猫头虎AI分享:GLM-4.6V 开源了!从看懂图片到能自己跑任务的多模态怪兽,终于来了
智谱AI重磅开源GLM-4.6V系列多模态模型,包含106B云端版和9B本地版。该模型突破性地将Function Call原生融入视觉处理,实现图像直接作为工具参数调用,打通"视觉感知-任务理解-工具调用-再理解-决策"全链路。在图文混排、识图购物、前端复刻、长文档理解等场景展现强大能力,支持128k上下文窗口。性能指标在同规模模型中达到SOTA水平,9B轻量版可免费体验。开源
猫头虎AI分享:GLM-4.6V 开源了!从看懂图片到能自己跑任务的多模态怪兽,终于来了
近期,智谱 AI 又抛来一个重磅更新:GLM-4.6V 系列正式上线并开源!
这一次的更新,说句不夸张的话,是我最近看到的多模态模型里最有“从研究走向真实 Agent”味道的。
本次开源包含两款模型👇
- GLM-4.6V(106B-A12B):云端/集群版本,适合算力豪横的同学
- GLM-4.6V-Flash(9B):轻量小钢炮,本地部署友好,关键是 免费
从性能到价格,这代模型可以说是“把门槛按在地上摩擦”:
- 视觉精度同规模 SOTA
- 上下文窗口拉到 128k tokens
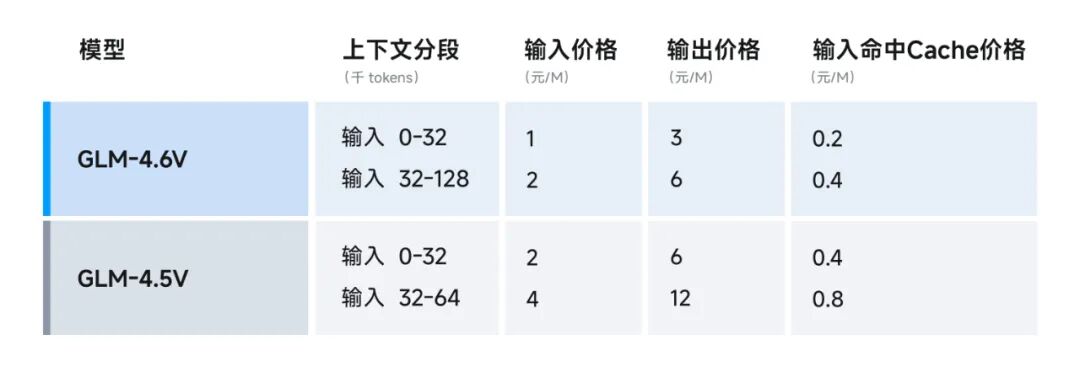
- 调用价格直接砍 50%
- Flash 小模型直接 免费体验
而最让我眼前一亮的是这一句:
首次将 Function Call 原生融入视觉模型,让图片直接变成工具调用参数。
这是多模态 Agent 真正起飞的信号。
下面就跟着猫头虎来一起扒一扒这只新模型到底多能打👇
文章目录
🐯🦉原生视觉工具调用:从“看见”到“做事”
以往工具调用基本是纯文本世界的事。多模态工具链往往这么走:
图片 → 文字描述 → 工具参数 → 工具结果 → 再把图片结果转描述 → 再推理
中间损耗巨大,也很费工程师头发。
GLM-4.6V 直接砍掉所有中间步骤。
模型架构的理念很简单粗暴:
图像就是参数,工具结果就是上下文。
这意味着:
- 输入图片、截图、文档页面……都能直接变工具参数
- 工具返回的图片、图表、网页截图……还能继续被模型“看”、继续推理
也就是说,这模型真正打通了:
视觉感知 → 任务理解 → 工具调用 → 再视觉理解 → 决策输出
这才是真·多模态 Agent。
🐯🦉场景1:自动图文混排,内容创作者狂喜
对我们这种常年做内容的博主来说,这段 demo 看得我热泪盈眶。
GLM-4.6V 能干啥?
- 直接吃论文、PPT、研报等复杂图文
- 自动抽取结构化内容
- 自动为内容选图,甚至直接从原文截关键图
- 图片还能自动“视觉审核”,过滤无关或丑图
- 最终输出可直接发公众号/小红书的图文稿
案例:输入主题即可自动生成资讯内容。
🐯🦉场景2:识图购物 & 自动比价,真正的导购 Agent
我看到第二个 demo 时只想说一句:
淘宝逛街时代,结束了。
GLM-4.6V 能自动完成:
- 看街拍图 → 识别你要“搜同款”
- 自动调用 image_search 在多平台找货
- 对不同平台的内容做清洗、对齐、过滤
- 自动生成一张 Markdown 导购表格
包含:平台、价格、缩略图、匹配度、差异说明、购买链接
案例:搜同款、比价、自动生成清单。
这已经不是简单的“给你推荐”,
这是一个懂你、会看图、能比价、能决策的购物助理。
🐯🦉场景3:前端复刻:设计稿 → 代码,一条龙生成
对于前端朋友来说,这代模型的更新非常致命:
- 上传截图,自动识别布局、组件、配色
- 产出 HTML / CSS / JS,几乎像素级还原
- 支持视觉交互修改
你框出一个按钮说:“往左移一点,改深蓝”,
它自动定位代码并修改
案例:前端复刻与多轮修改。
我自己试了下 Flash 版,惊到我了:
小模型也能用,非常丝滑。
🐯🦉场景4:128k 上下文,超长文档 & 视频理解
128k tokens 是一种什么概念?
