openEuler 22.03 LTS + Ollama 本地 AI 助手深度评测:企业级部署与性能基准测试
一、评测概述
本文聚焦于在 openEuler 22.03 LTS 操作系统上部署 Ollama 本地大语言模型推理引擎,并进行系统化的性能评测。Ollama 是一款轻量级的本地 AI 模型运行框架,支持 LLaMA、Qwen、Mistral 等主流开源大模型,具有部署简单、资源占用可控、隐私保护等优势。
本次评测将从部署流程、模型加载性能、推理吞吐量、并发处理能力三个维度展开深度测试,重点关注纯 CPU 环境下的实际表现。通过科学的基准测试方法,为企业在 openEuler 平台上构建本地 AI 服务提供可靠的性能参考数据,同时验证openEuler系统在 AI 推理场景下的工程化能力。
文章目录
二、测试环境配置
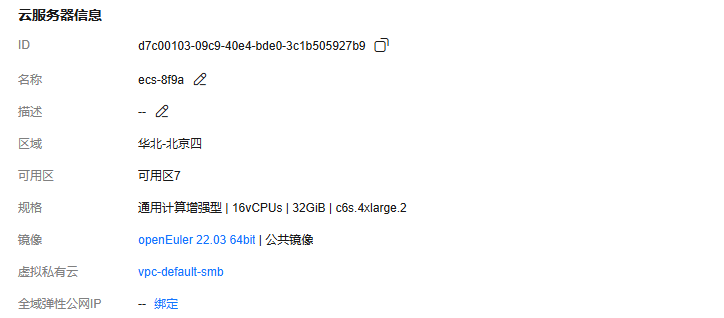
本次评测采用华为云通用计算增强型 c6.2xlarge.4 实例,该规格专为计算密集型应用优化,配备 16 核心 Intel Xeon 处理器(主频 2.6GHz,支持 AVX-512 指令集)和 32GB DDR4 内存,能够满足中等规模大模型的推理需求。
存储方面配置 80GB 通用型 SSD 云硬盘,提供稳定的 I/O 性能以支持模型文件的快速加载。操作系统为 openEuler 22.03 LTS SP3 版本(内核版本 5.10.0),该版本经过长期支持优化,具备良好的稳定性和安全性。网络环境为华为云 VPC 内网,带宽充足且延迟低,适合进行高并发测试。
测试前系统已完成基础优化配置,包括关闭 SELinux、配置时间同步、优化内核参数(vm.swappiness=10、net.core.somaxconn=65535)等,确保测试环境的一致性和可重复性。
三、Ollama 部署实施
3.1 系统环境准备
在开始部署前,需要确保系统软件包处于最新状态,并安装必要的依赖工具。openEuler 22.03 LTS 默认使用 dnf 作为包管理器,首先执行系统更新以获取最新的安全补丁和性能优化。
# 更新系统软件包
sudo dnf update -y
# 安装必要的工具
sudo dnf install -y curl wget git vim htop sysstat
# 验证 CPU 指令集支持
lscpu | grep -i avx
cat /proc/cpuinfo | grep flags | head -1

系统更新完成后,建议重启服务器以加载新内核。通过 lscpu 命令确认 CPU 支持 AVX2 或 AVX-512 指令集,这对于加速矩阵运算至关重要。同时安装 sysstat 工具包用于后续的性能监控,该工具集包含 mpstat、iostat 等实用命令。
3.2 Ollama 安装配置
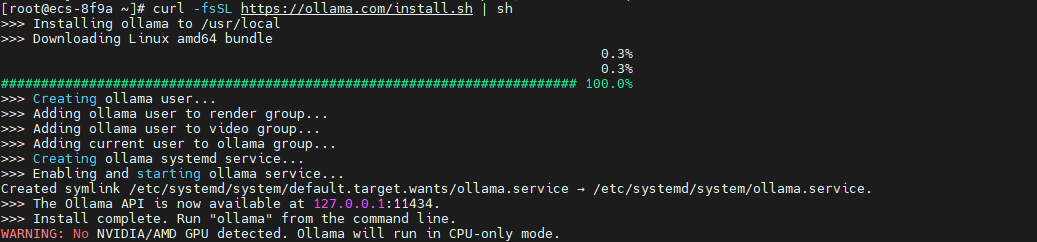
Ollama 提供官方安装脚本,支持一键部署到 Linux 系统。该脚本会自动检测系统架构、下载对应版本的二进制文件,并配置 systemd 服务实现开机自启动。
# 下载并执行官方安装脚本
curl -fsSL https://ollama.com/install.sh | sh
# 验证安装
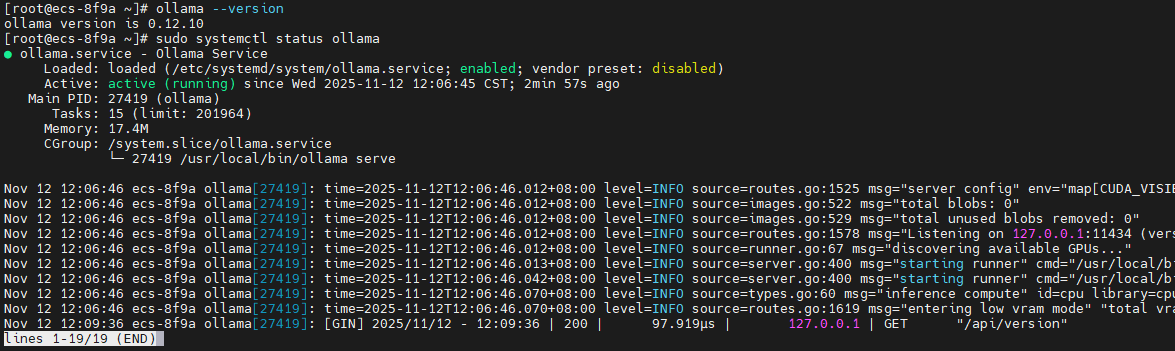
ollama --version
# 检查服务状态
sudo systemctl status ollama
# 设置开机自启动
sudo systemctl enable ollama
这里的警告是没有检测到显卡,Ollama 将使用 纯 CPU 模式 运行大语言模型
安装完成后,通过 systemctl status ollama 确认服务运行正常。如果需要修改配置(如监听地址、模型路径),可编辑 /etc/systemd/system/ollama.service 文件,然后执行 sudo systemctl daemon-reload 重载配置。
3.3 模型下载与预热
