大模型本地部署硬件指南
GPU。
如何选择合适的硬件配置
为了在本地有效部署和使用开源大模型,深入理解硬件与软件的需求至关重要。在硬件需求方面,关键是配置一台或多台高性能的计算机或租用配备了先进GPU的在线服务器,确保有足够的内存和存储空间来处理大数据和复杂模型。
- 软件需求:推荐使用
Ubuntu操作系统,因其在机器学习领域的支持和兼容性优于Windows。 - 编程语言:建议以
Python为主,结合TensorFlow或PyTorch等流行机器学习框架,并利用DeepSpeed等优化工具来提升大模型的运行效率和性能。
所以在本系列课程中,我们将从硬件选择入手,逐步引导大家理解并掌握如何为大模型部署选择合适的硬件,以及如何高效地配置和运行这些模型,从零到一实现大模型的本地部署和应用。首先来看硬件方面,提前规划计算资源是必要的。目前,我们主要考虑以下两种途径:
- 配置个人服务器,组建一个适合大模型使用需求的计算机系统。
- 租用在线
GPU服务,通过云计算平台获取大模型所需的计算能力。
一、大模型应用需求分析
大模型的本地部署主要应用于三个方面:训练(train)、高效微调(fine-tune)和推理(inference),这些过程在算力消耗上有显著差异:
- 训练:算力最密集,通常消耗的算力是推理过程的至少三个数量级以上。
- 微调:微调是在预训练模型的基础上对其进行进一步调整以适应特定任务的过程,其算力需求低于训练,但高于推理。
- 推理:推理指的是使用训练好的模型来进行预测或分析,是算力消耗最低的阶段。
举例:以
cahtGPT参数为例,训练时:需要10000张80G的A100显卡训练1个月的时,推理时:需要9张80G的A100显卡;
总的来说,在算力消耗上:训练 > 微调 > 推理。
从0训练一个大模型并非易事,这不仅对个人用户,对于许多企业而言也同样困难。因此,如果个人使用,关注点应该放在推理和微调的性能上。在这两种应用需求下,对**硬件的核心要求体现在GPU的选择上,对CPU和内存的要求并不高。**无论是选择租用在线算力还是配置本地计算机,如果想在本地运行大模型,我们可以拆分成两个关注点:
- 模型:选择什么基座模型或微调模型,这可以直接下载至本地。
- 硬件:希望在什么硬件平台上来执行,可以分为
CPU和GPU两大类。
大部分开源大模型支持在 CPU 和 Mac M系列芯片上运行,但较为繁琐且占⽤内存⾄少 32G 以上,因此更推荐在 GPU 上运行。
针对本地部署大模型,在选择
GPU时,可以遵循的简单策略是:在满足具体的大模型的官方配置要求下,选择性价比最高的GPU。
GPU的性能主要由以下三个核心参数决定:
-
计算能力:这是最关注的指标,尤其是32位浮点计算能力。随着技术发展,16位浮点训练也日渐普及。对于仅进行预测的任务,
INT 8量化版本也足够; -
显存大小:大模型的规模和训练批量大小直接影响对显存的需求。更大的模型或更大的批量处理需要更多的显存;
-
显存带宽:决定了
GPU处理器能够多快地从显存中读取、写入数据。显存带宽越高,GPU处理大量数据时的性能通常也越好;
注:显存带宽相对固定,选择空间较小。
二、硬件配置的选择标准
我们的建议是:根据部署的大模型配置需求,先选择出最合适的
GPU,然后再根据所选GPU的特性,进一步搭配计算机的其他组件,如CPU、内存和存储等,以确保整体系统的协调性和高效性能。最简单的匹配GPU的标准是显存、算力和性价比。
实际训练的过程当中,将海量的数据切块成不同的 batch size,然后送入显卡进行训练。显存大,意味着一次可以送进更大的数据块。但是芯片算力如果不足,单个数据块就需要更长的等待时间显存和算力,因此显存和算力必须要相辅相成。
简单来说,在深度学习的训练和推理中,GPU的显存主要用于以下几个方面:
-
权重存储:模型的参数,包括权重和偏置,都需要在显存中存储。这些参数是模型进行预测或分类所必需的。
-
中间过程数据存储:在模型计算的前向传播和反向传播过程中,会产生并且需要暂时存储大量的中间计算结果。这些数据同样存储在显存中。
-
计算过程:
GPU专门为并行处理大量的矩阵和向量运算而设计,这正是深度学习中常见的计算类型。这些计算直接在显存中进行,以利用GPU的高速运算能力。
所谓的"算力"大小,通常指的是整个计算系统的处理能力,尽管在特定上下文中,它有时特指GPU的处理能力。
我们以ChatGLM-6B模型为例,官方给出的硬件配置说明如下:

-
模型量化是一种用于优化模型的技术,特别是在推理时,通过减少模型中使用的数值精度来减小模型的大小,加快推理速度,并降低内存和能源消耗。
-
模型量化常用于将模型部署到资源受限的设备上,如手机或嵌入式系统,量化程度越高,对硬件的要求就会越低。
2.1 选择满足显存需求的 GPU
关于如何选择GPU,当前市场 NVIDIA 和 AMD 是两大主要显卡生产商。但在人工智能、大数据、深度学习领域,NVIDIA(通常被称为N卡)几乎独占鳌头。主要原因还是NVIDIA在很早期就开始专注于AI和深度学习市场,开发了强大的软件工具和库,例如cuDNN、TensorRT,这些都是专门为深度学习优化的,与流行的深度学习框架(如TensorFlow、PyTorch等)紧密集成,同时NVIDIA的CUDA(Compute Unified Device Architecture)作为独特的平行计算平台和编程模型,它允许开发者利用NVIDIA的GPU进行高效的通用计算。这一点对于深度学习和大数据分析等需要大量并行处理的应用来说至关重要。
英伟达是一家什么公司?
