AI导读AI论文: CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced
为解决现有CAD模型生成方法(如依赖 latent vectors、点云,数据获取难、存储成本高)及传统多模态大语言模型(MLLMs,如GPT-4)3D空间推理能力弱的问题,研究团队提出CAD-GPT——一种基于的空间推理增强型多模态LLM,可通过单张图像或文本描述生成CAD建模序列;其核心是3D建模空间定位机制,将3D空间位置、3D草图平面旋转角映射到1D语言特征空间,并离散2D草图坐标,同时引

1. 一段话总结
为解决现有CAD模型生成方法(如依赖 latent vectors、点云,数据获取难、存储成本高)及传统多模态大语言模型(MLLMs,如GPT-4)3D空间推理能力弱的问题,研究团队提出CAD-GPT——一种基于LLaVA1.5 7B的空间推理增强型多模态LLM,可通过单张图像或文本描述生成CAD建模序列;其核心是3D建模空间定位机制,将3D空间位置、3D草图平面旋转角映射到1D语言特征空间,并离散2D草图坐标,同时引入三类定制token(3D朝向、3D坐标、2D草图)及可学习位置嵌入;数据集基于DeepCAD构建,包含160k固定视角CAD图像和18k高质量文本描述;实验表明,CAD-GPT在定量(图像输入下median CD 9.77、IR 1.61%,文本输入下median CD 28.33、IR 7.43%)和定性上均显著优于DeepCAD、GPT-4等SOTA方法,大幅提升CAD模型生成的精度与有效性。
2. 思维导图(mindmap)
## 研究背景与问题
- CAD技术的行业价值:设计效率、精度提升,广泛应用于制造业
- 现有方法局限
- 生成模型(VAE/VQ-VAE):依赖高维latent vectors,易累积误差,数据难获取
- 点云/草图驱动:点云需专业设备(成本高),草图需专业绘制
- MLLMs(如GPT-4):3D空间推理弱,CAD生成失败率高(30%-50%)
- 核心研究问题:如何增强MLLMs的3D空间推理能力以实现精准CAD生成
## CAD-GPT模型架构与机制
- 基础架构
- 底座模型:LLaVA1.5 7B(基于Vicuna-LLaMA2)
- 三大模块:ViT-L/14-336px视觉编码器、视觉-语言线性投影层、LLM推理层
- 核心机制:3D建模空间定位机制
- 定制token设计(新增至LLM词汇表)
- 3D草图平面朝向token:<An>(n∈0-728,θ/ϕ/γ各离散为9级)
- 3D坐标定位token:<Pk>(k∈0-36³-1,1×1×1立方体离散为36³网格)
- 2D草图坐标token:<SlX>/<SmY>(l/m∈0-127,2D坐标量化为128级)
- 可学习位置嵌入:W_angle(729×D)、W_3D_pos(36³×D)、W_2D_sketch_x/y(128×D)
## 数据集构建
- 数据来源:DeepCAD(178,238个CAD建模序列,去重后使用)
- 数据类型与规模
- 图像数据:OpenCascade渲染160k固定视角CAD图像,配套10类生成指令
- 文本数据:GPT-4o筛选19k可描述模型→InstructGPT生成→人工清洗,最终18k文本描述
- 数据格式:图像-CAD序列、文本-CAD序列(适配LLaVA微调格式)
## 实验设置与结果
- 实验设置
- 训练策略:两阶段(先image2CAD,后text2CAD,学习率2e-5→降低,4×A800 GPU,批大小8,总时长96h)
- 评价指标:Chamfer距离(CD)、无效率(IR)、命令准确率(ACC_cmd)、参数准确率(ACC_param)
- 实验结果
- 图像输入对比(表3):CAD-GPT vs 基线(DeepCAD/SkexGen/HNC-CAD/GPT-4)
- median CD:9.77(比HNC-CAD低48%,比GPT-4低84%)
