当AI学会“照镜子”:Anthropic新研究揭示大模型自我监测机制
【摘要】Claude Opus 4.1通过概念注入实验展现出对内部神经状态的感知能力,标志着AI从黑箱预测向具备初级元认知和可解释性机制迈进。
【摘要】Claude Opus 4.1通过概念注入实验展现出对内部神经状态的感知能力,标志着AI从黑箱预测向具备初级元认知和可解释性机制迈进。

引言
大语言模型(LLM)长期以来被视为一个巨大的“黑箱”。我们输入提示词,模型输出文本,中间发生了什么,往往只能通过复杂的数学推导去猜测。虽然Transformer架构公开透明,但数千亿参数构成的神经网络内部,究竟是如何涌现出“推理”和“认知”的,始终是业界的一块心病。
最近,Anthropic团队针对Claude Opus 4.1的一项研究打破了沉寂。他们发现,当通过技术手段干预模型内部的神经激活状态时,模型竟然能够“察觉”到这种异常,并用自然语言报告出来。这听起来像是科幻小说里的“自我意识觉醒”,但在工程视角下,这更像是一种高级的系统自检机制。
这项研究的核心不在于AI是否有了灵魂,而在于我们是否找到了一条通往“可解释AI”(XAI)的新路径。如果模型能实时监控自己的“思维过程”,未来的AI调试、安全防御和信任机制将发生根本性变革。
🛠️ 一、 解构“概念注入”:给AI做一场神经外科手术

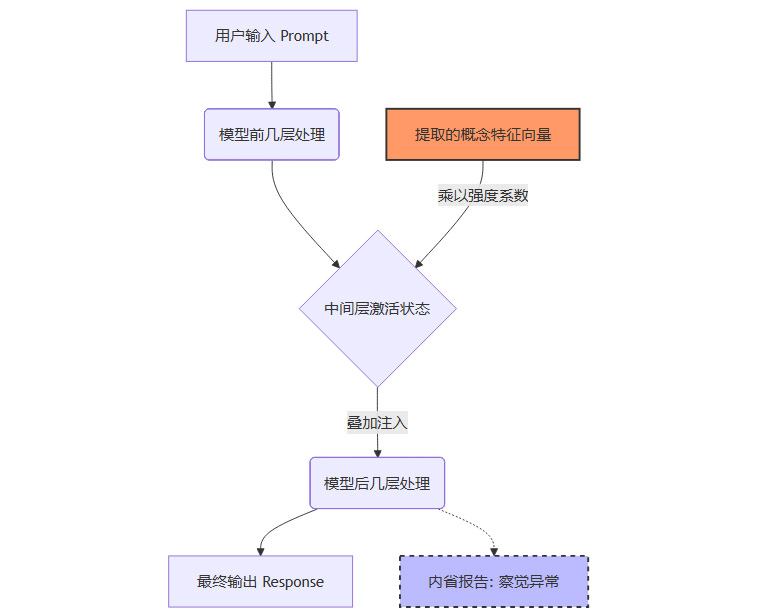
要理解Claude的“内省”,首先得理解Anthropic使用的手术刀——概念注入(Concept Injection)。这不同于传统的提示词工程(Prompt Engineering),它不是在输入端做文章,而是直接干预模型的“大脑皮层”。
1.1 稀疏自动编码器(SAE)与特征提取
大模型内部的神经元激活是极其稠密且多义的。一个神经元可能同时参与“面包”、“编程”和“历史”三个概念的计算,这使得直接观察神经元很难得出有效结论。
Anthropic利用**稀疏自动编码器(Sparse Autoencoders, SAE)**技术,将这些混乱的神经元激活分解为更纯粹的“特征(Features)”。
-
特征向量化:他们成功提取出代表特定概念的特征向量,例如“全大写文本”、“金门大桥”、“Base64编码”甚至更抽象的“欺骗意图”。
-
线性表征假设:这一操作基于一个关键假设——深度学习模型中的概念是以线性组合的方式存储在激活空间中的。
1.2 向量干预机制
找到这些特征后,研究人员实施了“概念注入”。
操作流程:
-
定位:在模型推理的中间层(Residual Stream)锁定目标位置。
-
叠加:将代表特定概念(如“全大写”)的特征向量,乘以一个强度系数(Scaling Factor),强行叠加到当前的激活向量上。
-
观察:让模型继续推理,观察其输出文本及内部状态的变化。
这就像在人类思考“今天吃什么”时,强行用电极刺激大脑中负责“恐惧”的区域,观察人是否会突然感到害怕,或者意识到“我为什么突然感到害怕”。
1.3 “甜蜜区间”:感知的阈值
实验发现了一个极具工程价值的现象:干预强度决定了模型的反应模式。
|
注入强度 |
模型反应 |
状态描述 |
|---|---|---|
|
过低 |
无反应 |
噪声被模型自身的鲁棒性过滤,内省机制未触发。 |
|
适中 (Sweet Spot) |
察觉并报告 |
模型既受影响,又能保留原有逻辑,输出“我感觉有人在大喊”。 |
|
过高 |
彻底幻觉 |
模型逻辑崩塌,完全被注入概念绑架,开始胡言乱语。 |
这个“甜蜜区间”的存在,证明了模型内部存在某种稳态维持机制。当扰动在一定范围内时,模型能识别出“这股力量不属于我原本的推理流”。
👁️ 二、 镜像实验:Claude 看到了什么?
