AI+材料表征
AI+材料表征
文章目录
1.基于原子力显微镜的微纳结构多视角神经三维重建
Multi-view neural 3D reconstruction of micro- and nanostructures with atomic force microscopy communications engineering
摘要:原子力显微镜(AFM) 是一种广泛应用于微米和纳米尺度形貌成像的工具。然而,传统的AFM扫描由于受限于不完全的样品形貌捕获以及探针-样品卷积伪影等问题,难以精确重建复杂的3D微纳结构。在此,我们提出一种基于多视图神经网络的AFM框架,命名为MVN-AFM,能够准确重建复杂微纳结构的表面模型。与以往的3D-AFM方法不同,MVN-AFM不依赖于任何特殊形状的探针,也无需对AFM系统进行昂贵的改装。为实现这一目标,MVN-AFM采用一种迭代方法,同时对多视角数据进行配准并消除AFM伪影。此外,我们将神经隐式表面重建技术应用于纳米技术领域,并取得了更好的效果。进一步的广泛实验表明,MVN-AFM能有效消除原始AFM图像中存在的伪影,并重建多种微纳结构,包括通过双光子光刻打印的复杂几何微结构,以及聚甲基丙烯酸甲酯(PMMA)纳米球、沸石咪唑酯骨架-67(ZIF-67)纳米晶体等纳米颗粒。这项工作为微纳尺度三维分析提供了一种经济高效的工具。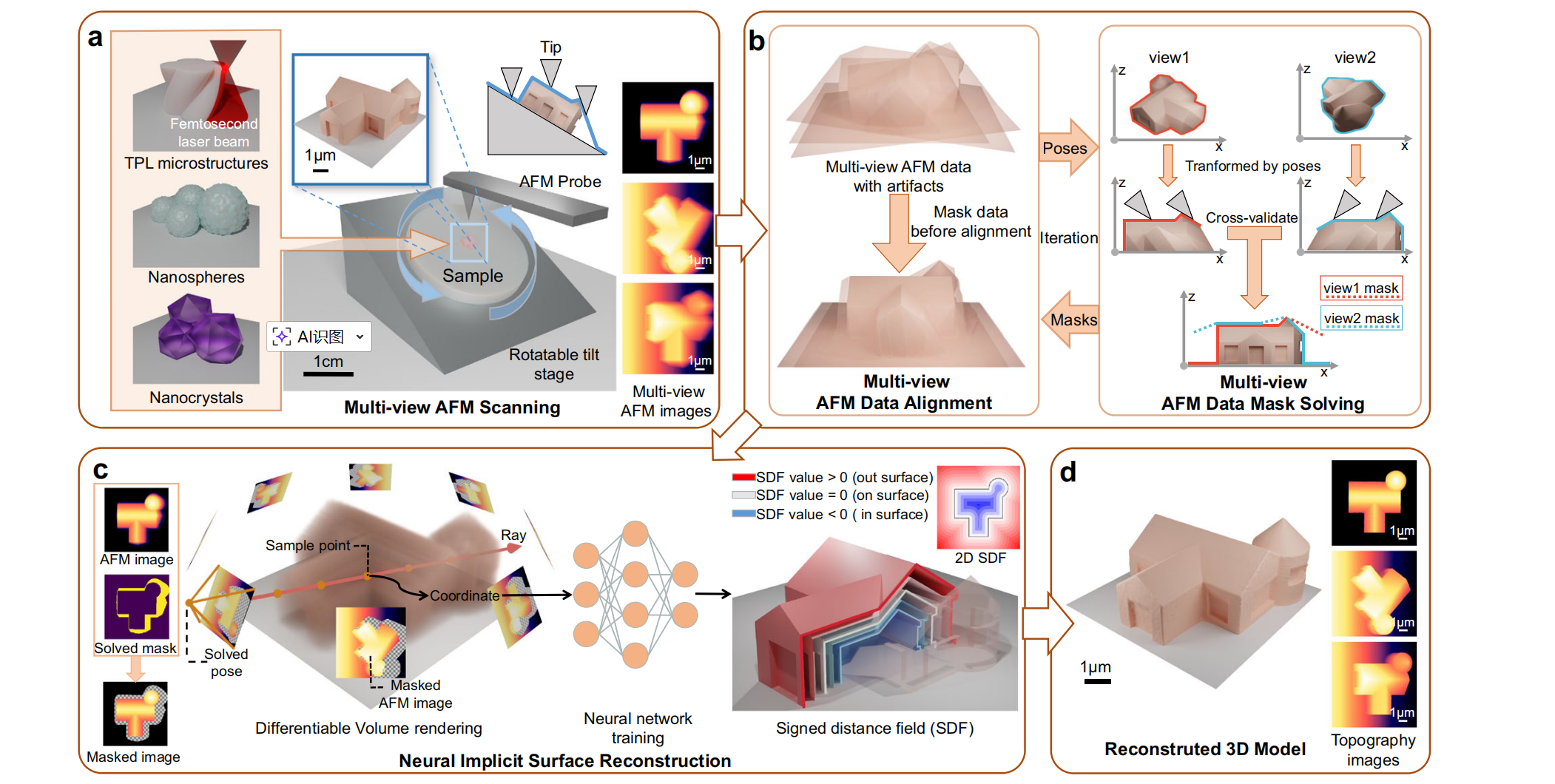
图1 | MVN-AFM 技术流程
a 首先,我们将多种微纳结构置于可旋转倾斜台上,包括双光子光刻(TPL)微结构及一些常用纳米颗粒。随后,旋转平台并通过常规原子力显微镜(AFM)测量垂直高度,得到一组存在大量伪影的多视图AFM图像。
b 输入带有伪影的原始AFM图像,并迭代两个子步骤:在数据对齐过程中,先剔除判定为伪影的数据再进行对齐,并更新多视图图像的姿态;在掩模求解过程中,利用已求解的姿态变换多视图数据,并通过交叉验证数据一致性来求解伪影掩模。
c 将已标定姿态并去除伪影的多视图AFM图像用于训练神经网络,该网络通过可微分体积渲染技术(附图5)表示空间中的有向距离场。
d 从有向距离场提取的三维表面模型,以及对应的无伪影形貌图像。
1. 介绍
(1)、微纳3D结构研究的重要性与现有表征工具
3D结构研究在纳米技术(含纳米制造、纳米机器人、纳米药物)领域至关重要,直接决定微纳尺度物体的功能特性。
现有主流表征工具对比:
- 扫描电子显微镜(SEM):可提供微纳结构几何形态的定性信息,但属于破坏性方法、需真空环境,且无法在图像中提供准确的高度信息。
- 原子力显微镜(AFM):通过探针与样品间的作用力获取精确的表面高度信息,支持多环境工作、对样品材料不敏感且非破坏性。
(2)、传统AFM的局限与3D-AFM的技术方向
- 传统AFM的不足:仅能获取2.5D信息(无法实现完整3D表征);针尖与样品的几何作用会产生“针尖-样品卷积”伪影,这类伪影难与真实结构区分,限制了AFM对复杂微纳结构的应用。
- 3D-AFM的两大技术路径:
- 路径1:特殊探针设计(如CD-AFM、铰链结构探针等):可表征侧墙等结构,但特殊探针与定制扫描系统的高成本、高复杂度,阻碍了该方法的普及。
- 路径2:倾斜扫描拼接法:通过倾斜探针/样品进行多视角扫描,再拼接为3D模型。该方法过去仅适用于光栅等简单结构;但面对双光子光刻制备的复杂结构、纳米颗粒等样品时,会出现“伪影难手动去除”“伪影降低拼接精度”“多视角重叠关系复杂导致模型不清晰”等问题。
(3)、本研究的MVN-AFM框架
本研究提出MVN-AFM框架,可在无需特殊探针或昂贵AFM改装的前提下,重建各类复杂微纳结构的3D表面模型:
- 技术特点:通过迭代优化算法自动去除伪影、提升多视角数据的对齐精度,可处理8个倾斜角度的多视角AFM数据;借鉴计算机视觉的多视角深度融合技术,结合神经隐式表面重建方法,通过差异体积渲染训练网络,融合多视角数据得到精准3D模型。
- 实验效果:对双光子光刻微结构、PMMA纳米球、ZIF-67纳米晶等样品,该框架可有效去除原始AFM图像的伪影,完整重建结构的整体形状与传统AFM无法分辨的细节,且实施成本低,是纳米技术研究中潜在的实用工具。
2 结果:MVN-AFM的流程
MVN-AFM的目标是构建一套通用流程,基于多视角AFM扫描数据重建未知形状的复杂微纳结构,且仅依赖传统AFM系统。该流程包含3个核心步骤:
- 多视角AFM扫描
目的:获取微纳结构的多视角AFM图像,为后续重建提供几何信息。
- 设计思路:不同于传统倾斜法仅用2次扫描(适用于光栅类已知结构),本流程不依赖样品形状,采用样品倾斜法(避免改装AFM机械结构),设计了带倾斜角的旋转台(实验中倾斜角设为30°,避免探针碰撞样品),尺寸适配商用AFM。
- 扫描方案:每个样品进行8次均匀分布在360°范围内的倾斜扫描,加1次无倾斜扫描,共获取9组多视角数据。
- 数据对齐与掩模求解
目的:将多视角数据迭代对齐到统一坐标系,并去除AFM图像中的伪影。
- 核心问题:需确定坐标变换(位姿 T T T)来对齐多视角数据,但传统方法(高成本组件/ICP算法)易受伪影干扰,且无法处理复杂结构的伪影。
- 解决方案:提出EM-like算法,将伪影标记为隐变量(掩模 M M M),同时求解 T T T和$M$:
- 初始阶段:假设无伪影,用ICP得到粗略位姿$T_0$;
- E步:用前一次迭代的位姿投影多视角数据,通过交叉验证(伪影在不同视角下会不一致,而真实几何表面一致)识别不一致区域,更新掩模 M i M_i Mi;
- M步:通过 M i M_i Mi去除伪影,再用ICP更新位姿 T i T_i Ti;
- 迭代上述步骤,最终得到准确的位姿 T k T_k Tk和伪影掩模 M k M_k Mk。
- 神经隐式表面重建
目的:利用对齐并去伪影后的AFM数据,训练神经网络以提取微纳结构的3D表面模型。
- 方法:
- 将样品几何表面建模为多层感知机(MLP)编码的符号距离场(SDF)(空间点到表面的最短距离,外部为正、内部为负);
- 把AFM图像转换为深度图,以“AFM数据与差异体积渲染得到的深度值的差值”为损失函数,通过反向传播优化MLP参数(结合多分辨率哈希编码加速训练);
- 训练完成后,查询任意空间点的SDF值,利用Marching Cubes算法提取3D表面模型。
 图2 | MVN-AFM重建双光子光刻(TPL)微结构的表面模型
