「 LLM实战 - 企业 」构建工业级大模型文档处理流水线:解决截断、幻觉与延迟不确定性的端到端实践解决方案
本文记录了我在企业大模型实战项目中遇到的一个比较典型的问题,大模型生成不确定问题。本文记录了自己的解决思路和方案,有什么问题可以找我:codelinghu
最近在公司做大模型相关的项目,在做的过程中,出现了一个比较典型的问题:大模型输出不确定性问题。
所谓的大模型不确定问题指的是:
- 大模型中英翻译文档时内容总是被截断。
- 大模型翻译中英翻译的时候老是自我发挥,擅自做一些总结。
- 大模型做中英翻译的时候过程非常缓慢。
其实这三个问题在业界是非常典型的。那今天令狐小哥就带着大家逐一分析以上问题,并解决上面的问题。
文章目录
场景
环境
先说一下公司的GPU 用的是4090,49GB显存,双卡。单卡没法跑Qwen3-32B,但是双卡可以。我总共部署了两个大模型:
- Qwen32B
- Qwen7B
双卡同时跑两个模型度没问题,会吃掉60G的显存,亲测可用。
需求
有一堆英文的pdf文件,需要做结构化处理,具体来说就是把pdf文档转中文md、同时要做:
- 中英翻译
- 重要段落的提取
- 智能总结
其实这个场景还是比较常见对吧?千问的阅读助手,目前市面上主流的阅读助手工具:kimi、通义都有这个需求。
问题一:内容总是被截断
我主要是通过ollama把大模型在服务器跑起来以后暴露一个API出来,客户端去掉用。我在服务器部署了一个VLM-MinerU,这个MinerU也是比较吃显存的,然后通过调用MinerU的api实现OCR的效果,实现把英文的pdf转成Markdown文本(也是英文版的)。

你可以理解:我把pdf上传到MinerU,通过OCR得到了pdf的md版本,拿到了Markdown版本的文档。这样转换出来的md文档,里面有很多无序、杂乱的公式,那就导致md文档内容又臭又长,还是英文的。
当我把这些md文档交给了Qwen32b以后,qwen就开始去翻译这些又臭又长的md,翻译出来的中文内容翻译不到10句就停下了。这个时候我们可以先看一下,大模型的处理是否设置的是流式处理Stream*。*

如果你不是流式处理,而是让大模型直接把答案一大坨扔给你,那就是一口吃成胖子了。这种叫做同步处理。大模型的思考是通过消耗token来实现的,你可以理解成大模型在思考答案是要吃饭的,吃的是token。吃多少token就思考什么问题,明明是一个很难的问题,需要消耗大量的token,你直接就丢给了大模型一个长文本的问题,结果就是大模型罢工了,不干了,token不够啊。
流式处理的奥妙之处就是:一边思考一边消耗token。相当于你问了它一个很难的问题,它可以一边思考一边吃饭一边消耗token,一边输出答案。这不就友好多了吗?
