大模型驱动的Agent技术框架:解锁金融、健康、客户服务领域的AI革命!大模型应用开发
大语言模型(LLM)作为智能体的核心引擎之一,为智能体的构建带来了新的范式。传统的智能体系统依赖于预定义规则与有限的推理能力,而LLM的引入让智能体具备了自然语言理解、知识推理以及上下文管理的能力,拓展了智能体的适用场景。在金融、健康管理、客户服务等领域,基于大模型的Agent技术框架展现出高效且灵活的表现。通过API和向量数据库的无缝集成,智能体能够动态获取数据,并在复杂任务中进行多步骤推理与动
大语言模型(LLM)作为智能体的核心引擎之一,为智能体的构建带来了新的范式。传统的智能体系统依赖于预定义规则与有限的推理能力,而LLM的引入让智能体具备了自然语言理解、知识推理以及上下文管理的能力,拓展了智能体的适用场景。在金融、健康管理、客户服务等领域,基于大模型的Agent技术框架展现出高效且灵活的表现。通过API和向量数据库的无缝集成,智能体能够动态获取数据,并在复杂任务中进行多步骤推理与动态响应。同时,ReAct、Hugging Face和LangChain等常见框架的应用,不仅降低了开发门槛,还推动了智能体从简单的语言交互向自主化、多任务处理的系统化转型。
本文从智能体结构、上下文管理、任务调度到技术栈的选用与集成,全面剖析如何在大模型的基础上设计高效的智能体系统。
一、大语言模型(LLM)在智能体中的核心作用
本节将通过分析LLM的具体能力,探讨其在智能体中如何实现自然语言理解、知识推理、动态更新以及多语言支持。
1.1 LLM的自然语言理解与生成能力
LLM展现了在自然语言理解和自然语言生成方面的非凡能力。通过数以亿计的文本数据训练,这些模型能够捕捉上下文语境,解析复杂句子结构,并提供连贯且准确的语言输出。如图1所示,Agent和LLM架构图展示了二者的分工与交互关系,这一能力使得LLM成为构建自然语言交互类智能体的重要基础,广泛应用于智能客服、虚拟助手、智能问答等领域。
自然语言理解关键在于模型如何将人类语言转换为计算机可以理解的语义结构。例如,当用户输入一句“我感到很疲惫,需要一些放松的建议”时,LLM能准确识别出其中的情感状态,并提取“疲惫”和“放松的建议”这两个核心需求。接下来,模型根据上下文判断,可以生成诸如“试试深呼吸和轻松的音乐”之类的回复。这表明模型不仅能理解词汇的表面含义,还能根据隐含的情感和语义提供个性化的建议。
自然语言生成能力使得LLM能够根据输入内容生成自然、流畅的文本。这种生成不局限于简单的句子,而是可以生成长段文字,如邮件、报告甚至创意文案。在对话系统中,LLM能基于多轮对话的上下文生成逻辑严谨的回答。例如,在客户支持系统中,当客户连续问及多个相关问题时,模型能够保持上下文的一致性并生成连贯的答复,而不丢失先前的关键信息。
为了确保生成内容的多样性和准确性,LLM会通过注意力机制(Attention Mechanism)定位用户输入中的关键信息,并在生成过程中不断调整输出的语言风格和逻辑。这些技术让LLM在各类任务中都表现出色,从简化邮件回复到生成复杂的客户报告都能胜任。
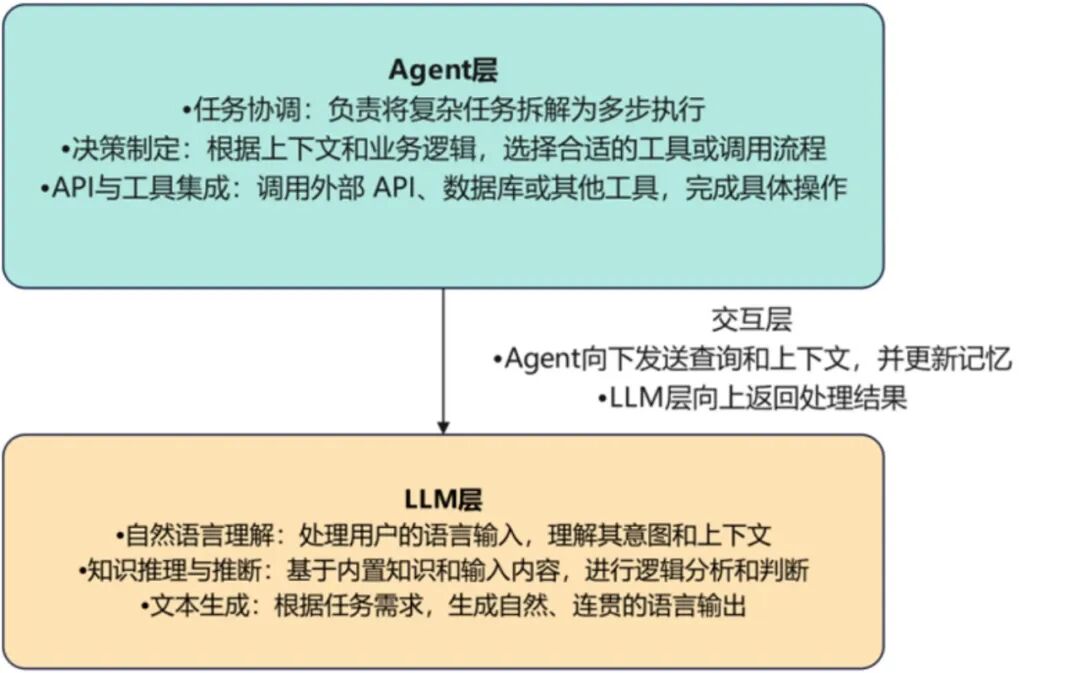
图1 LLM与Agent的分工、交互架构图
1.2 LLM赋能智能体的知识推理能力
知识推理是智能体实现复杂任务不可或缺的能力。LLM通过预训练和微调积累了海量的知识,并能在对话中进行隐式推理,这种能力让模型不仅能准确回答问题,还能通过现有信息推断出隐含的答案。
例如,对于一个虚拟健康助手,当用户告知“最近几天一直头疼,并且睡眠不好”时,模型不仅能识别出健康问题,还能推断出可能的原因(如焦虑或疲劳)。基于这些推断,智能体可以进一步提供建议,如“建议尝试冥想放松,或调整作息时间”。这种推理能力超越了简单的问答,并且体现了模型对复杂问题的深入理解与逻辑分析。
LLM还支持知识迁移。即使模型在初次训练时没有直接接触过特定领域的内容,通过微调也能够将已有的知识迁移到新的场景中,在客户服务系统中,智能体可以利用基本的客服知识,加上针对企业产品的微调模型,为客户提供准确的技术支持。这样的迁移能力大大提升了模型的实用性,使其能够适应不同领域的需求。
推理能力还体现在模型对模糊问题的处理上,当用户在金融助手中询问“如何实现稳健的理财?”时,这并非一个明确的计算问题,而是需要模型从多个角度进行分析。LLM可以根据用户的年龄、收入水平和市场动态生成个性化的理财建议,并根据用户的追问不断优化和细化方案。
1.3 持续学习与动态更新的智能体构建