图2 | MVN-AFM重建双光子光刻(TPL)微结构的表面模型
a-f 双光子光刻微结构的扫描电子显微镜(SEM)图像。
g-l 基于传统AFM扫描数据得到的双光子光刻微结构3D模型。
m-r 经MVN-AFM重建得到的双光子光刻微结构3D模型。
g、h、m、n 包含x-z平面的横截面轮廓。
i-l、o-r 包含x-y平面的横截面轮廓。
2.人工智能辅助下,基于随机分布单根碳纳米管的纳米悬臂梁批量制备
Artificial-intelligence-assisted mass fabrication of nanocantilevers from randomly positioned single carbon nanotubes Microsystems & Nanoengineering
摘要:由碳纳米管(CNTs)制成的纳米级悬臂梁(纳米悬臂梁)在传感和电磁应用中具有巨大优势。这类纳米结构通常通过化学气相沉积和/或介电泳法制备,但这些方法包含手动、耗时的步骤(例如额外电极的放置,以及对单根生长碳纳米管的细致观测)。本文提出一种简单的、人工智能(AI)辅助的方法,可高效批量制备碳纳米管基纳米悬臂梁:我们利用基底上随机分布的单根碳纳米管,通过训练后的深度神经网络识别碳纳米管、测量其位置,并确定碳纳米管上应夹持电极以形成纳米悬臂梁的边缘。实验结果显示:该方法的识别与测量过程可在2秒内自动完成,而同类手动操作需12小时;尽管训练后的网络存在较小的测量误差(90%的已识别碳纳米管误差在200 nm以内),单次流程仍成功制备了34个以上的纳米悬臂梁。这种高精度有助于开发基于碳纳米管纳米悬臂梁的批量场发射器——这类发射器可在低外加电压下输出电流。我们还展示了批量制备碳纳米管纳米悬臂梁基场发射器在神经形态计算中的优势:利用单个碳纳米管基场发射器,物理实现了神经网络的核心功能(激活函数);结合该场发射器的神经网络可成功识别手写图像。我们认为,该方法可加速碳纳米管基纳米悬臂梁的研发进程,助力其实现极具前景的未来应用。
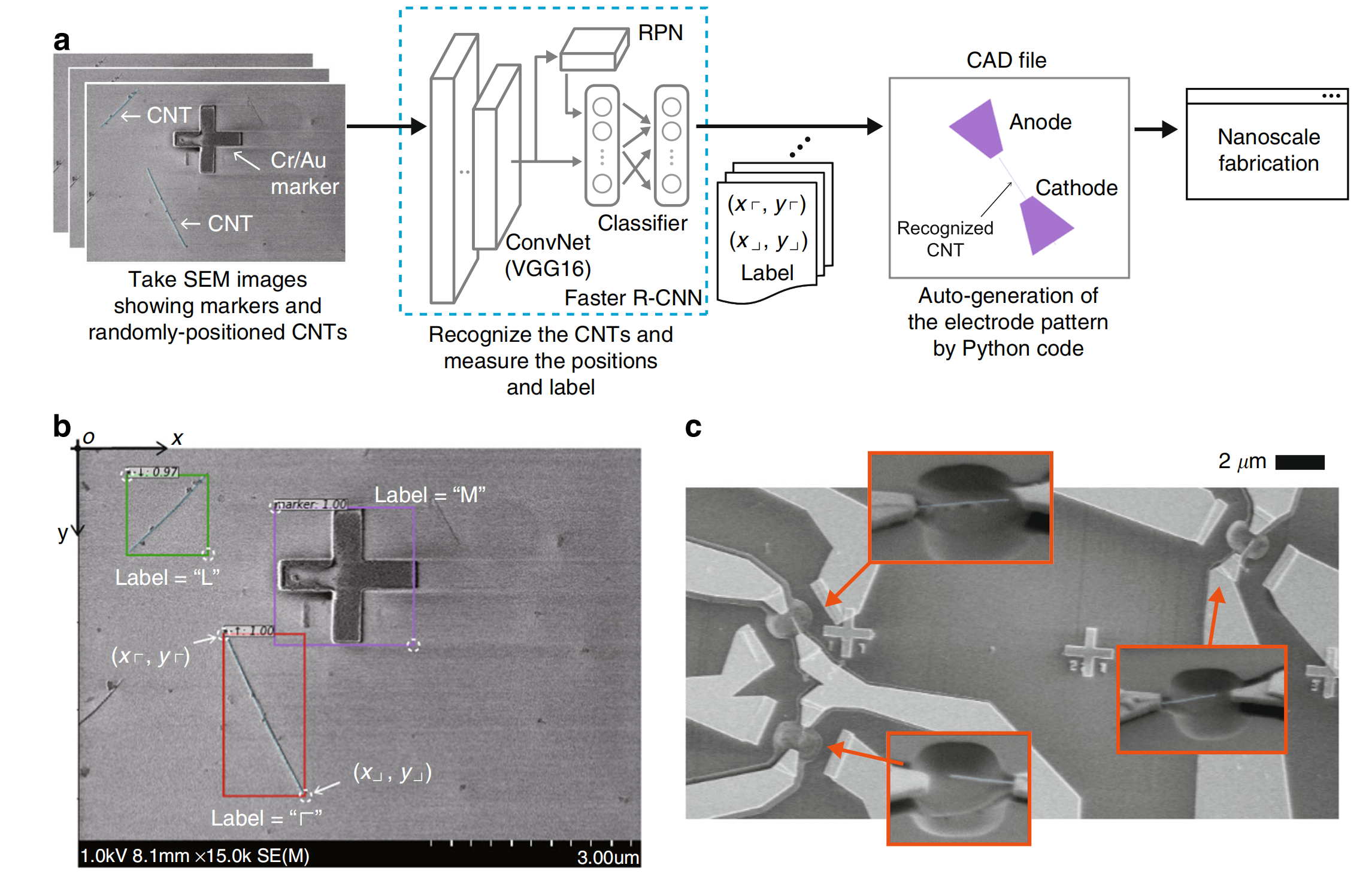
图1 AI辅助纳米悬臂梁制造及识别/制造示例
a AI辅助制造框架。将显示随机分布碳纳米管(CNT)的扫描电镜(SEM)图像输入“ F a s t e r R − C N N Faster R-CNN FasterR−CNN”神经网络,使其能够自动识别碳纳米管。识别出的碳纳米管被边界框标注,随后训练后的网络分别输出边界框左上角和右下角的坐标 ( x r x_{r} xr , y r y_{r} yr ) 和 ( x ⊥ x_{\bot} x⊥ , y ⊥ y_{\bot} y⊥ )。此外,该网络会判断哪个角落更适合放置阳极,该决定将应用于标签(参见b)。基于此信息,我们的Python代码自动生成电极图案,并创建用于纳米制造工艺的CAD文件。最终,如(c)所示,大量纳米悬臂梁被同时制造出来。
b 随机分布碳纳米管的识别结果示例。训练后的网络成功通过边界框识别出碳纳米管和标记点。标签“r”表示边界框的左上角(即识别出的碳纳米管的一端)适合制造阳极。
c 采用所提出的AI辅助方法制造的成果。我们的方法能够在单一基板的有限空间内制造出高密度的纳米悬臂梁。
3. 以机器学习模型与自动化技术革新碳纳米管合成
Transforming the synthesis of carbon nanotubes with machine learning models and automation Cell Press: matter
摘要:碳基纳米材料凭借其优异性能彻底改变了材料科学,但其合成面临瓶颈,无法满足应用需求。随着研究兴趣从实验室的小型演示转向工业应用,可重复性、均匀性和指标的统计显著性等挑战被放大,使得传统方法显得力不从心。克服这些挑战需要新的研究范式。人工智能技术擅长探索复杂的科学系统,为解决这些长期存在的挑战提供了新途径。为此,我们开发了一个专为碳基纳米材料设计的人工智能驱动平台,命名为"碳基副驾驶"。我们将CARCO应用于前景广阔但极具挑战性的水平排列碳纳米管阵列领域,并解决了两个重大挑战。首先,通过高通量筛选,CARCO发现了一种突破性的钛-铂双金属催化剂,其性能优于自21世纪初以来被认为最适合生长高密度HACNT阵列的传统铁催化剂。此外,CARCO借助虚拟实验实现了密度可控的生长,极大地增强了针对各种应用的定制化能力。值得注意的是,这些成果仅在43天内完成,时间远短于可能长达一年的传统研究过程。
在此,我们介绍"碳基副驾驶",这是一个由人工智能驱动的平台,它集成了基于Transformer的语言模型、机器人化学气相沉积系统以及数据驱动的机器学习模型。运用CARCO,我们发现了一种用于合成高密度水平排列碳纳米管阵列的新型钛-铂双金属催化剂,其性能优于传统催化剂。此外,借助数百万次虚拟实验,我们在合成预定密度的HACNT阵列方面实现了前所未有的56.25%的精确度。所有工作均在43天内完成。这项工作不仅推动了碳基纳米材料领域的发展,而且例证了人工智能与人类专业知识的结合可以克服传统实验方法的局限,标志着纳米材料研究的范式转变,并为更广泛的应用铺平了道路。
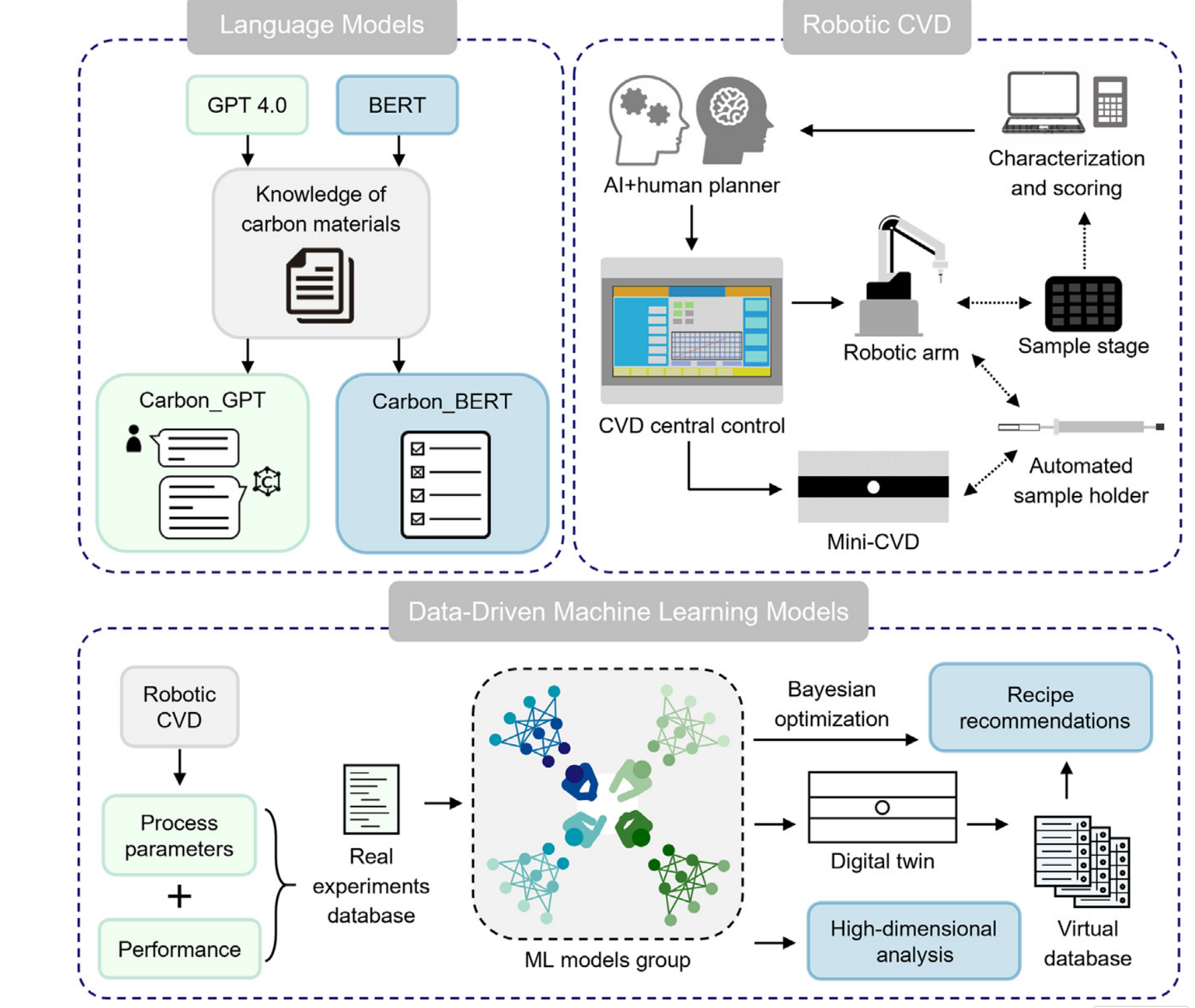
图1. CARCO平台构建
C A R C O CARCO CARCO平台由三个模块构成:语言模型模块包含两个基于碳材料知识定制的Transformer模型, C a r b o n G P T Carbon_GPT CarbonGPT用于问答任务, C a r b o n B E R T Carbon_BERT CarbonBERT用于筛选任务;机器人化学气相沉积( C V D CVD CVD)模块由CVD中央控制系统协调,实线箭头表示指令流,虚线箭头表示样品传输;数据驱动的机器学习( M L ML ML)模型模块围绕基于数据库构建的ML模型组,便于进行过程推荐和高维分析任务。
1、介绍
(1)研究背景与挑战
碳基纳米材料(如碳纳米管、石墨烯)因其卓越性能在多个前沿领域具有革命性潜力,但其从实验室走向工业应用面临核心合成挑战:
- 可控性瓶颈:难以实现结构可控、大面积均匀且高产率的合成。
传统研究范式的局限: - 在复杂的高维多变量合成系统中,传统的“单次单变量”优化方法无法解析参数间的耦合效应,易导致误解生长机理并错过全局最优条件。
- 基于假设-演绎或类比推理的研究方法,在应对机理不明确、变量高度耦合的复杂系统时效率低下,且严重依赖专家经验。
