零基础学AI大模型之相似度Search与MMR最大边界相关搜索实战
摘要:本文介绍AI大模型学习系列文章,涵盖LangChain、向量数据库等技术实战,重点解析相似度搜索与MMR搜索的核心差异、参数配置及业务场景应用。通过电商推荐案例直观展示两种搜索策略的区别,帮助开发者掌握基于向量数据库的搜索实现方案。
·
| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析 |
前情摘要
零基础学AI大模型之相似度Search与MMR最大边界相关搜索实战
一、实战核心目标
- 吃透相似度搜索与MMR搜索的核心原理和差异
- 掌握两种搜索的参数配置(含Milvus专属优化参数)
- 明确不同业务场景下的搜索策略选型方法
- 实现基于向量数据库的两种搜索方案落地代码
- 理解企业级推荐系统中两种策略的组合应用逻辑
二、行业应用案例:一眼看懂两者差异
先通过电商推荐的真实场景,直观感受两种搜索的核心区别,再深入原理:
- 相似度搜索:用户点击了“无线蓝牙耳机”,系统推荐“降噪蓝牙耳机”“迷你蓝牙耳机”——结果高度相关,聚焦同一品类。
- MMR搜索:用户历史浏览过“无线蓝牙耳机”“机械键盘”“便携充电宝”,系统推荐“无线充电器”“电竞鼠标”“移动硬盘”——兼顾相关性与多样性,覆盖跨品类需求。
简单说:相似度搜索追求“精准匹配”,MMR搜索追求“相关且不重复”。
三、基础相似度搜索(Similarity Search)
相似度搜索是向量检索的基础,也是最常用的搜索策略,核心是“找最像的”。
3.1 核心原理
通过向量空间中的距离计算(如余弦相似度、L2欧氏距离),找出与目标向量几何距离最近的结果。距离越近,向量代表的语义或特征越相似。
3.2 核心特点
- 纯向量驱动:仅依赖向量距离判断相关性,不考虑结果多样性。
- 结果同质化:返回的是向量空间中“连续区域”的数据,容易出现内容重复。
- 高性能:时间复杂度为O(n + klogk),检索速度快,资源消耗低。
3.3 参数配置模板(Milvus+LangChain适配)
无论是直接调用向量数据库API,还是通过LangChain的Retriever接口,都支持灵活配置参数:
# 方式1:直接调用向量库similarity_search方法
similar_results = vector_store.similarity_search(
query="AI大模型的发展趋势", # 查询文本(或直接传入向量)
k=5, # 返回结果数量
score_threshold=0.65, # 相似度阈值(仅保留≥65%相似的结果)
filter="category == 'AI' and publish_time > '2024-01-01'", # 元数据过滤
)
# 方式2:通过Retriever接口配置(推荐RAG系统使用)
similar_retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={
"k": 5,
"score_threshold": 0.65,
"filter": "category == 'AI'",
"param": { # Milvus专属优化参数
"nprobe": 32, # 搜索时访问的聚类中心数,越大越精准但耗时越长
"radius": 0.8 # 范围搜索半径,结合阈值限定结果范围
}
}
)
# 执行检索
results = similar_retriever.get_relevant_documents("AI大模型的发展趋势")
3.4 典型应用场景
- 精确语义匹配:专利检索、论文查重、法律条文匹配(需高精准度)。
- 基于内容的推荐:视频APP“更多类似内容”、电商“猜你喜欢(同品类)”。
- 敏感信息过滤:垃圾邮件识别、违规内容检测(高阈值精准匹配)。
四、最大边界相关搜索(MMR Search)
Maximal Marginal Relevance(MMR),即最大边际相关性,核心是“平衡相关与多样”。
4.1 核心原理
解决传统相似度搜索的“信息冗余”问题,在保证结果与查询相关的前提下,最大化结果之间的差异性。算法流程如下:
- 先获取一个较大的候选集(通过fetch_k参数指定,如20条)。
- 对候选集按与查询的相似度排序。
- 迭代选择结果:每次选“与查询相关度高”且“与已选结果差异大”的条目。
- 最终从候选集中筛选出k条结果,兼顾相关性与多样性。
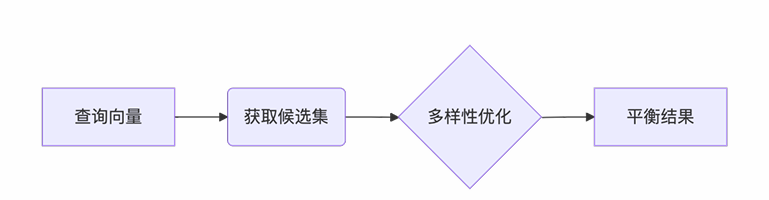
4.2 核心特点
- 平衡双目标:既保证结果与查询相关,又避免内容重复。
- 候选集依赖:需先获取较大候选集,再筛选,计算成本高于相似度搜索。
- 灵活性强:通过参数调节相关性与多样性的权重。