智能体要在动态环境中始终保持高效的响应和决策能力,就必须具备持续学习与动态更新的能力。大语言模型为此提供了多种技术支持,使智能体能通过反馈与新数据不断优化自身的表现。
微调(Fine-tuning)是实现持续学习的重要方式。通过引入最新的数据,智能体可以在短时间内适应新的业务需求或市场变化。例如在一个金融领域的智能体中,可以通过微调让模型掌握最新的市场动态,生成更符合当前市场状况的投资建议。此外,企业还可以通过微调为智能体植入企业内部知识,确保客户在使用过程中获得一致的服务体验。
接下来以金融领域的智能体微调为例来初步演示如何实现智能体微调,本实例采用的预训练模型是GPT-4o。
首先,在终端安装相关的依赖库:
pip install torch transformers datasets accelerate
由于GPT-4o本身是闭源的,因此也可以使用开源的替代品,如GPT-2或GPT-NeoX。这些模型可以进行下游微调。此外,还需要注意,如果使用的是Google Colab或本地GPU,则需要确保本地已经安装了CUDA,并且CUDA驱动可以正常工作。
其次,需要一个金融领域的语料库来训练模型。数据格式为文本数据(比如新闻、市场报告、财务报表等)。示例数据如下:
financial_data.txt
股票市场是全球金融体系的重要组成部分。
债券投资适合风险偏好较低的投资者。
美元的升值通常会导致黄金价格下跌。
再次,进行模型加载和Tokenizer加载,并进行数据预处理。这里建议从本地加载模型。
从本地加载模型的步骤如下:
(1)在浏览器中打开https://huggingface.co/gpt2。
(2)下载模型文件并解压,并将其放在项目目录下,比如./models/gpt2/。
(3)从本地加载模型:
from transformers import GPT2Tokenizer, GPT2LMHeadModeldef load_model_and_tokenizer(): """加载GPT模型和Tokenizer""" model_name = "gpt2"# 或者使用 gpt-neo 等模型 tokenizer = GPT2Tokenizer.from_pretrained(model_name) model = GPT2LMHeadModel.from_pretrained(model_name) return model, tokenizermodel, tokenizer = load_model_and_tokenizer()print("模型和分词器加载成功!")from transformers import GPT2Tokenizer, GPT2LMHeadModeldef load_model_and_tokenizer(): """加载本地GPT模型和Tokenizer""" model_name = "./models/gpt2/"# 本地路径 tokenizer = GPT2Tokenizer.from_pretrained(model_name) model = GPT2LMHeadModel.from_pretrained(model_name) return model, tokenizermodel, tokenizer = load_model_and_tokenizer()print("模型和分词器加载成功!")
加载金融数据并转换为模型可以接受的格式:
from datasets import load_datasetdef prepare_dataset(file_path, tokenizer, block_size=128): """加载并预处理数据""" dataset = load_dataset('text', data_files={'train': file_path}) def tokenize_function(examples): return tokenizer(examples['text'], truncation=True, max_length=block_size, padding="max_length") tokenized_dataset = dataset.map(tokenize_function, batched=True, remove_columns=["text"]) return tokenized_dataset['train']# 加载和预处理数据file_path = "./financial_data.txt"dataset = prepare_dataset(file_path, tokenizer)print("数据集加载并预处理成功!")
