Spring AI:Jsoup 提取网页纯文本:降低提示词 Token 消耗
Spring AI:Jsoup 提取网页纯文本:降低提示词 Token 消耗
历史文章
Spring AI:对接DeepSeek实战
Spring AI:对接官方 DeepSeek-R1 模型 —— 实现推理效果
Spring AI:ChatClient实现对话效果
Spring AI:使用 Advisor 组件 - 打印请求大模型出入参日志
Spring AI:ChatMemory 实现聊天记忆功能
Spring AI:本地安装 Ollama 并运行 Qwen3 模型
Spring AI:提示词工程
Spring AI:提示词工程 - Prompt 角色分类(系统角色与用户角色)
Spring AI:基于 “助手角色” 消息实现聊天记忆功能
Spring AI:结构化输出 - 大模型响应内容
Spring AI:Docker 安装 Cassandra 5.x(限制内存占用)&& CQL
Spring AI:整合 Cassandra - 实现聊天消息持久化
Spring AI:多模态 AI 大模型
Spring AI:文生图:调用通义万相 AI 大模型
Spring AI:文生音频 - cosyvoice-V2
Spring AI:文生视频 - wanx2.1-i2v-plus
Spring AI:上手体验工具调用(Tool Calling)
Spring AI:整合 MCP Client - 调用高德地图 MCP 服务
Spring AI:搭建自定义 MCP Server:获取 QQ 信息
Spring AI:对接自定义 MCP Server
Spring AI:RAG 增强检索介绍
Spring AI:Docker 安装向量数据库 - Redis Stack
Spring AI:文档向量化存储与检索
Spring AI:提取 txt、Json、Markdown、Html、Pdf 文件数据,转换为 Document 文档
Spring AI:Apache Tika 读取 Word、PPT 文档
Spring AI:Docker 安装 SearXNG 搜索引擎
Spring AI:整合 OKHttp3:获取 SearXNG 搜索结果
Spring AI:自定义线程池 - 通过 CompletableFuture 并发获取搜索结果页面内容

上文中,我们已经成功通过 CompletableFuture 并发去获取多个页面 HTML 代码。但是,也要考虑到一个问题,那就是如果直接将 HTML 添加到提示词上下文中,不做任何处理的话,那么,势必会导致提示词长度太大,调用 AI 大模型的费用成本,也会显著增加。
为了避免此问题,我们还需要对 HTML 提纯一下,这里选型的是 Jsoup 库,它能够将 css 、js 、html 等无用的代码部分去除掉,仅提取出纯文本。
Jsoup 介绍
Jsoup 是一个强大的 Java HTML 解析、操作、清理和数据抓取库。专为处理 “现实世界” 的 HTML(即使格式混乱)而设计。
其核心功能如下:
- 极简 API (类似 jQuery): 最大亮点是提供极其易用、基于 CSS 选择器 (select()) 和流畅链式调用的 API,学习成本低,代码简洁高效。
- 强大容错解析: 能优雅处理格式错误、标签未闭合等“脏” HTML,构建合理的 DOM 树,而严格 XML 解析器会失败。
- 高效数据抽取: 结合 CSS 选择器和 DOM 方法,轻松精准提取链接、文本、图片、属性值等目标数据(Web Scraping 利器)。
- 健壮 HTML 清理 (XSS 防护): 提供强大的白名单机制,可清除用户提交的 HTML 中的危险内容(如恶意脚本),有效防御跨站脚本攻击 (XSS)。
- 灵活输入支持: 可直接从 URL、文件、字符串或 InputStream 加载并解析 HTML 文档。
- 良好性能: 对于常见 HTML 处理任务(解析、抓取、清理),性能表现优秀,比无头浏览器轻量快速。
- 整洁 HTML 输出: 输出的 HTML 会自动格式化(缩进、换行),结构清晰易读。
- 轻量级: 独立 JAR 包,无复杂依赖,易于集成。
添加依赖
编辑 pom.xml ,添加 Jsoup 的依赖,如下:
<properties>
// 省略...
<jsoup.version>1.17.2</jsoup.version>
</properties>
// 省略...
<dependencies>
// 省略...
<!-- Jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>${jsoup.version}</version>
</dependency>
</dependencies>
// 省略...
