具身系统中的生成式AI:性能、效率和可扩展性的系统级分析(上)
25年4月来自Georgia Tech、明尼苏达大学和哈佛大学的论文“Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability”。具身系统利用大语言模型(LLM)驱动的集成感知、认知、行动和高级推理能力,使生成式自主智体能够与物理世界互动,从而在现实世界环境
25年4月来自Georgia Tech、明尼苏达大学和哈佛大学的论文“Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability”。
具身系统利用大语言模型(LLM)驱动的集成感知、认知、行动和高级推理能力,使生成式自主智体能够与物理世界互动,从而在现实世界环境中处理复杂、长周期、多目标任务方面具有巨大潜力。然而,由于运行时延迟过长、可扩展性有限以及系统对环境因素高度敏感,导致系统效率显著降低,因此部署这些系统仍然面临挑战。本文旨在理解具身智体系统的工作负载特征并探索优化方案。这些系统系统地分为四种范式,并通过基准测试研究评估其在不同模块、智能体规模和具身任务下的任务性能和系统效率。基准测试研究揭示一些关键挑战,例如规划和通信延迟过长、智体交互冗余、底层控制机制复杂、内存不一致、提示长度爆炸、对自我纠正和执行的敏感性、成功率急剧下降以及随着智体数量的增加协作效率降低等。利用这些分析结果,其提出系统优化策略,以提升不同范式下具身智体的性能、效率和可扩展性。
具身智能系统代表能够通过感知、认知和行动与物理世界交互并执行复杂任务的智体[1]–[5]。这些系统将先进的认知框架与环境感知和任务执行相结合,以应对诸如运动规划和自主决策等长时程多目标挑战。大语言模型(LLM)已被越来越多地集成到具身智能系统中,以增强其在动态和不确定环境中的规划、通信和推理能力。这些系统将LLM的高级推理与精确的低级执行相结合,从而在需要与环境持续交互的复杂任务中实现稳健且适应性强的行为。
具身人工智体在机器人、自动驾驶汽车和协作式多智体系统等现实世界应用中具有巨大的潜力。这些系统已在各个领域的长时程多目标任务中展现出卓越的能力。例如,CoELA[6]在复杂物体运输、餐桌布置和人机交互任务中将成功率提高了23%。具身人工智能系统能够适应动态环境、处理多模态输入并执行复杂的动作序列,使其非常适合需要与现实世界持续交互的任务。
尽管具身人工智能系统具有广阔的应用前景,但它们也面临着严峻的挑战。首先,长时程任务中较高的计算延迟源于重复的推理运行和复杂的规划过程。其次,系统效率低下,例如冗余通信和顺序处理,会导致运行时间延长和任务效率降低。第三,多智体系统的可扩展性受到通信瓶颈、内存开销以及随智体数量增加而呈指数级增长的动作相互依赖性的制约。最后,局部模型的局限性和内存不一致性会进一步降低系统在大规模任务中的性能。例如,目前的具身人工智能智体系统,如 CoELA [6]、COMBO [7] 和 MindAgent [8],即使在桌面 GPU 上,也分别需要 18、23 和 21 分钟才能完成一项长期多目标任务。
