Meta开源“语言神器“:1600种语言ASR系统,元宇宙又要卷土重来?
Meta开源全语言语音识别系统OmnilingualASR,支持1600+种语言(含500种首次被AI识别的语言)。该系统突破性地采用70亿参数语音编码器和大语言模型架构,实现"零样本"学习新语言的能力。通过Apache 2.0许可证完全开源,包括模型家族和350种语言的语料库。这一技术突破标志着AI发展从追求极致性能转向包容普惠,使边缘语言群体首次获得数字话语权。虽然10%的
尽管自动语音识别(ASR)系统在诸多高资源语言领域已取得显著进展,但全球 7000 多种语言中的大部分仍未得到支持,数千种长尾语言实际上被忽视了。
长久以来,扩展 ASR 覆盖范围被视作成本高昂且基准价值有限之举。而将语言覆盖范围限定于固定集合的架构,进一步阻碍了扩展进程,使得大多数社区难以开展扩展工作。这一切还关联着缺乏社区合作扩展计划所引发的伦理问题。

而最近,Meta FAIR团队甩出一颗重磅炸弹——Omnilingual ASR(全语言自动语音识别)系统。不是PPT,不是Demo,是直接开源的那种。这套系统能听懂超过1600种语言,其中500种是历史上第一次被AI"听见"。更狠的是,他们还把核心模型、70亿参数的底座、350种语言的语料库,一股脑全放了出去。
当我看到这个消息时,脑海里浮现的是南美雨林里,一位用濒危语言讲述传说的老人;是非洲部落中,围绕篝火用母语吟唱的青年;是东南亚山村,用方言叫卖手工艺品的妇人。他们的声音,曾因为"商业价值不足"被AI时代遗忘。而今天,Meta说:每一种声音都值得被记录。

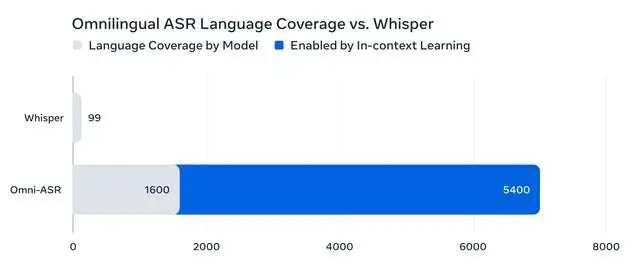
打破"语言精英主义":从99种到1600种的跃迁
在Omnilingual ASR出现前,业界标杆是OpenAI的Whisper,支持99种语言。听起来不少?但全球现存7000多种语言中,超过95%长期被AI语音技术忽视。头部公司把资源砸在英语、中文、西班牙语等"高富帅"语言上,因为数据多、商业回报高。
这种"语言精英主义"造成了触目惊心的数字鸿沟。想象一下,当你的孩子能用AI助手学英语、练口语时,远在巴布亚新几内亚的孩子,连用自己母语搜索信息都做不到。技术本该是平权工具,却成了新的不平等源头。
Meta这次狠狠撕开了这个口子。1600种语言是什么概念?这意味着:
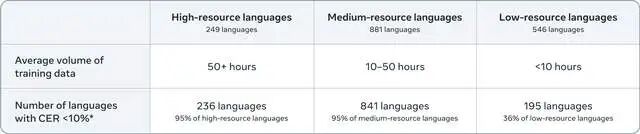
78%的语言字符错误率低于10%(CER<10%)
如果某种语言有10小时以上训练音频,达标率飙升到95%
即便是数据极度匮乏的"低资源语言",仍有36%实现了可用水平
这些数字背后,是非洲部落、南美原住民、东南亚少数民族第一次拥有了"数字声音"。
技术深水区:70亿参数+大语言模型+"自带语言"魔法
作为从业者,我更关心的是:Meta到底怎么做到的?