为应对上述挑战,研究团队开发了名为“碳基副驾驶”(CARCO)的AI驱动自主化学气相沉积平台。该平台由三大核心模块协同构成:
1. 基于Transformer的语言模型:
- Carbon_GPT:基于专业知识库构建,擅长识别和解答碳材料相关的宏观科学问题,提供学术见解。
- Carbon_BERT:通过碳材料文献微调,擅长基于词嵌入的筛选任务(如催化剂选择)。
2. 机器人化CVD系统:
◦ 集成中央控制器、机械臂、自动样品台等,可实现7×24小时全自动实验,显著提升实验效率、一致性与可靠性(每日可完成超过30次可靠实验)。
3. 数据驱动的机器学习模型:
-
利用自动化系统快速积累高质量标准化数据集(约1个月可建立超500组数据集)。
-
构建了CVD过程的“数字孪生”模型,能在20分钟内模拟数百万次实验,通过穷举搜索或贝叶斯优化等策略,精准映射合成参数与样品性能间的复杂关系,并解析工艺参数间的相互作用。
应用示范与成果
以高水平排列碳纳米管阵列的合成为例,CARCO在43天内取得两项关键突破:
- 催化剂创新:通过 C a r b o n G P T Carbon_GPT CarbonGPT与 C a r b o n B E R T Carbon_BERT CarbonBERT的协同分析,发现了性能优于传统铁基催化剂的新型钛-铂双金属催化剂。
- 可控生长突破:利用数字孪生模型进行数百万次虚拟实验,实现了对HACNT阵列预定生长密度的精确合成,精度达56.25%,标志着在应对复杂变量方面取得重要里程碑。
本研究不仅推动了碳基纳米材料(特别是碳纳米管)的发展,更展示了一种人机协作的新科研范式。CARCO平台通过整合AI大语言模型、自动化实验与数据驱动模型,克服了传统方法在复杂性、效率与可解释性上的局限,为纳米材料及其他复杂系统的研究提供了可扩展的高效路径。
4. 以石墨烯为案例:迈向AI驱动的二维材料自主生长
Towards AI-driven autonomous growth of 2D materials based on a graphene case study nature:Communications Physics
摘要:二维(2D)材料的规模化合成,仍是其集成至固态技术中的关键挑战。尽管剥离技术推动了诸多科学进展,但它并不适用于大规模应用。如今人工智能(AI)的发展为材料合成提供了新策略:本研究探索了通过进化方法训练的人工神经网络(ANN)在石墨烯生长优化中的应用。该ANN可在无需有效配方先验知识的前提下,自主优化随时间变化的合成方案。研究以拉曼光谱为评估依据——类单层石墨烯的结果会获得更高评分;这种反馈机制能实现合成条件的迭代改进,逐步提升样品质量。通过将AI驱动的优化融入材料合成,本研究助力了2D材料规模化方法的开发,同时展示了机器学习在指导实验过程中的潜力。
1、介绍
(1). 2D材料规模化的痛点
2D材料革新了材料科学,但高质量单晶2D材料的规模化生产仍是难题:
- 剥离法制备的材料虽有应用潜力,但基于其制造的器件缺乏可重复性、制备流程繁琐;
- 石墨烯可通过化学气相沉积(CVD)实现大规模生长,但其他2D材料及异质结构缺乏成熟的规模化方法,难以制备大尺寸、低缺陷、厚度可控的晶体,导致可重复性与缺陷管理不足,限制了其在量子计算、传感等领域的实用化。
(2). AI在材料合成中的价值
AI是解决上述挑战的有效方案:
- 它已在石墨烯研究中用于预测能隙、模拟裂纹演化等;
- 近年AI还推动了材料科学的新型合成方法(如结合机器人、从头算数据库与主动学习,优化新型无机材料合成——传统方法通常耗时且昂贵)。
(3). 本研究的AI驱动石墨烯生长方案
本研究采用人工神经网络(ANN)+自适应蒙特卡洛(aMC)主动学习法,实现石墨烯的自主生长优化:
- ANN的优势:适合编码“随时间动态变化的合成方案”这类高维对象,能有效建模复杂关系,适配自主优化任务;
- 核心逻辑:ANN无需生长工具的先验知识,通过aMC方法迭代优化合成方案(以SiC热分解生长同质石墨烯为案例,可控参数包括最低温、最高温、升温速率);
- 意义:该方法无需气态碳前驱体,展示了AI定制、优化2D材料生长的可行性;为“自主合成智能材料”铺路,有望发现当前技术难以制备的高质量材料,开拓材料科学新前沿。
图1 研究目标与方法
本研究旨在探索人工神经网络能否在无先验生长协议知识的前提下,自主学习并优化时变控制协议,以实现具有特定光学与晶体性质的材料合成。该研究采用了与传统方法截然不同的新思路。
方法核心:采用自适应蒙特卡洛主动学习策略。在该框架下,ANN不依赖于历史数据集,而是通过与实验系统的闭环迭代,直接根据实验反馈持续优化合成方案。
验证体系:以碳化硅热分解法制备高质量、均匀的石墨烯作为原理验证。此体系生长参数较少(仅涉及最低温度、最高温度和升温速率),是验证ANN学习晶体生长可行性的理想模型。ANN的任务是提出一个温度随时间变化的协议,以实现合成目标。
研究意义:这项工作展示了利用人工智能定制和优化二维材料生长的可行性与显著优势。通过将能够学习与适应的ANN整合到合成实验室,相当于为实验室嵌入了一个“大脑”,为材料的自主合成开辟了道路。更进一步,该方法有望发现合成当前无法制备的高质量材料的新途径,从而开拓材料科学的新前沿。

图1 | 本研究中所用人工神经网络( A N N ANN ANN)训练的示意图
先基于参数猜测完成初始化,随后进行方案生成(步骤i),接着开展样品生长(步骤ii);随后通过拉曼光谱对所得样品进行表征(步骤iii);提取的数据用于评估得分(步骤iv);最后,利用新参数更新方案(步骤v),并生成新的方案。
2、方法
本文介绍了通过自适应蒙特卡洛( a M C aMC aMC)训练人工神经网络( A N N ANN ANN)的方法,以自主找到SiC热分解法生长石墨烯的最高效方案。仅需输入炉体工作温度范围与起始温度即可启动。整个ANN训练流程如图1所示,包含5个迭代步骤:
(i) 方案生成:由ANN生成温度剖面协议 P T C PTC PTC(即温度随时间变化的曲线 T ( t ) T(t) T(t)),并将其输入冷壁反应器;
(ii) 样品生长:反应器以步骤(i)生成的温度剖面为输入,在SiC上进行石墨烯生长;
(iii) 样品表征:对合成样品进行拉曼光谱表征,将所得光谱与理想目标光谱对比,生成得分;
(iv)(流程环节):基于上述结果更新ANN参数;