- IR:1.61%(比HNC-CAD低91%,比GPT-4低97%)
- ACC_cmd/ACC_param:99.21%/98.87%(超所有基线)
- 文本输入对比(表4):CAD-GPT vs LLaMA-3.1/GPT-4
- median CD:28.33(比GPT-4低83%)
- IR:7.43%(比GPT-4低90%,比LLaMA-3.1低92%)
- ACC_cmd/ACC_param:98.73%/98.12%(超基线6%以内)
- 消融研究(表5):验证token+嵌入的有效性(无Loc时IR 37.15%→有Loc+Emb时1.61%)
## 结论与核心贡献
- 首次提出专为CAD建模序列生成设计的MLLM(CAD-GPT)
- 创新3D空间定位机制:3D空间→1D语言特征空间映射,提升空间推理
- 构建并将开源160k图像+18k文本的CAD数据集
- 实验验证CAD-GPT在image2CAD和text2CAD任务上的SOTA性能
3. 详细总结
一、研究核心背景(摘要与引言)
- CAD技术的重要性:计算机辅助设计(CAD)是制造业设计的标准工具,通过2D/3D建模、分析优化提升设计效率与精度,几乎所有工业产品均源于参数化CAD工具。
- 现有CAD生成方法的局限:
- 生成模型(VAE/VQ-VAE):如DeepCAD(2021)、HNC-CAD(2023),依赖高维latent vectors或codebooks,数据获取难且易累积误差;
- 点云/草图驱动:如CADSIGNet(2024),点云需专业设备采集(成本高),草图需专业人员绘制;
- 传统MLLMs:如GPT-4、Qwen2-VL-Max,3D空间推理能力弱,CAD生成失败率高(30%-50%),常出现“车轮水平放置”“桌腿超桌面”等空间错误。
- 研究目标:提出CAD-GPT,增强MLLMs的3D空间推理能力,实现从单张图像或文本描述到精准CAD建模序列的生成。
二、相关工作梳理
| 研究方向 | 核心方法与局限 |
|---|---|
| 近似3D表示 | 点云(缺表面细节)、网格(复杂度高)、3D高斯(缺精准表面)、NeRF(算力/数据需求大) |
| CAD模型表示 | 1. 直接B-rep生成:合成参数曲线/曲面,难转化为建模序列;2. 建模序列生成:DeepCAD/HNC-CAD依赖latent vectors,CADSIGNet依赖点云 |
| MLLMs应用 | 集成LLM与LVM,可生成网页代码/OCR推理,但未适配CAD建模序列生成 |
| 用户控制2D/3D建模 | IconShop(文本→SVG)、CAD-Llama(LLM→参数CAD)、Query2CAD(GPT→CAD代码),但失败率高 |
三、CAD-GPT方法设计
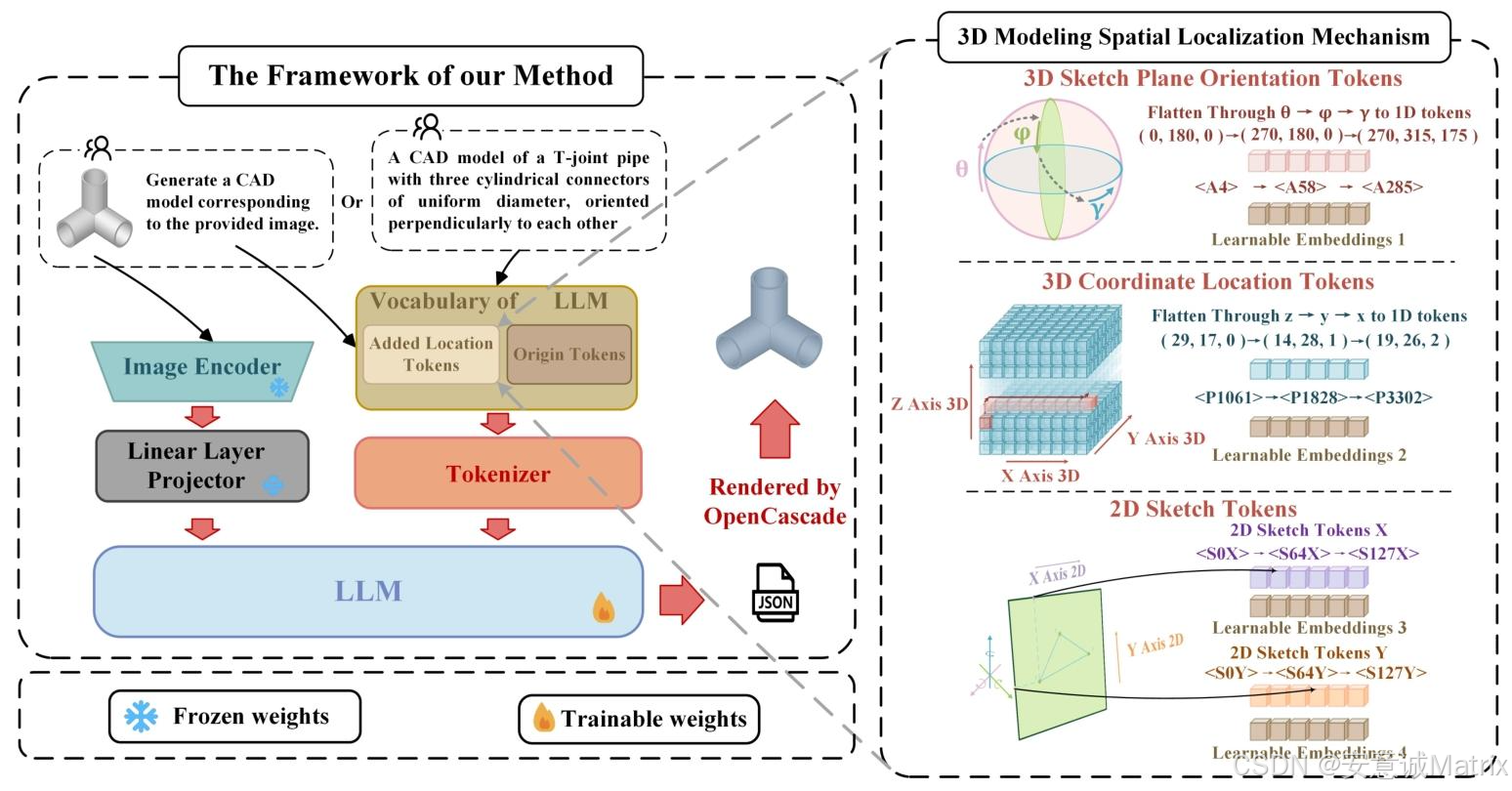
1. 模型架构
- 基础框架:基于LLaVA1.5 7B(底座为Vicuna-LLaMA2),包含三大模块:
- 视觉编码器(g):预训练ViT-L/14-336px,输入图像IVI_VIV输出视觉特征Zv=g(IV)Z_v = g(I_V)Zv=g(IV);
- 视觉-语言投影层(P):2层线性层,将ZvZ_vZv映射到文本特征空间,得到视觉tokenSvS_vSv;
- LLM推理层(fϕf_\phifϕ):处理SvS_vSv、指令tokenSinstructS_{instruct}Sinstruct,按概率生成CAD序列SaS_aSa,公式为:
p(Sa∣IV,Sinstruct)=∏i=1LpΘ(xi∣SV,Sinstruct,Sa,<i)p\left(S_{a} | I_{V}, S_{instruct }\right)=\prod_{i=1}^{L} p_{\Theta}\left(x_{i} | S_{V}, S_{instruct }, S_{a,<i}\right)p(Sa∣IV,Sinstruct)=i=1∏LpΘ(xi∣SV,Sinstruct,Sa,<i)