- 150 页报告
- 200 页 PPT
- 一小时视频
全部一次塞进去。
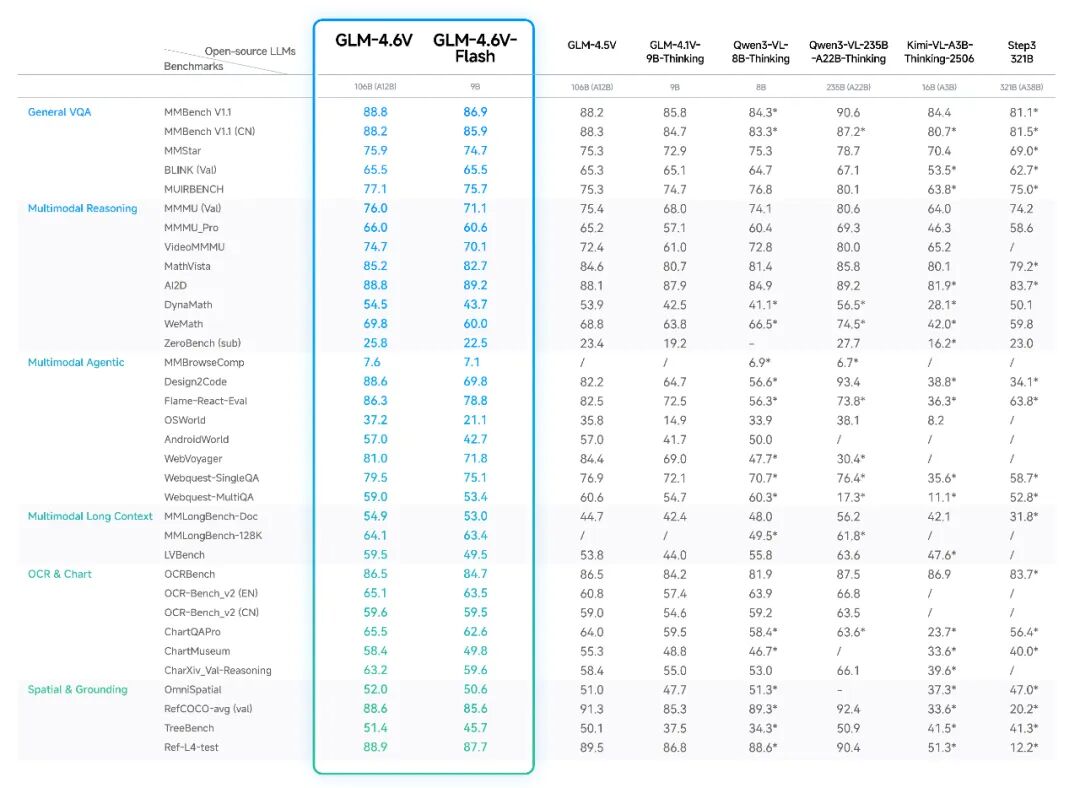
🐯🦉同规模 SOTA,多项指标炸裂
GLM-4.6V 在 30+ 多模态基准上全面测过,整体拉满:
- GLM-4.6V-Flash(9B) > Qwen3-VL-8B
- GLM-4.6V(106B-A12B)≈ Qwen3-VL-235B(2x 参数)
直接上图👇
🐯🦉开源 & 资源入口(原文全部保留)
如果你是开发者,下面这部分你会非常喜欢:
🔓 开源资源
- GitHub:https://github.com/zai-org/GLM-V
- Hugging Face:https://huggingface.co/collections/zai-org/glm-46v
- 魔搭社区:https://modelscope.cn/collections/GLM-46V-37fabc27818446
支持的推理框架包括:
- SGLang
- vLLM
- transformers
- xLLM
可部署在 GPU 与多种国产 NPU 上。
☁️ 在线调用 & 开放平台
- 开放平台:https://docs.bigmodel.cn/cn/guide/models/vlm/glm-4.6v
- 视觉 MCP 工具:https://docs.bigmodel.cn/cn/coding-plan/mcp/vision-mcp-server
在线体验入口:
- z.ai:选择 GLM-4.6V 即可体验
- 智谱清言 APP / 网页版:开启“推理模式”就能多模态推理
技术 Blog:z.ai/blog/glm-4.6v
🐯🦉 碎碎念:多模态 Agent 真的来了
这一代更新最大的意义不是“模型更强了”,而是:
多模态 → 原生工具调用 → 能把任务独立完成
这意味着:
📌不是“帮你回答问题”,
而是“帮你做事”。
📌不是“给你建议”,
而是“执行整个任务链路”。
从内容创作,到购物导购,到工程开发,到长文档理解……
GLM-4.6V 正在真正让 AI 从“语言助手”进化为“视觉+行动的 Agent”。
智谱这波多模态开源周,也正式拉开帷幕。
更多模型、更多能力,值得期待。
猫头虎继续盯着,后续继续给你们更新🐯🦉📡
——完——

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)