Multidimensional harmonic retrieval based on Vandermonde tensor train
摘要—多维谐波恢复 (MHR) 处于重要的基于信号的应用的核心。利用大量可用的测量分集进行数据融合,必然会增加张量的阶数/维数。在这种情况下,缓解 “维数灾难” (curse of dimensionality) 至关重要。为了有效应对这一海量数据处理问题,提出了一种名为 JIRAFE (Joint dImensionality Reduction And Factors rEtrieval,联合
摘要—多维谐波恢复 (MHR) 处于重要的基于信号的应用的核心。利用大量可用的测量分集进行数据融合,必然会增加张量的阶数/维数。在这种情况下,缓解 “维数灾难” (curse of dimensionality) 至关重要。为了有效应对这一海量数据处理问题,提出了一种名为 JIRAFE (Joint dImensionality Reduction And Factors rEtrieval,联合维数约减与因子恢复) 的新方案,用于估计 MHR 问题中感兴趣的参数,即相关的 P-order rank-M Canonical Polyadic Decomposition (CPD)。我们的方法包含两个主要步骤。
-
第一步将高阶测量张量拆分为一组图连接的 3 阶张量,每个张量服从秩 M M M 的 3 阶 CPD,也称为张量列 (TT) 核 (TT-cores)。这一结果是基于 CPD 与具有耦合 TT 核的张量列分解 (TTD) 之间的模型属性等价性。
-
第二步利用一种基于范德蒙德 (Vandermonde) 的修正交替最小二乘 (RecALS) 算法,通过强制所需的矩阵结构来估计感兴趣的因子。
我们表明,我们的方法在灵活性、抗噪鲁棒性、计算成本以及关于张量阶数的感兴趣参数自动配对方面具有若干优势。
文章目录
1. Introduction
从估计的角度来看,最大似然估计器 [28,29] 是最佳选择,因为它是统计有效的,即在存在噪声的情况下,其均方误差 (MSE) 达到克拉美-罗下界 (CRB)。最大似然估计器的主要缺点是其极其昂贵的复杂度成本。这种限制在高阶数据张量的背景下尤为严重。
为了克服这个问题,文献中可以找到几种低复杂度的方法。这些方法有时可能无法达到 CRB,但与最大似然估计器相比,它们在计算成本方面提供了显著的收益。本质上主要有两类方法。
-
第一类基于数据的因式分解来估计众所周知的信号/噪声子空间,例如通过旋转不变技术估计信号参数 (ESPRIT) [30]、ND-ESPRIT [31]、改进的多维折叠技术 [32] 和 CP-VDM [33]。
-
第二类基于 CPD 的唯一性属性。事实上,利用 ALS 算法 [34] 对数据张量进行因式分解,可以通过检查因子矩阵直接识别未知参数。
然而,ALS 算法 [25] 及其大多数变体并没有考虑因子矩阵的范德蒙德 (Vandermonde) 结构。潜在地,舍弃这种关于 MH 模型的物理 先验 知识可能会降低未知参数的估计性能 [35]。因此,最近在 [36] 中引入了一类新的估计方法。这种被称为 RecALS (即 Rectified ALS,修正 ALS) 的方法通过在因子矩阵的范德蒙德结构上集成一种修正/增强策略来修改 ALS 方法。
在这项工作中,我们提出了一种名为 JIRAFE (Joint dImensionality Reduction And Factors rEtrieval,联合维数约减与因子恢复) 的新方案。JIRAFE 由两个主要步骤组成。
- 第一步是利用张量列分解 (TTD) [20] 对高阶谐波模型进行维数约减。我们展示了如何利用 CPD 和 TTD [1] 之间的模型等价性来设计一种高效的优化策略,该策略利用了耦合最小二乘 (LS) 问题之和。
- 第二步致力于使用多项式求根过程来估计未知参数。该方案属于 RecALS 家族,可以被视为 [36] 中提出的方案的一种替代方案。
我们的主要贡献可以总结如下:
- 基于范德蒙德的张量列分解 (VTTD)。 经典的 MHR 问题被重新表述为基于范德蒙德的 TT 格式,而不是通常的 CPD 表述。
- VTTD 的优化策略。 提供了 TT 核 (TT-cores) 的结构,特别是解释并利用了 TT 核之间存在的潜在耦合属性,用于耦合 LS 问题之和的顺序优化策略。这是 JIRAFE 的第一步,即维数约减步骤。
- 范德蒙德因子的新修正策略。 提出了一种针对范德蒙德因子的新修正策略,并将其用于 JIRAFE 的第二步,即恢复步骤。
接下来,本文的组织结构如下。在第 2 节中,我们将 MH 模型作为一个结构化的 CPD 进行介绍。在第 3 节中,将详细介绍 TT 分解和使用 TT-SVD 算法的维数约减策略。第 4 节给出了新提出的恢复方案的算法描述。第 5 节通过评估所提方法与一些最先进算法相比的鲁棒性和计算时间,给出了展示所提方法有效性的仿真结果。第 6 节为结论。
3. Dimensionality reduction based on a train of low-order tensors
3.1. Tensor train decomposition
Tensor Train 最初由 [20] 在线性代数领域引入。TTD 的原理是将一个大小为 N 1 × ⋯ × N P N_1 \times \cdots \times N_P N1×⋯×NP 的 P P P 阶张量 X \boldsymbol{\mathcal{X}} X 分解为一列 P − 2 P-2 P−2 个 3 阶张量/核以及两个矩阵。如图 1 所示,TT 核 (TT-cores) 是图中的节点,边是两个连续核之间的公共维数,称为 TT 秩 (TT-ranks)。TTD 的正式定义如下。