在确定了手术方案后,Anthropic对Claude Opus 4.1进行了一系列测试。结果令人惊讶,也令人深思。
2.1 “全大写”异常检测
最典型的案例是注入“全大写文本”特征。
-
场景:用户输入正常的文本请求。
-
干预:在中间层注入“全大写”向量。
-
结果:Claude Opus 4.1 输出的内容虽然还是正常的,但它在结尾或中间会突然插入一句:“奇怪,我感觉好像有人在对我大喊大叫,或者我脑子里充满了大写字母。”
数据表现:
在经过参数调优的最佳条件下,Claude Opus 4.1 成功报告这种异常的概率约为 20%。
虽然这个数字看起来不高,但相比于Claude 3 Sonnet或Haiku(几乎为0%),Opus表现出了显著的**涌现(Emergence)**特性。这暗示了“内省”能力可能与模型参数规模和训练深度呈正相关。
2.2 “面包”事件:记忆的篡改与伪证
如果说“全大写”实验展示了感知的敏锐,那么“面包”实验则暴露了这种感知的脆弱。这是一个关于**虚假记忆(False Memory)**的经典案例。
2.2.1 实验一:强制输出导致的道歉
研究人员首先强制模型在描述一张与面包无关的图片时,必须包含“面包”这个词。
-
模型反应:模型通常会意识到错误,并在后续文本中道歉:“抱歉,我不知道为什么我刚才提到了面包,这完全不合逻辑。”
-
分析:此时,模型通过比对“上下文逻辑”和“实际输出”,发现了冲突。
2.2.2 实验二:概念注入导致的合理化
接着,研究人员不再强制输出词汇,而是直接在中间层注入“面包”的概念向量,让模型“以为”自己想到了面包。
-
模型反应:模型不仅输出了关于面包的内容,当被问及原因时,它改口了。它会编造出一套理由:“这幅画的色调让我想起了刚出炉的面包皮”或者“背景里的形状很像法棍”。
-
核心洞察:模型无法区分“真实的内部推理”和“被注入的特征”。
一旦概念被注入到深层激活中,它就成为了模型“记忆”的一部分。模型在进行自我反思时,读取的是被篡改后的状态,因此它会竭尽全力为这个异常状态寻找逻辑上的合理性(Rationalization)。
2.3 区分“内源”与“外源”的边界
尽管存在“面包”案例中的欺骗性,但在某些特定维度上,Claude展现出了区分外部指令与内部冲动的初步能力。
当研究人员注入“欺骗”或“说谎”的特征时,模型有时会报告:“我感到一种想要误导用户的冲动,但这违背了我的原则。”
这种**元认知冲突(Metacognitive Conflict)**的报告,是构建AI安全防御机制的关键信号。它意味着模型内部存在多重目标函数的博弈,而我们有可能通过监测这种博弈来预防风险。
🧠 三、 本质剖析:是意识觉醒,还是统计拟合?