- 训练策略:冻结视觉编码器与投影层权重,全量微调LLM;输入为“图像-CAD序列”“文本-CAD序列”混合数据。
2. CAD命令序列表示
- 遵循DeepCAD格式,以JSON存储建模操作序列(人类可读、易编辑,适配LLaMA2预训练知识);
- 核心命令与参数(表1):
命令(Command) 关键参数(Parameters) Line(直线) 2D起点(x,y)、2D终点(x,y) Arc(圆弧) 2D起点(x,y)、2D中点(x,y)、2D终点(x,y) Circle(圆) 2D起点(x,y)、2D圆心(x,y) Extrude(拉伸) 3D草图平面朝向(θ,ϕ,γ)、3D草图原点((p_x,p_y,p_z))、拉伸比例(s)、拉伸距离(e1,e2)、类型(b,u) - 序列结构:M=[C1,...,CNc]M=[C_1,...,C_{N_c}]M=[C1,...,CNc],每个Ci=(ti,pi)C_i=(t_i,p_i)Ci=(ti,pi)(tit_iti为命令类型,pip_ipi为参数),通过“绘制2D草图→拉伸为3D”迭代生成模型。
3. 核心创新:3D建模空间定位机制
- 解决痛点:MLLMs难以精准推断3D草图平面朝向、3D原点坐标、2D草图坐标;
- 设计思路:将3D空间信息转化为LLM可理解的定制token,并引入可学习嵌入;
- 具体实现(表2):
定制token类型 设计细节 数量/范围 3D草图平面朝向token θ→ϕ→γ顺序离散(各9级),映射为1D token n∈0-728(共729个) 3D坐标定位token CAD模型归一化到1×1×1立方体,z→y→x顺序离散为(K^3)网格(K=36),映射为 k∈0-36³-1(共46656个) 2D草图坐标token 2D草图归一化到边界框,x/y坐标各量化为128级,映射为/ l/m∈0-127(各128个) 边界token 标记token类型,如、</spatial position> - - 可学习嵌入:新增4类嵌入矩阵,增强空间信息表示:
Wangle∈R729×DW_{angle} \in \mathbb{R}^{729×D}Wangle∈R729×D、W3D_pos∈R46656×DW_{3D\_pos} \in \mathbb{R}^{46656×D}W3D_pos∈R46656×D、W2D_sketch_x∈R128×DW_{2D\_sketch\_x} \in \mathbb{R}^{128×D}W2D_sketch_x∈R128×D、W2D_sketch_y∈R128×DW_{2D\_sketch\_y} \in \mathbb{R}^{128×D}W2D_sketch_y∈R128×D。
四、数据集构建
- 基础数据:基于DeepCAD数据集(178,238个CAD建模序列,去重后使用);
- 图像数据生成:
- 工具:OpenCascade(开源CAD渲染工具);
- 内容:为每个CAD模型生成固定视角2D图像;
- 规模:160k图像,配套10类生成指令(如“基于提供的图像创建CAD模型”),微调时随机选择指令;
- 文本数据生成:
- 筛选:GPT-4o结合JSON与渲染图像,筛选19k可描述的CAD模型;
- 生成:基于InstructGPT pipeline生成文本描述;
- 清洗:人工剔除无关/错误描述,最终保留18k高质量文本;
- 数据格式:适配LLaVA微调格式,分为“图像-CAD序列”(160k)、“文本-CAD序列”(18k)两类。
五、实验结果与分析
1. 实验设置
- 硬件:4×NVIDIA RTX A800 GPU;
- 训练参数:批大小8/GPU,总时长96h,初始学习率2e-5(CosineWarmup策略,暖身比0.3),最大输入序列长度扩展到8192;
- 评价指标:
- 定量:Chamfer距离(CD,越小越好)、无效率(IR,%,越小越好)、命令准确率(ACC_cmd,%,越大越好)、参数准确率(ACC_param,%,越大越好);
- 定性:视觉对比CAD模型的空间合理性与细节完整性。
2. 图像输入下的性能(表3)
| 模型 | IR(%)↓ | Median CD ↓ | ACC_cmd(%)↑ | ACC_param(%)↑ |
|---|---|---|---|---|
| DeepCAD | 23.16 | 23.78 | 95.34 | 96.23 |
| SkexGen | 22.32 | 20.45 | 95.82 | 96.63 |
| HNC-CAD | 18.64 | 18.64 | 97.87 | 97.77 |
| GPT-4 | 64.37 | 62.64 | 98.22 | 97.36 |
| CAD-GPT | 1.61 | 9.77 | 99.21 | 98.87 |
- 关键结论:CAD-GPT的median CD比最佳基线HNC-CAD低48%,IR比GPT-4低97%,在所有指标上均显著领先,且生成模型细节完整、空间合理(如无“车轮水平”错误)。
3. 文本输入下的性能(表4)
| 模型 | IR(%)↓ | Median CD ↓ | ACC_cmd(%)↑ | ACC_param(%)↑ |
|---|---|---|---|---|
| LLaMA-3.1 | 98.68 | NA | NA | NA |
| GPT-4 | 76.97 | 187.52 | 92.21 | 93.65 |
| CAD-GPT | 7.43 | 28.33 | 98.73 | 98.12 |
- 关键结论:CAD-GPT的median CD比GPT-4低83%,IR比LLaMA-3.1低92%,可精准生成符合文本描述的模型(如“带圆形孔的钥匙”“三层开放式书架”),而LLaMA-3.1几乎无法生成有效模型,GPT-4常出现空间错误。
4. 消融研究(表5):验证3D空间定位机制的有效性
| 输入类型 | 模型配置 | IR(%)↓ | Median CD ↓ | ACC_cmd(%)↑ | ACC_param(%)↑ |
|---|---|---|---|---|---|
| 图像输入 | w/o Loc(无token+嵌入) | 37.15 | 161.31 | 90.45 | 91.37 |
| 图像输入 | w/o Emb(有token无嵌入) | 4.31 | 27.98 | 91.63 | 91.55 |
| 图像输入 | CAD-GPT(token+嵌入) | 1.61 | 9.77 | 99.21 | 98.87 |
| 文本输入 | w/o Loc(无token+嵌入) | 40.23 | 145.87 | 83.42 | 83.44 |
| 文本输入 | w/o Emb(有token无嵌入) | 10.12 | 29.58 | 87.54 | 88.23 |
| 文本输入 | CAD-GPT(token+嵌入) | 7.43 | 28.33 | 98.73 | 98.12 |
- 关键结论:同时引入“定制token+可学习嵌入”可最大程度提升性能,证明3D空间定位机制是CAD-GPT空间推理能力的核心。
六、核心贡献与结论
- 方法创新:首次提出专为CAD建模序列生成设计的MLLM(CAD-GPT),支持图像/文本双输入;
- 机制突破:设计3D建模空间定位机制,通过“3D空间→1D语言特征空间”映射,解决MLLMs空间推理弱的问题;
- 数据贡献:构建并计划开源包含160k图像+18k文本的CAD数据集,填补领域数据空白;
- 性能验证:实验表明CAD-GPT在image2CAD和text2CAD任务上均达到SOTA,为CAD自动化设计提供新方案。
4. 关键问题
问题1:CAD-GPT通过何种核心设计解决了传统MLLMs(如GPT-4)在CAD模型生成中的3D空间推理不足问题?