使用Hugging Face的Trainer API进行微调:
from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModelingdef get_training_arguments(output_dir="./results"): """配置训练参数""" return TrainingArguments( output_dir=output_dir, overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=2, # 根据显存大小调整 save_steps=500, save_total_limit=2, logging_dir='./logs', # 日志文件路径 logging_steps=10, evaluation_strategy="steps", eval_steps=500, report_to="none"# 关闭wandb或其他报告 )# 创建数据集的Data Collatordata_collator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm=False)training_args = get_training_arguments()trainer = Trainer( model=model, args=training_args, data_collator=data_collator, train_dataset=dataset)# 开始训练trainer.train()print("模型训练完成!")
保存训练、微调后的模型:
保存微调后的模型和分词器
# 保存微调后的模型和分词器model.save_pretrained("./finetuned_gpt2")tokenizer.save_pretrained("./finetuned_gpt2")print("微调后的模型已保存!")
最后,使用微调后的模型生成文本,来验证它是否学到了金融领域的知识:
def generate_text(prompt, model, tokenizer, max_length=50): """生成文本""" inputs = tokenizer(prompt, return_tensors="pt") output = model.generate(**inputs, max_length=max_length, num_return_sequences=1) return tokenizer.decode(output[0], skip_special_tokens=True)
测试生成
prompt = "债券投资的特点是"generated_text = generate_text(prompt, model, tokenizer)print("生成的文本:", generated_text)
通过以上步骤,你应该学会了如何:
(1)加载GPT-2模型和分词器。
(2)准备和预处理金融领域的数据。
(3)配置训练参数并进行微调。
(4)保存并测试微调后的模型。
此外,也可以使用更大的模型(如GPT-NeoX)来提高效果,或者将生成的模型集成到具体的金融应用中,例如掌上银行App等。开发人员需要准备金融领域的训练数据,并在微调过程中使用预训练模型(例如GPT-2)作为基础,随后配置训练参数并运行训练,通过设置训练轮次和批次大小实现模型微调,最后保存训练结果,将微调后的模型保存在微调结果文件夹中。微调架构如图2所示。
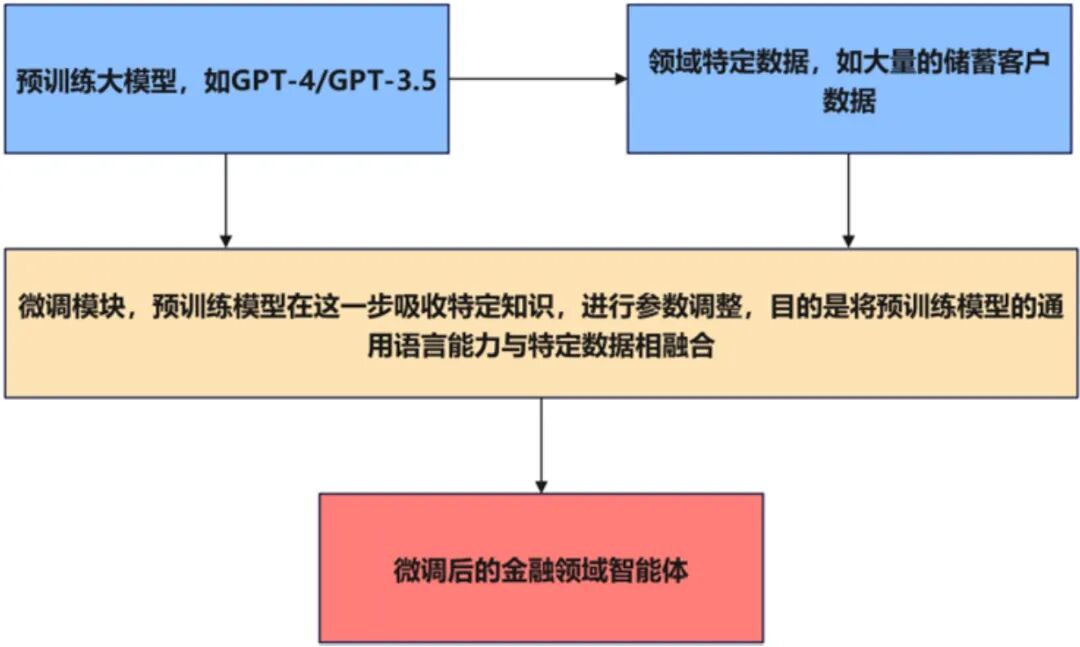
图2 智能体微调架构图
主动学习(Active Learning)是另一种实现动态更新的方式。智能体可以识别自身不确定的领域,并自动请求用户或管理员的反馈,从而不断完善自身,在法律顾问系统中,当模型无法确定特定条款的解释时,可以生成多个可能的答案,并请求用户确认。这种机制确保智能体能够在用户的帮助下快速成长。
模型的迭代更新也是确保智能体长期表现优异的关键。随着时间的推移,智能体可能会遇到新的问题或领域。开发者可以定期用新数据对模型进行再训练,并通过在线学习(Online Learning)实现模型的持续更新。这样的设计使得智能体能够紧跟时代变化,始终保持卓越的服务能力。
1.4 多语言支持与跨文化交互的实现
在全球化的背景下,智能体的多语言支持能力显得尤为重要。LLM凭借其强大的语言生成能力,能够在多语言环境中实现高质量的语言转换与理解,为跨文化交流提供强有力的支持。
LLM的多语言支持不仅体现在简单的翻译上,还包括对文化差异的理解与适应,在不同的文化背景下,同样的表达可能会有不同的含义。在智能客户服务系统中,模型不仅要将用户的语言转换成目标语言,还需要理解并尊重不同文化的沟通习惯,以避免误解或冒犯。
实现多语言支持的关键在于模型的跨语言模型共享能力。通过跨语言共享参数,LLM可以在训练过程中学习到不同语言之间的共性。这种设计让模型能够在接触新语言时,快速适应并生成高质量的语言输出,在一些特殊场景下,模型可以在汉语和英语之间无缝切换,并根据用户的语境选择合适的表达方式。
在技术实现层面,智能体可以结合LLM和翻译API实现实时对话的翻译。例如在国际会议的实时翻译系统中,智能体不仅需要准确翻译演讲者的语言,还要确保语调和措辞符合听众的文化习惯。这一能力让智能体在跨文化环境中如鱼得水,为用户提供流畅的交流体验。
随着全球化的深入,多语言和跨文化交互将成为智能体的必备能力。未来,智能体不仅要能处理不同语言之间的转换,还需要在多语言环境中实现语义一致性和逻辑连贯性,进一步提升跨文化交流的质量和效率。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、Agent技术框架的结构与关键模块
