PIXELCRAFT: A MULTI-AGENT SYSTEM FOR HIGH-FIDELITY VISUAL REASONING ON STRUCTURED IMAGES翻译
结构化图像(例如图表和几何图形)对多模态大语言模型(MLLM)而言仍然是一个挑战,因为感知偏差可能导致错误的结论。中间视觉线索可以引导推理;然而,现有的基于线索的方法受限于低保真度的图像处理和线性、僵化的推理模式,限制了它们在复杂结构化图像任务上的有效性。本文提出了一种名为 **PixelCraft** 的新型多 Agent 系统,用于对结构化图像进行高保真度图像处理和灵活的视觉推理。**该系统包
摘要
结构化图像(例如图表和几何图形)对多模态大语言模型(MLLM)而言仍然是一个挑战,因为感知偏差可能导致错误的结论。中间视觉线索可以引导推理;然而,现有的基于线索的方法受限于低保真度的图像处理和线性、僵化的推理模式,限制了它们在复杂结构化图像任务上的有效性。本文提出了一种名为 PixelCraft 的新型多 Agent 系统,用于对结构化图像进行高保真度图像处理和灵活的视觉推理。该系统包含调度器、规划器、推理器、评估器和一组视觉工具智能体。为了实现高保真度处理,我们构建了一个高质量的语料库,并将 MLLM 微调为一个定位模型,该模型的像素级定位与工具智能体中的传统计算机视觉(CV)算法相结合。在此基础上,PixelCraft 通过动态的三阶段工作流程(工具选择、智能体讨论和自我批评)促进灵活的视觉推理。此外,与以往简单地附加历史图像的线性推理模式不同,PixelCraft 维护着图像记忆,使规划器能够自适应地重访早期的视觉步骤,探索不同的推理分支,并在讨论过程中动态调整推理轨迹。在具有挑战性的图表和几何基准测试中进行的大量实验表明,PixelCraft 显著提升了 MLLM 的视觉推理性能,为结构化图像推理树立了新的标杆。我们的代码可在 https://github.com/microsoft/PixelCraft 获取。
1.INTRODUCTION
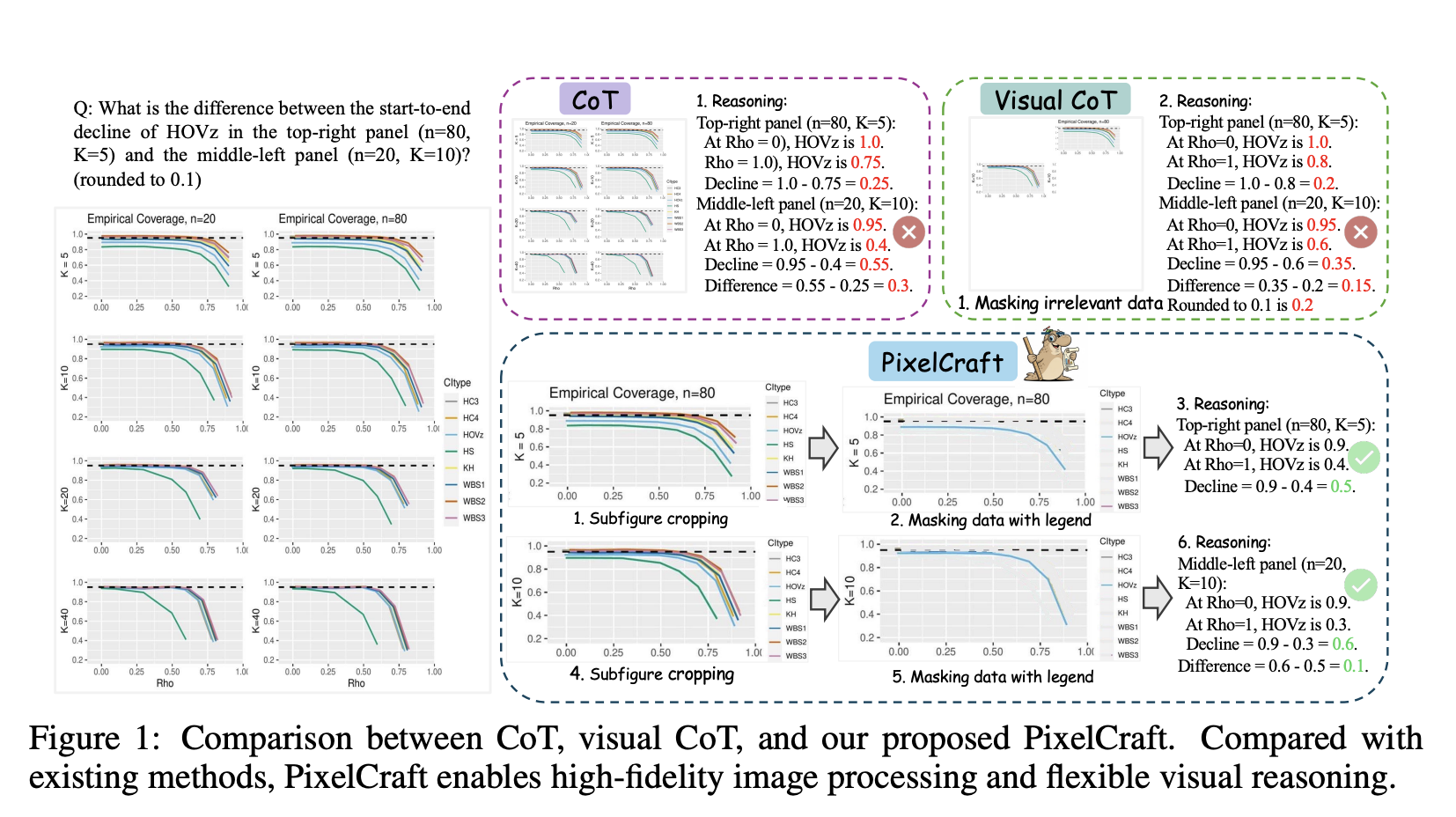
结构化图像,例如图表和几何图形,对当前的多模态大语言模型(MLLM)提出了巨大的挑战。自然图像通常以物体、纹理和局部视觉模式等形式为特征,这些特征可以被现有的视觉模型有效地捕捉;而结构化图像则编码了坐标、数据点、线连接和数值标注等符号和结构元素。解释这些结构化表示需要精确的符号抽象,而不仅仅是模式识别。此外,对结构化图像进行推理需要更高的粒度和精度。虽然粗略的视觉特征可能足以理解自然图像,但即使是结构化图像中细微的差异(例如,对单个柱状图高度的轻微误读)也可能显著改变对图像的解释和后续的推理。
