MIAOYUN | 每周AI新鲜事儿(11.28-12.05)
12月3日,火山引擎正式发布豆包图像创作模型「Doubao-Seedream-4.5」,该模型在主体一致性、指令遵循精准度、空间逻辑理解及美学表现力上实现迭代,不仅强化了多图组合生成能力,优化了海报排版与Logo设计功能,支持高精度图文混排,还能精准响应高阶复杂指令,凭借内置的世界知识与空间逻辑实现合理透视关系和物理规律还原,同时显著提升画面立体感与氛围感,可生成电影级质感图像,目前已全面支持广告
本周全球科技企业密集发布AI领域新成果,腾讯、昆仑万维、快手、Meta、智谱AI、生数科技、DeepSeek、Runway、NVIDIA、华为、Mistral AI、阿里、火山引擎、可灵AI等推出多模态、3D生成、视频生成、推理优化等方向新模型,聚焦性能提升与商业化适配;技术上,华为发布MoE推理优化技术、商汤开源原生多模态架构;同时,阶跃星辰开源 GUI 智能体,拍我AI、Anuttacon推出AI创作与聊天工具,覆盖生成式AI、具身智能、行业应用等核心场景,一起来回顾本周发生的AI新鲜事儿吧!
AI大模型
腾讯「混元3D Studio 1.1」接入「PolyGen 1.5」,直出艺术家级3D资产
11月28日,腾讯混元正式推出「混元3D Studio 1.1」,并接入最新的美术级3D生成大模型「混元3D PolyGen 1.5」,能够直出艺术家级的3D资产。「PolyGen 1.5」首创端到端原生四边形网格生成方法,可直接学习四边形拓扑,生成连贯边缘环,布线效果大幅度提升,支持混合拓扑,适用于软/硬表面模型,进一步提升3D生成模型的专业可用性。

图:PolyGen1.5与mesh自回归SOTA方法效果对比
昆仑万维发布「Mureka V7.6/O2」双模型,音质与效率双提升
11月28日,昆仑万维发布「Mureka V7.6」与「Mureka O2」模型,新模型在音乐性、编曲能力、音质质感和Prompt贴合度等多个维度相较前序版本实现显著提升,响应速度和推理效率大幅增强,更适合大规模商业化使用。自今年3月发布O1与V6以来,「Mureka」已吸引近700万新增注册用户,覆盖百余国家和地区。
参考:Mureka V7.6和Mureka O2模型正式发布,开启AI音乐创作黄金时代
快手发布「Keye-VL-671B-A37B」模型,升级跨模态对齐能力
11月28日,快手发布了新一代旗舰多模态大语言模型「Keye-VL-671B-A37B」,模型基于DeepSeek-V3-Terminus打造,拥有671B参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。
参考:视频理解霸榜!快手Keye-VL旗舰模型重磅开源,多模态视频感知领头羊
智谱AI发布「清影2.0」,一句话生成1080P视频自带AI音效
11月28日,智谱AI推出视频生成模型「清影2.0」,基于自研CogVideoX大模型架构,实现了用文本直接生成1080P高清视频的突破,还集成了CogSound音效模型,开创了"文生音画"一体化体验的新时代。「清影2.0」支持最长10秒的1080P分辨率视频生成,可满足大多数短视频内容创作;集成的CogSound音效模型能够根据视频内容智能匹配背景音乐、环境音效等音频元素,实现音画同步的沉浸式体验。
生数科技「Vidu Q2」全球同步上线,生图功能升级,5秒极速生成
12月1日,生数科技「Vidu Q2」全球同步上线,升级参考生图功能,新增文生图、图像编辑功能,以超强主体一致性、5秒极速生成、任意比例及4K输出等优势,在Artificial Analysis全球图像编辑榜单跻身前四超越「GPT-5」,还打通“生图-保存主体-生视频”一站式工作流,覆盖多商业化场景。
参考:Vidu Q2生图掀起「一致性革命」,限时无限免费来袭,全球同步上线