定义 4. 如果一个 P P P 阶张量 X \boldsymbol{\mathcal{X}} X 满足以下条件,则它可以分解为张量列
[ X ] n 1 , … , n P = ∑ r 1 , … , r P − 1 = 1 R 1 , … , R P − 1 [ G 1 ] n 1 , r 1 [ G 2 ] r 1 , n 2 , r 2 ⋯ [ G P − 1 ] r P − 2 , n P − 1 , r P − 1 [ G P ] r P − 1 , n P , (10) [\boldsymbol{\mathcal{X}}]_{n_1, \ldots, n_P} = \sum_{r_1, \ldots, r_{P-1}=1}^{R_1, \ldots, R_{P-1}} [\mathbf{G}_1]_{n_1, r_1} [\boldsymbol{\mathcal{G}}_2]_{r_1, n_2, r_2} \cdots [\boldsymbol{\mathcal{G}}_{P-1}]_{r_{P-2}, n_{P-1}, r_{P-1}} [\mathbf{G}_P]_{r_{P-1}, n_P}, \tag{10} [X]n1,…,nP=r1,…,rP−1=1∑R1,…,RP−1[G1]n1,r1[G2]r1,n2,r2⋯[GP−1]rP−2,nP−1,rP−1[GP]rP−1,nP,(10)
- 1 ≤ p ≤ P 1 \le p \le P 1≤p≤P: P P P 代表张量的阶数(Order),即维度的总数量。 p p p 是维度的序号。它表示我们当前正在讨论第几个维度(从第 1 维到第 P P P 维)。
- 1 ≤ n p ≤ N p 1 \le n_p \le N_p 1≤np≤Np: N p N_p Np 代表第 p p p 个维度的大小(Size/Dimension length)。 n p n_p np 代表在第 p p p 个维度上的具体坐标索引。它的取值范围是从 1 到该维度的大小 N p N_p Np。
或者等价地
X = G 1 × 2 1 G 2 × 3 1 G 3 × 4 1 ⋯ × P − 1 1 G P − 1 × P 1 G P , (11) \boldsymbol{\mathcal{X}} = \mathbf{G}_1 \times_2^1 \boldsymbol{\mathcal{G}}_2 \times_3^1 \boldsymbol{\mathcal{G}}_3 \times_4^1 \cdots \times_{P-1}^1 \boldsymbol{\mathcal{G}}_{P-1} \times_P^1 \mathbf{G}_P, \tag{11} X=G1×21G2×31G3×41⋯×P−11GP−1×P1GP,(11)
其中 TT 核 G 1 \mathbf{G}_1 G1, G p \boldsymbol{\mathcal{G}}_p Gp ( 2 ≤ p ≤ P − 1 2 \le p \le P-1 2≤p≤P−1) 和 G P \mathbf{G}_P GP 的大小分别为 N 1 × R 1 N_1 \times R_1 N1×R1, R p − 1 × N p × R p R_{p-1} \times N_p \times R_p Rp−1×Np×Rp 和 R P − 1 × N p R_{P-1} \times N_p RP−1×Np。 { R 1 , … , R P − 1 } \{R_1, \ldots, R_{P-1}\} {R1,…,RP−1} 被称为 TT 秩 (TT-ranks),其中 1 ≤ n p ≤ N p 1 \le n_p \le N_p 1≤np≤Np 且 1 ≤ p ≤ P 1 \le p \le P 1≤p≤P。
备注 2. 值得注意的是,存在大量其他的图拓扑结构。在这种情况下,我们参考张量网络理论(见 [15] 及其参考文献),例如分层/树 Tucker 分解 [18,19]。看来,在实践中,更复杂的图拓扑结构不容易利用,据我们所知,与 TTD 相比,没有有效的分解算法。
由于 TT 简单的基于图的形式体系,可以很直接地将方程 (8) 中引入的对角张量 A \boldsymbol{\mathcal{A}} A 重写为以下 TTD
A = A × 2 1 I 3 , M × 3 1 ⋯ × P − 1 1 I 3 , M × P 1 I M (12) \boldsymbol{\mathcal{A}} = \mathbf{A} \times_2^1 \boldsymbol{\mathcal{I}}_{3,M} \times_3^1 \cdots \times_{P-1}^1 \boldsymbol{\mathcal{I}}_{3,M} \times_P^1 \mathbf{I}_M \tag{12} A=A×21I3,M×31⋯×P−11I3,M×P1IM(12)
其中 A \mathbf{A} A 是一个 M × M M \times M M×M 的对角矩阵,其元素 [ A ] m , m = α m [\mathbf{A}]_{m,m} = \alpha_m [A]m,m=αm。图 2 给出了基于图的可视化。

将张量 A \boldsymbol{\mathcal{A}} A 的 TTD 代入方程 (8),得到