问题二:大模型总是自由发挥
再把英文pdf转成了中文md的过程中,我们会给大模型提示词,让他不光要翻译pdf,还要帮忙总结,这个时候老出现一个问题:大模型要么不帮你把英文pdf翻译从中文,要么总结的时候给你乱总结,我要的是文章的摘要简介,它自己乱总结一通。
首先说一个常规的方案:
调节大模型的常规参数
大模型不听话,那就调节几个重要的参数:
- temperature
- top_p
1、调 temperature —— 控制“随机程度”
适用于:
- 想让模型更严谨、更稳定 → 调低(0.1–0.4)
- 想让模型更有创意、发散 → 调高(0.7–1.0)
- 需要“风格、语气”变化 → 调高
- 做翻译、代码、逻辑推理 → 调低
特点
- 线性影响所有 token 的概率分布
- 越高越乱,越低越稳
常用配置
- 代码:0.1–0.3
- 技术回答:0.3–0.5
- 创意写作:0.7–1.0
2、 调 top_p —— 控制“采样空间大小”
适用于:
- 你希望模型“有创意但不乱”
- 想限制输出只来自最可能的前 N% 的 token
- 用于 NLP 系统中细致调优模型“话太多/太少、啰嗦、飘”的情况
特点
- 不改变分布形状,只决定“采样的范围”
- 低 top_p → 模型更保守,只选“最常见用法”
- 高频用于 OpenAI 官方 GPT 采样策略(nucleus sampling)
常用配置
- 0.8–1.0 → 常规对话
- 0.4–0.7 → 更保守、少走偏
- <0.3 → 强约束文本(很少用)
3、把大模型的提示词设置为系统级提示词。
这里说的提示词是指你的翻译规则,或者你定下的规则,你把这个规则放在system里而不是user里。
4、将输入的数据集做转义处理。
原生的pdf数据里包含了很多公式、图表、各种公式索引啥的,奇奇怪怪的符号,一定要做转义处理。
在这里我是用了python的转义模块做的处理。
问题三:大模型翻译过程非常缓慢
其实这跟你机器配置有关了,我们的机器跑32B做翻译就是拿大炮打蚊子了。
怎么理解?
32B的大模型不适合用来做翻译,因为翻译不是一个深度推理的过程,翻译是一个简单的规则性的任务。所以在做翻译的时候,我们不需要考虑大参数的大模型,用一个7b的大模型就行了。
7b的大模型更适合做翻译,速度快啊,参数小。
终极解决方案
接下来分享一下我的解决方案,能够同时解决上面三个问题。啊,真的吗?还能同时解决三个问题。
对,大模型的不确定问题终归到底来说就是你输入的东西有问题,它执行处理的时候吃力了。
大模型擅长什么?
擅长推理!
但是我们让它一边翻译,一边推理,他就会乱来啊。如果你只是想翻译,那你就用小模型解决就行了。你让大模型去搞英语翻译,就类似于让中科院的院士去跟高中生玩速算、玩奥数。一个推理能力强的人,不代表规则性的东西玩的熟啊,他追求的是推理精度,不是速度。
按行块分割的思路
这个思路就是:把要处理的pdf、MD文档按行进行分块,再把每个块丢给大模型做翻译,翻译完再把结果拼接在一起。
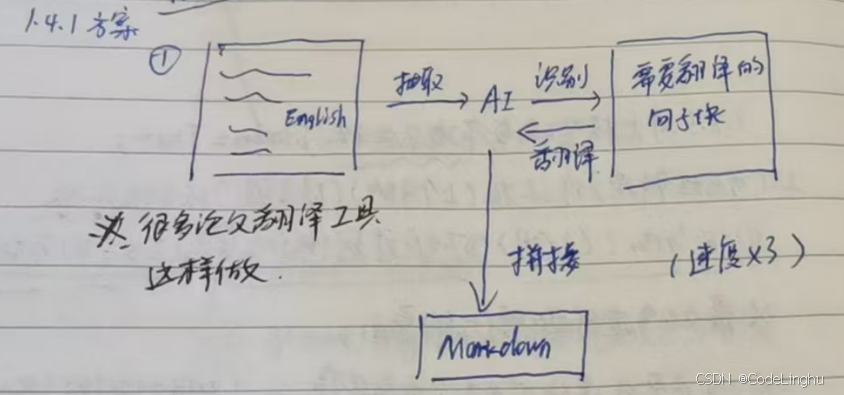
在这个思路里,大模型主要做两个工作:
- 识别文档里哪些是真正要翻译的内容,抛除掉图片链接、公式、其他乱七八糟的符号
- 进行中英翻译
怎么识别哪些内容需要翻译呢?
我们要翻译的是什么?