添加完成后,刷新一下 Maven, 将包下载到本地仓库中。
提取 HTML 中的纯文本
接着,编辑 SearchResultContentFetcherServiceImpl 业务类,将 batchFetch() 方法中 “步骤3” 的 map() 方法改造一下,通过 Jsoup 提取 HTML 中的纯文本,代码如下:
// 步骤3:当所有任务完成后收集结果
return allFutures.thenApplyAsync(v -> // 所有任务完成后触发
futures.stream() // 遍历所有已完成的任务
.map(future -> {
SearchResult searchResult = future.join();
// 获取页面 HTML 代码
String html = searchResult.getContent();
if (StringUtils.isNotBlank(html)) {
// 提取 HTML 中的文本
searchResult.setContent(Jsoup.parse(html).text());
}
return searchResult;
}) // 提取每个任务的结果
.collect(Collectors.toList()), // 合并所有结果为一个集合,并返回
processingExecutor // 使用专用的 processingExecutor 线程池
);
测试
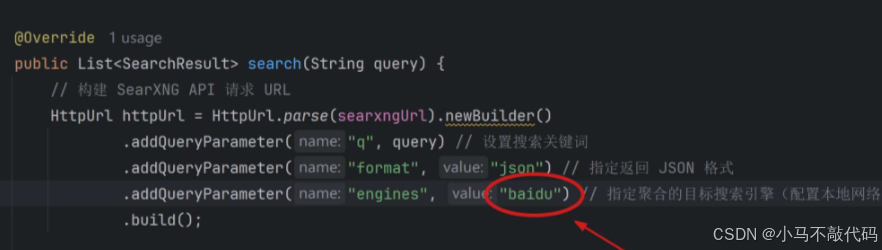
接着,我们将 SearXNGServiceImpl 中的搜索引擎指定部分,先改为仅使用 baidu 百度,如下图所示:
重启后端项目,浏览器请求如下地址,先看看是否能够成功提取出 HTML 中的纯文本:
http://localhost:8090/network/test?message=最新上映的最火的剧叫什么
有些页面的 content 字段值可能会出现:
空字符串:这是因为防止用户等待时间较长,代码中有设置超时时间,如果长时间未响应,或者请求发生异常,则会直接返回 “空字符串”;
拿不到页面真实数据:如上图 ② 提示 “百度安全校验” 等等,这是因为有些网站有反爬虫机制,或者是异步渲染,这会导致我们拿不到真实的文本信息;
增加聚合的搜索引擎
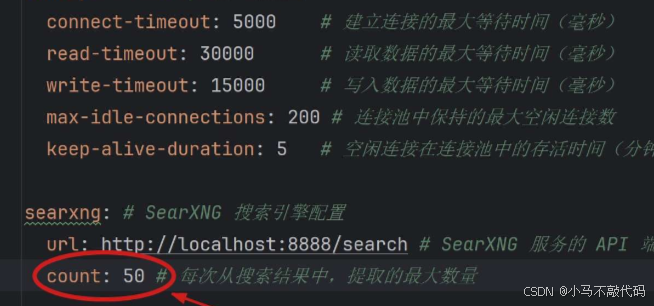
考虑上述问题的存在,我们可以增加提取搜索结果的最大数量,如 50 页,以免样本数太少,导致能够提供给 AI 大模型的信息太少,无法正确回答问题的情况发生!
如何提升 SearXNG 获取的搜索结果数呢?可以增加聚合的搜索引擎数量。进入到 SearXNG 的 “首选项” 中,如下图,将所有搜索引擎都勾选上:
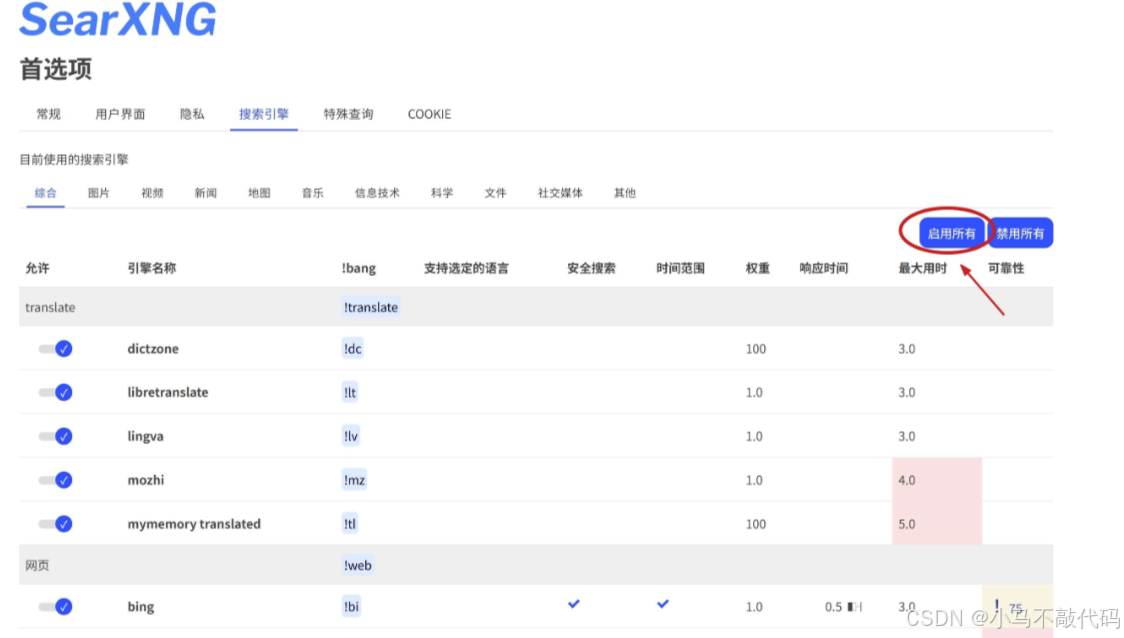
然后,执行一下搜索,看看效果,如下图,点击展开右侧栏的 “响应时间”,就能看到哪些搜索引擎基于本地的网络环境,能够成功获取响应,哪些获取不到响应了(由于墙的原因):
TIP: 如果你有科学上网方式,建议开下自动代理,这样能够拿到的搜索结果会更多。
知道哪些搜索引擎响应正常后,就可以在请求 SearXNG API 接口时,将它们都添加到 engines 参数中:
// 构建 SearXNG API 请求 URL
HttpUrl httpUrl = HttpUrl.parse(searxngUrl).newBuilder()
.addQueryParameter("q", query) // 设置搜索关键词
.addQueryParameter("format", "json") // 指定返回 JSON 格式
.addQueryParameter("engines", "wolframalpha,presearch,seznam,mwmbl,encyclosearch,bpb,mojeek,right dao,wikimini,crowdview,searchmysite,bing,naver,360search") // 指定聚合的目标搜索引擎(配置本地网络能够访问的通的搜索引擎)
.build();
重启后端项目,再次测试一下。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)