(v) 方案更新:按照下文所述的aMC方法更新参数后,生成新的协议 P T C j PTC_j PTCj。
该迭代过程每个周期生成一个协议:第1周期生成 P T C 0 PTC_0 PTC0,第2周期生成 P T C 1 PTC_1 PTC1,以此类推,第 j j j周期生成 P T C j PTC_j PTCj。
神经网络的核心是非线性函数逼近器,由一组参数(权重与偏置)定义。网络节点以时间序列 t = { t 1 , t 2 , . . . } t = \{t_1, t_2, ...\} t={t1,t2,...}为输入,生成定义协议( PTC )的温度剖面( T(t) ),基于学习到的“时间-温度”关系建模温度随时间的演化。网络生成的每个协议 P T C j PTC_j PTCj都会通过实验数据验证并生成一个标量得分,该得分将用于学习步骤——调整网络的权重与偏置以最小化误差、提升模型预测精度。
在介绍aMC算法细节前,先说明SiC上外延石墨烯的生长要点:
这是一个晶体热分解的高温过程³⁸,生长过程的核心控制参数为温度、压力与时间。该技术最初在超高真空(UHV)腔室中实现³⁷,目前学界普遍认为:在惰性气体氛围、常压条件下,利用石英反应器(冷壁/热壁、卧式/立式)能获得最利于石墨烯生长的环境³⁹。
热分解过程中,硅原子从SiC表面升华,残留的碳层形成类石墨烯蜂窝晶格——其中1/3的碳原子通过sp³杂化轨道与SiC基底形成共价键⁴⁰,这一层被称为缓冲层(或零层石墨烯,ZLG)。ZLG并非真正的石墨烯,它具有带隙³⁹·⁴¹;要生长石墨烯,需升至更高的最优温度,此时第一层下方会形成富碳层,使第一层与基底解耦,这一层才会呈现单层石墨烯(MLG)特有的线性色散³⁹。若生长持续进行,SiC界面处会形成新的缓冲层,将原有石墨烯与缓冲层转化为双层石墨烯(BLG)。因此,设计合理的温度剖面是获得“含少量ZLG、BLG杂质的MLG”的关键。
考虑到温度剖面对MLG覆盖度的重要性,本研究选择了宽且具有物理意义的温度范围:将温度边界设为 T m i n = 1100 °C T_{min}=1100\ \text{°C} Tmin=1100 °C(低于已知石墨烯合成温度,为ANN提供足够的探索空间)、 T m a x = 1300 °C T_{max}=1300\ \text{°C} Tmax=1300 °C(匹配反应器的最高操作温度,兼顾安全与设备限制);起始温度 T s t a r t = 1200 °C T_{start}=1200\ \text{°C} Tstart=1200 °C取上述范围的中点,既不会过低而阻碍生长启动,也不会过接近最优合成温度,可促使ANN探索多样的温度剖面)。后续实验中,我们会移除起始温度限制,让ANN更自由地探索全温度范围。生长过程的详细实验信息见补充说明1。
aMC是一种进化算法,适用于实验次数较少的场景:每个学习步骤仅需1次实验,算法从过往成功案例中学习,以更高概率提出相似的参数调整⁴²。其流程如下:
设 x = { x 1 , x 2 , . . . , x N } \boldsymbol{x} = \{x_1, x_2, ..., x_N\} x={x1,x2,...,xN}为神经网络的参数向量(定义随时间变化的协议), U ( x ) U(\boldsymbol{x}) U(x)为损失函数(量化该协议对应的合成效果)。算法通过小高斯随机数对所有网络参数进行调整( x → x ′ \boldsymbol{x} \to \boldsymbol{x}' x→x′):
x i → x i ′ = x i + ε i (1) x_i \to x_i' = x_i + \varepsilon_i \tag{1} xi→xi′=xi+εi(1)
其中 ε i ∼ N ( μ i , σ 2 ) \varepsilon_i \sim \mathcal{N}(\mu_i, \sigma^2) εi∼N(μi,σ2), σ \sigma σ为参数更新的尺度, μ i \mu_i μi为类动量参数(下文详述)。若新协议的合成效果优于(或等同于)当前效果(即 U ( x ′ ) ≤ U ( x ) U(\boldsymbol{x}') \leq U(\boldsymbol{x}) U(x′)≤U(x)),则接受更新(1), x ′ \boldsymbol{x}' x′成为新的网络参数;否则恢复为原参数,重复上述更新流程。
类动量参数 μ i \mu_i μi初始设为0,每次接受更新后,按 μ i → μ i + η ( ε i − μ i ) \mu_i \to \mu_i + \eta(\varepsilon_i - \mu_i) μi→μi+η(εi−μi)更新( η \eta η为方法的超参数)——这能让后续参数更新更易接近过往被接受的更新。若连续多次更新被拒绝,则将类动量参数重置为0,并减小尺度参数( \sigma )的取值⁴²。
本研究中,损失函数( U )与拉曼光谱相关:每个实测光谱会被赋予一个得分,反映其与理想特征的匹配度;损失函数与得分呈负相关(损失函数越小,得分越高)。理想拉曼光谱对应的得分最高,是评估的基准。因此,ANN训练的目标是通过最大化“实测光谱与理想光谱的相似度”来最小化损失函数。
拉曼光谱的核心优势之一是能对样品进行精细mapping,有效区分石墨烯的不同类型与质量(如缓冲层、MLG、BLG)⁴³,从而明确其在样品中的分布。这种区分石墨烯层变化的能力,有助于优化生长条件、提升2D材料的整体质量。
石墨烯的拉曼光谱通常包含两个显著峰:G峰(主面内振动模式)与2D峰(面内振动模式D的二阶峰)⁴⁴。这些峰的强度、位置与宽度对石墨烯的质量和结构高度敏感——高质量石墨烯的拉曼峰通常尖锐且强度高。
本研究以2D峰为分析对象(可拟合为洛伦兹函数),得分 f f f通过公式(2)计算:
f = I + σ + 1 χ ⋅ ( σ ⋅ I ) (2) f = I + \sigma + \frac{1}{\chi} \cdot (\sigma \cdot I) \tag{2} f=I+σ+χ1⋅(σ⋅I)(2)
其中( I )与2D峰强度相关, σ \sigma σ通过双曲正切与洛伦兹半高全宽(FWHM)相关,具体定义为:
I = tanh ( I 2 D + a b ) + 1 (3) I = \tanh\left( \frac{I_{2D} + a}{b} \right) + 1 \tag{3} I=tanh(bI2D+a)+1(3)