Agent技术框架在现代人工智能系统中承担了任务管理与自主决策的核心角色。这一框架通过感知、决策、执行等多个模块,赋予智能体高效应对复杂任务的能力。此外,智能体通过记忆管理实现上下文的追踪,在多任务并行处理中展现出了卓越的调度能力。
本节将详细解析Agent的三层结构及其关键模块,展示智能体如何通过协调各个组件实现高效运作。
2.1 感知、决策、执行:Agent的三层结构解析
Agent的三层结构分别是感知(Perception)、决策(Decision-Making)和执行(Execution)。每一层在智能体的运行过程中发挥着关键作用,共同确保任务的顺利完成。
感知层主要负责捕捉环境中的数据和信息。这些信息可以通过多种形式获取,如摄像头、传感器、API接口或用户输入。在智能客服系统中,感知层通过文本分析识别客户的需求和情绪。在自动驾驶系统中,感知层则通过摄像头和雷达感知路况和障碍物。感知层的精准度决定了智能体对外界信息的理解能力。
决策层是Agent系统的核心。它通过接收感知层的数据,结合预定义的逻辑、规则和算法进行推理,并做出行动决策。在智能金融助手中,决策层会根据市场数据和客户的投资偏好,生成个性化的投资建议。这一层通常依赖于大语言模型和知识图谱,实现了更加智能的推理和分析。
执行层负责将决策层的输出转换为具体的操作。例如,机器人智能体的执行层会根据路径规划系统的指令执行移动,客服智能体的执行层会生成并发送回复。在这一层中,智能体需要与外部系统进行交互,如通过API调用实现任务的落地。
感知、决策和执行的协同工作使智能体在面对复杂任务时具备清晰的逻辑流程。任何一层出现问题,都会直接影响智能体的整体表现。因此,这三层结构必须相互协调,确保高效运作。
2.2 上下文管理与记忆模块的集成设计
上下文管理与记忆模块的集成设计对于智能体的多轮对话和长期任务至关重要。在智能体与用户交互的过程中,系统不仅要理解当前输入,还需要追踪之前的内容,以实现连贯的对话和任务管理。
上下文管理模块的作用在于捕捉每轮对话中的关键信息,并确保这些信息在后续的交互中得以应用。例如,在客户服务场景中,如果用户在多个问题中涉及同一订单号,系统需要将订单号与当前对话关联,以便进行后续处理。这种上下文追踪不仅提高了用户体验,还减少了重复沟通的成本。
记忆模块是上下文管理的延伸,它负责保存更长时间的交互历史。在健康管理系统中,记忆模块会记录用户的健康状况和建议措施,并在未来的交互中基于这些记录提供优化的建议。大语言模型通过这种记忆机制,在与用户的长期交互中表现得更加智能。
以下我们来看一个记忆模块设计方案。
示例场景:智能客服系统中的记忆模块。
在一个银行的智能客服系统中,记忆模块用于帮助客服智能体记住用户的关键信息,例如客户的账户信息、常见问题和咨询记录。
1)短期记忆(Short-term Memory)
处理当前会话的上下文。例如,当用户提问“我上次的信用卡账单是什么?”时,智能体会将当前会话中的订单号或用户的账户信息保存在短期记忆中,以便在多轮对话中直接引用。
实现方式:短期记忆的数据存储在内存缓存(如Python的字典结构)中,会在会话结束后自动清空。
示例:短期记忆的存储
# 示例:短期记忆的存储short_term_memory = {"account": "12345678", "last_query": "信用卡账单"}
2)长期记忆(Long-term Memory)
保存客户的历史问题和反馈。例如,如果用户之前咨询过贷款利率,长期记忆模块会将这些信息保存,以便智能体在未来对话中主动询问用户是否需要进一步的贷款服务。
实现方式:长期记忆使用数据库或持久化存储(如MongoDB、PostgreSQL),支持智能体在未来会话中查询历史数据。
# 示例:长期记忆的保存和查询import sqlite3conn = sqlite3.connect("customer_memory.db")cursor = conn.cursor()# 创建表用于保存客户咨询历史cursor.execute("""CREATE TABLE IF NOT EXISTS customer_history ( customer_id TEXT, query TEXT, timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP)""")# 保存用户的历史问题def save_to_memory(customer_id, query): cursor.execute("INSERT INTO customer_history (customer_id, query) VALUES (?, ?)", (customer_id, query)) conn.commit()
示例场景:当客户多次咨询贷款利率时,智能体可以在第二次交互中说:“上次您询问了贷款利率,这里有最新的利率信息。”这种行为提升了用户体验,使用户感觉到智能体记住了自己的需求。
为了实现上下文管理与记忆的高效集成,常用的方法包括短期记忆和长期记忆的结合。短期记忆用于当前会话的上下文追踪,而长期记忆则用于保存历史数据,支持未来的查询和分析。合理的上下文和记忆设计使智能体在应对多轮对话和复杂任务时更加得心应手。
三、智能体与API、向量数据库的无缝集成
在构建智能体系统时,API和向量数据库的集成是实现智能体功能的重要环节。通过API,智能体可以调用外部系统的功能和数据,实现动态查询与操作。而向量数据库则提供了高效的语义检索能力,使智能体能够快速从大规模数据中提取相关信息。这种无缝集成使得智能体在信息获取、任务执行和知识管理方面具备高度灵活性与智能化。
本节将详细探讨智能体如何与RESTful API和向量数据库进行高效集成,并分析这些技术在实际场景中的应用。
3.1 智能体与RESTful API的集成方法