英伟达的确是靠着游戏显卡起家,并且在人工智能爆发的现在靠着一手AI计算芯片市值突破了万亿美元,但其实它并不是一家卖芯片的公司,我对英伟达的定位是一家卖人工智能系统的公司。这就有两个核心的概念,一个是英伟达的计算芯片,一个是英伟达针对自家芯片做的计算架构CUDA,二者缺一不可。英伟达就依靠着GPU和计算芯片与CUDA计算架构,共同组成的AI生态系统赢得了市场青睐。
根据相关机构的统计数据,在独立显卡领域,英伟达的市占率高达85%,在AI算力芯片领域,在未来可能达到90%,现在做深度学习,英伟达的卡就是刚需,没有其他的选择。因此,我们建议还是选择 NVIDIA 的显卡。如果对应的ChatGLM-6B模型的硬件配置说明,我们就可以这样选择GPU。理论上,在进行少量对话时:
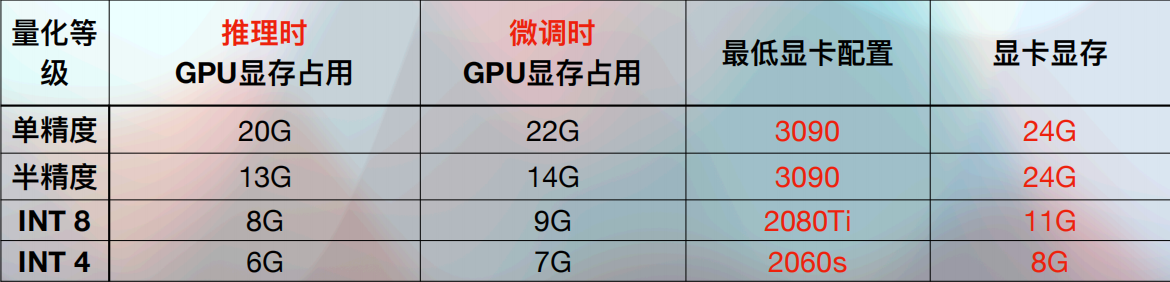
在选择显卡时,必须遵循的首要准则是:显卡的显存容量一定要高于大模型官方要求的最低显存配置。这是确保模型能够有效运行的基本要求。显存容量越大,其推理或微调的能力就会越强。当然,随着显存容量的增加,显卡的价格也相应提高。以下是目前最主流的几款大模型的显卡型号及其显存容量:
| 显卡型号 | 显存容量 |
|---|---|
H100 |
80 GB |
A100 |
80/40 GB |
H800 |
80 GB |
A800 |
80 GB |
4090 |
24 GB |
3090 |
24 GB |
其组合形式可以分为以下四类:
- 纯
CPU:基于不同架构的CPU配置,适用于不需要或不能使用GPU加速的场景。(不推荐)x86(如Intel或AMD)ARM(如Apple、Qualcomm、MTK)
- 单机单卡:使用一块
GPU进行计算,适用于大多数个人使用和一些中等计算负载的场景。(典型配置)NVIDIA系列GPUAMD系列GPUApple系列GPU
- 单机多卡:在一台机器上使用多张
GPU卡,适用于高计算负载的场景,如模型分割处理。(典型配置) - 多机配置:使用多台计算机进行集群计算,通常超出个人使用范围,主要用于从0预训练基座模型等高负载任务。
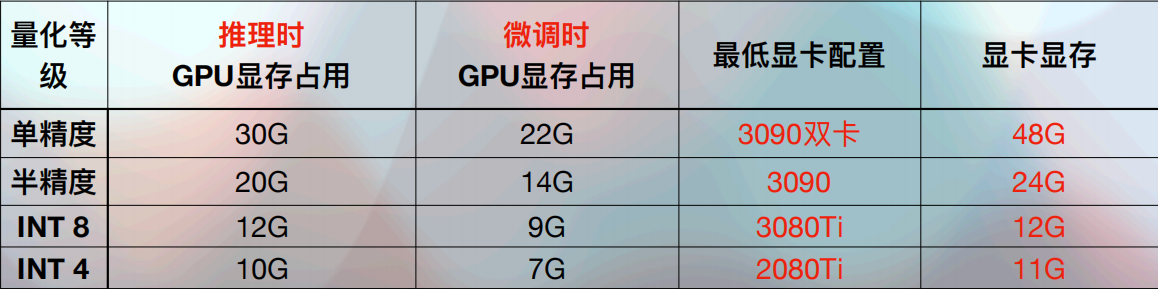
所以,在单个显卡的显存容量不足以满足需求时,也可以采用多显卡配置来增加整体的显存容量。只要总显存超过官方推荐的配置要求就可以。此外,在选择显卡时,除了考虑整体显存容量,还要根据不同显卡的性能和成本进行权衡。根据具体需求和预算,决定是选择单张高性能显卡,还是部署多张成本效益更高的低版本显卡。实现最优的性价比。比如:进行多轮对话时或需要微调时,采用单机多卡:
2.2 主流显卡性能分析
对于 NVIDIA 的显卡(N卡)卡来说,我们可以按照以下几个维度来划分:
按照产品线划分:
| 系列 | 特点 | 主要应用领域 |
|---|---|---|
GeForce系列(G系列) |
消费级GPU产品线,注重提供高性能的图形处理能力和游戏特性,性价比高,适合游戏和深度学习推理、训练。 |
主要面向游戏玩家和普通用户。 |
Quadro系列(P系列) |
专业级GPU产品线,针对商业和专业应用领域进行了优化,适用于设计、建筑等专业图像处理。 |
设计、建筑、专业图像处理等领域。 |
Tesla系列(T系列) |
主要用于高性能计算和机器学习任务,集成深度学习加速器,提供快速的矩阵运算和神经网络推理。 | 高性能计算、机器学习任务等领域。 |
Tegra系列 |
移动处理器产品线,用于嵌入式系统、智能手机、平板电脑、汽车电子等领域,具备高性能的图形和计算能力,低功耗。 | 嵌入式系统、智能手机、平板电脑、汽车电子等领域。 |
Jetson系列 |
面向边缘计算和人工智能应用的嵌入式开发平台,具备强大的计算和推理能力,适用于智能摄像头、机器人、自动驾驶系统等。 | 边缘计算、人工智能、机器人等领域。 |
DGX系列 |
面向深度学习和人工智能研究的高性能计算服务器,集成多个GPU和专用硬件,支持大规模深度学习模型的训练和推理。 |
深度学习、人工智能研究和开发等领域。 |
按照架构划分:
| 架构 | 年份 | 芯片代号 | 特点 | 代表产品 |
|---|---|---|---|---|
| Tesla | 2006 | GT | 第一个通用并行计算架构,主要用于科学计算和高性能计算。 | Tesla C870/GeForce 8800 GTX |
| Fermi | 2010 | GF | 引入CUDA架构、ECC内存等,用于科学计算、图形处理和高性能计算。 | Tesla C2050/GeForce GTX 480 |
| Kepler | 2012 | GK | 功耗效率和性能改进,引入GPU Boost技术,适用于科学计算、深度学习和游戏。 |
Tesla K40/GeForce GTX 680 |
| Maxwell | 2014 | GM | 提高功耗效率,引入新技术如多层次内存系统,应用于游戏、深度学习和移动设备。 | Tesla M40/GeForce GTX 980 |