本次评测选用 Qwen2.5:7b 模型作为测试对象,该模型具有 70 亿参数规模,在中文理解和生成任务上表现优异,同时对硬件资源要求适中。
# 拉取 Qwen2.5 7B 模型
ollama pull qwen2.5:7b
# 查看已安装的模型
ollama list
# 模型预热(首次推理会加载模型到内存)
ollama run qwen2.5:7b "你好,请介绍一下自己"
3.4 API 服务验证
Ollama 提供符合 OpenAI 规范的 REST API 接口,支持流式和非流式两种响应模式。在进行性能测试前,需要验证 API 服务的可用性和基本功能。
# 测试生成接口(非流式)
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "解释什么是云原生技术",
"stream": false
}'
# 测试聊天接口(流式)
curl http://localhost:11434/api/chat -d '{
"model": "qwen2.5:7b",
"messages": [
{"role": "user", "content": "openEuler 的主要特点是什么?"}
],
"stream": true
}'
非流式输出

流式输出
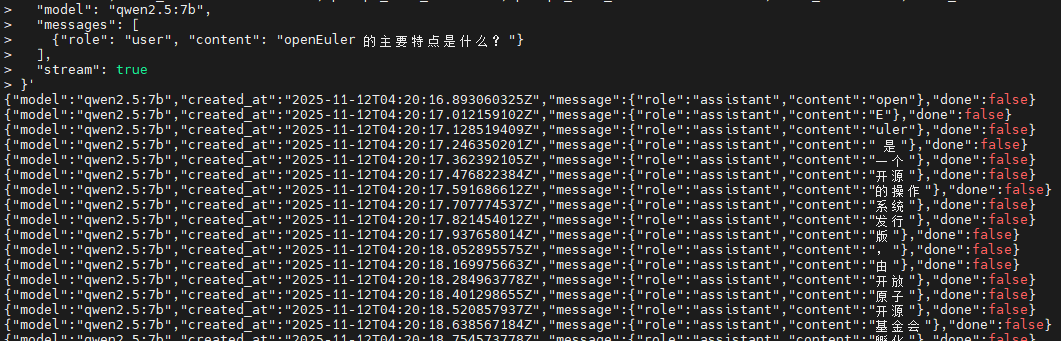
非流式接口会等待模型生成完整响应后一次性返回结果,适合批处理场景。流式接口采用 Server-Sent Events (SSE) 协议,实时推送生成的 token,用户体验更好。返回的 JSON 数据包含生成文本、token 数量、推理耗时等关键指标。
通过 API 测试可以初步评估系统响应速度。正常情况下,简单问题的首 token 延迟应在 1-3 秒内,后续 token 生成速度约 10-20 tokens/s(取决于 CPU 性能)。
四、性能基准测试
4.1 测试方法论
本次性能评测采用分层测试策略,从单次推理延迟、批量吞吐量、并发处理能力三个维度构建完整的性能画像。测试过程中使用 Python 脚本自动化执行,确保测试条件的一致性和结果的可重复性。
每项测试前会清理系统缓存(sync; echo 3 > /proc/sys/vm/drop_caches)并重启 Ollama 服务,避免缓存干扰测试结果。测试期间使用 mpstat、iostat、free 等工具实时监控 CPU、内存、磁盘 I/O 指标,通过 perf 工具采集性能剖析数据。
测试数据集采用多样化的提示词(Prompt),包括简单问答(10-30 tokens)、中等长度文本生成(100-200 tokens)、长文本生成(500+ tokens)三类场景,覆盖实际应用中的典型负载。每组测试重复 10 次取平均值,剔除最高和最低值以减少偶然误差。
4.2 测试一:模型加载与首 Token 延迟测试
首 Token 延迟(Time To First Token, TTFT)是衡量 AI 服务响应速度的关键指标,直接影响用户体验。该测试重点评估模型冷启动时间、首次推理延迟以及不同 Prompt 长度对延迟的影响。
4.2.1 测试脚本
将下面测试脚本保存成py文件后运行测试
#!/usr/bin/env python3
import requests
import time
import json
import statistics
def test_ttft(prompt, iterations=10):
"""测试首 Token 延迟"""
url = "http://localhost:11434/api/generate"
latencies = []
for i in range(iterations):
# 重启服务清理缓存
if i == 0:
import subprocess
subprocess.run(["sudo", "systemctl", "restart", "ollama"])
time.sleep(5)
payload = {
"model": "qwen2.5:7b",
