统在某个工业领域的效率提升了10%,则很难引起广泛关注。
这种外部环境形成了一个强大的正反馈循环。公司推出炫酷功能 -> 媒体争相报道 -> 公众产生更高期待 -> 公司投入更多资源开发更炫酷的功能。而那些真正重要的、但不够“性感”的基础性工作,则在这个循环中被边缘化。
🎯 三、技术歧途的代价:风险与机会成本

沉迷于“多巴胺陷阱”并非没有代价。它不仅会带来直接的技术风险,更会产生巨大的、难以估量的机会成本。
3.1 技术发展的“局部最优”陷阱
从优化理论的角度看,整个AI行业可能正陷入一个**“局部最优解”**。
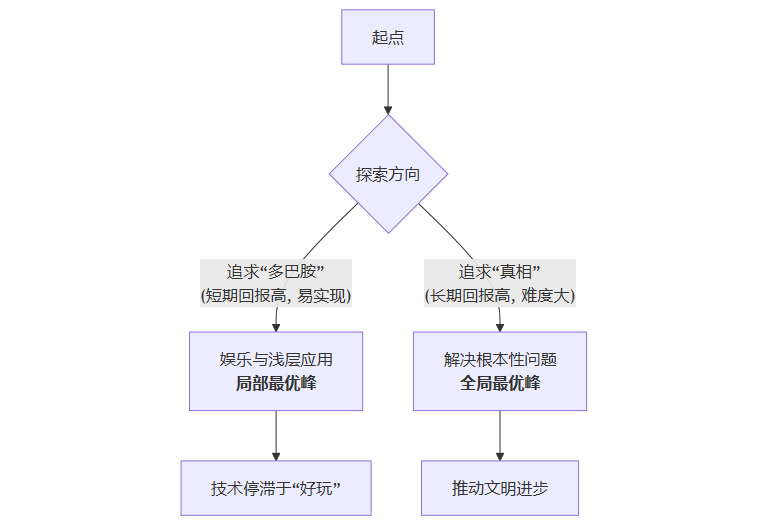
这个“局部最优峰”就是由各种娱乐性、浅层AI应用构成的繁荣景象。它看起来很高,回报很快,吸引了绝大多数的资源。然而,旁边可能存在一个更高、更有价值的“全局最优峰”——即利用AI解决人类面临的重大挑战。如果所有人才和资本都涌向了那个更低的“山峰”,我们可能永远没有足够的力量去攀登那座真正的高峰。
3.2 信任的侵蚀与“幻觉”常态化
“多巴胺”优化最直接的技术恶果,就是“幻觉”(Hallucination)问题被变相加剧。
为了让对话显得流畅、自信和无所不知,模型被训练得倾向于“编造”答案,而不是承认自己的无知。当这种行为模式从闲聊场景迁移到严肃的知识问答、医疗咨询或金融分析时,其后果可能是灾难性的。
-
错误信息的放大器:一个能言善辩的AI,可以把错误信息包装得比事实更有说服力,成为虚假信息传播的强大工具。
-
专业领域的风险:在法律、医疗等领域,一个看似专业但包含关键事实错误的AI建议,可能导致用户做出错误的决策,造成不可挽回的损失。
-
公众信任的流失:如果公众普遍认为AI“不可信”、“满嘴跑火车”,那么即便未来出现了真正可靠的AI系统,也很难获得社会的接纳和应用。
3.3 人才与算力的巨大错配
这是最令人痛心的机会成本。
-
人才浪费:全球最顶尖的一批数学家、计算机科学家和工程师,他们本可以致力于攻克癌症、开发清洁能源、设计更高效的城市交通系统。但现在,他们中的许多人正在花费宝贵的智力,去优化一个AI模型生成笑话的“幽默感”,或者调整图片生成模型中“手指”的细节。
-
算力空耗:训练和运行大型AI模型需要消耗惊人的计算资源和能源。当这些宝贵的算力被大量用于生成表情包、编写营销文案时,我们必须反思,这是否是对人类社会稀缺资源的最优配置。
这种资源错配,延缓了AI在真正关键领域创造价值的进程,其代价难以用金钱衡量。
🎯 四、破局之道:Surge AI的务实主义实践
在行业普遍浮躁的背景下,Edwin Chen领导的Surge AI提供了一个截然不同的、以“实质”为核心的成功范例。分析其模式,可以为我们找到摆脱陷阱的路径。
4.1 核心理念:数据质量决定智能上限
Surge AI的官网异常简洁,没有花哨的动画,只有一行核心标语:“数据质量决定了你的抱负上限”。这揭示了他们的第一性原理。在算法、算力和数据这AI三要素中,他们将高质量数据置于绝对核心的地位。
他们认为,模型的智能水平,最终不是由模型参数量或计算能力决定的,而是由其“消化”的训练数据的“智力密度”决定的。低质量、重复性的数据,无论规模多大,都只能训练出“鹦鹉学舌”式的模型。
4.2 实践一:专家驱动的高质量数据标注
Surge AI的数据标注方法论,与传统的“计件式”众包平台有着本质区别。
4.2.1 拒绝“简单重复”,拥抱“复杂推理”
他们专注于那些需要领域专家知识和深度推理能力的复杂标注任务。例如,让一位资深程序员标注代码中的逻辑错误,或者让一位医生评估医疗影像的诊断报告。这些任务无法通过简单的指令让普通人完成。
4.2.2 创新范式:记录“推理轨迹”
