Agent 与 LLM 的关系及技术实现
在当前的人工智能浪潮中,如果说 LLM(大语言模型)是引发海啸的震源,那么 Agent(智能体)就是驾驭这股力量冲向现实世界的巨轮。
要理解这两者的关系,我们可以用一个最直观的比喻作为开篇:
如果说 LLM 是“大脑”,那么 Agent 就是给这个大脑装上了“五官”和“四肢”的一个完整的人。
本文将从定义、深层联系、核心架构的技术实现以及工作流四个维度,为您详细拆解这一前沿概念。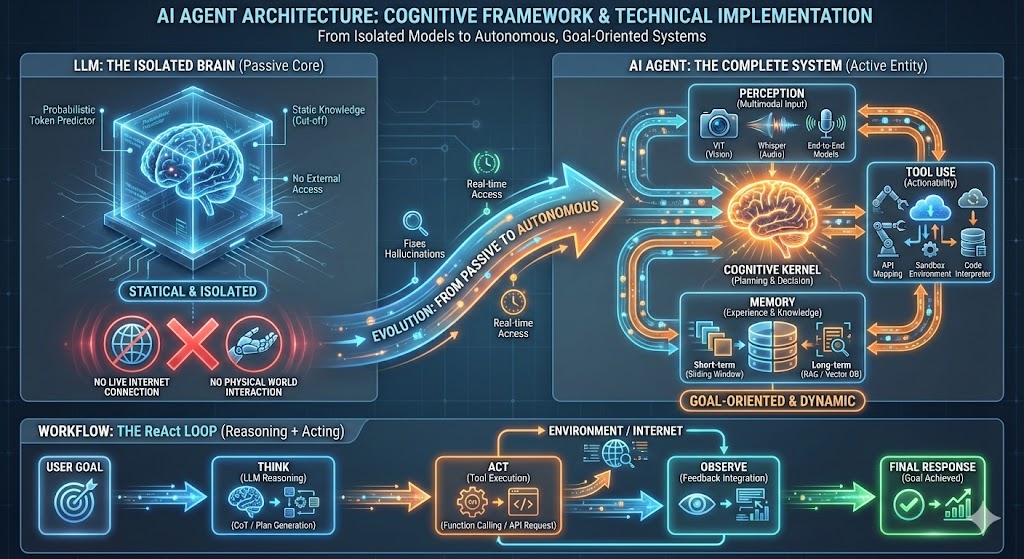
一、 定义与本质区别
1. 什么是 LLM (大语言模型)?
LLM(如 GPT-4, Llama 3, Qwen)本质上是一个概率预测机器。
-
核心功能: 输入一段文本,根据海量训练数据,概率性地预测下一个 Token 是什么。
-
局限性: 它是静态的、被动的。它没有身体,无法联网(除非外挂),无法直接操作数据库,且它的知识截止于训练结束的那一刻。
-
比喻: 它就像一个被锁在密室里、读过人类所有书籍的“天才”,但他瘫痪在床,且与外界完全隔绝。
2. 什么是 Agent (智能体)?
Agent 指的是一个能够感知环境、进行推理决策,并采取行动以实现特定目标的自主系统。
-
核心变化: LLM 爆发后,Agent 被赋予了新的含义。它不再是简单的规则脚本,而是以 LLM 为核心驱动的复杂系统。
-
比喻: Agent 是把那个被锁在密室里的“天才”释放出来,给他配了眼睛(感知)、手(工具)和笔记本(记忆),让他能真正解决现实问题。
二、 核心架构与技术实现 (The Anatomy of an Agent)
现在的 AI Agent 通常具备四大核心能力。下面我们将逐一拆解这些能力的概念,并揭示工程师是如何通过代码实现它们的。
1. 大脑 (Brain):规划与决策
概念: 负责处理信息、记忆检索、逻辑推理和任务拆解。这是 LLM 扮演的角色。
技术实现:
LLM 本身只是预测文字,要让它学会“规划”,主要依靠以下两种技术:
-
复杂的提示工程 (Advanced Prompt Engineering):
-
思维链 (CoT): 在 System Prompt 中强制要求模型“Please think step by step”。
-
ReAct 模板: 开发者构建固定的文本模板,要求 LLM 必须严格按照
Question -> Thought -> Action -> Observation的格式输出。代码逻辑本质上是一个While循环,解析这些特定关键词。
-
-
函数调用 (Function Calling):
-
这是 OpenAI、Qwen 等模型经过微调后的能力。开发者不直接让模型生成文本,而是传入工具的 JSON 定义(如
tool: google_search)。模型会精准输出一个结构化的 JSON 对象,程序捕获这个对象即可触发后续代码。
-
2. 工具使用 (Tool Use):行动力
概念: 能够调用外部工具(如搜索引擎、代码解释器、API)来改变环境或获取新知。
技术实现:
Agent 并没有长出物理手臂,它的“手”是 API 映射。
-
API Mapping: 开发者编写 Python 函数(例如
def search(query)),通过 LangChain 等框架注册给 Agent。当 LLM 决定调用时,框架在本地运行该函数,并将返回结果(HTTP Response)转化为字符串,作为“环境反馈”再次喂回给 LLM。 -
沙箱环境 (Sandbox): 对于复杂的计算任务,Agent 会连接到一个 Docker 容器或 Jupyter Kernel。LLM 生成 Python 代码,宿主程序提取代码并在沙箱中运行,最后捕获
stdout返回给大脑。这让 Agent 获得了数学计算和数据分析的能力。
3. 记忆 (Memory):经验与知识
概念: 解决 LLM 上下文窗口有限的问题,让 Agent 拥有短期和长期记忆。
技术实现:
-
短期记忆 (List + Sliding Window): 本质是一个简单的 Python List,存储最近的对话历史。当超出 Token 限制时,使用滑动窗口丢弃最早的对话,或调用 LLM 将旧对话压缩成一段“摘要”。
-
长期记忆 (RAG - Vector DB):
-
存储: 使用 Embedding 模型(如
text-embedding-3)将文本转化为向量 (Vector),存入向量数据库(如 Milvus, Chroma)。 -