X = A × 1 V 1 × 2 ⋯ × P V P = ( A × 2 1 I 3 , M × 3 1 ⋯ × P − 1 1 I 3 , M × P 1 I M ) × 1 V 1 × 2 ⋯ × P V P = ( V 1 A ) × 2 1 V 2 × 3 1 ⋯ × P − 1 1 V P − 1 × P 1 V P T \begin{align} \boldsymbol{\mathcal{X}} &= \boldsymbol{\mathcal{A}} \times_1 \mathbf{V}_1 \times_2 \cdots \times_P \mathbf{V}_P \tag{13} \\ &= \left( \mathbf{A} \times_2^1 \boldsymbol{\mathcal{I}}_{3,M} \times_3^1 \cdots \times_{P-1}^1 \boldsymbol{\mathcal{I}}_{3,M} \times_P^1 \mathbf{I}_M \right) \times_1 \mathbf{V}_1 \times_2 \cdots \times_P \mathbf{V}_P \tag{14} \\ &= (\mathbf{V}_1 \mathbf{A}) \times_2^1 \boldsymbol{\mathcal{V}}_2 \times_3^1 \cdots \times_{P-1}^1 \boldsymbol{\mathcal{V}}_{P-1} \times_P^1 \mathbf{V}_P^T \tag{15} \end{align} X=A×1V1×2⋯×PVP=(A×21I3,M×31⋯×P−11I3,M×P1IM)×1V1×2⋯×PVP=(V1A)×21V2×31⋯×P−11VP−1×P1VPT(13)(14)(15)
其中 V p = I 3 , M × 2 V p \boldsymbol{\mathcal{V}}_p = \boldsymbol{\mathcal{I}}_{3,M} \times_2 \mathbf{V}_p Vp=I3,M×2Vp 的大小为 M × N p × M M \times N_p \times M M×Np×M。 V p \boldsymbol{\mathcal{V}}_p Vp 和 X \boldsymbol{\mathcal{X}} X 的表示分别在图 3 和图 4 中给出。根据方程 (15),张量 X \boldsymbol{\mathcal{X}} X 的广义范德蒙德 (Vandermonde) CPD 等价于一列 ( P − 2 ) (P-2) (P−2) 个 3 阶张量,这些张量服从受约束的秩 M M M CPD,且在其第 2 模态上具有范德蒙德因子。
3.3. TTD based on the TT-SVD algorithm
在本节中,我们展示了当 TT-SVD 算法 [20] 应用于式 (8) 中的原始张量时,恢复出的 TT 核结构。我们首先回顾一下,TT-SVD 算法是一种顺序算法,它通过使用截断 SVD 提取原始张量展开矩阵的主子空间来恢复 TT 核。该算法恢复出的原始 TT 核存在非奇异变换矩阵的差异(up to nonsingular transformation matrices) [1]。

在图 5 中,我们展示了一个 4 阶张量的 TT-SVD。请注意,在每一步中,右奇异向量矩阵被重塑为一个矩阵 V ( 2 ) ( p ) \mathbf{V}_{(2)}^{(p)} V(2)(p),其在一个维度上具有一个模态,而在另一个维度上具有剩余模态的组合。对 V ( 2 ) ( p − 1 ) \mathbf{V}_{(2)}^{(p-1)} V(2)(p−1) 应用 SVD 会生成分别包含左奇异向量和右奇异向量的矩阵 U ( p ) \mathbf{U}^{(p)} U(p) 和 V ( p ) \mathbf{V}^{(p)} V(p)。请注意,奇异值被吸收在 V ( p ) \mathbf{V}^{(p)} V(p) 中。
TT 核 G p \boldsymbol{\mathcal{G}}_p Gp 是通过重塑 U ( p ) \mathbf{U}^{(p)} U(p) 恢复得到的。在接下来的定理中,我们给出了将 TT-SVD 算法应用于式 (8) 中的多维谐波模型时恢复出的 TT 核结构。
定理 1. 将 TT-SVD 算法应用于具有列满秩因子的式 (15),我们得到以下结果:
G 1 = V 1 A M 1 − 1 (16) \mathbf{G}_1 = \mathbf{V}_1 \mathbf{A} \mathbf{M}_1^{-1} \tag{16} G1=V1AM1−1(16) G p = I 3 , M × 1 M p − 1 × 2 V p × 3 M p − T , 其中 2 ≤ p ≤ P − 1 , (17) \boldsymbol{\mathcal{G}}_p = \boldsymbol{\mathcal{I}}_{3,M} \times_1 \mathbf{M}_{p-1} \times_2 \mathbf{V}_p \times_3 \mathbf{M}_p^{-T}, \quad \text{其中 } 2 \le p \le P-1, \tag{17} Gp=I3,M×1Mp−1×2Vp×3Mp−T,其中 2≤p≤P−1,(17) G P = M P − 1 V P T (18) \mathbf{G}_P = \mathbf{M}_{P-1} \mathbf{V}_P^T \tag{18} GP=MP−1VPT(18)
其中 M p ∈ C M × M \mathbf{M}_p \in \mathbb{C}^{M \times M} Mp∈CM×M 是一个非奇异变换矩阵。
X = A × 1 V 1 × 2 … × P V P (8) \mathcal{X}=\mathcal{A} \times_{1} \mathbf{V}_{1} \times 2 \ldots \times{ }_{P} \mathbf{V}_{P}\tag{8} X=A×1V1×2…×PVP(8)