具身智能智体系统的构建模块
具身智能智体通常由六个关键模块组成:感知、规划、通信、记忆、反思和执行。感知模块负责感知环境并提取重要数据。规划模块分解长周期任务,并生成高级规划和指令。通信模块利用对话生成和理解能力管理代理的信息共享。执行模块通过生成底层基本动作来执行高级规划。反思模块反映错误或低效的动作,防止出现幻觉。记忆模块存储整个具身任务过程中的环境观测结果、智体动作和对话历史记录。如下图 a 展示具身人工智能智体的构建模块。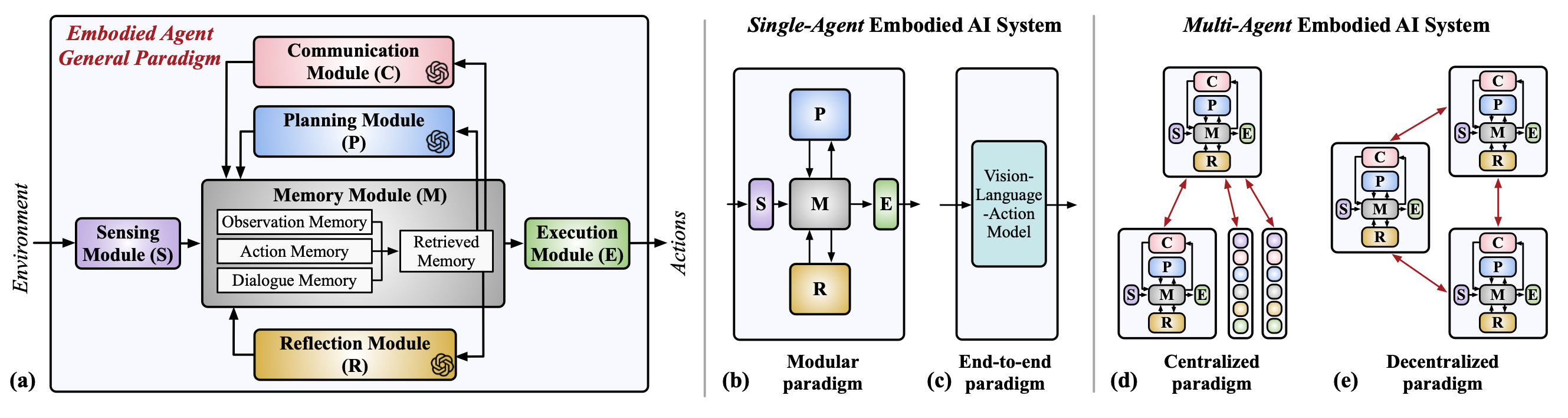
感知模块。该模块处理传感器数据,使智体能够收集和分析对更高层次推理至关重要的周围信息 [9]、[10]。它建立一个全局或共享的环境模型,其中包括空间布局图、移动实体、障碍物和资源位置[11]–[14]。智体在任务进行过程中不断更新其环境视图。在多智体场景中,智体还可以与其他智体交流其局部视图。
规划模块。规划模块将长时任务分解为一系列子目标。它首先从记忆模块检索相关信息并将其转换为文本描述。然后,它基于当前状态和存储的程序知识编译所有潜在的高级规划,使LLM能够做出明智的决策[15]–[18]。通过形式化行动列表,LLM 可以专注于推理并生成可执行的规划,而无需进行少量演示。为了增强推理能力,可以采用提示技术(例如,思维链[19]、思维树[20]和思维图[21]),引导LLM在做出最终决策前进行更深入的思考。
通信模块。通信模块从记忆中获取相关数据(例如,环境地图、任务进度、智能体状态和过往交互),并生成适当的消息,以便在多智体系统中与其他智体进行通信[22]–[24]。通信模块通常依赖于LLM先进的对话生成和理解能力。
记忆模块。具身智体将其与环境和其他智体交互中获得的知识和经验存储在记忆模块中,通常分为观察记忆、对话记忆和行动记忆。观察记忆[8]、[25]、[26]保存着智体对世界的理解,包括地图、任务进度以及智能体自身和其他智能体的状态。该记忆库会根据感知模块处理的新数据进行更新。对话记忆库[6]、[24]记录智体的交互历史和对话交流。每次智体与其他智体发送或接收消息时,相关信息都会添加到该记忆库中。动作记忆库[27]–[29]记录智体的动作和状态,并包含在不同环境下如何执行特定高级规划的知识,这些知识以代码或神经模型参数的形式编码。
反思模块。具身智体可能会产生意料之外的操作,甚至产生严重的幻觉。反思模块通常会观察决策智体操作前后的状态,以确定当前计划是否符合预期[30]–[32]。基于反思结果(例如,错误、无效和正确),智体将选择是否重新规划,并将正确的操作信息更新到记忆模块中。