为了增强对结构化图像的理解和推理能力,最初的策略(以思维链(CoT)为代表)侧重于通过专门的文本推理路径进行微调。然而,仅仅依赖文本推理往往会导致精细的空间和结构信息的丢失,难以捕捉诸如细微的视觉差异或几何约束等模式。近期的研究试图通过构建中间视觉线索来支持视觉思维链,从而解决这一局限性。尽管有此创新,但现有方法要么依赖于底层源代码(而这些源代码通常无法获取),要么只能提供低保真度的图像处理。因此,它们的适用范围仅限于特定的结构化图像集,并且在日益复杂和真实的基准测试(例如 CharXiv 和 ChartQAPro)上的性能仍然有限。
除了高保真图像处理之外,结构化图像理解还需要准确且灵活的多步骤视觉推理。然而,现有的大多数研究都集中于单步编辑或采用链式线性范式,其中每个中间图像都完全由其前一个图像推导而来。这种线性方法造成了认知上的僵化,迫使模型进行单向推理。然而,复杂的视觉分析本质上是一个非线性过程,它包括假设检验、构建前提、视觉探索其含义,以及在遇到矛盾时回溯并修正先前的假设。虽然一些关于自然图像的研究通过放大或多区域标记暗示了非线性,但它们无法支持结构化图像所需的丰富递归探索。如图1所示,结构化图像理解需要灵活的视觉推理能力,这要求模型能够回忆历史图像、探索多个推理分支并动态调整推理路径。
为了填补这一研究空白,我们提出了 PixelCraft,一个专为高保真图像处理和结构化图像的灵活视觉推理而设计的多 Agent 系统。该系统包含调度器、规划器、推理器、规划评论器、视觉评论器以及一套视觉工具智能体。为了打破低保真度处理的壁垒,我们构建了一种协同方法:一个紧凑的 MLLM(Qwen2.5-VL-3B),经过我们合成语料库的微调以实现精确的像素级定位,充当“智能眼”,将文本引用映射到坐标。这些坐标随后驱动我们工具智能体中的经典计算机视觉(CV)算子,这些算子充当“机械手”,执行精确的图像编辑。为了摆脱线性推理的认知束缚,我们提出了一种以规划器为中心的三阶段工作流程:1)调度器执行查询感知智能体选择;2)规划器协调智能体之间基于角色的讨论,以构建视觉推理过程;第三,规划评论器会检查轨迹是否存在错误,并触发重新推理。至关重要的是,我们引入了一个由规划器管理的图像记忆系统,它充当“认知白板”。规划器不会不加区分地将所有历史图像输入到不断扩展的上下文中,而是存储中间线索,并在后续步骤中选择性地调用它们。这使得分支和回溯操作更加灵活,摆脱了以往视觉 CoT 方法短暂且单向的特性,同时降低了长上下文开销。我们工作的主要贡献总结如下:
- 我们提出了一种名为 PixelCraft 的新型多 Agent 系统,用于结构化图像推理。该系统集成了查询感知智能体选择、智能体讨论和迭代式自纠错机制,并采用规划器管理的图像记忆。其特色在于,规划器管理的图像记忆能够选择性地调用先前的视觉状态,而非传输所有图像,从而实现显式分支和回溯,同时保持上下文的紧凑性。这种非线性、以讨论为中心的工作流程突破了传统的视觉交错链,能够对结构化图像进行灵活、高保真的推理,同时降低长上下文开销并减少视觉错误。