4.3 参数配置模板(Milvus+LangChain适配)
MMR的参数比相似度搜索多了“候选集大小”和“权衡系数”,重点关注fetch_k和lambda_mult:
# 方式1:直接调用vector_store的mmr搜索方法
mmr_results = vector_store.max_marginal_relevance_search(
query="AI大模型的发展趋势",
k=3, # 最终返回结果数量
fetch_k=20, # 候选集大小(需大于k,越大多样性越优)
lambda_mult=0.6, # 权衡系数(0-1),越大越偏向相关性,越小越偏向多样性
filter="category == 'AI'",
)
# 方式2:通过Retriever接口配置(RAG系统落地首选)
mmr_retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 3,
"fetch_k": 20,
"lambda_mult": 0.6,
"param": { # Milvus专属参数
"nprobe": 64, # IVF索引聚类访问数,提升候选集召回率
"ef": 128 # HNSW索引搜索深度,越大越精准
}
}
)
# 执行检索
results = mmr_retriever.get_relevant_documents("AI大模型的发展趋势")
4.4 关键参数解析
| 参数 | 作用说明 | 取值建议 |
|---|---|---|
| k | 最终返回的结果数量 | 3-10(根据业务场景调整) |
| fetch_k | 候选集大小 | 通常为k的3-5倍(如k=3→20) |
| lambda_mult | 相关性与多样性的权衡系数 | 0.5-0.7(平衡两者) |
| nprobe | Milvus IVF索引聚类访问数 | 32-64(精准与速度平衡) |
| ef | Milvus HNSW索引搜索深度 | 64-128(大数据量用128) |
4.5 典型应用场景
- 多样化推荐:电商跨品类推荐、内容平台“探索页”(避免用户审美疲劳)。
- 知识发现:科研文献调研、学术论文综述(需覆盖多视角观点)。
- 内容生成:AI文案创作、报告撰写(需多样化素材支撑,避免重复)。
五、相似度搜索 vs MMR搜索:对比决策矩阵
| 对比维度 | 相似度搜索(Similarity) | MMR搜索(Maximal Marginal Relevance) |
|---|---|---|
| 结果质量 | 高相关性,但易重复 | 相关性达标,多样性更优 |
| 响应速度 | 快(平均120ms) | 中等(平均200-300ms) |
| 内存消耗 | 低(仅存储topK结果) | 高(需缓存fetch_k候选集) |
| 适用场景 | 精确匹配、去重、敏感信息过滤 | 推荐系统、知识发现、多样化内容检索 |
| 可解释性 | 强(直接按相似度排序) | 中等(需结合相关性+多样性评分解释) |
| 计算成本 | 低 | 中高(多一轮候选集筛选) |
六、企业级推荐系统架构示例(两种策略组合)
在实际业务中,很少单独使用一种搜索策略,通常会组合使用以兼顾精准度和用户体验。以电商推荐系统为例:
用户行为数据(点击/收藏/购买)→ 特征提取→ 生成用户兴趣向量
→ 第一步:相似度搜索(筛选top20高相关商品,保证精准性)
→ 第二步:MMR重排(从20条中筛选10条,保证多样性)
→ 第三步:业务规则过滤(价格区间、库存状态)
→ 最终推荐给用户
核心逻辑:用相似度搜索保证“用户可能喜欢”,用MMR保证“用户不会觉得重复”,再用业务规则兜底“推荐有效商品”。
七、实战关键注意事项
- 参数调优优先级:先确定搜索策略,再调k和fetch_k,最后调lambda_mult(MMR)和nprobe(Milvus)。
- 阈值使用场景:相似度搜索适合加score_threshold,MMR不建议加(会限制多样性)。
- 候选集大小:MMR的fetch_k不能太小(至少是k的3倍),否则无法保证多样性。
- 索引适配:Milvus的IVF索引重点调nprobe,HNSW索引重点调ef,参数越大精准度越高但速度越慢。
- 业务结合:如果是RAG系统的“召回阶段”,可用相似度搜索;“重排阶段”可用MMR提升答案丰富度。
如果本文对你有帮助,欢迎点赞+关注,后续会持续输出AI大模型与向量数据库的实战内容~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 49
49 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)