执行模块。尽管LLM在高层规划方面表现出色,但在处理低层规划和控制任务方面效率较低[33][34]。为了确保在各种环境下都能做出有效且适应性强的决策,执行模块会生成基本动作,以稳健的低层方式执行高层规划[35]。这种方法使得规划模块能够保持通用性,专注于更广泛的任务解决,同时充分利用LLM丰富的世界知识和推理能力。
单智体具身智能系统:模块化范式
许多具身智能系统利用模块化范式构建智能体(如上图 b)。单智体系统通常基于部分构建模块(例如,感知、规划、记忆、反思和执行),用于执行长时域多目标任务和运动规划。例如,STEVE [41]、AppAgent [37] 和 RoboGPT [17] 由三个构建模块(感知、规划、执行)组成;DEPS [18]、MP5 [39] 和 Mobile-Agent [36] 由四个构建模块(感知、规划、反思、执行)组成;MINEDOJO [44] 由四个构建模块(感知、规划、记忆、执行)组成。 CRA-DLE [28]、RILA [40]、JARVIS-1 [27] 和 Dadu-E [43] 由五个构建模块(感知、规划、记忆、反思和执行)组成。除了这些工作负载之外,MetaGPT [46] 和 Mobile-Agent-V2 [47] 也可被视为包含多个智体角色的单智体系统。
单智体具身人工智能系统:端到端范式
除了模块化范式之外,直接从模型输出智体动作的端到端范式是另一种适用于短期具身任务的方法[48]、[49]、[51]–[53]。端到端方法通常依赖于基于大规模文本、图像和视频数据训练的通用视觉对齐大语言模型,作为创建可在各种环境中行动的具身多模态智体的基础(如上图c)。例如,RT-2[48]是一个基于网络规模知识库预训练的视觉-语言-动作模型,用于实现端到端的机器人控制。RoboVLMs[49]提出一种旨在将视觉-语言模型转换为通用视觉-语言-动作模型的框架。 3D-VLA [51] 通过整合 3D 输入扩展这一范式,实现了与更广泛的 3D 物理世界的无缝集成。GAIA-1 [50] 利用视频、文本和动作输入生成逼真的驾驶场景,并对自车行为和场景特征进行精细控制。
多智体具身人工智能系统:集中式范式
基于单个具身智体所展现出的卓越能力,多智体具身人工智能系统应运而生,旨在充分利用多个智体的集体智慧和专业技能。在多智体系统中,每个智体通常包含全部或部分构建模块(感知、规划、通信、记忆、反思和执行),从而协同进行规划、讨论和决策,模拟人类群体在长期多目标任务中的合作模式。
构建多智体具身系统的一种方法是,由一个集中式智体生成并向系统中的所有具身智体传达下一步规划,每个智体可以向中央智体规划器提供本地反馈(如上图 d)。例如,MindAgent [8]、OLA [24]、CMAS [23] 和 COHERENT [31] 都采用集中式范式,以协作的方式进行游戏交互以及长期任务和运动规划。