| Pascal | 2016 | GP | 16nm FinFET制程技术,加强深度学习和AI计算支持,引入Tensor Cores,应用于深度学习和高性能计算。 | Tesla P100/GeForce GTX 1080 |
| Volta | 2017 | GV | 深度学习优化特性,如Tensor Cores,主要用于深度学习、科学计算和高性能计算。 | Tesla V100 |
| Turing | 2018 | TU | 实时光线追踪技术、深度学习技术,适用于游戏、深度学习和专业可视化。 | Tesla T4/GeForce RTX 2080 Ti |
| Ampere | 2020 | GA | 第二代深度学习架构,更多Tensor Cores、改进的Ray Tracing技术,应用于深度学习、科学计算和高性能计算。 | Telsa A100/GeForce RTX 3090 |
| Ada Lovelace | 2022 | AD | 专为光线追踪和基于AI的神经图形设计,第四代Tensor Core,第三代RT Core,提高GPU性能。 |
GeForce RTX 4090 |
| Hopper | 2022 | GH | 下一代加速计算平台,支持PCIe 5.0,专用的Transformer引擎,适用于大型语言模型和对话AI,提供企业级AI支持。 | Telsa H100 |
按应用领域划分:

像大模型领域这种生成式人工智能,需要强大的算力来生成文本、图像、视频等内容。在这个背景下,NVIDIA先后推出、A100、L40和H100等多款用于AI训练的芯片,L40性能高于4090,低于A100;其中 A100 是 H100 的上一代产品,于2020年发布,使用7纳米工艺,支持AI推理和训练。而H100,该显卡是2022年3月发布,可谓是核弹级性能显卡,采用了台机电4纳米工艺,具备800亿个晶体管,采用最新 Neda Hopper架构,同时显存还支持 hbm3,最高带宽可达 3TB每秒。第四代MNLINK的带宽,900G每秒。是PCIE5.0的7倍,比上一代的A100显卡高一倍,显卡对外总带宽达到超高的 4.9TB每秒。
性能上H100显卡相对于上一代
A100来说,可谓是质的飞跃,各项基础性能是A100的三倍之多,H100的单片显卡售价24万元左右。
但在2022年10月,TA国发布禁令:禁止NVIDIA向国内出售A100和H100显卡。虽然NVIDIA的A100,H100这样的顶级芯片不能卖给国内,但NVIDIA作为商业公司为了合规,NVIDIA针对传输速率进行了限制,提出了国内特供版的A800 和 H800,即:H100、A100的阉割版。
2.3 主流显卡性能对比
那么个人使用或者实验室针对大模型的推理和微调需求配置服务器,高端显卡目前我们可选的就是A100、A800、H100、H800和4090等,那么应该如何选呢?
2.3.1 H100 vs H200
在2023年11月13日NVIDIA又放出来两个核弹:
第一个核弹就是它推出了全新的超算GPU H200,直接说是当今世最强,听起来很嚣张,但其实一点没有吹牛。在AI超算领域,对手只有看NVIDIA车尾灯的份。从数据层面看,H200强在大模型推理上,以700亿参数的Llama2 二代大模型为例,H200推理速度几乎比前代的H100快了一倍,而且能耗还降低了一半。
- 显存从
H100的80GB,直接拉到了141gb; - 内存带宽也从
3.35TB/s,提升到了4.8TB/s; GPU的通信速度达到了4.8TB/s;
这样就使得ChatGPT大模型的推理速度大大的提升,跟A100相比提高了 18倍。
第二个核弹就是CPU和GPU的合体:GH200, 就是把ARM的CPU和它的GPU封装在了同一块GPU晶圆板上,这样CPU和GPU之间的传输速度就非常快,而且可以共享内存。内存也达到了惊人的624GB。而且上面有72个ARM的计算核。这个算力跟X86的芯片相比,提高了100倍。而功耗却只有1/2。
炸一听好像是王炸升级,但实际上,H200可能只是H100的一个中期改款。单论峰值算力,H100和H200其实是一模一样的,真正提升的是显存和带宽,然而对于AI芯片的性能,讨论最多的是训练能力。在GPT-3 175B大模型的训练中,H200相较于H100,只强了10%,提升并不明显。这操作,大概率是NVIDIA有意为之,以前为了打造大模型,对GPU的首要要求是训练,但是到了现在,随着各种AI大预言模型的落地,大家开始卷的是推理速度。于是H200的升级,就忽略了算力升级,转向推理方面的发力,哪怕只是小提升,依然当得起最强的称号。但这因为是断供后的新卡,国内现在基本买不到。
2.3.2 A100 vs A800 & H100 vs H800
由于TA国的禁令,我们现在使用的GPU都是国内特供版的,像A100,到国内就成了A800,H100到国内就成了H800,那么 A ~ H的差距在哪里呢?