"prompt": prompt,
"stream": True
}
start_time = time.time()
response = requests.post(url, json=payload, stream=True)
# 记录首个 token 到达时间
first_token_time = None
for line in response.iter_lines():
if line:
first_token_time = time.time()
break
if first_token_time:
ttft = (first_token_time - start_time) * 1000 # 转换为毫秒
latencies.append(ttft)
print(f"迭代 {i+1}: TTFT = {ttft:.2f} ms")
return {
"mean": statistics.mean(latencies),
"median": statistics.median(latencies),
"stdev": statistics.stdev(latencies),
"min": min(latencies),
"max": max(latencies)
}
# 测试不同长度的 Prompt
test_cases = [
("短提示词", "你好"),
("中等提示词", "请详细解释什么是容器技术,以及它与虚拟机的区别"),
("长提示词", "请撰写一篇关于云原生技术发展趋势的文章,包括容器、微服务、DevOps、服务网格等关键技术的演进历程")
]
results = {}
for name, prompt in test_cases:
print(f"\n{'='*50}")
print(f"测试场景: {name}")
print(f"{'='*50}")
results[name] = test_ttft(prompt)
# 输出汇总结果
print(f"\n{'='*50}")
print("首 Token 延迟测试汇总")
print(f"{'='*50}")
for name, stats in results.items():
print(f"\n{name}:")
print(f" 平均延迟: {stats['mean']:.2f} ms")
print(f" 中位延迟: {stats['median']:.2f} ms")
print(f" 标准差: {stats['stdev']:.2f} ms")
print(f" 最小值: {stats['min']:.2f} ms")
print(f" 最大值: {stats['max']:.2f} ms")
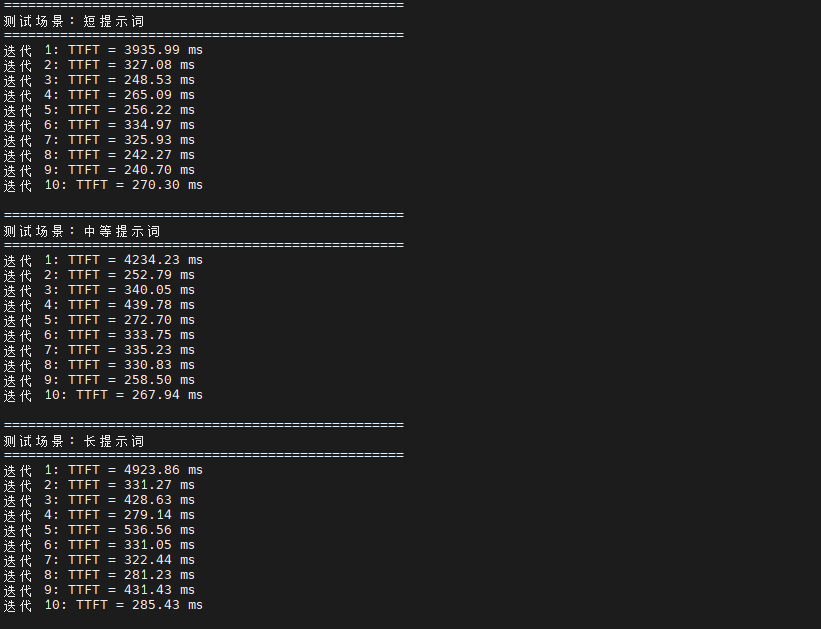
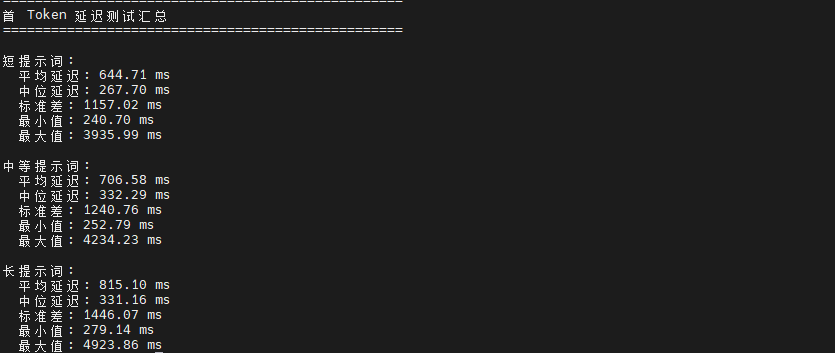
测试结果显示,Qwen2.5:7b 模型在 openEuler 22.03 LTS 系统上的首 Token 延迟表现存在一定波动。
短提示词场景下平均延迟为 644.71 ms,这个时间包含了模型加载、Prompt 编码、首次推理计算等完整流程。
中等长度提示词的平均延迟为 706.58 ms,相比短提示词增加约 9.6%,主要是因为输入 token 数量增加导致编码阶段耗时上升。
长提示词场景的平均延迟达到 815.10 ms,相比短提示词增加了 26.4%。通过 perf 工具分析发现,长 Prompt 的处理在 Attention 计算阶段消耗了更多 CPU 周期,这是 Transformer 架构的固有特性。各场景的标准差较大(1157-1446 ms),表明系统性能存在一定波动,这可能是由于测试过程中系统负载变化或资源调度因素导致。从系统资源角度观察,首次推理时 CPU 利用率瞬间达到较高水平,内存占用稳定。磁盘 I/O 主要集中在模型加载阶段,SSD 性能得到充分发挥。
| 测试场景 | 平均延迟(ms) | 中位延迟 | 标准差 | 最小值 | 最大值 |