智能体通过集成RESTful API实现与外部系统的通信。RESTful API基于HTTP协议,具有简单、轻量级和易于扩展的特点,是智能体常用的数据交互方式。通过调用API,智能体可以访问数据库、调用云服务,或与其他应用系统进行对接。
API调用的基本流程包括:发送请求、接收响应、解析数据和执行操作。在银行的智能客服系统中,当用户询问账户余额时,智能体通过API请求查询用户的账户信息,并将结果呈现给用户。API的调用过程包含HTTP方法(如GET、POST)的使用,以及请求头和参数的设置。
这里以智能体调用天气API为例:
import requestsdef get_weather(city): """调用天气API获取指定城市的天气信息""" api_url = f"http://api.weatherapi.com/v1/current.json?key=your_api_key&q={city}" response = requests.get(api_url) if response.status_code == 200: data = response.json() return f"{city}的温度是 {data['current']['temp_c']}°C" else: return "无法获取天气信息"print(get_weather("Beijing"))
注意,在尝试该实例时,应当前往WeatherAPI官网注册相应的密钥并替换your_api_key部分。该实例中智能体通过HTTP GET请求获取天气数据,并解析API返回的JSON数据,这种API集成方法使得智能体能够动态访问外部资源,实现实时数据更新,返回的JSON数据也可以进一步提交给预训练模型或智能体,从而辅助用户完成交互过程。
3.2 向量数据库在语义检索中的作用
在智能体应用中,语义检索是一个重要环节,尤其是在处理大量文本数据或需要进行复杂信息匹配的任务时。传统的关键词匹配方式难以捕捉文本中的语义关系,因此需要引入向量数据库进行语义检索。向量数据库将文本转换为向量,并通过计算向量间的相似度,实现基于语义的高效检索。
向量化是指将文本数据转换为向量表示。大语言模型(如GPT-4、BERT)在处理文本时,会将每个句子或段落转换为高维向量。向量数据库存储这些向量,并支持高效的相似度查询。当用户输入查询语句时,智能体会将其向量化,并与数据库中的向量进行比较,找到最相似的结果。
这里以基于向量检索的智能问答系统为例。注意,这里采用加载本地模型的方法来开发智能问答系统,首先需要访问paraphrase-MiniLM-L6-v2模型页面,并下载整个模型文件。下载完成后,将模型放在项目目录中,并完成本地加载:
model = SentenceTransformer('./paraphrase-MiniLM-L6-v2')
完整代码如下:
from sentence_transformers import SentenceTransformerimport numpy as npfrom sklearn.metrics.pairwise import cosine_similarity# 使用本地路径加载模型model = SentenceTransformer('./paraphrase-MiniLM-L6-v2')knowledge_base = [ "股票市场是风险投资的主要渠道。", "债券投资具有较低风险,适合保守型投资者。", "外汇市场波动较大,适合有经验的投资者参与。"]knowledge_vectors = model.encode(knowledge_base)def semantic_search(query): query_vector = model.encode([query]) similarities = cosine_similarity(query_vector, knowledge_vectors) closest_idx = np.argmax(similarities) return knowledge_base[closest_idx]print(semantic_search("适合风险偏好低的投资"))
在这个例子中,智能体使用句子嵌入模型(Sentence Transformers)将查询语句和知识库中的句子转换为向量,并通过余弦相似度计算最相似的结果。这种语义检索方式克服了关键词匹配的局限性,能够更准确地找到与查询相关的内容。
本文完整代码如下,这段代码用于展示一个完整的金融智能Agent系统,集成了模型生成、语义检索、天气API调用和上下文管理等模块。
import timeimport sqlite3import asyncioimport requestsimport numpy as npfrom functools import wrapsfrom sentence_transformers import SentenceTransformerfrom transformers import GPT2Tokenizer, GPT2LMHeadModelfrom typing import Dict, List, Callable, Any# 全局上下文和内存模拟short_term_memory = {}long_term_db = "customer_memory.db"class MemoryManager: """管理上下文和记忆模块""" @staticmethod def load_long_term_memory(): conn = sqlite3.connect(long_term_db) cursor = conn.cursor() cursor.execute(""" CREATE TABLE IF NOT EXISTS customer_history ( customer_id TEXT, query TEXT, timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) """) conn.commit() return conn, cursor def save_to_memory(self, customer_id: str, query: str): conn, cursor = self.load_long_term_memory() cursor.execute("INSERT INTO customer_history (customer_id, query) VALUES (?, ?)", (customer_id, query)) conn.commit() conn.close() def get_last_query(self, customer_id: str) -> str: conn, cursor = self.load_long_term_memory() cursor.execute("SELECT query FROM customer_history WHERE customer_id = ? ORDER BY timestamp DESC LIMIT 1", (customer_id,)) result = cursor.fetchone() conn.close() return result[0] if result else"No history found."memory_manager = MemoryManager()def performance_monitor(func: Callable) -> Callable: @wraps(func) asyncdef wrapper(*args, **kwargs): start_time = time.time() result = await func(*args, **kwargs) elapsed = time.time() - start_time print(f"{func.__name__} executed in {elapsed:.2f}s") return result return wrapperclass ModelManager: """管理模型加载和生成""" def __init__(self): self.model, self.tokenizer = self.load_model_and_tokenizer() @staticmethod def load_model_and_tokenizer(): print("Loading model and tokenizer...") tokenizer = GPT2Tokenizer.from_pretrained("gpt2") model = GPT2LMHeadModel.from_pretrained("gpt2") print("Model and tokenizer loaded successfully.") return model, tokenizer def generate_text(self, prompt: str, max_length: int = 50) -> str: inputs = self.tokenizer(prompt, return_tensors="pt") output = self.model.generate(**inputs, max_length=max_length, num_return_sequences=1) return self.tokenizer.decode(output[0], skip_special_tokens=True)model_manager = ModelManager()class VectorSearch: """语义检索模块""" def __init__(self): self.model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2') self.knowledge_base = [ "股票市场是风险投资的主要渠道。", "债券投资适合保守型投资者。", "外汇市场波动较大,适合有经验的投资者参与。" ] self.knowledge_vectors = self.model.encode(self.knowledge_base) @staticmethod def cosine_similarity(vector_a: np.ndarray, vector_b: np.ndarray) -> float: """手动计算余弦相似度""" return np.dot(vector_a, vector_b) / (np.linalg.norm(vector_a) * np.linalg.norm(vector_b)) def search(self, query: str) -> str: query_vector = self.model.encode([query])[0] similarities = [self.cosine_similarity(query_vector, vec) for vec in self.knowledge_vectors] closest_idx = np.argmax(similarities) return self.knowledge_base[closest_idx]vector_search = VectorSearch()class APIManager: """API管理器,用于调用外部服务""" @staticmethod def get_weather(city: str) -> str: api_url = f"http://api.weatherapi.com/v1/current.json?key=your_api_key&q={city}" response = requests.get(api_url) if response.status_code == 200: data = response.json() returnf"{city}的温度是 {data['current']['temp_c']}°C" return"无法获取天气信息"class FinancialAgent: """金融智能体,整合上下文、模型与API""" @performance_monitor asyncdef handle_query(self, customer_id: str, query: str): memory_manager.save_to_memory(customer_id, query) if"天气"in query: city = query.split(" ")[-1] weather_info = APIManager.get_weather(city) print(weather_info) elif"投资建议"in query: advice = vector_search.search(query) print(f"智能投资建议: {advice}") else: response = model_manager.generate_text(query) print(f"智能生成: {response}")asyncdef main(): agent = FinancialAgent() await agent.handle_query("customer_001", "请问北京的天气如何?") await agent.handle_query("customer_001", "给我一些投资建议")if __name__ == "__main__": asyncio.run(main())
运行效果如下:
>> Loading model and tokenizer...>> Model and tokenizer loaded successfully.>> 北京的温度是 16°C>> 智能投资建议: 债券投资适合保守型投资者。
向量数据库设计与应用的关键点可以概括为以下几个方面。
(1)高效存储与检索:向量数据库需要支持大规模数据的高效存储和检索。常用的向量数据库包括FAISS和Milvus,它们能够快速计算向量之间的相似度,并支持分布式存储。
(2)数据更新与维护:向量数据库中的数据需要定期更新,以确保检索结果的准确性。对于金融智能体来说,数据库中的市场信息和分析报告应及时更新。
(3)查询优化与缓存:为了提高检索效率,向量数据库可以使用查询缓存和索引优化技术。常用的优化方法包括构建向量索引和提前计算相似度。
(4)与大语言模型的协同:向量数据库与大语言模型相结合,使智能体具备了更强的知识管理能力。在智能问答系统中,模型负责生成向量表示,而数据库负责高效存储和检索。
当然,也可以进行智能体调用和向量数据库的集成。例如,在一个智能金融助手中,API和向量数据库的结合实现了高度灵活的数据管理。当用户询问“最近的股市表现如何”时,智能体首先通过API获取最新的市场数据,并将结果存储到向量数据库中。随后,用户提出关于具体公司的问题时,智能体通过语义检索找到与查询最相关的市场分析,并生成个性化的回答。
四、常见框架与开发者平台:ReAct、Hugging Face和LangChain
ReAct、Hugging Face和LangChain等技术栈已经成为业内公认的高效工具,广泛应用于自然语言处理、任务规划与多步推理等领域。这些框架不仅大大降低了开发复杂智能体的门槛,还通过开源社区的支持不断推动技术进步。
本节将详细介绍这些框架的核心思想、技术特点与具体应用场景,帮助开发者理解如何在实践中运用这些技术来构建强大而高效的智能体系统。
4.1 ReAct框架的核心思想与应用场景
ReAct是一个创新性的多步推理框架,旨在将决策过程与任务执行融合在一起。ReAct的名字来源于两个核心概念:Reasoning(推理)和Acting(行动)。它突破了传统任务执行系统的局限,将推理能力嵌入智能体的任务流中,使其在执行过程中能够自适应地调整策略。ReAct框架的出现解决了在处理复杂任务时常见的割裂问题,即决策和执行模块彼此独立,缺乏实时交互的能力。
在ReAct框架中,智能体可以动态调整任务流程,比如在客户服务场景中,当用户的请求涉及多种问题时,智能体需要通过ReAct的推理机制判断这些问题的优先级,并决定任务的执行顺序。ReAct的优势在于,它不仅能够依赖预设的规则进行任务规划,还能通过不断的学习和反馈优化自身的决策过程。
典型的应用场景包括多轮对话系统、自动化客户支持和智能客服调度。在这些场景中,ReAct通过其灵活的推理和行动机制,使智能体具备了更高的响应速度和处理复杂任务的能力。例如,在一个保险公司的智能客服系统中,ReAct框架可以帮助智能体根据客户的保险查询和索赔请求,动态调整对话路径,提高服务效率。
4.2 Hugging Face平台与模型管理
Hugging Face已成为自然语言处理领域的重要技术平台。它以模型共享、管理与部署的便捷性著称,为开发者提供了丰富的预训练模型、工具和API支持。
Hugging Face的核心在于其开源模型库和Transformer框架,使开发者能够快速构建和微调高性能的NLP模型。如图3所示为HuggingFace平台官网,其所能提供的常用预训练模型和数据集如图4所示。
Hugging Face的平台优势主要体现在以下几个方面。
