AI 也是脸盲?一文看懂 YOLO 和大模型怎么看世界
本文对比了AI视觉领域的两种主流技术:YOLO系列和视觉大模型(VLM)。YOLO作为快速检测模型,在速度和效率上表现突出,但局限于训练数据;新版YOLO-World已拓展到开放词汇识别。VLM则具备更强的语义理解能力,但计算成本高、响应慢。文章分析了它们各自的应用场景:YOLO适用于实时性要求高的场景如自动驾驶,VLM则更适合需要深度理解的智能交互任务。最后介绍了相关AI学习课程,帮助读者掌握这
·
AI 也是脸盲?一文看懂 YOLO 和大模型怎么看世界
你的眼睛 vs AI 的眼睛
想象一下,你站在街头,朋友让你找“一辆红色的跑车”。你的眼睛迅速扫描,瞬间锁定了目标。这听起来很简单,对吧?
但在 AI 的世界里,这曾经是一个巨大的难题。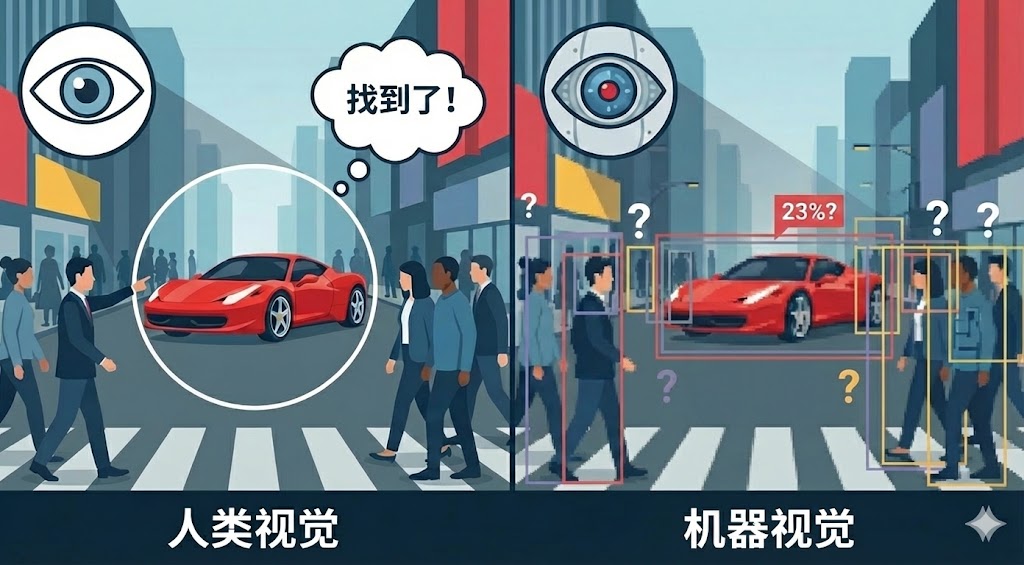
今天,我们就来聊聊 AI 是如何“看”世界的,以及为什么最近的 AI 突然变得像人一样聪明了。我们要介绍两位主角:老牌选手 YOLO 和新晋网红 视觉大模型 (VLM)。
1. YOLO 家族的进化:从“死记硬背”到“举一反三”
YOLO(You Only Look Once)一直是 AI 视觉界的“速度担当”。你可以把它想象成一个动作敏捷的流水线工人。随着技术的发展,这位工人也迎来了升级。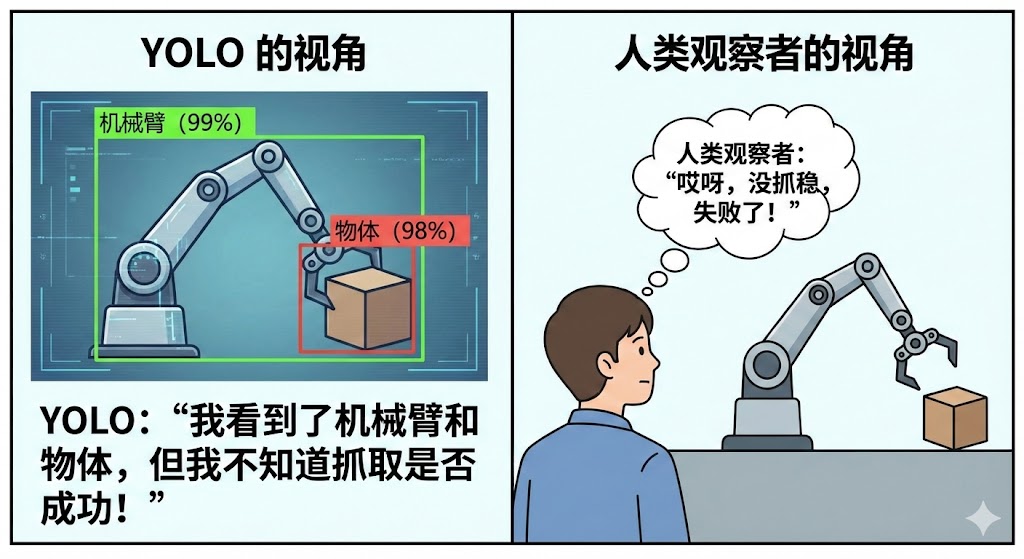
1.1 传统 YOLO:只能在“训练集内”工作
- 特长:快、准、小。它的参数量很小,在普通设备上也能飞快运行。
- 局限:只认死理。它严格受限于训练集。
- 在“上岗”前,工程师给它看了什么(比如猫、狗、车),它就只认什么。
- 如果你突然问它:“帮我找一下‘鳄梨’”,它会直接懵圈,因为它没学过。这就叫**“封闭集”**。
- 注:它也缺乏深层理解能力,只能框出物体位置,无法判断逻辑(如机械臂是否抓取成功)。
1.2 新版 YOLO-World:拓展到“训练集外”
-
能力:在YOLO基础上它额外获得了识别训练集之外物体的能力。
- 实现了从“封闭集”到**“开放词汇”**(Open-Vocabulary)的跨越,既保留了速度,又拥有了一定灵活性。
2. 新晋网红 VLM:博学但笨重的“百科全书专家”
最近两年,随着 ChatGPT 等大火,视觉领域也出现了视觉语言模型 (VLM),比如 GLIP 和 GPT-4V。你可以把它想象成一个读过万卷书但行动迟缓的老教授。