第一板斧:把wav2vec 2.0怼到70亿参数
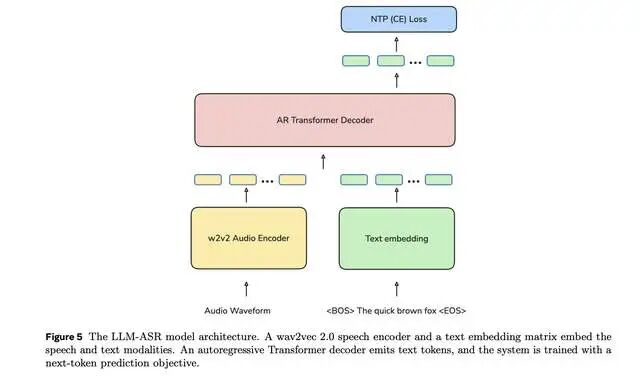
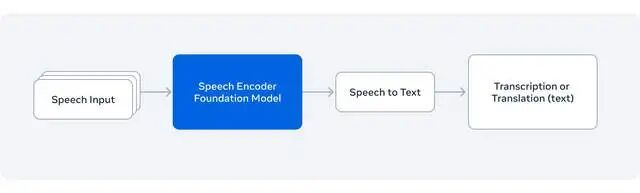
Meta首次将自家的语音编码器扩展到70亿参数规模,从430万小时的多语言原始音频中,"听"出了跨语言的通用语音表征。这相当于让AI先学会"听人话"的底层逻辑,而不是死记硬背每种语言。
第二板斧:LLM-ASR架构跨界融合
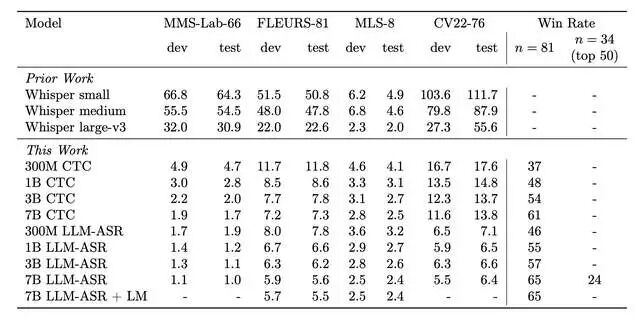
最妙的是引入了大语言模型(LLM)的Transformer解码器。传统ASR用CTC(连接主义时间分类)目标函数,像个死记硬背的学霸;而LLM-ASR则像个会举一反三的语言学家,尤其在"长尾语言"上表现炸裂。7B-LLM-ASR版本在1600多种语言上全面达到SOTA(state-of-the-art)。
第三板斧:真正的"零样本"学习
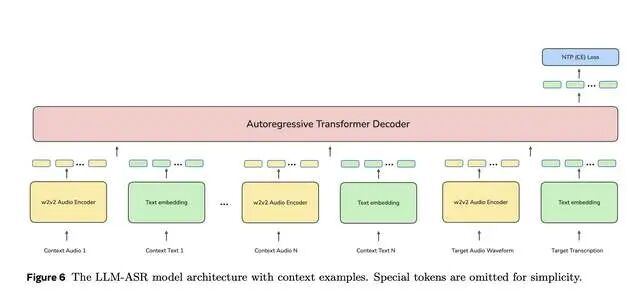
这才是改变游戏规则的杀招。Omnilingual ASR提出了"自带语言"(Language-in-the-Box)功能——用户只需提供3-5段音频-文本配对样本,系统就能通过上下文学习,当场学会一门新语言,无需重新训练。
这意味着什么?理论上,这套系统可扩展到5400多种语言,几乎覆盖所有有文字记录的语言。一位语言学家带着录音设备走进亚马逊部落,现场录几句对话,就能当场生成转录工具。这不再是科幻。
在建模层面,Omnilingual ASR 将自监督预训练拓展至 70 亿个参数,以学习稳健的语音表征,并引入了一种专为零样本泛化设计的编码器 - 解码器架构,借助大型语言模型启发式解码器来高效利用这些表征。此功能依托于庞大且多样的训练语料库。通过融合广泛的覆盖范围与语言多样性,该模型学习到足够强大的表征,能够适应此前从未见过的语言。
Omnilingual ASR 整合了公共资源以及通过付费本地合作收集的社区录音,将覆盖范围拓展至 1600 多种语言,堪称迄今为止规模最大的此类项目。其中包含 500 多种此前任何 ASR 系统都未曾覆盖的语言。
自动评估显示,与先前的系统相比,Omnilingual ASR 的性能有了显著提升,尤其是在资源极度匮乏的情形下,并且对训练过程中从未遭遇过的语言具备强大的泛化能力。
至关重要的是,Omnilingual ASR 以模型系列的形式发布,从适用于低功耗设备的 3 亿字节紧凑型模型到用于实现最高精度的 70 亿字节大型模型,一应俱全。
开源核弹:Apache 2.0许可证背后的野心
Meta这次没玩"有限开源"那套把戏。全套系统采用Apache 2.0许可证发布——这是商业友好度最高的开源协议之一。研究人员能免费用,创业公司能商用,开发者能随意魔改。