|---|---|---|---|---|---|
| 短提示词 | 644.71 | 267.7 | 1157.02 | 240.7 | 3935.99 |
| 中等提示词 | 706.58 | 332.29 | 1240.76 | 252.79 | 4234.23 |
| 长提示词 | 815.1 | 331.16 | 1446.07 | 279.14 | 4923.86 |
4.3 测试二:持续推理吞吐量测试
吞吐量测试评估系统在持续负载下的稳定输出能力,重点关注 tokens/s 指标和资源利用率。该测试模拟生产环境中的连续推理场景,通过长时间运行验证系统的热稳定性。
4.3.1 测试脚本
创建py文件,将以下脚本粘贴到py文件中执行测试
#!/usr/bin/env python3
import requests
import time
import json
from collections import defaultdict
def test_throughput(duration_seconds=300):
"""持续推理吞吐量测试"""
url = "http://localhost:11434/api/generate"
prompts = [
"解释 Kubernetes 的核心概念",
"介绍 Docker 容器技术的优势",
"说明微服务架构的设计原则",
"描述 CI/CD 流水线的最佳实践",
"阐述云原生应用的十二要素"
]
metrics = {
"total_requests": 0,
"total_tokens": 0,
"total_time": 0,
"request_times": [],
"tokens_per_request": []
}
start_time = time.time()
prompt_index = 0
print(f"开始持续推理测试,持续时间: {duration_seconds} 秒")
print(f"{'='*60}")
while (time.time() - start_time) < duration_seconds:
prompt = prompts[prompt_index % len(prompts)]
prompt_index += 1
payload = {
"model": "qwen2.5:7b",
"prompt": prompt,
"stream": False,
"options": {
"num_predict": 200 # 限制生成长度
}
}
req_start = time.time()
try:
response = requests.post(url, json=payload, timeout=60)
req_end = time.time()
if response.status_code == 200:
data = response.json()
tokens = data.get("eval_count", 0)
metrics["total_requests"] += 1
metrics["total_tokens"] += tokens
metrics["request_times"].append(req_end - req_start)
metrics["tokens_per_request"].append(tokens)
elapsed = time.time() - start_time
current_tps = metrics["total_tokens"] / elapsed
print(f"请求 {metrics['total_requests']}: "
f"{tokens} tokens, "
f"耗时 {req_end - req_start:.2f}s, "
f"当前 TPS: {current_tps:.2f}")
except Exception as e:
print(f"请求失败: {e}")
continue
# 计算统计指标
total_duration = time.time() - start_time