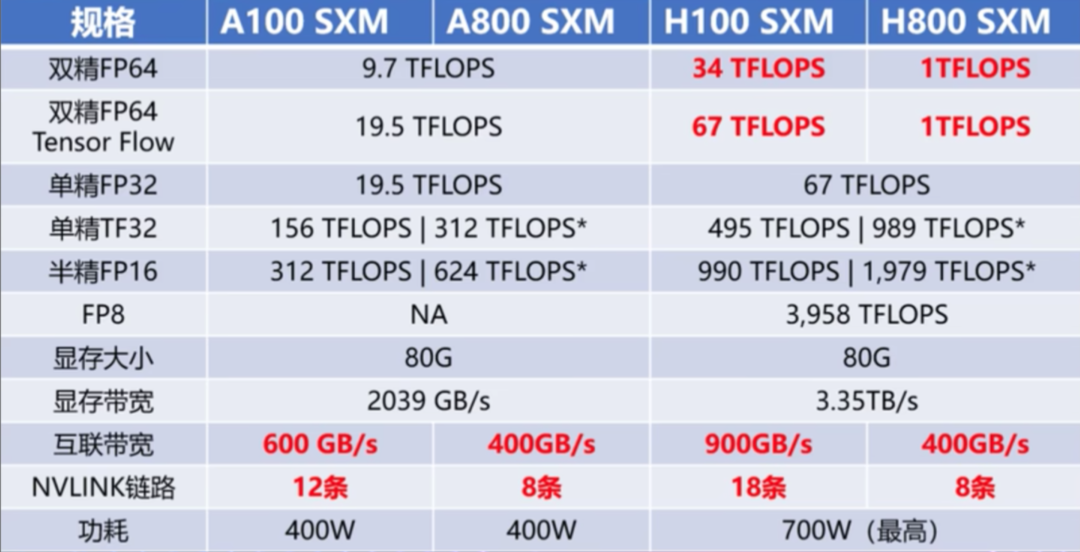
除了 FP64 和 NVLink传输速率上的明显削弱,其他参数和H100都是一模一样的。FP64上的削弱主要影响是H800在科学计算、流体计算、有限元分析等超算领域的应用,受到影响最大的还是NVLINK上的削减。
说白了,NVIDIA想要抓住国内市场,就算是阉割,也不会阉割的特别过分。只要保证H800在大部分场景下的性能不受影响,能满足大部分人的使用需求就足够了。毕竟也不会有人跟钱过不去,所以 其实H800和 H100的性能差距并没有想象的那么夸张,就算是砍掉了FP64和 NVLINK的传输速率,性能依旧够用。
2.3.3 单卡4090 vs A100系列
先说结论:
有双精度需求的,选
A100,没有A100退而选A800没有双精度需求,追求性价比,选
4090;
- 如果是做大模型的训练,GeForce RTX
4090是不行的,但做推理任务时,使用 RTX4090不仅可行,而且在性价比方面甚至略优于A100,同时如果做微调,也勉强是可以的,但建议多卡。
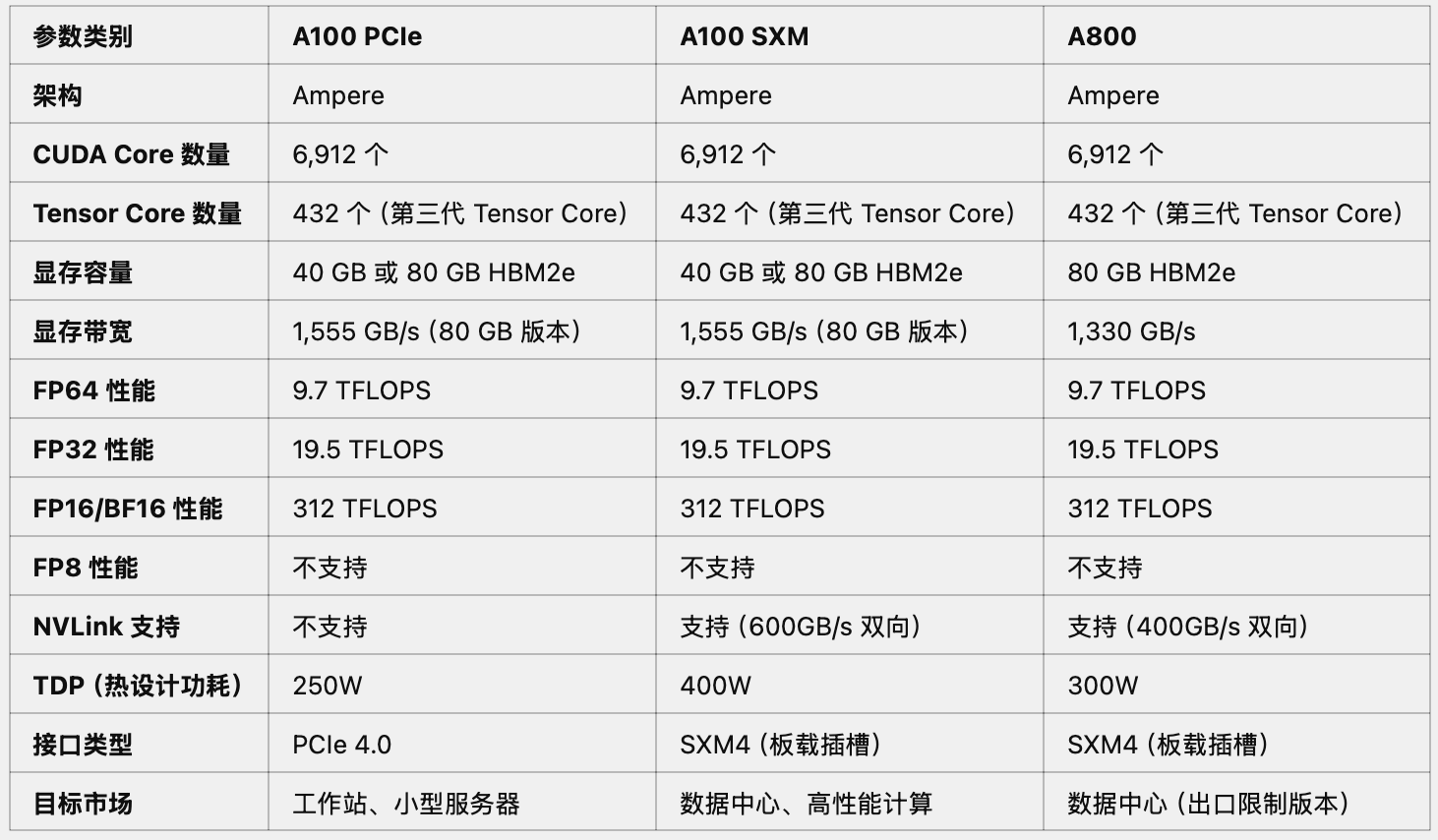
GPU型号 |
Tensor FP16 算力 | Tensor FP32 算力 | 内存容量 | 内存带宽 | 通信带宽 | 通信时延 | 售价(美元) |
|---|---|---|---|---|---|---|---|
H100 |
989 Tflops | 495 Tflops | 80 GB | 3.35 TB/s | 900 GB/s | ~1 us | 30000~40000 |
A100 |
312 Tflops | 156 Tflops | 80 GB | 2 TB/s | 900 GB/s | ~1 us | 15000 |
4090 |
330 Tflops | 83 Tflops | 24 GB | 1 TB/s | 64 GB/s | ~10 us | 1600 |
- 推理
从数据对比来看,A100 和 GeForce RTX 4090 显卡在通信能力和内存容量方面存在显著差异,但在算力上差距并不大。在 FP16 算力方面,两者几乎相当,4090 甚至略有优势。
相较于 A100,4090较高的性价比主要源于推理过程,在这种场景下,显卡的算力才是关键因素,而 4090 在这方面表现出色。虽然内存带宽同样重要,但在推理任务中,4090 的内存带宽通常足以应对需求,不会成为显著的制约因素。