- PixelCraft 能够实现高保真度的像素级图像处理,从而提升结构化图像的视觉推理性能。我们构建了一个高质量语料库,用于微调紧凑型 MLLM(Qwen2.5-VL-3B),以实现高保真度的像素级定位;其精确坐标驱动工具 Agent 内部的经典计算机视觉算子,从而产生精确、鲁棒且忠实的编辑结果。
- PixelCraft 在结构化图像基准测试中展现出显著的性能提升,并有分量级的证据支持。这些提升在广泛使用且具有挑战性的基准测试(ChartXiv、ChartQAPro、EvoChart)中均保持一致且显著,并且在各种先进的骨干网络(GPT-4o、GPT4.1-mini 和 Claude 3.7 Sonnet)上也有效。
2.RELATED WORKS
Visual understanding of structured images。对于多模态模型而言,理解结构化图像(例如图表)的视觉效果仍然是一项重大挑战。早期研究采用两阶段方法,首先使用光学字符识别(OCR)进行数据提取,然后进行 LLM 推理。为了增强推理能力,后续研究利用思维链(CoT)数据对模型进行微调,而近期研究则引入了强化学习(RL)。尽管取得了这些进展,但在具有挑战性的基准测试中,模型的性能仍然不尽如人意,尤其是在仅依赖模型自身固有能力的情况下。
Tool use for visual reasoning。近年来,MLLM 的进步主要得益于其与光学字符识别(OCR)和搜索引擎等外部工具的集成。早期的工具增强型方法,例如MM-REACT和ViperGPT,主要生成文本或代码输出,通过协调对视觉模型的调用或生成Python脚本来解决视觉查询。为了应对更复杂的任务,后续研究致力于生成中间视觉证据。一个突出的例子是 Set-of-Mark (SoM),它将显式标记叠加到图像区域,为模型提供清晰的视觉词汇,这种范式已成功扩展到视觉定位和目标检测等任务。我们的工作与之不同,专注于结构化图像的视觉推理,这是一个需要高保真处理的领域。近期的 Refocus 和 OpenThinkImg 也利用视觉工具进行图表理解。然而,它们的工具集通常是专门化的——例如,依赖于轮廓或线条检测——这限制了其通用性。此外,他们的线性链式推理缺乏灵活性:它缺乏回溯和分支,同时忽略了最近的研究结果,即 MLLM 在多图像输入上的性能会下降。
