智算中心与RDMA网络
智算中心作为AI和数字经济的"超级大脑",通过分布式架构和高速网络整合算力资源,支撑深度学习等高性能计算需求。RDMA技术凭借零拷贝、低延迟特性成为核心传输方案,其中RoCEv2因兼容性和成本优势成为主流。国内外应用显示,该技术能显著提升GPU集群训练效率,但面临拥塞敏感等挑战。未来需优化传输控制技术,以支撑更大规模部署。智算中心建设正加速推进,为"东数西算"
智算中心就像人工智能、数据分析和高端计算领域的“超级大脑”,是支撑这些领域运转的关键基础设施。无论是处理复杂的计算任务,还是高效处理海量数据,它都不可或缺。近年来,随着国家“东数西算”工程的持续推进及相关政策的大力扶持,国家在智算中心建设上投入大量资源,旨在搭建覆盖全国的高性能算力网络,为人工智能和数字经济发展筑牢技术根基。智算中心并非依赖单个设备“单打独斗”,而是整合分散的计算资源与高效的网络技术,形成协同性强的“算力+存储”综合平台。它不仅能承接深度学习模型训练等高强度任务,还可满足科学计算模拟、大规模分布式存储等多样化应用需求。
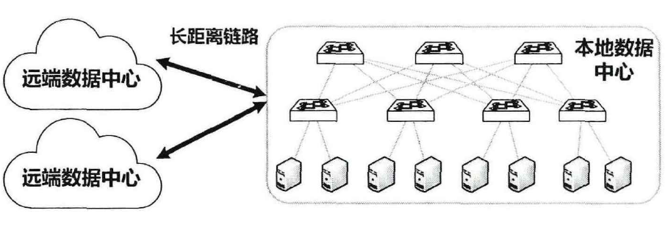
智算中心的网络架构呈现出显著的层次性与分布式特征。通常而言,一个智算中心由多个部署于不同地理位置的数据中心构成,这种分布式布局可有效弥补单个数据中心的短板,例如计算能力不足、供电与冷却系统负荷受限等问题。毕竟单个数据中心受物理空间和资源供给的约束,难以支撑大规模的计算任务。多个数据中心分散部署后,会通过专用长距离光纤实现互联,进而达成算力资源的高效协同与灵活调度。该模式不仅能提升整个系统的可靠性与抗风险能力,还可灵活响应不同区域的算力需求。聚焦单个数据中心内部,当前应用最广泛的是“胖树(Fat-tree)”网络拓扑结构。该结构通过多层交换机的分层连接设计,既能支撑海量计算节点并行运转,又能有效缓解网络拥堵、规避拓扑失衡问题,保障数据传输的高速性与稳定性。
随着智算中心承载任务规模的持续扩大,对网络性能的要求也不断攀升,尤其在超低延迟、高吞吐两大核心维度提出了更为严苛的标准。国家在智算中心建设规划中明确指出,需通过构建高速、低延迟的网络架构,推动算力资源的高效协同。然而,传统以太网架构受限于较高的协议栈开销及延迟瓶颈,在支撑智算中心大规模分布式训练、高性能计算、分布式存储等核心任务时,难以满足需求,面临诸多挑战。为破解这一困境,远程直接内存访问技术(Remote Direct Memory Access,RDMA)凭借其绕开操作系统内核、实现设备间直接内存访问的核心优势,已成为智算中心网络架构中的关键组成部分。
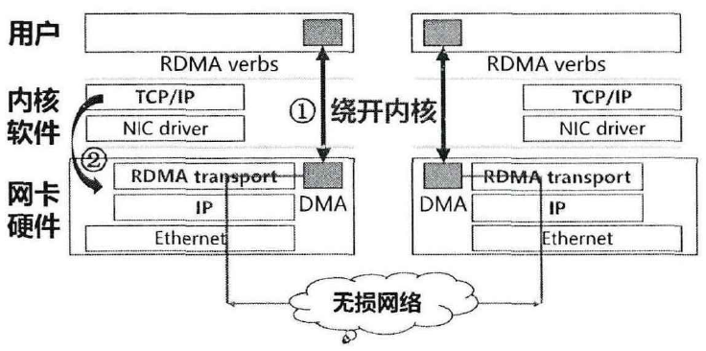
RDMA技术通过将传统网络协议栈操作卸载至硬件网卡(Network Interface Card,NIC)(操作①),实现发送端与接收端内存间的数据直接传输,避免了系统内核处理器的干预,同时省去了传统以太网架构中必需的多次内存拷贝操作(操作②)。这一设计大幅降低了传输延迟,还显著提升了数据传输效率。其具备的零拷贝(zero-copy)机制与超低CPU占用率特性,让RDMA成为支撑高性能计算、分布式训练及机器学习训练的核心技术工具。例如,在智算中心网络承载GPU集群深度学习训练任务时,RDMA的高传输吞吐与超低时延优势,能有效缩短节点间的通信耗时,进而显著加速模型训练进程。
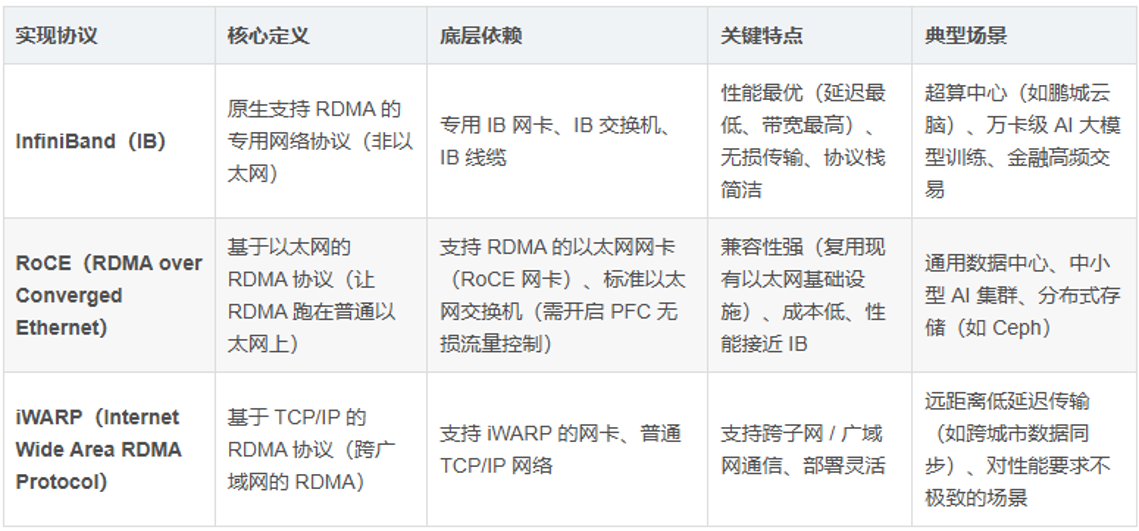
RDMA技术的实现方式主要包括iWARP、InfiniBand和RoCEv2三种。其中,iWARP基于TCP/IP协议栈,可在标准以太网设备上运行,兼容性较好,但受限于传统协议栈,延迟性能略逊于其他两种方式;InfiniBand是一种高性能专用互连技术,以超高带宽和超低延迟为核心优势,不过其需搭配专用网络设备,成本较高,仅适用于对性能要求极为苛刻的场景;基于融合以太网的RDMA(RDMA over Converged Ethernet v2,RoCEv2)是目前应用最广泛的实现方式,它兼具以太网的灵活性与RDMA的高性能,支持在现有组网设备上大规模部署,已成为智算中心RDMA网络架构的主流选择。