这是Surge AI最具洞察力的一点。他们不仅仅要求标注者给出最终的“正确答案”,更要求他们详细记录得出这个答案的完整思考过程,即“推理轨迹”(Chain of Thought)。
下面是两种标注范式的对比:
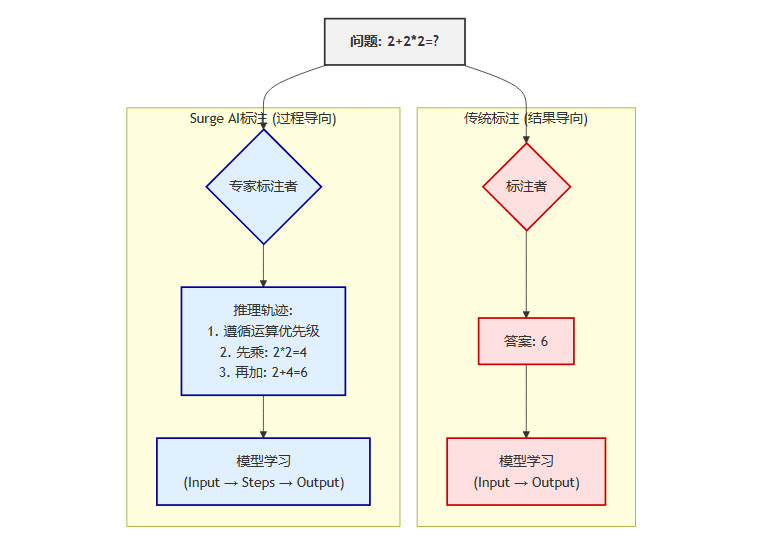
通过学习这种“推理轨迹”,模型不再是简单地拟合“问题-答案”对,而是在学习如何像专家一样思考。这为训练出真正具备推理能力、而不仅仅是模式匹配能力的AI模型,提供了至关重要的数据基础。这种方法后来被称为“过程监督”(Process Supervision),被认为是克服LLM局限性的关键路径之一。
4.3 实践二:独特的人才与商业模式
为了实现高质量的数据标注,Surge AI建立了一套独特的商业模式。
-
高薪酬吸引顶尖人才:其零工平台Data Annotation为自由职业者提供远高于行业平均水平的薪酬,时薪可达40美元甚至更高。这吸引了大量具备专业技能和高学历的人才加入。
-
严格的筛选机制:平台会对申请者进行严格的技能测试,确保只有最优秀的人才能参与到核心项目中。
-
价值驱动的定价:尽管成本更高,但Surge AI为客户提供的数据质量也远超同行。顶级AI公司如OpenAI、Anthropic、Google都愿意为其“智力密度”和“创造力密度”极高的数据支付溢价。
这种模式的成功证明了,在AI领域,对质量的极致追求本身就可以构成坚实的商业护城河。在没有外部融资、没有销售团队的情况下,Surge AI实现了惊人的增长,年营收据称已超过10亿美元,其利润留存和资本效率远超规模更大的竞争对手。
4.4 实践三:极致的产品主义与务实文化
Edwin Chen本人是“最小可用产品”(MVP)理念的坚定信徒。他反对在产品价值得到验证前进行过度宣传和融资。这种文化贯穿了整个公司。
-
产品为王:公司将所有资源都聚焦于打磨核心产品——高质量数据。
-
低调务实:在行业内,Surge AI长期保持低调,直到其业务规模和行业影响力已经无法被忽视。
-
拒绝泡沫:他们相信真正的价值来自于为客户解决实际问题,而不是参与一场“地位游戏”或资本炒作。
🎯 五、回归本源:构建追求“真相”的AI系统

Surge AI的实践为整个行业指明了方向。要摆脱“多巴胺陷阱”,我们需要在技术、评估和战略层面进行系统性的变革。
5.1 训练范式的革新:从“取悦”到“求真”
我们需要重新设计模型的训练和微调流程,将优化目标从“主观偏好”转向“客观事实”。
5.1.1 改进RLHF流程
-
引入事实核查:在标注流程中加入强制性的事实核查环节。对于包含事实性知识的回答,标注者必须验证其准确性,并对包含错误信息的回答给予强烈的负反馈。
-
奖励“诚实的无知”:明确鼓励模型在面对超出其知识范围或不确定的问题时,回答“我不知道”或“我无法确定”。在奖励模型中,一个诚实的“不知道”应该比一个自信的“胡说八道”获得更高的分数。
-
多维度评价:将单一的“偏好”评分,分解为多个维度的评价,如事实准确性、逻辑一致性、信息有用性、表达清晰性等,并为“事实准确性”赋予最高的权重。
5.1.2 全面拥抱过程监督(Process Supervision)
行业需要从结果监督(Supervising Outcomes)大规模转向过程监督(Supervising Processes)。这意味着我们的数据标注和模型训练,都应该更关注“思考过程”的正确性,而非仅仅是最终答案的对错。这不仅能提升模型的推理能力,还能极大地增强其可解释性。
5.2 评估体系的重塑:超越主观排行榜
我们需要建立一套更科学、更全面的AI模型评估体系,以取代当前被主观偏好主导的排行榜。
-
发展领域专用基准测试(Domain-Specific Benchmarks):针对医疗、法律、金融、编程等专业领域,开发能够衡量模型在真实世界任务中表现的标准化测试集。这些测试应侧重于评估模型的专业知识、推理能力和解决实际问题的效果。