Multi-agent collaboration。多 Agent 协作范式增强了推理能力,超越了单 Agent 系统。一种突出的方法是“多智能体辩论”,其中智能体独立生成解决方案,然后通过聚合或讨论达成最终答案,从而提高推理质量。这种利用解决方案多样性的原则也体现在投票、医疗决策和群体讨论(例如 ReConcile)等框架中。与这些“辩论选择”方法不同,另一种范式侧重于专业智能体之间的结构化协作。一种流行的方法是角色扮演,即将任务分解,并由扮演特定角色(例如规划器或推理器)的智能体协作完成。我们的工作基于这种角色扮演概念,定义了一个具有协同规划、图像处理、推理和批判能力的智能体团队。虽然最近的研究探索了动态工具生成,但自动创建高保真度的可视化工具仍然是一个挑战。我们的框架基于 LLM 生成的工具,为专用工具智能体配备了相应的功能。
3.PIXELCRAFT
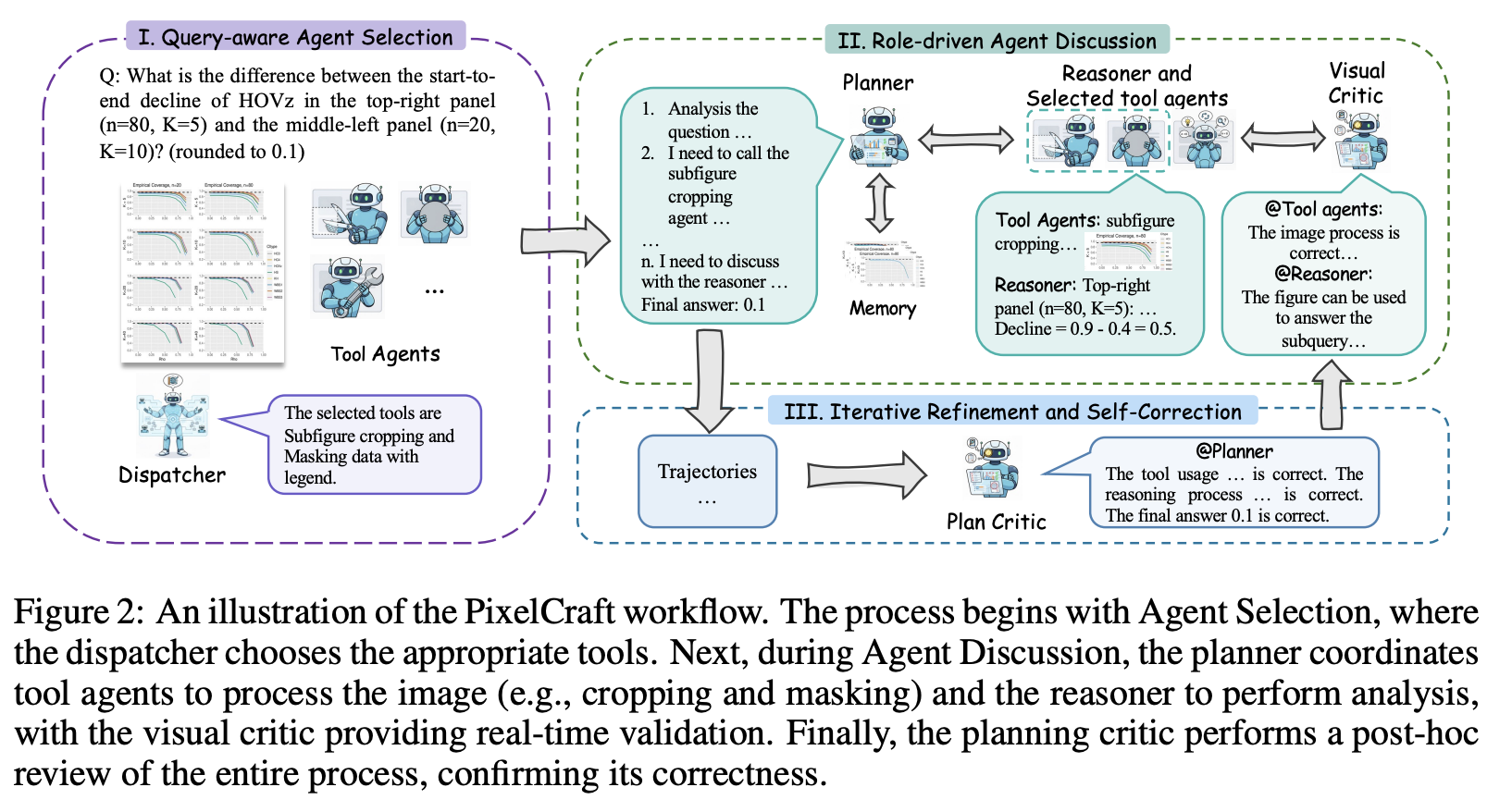
我们考虑图表和几何理解中复杂的视觉推理任务,这些任务需要逐步获取中间视觉线索才能得出最终答案。为了实现这一目标,我们提出了 high-fidelity agents (PixelCraft),这是一个多模态多 Agent 系统,能够对结构化图像进行高保真且灵活的视觉推理。其设计基于两个核心原则:将 MLLM 的智能与计算机视觉(CV)算法相结合,以实现高保真工具的使用;并通过以规划器为中心、基于讨论的工作流程,实现灵活的非线性推理。如图2所示,MLLM充当调度器、规划器、推理器和评论器的角色,与专门的工具智能体协作执行三阶段流程:1)基于查询的智能体选择;2)基于角色的智能体讨论;3)迭代改进和自我纠错。
3.1 AGENT ROLES
Dispatcher。调度器作为初始入口点,分析查询需求,并智能地激活最相关的工具 Agent 进行推理,从而提高效率和响应质量。
Planner。规划器如同 Agent 交响乐团的“指挥”,统筹整个推理过程。它将复杂的查询分解为易于管理的子任务,选择下一个要执行操作的 Agent,并管理图像和文本信息的流。其中一项关键特性是引入了图像记忆。传统的将所有历史图像都输入上下文的方法会受到严重的上下文开销影响,并且只能进行线性、链式的推理。规划器的图像记忆存储所有中间视觉输出,使其能够自适应地调用任何历史图像。这使得规划器能够探索不同的推理分支,并为复杂查询提供更灵活、更高效的视觉推理过程。
Tool Agents。为了满足视觉分析的细微需求,我们最初尝试引导 LLM 基于 ArxivQA 训练集生成专用工具 Agent。然而,我们发现这些自动生成的工具往往效果不佳,主要原因是缺乏精确的定位坐标,或者工具本身无效,存在代码执行错误并产生错误的视觉输出。为了克服这些挑战,我们采用了双管齐下的方法:首先,我们在一个精心整理的数据集上微调定位模型(第 4 节),以提供精确的像素级参考。其次,我们手动改进无效的工具,以确保其功能性和正确性。这种结合了基于 LLM 的生成和专家驱动验证的半自动化方法,对于构建可靠的工具集至关重要。工具生成和改进的详细过程见附录 A。