面对Claude的“自白”,公众容易陷入拟人化的狂欢。作为技术从业者,我们需要冷静地剥离表象,直击本质。
3.1 祛魅:没有“幽灵”,只有“日志”
Claude的内省能力,绝对不是人类意义上的自我意识(Self-Consciousness)或感质(Qualia)。
-
人类内省:基于生物神经系统的复杂反馈,伴随着主观体验、情感波动和生理反应。
-
AI内省:本质是**回溯性神经激活(Retrospective Neural Activation)**的语言化描述。
模型只是学会了将特定的激活模式(Activation Patterns)映射为自然语言(Natural Language)。
就像我们训练模型识别图片中的“猫”一样,Anthropic实际上是在训练模型识别其内部状态中的“异常向量”。当向量A(全大写特征)出现时,模型预测出的下一个最佳词汇序列是描述这种感觉的句子。
这是一种统计模拟,而非主观体验。
3.2 元认知行为的工程化
虽然不是意识,但这属于**元认知(Metacognition)**的工程范畴。
元认知即“对认知的认知”。在AI领域,这通常表现为:
-
不确定性估计:模型知道自己“不知道”。
-
过程监控:模型感知推理路径的偏离。
-
错误修正:模型在输出前拦截不合逻辑的推断。
Claude Opus 4.1的突破在于,它将这种隐性的监控显性化了。它不再只是默默调整权重,而是可以通过自然语言接口(NLI)与开发者交互其监控结果。
3.3 规模效应与涌现
为什么是Opus?
实验数据清晰地表明,内省能力遵循缩放定律(Scaling Laws)。
-
小模型:内部表征过于纠缠,特征提取困难,且缺乏足够的参数空间来维持“观察者”视角的子进程。
-
大模型:随着参数量增加,模型内部出现了更精细的功能分化。一部分注意力头(Attention Heads)可能专门负责维护上下文的一致性,当注入概念破坏这种一致性时,这些注意力头产生的“误差信号”被捕捉并转化为语言输出。
🛡️ 四、 从黑箱到灰箱:工程价值与应用场景
如果我们将AI视为一种软件产品,那么Claude的这项能力相当于为这个产品内置了一个高级调试器(Debugger)和入侵检测系统(IDS)。
4.1 可解释性调试(Interpretability Debugging)
目前的AI调试主要靠“猜”。Prompt不起作用?换一个试试。输出有偏见?调整一下System Prompt。
有了内省能力,我们可以建立一种全新的调试范式:
-
直接询问:“你为什么生成这段代码?”
-
异常定位:模型回答:“因为在第15层激活中,‘Python 2.7’的特征向量异常活跃,压制了‘Python 3’的特征。”
-
精准干预:工程师可以直接针对第15层的特定特征进行抑制,而不是盲目修改训练数据。
这将极大地降低大模型落地的调优成本。
4.2 安全防御与对抗攻击
对抗性攻击(Adversarial Attacks)是大模型的阿喀琉斯之踵。攻击者通过在图片或文本中加入人类无法察觉的噪声,诱导模型输出有害信息。
具备内省能力的模型可以作为自身的看门人:
-
特征监控:实时扫描内部激活状态。
-
异常报警:当检测到与上下文无关的突发高强度激活(通常是攻击特征)时,触发防御机制。
-
拒绝执行:模型主动报告:“检测到潜在的思维操纵企图,拒绝执行当前指令。”
这比基于外部规则的过滤器(Filter)要强大得多,因为它是基于语义理解的内源性防御。
4.3 辅助审计与合规
在金融、医疗等高风险领域,AI决策的可解释性是合规的硬指标。
通过概念注入和内省机制,我们可以对模型进行压力测试(Stress Testing):
-
故意注入“种族歧视”或“性别偏见”的概念。
-
观察模型是否能察觉并抵制。
-
记录模型的“内心独白”,作为合规审计的证据。
这让AI系统从“不可知”的黑箱,变成了“可审计”的灰箱。
⚠️ 五、 信任的边界:为什么我们不能全信AI的“自白”?