我们要翻译的是文本,我们不要的是啥?我们不要的是图片链接、公式…
那我的思路是写一个句子块提取器:

句子块提取器的主要职责:
- 把MD文档里的每一行拿出来,标一个号,id=标号;再把文本拿出来赋值给text,这样你就得到一个句子块,一个句子块就是上面图像上的一个json对象的样子,句子块我是这样写的:
# -*- coding: utf-8 -*-
# @Time : 2025/12/4 10:52
# @Author : linghu
# @File : sentence_splitter.py
# @Software: PyCharm
##
# 句子块抽取器模块
# #
from ollama import Client
import json
import re
from src.models.llm_client import LLMClient
from src.utils.config import get_config
class SentenceSplitter:
def __init__(self, model=None, host=None):
# 使用模块特定配置,如果没有则使用全局默认配置
self.host = host if host is not None else get_config("host", module="sentence_splitter")
self.model = model if model is not None else get_config("model", module="sentence_splitter")
self.client = LLMClient.get_client(self.host)
def split(self, content):
prompt = (
"你是一个严格的句子块抽取器。\n"
"请按照 Markdown 行结构,把每一行拆成可翻译句子块。\n"
"⚠️ 不要翻译、总结或合并。\n"
"输出 JSON 数组,每个元素包含 id 和 text:\n\n"
f"原文:\n{content}"
)
try:
resp = self.client.chat(
model=self.model,
messages=[{"role": "user", "content": prompt}],
stream=False
)
blocks = json.loads(resp["message"]["content"])
except Exception:
# Fallback
lines = content.splitlines()
blocks = [{"id": i, "text": l.strip()} for i, l in enumerate(lines) if l.strip()]
# 过滤英文
return [b for b in blocks if b["text"] and re.search(r"[A-Za-z]", b["text"])]
实际上id的行号最后统计出来是多少,那就说明你要翻译的这个文档有多少个句子块了。
AI大模型只需要翻译一个个的句子块就行了,一个句子块没多少文字的。翻译完所有句子块再通过id把所有句子块进行一个拼接就可以了。
AI再翻译句子块的时候,自然知道什么该翻译,什么不该翻译。
并发翻译
我们把行块划分好了,分割好了,成了一个个json。那现在需要丢给翻译模块翻译了:
# -------------------------------
# 步骤 2:并发翻译
# -------------------------------
async def translate_blocks(self, blocks):
semaphore = asyncio.Semaphore(self.concurrency)
async def _task(block):
async with semaphore:
return await self.translate_sentence(block)
tasks = [_task(b) for b in blocks]
results = await asyncio.gather(*tasks)
results.sort(key=lambda x: x["id"])
return results
翻译的时候就是通过json的id自增不断翻译的。并发翻译我设置的并发数是8.这个你可以自己调。
总结
大模型产生不确定,我们除了调几个常规的参数,我主要的思路还是针对数据集进行处理。
处理思路就是把数据集文本先按行拆分,拆成一个个json对象,美其名曰:句子块。拆解句子块的办法也是用大模型去拆,让大模型帮我拆出来,拆成json,用魔法打败魔法,事半功倍,提示词一定要写好哈!
prompt = (
"你是一个严格的句子块抽取器。\n"
"请按照 Markdown 行结构,把每一行拆成可翻译句子块。\n"
"⚠️ 不要翻译、总结或合并。\n"
"输出 JSON 数组,每个元素包含 id 和 text:\n\n"
f"原文:\n{content}"
)
拆成句子块以后,再把这些句子块丢给大模型让它按id去翻译,翻译完再拼接出来就是一篇翻译好的文章啦。
这是一种空间换时间的思路,如果我们把一大段的markdown文本直接丢给大模型,大模型会一下子把所有文本吞掉,开始推理训练。这个过程十分不确定,而且特别耗时。现在我们把大模型拆成句子块,让大模型只专注到了一个个句子块身上,把原本一大段的空间拆分成更小的空间,翻译更小的空间,再相连。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)