Nano Banana Pro 真的有那么神吗,硬核测评!附:Nano Banana Pro 提示词 & 玩法大全

在过去两三年里,图像生成模型的更新频率非常快,但如果你真正参与过 AI 视频、AI 漫剧或广告分镜制作,大概率会有一种共同感受:
模型确实越来越会“画”,但在真实生产中依旧不够稳定。
最常见的问题并不在“好不好看”,而在于以下几点:
-
跨镜头角色不一致
-
指令理解不到位
-
多图参考合成生硬
-
文字、UI、表格不可用
-
无法真正理解分镜和镜头语言
这些问题会直接导致一个结果:生成的图无法顺畅进入视频生产链路,最终还是要人工大量返工。
基于这些长期存在的痛点,本文尝试通过一组高约束、偏实战的压力测试任务,对近期一款新的图像生成模型在 分镜一致性、叙事理解与可交付性 方面的表现进行记录与分析。
此外,如果你也想一起测评Nano Banana Pro,我这里有个Demo:
Nano Banana Pro | 中文版在线
一、测试目标与方法说明
与常见“看单张图好不好看”的测试不同,这次测试的核心目标是:
判断图像模型是否具备进入 AI 视频生产前期的能力
因此测试重点集中在:
-
连续分镜的一致性
-
复杂指令的遵循能力
-
文字与 UI 的可读性
-
多图融合与真实合成