σ = tanh ( − FWHM + a ′ b ′ ) + 1 (4) \sigma = \tanh\left( -\frac{\text{FWHM} + a'}{b'} \right) + 1 \tag{4} σ=tanh(−b′FWHM+a′)+1(4)
χ \chi χ为交互系数参数, a 、 b 、 a ′ 、 b ′ a、b、a'、b' a、b、a′、b′为经验参数。
强度参数 I I I至关重要(直接关联基底表面的石墨烯量),而与FWHM相关的项可帮助区分 M L G MLG MLG与 B L G BLG BLG( B L G BLG BLG的 F W H M FWHM FWHM通常更大)⁴⁵。选择双曲函数的原因是:超过某一阈值后生长完成,低于某一值时生长可忽略;此外,交互项 1 χ ⋅ ( σ ⋅ I ) \frac{1}{\chi} \cdot (\sigma \cdot I) χ1⋅(σ⋅I)可避免算法收敛于“仅优化两个项之一”的区域。
公式(3)(4)中经验参数的取值见补充说明2的表S1;图S1展示了本研究各协议对应的2D拉曼峰(橙色实线)及其洛伦兹拟合(蓝色实线); I I I与 σ \sigma σ的结果汇总见表S2。所有样品均在相同光谱采样条件下进行拉曼分析,每个协议均生长多个样品以测试过程的可重复性;同时通过对比“理论温度剖面”与“炉体实际温度剖面”,验证了单一协议的可重复性(见补充说明3的图S2)。
5. 推进密度泛函前沿:解决分数电子问题
Pushing the frontiers of density functionalsby solving the fractional electron problem science 正刊
背景:密度泛函理论在量子层面描述物质,但所有主流近似方法均因违反精确泛函的数学性质而存在系统误差。我们通过训练神经网络处理分子数据及具有分数电荷与自旋的虚构体系,突破了这一基础局限。所得泛函DM21(DeepMind 21)能正确描述人工电荷离域和强关联的典型案例,并在主族原子与分子的系统测试中表现优于传统泛函。DM21可精确模拟氢链、带电DNA碱基对、双自由基过渡态等复杂体系。更重要的是,该方法依托于数据和约束条件的持续优化,为逼近精确的通用泛函提供了可行路径。
1、DFT的核心困境与本文突破
量子化学与材料科学的电子能量计算以密度泛函理论(DFT)为基础,但精确泛函(电子密度到能量的映射)的具体形式尚未明确,现有主流近似泛函因违背“分数电子”的精确数学约束,普遍存在系统误差。
本文通过深度学习训练得到DM21(DeepMind 21)泛函:它遵循分数电荷(FC)、分数自旋(FS)系统的约束,在主族化学体系中表现优异,为获取精确普适泛函提供了可行路径。
2、背景:DFT约束与机器学习的应用
- DFT的约束与现有泛函:满足更多数学约束的DFT近似性能更优(如强约束的SCAN泛函精度突出);但长期以来,“分数电子”相关约束未被充分解决。
- 机器学习与泛函开发:机器学习(尤其是神经网络)已成为分子建模的核心工具,近年被用于泛函开发——原型研究表明,神经网络训练的泛函精度可与传统人工设计泛函媲美。
3、DM21泛函的设计与训练
- 约束系统:基于分数电荷(FC,总电荷非整数)、分数自旋(FS,自旋磁矩非整数)的虚拟系统训练;这类系统虽为虚拟,但能反映真实体系的电荷/自旋特性,保障泛函在各类分子、材料中表现合理。
- 训练细节:
- 以多层感知机(MLP)构建泛函,结合PySCF代码,输入Kohn-Sham(KS)轨道,属于局域范围分离杂化类型;
- 训练集包含2235个反应(原子化能、电离能等)、1161个主族分子反应、1074个FC/FS密度(仅H-Ar原子);
- 标签来自传统泛函(B3LYP)或高精度耦合簇(CCSD(T))计算;梯度训练基于微扰理论,比传统自洽迭代方法更高效。
4、DM21的性能优势
- 泛化能力:仅在裸原子的精确约束下训练,却能在分子的FC/FS体系中表现良好,证明其未过拟合,而是学习到了电荷密度的通用特征。
- 修正传统泛函缺陷:
- 解决了带电分子解离时的电荷离域误差(传统泛函会错误预测“带电分子无限分离时仍成键”,DM21能得到正确渐近线);
- 改善了闭壳层分子拉伸时的能量高估问题(传统泛函因静态关联误差高估能量,DM21可输出正确渐近线)。
- 键断裂基准优化:在量子蒙特卡洛键断裂基准(QMBB)中,DM21通过优化闭壳层轨道的分数占据,修正了能量“隆起”问题。
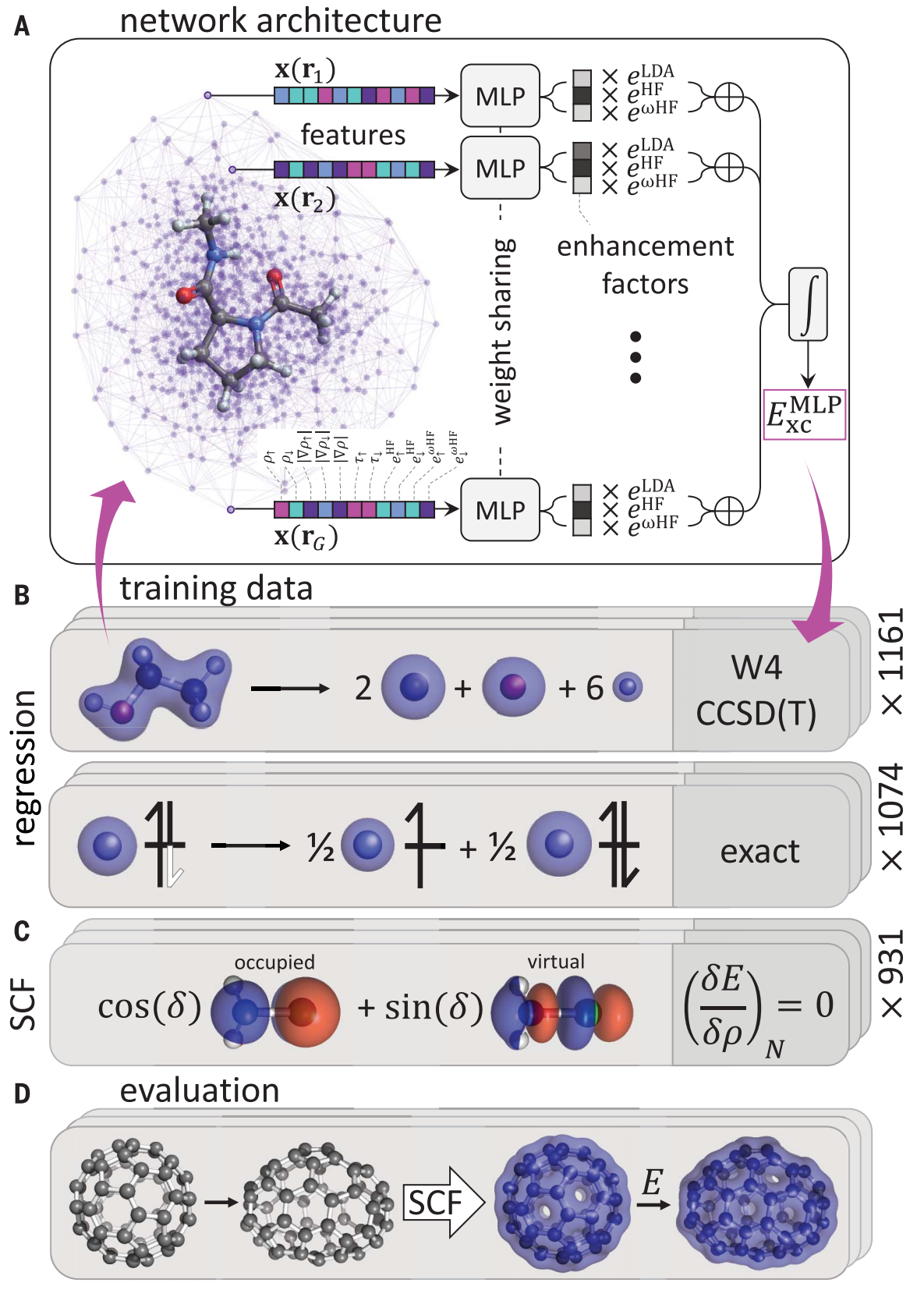
图1. 泛函架构与训练概述
(A) 由KS(科恩-沙姆)轨道计算得到的电子密度特征,在原子中心求积网格上采样。具体而言,输入特征包括:自旋索引电荷密度 ρ \rho ρ、其梯度的范数 ∣ ∇ ρ ∣ |\nabla\rho| ∣∇ρ∣、动能密度 τ \tau τ,以及(范围分离的)局域哈特里-福克交换能密度 e ω HF e^{\omega\text{HF}} eωHF与 e HF e^{\text{HF}} eHF。这些特征输入至共享的多层感知机( M L P MLP MLP),该MLP预测“局域密度近似”与“哈特里-福克贡献”对应的局域增强因子,用于局域交换关联能密度的计算;随后对全空间积分,再为泛函添加色散修正。
(B) 网络的训练数据包含:KS输入密度的数据集、分子的高精度能量标签,以及精确的数学约束。
© 固定电子数( N N N)时,所学泛函的梯度通过如下要求进行监督:提供的轨道是“总能量关于占据轨道与虚轨道幺正旋转”的驻点(以角度 δ \delta δ示例说明)。
(D) 训练完成后,该泛函可用于自洽计算。右侧数字表示 D M 21 DM21 DM21泛函的数据集规模(不含网格增强)。
6. TEMImageNet训练库与AtomSegNet深度学习模型:用于原子分辨图像的高精度原子分割、定位、降噪及超分辨率处理 Scientific Reports
代码:github
网站:temimagenet
摘要: 实现原子分辨扫描透射电子显微镜(STEM)图像的高精度、稳健性原子分割、定位、降噪与去模糊是一项具有挑战性的任务。尽管阈值处理、边缘检测、聚类等传统算法在部分预设场景中能取得尚可的性能,但当背景干扰强烈且不可预测时,这些算法往往会失效。尤其是对于原子分辨STEM图像,目前尚无成熟算法能在记录图像存在较大厚度变化时,稳健地分割或检测所有原子柱。