「DeepSeek-V3.2」双模型正式发布,强化Agent能力,融入思考推理
12月1日,深度求索正式发布「DeepSeek-V3.2」及常思考增强版 「DeepSeek-V3.2-Speciale」两款模型,前者平衡推理能力与输出长度,适合日常使用及通用Agent任务;后者融合数学定理证明能力,在IMO、ICPC等国际赛事中斩获金牌,推理性能媲美「Gemini-3.0-Pro」。新模型突破过往局限,首次实现思考模式与非思考模式的工具调用融合,通过大规模Agent训练数据合成方法构造1800+环境、85000+复杂指令,大幅提升泛化能力。
参考:DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理
Runway推出「Gen-4.5」视频模型,登顶文本转视频SOTA
12月1日,美国AI初创公司Runway推出「Gen-4.5」视频模型,在Artificial Analysis文本转视频排行榜中以1247 Elo评分拿下SOTA,超越Google和OpenAI同类产品。该模型擅长理解并执行复杂序列式指令,可在单个提示词中精准指定镜头运镜、场景构图、时间节点和氛围变化,物体移动具备真实重量感与动量特征。
参考:Runway重夺全球第一!1247分碾压谷歌Veo3,没有千亿算力也能干翻科技巨头
NVIDIA开源全球首个VLA模型「Alpamayo-R1」,突破L4自动驾驶“黑箱”困境
12月1日,NVIDIA宣布开源全球首个推理型视觉-语言-动作(VLA)模型「Alpamayo-R1」(AR1),支持摄像头画面与文本指令处理及行车决策输出,主打可解释性,创新引入标注“为什么这样做”的因果链(CoC)数据集、扩散式轨迹解码器及多阶段训练策略,通过高效多相机时序感知的统一编码方式,实现规划精度提升12%、越界率降低35%等多项性能优化,端到端延迟仅99ms,能让自动驾驶AI具备“会开车+会思考+会解释”的能力,推动自动驾驶从“黑箱”迈向可解释的L4级别。
华为开源扩散语言模型「openPangu-R-7B-Diffusion」,双模式解码创SOTA
12月2日消息,华为开源扩散语言模型「openPangu-R-7B-Diffusion」,基于 「openPangu-Embedded-7B」经800B tokens续训练,创新融合前文因果注意力掩码架构,突破32K上下文长度限制,具备“自回归+扩散”双模式解码能力(并行解码速度最高达自回归的 2.5倍)及“慢思考”能力,在多学科知识、数学推理、代码生成等权威基准中创下7B参数量级SOTA纪录,其训练推理全流程依托昇腾NPU集群完成。
参考:华为新开源!扩散语言模型突破32K上下文,还解锁了「慢思考」
火山引擎发布豆包图像创作模型「Doubao-Seedream-4.5」,强化多图组合能力
12月3日,火山引擎正式发布豆包图像创作模型「Doubao-Seedream-4.5」,该模型在主体一致性、指令遵循精准度、空间逻辑理解及美学表现力上实现迭代,不仅强化了多图组合生成能力,优化了海报排版与Logo设计功能,支持高精度图文混排,还能精准响应高阶复杂指令,凭借内置的世界知识与空间逻辑实现合理透视关系和物理规律还原,同时显著提升画面立体感与氛围感,可生成电影级质感图像,目前已全面支持广告营销、电商运营、影视制作、数字娱乐及教育等核心场景。
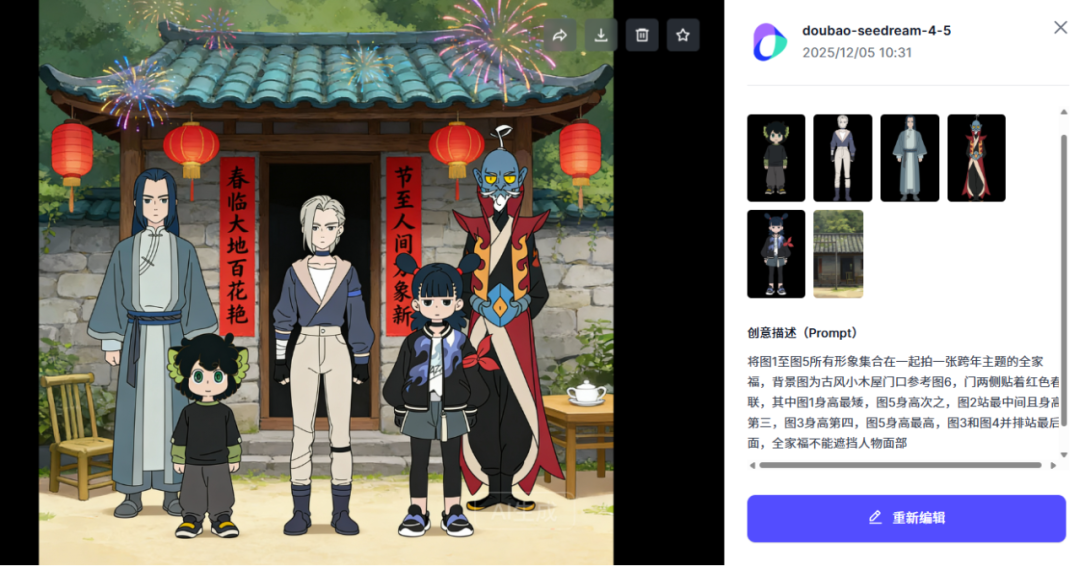
体验链接:https://exp.volcengine.com/ark/vision?mode=vision&modelId=doubao-seedream-4-5-251128&sessionid=&tab=GenImage
参考:豆包图像创作模型Seedream 4.5发布:聚焦商业生产力场景