X = ( V 1 A ) × 2 1 V 2 × 3 1 ⋯ × P − 1 1 V P − 1 × P 1 V P T (15) \boldsymbol{\mathcal{X}} =(\mathbf{V}_1 \mathbf{A}) \times_2^1 \boldsymbol{\mathcal{V}}_2 \times_3^1 \cdots \times_{P-1}^1 \boldsymbol{\mathcal{V}}_{P-1} \times_P^1 \mathbf{V}_P^T \tag{15} X=(V1A)×21V2×31⋯×P−11VP−1×P1VPT(15)
规范秩 (Canonical Rank) 是这个概念向高维张量的直接推广。对于一个 P P P 阶张量 X \boldsymbol{\mathcal{X}} X,如果它的规范秩是 M M M,意味着它最少需要 M M M 个“秩-1 张量”相加才能得到: X = ∑ m = 1 M v 1 , m ∘ v 2 , m ∘ ⋯ ∘ v P , m \boldsymbol{\mathcal{X}} = \sum_{m=1}^M \mathbf{v}_{1,m} \circ \mathbf{v}_{2,m} \circ \dots \circ \mathbf{v}_{P,m} X=m=1∑Mv1,m∘v2,m∘⋯∘vP,m其中 ∘ \circ ∘ 表示外积。
对于一个 P P P 阶张量 X ∈ C N 1 × N 2 × ⋯ × N P \boldsymbol{\mathcal{X}} \in \mathbb{C}^{N_1 \times N_2 \times \cdots \times N_P} X∈CN1×N2×⋯×NP,其 TT 秩 并不是一个单一的数值,而是一个由 P + 1 P+1 P+1 个整数组成的向量(或者说序列): { R 0 , R 1 , R 2 , … , R P − 1 , R P } \{R_0, R_1, R_2, \dots, R_{P-1}, R_P\} {R0,R1,R2,…,RP−1,RP}通常边界秩固定为 R 0 = R P = 1 R_0 = R_P = 1 R0=RP=1(对于标量输出的张量)。因此,我们通常关注中间的 P − 1 P-1 P−1 个数值 { R 1 , … , R P − 1 } \{R_1, \dots, R_{P-1}\} {R1,…,RP−1}。TT 秩 R k R_k Rk 就是连接第 k k k 个节点和第 k + 1 k+1 k+1 个节点的边的“粗细”
上述结果的含义是,将 TT-SVD 算法应用于式 (8) 会生成服从 CPD 的 3 阶 TT 核,其 TT 秩均等于规范秩 M M M(见图 6)。

此外,每个 CPD 列核 G p \boldsymbol{\mathcal{G}}_p Gp 与两个连续的 TT 核 G p − 1 \boldsymbol{\mathcal{G}}_{p-1} Gp−1 和 G p + 1 \boldsymbol{\mathcal{G}}_{p+1} Gp+1 具有一个公共的耦合因子。定理 1 表明,将 TT-SVD 算法应用于式 (8) 允许恢复式 (15) 中定义的精确 TT 核,但存在变换矩阵 M p \mathbf{M}_p Mp 的差异。这些矩阵 M p \mathbf{M}_p Mp 是 基变换 矩阵,正如前面的证明所示,它们与使用 SVD 和 TT-SVD 估计主子空间有关。
前一个核 ( G p − 1 \boldsymbol{\mathcal{G}}_{p-1} Gp−1): G p − 1 = I 3 , M × 1 M p − 2 × 2 V p − 1 × 3 M p − 1 − T \boldsymbol{\mathcal{G}}_{p-1} = \boldsymbol{\mathcal{I}}_{3,M} \times_1 \mathbf{M}_{p-2} \times_2 \mathbf{V}_{p-1} \times_3 \textcolor{red}{\mathbf{M}_{p-1}^{-T}} Gp−1=I3,M×1Mp−2×2Vp−1×3Mp−1−T当前核 ( G p \boldsymbol{\mathcal{G}}_p Gp): G p = I 3 , M × 1 M p − 1 × 2 V p × 3 M p − T \boldsymbol{\mathcal{G}}_p = \boldsymbol{\mathcal{I}}_{3,M} \times_1 \textcolor{red}{\mathbf{M}_{p-1}} \times_2 \mathbf{V}_p \times_3 \textcolor{blue}{\mathbf{M}_p^{-T}} Gp=I3,M×1Mp−1×2Vp×3Mp−T后一个核 ( G p + 1 \boldsymbol{\mathcal{G}}_{p+1} Gp+1): G p + 1 = I 3 , M × 1 M p × 2 V p + 1 × 3 M p + 1 − T \boldsymbol{\mathcal{G}}_{p+1} = \boldsymbol{\mathcal{I}}_{3,M} \times_1 \textcolor{blue}{\mathbf{M}_p} \times_2 \mathbf{V}_{p+1} \times_3 \mathbf{M}_{p+1}^{-T} Gp+1=I3,M×1Mp×2Vp+1×3Mp+1−T
解释:
- 左侧耦合 ( G p − 1 \boldsymbol{\mathcal{G}}_{p-1} Gp−1 与 G p \boldsymbol{\mathcal{G}}_p Gp):第 p − 1 p-1 p−1 个核的“输出端”(第 3 模态)含有变换矩阵 M p − 1 \mathbf{M}_{p-1} Mp−1(以逆转置形式存在)。而第 p p p 个核的“输入端”(第 1 模态)恰好也含有同一个矩阵 M p − 1 \mathbf{M}_{p-1} Mp−1。这就是它们共享的公共耦合因子。
- 右侧耦合 ( G p \boldsymbol{\mathcal{G}}_p Gp 与 G p + 1 \boldsymbol{\mathcal{G}}_{p+1} Gp+1):同理,第 p p p 个核的“输出端”含有 M p \mathbf{M}_p Mp,而它正是第 p + 1 p+1 p+1 个核“输入端”的因子。
备注 3. 人们应谨慎,不要将上述定理简化为众所周知的 TT 模型模糊性。实际上,服从 TT 模型的张量的每个元素都是 P P P 个矩阵的乘积,每个矩阵都是由 TT 核重塑得到的 [20]。事实上,只有当因子是列满秩时,TT-SVD 算法中涉及的变换矩阵才与 TT 模型模糊性重合。最后,上述定理表明,TT-SVD 在必须估计的变换矩阵中包含了潜在但至关重要的信息。
备注 4. 在温和条件下,众所周知, P P P 阶 CPD 的因子在平凡模糊性(公共列置换和缩放 [40])下是唯一的。在 [1] 中证明了,基于式 (17) 的因子也可以在相同的平凡模糊性下被估计。
4. Factor retrieval scheme
4.1. JIRAFE with vandermonde-based rectification
提出的估计器基于 JIRAFE 原理。JIRAFE,意为联合维数约减与因子恢复 (Joint dimensionality Reduction And Factors rEtrieval),由两个主要步骤组成。
- 第一步是计算初始张量的 TTD。通过这样做,初始 P P P 阶张量被分解为 P P P 个图连接的 3 阶张量,称为 TT 核 (TT-cores),如图 4 所示。这种维数约减是缓解 “维数灾难” 的有效方法。为了达到这一目标,上面介绍的 TT-SVD [20] 被用作第一步。
- 第二步致力于 TT 核的因式分解。回顾 定理 1 给出的主要结果,即如果初始张量服从秩为 M M M 的 P P P 阶 CPD,则 2 ≤ p ≤ P − 1 2 \le p \le P-1 2≤p≤P−1 的 TT 核服从秩为 M M M 的耦合 3 阶 CPD。因此,JIRAFE 在物理量 { V 1 , … , V P } \{\mathbf{V}_1, \dots, \mathbf{V}_P\} {V1,…,VP} 和潜在量 { M 1 , … , M P − 1 } \{\mathbf{M}_1, \dots, \mathbf{M}_{P-1}\} {M1,…,MP−1} 上最小化以下准则:
C = ∥ G 1 − V 1 A M 1 − 1 ∥ F 2 + ∥ G P − M P − 1 V P T ∥ F 2 + ∑ p = 2 P − 1 ∥ G p − I 3 , M × 1 M p − 1 × 2 V p × 3 M p − T ∥ F 2 . \begin{align} C &= \|\mathbf{G}_1 - \mathbf{V}_1 \mathbf{A} \mathbf{M}_1^{-1}\|_F^2 + \|\mathbf{G}_P - \mathbf{M}_{P-1} \mathbf{V}_P^T\|_F^2 \tag{41} \\ &\quad + \sum_{p=2}^{P-1} \|\boldsymbol{\mathcal{G}}_p - \boldsymbol{\mathcal{I}}_{3,M} \times_1 \mathbf{M}_{p-1} \times_2 \mathbf{V}_p \times_3 \mathbf{M}_p^{-T}\|_F^2. \tag{42} \end{align} C=∥G1−V1AM1−1∥F2+∥GP−MP−1VPT∥F2+p=2∑P−1∥Gp−I3,M×1Mp−1×2Vp×3Mp−T∥F2.(41)(42)
上述代价函数是耦合最小二乘 (LS) 准则之和。JIRAFE 的目的是基于式 (17) 给出的结果,仅使用 3 阶张量 G p \boldsymbol{\mathcal{G}}_p Gp 来恢复原始张量因子。由于通过 定理 1 证明的矩阵 { M 1 , … , M P − 1 } \{\mathbf{M}_1, \dots, \mathbf{M}_{P-1}\} {M1,…,MP−1} 之间存在的耦合属性,式 (42) 被表示为相关正项之和。请注意,张量之间的耦合属性通常归因于物理约束 [12,41]。
在我们的案例中,这些属性是 TT-SVD 算法顺序结构的结果。矩阵 { M 1 , … , M P − 1 } \{\mathbf{M}_1, \dots, \mathbf{M}_{P-1}\} {M1,…,MP−1} 可以被视为潜在矩阵,即它们没有物理意义,但从估计的角度来看是必不可少的。这些显著的耦合属性发生在给定的 TT 核与基于图的表示中连接到它的另外两个 TT 核之间(见图 6)。
-
独立地最小化式 (42) 中的所有正项是一个简单的过程,但这同时也意味着完全回避了感兴趣问题的结构。
-