在此,我们报道了一个训练库与一种深度学习方法的开发:它们可对实验图像进行稳健且精确的原子分割、定位、降噪及超分辨率处理。尽管以模拟图像作为训练数据集,该深度学习模型仍能自适应实验STEM图像,在对比度条件复杂的场景中展现出优异的原子检测与定位性能,且其精度持续优于当前最先进的二维高斯拟合方法。
更进一步,我们已将该深度学习模型部署至带有图形用户界面的桌面应用中,且该应用是免费开源的。我们还搭建了TEM ImageNet项目网站,便于训练数据的浏览与下载。
1. 介绍
本文报道了一种基于深度学习的解决方案,用于原子分辨率扫描透射电子显微镜图像中原子柱的精确分割、定位、去噪与超分辨率处理。尽管已有多种传统算法,但在图像背景复杂、噪声强烈或样品厚度变化显著时,其性能往往不足。
近年来,深度卷积神经网络在计算机视觉领域取得显著成功,但其在STEM成像中的应用因缺乏大规模、高质量的标注训练数据集而受到限制。为此,我们开发了一个包含真实扫描噪声和泊松噪声的前向模型,用以生成大量类实验的ADF-STEM模拟图像,并据此构建了“TEM ImageNet”训练库。该库包含八种材料沿多个晶带轴的图像,并提供了十类真实标签,用于训练完成原子分割、检测、去噪等不同任务的模型。
基于此训练库,我们开发了编码器-解码器型深度学习模型。实验证明,该模型在对训练库未包含的晶体结构的实验图像进行处理时,在原子柱定位、分割等方面的性能优异,其定位精度甚至可超越当前最先进的二维高斯拟合方法。所有模型均已集成至开源桌面应用程序AtomSegNet中,供用户免费下载使用。
2. 方法
本节介绍训练数据集的生成方式,以及神经网络结构与训练策略。
训练数据集
采集带高精度真值标注的原子分辨ADF-STEM数据集耗时极长,因此我们通过正向模型生成不同原子结构、晶向的类实验ADF-STEM图像(真值原子位置预设),高效覆盖多种空间对称性、原子排布、噪声水平与随机背景,提升模型稳健性。
正向模型
采用简化的线性成像模型(通过材料投影原子势与电镜点扩散函数( P S F PSF PSF)的卷积模拟图像,忽略PSF的三维形状——仅降低对比度,对原子分辨图像影响微弱),公式如下:
I ( x , y ) = ∬ σ ( x ′ , y ′ ) ∣ Ψ ( x − x ′ , y − y ′ ) ∣ 2 d x ′ d y ′ = σ ⊗ PSF \begin{aligned} I(x,y) &= \iint \sigma(x',y') \left| \Psi(x-x',y-y') \right|^2 dx'dy' \\ &= \sigma \otimes \text{PSF} \end{aligned} I(x,y)=∬σ(x′,y′)∣Ψ(x−x′,y−y′)∣2dx′dy′=σ⊗PSF
PSF ( x , y ; d f ) = 4 π 2 k 2 ∣ ∬ H ( k ) exp [ − i x ( k ; d f ) − 2 π i k ⋅ r ] d 2 k ∣ \text{PSF}(x,y; df) = \frac{4\pi^2}{k^2} \left| \iint H(k) \exp\left[-ix(k; df) - 2\pi i \boldsymbol{k} \cdot \boldsymbol{r} \right] d^2\boldsymbol{k} \right| PSF(x,y;df)=k24π2
∬H(k)exp[−ix(k;df)−2πik⋅r]d2k
我们未采用布洛赫波、多层切片等量子模拟方法(线性模型计算成本远更低,数分钟可生成上万张256×256图像,更适合快速训练);虽多层切片更贴合散射物理,但线性模型足以预测原子柱的表观位置。我们还构建了两种数据集:线性模型模拟版与多层切片模拟版。
噪声模拟
正向模型同时模拟ADF-STEM的真实噪声:
-
泊松噪声:像素预期入射电子数为 n = t dwell × I / e n = t_{\text{dwell}} \times I / e n=tdwell×I/e,计数电子数服从泊松分布:
P ( n ) = e − n n k / k ! P(n) = e^{-n} n^k / k! P(n)=e−nnk/k!(光电倍增管量子效率高,忽略额外噪声传播) -
扫描噪声:电磁干扰导致光束偏离扫描位置,定义偏差向量 δ i , j = ( δ x i , j , δ y i , j ) \boldsymbol{\delta}_{i,j} = (\delta_x^{i,j}, \delta_y^{i,j}) δi,j=(δxi,j,δyi,j)( i i i为行、 j j j为列),假设水平行内偏差不变( δ i , j = δ i \boldsymbol{\delta}^{i,j} = \boldsymbol{\delta}^i δi,j=δi),偏差服从“正态分布+周期线频调制”:
δ i , x = f ( ∣ Normal ( μ = 0 , σ = 1 ) ∣ ) × σ jitter sin ( 2 π f t ) δ i , y = f ( ∣ Normal ( μ = 0 , σ = 1 ) ∣ ) × σ jitter sin ( 2 π f t + ϕ 0 ) \begin{aligned} \delta_{i,x} &= f(| \text{Normal}(\mu=0, \sigma=1) |) \times \sigma_{\text{jitter}} \sin(2\pi f t) \\ \delta_{i,y} &= f(| \text{Normal}(\mu=0, \sigma=1) |) \times \sigma_{\text{jitter}} \sin(2\pi f t + \phi_0) \end{aligned} δi,xδi,y=f(∣Normal(μ=0,σ=1)∣)×σjittersin(2πft)=f(∣Normal(μ=0,σ=1)∣)×σjittersin(2πft+ϕ0)
最终图像为理想图像 I 0 I_0 I0的变换:
I ( i , j ) = I 0 ( i − δ x i , j , j − δ y i , j ) I(i,j) = I_0\left(i - \delta_{x}^{i,j}, j - \delta_{y}^{i,j}\right) I(i,j)=I0(i−δxi,j,j−δyi,j)
要不要我帮你整理一份本方法核心模块的技术要点清单?