为了便于图表推理,我们开发了四个可视化工具:1)子图裁剪:使用文本描述(例如,“第 2 行第 1 列的子图”)从多图图像中裁剪出单个子图。2)区域放大:放大指定区域,以突出显示带有 x/y 轴刻度的局部细节。3)添加辅助线:添加带有 x/y 轴刻度的参考线。4)使用图例遮罩数据:通过识别与指定图例项关联的颜色来遮罩无关的数据系列。
为了进行几何推理,我们基于符号实体(点和线)及其关系构建了以下工具代理:1)点连接:在两个指定点之间绘制虚线段,以可视化它们的几何关系。2)垂线构造:构造一条垂直于参考线且经过给定点的直线。3)平行线构造:构造一条平行于参考线且经过给定点的直线。我们还包含代码执行工具,用于对上述两个任务进行数值计算。
Reasoner。推理器作为系统的专属分析专家,在给定输入图像和查询的情况下,运用逻辑推理来解读图表和几何图形中的结构化数据。虽然可以采用各种复杂的提示策略,但我们特意使用简短的通用指令,旨在展示我们高保真工具 Agent 和整体框架的强大功能,而不是将性能提升归功于复杂的提示设计。
Planning Critic and Visual Critic。为了构建一个稳健的双层纠错机制,我们引入了两个在工作流程不同阶段运行的独立评价器:1)用于循环内验证的视觉评价器:与确定性编码不同,视觉工具可能会引入错误。为了确保推理链的准确性,视觉评价器在将处理后的图像传递给推理器之前,对其进行循环内目标满足性检查(例如,验证裁剪是否成功)和图像的可解答性检查。(2) 用于事后改进的规划评价器:它仔细检查工具的使用顺序和逻辑步骤,以发现效率低下或错误之处,例如使用了次优工具或存在缺陷的推理路径。其反馈将用于指导自我纠错阶段。
3.2 WORKFLOW OF PIXELCRAFT
PixelCraft 的工作流程是查询感知、角色驱动和视觉评论,这使其能够实现高保真图像处理和灵活的视觉推理。该系统的工作流程分为以下三个阶段:
Query-aware Agent Selection。工作流程始于调度器,它分析传入的查询,以确定所需的模态和处理要求。基于初步筛选,调度器选择一组相关的工具 Agent,与推理器一起执行视觉推理。这种精心的选择确保只激活最相关的 Agent,从而优化计算效率和后续处理的相关性。
Role-driven Agent Discussion。在选择 Agent 之后,规划器负责协调推理过程。它将主查询分解为易于管理的子查询,对 Agent 的激活进行排序,并协调所有 Agent 间的通信。在每个步骤中,规划器动态激活相应的 Agent(工具 Agent 或推理器),并从图像记忆(包含所有历史视觉线索及其对应的描述)中选择图像。为了确保高保真执行,规划器会为工具 Agent分配特定目标(例如,“裁剪第 1 行第 1 列的子图”),或向推理器提出精确的子查询。在整个过程中,处理后的图像和文本信息(例如目标、子查询和分析输出)通过规划器在 Agent 之间灵活交换,从而使每个子查询都能由最合适的 Agent 来处理。