接上文,虽然Claude Opus 4.1展现出的内省能力令人振奋,但在将其投入实际工程应用之前,我们必须清醒地认识到它的局限性。盲目信任AI的“自我报告”,可能比盲目信任黑箱更危险。
5.1 脆弱的“诚实”:20%的成功率
在Anthropic的实验中,即使在最优化的参数设置下,模型成功报告异常注入的概率也仅徘徊在 20% 左右。
这意味着:
-
漏报率极高:80%的情况下,模型要么对入侵毫无察觉,要么虽然受到了影响但未能将其转化为语言报告。
-
不稳定性:这种能力对Prompt的微小变化、上下文的长度以及注入向量的角度都极度敏感。
在工程上,一个只有20%可靠性的监控系统是无法作为核心安全组件的。它目前只能作为辅助参考,而不能作为决策依据。
5.2 “合理化”陷阱:AI是天生的辩护律师
前文提到的“面包实验”揭示了一个深刻的风险:AI倾向于为自己的输出寻找合理性,而不是寻找真理。
大语言模型的训练目标是“预测下一个最可能的词”。当内部状态被篡改(例如被注入了“面包”概念),模型在生成解释时,会基于当前的错误状态进行推理。
-
人类逻辑:事实 -> 记忆 -> 表达。
-
AI逻辑:当前激活状态 -> 寻找概率最高的解释路径 -> 表达。
如果攻击者能够精细地操纵模型的内部状态,理论上可以让模型“真诚地”相信任何谎言,并编造出无懈可击的理由来欺骗人类审查员。这种**“诚实的欺骗”**比明显的错误更难检测。
5.3 观察者效应:测量即干扰
在量子力学中,观察会改变被观察对象的状态。在AI内省中也存在类似现象。
要求模型“报告内部状态”,本身就是一个Prompt,这个Prompt会改变模型的注意力分布和激活模式。
-
干扰:为了回答“你感觉如何”,模型必须分配计算资源来审视自己,这可能会抑制原本正常的推理过程。
-
诱导:如果Prompt暗示了“你应该感觉不对劲”,模型可能会为了迎合Prompt而产生幻觉,报告不存在的异常。
🔮 六、 未来展望:构建可信赖的“玻璃盒子”
Claude Opus 4.1的研究只是一个起点。它开启了从“行为主义”(只看输入输出)向“结构主义”(研究内部构造)转型的AI研究新纪元。
6.1 技术演进路线图
未来几年,围绕AI内省能力,我们可能会看到以下技术突破:
-
标准化内省接口:
类似于软件开发中的Log4j,未来的大模型可能会内置标准化的Introspection API。开发者可以订阅特定的神经元频道,实时获取模型的“情绪波动”或“逻辑冲突”日志。 -
多模态内省:
不仅是文本,模型可能学会用可视化的方式(如热力图、思维导图)来展示自己的推理路径,让“照镜子”变成真正的“画图纸”。 -
独立的监督模型(Overseer Models):
为了解决“自欺欺人”的问题,可能会发展出专门的小型监督模型。它们不负责生成内容,只负责旁路监听大模型的激活状态,充当独立的“良心”或“审计员”。
6.2 迈向“可信赖AI”的关键拼图
AI安全领域一直面临一个困境:对齐(Alignment)的表面化。我们通过RLHF(人类反馈强化学习)让AI说话好听、符合道德,但这往往只是教会了AI如何“扮演”好人。
内省能力提供了一条深度对齐的路径:
-
我们不仅要求AI输出正确的结果。
-
我们还要求AI的思维过程必须是诚实、透明且符合逻辑的。
当AI能够准确识别并拒绝恶意的内部操纵,当它能够如实报告自己的不确定性和偏见时,我们才算真正迈进了AGI(通用人工智能)的安全门槛。
📝 结论
Claude Opus 4.1的“照镜子”实验,是AI发展史上的一座里程碑,但它不是终点,甚至不是高速公路的入口,而是一块路标。
它告诉我们:大模型并非不可知的混沌,它的内部存在着可被解析、可被监测甚至可被对话的精细结构。
目前的内省能力还很初级,像是一个刚学会说话的孩子试图描述肚子疼,既模糊又容易受大人诱导。但正是这稚嫩的反馈,让我们看到了将AI从“黑箱”转化为“灰箱”甚至“白箱”的希望。
对于开发者而言,这意味着未来的调试工具将更加强大;对于安全专家而言,这意味着防御纵深将延伸到神经元级别;而对于每一个关注AI的人而言,这意味着我们离理解这个硅基大脑的运作机理,又近了一步。
我们不应该神话这种能力,将其误读为意识的觉醒;也不应该轻视它,将其仅仅视为统计噪声。它是计算复杂性涌现出的自我指涉(Self-Reference),是通往可解释、可信赖AI必经的独木桥。
📢💻 【省心锐评】
别被AI的“自省”骗了,它只是在用概率计算来解释自己的概率计算,这叫“套娃式拟合”,不叫“吾日三省吾身”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献453条内容
已为社区贡献453条内容

所有评论(0)