LambdaLabs 有个很好的 GPU 单机训练性能和成本对比:https://lambdalabs.com/GPU-benchmarks , 我们来看:
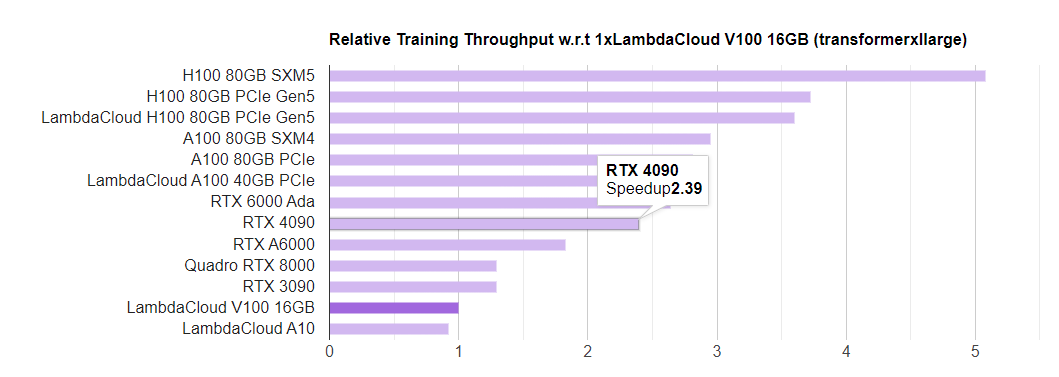
可以看到,4090的速度是2.39,A100是2.29,差别不大,但价格相差10倍,所以4090的性价比是非常高的。
- 微调
反观训练需求下,
4090在训练的时候表现不佳的原因主要是其有限的通信能力和内存容量。
我们拿 LLaMA-2来说,训练 LLaMA-2 70B 时需要2400块 A100 ,主要还是因为训练过程除了存储模型参数外,还需要处理大量数据以及各层之间的中间数据和参数。因此,大容量内存和高通信带宽会比较关键,以便高效地处理和协调这些信息。2400块GPU之间要进行大量的协调和通讯计算,这种复杂的并行结构需要 GPU 之间进行大量的协调和通信。4090 的通信带宽仅为 64 GB/s,与 A100 的 900 GB/s 相比差距过大,导致在这类大规模训练任务中通信成为瓶颈,进而影响整体性价比。因此,尽管 4090 在某些方面表现优秀,但在大模型训练中的局限性仍然明显。尽管微调过程对硬件的要求相较于训练相对较低,但这个过程仍然需要足够的内存以存储模型参数,以及有效的通信带宽来处理数据和模型层之间的交互。所以对于需要高通信带宽和大内存容量的大模型微调任务,A100等高端GPU可能是更合适的选择。
我们拿 GPT-3 来说,GPT-3的参数将近700亿,假设每个参数使用4字节(通常使用float 32)进行存储,训练运算储备需求是 4200 GB,完成一次GPT 3训练的总算力是:3.15 * 10 ^23 Flops,仅考虑算力的情况下,单块 A100 需要45741天,几乎是128年(假设有效算力是78Tflpos),单块4090 需要91146天,几乎是250年,(假设有效算力是40 Tflpos)。任何一张单卡训练一次都需要超过100年,对于参数量达到10亿级别的大模型,参数本身就大,而且大模型通常需要更高的显存来来存储参数、中间计算结果和梯度等,既然要多卡运行,数据的同步效率就会显得非常重要,那么内存带宽、通信带宽、通信延时等性能将非常非常重要。4090 24g的显存小,而且内存带块、通信贷款、和通信延时都相对较弱,这就有点像短板理论:最弱的那一项就决定了显卡的能力。
综上,