另一方面,联合寻找 { V 1 , … , V P } \{\mathbf{V}_1, \dots, \mathbf{V}_P\} {V1,…,VP} 和 { M 1 , … , M P − 1 } \{\mathbf{M}_1, \dots, \mathbf{M}_{P-1}\} {M1,…,MP−1} 并非易事且非常耗时 [12,42]。
因此(Consequently),JIRAFE 方法采用一种直接的顺序方法(如图 7 所述)来最小化代价函数 C C C。

文献中现有的致力于计算 3 阶 CPD 的算法都可以被利用,例如流行的 ALS 算法 [34]。然而,在 MHR 问题的背景下,使用并扩展了 [36] 中介绍的 RecALS 方法。RecALS 的思想是将 ALS 算法与 Vandermonde 校正策略联系起来。在 [36] 中,提出了 Vandermonde 向量与 Toeplitz 矩阵的秩-1 分解之间的联系。作为一种更廉价的替代方案,下一节提出并描述了移位不变性(SIP)。
X = ( V 1 A ) × 2 1 V 2 × 3 1 ⋯ × P − 1 1 V P − 1 × P 1 V P T (15) \boldsymbol{\mathcal{X}} =(\mathbf{V}_1 \mathbf{A}) \times_2^1 \boldsymbol{\mathcal{V}}_2 \times_3^1 \cdots \times_{P-1}^1 \boldsymbol{\mathcal{V}}_{P-1} \times_P^1 \mathbf{V}_P^T \tag{15} X=(V1A)×21V2×31⋯×P−11VP−1×P1VPT(15)
基于公式 (15) 中新的 Vandermonde 约束张量列建模,以及定理 1 中 TT-cores 的 CPD 结构,所提出方案的思想是用仅对 3 阶张量进行操作的顺序估计过程来代替对高 P P P 阶张量的估计。在所提出的解决方案中,在使用 CPD-train 模型对原始张量进行降维后,使用迭代算法(如 ALS)变得更加容易,因为它们被应用于(较小的)3 阶张量。这一新提出的解决方案称为 VTT-RecALS 算法,其伪代码如算法 1 所示。
我们要回顾的是,RecALS 算法是一种基于 ALS 的解决方案,它对于 3 阶张量是有效的,但对于高阶张量则变成了一个棘手的估计器。此外,基于 ALS 的技术可能需要多次迭代才能收敛,并且当张量的阶数增加时,收敛变得越来越困难,甚至无法保证。

VTT-RecALS 算法通过 TT-SVD 先将高维张量“打碎”成小块(TT-cores),然后通过 RecALS 算法像“拉链”一样,利用中间的耦合矩阵 M \mathbf{M} M 将因子逐个恢复出来。这种方法避免了直接处理巨大的高维张量,提高了计算效率。
- G p ≈ I 3 , M × 1 M p − 1 × 2 V p × 3 M p − T \mathcal{G}_p \approx \mathcal{I}_{3,M} \times_1 M_{p-1} \times_2 V_p \times_3 M_p^{-T} Gp≈I3,M×1Mp−1×2Vp×3Mp−T
- unfold 1 G p ≈ M p − 1 ( M p − T ⊙ V p ) T \text{unfold}_1 \mathcal{G}_p \approx M_{p-1} (M_p^{-T} \odot V_p)^T unfold1Gp≈Mp−1(Mp−T⊙Vp)T
- unfold 2 G p ≈ V p ⋅ ( M p − T ⊙ M p − 1 ) T \text{unfold}_2 \mathcal{G}_p \approx V_p \cdot (M_p^{-T} \odot M_{p-1})^T unfold2Gp≈Vp⋅(Mp−T⊙Mp−1)T
VTT-RecALS 算法实际上分为两部分。
- 第一部分致力于降维,即利用定理 1 将高 P P P 阶张量的维度分解为一组 3 阶张量。
- 第二部分致力于使用下一节介绍的 RecALS 算法从 TT-cores 中恢复因子。
值得注意的是,因子 V ^ p \hat{\mathbf{V}}_p V^p 的估计存在平凡(公共)置换模糊性 [40]。正如 [1] 中指出的那样,由于所有因子都是在一个唯一的列置换矩阵下估计的,因此估计出的角频率会自动配对。
4.2. Shift invariance principle (SIP)
在本节中,我们提出了一种针对 Vandermonde 因子新的校正策略,这是 [36] 中提出的 Toeplitz 秩-1 近似 (TR 1 _1 1A) 的替代方案。该校正策略称为移位不变性原理 (SIP),其灵感来自于矩阵束的概念(例如参见 [43])。这是一种应对 MH 模型多维性的校正策略,并被集成到 VTT-RecALS 算法中以校正 Vandermonde 因子。
4.2.1. The SIP criterion
X = A × 1 V 1 × 2 … × P V P (8) \mathcal{X}=\mathcal{A} \times_{1} \mathbf{V}_{1} \times 2 \ldots \times{ }_{P} \mathbf{V}_{P}\tag{8} X=A×1V1×2…×PVP(8)
注意,在无噪声场景下,公式 (8) 中的每个 Vandermonde 因子矩阵 V p \mathbf{V}_p Vp 满足以下等式 [44,45]
V ‾ p = V ‾ p diag ( z p ) , \overline{\mathbf{V}}_p = \underline{\mathbf{V}}_p \text{diag}(\mathbf{z}_p), Vp=Vpdiag(zp),
其中 V p \mathbf{V}_p Vp 是公式 (8) 中的第 p p p 个因子。现在让我们考虑以下代价函数:
min z p C ( z p ) where C ( z p ) = ∣ ∣ V ‾ p − V ‾ p diag ( z p ) ∣ ∣ F 2 = ∑ m = 1 M P ( z m , p ) (43) \min_{\mathbf{z}_p} \mathcal{C}(\mathbf{z}_p) \quad \text{where} \quad \mathcal{C}(\mathbf{z}_p) = ||\overline{\mathbf{V}}_p - \underline{\mathbf{V}}_p \text{diag}(\mathbf{z}_p)||_F^2 = \sum_{m=1}^{M} P(z_{m,p}) \tag{43} zpminC(zp)whereC(zp)=∣∣Vp−Vpdiag(zp)∣∣F2=m=1∑MP(zm,p)(43)
其中 P ( z m , p ) = ∣ ∣ v ‾ ( z m , p ) − v ‾ ( z m , p ) z m , p ∣ ∣ 2 P(z_{m,p}) = ||\overline{\mathbf{v}}(z_{m,p}) - \underline{\mathbf{v}}(z_{m,p})z_{m,p}||^2 P(zm,p)=∣∣v(zm,p)−v(zm,p)zm,p∣∣2。针对 z p \mathbf{z}_p zp 最小化公式 (43) 等价于最小化求和中的每个正项 P ( z m , p ) P(z_{m,p}) P(zm,p)。此外,对于 m ′ ≠ m m' \neq m m′=m, P ( z m , p ) P(z_{m,p}) P(zm,p) 不是 z m ′ , p z_{m',p} zm′,p 的函数。因此,针对 z p \mathbf{z}_p zp 最小化公式 (43) 等价于解决 M M M 个如下形式的独立问题:
min z m , p P ( z m , p ) where P ( z m , p ) = − z m , p ∗ ⋅ Q ( z m , p ) (44) \min_{z_{m,p}} P(z_{m,p}) \quad \text{where} \quad P(z_{m,p}) = - z_{m,p}^* \cdot Q(z_{m,p}) \tag{44} zm,pminP(zm,p)whereP(zm,p)=−zm,p∗⋅Q(zm,p)(44)
以及
Q ( z m , p ) = a m , p z m , p 2 − b m , p z m , p + a m , p ∗ (45) Q(z_{m,p}) = a_{m,p} z_{m,p}^2 - b_{m,p} z_{m,p} + a_{m,p}^* \tag{45} Q(zm,p)=am,pzm,p2−bm,pzm,p+am,p∗(45)
其中 a m , p = v ‾ ( z m , p ) H v ‾ ( z m , p ) a_{m,p} = \overline{\mathbf{v}}(z_{m,p})^H \underline{\mathbf{v}}(z_{m,p}) am,p=v(zm,p)Hv(zm,p), b m , p = ∣ ∣ v ‾ ( z m , p ) ∣ ∣ 2 + ∣ ∣ v ‾ ( z m , p ) ∣ ∣ 2 b_{m,p} = ||\overline{\mathbf{v}}(z_{m,p})||^2 + ||\underline{\mathbf{v}}(z_{m,p})||^2 bm,p=∣∣v(zm,p)∣∣2+∣∣v(zm,p)∣∣2,并且 Q ( z m , p ) Q(z_{m,p}) Q(zm,p) 是一个二次多项式,其两个根的辐角为
ω ^ m , p = ∠ z ^ m , p = ∠ ( b m , p ± b m , p 2 − 4 ∣ a m , p ∣ 2 2 a m , p ) = ∠ ( 1 a m , p ) , (46) \hat{\omega}_{m,p} = \angle \hat{z}_{m,p} = \angle \left( \frac{b_{m,p} \pm \sqrt{b_{m,p}^2 - 4 |a_{m,p}|^2}}{2 a_{m,p}} \right) = \angle \left( \frac{1}{a_{m,p}} \right), \tag{46} ω^m,p=∠z^m,p=∠ 2am,pbm,p±bm,p2−4∣am,p∣2 =∠(am,p1),(46)
其中 ω ^ m , p \hat{\omega}_{m,p} ω^m,p 是沿第 p p p 维的第 m m m 个角频率的估计值。
公式 (46) 中的结果被集成在 RecALS 3 _3 3 算法中。我们用
- RecALS 3 _3 3 表示应用于 3 阶张量的 RecALS,
- 而 RecALS 2 _2 2 表示利用了一个已知因子的应用于 3 阶张量的 RecALS。

算法 1 中使用的 RecALS 3 _3 3 算法总结在算法 2 中。RecALS 2 _2 2 具有与算法 2 类似的算法描述,只是去掉了步骤 3,因为 M p − 1 \mathbf{M}_{p-1} Mp−1 变成了先验已知的输入。这些算法被应用于生成的 3 阶 TT-cores,以恢复具有 Vandermonde 第 2 模态因子的 3 个因子。
- These algorithms are applied to the resultant 3-order TT-cores to recover the 3 factors with a Vandermonde 2nd mode factor.