北邮联合小米提出「C²-Cite」溯源大模型,革新AI内容可信度技术路径
12月3日,北邮百家AI团队联合小米大模型团队提出的溯源大模型「C²-Cite」(已被WSDM 2026收录),首创上下文感知的归因生成技术,不仅能让大模型在生成内容时自动标注精准的信息来源,更能确保生成内容与引用的外部知识高度语义对齐,实现每一处表述都有溯源依据、与参考来源深度协同,从根本上解决大模型生成内容的可信度问题。
参考:句子级溯源+生成式归因,C²-Cite重塑大模型可信度
Mistral AI全量开源「Mistral 3」系列模型,硬刚DeepSeek
12月3日,法国公司Mistral AI发布开源「Mistral 3」系列模型,包含旗舰模型「Mistral Large 3」(总参数675B,激活参数41B,MoE架构)及3B、8B、14B尺寸的「Ministral 3」小模型(均有 pretraining、instruct、reasoning 三个版本,支持图像理解与40+语言)。训练使用3000张NVIDIA H200,LMArena排名开源非推理模型第二、总榜第六,且该系列模型已与NVIDIA 等合作优化部署,支持多种硬件设备与算力平台API服务,此次开源被视为对DeepSeek激进开源策略的战略应对。
阿里通义千问上线「Qwen3-Learning」,推出拍题批改双功能
12月3日,阿里巴巴通义千问上线学习大模型「Qwen3-Learning」,推出拍题答疑和作业批改两大功能。该模型采用混合专家(MoE)架构,总参数量2350亿,激活仅需220亿,支持拍照识别题目内容,兼容印刷体与手写体,覆盖小学至高中全学科作业批改与解题辅导,融合多国考试体系与真题数据,实现跨文化、多语言精准解答。
参考:千问再放大招!阿里最强学习模型上线,能讲题、会批改、懂专业,直接把老师“请回家”
快手旗下可灵AI全能灵感周,连发多款新模型与新功能
快手旗下可灵AI全能灵感周,连续5天发布新模型与新产品,分别是统一多模态视频大模型「可灵O1」、新一代全能型图片模型「可灵图片O1」、音画同出模型「可灵2.6」、「可灵数字人2.0」等。
12月1日,可灵AI正式上线全球首个统一多模态视频大模型「可灵O1」,打破功能割裂,构建全新生成式底座。 该模型采用MVL(多模态视觉语言)交互架构与 Chain-of-thought 技术,支持照片、视频、文字等多模态输入,可实现创意视频生成、局部编辑、镜头延展、动作捕捉等功能,能解决视频一致性难题,支持多主体组合及3-10秒、多种比例的视频生成。
12月2日,可灵AI全量上线「可灵图片O1」全能型图像模型,兼具特征全保真、细节全掌控、风格全复刻、创意全融合四大优势,支持图像生成、编辑、风格转换及创意呈现等一站式操作。


图1为参考图,输出图2为毛毡风格
体验链接:https://app.klingai.com/cn/?sessionid=
参考:Day2|可灵图片 O1 模型全量上线,让创意精准落地!
12月3日,「可灵2.6」全量上线,Web端与App端同步推出首个音画同出模型,支持文生音画、图生音画两条高效创作路径,能单次生成画面、自然语音、匹配音效及环境氛围,实现音画同步,涵盖单人独白、旁白解说、多人对白、音乐表演、创意场景等多种适用场景,新手也可一键成片,创作效率翻倍,同时需注意禁止利用该AI生成功能从事违法活动。
12月4日,可灵AI全量上线「可灵数字人2.0」,用户仅需上传角色图、添加配音内容、描述角色表现三步即可生成视频。该版本实现三大突破性升级,表演力全面进化,能精准控制体态动作、手势、表情及镜头语言,口型和手部细节更真实自然,同时打破时限支持最长5分钟单次视频生成,可覆盖深度科普、广告营销等多类长内容场景,评测得分超同类产品。
参考:Day4|可灵数字人 2.0 功能正式上线!不止会说,更会演!