随着RDMA技术的广泛普及, 许多领先的互联网科技企业在其智算中心网络中大规模部署了这一 技术,以满足高性能计算、分布式业务以及机器学习训练等仟务对网络性能的严苛要求。 例如:
|
分类 |
应用主体/案例 |
核心技术路线 |
部署场景 |
关键性能表现 |
核心特点 |
|---|---|---|---|---|---|
|
国外 |
亚马逊AWS(云服务) |
Elastic Fabric Adapter(EFA),支持RoCEv2/InfiniBand |
AI训练集群、高性能计算云服务 |
单链路带宽200Gbps,延迟<2μs,支持32768个GPU集群互联 |
商业化成熟,适配多场景算力需求,生态完善 |
|
微软Azure(云服务) |
RoCEv2为主,部分高端场景采用InfiniBand |
云原生存储、大模型训推、HPC任务 |
RDMA流量占数据中心总流量70%,GPU间同步效率提升80% |
规模化部署领先,深度融合云服务生态 |
|
|
美国橡树岭国家实验室(超算中心) |
InfiniBand(高性能专用网络) |
Frontier超算节点互联、核聚变模拟、气象预测 |
单链路带宽400Gbps,延迟微秒级,支撑10万+节点并行计算 |
聚焦极致性能,适配超大规模科学计算 |
|
|
谷歌云(云服务) |
Elastic Fabric Adapter(EFA),基于RoCEv2 |
分子动力学、流体力学等HPC场景,AI模型训练 |
CPU占用率从30%降至1%以下,延迟<5μs |
硬件卸载能力突出,降低计算资源消耗 |
|
|
国内 |
上海电信(运营商) |
华为AI WAN方案,基于RoCEv2无损传输 |
城域智算POD、云边协同训推、算力租用服务 |
跨240公里拉远推理效率不下降,单链路带宽400Gbps |
聚焦广域算网融合,适配“东数西算”长距离传输需求 |
|
阿里云(云服务) |
RoCEv2为主,自主研发RDMA网卡适配 |
AI训练集群、分布式存储、达摩院大模型训推 |
覆盖80%AI集群,支持10万+节点互联,GPU间带宽200Gbps |
国产化适配加速,结合自研硬件降低成本 |
|
|
中科类脑(新疆智算中心) |
RoCEv2,搭配胖树拓扑 |
万卡级GPU集群、百亿参数大模型训练 |
算力利用率超97%,节点间延迟<5μs |
聚焦智算中心核心场景,适配大规模并行计算 |
|
|
微众银行(金融科技) |
自研RDMA交换机,基于RoCEv2 |
AI风控模型训练、分布式金融数据存储 |
网络延迟<2μs,建网成本降低70% |
行业定制化开发,兼顾性能与成本效益 |
从统计结果可见,国外RDMA部署侧重商业化生态构建和极致性能适配,国内则聚焦智算中心建设、算网融合及国产化替代,RoCEv2因兼容性和成本优势成为国内外主流技术路线。
尽管RDMA技术在智算中心网络中展现出显著的性能优势,但在大规模部署及复杂业务场景下,其传输性能仍受多种因素制约。例如,网络流量拥塞、资源竞争等问题,常会导致RDMA实际效能受损——尤其主流的RoCEv2协议基于UDP实现,缺乏完善的丢包保护机制,对网络拥塞和丢包异常敏感,一旦出现Incast流量瞬时突发,易造成设备队列缓存溢出,进而引发时延增加、吞吐下降等问题。要进一步释放RDMA的技术潜力,实现高效的传输控制与网络资源利用,网络传输控制技术的优化与创新至关重要。而传输控制技术的持续优化,将成为推动RDMA在更大规模、更复杂场景下落地的关键支撑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)