多智体具身人工智能系统:去中心化范式
多智体具身系统也可以构建在去中心化范式中,其中每个智体生成自己的规划并与其他智体进行协作对话(如上图 e)。同样,每个智体都配备感知、规划、通信、记忆、反思和执行模块。例如,CoELA [6]、COMBO [7]、DMAS [23]、RoCo [30]、Organized LLM Agents [24] 和 KoMA [61] 都利用去中心化范式来完成诸如物体运输、机器人操作、自动驾驶车辆控制和游戏交互等长期任务。
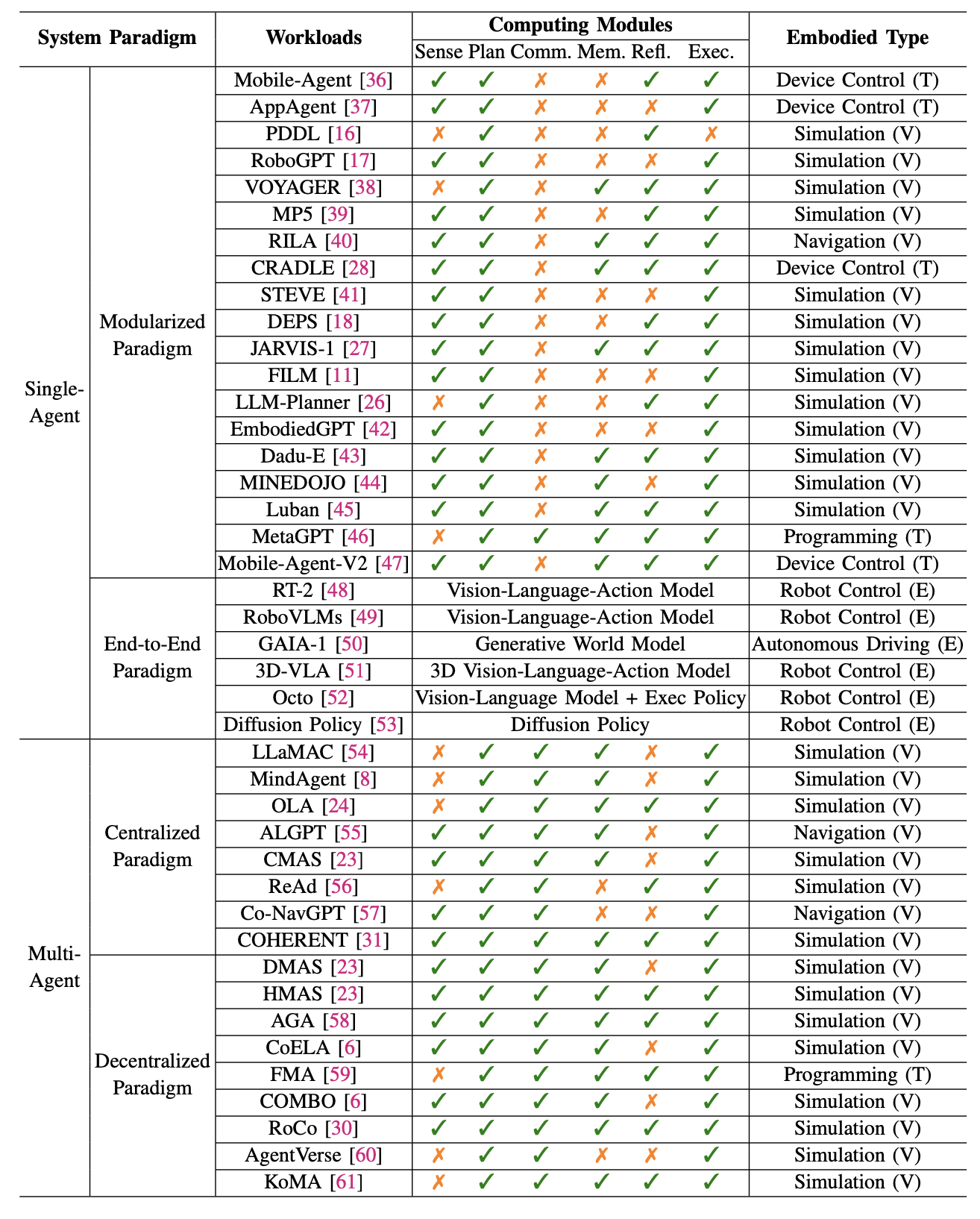
最后如下表所示,根据计算模块组成,将近期出现的具身人工智能智体系统分为四种范式:动作类型 V、T和E,分别代表虚拟动作、工具使用和物理动作。
工作负载套件概述
工作负载套件包含 14 个具身人工智能智体系统。如表所示,每个具身系统都针对特定的用例,并详细说明构建模块、应用程序、部署场景和范式。此外,为了提高可移植性,将每个系统都实现为 Docker 镜像。这 14 个具身人工智能智体系统包括 5 个单智体系统(EmbodiedGPT [42]、JARVIS-1 [27]、DaDu-E [43]、MP5 [39]、DEPS [18])、4 个集中式多智系统(CoELA [6]、COMBO [7]、RoCo [30]、DMAS [23]、HMAS [23])。这些系统代表了多种具身认知范式,并在长期任务中展现出最先进的性能。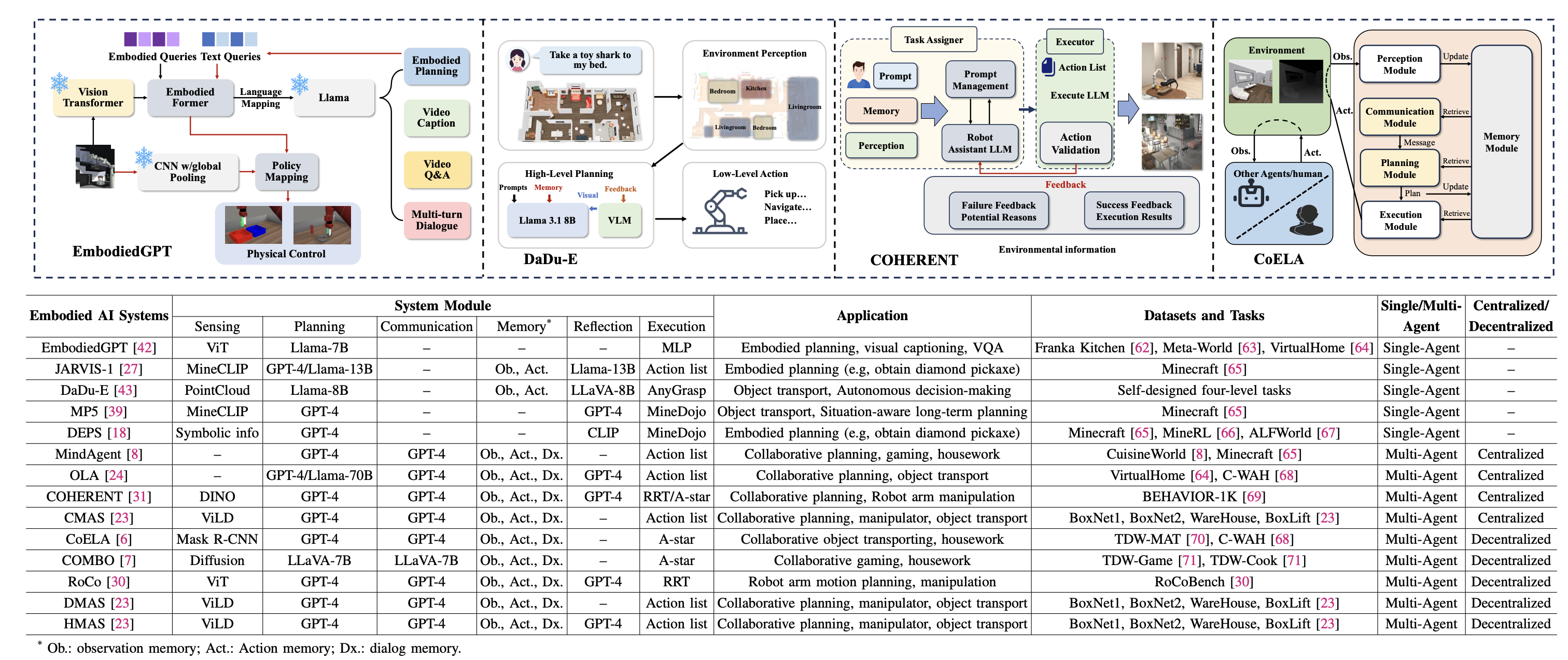
单智体具身系统
对于单智体系统,分析主要集中在模块化范式上,因为这些智体是为长期具身规划任务而设计的。
EmbodiedGPT。EmbodiedGPT [42] 是一个用于长期具身任务的多模态模块化具身系统。它由感知模型(Vision Transformer)、视觉语言规划模型(微调的 Llama-7B 模型)和底层执行策略网络(多层感知器)组成,实现了高层规划和底层控制的无缝集成。在 Franka Kitchen [62]、Meta-World [63] 和 Virtual-Home [64] 等场景上进行评估后,EmbodiedGPT 在具身规划、具身控制、视觉字幕和视觉问答等具身任务中表现出色。
JARVIS-1。 JARVIS-1 [27] 是一个开放世界智体,能够感知多模态输入(视觉观察和人类指令),生成复杂的规划,并执行具身控制。它由感知模型(MineCLIP [44])、长时程规划模块(GPT-4 或 Llama-13B)、用于存储观察结果和动作的记忆模块、自我反思模块和执行模块组成。在 Minecraft [65] 上进行评估后,JARVIS-1 在从短时程规划(例如砍树)到长时程任务(例如获取钻石镐)的各种具身任务中表现出色。