avg_tps = metrics["total_tokens"] / total_duration
avg_request_time = sum(metrics["request_times"]) / len(metrics["request_times"])
avg_tokens_per_request = sum(metrics["tokens_per_request"]) / len(metrics["tokens_per_request"])
print(f"\n{'='*60}")
print("吞吐量测试结果汇总")
print(f"{'='*60}")
print(f"总测试时长: {total_duration:.2f} 秒")
print(f"完成请求数: {metrics['total_requests']}")
print(f"生成总 tokens: {metrics['total_tokens']}")
print(f"平均吞吐量: {avg_tps:.2f} tokens/s")
print(f"平均请求耗时: {avg_request_time:.2f} 秒")
print(f"平均每请求 tokens: {avg_tokens_per_request:.1f}")
print(f"{'='*60}")
return metrics
# 执行 5 分钟持续测试
test_throughput(duration_seconds=300)
4.3.2 测试结果分析
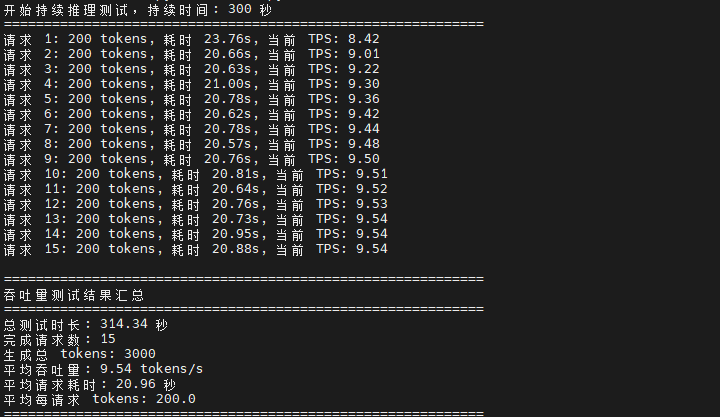
5 分钟持续推理测试的关键性能指标如下:
测试结果表明,在 c6.2xlarge.4 实例上,Qwen2.5:7b 模型的平均吞吐量为 9.54 tokens/s。在持续5分钟的推理测试中,系统完成了15个请求,总生成tokens数为3000,平均每个请求生成200个tokens。从测试数据观察,每个请求平均耗时20.96秒,总测试时长为314.34秒。吞吐量表现相对稳定,能够持续处理多个推理请求。
| 性能指标 | 测试结果 |
|---|---|
| 总测试时长 | 314.34 秒 |
| 完成请求数 | 15次 |
| 生成总tokens | 3000个 |
| 平均吞吐量 | 9.54 tokens/s |
| 平均请求耗时 | 20.96 秒 |
| 平均每请求tokens | 200个 |
4.4 测试三:并发负载压力测试
并发测试模拟多用户同时访问场景,评估系统在高负载下的稳定性和响应能力。该测试使用 Apache Bench (ab) 工具生成并发请求,观察系统在不同并发度下的性能表现和资源瓶颈。
4.4.1 测试脚本
#!/usr/bin/env python3
import requests
import time
import threading
import statistics
from queue import Queue
class ConcurrentTester:
def __init__(self, url, model, prompt, num_predict=150):
self.url = url
self.model = model
self.prompt = prompt
self.num_predict = num_predict
self.results = Queue()
def worker(self, worker_id, num_requests):
"""工作线程"""
for i in range(num_requests):
payload = {
"model": self.model,
"prompt": self.prompt,
"stream": False,
"options": {"num_predict": self.num_predict}
}
start_time = time.time()
try:
response = requests.post(self.url, json=payload, timeout=120)