检索: 当用户提问时,计算“问题向量”与“数据库中记忆向量”的余弦相似度,找出最相关的片段拼接到 Prompt 中。
-
4. 感知 (Perception):多模态输入
概念: 接收视觉、听觉等非文本信息。
技术实现:
-
多模态编码器 (Encoders): 视觉上使用 ViT (Vision Transformer) 将图片切片并转化为 Token;听觉上使用 Whisper 等模型将音频转录为文本。
-
端到端模型: 最新的 GPT-4o 等模型原生支持多模态,直接处理像素和音频波形,无需中间转换,响应速度极快。
三、 深层联系:为什么 LLM 需要 Agent?
LLM 是 Agent 的认知核心 (Cognitive Kernel),它们的关系体现为:
-
从“被动”到“主动”: LLM 是问答式的(Stateless),交互随回答结束。Agent 是目标导向的(Goal-oriented),它会为了一个目标(如“策划旅行”)进行多步循环操作。
-
弥补 LLM 的短板:
-
幻觉问题: Agent 通过搜索工具验证事实,不瞎编。
-
时效性: Agent 通过联网获取实时新闻,打破数据截止日期的限制。
-
行动力: LLM 只能输出建议,Agent 能真正执行(如发送邮件、生成文件)。
-
四、 协同工作流:ReAct 模式图解
最经典的 Agent 工作模式被称为 ReAct (Reasoning + Acting)。
场景: 用户问:“iPhone 15 现在的价格比上一代发布时贵吗?”
内部循环逻辑:
-
Think (LLM): “我不知道实时价格。计划:先查 iPhone 15 价格,再查 iPhone 14 发布价,最后对比。” -> 输出 JSON 指令。
-
Act (Agent): 解析 JSON,调用
Google Search API搜索 "iPhone 15 price"。 -
Observe (反馈): 搜索引擎返回:“iPhone 15 售价 799 美元起。” -> 转为文本喂回 LLM。
-
Think (LLM): “已知 15 的价格,现在查 14 的。” -> 再次输出指令。
-
Act (Agent): 调用搜索 "iPhone 14 launch price"。
-
Observe (反馈): 搜索返回:“iPhone 14 发布价 799 美元。”
-
Response (LLM): 进行逻辑比对,最终输出:“两者起售价相同,并未涨价。”
代码级逻辑可视化 (伪代码)
为了让你彻底理解这个循环是如何跑起来的,我们可以看一段简化的 Python 逻辑:
Python
def run_agent(user_input):
# 1. 记忆检索:从向量库找背景知识
context = vector_db.search(user_input)
# 2. 初始 Prompt
prompt = f"目标: {user_input}, 背景: {context}, 请思考下一步。"
while True: # 核心循环 (The Loop)
# 3. 大脑推理
response = llm.generate(prompt)
# 4. 判断:大脑是想说话还是想用工具?
if response.is_tool_call:
# 5. 执行工具
print(f"调用工具: {response.tool_name}")
result = execute_tool(response.tool_name, response.args)
# 6. 关键点:把工具结果追加到 Prompt,让大脑看到
prompt += f"\n工具返回结果: {result}\n"
else:
# 7. 任务完成,输出最终回答
return response.text
五、 总结
| 特性 | LLM (大语言模型) | AI Agent (智能体) |
| 本质 | 知识库 + 推理引擎 (大脑) | 系统架构 + 自动化流程 (完整的人) |
| 核心公式 | Token 输入 -> 概率预测 | LLM + 规划 + 记忆 + 工具 |
| 能力边界 | 仅限文本生成,静态 | 具备联网、执行、长期记忆能力,动态 |
| 运行模式 | 单次推理 | 循环迭代 (感知-决策-行动-反馈) |
结论:
未来的 AI 应用趋势,正在从单纯的“与 LLM 对话”向“构建 Agent 解决复杂任务”转变。LLM 提供了通用的智能基础,而 Agent 架构则通过工程化的手段,将这份智能转化为解决实际问题的生产力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)