DaDu-E [43] 是一个用于具身人工智能机器人的鲁棒闭环规划框架。它配备了基于激光雷达点云的传感模块、轻量级规划模块(Llama-8B)、反思模块(LLaVA-8B)、记忆增强模块和底层抓取执行模块(AnyGrasp [72])。在自主设计的四级具身人工智能任务上进行评估后,DaDu-E 在多任务执行、长时程决策、认知语言理解和物体运输方面表现良好。
MP5。MP5 [39] 是一个开放式的多模态具身系统,能够分解可行的子目标,设计复杂的态势-觉察的规划,并执行具身动作控制。它由传感模块(MineCLIP [44])、规划模块(GPT-4)、反思巡逻器(GPT-4)和底层执行器(MineDojo [44])组成。在 Minecraft [65] 上进行评估后,MP5 在具有高度进程依赖性和上下文依赖性的开放式任务中表现良好。
DEPS [18] 是一个多任务具身智体系统,用于解决开放世界环境中复杂且长期的任务。它配备感知模块(符号信息)、规划模块(GPT-4)、反思模块(CLIP)和底层控制器(MineDojo [44])。在 Minecraft [65]、MineRL [66] 和 ALFWorld [67] 上进行评估后,DEPS 展现了在开放世界中处理具有复杂依赖性和关系的复杂任务的能力。
多智体集中式具身系统
MindAgent。MindAgent [8] 是一个用于协作游戏和家务的多智体具身系统,它使智体能够以集中的方式协作完成复杂的长期任务,并具备涌现式规划能力。LLM(GPT-4)促进任务调度和协作,通过少样本提示和反馈提高规划效率。在 CuisineWorld [8] 和 Minecraft [65] 上进行评估后,MindAgent 在增强多智体协调和协作效率方面表现出色。
OLA。Organized LLM Agents (OLA) [24] 是一个多智体框架,它能够灵活地提示和组织具身智体,使其组成各种团队结构,从而促进智体之间多样化的通信。每个智体都配备规划和通信模块(GPT-4),能够对团队绩效进行批判性反思,并生成改进的组织提示。在 VirtualHome [64] 和 C-WAH [68] 上进行评估后,OLA 在长时程规划任务中表现出色,通信成本更低,效率更高。
COHERENT. 异构多机器人系统协作 (COHERENT) [31] 是一个用于异构多机器人任务规划的集中式分层框架。它由一个感知模块 (DINO [73]) 和一个提议-执行-反馈-调整机制 (GPT-4) 组成,用于将复杂任务分解为子任务,然后将子任务分配给机器人执行器(RRT 或 A*)。在 100 个 BEHAVIOR-1K 场景 [69] 上进行评估后,COHERENT 能够高效地完成复杂且长时程的任务和运动规划。
