《Attention Is All You Need》精读(欢迎纠错)
《Attention Is All You Need》提出了一种基于自注意力机制的Transformer架构,完全取代了传统的循环和卷积结构。该模型通过多头注意力机制实现了跨距离的上下文联系,提高了并行计算效率。关键创新包括:1)自注意力机制计算输入序列内部关联;2)多头注意力从不同维度提取信息;3)位置编码处理序列顺序。实验表明该架构性能超越当时SOTA模型,并启发了CV、语音等领域的应用。文章
一、基本信息区
|
项目 |
内容 |
|
论文标题 |
Attention Is All You Need |
|
关键词 |
自注意力机制,多头注意力机制,transformer |
二、研究概览
1. 核心贡献
第一次将整个编码解码器架构使用注意力机制完全重构,是全新的架构思路。
文章使用多头注意力机制,规避了卷积循环等方法的相关弊端,不仅可以跨距离联系上下文,同时并行性提高,加速了训练过程。同时自注意力机制使得模型能够在相同计算复杂度中,学习不同维度的信息,提高了模型性能,
三、技术细节
1. 模型架构
(1)整体框架
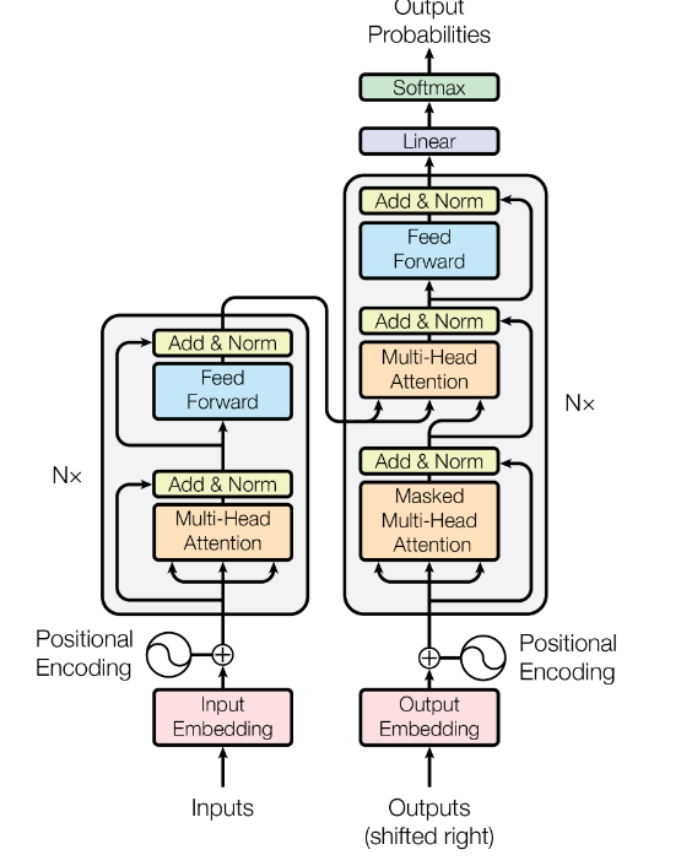
输入层→ 编码层→ 解码层→输出层
(2)核心模块
- 输入层:对输入进行编码,同时使用位置编码记录输入的顺序。输入编码同样采用独热码以及训练得到的词嵌入矩阵计算得到,位置编码使用固定编码,是固定数学公式生成的。
- 编码层:将输入层的编码同时作为注意力模块的K,V,Q输入,基础模型采用6个attention模块和前馈层堆叠。并将最后的的输出作为解码器注意力模块的K,V输入。
- 解码器:结构与编码层相似,只在前面加入了带掩码的注意力层,将目标词嵌入的输出作为输入,同时将此时刻后的输入赋值为极大负数经过层归一化后变为零。将经过掩码处理后的输出作为解码器的Q输入,K,V相同,来自于编码器的输出。
- 输出层:解码器输出经过线性层再接softmax归一化计算所有目标词的概率分布进行输出。
(2)关键点
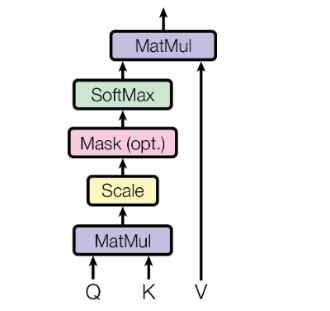
- 自注意力模块
注意力模块本质可训练的权重参数极少,仅仅只是将Q与转置后的K计算点积,再除以向量维度d的平方根,经过softmax层得到相关权重与V相乘得到所有包含上下文的相关程度的新向量。
除以d的平方根是为了缩小点积计算出来的数值,以便经过softmax后得到的权重更加普遍,而不是任意一个较大的数计算后都偏向1,这样不利于梯度计算。