12月5日,可灵AI全新上线可灵O1「主体库」和「对比模板」两大功能,其中「主体库」支持上传多角度参考图构建专属角色、道具和场景,可一键复用、自由组合(视频O1至多参考7个主体,图片O1至多参考10个主体),还能通过AI补图扩展视角、生成描述,同时提供海量官方主体素材;「对比模板」可一键整合多模态创作的输入与成品,实现Before& After高效同框对比,助力爆款传播。
AI Agent
阶跃星辰开源GUI智能体「GELab-Zero」,同步推出AndroidDaily评测标准
11月29日,阶跃星辰推出开源GUI智能体「GELab-Zero」,可适配几乎所有App,该系统由轻量级推理基础设施与4B参数规模的GUI Agent模型(GELab-Zero-4B-preview)构成,最大亮点在于可在消费级设备上高效运行,实现低延迟响应与用户隐私保护。此外,阶跃还同步开源了基于真实业务场景的自建评测标准「AndroidDaily」,以期推动GUI领域模型评测向消费级、规模化应用发展。
参考:告别GUI Agent工程基建噩梦:阶跃开源4B Agent模型,跑通所有安卓设备,手搓党一键部署
AI 工具
「拍我AI V5.5」发布,一键生成“分镜+音频”,AI视频迈入内容生成时代
12月1日,拍我AI(PixVerse)推出「V5.5」版本,成为国内首个能一键生成“分镜+音频”、实现完整叙事的AI视频大模型。该模型具备“导演思维”,能理解镜头、声音与叙事的逻辑关系,支持多角色音画同步、多镜头自主编排,兼容图片转视频、一句话生成剧情短片等场景,在广告片、影视预演等商业化场景中表现出高完成度,推动AI视频从“素材生成”迈入“内容生成”时代,降低专业创作门槛,让普通人也能轻松开展视频创作。
参考:不止 Sora2!拍我AI V5.5 更新:人人都能用 AI 视频当导演了
Anuttacon推出「AnuNeko」聊天AI,双聊天模式主打人格化交互
12月1日,米哈游创始人蔡浩宇创立的AI公司Anuttacon推出AI聊天产品「AnuNeko」,主打人格化交互与情绪价值,产品提供Orange Cat(温和友善的橘猫)和Exotic Shorthair(毒舌暴躁的异国短毛猫)两种人格模型,响应迅速且支持多语言交互,但不具备联网、读链接、图片识别、复杂逻辑推理及高效代码编写能。该产品是Anuttacon探索AI构建沉浸式虚拟世界的重要布局。
参考:「原神之父」做了个毒舌 AI 猫娘,聊了两天的我被怼了八百回
技术突破
华为发布准万亿级MoE推理优化技术「Omni Proxy智能调度」和「AMLA加速算法」
11月28日,华为发布了准万亿参数规模的MoE模型「openPangu-Ultra-MoE-718B-V1.1」及其量化版本,并开源了两大核心优化技术「Omni Proxy智能调度」和「AMLA加速算法」,通过六大创新解决传统调度痛点,推理加速套件覆盖服务扩展、任务调度等全栈能力,将硬件算力利用率推至86.8%、优化推理链路中的计算与通信效率,有效解决了超大规模MoE模型在部署时面临的计算、访存和并行策略等挑战,为模型的生产级落地提供了可行路径。
参考:华为放出「准万亿级MoE推理」大招,两大杀手级优化技术直接开源
商汤开源行业首个原生多模态架构「NEO」,1/10数据量追平旗舰级性能
12月1日,商汤科技与南洋理工大学S-Lab合作研发并开源全新原生多模态模型架构「NEO」,打破传统“视觉编码器+语言模型”拼接架构局限。通过原生图块嵌入、三维旋转位置编码、多头注意力三大底层创新及双阶段融合训练策略,实现视觉与语言的深层统一,显著提升图像细节捕捉能力与跨模态关联效率,仅需3.9亿图文对(仅业界1/10的数据量)即可达到甚至超越现有原生VLM的综合性能,支持任意分辨率与长图像输入并可无缝扩展至视频、具身智能等领域,目前已开2B与9B规格模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)