(1)模型库的开放性与多样性:Hugging Face拥有成千上万的预训练模型,涵盖自然语言理解、自然语言生成、语义匹配、情感分析等多个领域。这些模型由全球开发者社区共享与维护,使得智能体开发者能够以较低的成本获取强大的模型支持。
(2)模型微调与部署的便捷性:Hugging Face平台支持轻松地对预训练模型进行微调,使其适应特定领域的需求。通过简单的几行代码,开发者就能将模型部署到生产环境中,实现实时推理与响应。在金融领域的应用中,微调后的语言模型可以精准识别财务报表中的关键信息,并生成分析报告。
图3 HuggingFace平台官网
图4 HuggingFace平台常用预训练模型和数据集
(3)集成工具与API支持:Hugging Face提供了完善的API接口,使智能体能够无缝集成各种NLP功能。在智能客服系统中,智能体可以通过Hugging Face的情感分析模型实时判断客户的情绪变化,并相应调整服务策略。此外,Hugging Face的模型管理工具还支持模型版本控制和模型优化,确保智能体始终保持最佳性能。
(4)社区与开源支持:Hugging Face的成功离不开其活跃的开发者社区。社区提供了大量的教程、代码示例和技术支持,可以帮助开发者更快地掌握平台的使用方法,并推动NLP技术的创新与发展。
在实际应用中,Hugging Face平台已经被广泛应用于智能问答系统、自动摘要生成和对话系统的开发。通过与Hugging Face的深度集成,智能体不仅能够快速获取最新的技术成果,还能通过微调实现个性化的任务优化。
4.3 LangChain在复杂任务中的应用
LangChain是一种面向多步推理和复杂任务自动化的开源框架,专注于将语言模型与多种工具集成起来。LangChain的核心思想是将大语言模型作为基础组件,通过链式结构实现任务的分解与执行。它支持与API、数据库和外部知识库的无缝集成,使得智能体能够高效处理复杂的任务流。LangChain开始基本架构如图5所示。
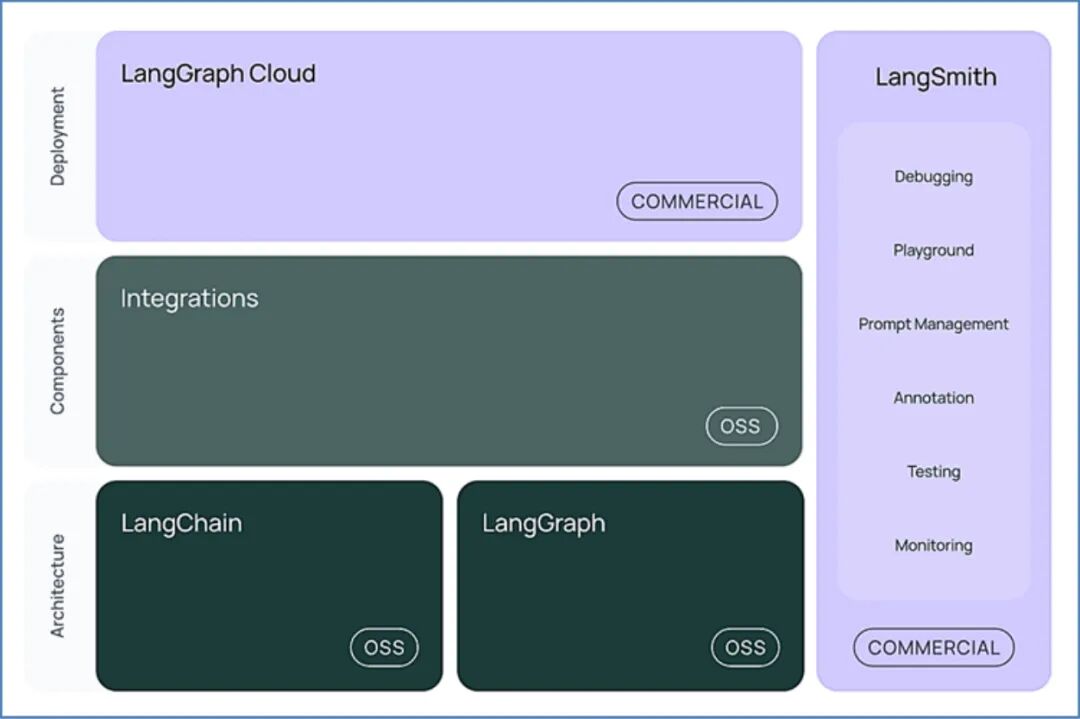
图5 LangChain开发基本架构图
LangChain的一个重要特点是其多步骤推理能力。在实际应用中,任务往往无法通过一次简单的语言生成来完成,需要智能体进行多次交互和推理。例如在客户支持场景中,客户的需求可能涉及多个问题,需要智能体逐步引导用户提供更多信息,并根据每一步的结果生成个性化的解决方案。LangChain的链式结构能够将这些步骤串联起来,实现自动化的任务分解与执行。
另一个关键特点是工具集成与动态调用。LangChain允许智能体在任务执行过程中,根据需要动态调用外部API或数据库,在一个智能金融助手中,当用户询问“当前的股票市场趋势如何”时,智能体可以通过LangChain调用市场分析API获取最新的数据,并在多轮对话中逐步引导用户完成投资决策。
LangChain在知识增强系统中的应用也非常广泛。通过集成向量数据库和知识库,智能体能够在生成语言输出时引用最新的知识,在学术研究助手中,LangChain可以将用户的问题与数据库中的文献进行语义匹配,并自动生成相关文献的摘要,帮助用户快速获取关键信息。
在后续章节中,本书将给出具体的LangChain开发实例。此外,LangChain的优势还体现在其灵活的任务调度能力。智能体可以根据任务的复杂程度和优先级,动态调整执行路径,确保关键任务得到及时处理。这种灵活性使得LangChain在复杂任务的自动化执行中具有突出的表现。
五、小结
本文详细探讨了大模型驱动的Agent技术框架的核心组成与实现方法。智能体的三层结构——感知、决策和执行,为其实现复杂任务提供了逻辑基础。而上下文管理和记忆模块的设计,则确保了智能体在多轮对话和长期任务中的连贯性。任务调度和并行处理机制使智能体在面对多任务时保持高效响应。
通过API的集成,智能体具备了动态获取外部资源的能力,而向量数据库的语义检索功能为智能体提供了更智能的数据查询支持。ReAct框架、Hugging Face平台与LangChain的应用,进一步增强了智能体的推理能力与任务执行效率。
基于这些技术栈的应用,智能体已经在金融、客户服务、健康管理等领域展现出了广泛的应用前景,为复杂任务的自动化提供了可靠的技术保障。
六、思考
(1)请结合ReAct框架的核心思想,设计一个用于保险理赔的智能体任务规划方案。该方案应包括感知、推理与执行的具体步骤,并说明在多轮对话过程中如何通过ReAct动态调整任务的执行顺序,以提高用户体验和理赔效率。
(2)在客户服务系统中,经常需要智能体处理涉及多轮对话的问题。请详细分析如何通过上下文管理模块,让智能体在对话过程中记住用户的订单号与咨询内容,并在未来对话中自动引用这些信息,简化用户与智能体的交互过程。
(3)请结合向量数据库的特点,构思一个用于医疗记录管理的智能体系统。在该系统中,智能体需要实现基于语义的病历检索和分析功能,并根据查询结果生成个性化的健康建议。请详细描述智能体如何调用向量数据库完成数据查询和语义匹配。
(4)在金融领域的投资咨询系统中,智能体需要频繁调用API获取市场行情数据。请设计一个完整的任务执行流程,包括如何通过RESTful API动态查询股票数据,并结合LangChain框架实现多步骤的投资策略分析。
(5)请详细描述如何在Hugging Face平台上微调一个大语言模型,使其适应法律领域的智能问答系统。具体说明微调过程中需要使用的数据类型和格式,并分析如何通过Hugging Face的模型管理功能实现模型的持续优化与部署。
(6)在复杂任务的并行处理场景中,智能体需要根据任务优先级动态调度资源。请以智能物流系统为例,设计一个并行任务处理方案,描述如何通过调度算法在高峰期高效分配快递车辆与运力资源,并确保实时订单信息的同步与更新。
七、如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献353条内容
已为社区贡献353条内容

所有评论(0)