自注意力机制同样是这个计算逻辑,只是Q,K,V向量全部是一个向量,那就是经过输入层处理后的词编码复制三份得到的,这样加权得到的新矩阵就包含所有向量和其他所有向量的相关程度。
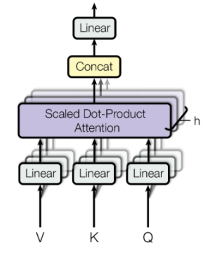
- 多头注意力机制
虽然经过注意力机制的计算能得到包含上下文信息的所有向量,但由于单头包含的信息是有限的,因此采用了多头注意力机制弥补有效分辨率下降的问题。
本质来说就是将512维的向量进行多次降维投影,投影规则由训练得到。这样模型就有机会在不同维度从不同的角度进行训练学习。最终再投影升维至512维,升维规则也由训练得到。
可以说注意力模块的可训练参数基本聚集在多头注意力机制的升维降维规则中。
- 前馈层
使用ReLU函数进行非线性处理,主要是为了模拟现实任务的非线性处理过程(例如翻译中由5个英文词汇转为3个中文字),模型大部分参数基本保存在全连接的前馈层中,这里可能也是模型存储知识的地方,
四、实验分析
3. 结果分析
(1)核心性能对比
性能基本追平甚至超越当时水平的SOTA。
(2)关键图表说明
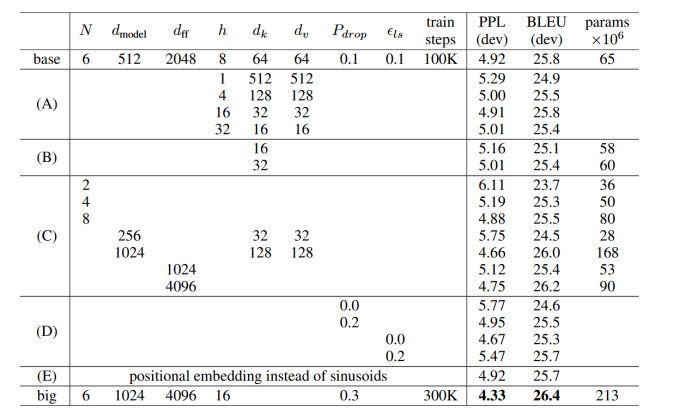
表中都是基础模型修改部分参数训练得到的,A中只更改了多头的头数,可得多头注意力机制不可少也不可多,不然性能都会受损;B中只更改了K向量的维度(投影降到更低的维度,但是保持头数不变),结合A说明计算Q,K是很重要的操作,可能需要更加复杂的计算方式;C说明模型越大性能越好(目前大模型越做越大的万恶之源);
D说明dropout必不可少;E中使用可训练的位置编码,但是效果差不多。
五、创新点与贡献
1. 核心创新
- 将注意力机制完全应用到解码器和编码器中,大幅提高了模型的并行程度。
- 自注意力机制打破以往卷积循环的弊端,实现了跨距离的上下文联系。
- 多头注意力机制提出弥补了单一维度的注意力机制提取信息不足的问题。
六、批判性思考
1. 优点分析
Transformers架构是深度学习的一大突破,不仅实现了任意距离的上下文联系,并行性大大提高,还启发了其他领域,如图片,音频,视频等。
同时多头注意力机制在不同维度表现为各个方向的建模结果,提高了模型的可解释性。
- 未来展望
文中提到非文本模态如图片,音频,视频的应用,目前均已实现,如ViT、Whisper 等,还提到局部注意力,但是由于目前计算能力的提高,局部注意力反而关注度下下降。同时文章还提到想要改模型顺序输出的限制,目前也部分实现,如 NAT、FastFormers。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)