4090在较大的大模型没有什么发挥的余地,但随着现在的大模型越来越小,对显存和算力需求相对较小的大模型,再加上推理的算力需求更低,至少对于学习和研究大模型的个人或实验室来说,4090是不错的选择。如LLama 7B 13B模型,单卡的4090都可以运行,
大模型的⼯业级实践要求,大模型全量微调需要⾄少4张A100 80G显卡;(ChatGLM6B 模型 全量微调差不多也是需要这个配置)
2.3.4 单卡4090 vs 双卡3090
如果预算差不多的情况下,对于两张
3090与一张4090的选择,推荐使用两张3090显卡。
4090 VS 3090参数对比:
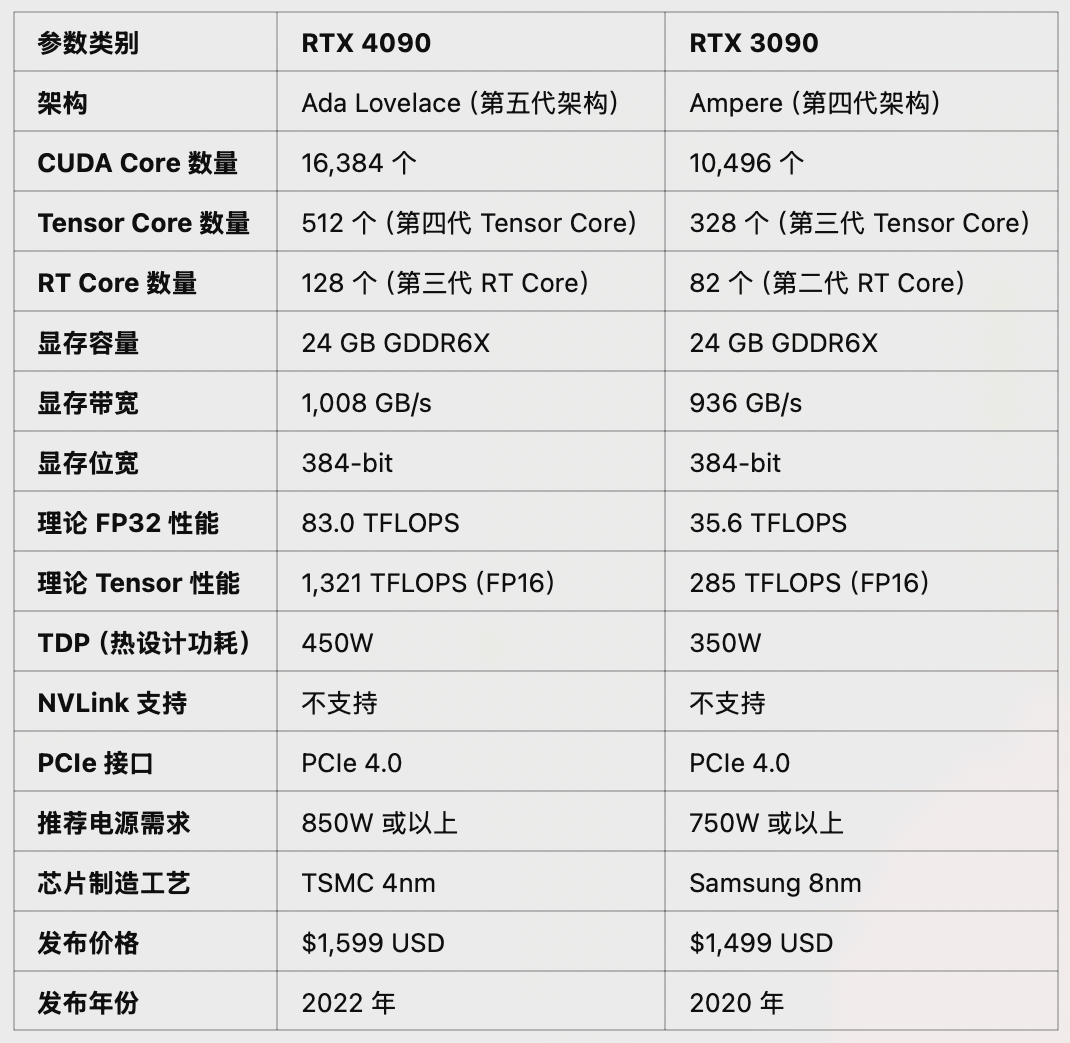
3090 vs 4090显卡核心参数对比:
CUDA Cores:增加了56%;Tensor Cores:提升了4.6倍;- 显存带宽:
RTX 4090带宽更高(1,008 GB/s vs 936 GB/s); RTX 4090的第四代Tensor Core引入FP8支持,更适合低精度推理任务;
虽然从算力角度看,两张3090与一张4090大致持平,但两张3090显卡提供的总显存会更多,这对于处理大型模型尤为重要。目前,大多数深度学习计算框架都支持各种并行计算技术,如流水线并行、张量并行和CPU卸载。这些技术使得即使是显存较小的显卡也能处理大型模型。在这种情况下,双3090配置可以更有效地利用流水线并行,同时,与单4090配置相比,CPU卸载的需求会降低。此外,企业环境一般都是多卡并行,使用双3090配置还可以练习如何写多卡代码。现有技术如串行反向传播,进一步增强了多卡系统的效率,使其成为一个经济高效的选择,尤其是在需要处理大量数据和复杂模型的情况下。因此,从目前的技术和应用需求来看,选择两张3090显卡无疑是更优的选择。
2.4 风扇卡与涡轮卡如何选择
一定要买涡轮卡。
2.5 整机参考配置
确定GPU后,根据GPU搭配合适的计算机组件,具体来说,计算机八大件:CPU、散热器、主板、内存、硬盘、显卡、电源、风扇、机箱。个人使用的计算机,典型的配置是单GPU或双GPU,一般不超过四个GPU,否则常规的机箱放不下,且运行时噪声很大,而且容易跳闸。
目前国内实验室主流的还是4090和3090,10万+的预算配置4张4090是没问题的,20~30万的预算则可以考虑8张4090,或者两张A100 80G,如果预算不限,A100 8卡服务器一定是最佳选择。
这里给出一个本地部署ChatGLM-6B,同时也适用于大多数消费级实验环境的配置:
GPU:3090双卡,涡轮版;总共48G显存,能够适⽤于大多数试验和复现性质深度学习任务;同时双卡也便于模拟多卡运行的⼯业级环境;CPU:AMD 5900X;12核24线程,模拟普通服务器多线程设置;- 存储:64G内存+2T SSD数据盘;内存主要考虑机器学习任务需求;
- 电源:1600W单电源;双卡
GPU的电源在1200W-1600W均可; - 主板:华硕ROG X570-E;服务器级PCE,支持双卡PCIE;
- 机箱:ROG太阳神601;atx全塔式大机箱,便于⾼功耗下散热;
总的来说:
3090⽐4090综合性价⽐更⾼,不过4090计算速度⼏乎是3090的两倍,有需求亦可考虑升级,不过4090需要的机箱空间更大、电源配置也要求更⾼;- 双卡
GPU升级路线:3090—>4090—>A10040G (2.5w左右)—>A10080G(6~7w左右); - 大模型的⼯业级实践要求,大模型全量微调需要⾄少4张
A10080G显卡;(ChatGLM6B模型 全量微调差不多也是需要这个配置)
2.6 理解cpu与gpu
CPU与GPU区别:CPU的核心很强,但数量少,每个核心就像出于一个智力巅峰的高三学生,他能熟练的解出模拟卷上的最后一道大题,但让他算 1000道,他得累死;而显卡上面密密麻麻的分布着几千个小核心,每个核心都像是一个小学生,高考题肯定是不会,但他们能同时并排启动,在10秒把10000道题做完。
显卡算力虽强,但是它们都是小学生,需要合适的软件能驾驭才行。沿用刚才的比方,GPU就是一万个小学生在同时工作,计算能力很强,但前提是你得能把一道难解的大题,分解成无数个小学生能解决的简单问题才行。否则显卡再强又有什么用呢?转换到现实中,就是得让开发者能方便的写出代码。利用上显卡的并行计算能力才行。所以斯坦福大学实验室在2006年,带领团队出现了至今仍然在不断更新的 CUDA,CUDA就是更方便的让开发人员能够面向GPU编程。如果绝大多数 AI模型的训练,背后都离不开CUDA的支持。除了CUDA,OpenCL、ROCm平台,作用也类似,每一个拿显卡干活的人,都绕不开它们,在硬件层面,显卡有强大的并行计算能力,在软件层面,配套的编程平台也成熟了,这就意味着,GPU可以完全离开游戏领域,走向更大的世界了。
2.7 总结
三、大模型硬件理论 & 推荐
3.1 GPU计算性能核心参数
-
CUDA Cores:CUDA核心,是NVIDIA GPU的基础计算单元,负责执行并行计算任务; -