- 它与普通 ALS 的唯一区别在于中间插入了 SIP 修正步骤,确保分解出的 V p \mathbf{V}_p Vp 始终符合 Vandermonde 物理模型,从而能够提取出您感兴趣的频率或角度参数。
4.2.2. Comparison with other recals scheme
值得注意的是,
对于每个参数 ω m , p \omega_{m,p} ωm,p,文献 [36] 中提出的针对大小为 N × ⋯ × N N \times \cdots \times N N×⋯×N 的 P P P 阶秩- M M M 张量的 TR 1 _1 1A 方法,是基于 (i) 秩-1 对角化以获得秩-1 N × N N \times N N×N Toeplitz 矩阵的主特征向量 u \mathbf{u} u 以及 (ii) 计算乘积 [ u ] 1 [ u ] 2 ∗ [\mathbf{u}]_1 [\mathbf{u}]_2^* [u]1[u]2∗ 的辐角。该成本被评估为 O ( N + 1 ) O(N+1) O(N+1)。因此,对于整组感兴趣的参数,TR 1 _1 1A 方法的最终计算成本被评估为 O ( N ⋅ P ⋅ M + P ⋅ M ) O(N \cdot P \cdot M + P \cdot M) O(N⋅P⋅M+P⋅M)。
在 SIP 方法论中,只需要计算 M P MP MP 个内积。每个内积意味着 N − 1 N-1 N−1 次加法和乘法,因此复杂度被评估为 O ( N − 1 ) O(N-1) O(N−1)。因此,SIP 方法的总成本为 O ( N ⋅ P ⋅ M − P ⋅ M ) O(N \cdot P \cdot M - P \cdot M) O(N⋅P⋅M−P⋅M)。我们可以看到,相对于 SIP 方法,TR 1 _1 1A 方法包含了一个额外的项 O ( P M ) O(PM) O(PM)。对于较大的 P P P 值,这个量可能会很大。
5. Simulation results
本节组织结构如下。
- 在 5.1 节中,阐述并研究了 VTT 方法的意义。
(a) 5.1.1 段将 VTT-RecALS-SIP 算法与 CPD-RecALS-SIP 算法进行了比较,以评估使用 VTT 代替 CPD 的意义。
(b) 5.1.2 段研究了参数 P P P 和 N N N 对 VTT-RecALS-SIP 算法估计精度的影响。 - 5.2 节致力于比较 VTT-RecALS-SIP 与最先进的估计器。
(a) 在 5.2.1 段中比较对噪声的鲁棒性。
(b) 在 5.2.2 段中比较计算时间。
5.1. Advantages of the TT approach
5.1.1. VTT over CPD
在本节中,我们展示了在抗噪鲁棒性方面使用 VTT 模型相对于 CPD 的意义。本节的目的是通过比较 VTT-RecALS-SIP 和 CPD-RecALS-SIP,并利用 4.2 节中提出的解决方案 SIP,来比较 VTT 和 CPD。

在图 8 中,VTT-RecALS-SIP 和 CPD-RecALS-SIP 算法被应用于一个 6 阶张量。秩被固定为 M = 3 M=3 M=3 且维度 N = 6 N=6 N=6。我们可以注意到,这两种方法在很宽的信噪比 (SNR) 范围内都是有效的,其中 VTT-RecALS-SIP 在低信噪比下具有更好的鲁棒性。对于秩 M = 2 M=2 M=2 的情况也发现了类似的行为。我们还注意到,对于 N = 8 N=8 N=8, M = 2 M=2 M=2 和 P = 6 P=6 P=6,即与上一次实验相比,待估计参数的数量 ( P M ) (PM) (PM) 更少,而样本数量更多时,VTT-RecALS-SIP 的均方误差 (MSE) 在低信噪比下更接近克拉美-罗界 (CRB),而 CPD-RecALS-SIP 保持相同的行为。
值得注意的是,VTT-RecALS-SIP 在低信噪比范围内相对于 CPD-RecALS-SIP 的有效性,可以通过应用 TT-SVD 时截断奇异值分解 (SVD) 的降噪特性来证明。
请注意,MSE 曲线中众所周知的阈值效应指示了两种状态之间的极限信噪比,即估计器未能成功估计和成功估计感兴趣参数的情况 [47–49]。因此,这是在实际应用中评估估计器质量的一个关键量(例如参见 [50,51])。得益于此处使用 VTT 执行的维数约减步骤,与图 8 中的 CPD 解决方案相比,该信噪比阈值至少提高了 10 dB。
5.2. VTT-RecALS-SIP versus the state-of-art estimators
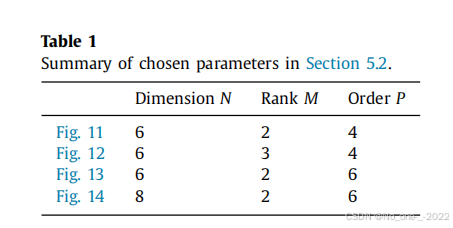
在展示了 VTT-RecALS-SIP 相对于 CPD-RecALS-SIP 的优势之后,在本节中,我们将提出的 VTT-RecALS-SIP 算法与不同的最先进方案进行了比较,例如 CPD-RecALS-TR 1 _1 1A [36]、ND-ESPRIT [31] 和 CP-VDM [28]。与第一个实验一样,我们考虑了不同的参数值。在表 1 中,我们给出了每个图中选择的数值。注意,从一个实验到另一个实验,只有一个参数发生了变化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)