随系统发布的还包括:
Omnilingual ASR语料库:350种低资源语言的转录数据(CC-BY许可)
Omnilingual wav2vec 2.0:70亿参数的语音表示模型
从3亿到70亿参数的完整模型家族:兼顾手机端和服务器端
这步棋走得极狠。如果说OpenAI的Whisper是"开源但我说了算",Meta这次直接"把底裤都脱了"。想想当年Llama开源如何颠覆大语言模型格局,就能理解这次Omnilingual ASR对语音领域的冲击。
我的观点:AI发展的"包容性拐点"
作为一个观察AI多年的从业者,我认为Omnilingual ASR的意义远超技术本身。它标志着AI发展正在经历一个重要拐点:从"极致性能"转向"包容普惠"。
过去几年,AI竞赛的关键词是"刷榜"、"SOTA"、"干掉人类"。所有火力集中在让英语识别准确率从95%提升到96%、97%。但问题是:在7000种语言里,英语只是1/7000。 你让英语识别准确率达到99.9%,对那95%没有AI支持的语言来说,意义为零。
Meta这次做了一个"反常识"选择:牺牲部分顶尖语言的极致性能,去换取覆盖1600种语言的普惠能力。结果呢?78%的语言可用,500种语言"绝处逢生"。如果把AI比作教育,这不再是只培养几个清华北大状元,而是搞起了全民义务教育。
更值得玩味的是社区共建的模式。Omnilingual ASR被设计为"社区驱动框架",全球语言学家、开发者、原住民社区都能参与进来,用自己的数据完善模型。这与OpenAI的"技术寡头"模式形成鲜明对比——Meta似乎在学Linux,而不是Apple。

当然,冷水也要泼一盆:
错误率10%对低资源语言仍是挑战,尤其在噪音环境或方言变体下
数据依赖依然存在,完全没有录音的语言还是无法覆盖
商业化路径不明,小语种ASR怎么赚钱?Meta没回答
但瑕不掩瑜。当一家硅谷巨头愿意投入资源,去服务"商业价值稀薄"的边缘语言时,这已经是一种态度宣言:技术的终极价值,不是让强者更强,而是让弱者不被落下。
写在最后:语言是文明的基因库
我们常说"语言是文化的载体",但更准确的说法是:语言本身就是文明。每一种语言都承载着独特的世界观、哲学思考和生存智慧。当一种语言消亡,一种认知世界的方式就永远消失了。
在AI时代之前,保护濒危语言靠语言学家的录音笔记,效率极低。而Omnilingual ASR这类技术,让大规模、低成本的语音文献化成为可能。一位非洲语言学家在博客中写道:"现在我们可以用AI帮助族人记录祖先的语言,让第三代移民孩子仍能听懂奶奶的故事。"技术的光,只有照到每个人身上,才算真正的光。
所以,给Meta这次的开源,点个赞。不是因为它是完美的,而是因为它指向了一个更人性化的AI未来。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)