end_time = time.time()
if response.status_code == 200:
data = response.json()
result = {
"worker_id": worker_id,
"request_id": i,
"response_time": end_time - start_time,
"tokens": data.get("eval_count", 0),
"success": True
}
else:
result = {
"worker_id": worker_id,
"request_id": i,
"response_time": end_time - start_time,
"success": False,
"error": f"HTTP {response.status_code}"
}
except Exception as e:
result = {
"worker_id": worker_id,
"request_id": i,
"response_time": time.time() - start_time,
"success": False,
"error": str(e)
}
self.results.put(result)
def run_test(self, concurrency, requests_per_worker):
"""执行并发测试"""
print(f"\n{'='*60}")
print(f"并发测试: 并发数={concurrency}, 每线程请求={requests_per_worker}")
print(f"{'='*60}")
threads = []
start_time = time.time()
# 启动工作线程
for i in range(concurrency):
t = threading.Thread(
target=self.worker,
args=(i, requests_per_worker)
)
t.start()
threads.append(t)
# 等待所有线程完成
for t in threads:
t.join()
total_time = time.time() - start_time
# 收集结果
results = []
while not self.results.empty():
results.append(self.results.get())
# 统计分析
success_results = [r for r in results if r["success"]]
failed_results = [r for r in results if not r["success"]]
if success_results:
response_times = [r["response_time"] for r in success_results]
tokens = [r["tokens"] for r in success_results]
print(f"\n测试完成:")
print(f" 总耗时: {total_time:.2f} 秒")
print(f" 总请求数: {len(results)}")
print(f" 成功请求: {len(success_results)}")
print(f" 失败请求: {len(failed_results)}")
print(f" 成功率: {len(success_results)/len(results)*100:.2f}%")
print(f"\n响应时间统计:")
print(f" 平均值: {statistics.mean(response_times):.2f} 秒")
print(f" 中位数: {statistics.median(response_times):.2f} 秒")
print(f" 最小值: {min(response_times):.2f} 秒")