-
是否具备基础的镜头理解
换句话说,就是直接拿平时最容易卡模型的题来测。
二、结论先行:它更像是在「按分镜做事」
如果用一句话总结这次测试的整体感受:
它不是更会画“单张好看的图”,而是开始能按分镜逻辑完成任务。
过去很多模型在单张表现上已经很强,但一进入连续叙事场景,就会出现明显掉链子的情况,例如人物跨镜不认人、道具细节变化、文字错误等。
而这次测试中,模型在 连续性和可控性 方面的表现,相比以往模型有明显提升,这也是本文重点记录的部分。
三、测试一:AI 漫剧最核心的问题——跨镜一致性
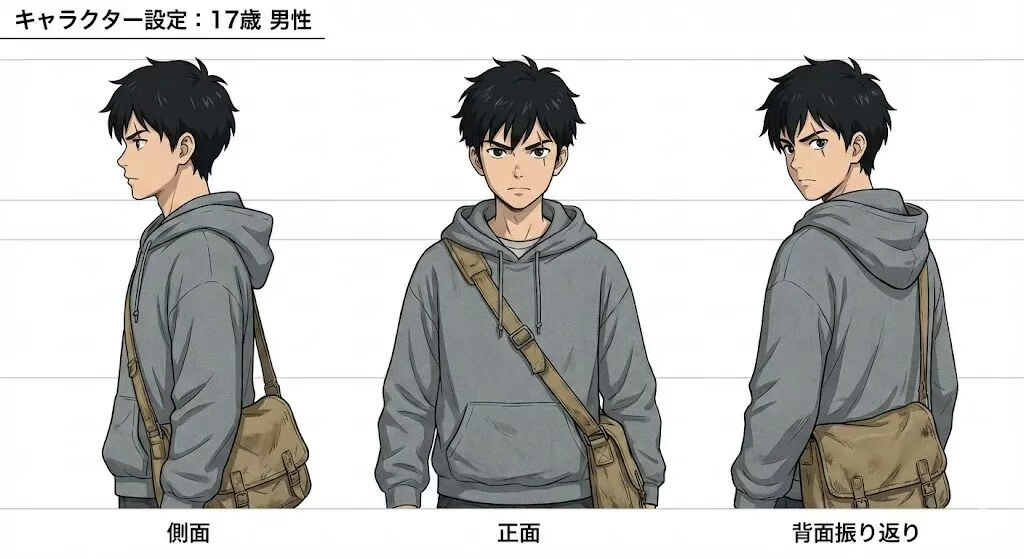
1. 三视图转身设定测试
连续分镜的基础,是模型能否真正“把一个角色当作同一个人”。
测试任务如下:
生成一个 AI 漫剧主角的三视图转身设定:
正面半身 / 侧面半身 / 背面半身回头要求:
同一张脸
同一套衣服
同一身材比例
仅角度变化
风格:高质感日漫,线条统一
这是很多模型的“第一道坎”。常见情况是:
正面还能接受,侧面开始变化,背面基本重来一个人。
在这次测试中,角色的关键特征(脸型、疤痕位置、服装细节、背包)在三张图中保持得相对稳定,属于可以直接用于连续叙事的水平。
从生产角度看,这意味着模型开始具备最基本的“角色概念”。