-
引入“对抗性”评估:设计专门的评估方法,主动探测模型的弱点。例如,通过精心设计的“陷阱问题”来测试模型的鲁棒性,或者通过多轮追问来检验其逻辑一致性。
量化“幻觉率”:将“幻觉率”作为衡量模型可靠性的核心指标,并建立标准化的测试流程。
-
推行长期、多轮的任务导向评估:用一个单一问题来评估模型是片面的。更有效的评估方式是,让模型完成一个需要多步骤、长期交互的复杂任务。观察模型在整个任务流程中的表现,才能全面地评估其规划、推理和纠错能力。
5.3 战略重塑:从“讲故事”到“创价值”
技术和评估体系的变革,最终需要企业战略层面的支持。企业必须从根本上转变对AI价值的认知。
5.3.1 回归真实业务场景
AI项目的起点,不应是“我们能用AI做什么炫酷的事”,而应是“我们业务中最棘手的痛点是什么”。这种以问题为导向的思路,才能确保AI技术真正落地并创造价值。
许多传统行业已经开始以一种严肃、实用的方式将大模型嵌入其核心流程,实现了效率和质量的实质性提升。
-
金融领域:利用AI进行复杂的合规文件审查、市场情绪分析和欺诈检测。
-
医疗领域:辅助医生解读医疗影像、分析病历、生成初步诊断报告。
-
制造业:通过AI进行供应链优化、设备预测性维护和产品质量控制。
这些应用或许不够“性感”,无法成为媒体头条,但它们实实在在地在为企业节省成本、增加收入、降低风险。这才是AI技术健康发展的基石。
5.3.2 建立企业自检清单
为了避免陷入“为了AI而AI”的陷阱,企业在规划和评估AI项目时,可以参考以下自检清单。
|
自检问题 |
警惕信号(Red Flag) |
务实方向(Green Flag) |
|---|---|---|
|
1. 项目动因 |
“我们必须用上最新的AI模型” |
“我们有一个业务瓶颈,AI可能是解决方案之一” |
|
2. 产品定位 |
产品是一个能讲故事的炫酷Demo |
产品是一个能实实在在改善业务流程的耐用品 |
|
3. 评价体系 |
评价标准奖励模型的“讨好”行为 |
评价标准严格奖励模型的“事实准确性”与“可靠性” |
|
4. 数据策略 |
追求数据量的规模,忽视质量 |
将资源优先投入到高质量、高“智力密度”的数据获取上 |
|
5. 失败容忍度 |
项目失败被视为团队能力的失败 |
将失败的AI项目视为一次有价值的业务实验,并复盘经验 |
这个清单可以帮助决策者保持清醒,确保每一分投入到AI领域的资源,都能对准真实、可衡量的业务价值。
结论
Edwin Chen和Surge AI的实践为整个行业敲响了警钟。当前AI领域对“多巴胺式”炫酷体验的过度追逐,正在将我们引向一条危险的技术歧途。这种趋势不仅浪费了宝贵的人才和算力,更在侵蚀公众对AI技术的长期信任。
摆脱这个陷阱,需要一场从上到下的系统性变革。在技术层面,我们必须革新训练范式,从“取悦人类”转向“追求真相”,将过程监督和事实核查置于核心。在评估层面,我们需要建立超越主观排行榜的、科学严谨的评估体系。在战略层面,企业必须回归商业本质,让AI服务于真实的业务痛点,而非沦为市场营销的噱头。
AI的最大潜力,蕴藏在那些看似枯燥但至关重要的基础工作中,蕴藏在对高质量数据和可靠推理的极致追求中。只有在浮华的创新与扎实的落地之间找到平衡,AI才能真正突破泡沫的幻象,成为推动社会进步的决定性力量,实现其解决人类宏大课题的最终承诺。
📢💻 【省心锐评】
AI的未来不在于取悦用户的炫技,而在于解决真实问题的能力。行业需戒除多巴胺依赖,回归对数据质量和客观真相的尊重。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献453条内容
已为社区贡献453条内容

所有评论(0)