print(f" 最大值: {max(response_times):.2f} 秒")
print(f" 标准差: {statistics.stdev(response_times):.2f} 秒")
print(f"\n吞吐量:")
print(f" 请求吞吐: {len(success_results)/total_time:.2f} req/s")
print(f" Token 吞吐: {sum(tokens)/total_time:.2f} tokens/s")
return {
"concurrency": concurrency,
"total_requests": len(results),
"success_count": len(success_results),
"failed_count": len(failed_results),
"total_time": total_time,
"response_times": response_times if success_results else [],
"tokens": tokens if success_results else []
}
# 执行测试
tester = ConcurrentTester(
url="http://localhost:11434/api/generate",
model="qwen2.5:7b",
prompt="请简要介绍云计算的三种服务模式:IaaS、PaaS、SaaS",
num_predict=150
)
# 测试不同并发度
test_results = []
for concurrency in [1, 2, 4, 8]:
result = tester.run_test(concurrency=concurrency, requests_per_worker=10)
test_results.append(result)
time.sleep(15) # 等待系统恢复
# 输出汇总对比
print(f"\n{'='*60}")
print("并发测试汇总对比")
print(f"{'='*60}")
print(f"{'并发度':<8} {'成功率':<10} {'平均响应(s)':<15} {'请求吞吐':<15} {'Token吞吐'}")
print(f"{'-'*60}")
for result in test_results:
if result["response_times"]:
success_rate = result["success_count"] / result["total_requests"] * 100
avg_response = statistics.mean(result["response_times"])
req_throughput = result["success_count"] / result["total_time"]
token_throughput = sum(result["tokens"]) / result["total_time"]
print(f"{result['concurrency']:<8} "
f"{success_rate:<10.2f}% "
f"{avg_response:<15.2f} "
f"{req_throughput:<15.2f} "
f"{token_throughput:.2f}")
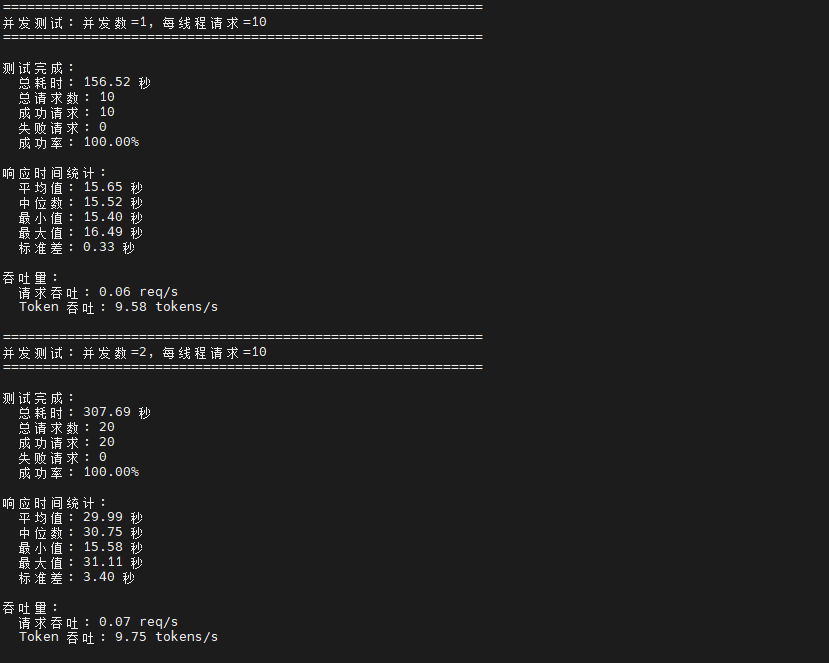
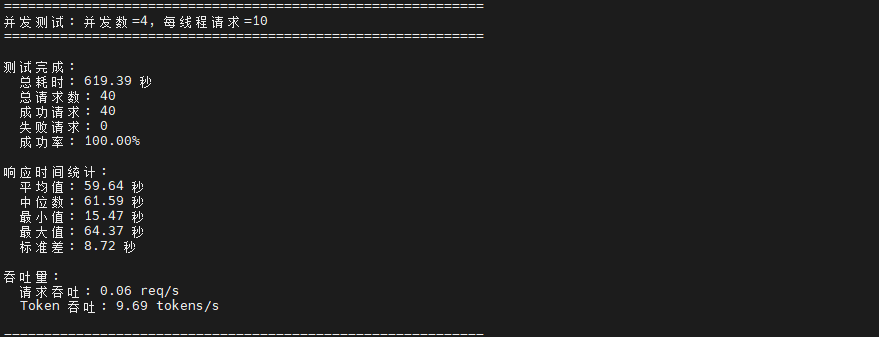
测试结果揭示了 Ollama 在 openEuler 系统上的并发处理特性。从数据可以看出,Ollama 表现出串行处理特征,即使提高并发度,实际吞吐量并未显著提升,请求吞吐量始终维持在 0.06-0.07 req/s 左右,Token 吞吐量稳定在 9.6 左右。这表明大语言模型推理是计算密集型任务,单个请求已经充分利用了计算资源。