四、测试二:连续镜头中的情绪与镜头语言
1. 雨夜天桥三镜头测试
第二组测试直接进入真实分镜场景:
同一场戏,三张连续分镜
远景建立环境
中景推进情绪
特写突出信息
要求人物、光影、雨势、环境严格连续
且关键文字必须清晰可读
测试结果中,三个镜头在整体光影方向、人物状态以及情绪推进上保持一致。
尤其明显的是:镜头关系是成立的,而不是简单的“三张相似图片”。
这一点对后续“图生视频”非常关键,可以明显减少前期素材修补的时间。

2. 镜头语言理解测试(虚焦 / 长焦 / 运动模糊)
进一步测试模型是否理解摄影语言,例如:
-
前景虚焦遮挡
-
主体焦点控制
-
运动模糊与追焦
-
背景光源拖影
在这些测试中,模型对“焦点位置”和“主体权重”的理解相对明确,生成结果在构图逻辑上是自洽的。

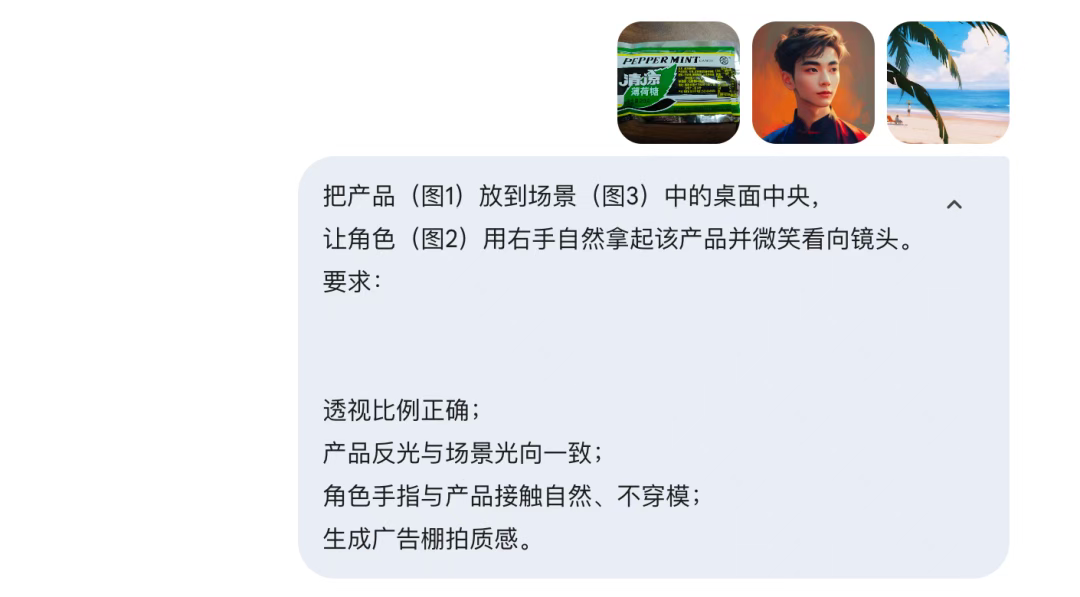
五、测试三:真实生产中最容易翻车的「产品合成」
在广告和商业项目中,“产品拿在手里是否自然” 是公认的高难度场景。
测试任务围绕:
-
手部结构
-
产品透视
-
光影方向
-
场景融合
在多次测试中,模型对产品位置、反光方向和阴影关系的处理较为稳定,生成结果没有明显“贴纸感”。