为了防止视觉错误传播,我们引入了关键的检查步骤。工具 Agent 处理图像后,视觉评论器会评估其目标满足度,即视觉输出是否成功满足规划器设定的目标。此外,当处理后的图像及其关联的子查询被发送给推理器时,视觉评论器会评估图像的可回答性。一旦检测到错误,错误警报将返回给规划器进行后续推理,从而确保推理的鲁棒性。
Iterative Refinement and Self-Correction。生成初始答案后,规划评估器会对整个推理过程进行最终审查,仔细检查每个步骤的准确性、逻辑一致性和完整性。通过识别误用的工具或错误的结论,规划评估器会提出工具列表的修正建议(例如,添加或移除工具),并提供改进推理过程的宝贵建议,例如提出更优的子查询或工具使用策略。这些反馈将作为第二次尝试的补充输入,PixelCraft 将在第二次尝试中重新回答查询。此过程实现了自我改进的循环,随着时间的推移不断提升系统的决策能力和工具选择能力。自我修正示例见附录 C.1。
通过这种结构化且协作式的工作流程,PixelCraft 集成了灵活的工具选择、自适应图像记忆、强大的视觉验证以及自纠错推理过程。这种协同作用实现了针对复杂查询的准确、灵活且易于解释的视觉推理。
4.GROUNDING FOR HIGH-FIDELITY IMAGE EDITING
精确的视觉定位对于下游图像编辑工具至关重要,例如提取特定子图进行进一步分析。然而,由于图表、科学图表和几何图等结构化视觉输入的抽象性和组合性,对其进行定位面临着独特的挑战。虽然之前的研究 Refocus 通过基于特定视觉基元(例如线条、正方形)定位对象来解决这个问题,但它对这些预定义结构的依赖限制了其适用范围,使其仅适用于少数几种图表类型。为了克服这些限制,我们引入了一个由合成图表和几何图组成的混合数据集,并利用该数据集对 Qwen2.5-VL-3B 进行微调,以在这些具有挑战性的领域实现高保真定位。我们从两个互补的来源构建了一个混合数据集:(1)程序生成的图表和(2)带注释的几何图。
Supervised Fine-Tuning。我们将结构化图像定位建模为一个自回归序列预测任务。具体来说,给定输入图像 III 和文本提示 PPP,模型生成一个序列 Y=(y1,...,yT)Y = (y_1, ..., y_T)Y=(y1,...,yT),该序列联合编码了文本答案和对应的边界框。为此,我们使用精心整理的数据集对 Qwen2.5-VL-3B 模型进行微调,其中空间位置以绝对坐标表示,以符合模型的原生定位格式。完整的训练细节见附录 B.1。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)