答案:CAD-GPT的核心解决方案是3D建模空间定位机制,具体包含两部分设计:
- 定制空间token:将3D空间信息转化为LLM可理解的语言token,包括:①3D草图平面朝向token(,n∈0-728,通过离散θ/ϕ/γ三个旋转角实现3D平面朝向的精准表示);②3D坐标定位token(,k∈0-46655,将CAD模型归一化到1×1×1立方体后离散为36³网格,实现3D原点坐标的精准映射);③2D草图坐标token(/,l/m∈0-127,将2D草图坐标量化为128级,确保2D绘制精度);
- 可学习空间嵌入:新增4类可学习嵌入矩阵(WangleW_{angle}Wangle、W3D_posW_{3D\_pos}W3D_pos、W2D_sketch_xW_{2D\_sketch\_x}W2D_sketch_x、W2D_sketch_yW_{2D\_sketch\_y}W2D_sketch_y),强化空间信息与语言特征的对齐,让LLM能像理解文字一样推理3D空间关系,避免“车轮水平”“桌腿超桌面”等空间错误。
问题2:CAD-GPT的数据集是基于何种基础构建的?包含哪些关键数据类型,各类型的规模与生成流程是什么?
答案:CAD-GPT的数据集基于DeepCAD数据集(含178,238个CAD建模序列,需先去重)构建,包含“图像-CAD序列”和“文本-CAD序列”两类关键数据,具体如下:
- 图像-CAD序列数据:
- 规模:160k个样本;
- 生成流程:使用OpenCascade工具为每个去重后的CAD模型生成固定视角2D图像,同时设计10类生成指令(如“基于提供的图像创建CAD模型”),微调时随机为图像匹配指令,形成“图像+指令→CAD序列”的样本对;
- 文本-CAD序列数据:
- 规模:18k个样本;
- 生成流程:①筛选:GPT-4o结合CAD模型的JSON文件与渲染图像,剔除无法描述的模型,保留19k个可描述模型;②生成:基于InstructGPT pipeline为19k模型生成文本描述;③清洗:人工剔除无关、错误的描述,最终保留18k个高质量文本,形成“文本→CAD序列”的样本对。
问题3:从定量实验结果看,CAD-GPT在“图像输入”和“文本输入”场景下,相比基线模型(如HNC-CAD、GPT-4)分别有哪些核心优势?请用关键数据说明。
答案:CAD-GPT在两类输入场景下均展现显著优势,核心定量对比如下:
- 图像输入场景(对比HNC-CAD、GPT-4等,表3):
- 精度优势:median CD(衡量3D重建精度)为9.77,比最佳基线HNC-CAD(18.64)低48%,比GPT-4(62.64)低84%;
- 有效性优势:无效率(IR,生成无效模型的比例)为1.61%,比HNC-CAD(18.64%)低91%,比GPT-4(64.37%)低97%;
- 准确性优势:命令准确率(ACC_cmd)99.21%、参数准确率(ACC_param)98.87%,均高于所有基线(HNC-CAD最高为97.87%/97.77%);
- 文本输入场景(对比LLaMA-3.1、GPT-4,表4):
- 精度优势:median CD为28.33,比GPT-4(187.52)低83%(LLaMA-3.1无法生成有效模型,无CD数据);
- 有效性优势:IR为7.43%,比GPT-4(76.97%)低90%,比LLaMA-3.1(98.68%)低92%;
- 准确性优势:ACC_cmd 98.73%、ACC_param 98.12%,比GPT-4(92.21%/93.65%)高6%以内,而LLaMA-3.1无有效ACC数据。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)