这类融合能力在实际商单和海报场景中具有较高参考价值。

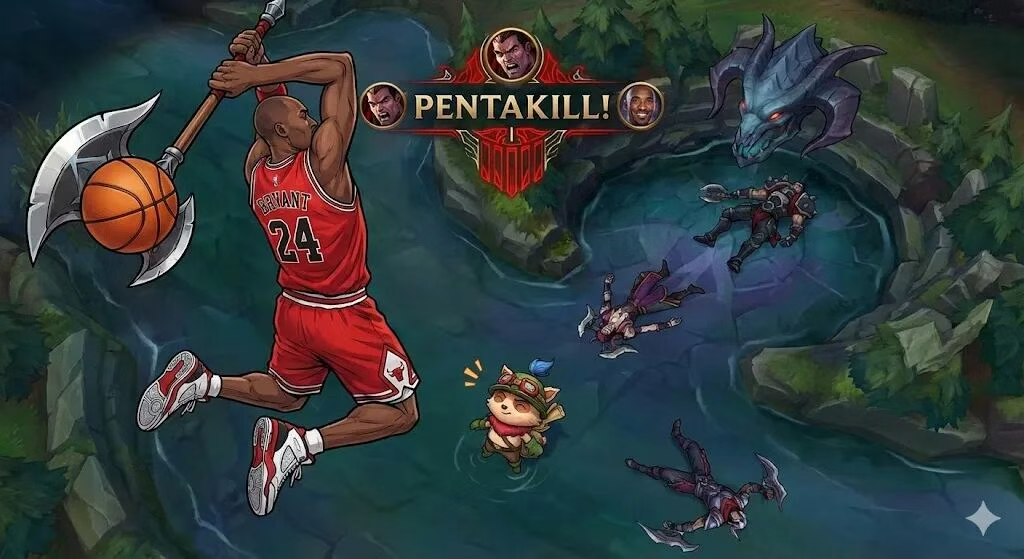
六、测试四:多 IP、多风格、大场景融合
为了验证模型的综合融图能力,还测试了:
-
不同 IP 的风格混合
-
大量人物同框
-
游戏 × 影视 × 漫画的设定融合
在降低图片复杂度后,模型在人物数量、风格统一性和指令遵循度上表现稳定,适合用于构思型画面或视觉提案。
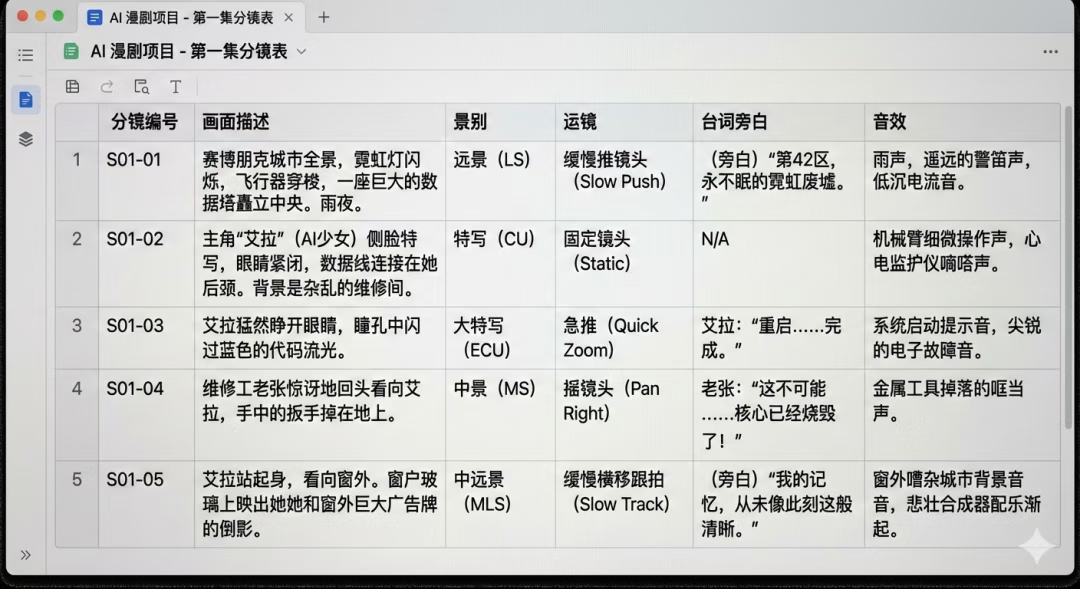
七、测试五:文字、表格、UI 的「可用性」测试
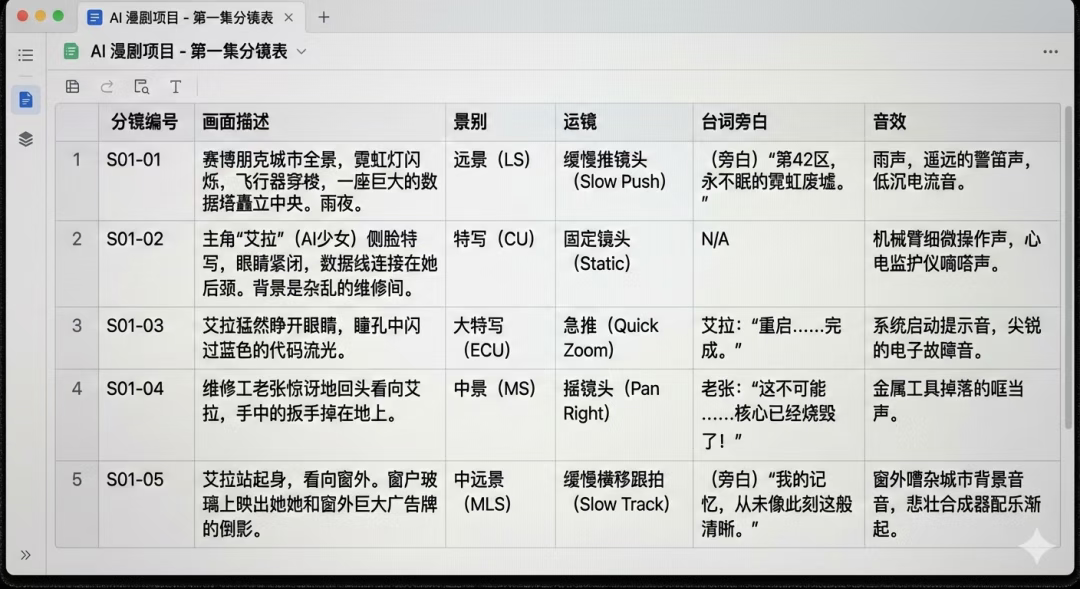
1. 分镜表截图
要求生成一张清晰可读的中文分镜表,包括列名、内容与排版。
在此测试中,表格结构完整,文字清晰,对齐合理,接近真实工作截图。
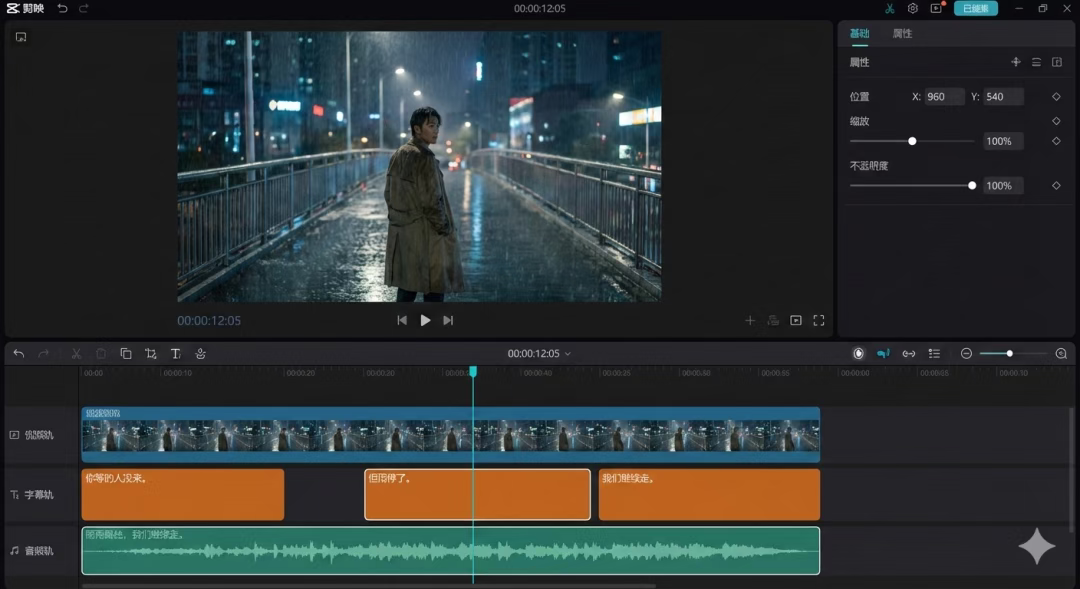
2. 视频剪辑时间线 UI
进一步测试复杂 UI 结构:
-
预览窗口
-
多轨时间线
-
可读字幕
-
参数面板
生成结果在结构逻辑上是合理的,文字可读性也达到了“可展示”的水平。
3. 教学黑板 / 手写笔记 / 静物物理测试
包括:
-
粉笔中文字
-
手写数学推导