- 它的特长:拥有深刻的理解能力。
- 它不仅认识物体,还能看懂它们之间的关系。
- 举个例子:还是那个机械臂。如果你问 VLM “抓取成功了吗?”,它能结合图像语义告诉你:“成功了,机械臂正紧紧握着苹果”或者“失败了,苹果已经掉在桌子上了”。
- 它的弱点:体型臃肿,且泛而不精。
- 参数巨大:它的“脑容量”非常大(参数量可能是 YOLO 的几百倍),运行起来非常吃力,很难在普通设备上实时跑起来。
- 不够专精:虽然它懂得多,但在一些极度专业的场景下(比如工厂里毫秒级的精密检测),它的准确率反而可能不如专门针对该场景训练过的 YOLO。就像教授虽然博学,但论拧螺丝的手艺,可能真比不上熟练工。
3. 应用场景
YOLO:争分夺秒的前线战士
- 自动驾驶:车速很快,必须在 0.1 秒内识别前面的行人或红绿灯,慢一点都可能出事。这时候必须用 YOLO,因为它够快!
- 工厂流水线:传送带飞速运转,每分钟要检测几百个零件。只有手疾眼快的 YOLO 能胜任这种高强度的重复工作。
VLM:善解人意的幕后智囊
- 智能机器人:你对机器人说“把那瓶红色的可乐递给我”。机器人需要理解什么是“红色的可乐”,这得靠 VLM 的理解能力。
- 文档审核员:公司里有成千上万张发票和合同照片。VLM 可以瞬间读懂上面的文字,告诉你哪张是“餐饮发票”,哪张金额超过了 1000 元,比人工审核快无数倍。
- 盲人辅助眼镜:帮视障人士描述面前的景象:“前面有一张空桌子,桌上放着一杯水。”这种需要生成语言描述的任务,非 VLM 莫属。
想亲自通过 AI 改变世界?
AI 并不神秘,它只是工具。无论你是想做一款自动识别垃圾的 App,还是想构建一个能陪你聊天的智能机器人,现在都是最好的时机!
加入 赋范空间 学习三门通往 AI 世界的钥匙:
- 🚀 Agent 智能体开发课程:想做一个像贾维斯(Jarvis)那样的助手?这门课教你如何让 AI 不仅能陪聊,还能帮你操作电脑、写代码、订机票。
- 📚 大模型原理通识:不用复杂的数学公式,用最通俗的语言带你拆解 ChatGPT 背后的秘密,让你在朋友面前成为 AI 懂王。
- 🔍 多模态 RAG 课程:教你搭建一个超级大脑,让 AI 能够同时阅读文字、看懂图片和视频,帮你处理海量信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)