CMAS. CMAS [23] 是一个用于协作规划的集中式多智体具身系统。它使用图像-到-文本模型 ViLD [74] 为环境目标提供文本描述。中央智体使用 GPT-4 为所有机器人生成下一步动作并传达指令。在 BoxNet、Warehouse 和 BoxLift 环境中进行评估后,CMAS 在长时程异构多机器人规划方面表现出色。
多智体去中心化具身系统
CoELA。协作具身语言智体 (CoELA) [6] 旨在使具身智体能够在去中心化环境中相互协作或与人类协作,以完成长时程多目标任务。CoELA 使用 Mask R-CNN 进行感知,使用 GPT-4 进行规划和通信,在 TDW-MAT [70] 和 C-WAH [68] 任务上表现出色,尤其擅长感知复杂环境、推理世界和其他智体、高效通信以及执行协作物体运输和家务等任务中的长时程规划。 COMBO(Compositional Model for Embodied Multi-Agent Cooperation,组合式具身多智体协作模型)[7] 是一个基于组合式世界模型的具身多智体去中心化系统,旨在促进在线协作规划。智体通过扩散模型 [75] 从部分自我中心观测数据中重构全局世界状态,并利用视觉-语言模型(LLaVA-1.5 [76])推断其他智体的意图、进行通信并提出行动方案。通过树搜索优化行动序列,COMBO 在 ThreeDWorld [71] 中的长时程协作任务(如 TDW-Game 和 TDW-Cook)中表现出色。
RoCo [30] 是一个零样本多机器人具身系统,用于协作操作和轨迹规划任务。它配备感知模块(OWL-ViT [77])、规划模块(GPT-4)、通信模块(GPT-4)、存储模块、反思模块(GPT-4)和底层RRT规划器。在RoCoBench [30] 上进行评估后,RoCo能够灵活地处理各种任务,并改进了任务级协调和动作级运动规划。
DMAS。DMAS [23] 是一个用于协同规划的去中心化多智能体具身系统。每个智能体使用 GPT-4 进行规划,智能体之间的对话以轮流发言的方式进行。DMAS 在 BoxNet、Warehouse 和 BoxLift 环境下进行了评估,结果表明其能够高效地完成协同规划、机械臂操作和物体运输任务。
HMAS。HMAS [23] 是一个结合集中式和去中心化方法的多智体系统。在 HMAS 中,一个智体提供初始规划以启动智体之间的对话,每个智体在任务执行期间向中央智体提供本地反馈。HMAS 在协同体动作则在Intel i7 CPU上执行。
。。。。。。待续。。。。。。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 33
33 0
0- 0



 已为社区贡献225条内容
已为社区贡献225条内容

所有评论(0)