-
时钟与液体物理关系
整体正确率较高,但在部分细节(如指针角度)上仍需要人工校验。

八、更多应用场景测试
测试还覆盖了:
-
批量 Logo 图标生成
-
教学卡片设计
-
信息图插画
-
节日主视觉
-
科普类视觉内容
在这些场景中,模型更像是一个可用于打底和构思的视觉工具,而不是仅供娱乐。
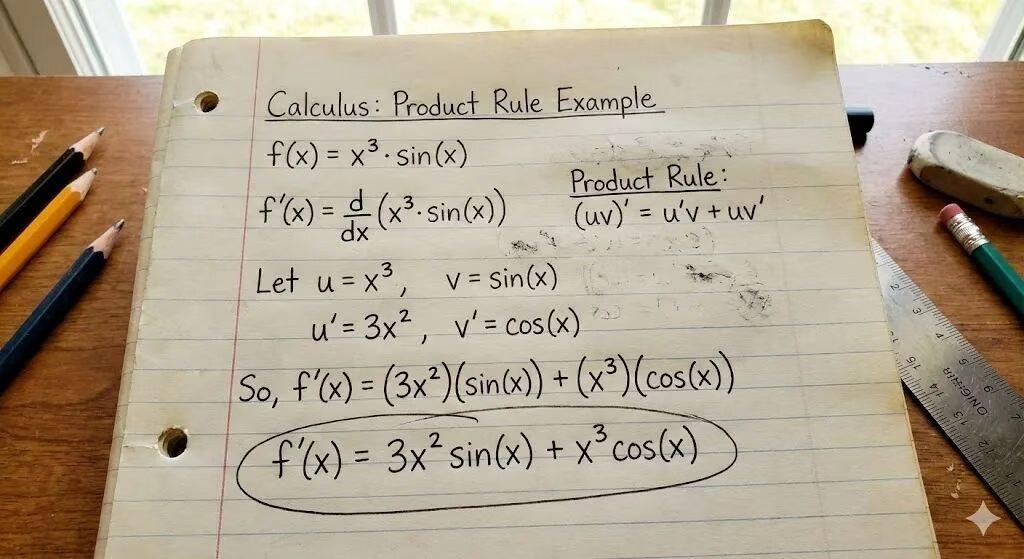

九、局限与不足
尽管整体表现较强,但仍存在明显限制:
-
浏览器端输出分辨率存在上限,高分辨率仍受限
-
个别复杂题材(如长条漫)偶发生成失败
-
数学与物理细节存在小概率错误
-
生成成功率并非 100%,仍需多次尝试
这些问题在严肃生产中仍需要人工介入。
十、总结:它开始更像“生产工具”
综合来看,这次测试最大的变化不在“画面多惊艳”,而在于:
模型开始理解“为什么要这样画”
对于需要连续分镜、稳定角色、可读文字和可进入视频流程的创作者来说,它在前期制作中的价值要明显高于以往模型。
如果只是单纯玩图,它只是一个更强的工具;
但在 AI 视频、AI 漫剧、分镜制作 这类场景里,它已经具备进入工作流的潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)