 图1. 合成图像:(a) 由简易线性成像正向模型生成的图像;(b) 含合成散粒噪声的图像;© 含扫描噪声的图像。
图1. 合成图像:(a) 由简易线性成像正向模型生成的图像;(b) 含合成散粒噪声的图像;© 含扫描噪声的图像。
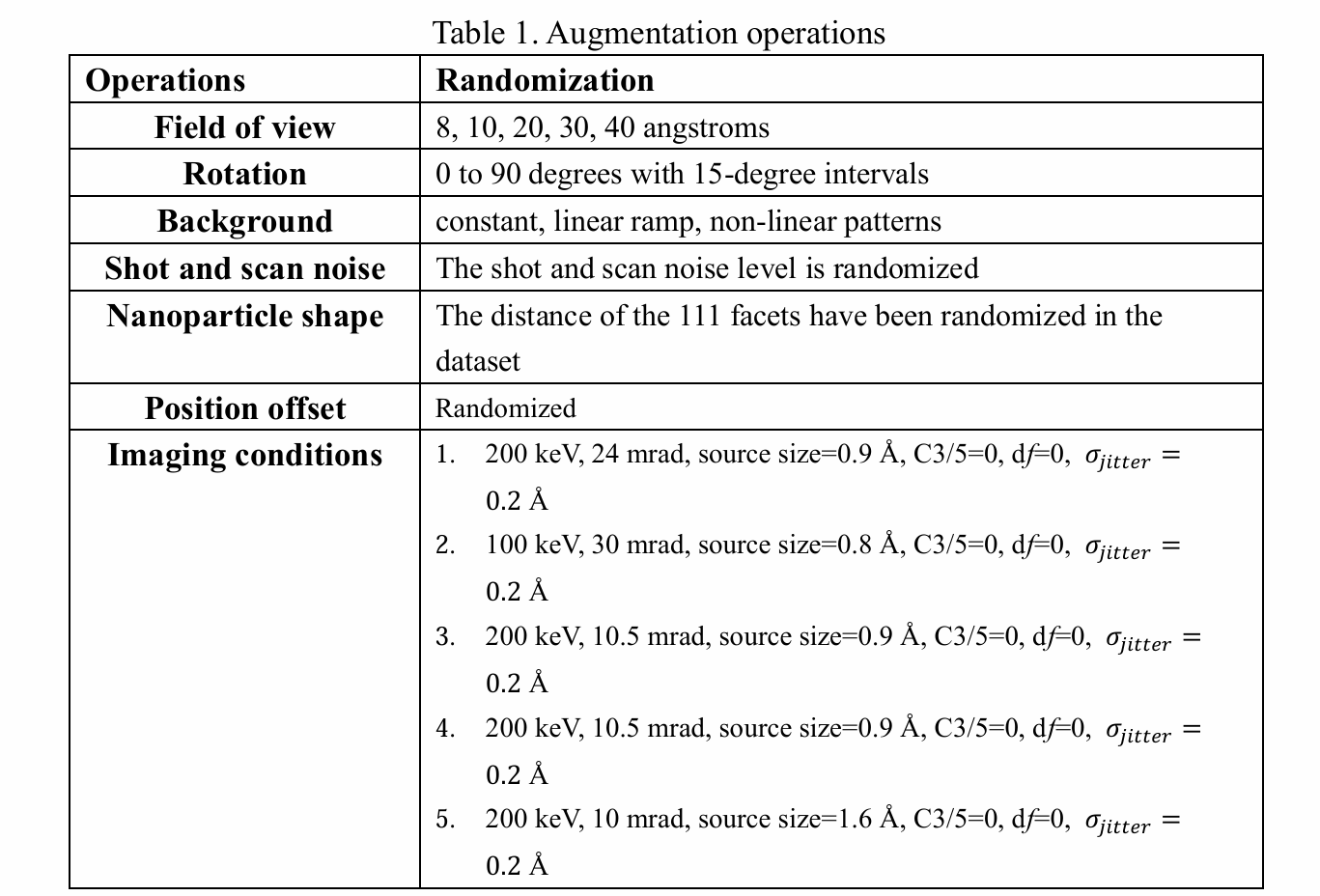
库的构成与增强
为构建涵盖多样空间对称性、原子柱对比度及厚度效应的训练库,我们纳入了以下材料体相结构的多取向图像:Pt [001]、Pt [110]、NiO [001]、NiO [110]、SrTiO₃ [001]与[110]、DyScO₃ [110]、Si [110]、石墨烯、无定形石墨烯、单层MoS₂、金红石TiO₂ [001]、[100]与[110]、LiCoO₂ [010]。我们还加入了带刻面的Pt纳米晶图像,以提升在纳米颗粒及界面的边界、边缘处识别原子的稳健性。
为实现稳健的尺度与边缘训练,我们在训练图像模拟中纳入了表1所列的随机化操作,部分示例图像见图2。

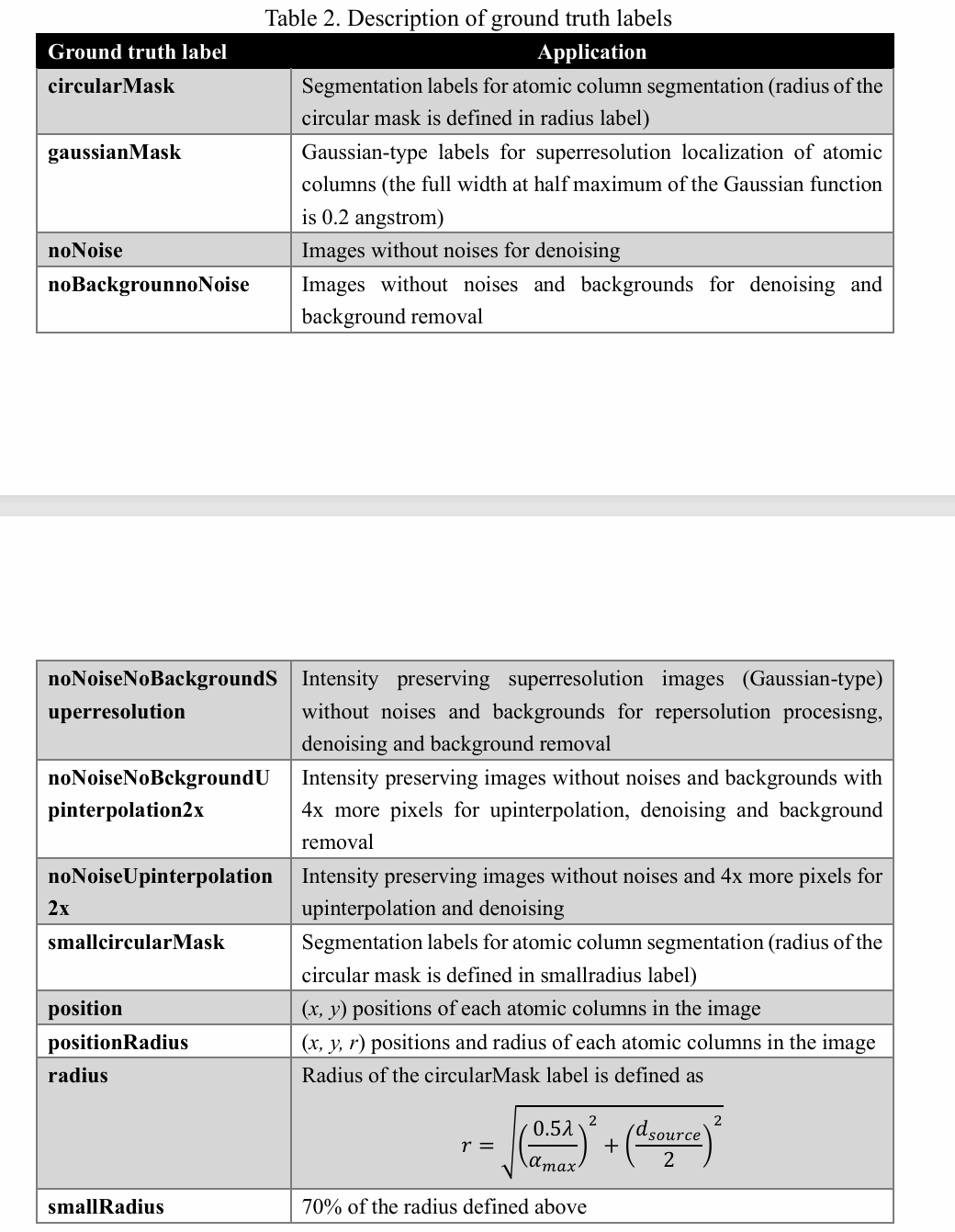
真值标签
我们训练模型实现了原子分割、原子柱高斯映射、保强度超分辨率(去模糊)处理、降噪及背景去除功能,其对应的真值标签详见图3与表2。圆形掩模的宽度由点扩散函数的半高全宽定义,而高斯掩模的宽度为0.2埃。

(a) 合成图像,以及对应功能的真值标签:(b) 保强度超分辨率(去模糊)处理、© 原子柱高斯映射、(d) 降噪、(e) 降噪+背景去除、(f) 原子柱分割。
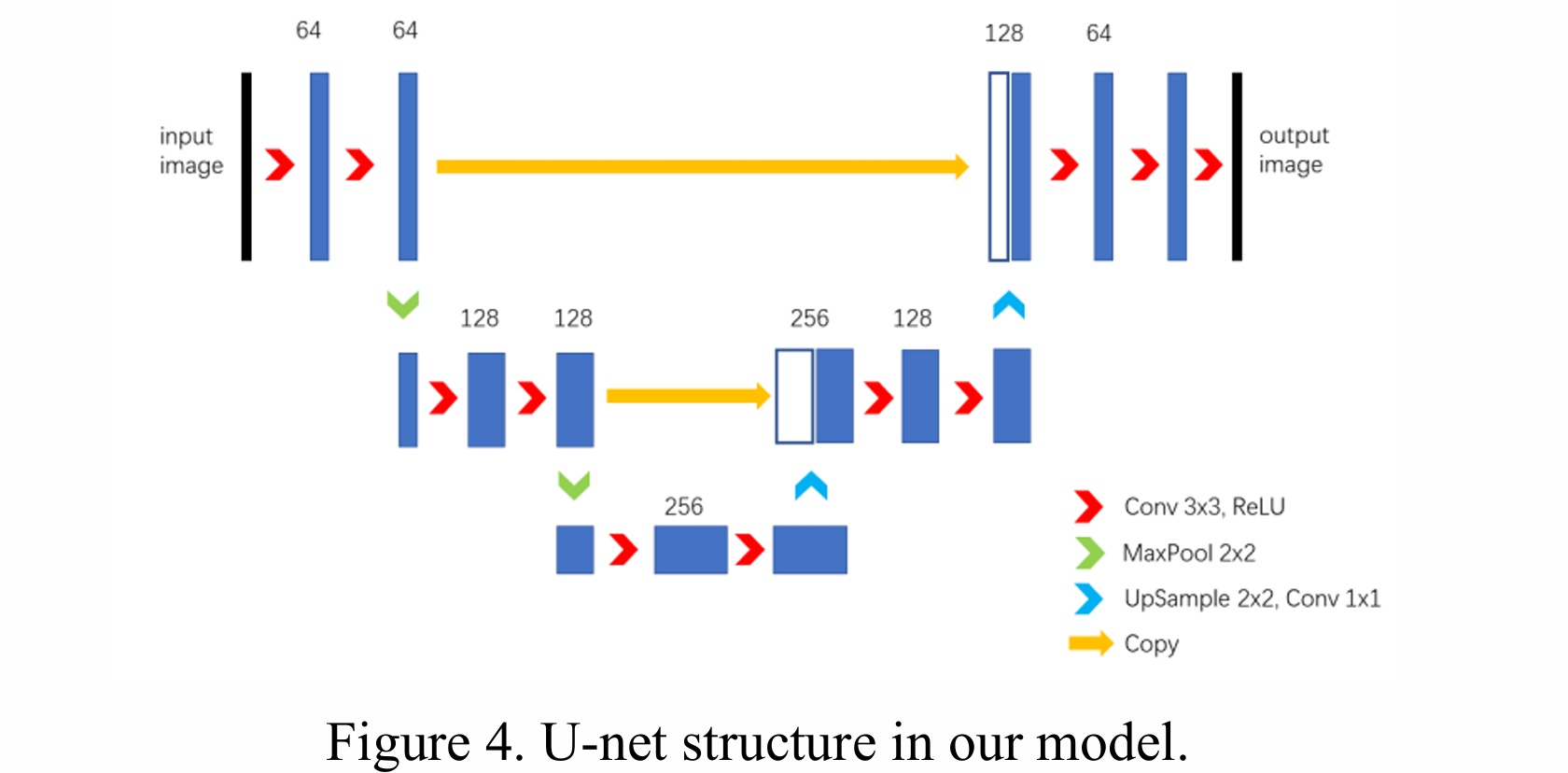
网络结构
针对原子柱分割、超分辨率/去模糊处理,我们采用了U-net架构的编解码型CNN网络——U-net可在训练图像极少的情况下工作,且能精准完成细胞追踪类任务的分割²⁸。其核心优势是将编码层直接输出的高分辨率特征通道,与解码层拼接,从而保留高分辨率上下文信息。
在我们的模型中:
- 收缩路径(图4左侧):重复执行“两次3×3卷积 + ReLU激活 + 步长为2的2×2最大池化下采样”;
- 扩张路径(图4右侧):包含“上卷积 + 拼接收缩路径对应的特征图 + 两次3×3卷积 + ReLU激活”。
损失函数与训练策略
测试训练中发现,均方误差(MSE)损失会提升假阳性率(因真值标签仅覆盖图像极小区域),因此我们采用改进的卡方函数:
χ mod 2 = ∑ i , j ( I i , j − I i , j ground truth ) 2 I i , j ground truth + max ( I ground truth ) / 10 \chi^2_{\text{mod}} = \sum_{i,j} \frac{\left(I_{i,j} - I_{i,j}^{\text{ground truth}}\right)^2}{I_{i,j}^{\text{ground truth}} + \max(I^{\text{ground truth}})/10} χmod2=i,j∑Ii,jground truth+max(Iground truth)/10(Ii,j−Ii,jground truth)2
该损失函数可惩罚背景区域的假原子。
数据集随机拆分为训练集(75%)与测试集;训练200轮后,平均训练损失为0.0174,平均测试误差为0.0195,批次大小设为4。
原子定位
采用**大津法(Otsu)**对模型输出的特征图进行二值化²⁹,将二值化后的每个独立区域视为原子柱,通过计算区域的几何中心确定原子柱位置。当模型基于“圆形标记”“高斯掩模”真值标签训练时,结合大津法的定位效果最优。
基准方法
我们通过迁移学习定制预训练的Faster R-CNN网络³⁰,用于直接原子检测;同时实现了二维高斯拟合(该方法是透射电子显微镜(TEM)领域原子柱定位的“黄金方法”)³¹。以上两种方法均作为基准,用于对比上述大津法原子定位器的精度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)