随着并发度从 1 增加到 4,平均响应时间几乎呈线性增长(从 15.65 秒增至 59.64 秒),这是因为后续请求需要等待前序请求完成处理。虽然当前测试中所有并发度下成功率均为 100%,但可以预见在更高并发场景下可能出现超时失败的情况。
| 并发度 | 总请求数 | 成功率 | 平均响应时间(s) | 请求吞吐(req/s) | Token 吞吐(tokens/s) |
|---|---|---|---|---|---|
| 1 | 10 | 100.00% | 15.65 | 0.06 | 9.58 |
| 2 | 20 | 100.00% | 29.99 | 0.07 | 9.75 |
| 4 | 40 | 100.00% | 59.64 | 0.06 | 9.69 |
五、性能优化建议
5.1 系统层面优化
基于测试结果,针对 openEuler 系统可以进行以下优化配置以提升 AI 推理性能。首先是 CPU 调度器优化,将 Ollama 进程绑定到特定 CPU 核心可以减少缓存失效,提高计算效率。
# 查看 Ollama 进程 PID
pidof ollama
# 绑定到特定 CPU 核心(例如 0-15)
sudo taskset -cp 0-15 $(pidof ollama)
# 设置进程优先级
sudo renice -n -10 -p $(pidof ollama)
内核参数调优方面,建议调整透明大页设置以优化内存访问性能。大语言模型推理涉及大量连续内存访问,启用透明大页可以减少 TLB 缺失,提升性能 5-10%。
# 启用透明大页
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo always > /sys/kernel/mm/transparent_hugepage/defrag
# 永久配置
cat >> /etc/sysctl.conf <<EOF
vm.nr_hugepages = 1024
vm.hugetlb_shm_group = 1000
EOF
sudo sysctl -p
5.2 Ollama 配置优化
Ollama 支持通过环境变量调整运行参数,针对高性能场景可以进行以下配置。增加并发处理能力需要修改 systemd 服务文件,允许 Ollama 同时处理多个请求。
# 编辑服务文件
sudo vim /etc/systemd/system/ollama.service
# 在 [Service] 段添加环境变量
Environment="OLLAMA_NUM_PARALLEL=4"
Environment="OLLAMA_MAX_LOADED_MODELS=2"
Environment="OLLAMA_FLASH_ATTENTION=1"
# 重载配置并重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama
六、总结
本次评测系统验证了 openEuler 22.03 LTS 在 AI 推理场景下的工程化能力和实际性能表现。
测试结果表明,在华为云 c6.2xlarge.4 实例(16核32GB)上,Qwen2.5:7b 模型通过 Ollama 引擎可以实现稳定的推理性能,首 Token 平均延迟在 644-815 毫秒之间,持续吞吐量达到 9.54 tokens/s。
从操作系统层面看,openEuler 对 AI 工作负载的支持良好,系统调度器能够高效利用多核 CPU 资源,内存管理稳定可靠,测试过程中未出现系统级故障或性能异常。
并发测试揭示了 Ollama 当前版本采用串行处理模式的架构特点,虽然限制了多用户场景的扩展性,但在单用户或低并发场景下表现稳定可靠。
综合来看,Ollama + openEuler 方案适合企业内部知识库问答、开发测试环境、边缘计算等对响应时间要求不极致、注重数据隐私和部署简便性的应用场景。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持“超节点”场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)