Tensor Cores:张量计算核心,是专门设计用于矩阵运算的硬件单元,核心任务是加速矩阵乘法,特别是用于深度学习的张量运算,其中20系显卡开始加入张量核心; -
GPU Memory:显存,决定了可以加载的模型大小、数据批量(Batch Size)以及中间激活值存储,显存不足会限制任务规模,甚至导致程序崩溃; -
FLOPS:每秒浮点计算次数,是衡量 GPU 浮点运算性能的单位,代表GPU的理论性能; -
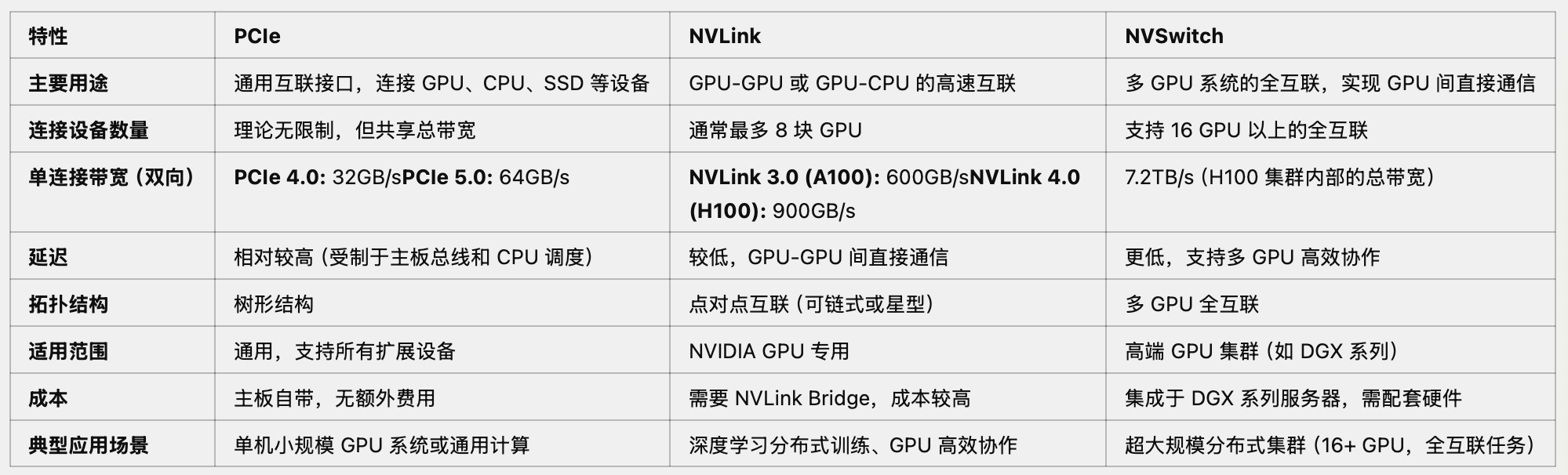
NVLink & NVSwitch:显卡桥接技术,30系显卡取消了NVLink,替代方案是PCIE,目前NVLink只用于企业级图形显卡;
PCIe、NVLink 与 NVSwitch 技术方案介绍介绍与对比:
3.2 主流CPU的性能对比
3.2.1 单卡推理&训练性能

不同显卡性能对比:重要结论
-
H系列显卡性能在训练以及各精度训练方面大幅领先;
-
4090推理性能很强(强于A100),但训练能力不如A100,且受限于显存大小和显存带宽,整体训练能力较弱; -
3090的推理和训练的理论性能约是A100的60%,但同样受限于显存大小和显存带宽,实际性能和A100差距较大,但仍不失为低成本模型训练; -
A10、T4等显卡在深度学习推理与训练方面表现较差;
3.2.2 显卡性价比对比
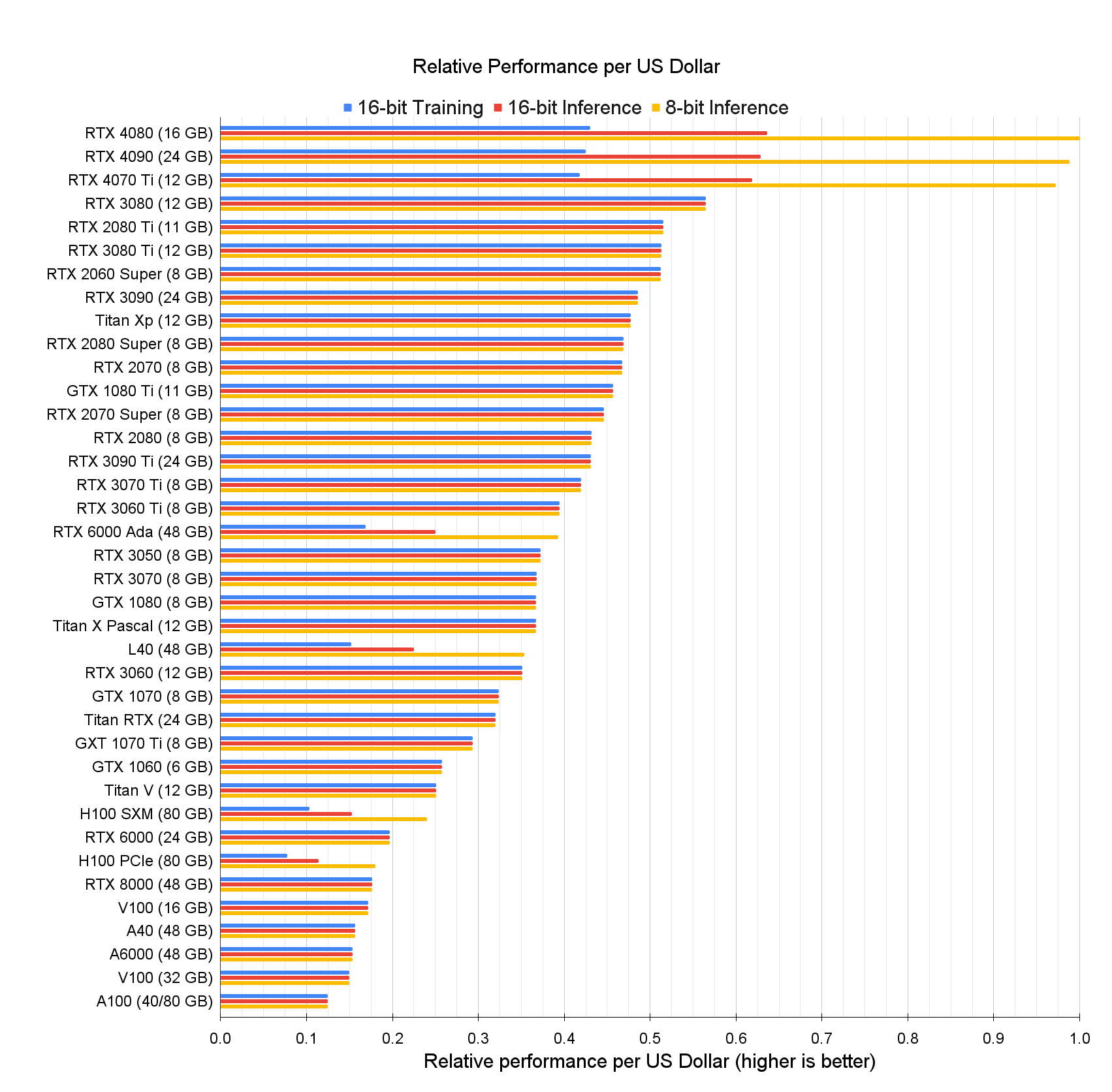
显卡性价比对比:重要结论
-
上述对比未考虑显卡本身运行稳定性与多卡集群带来的性能损耗,只用于在绝对环境下单卡性能对比;
-
单卡环境下,
4080(16G)是性价比之王,但在集群环境下,考虑到数据传输损耗和集群运行稳定性,A100/H100仍是首选; -
2080ti 22G魔改版(约2400元)性价比超越4080,但使用有一定风险; -
除了考虑集群架构外,还需要综合考虑旧版GPU在软件上的一些不适配问题。综合来看,从性价比角度考虑,推荐
2080ti 22G>4080>3090>4090>2080 11G;
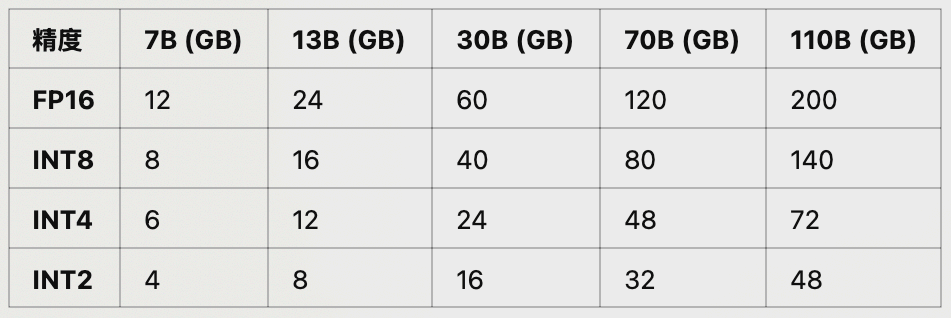
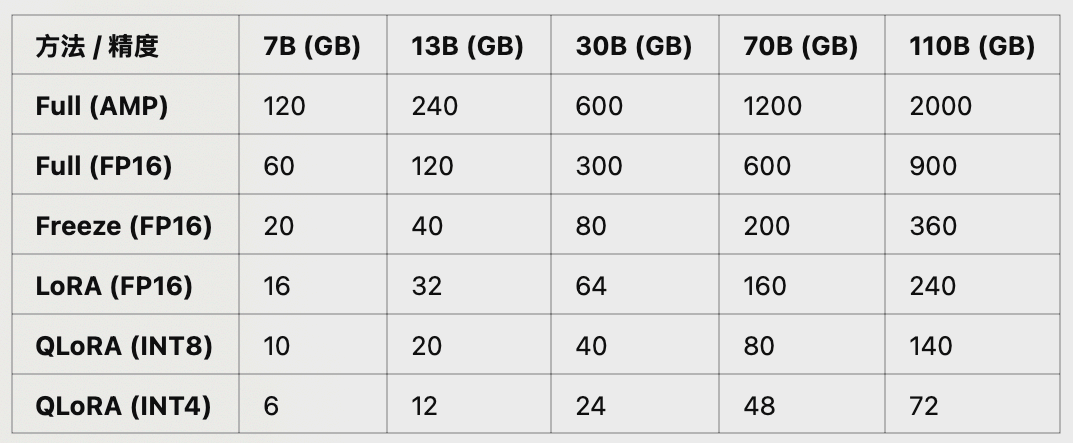
3.3 大模型占用显存分析
3.3.1 大模型推理&训练&微调显存占用
- 不同尺寸、不同精度大模型推理所需显存占用:
- 不同尺寸、不同精度大模型训练与微调所需显存占用:
3.3.2 大模型推理&训练&微调推荐GUP
不同尺寸、不同精度大模型推理推荐GPU
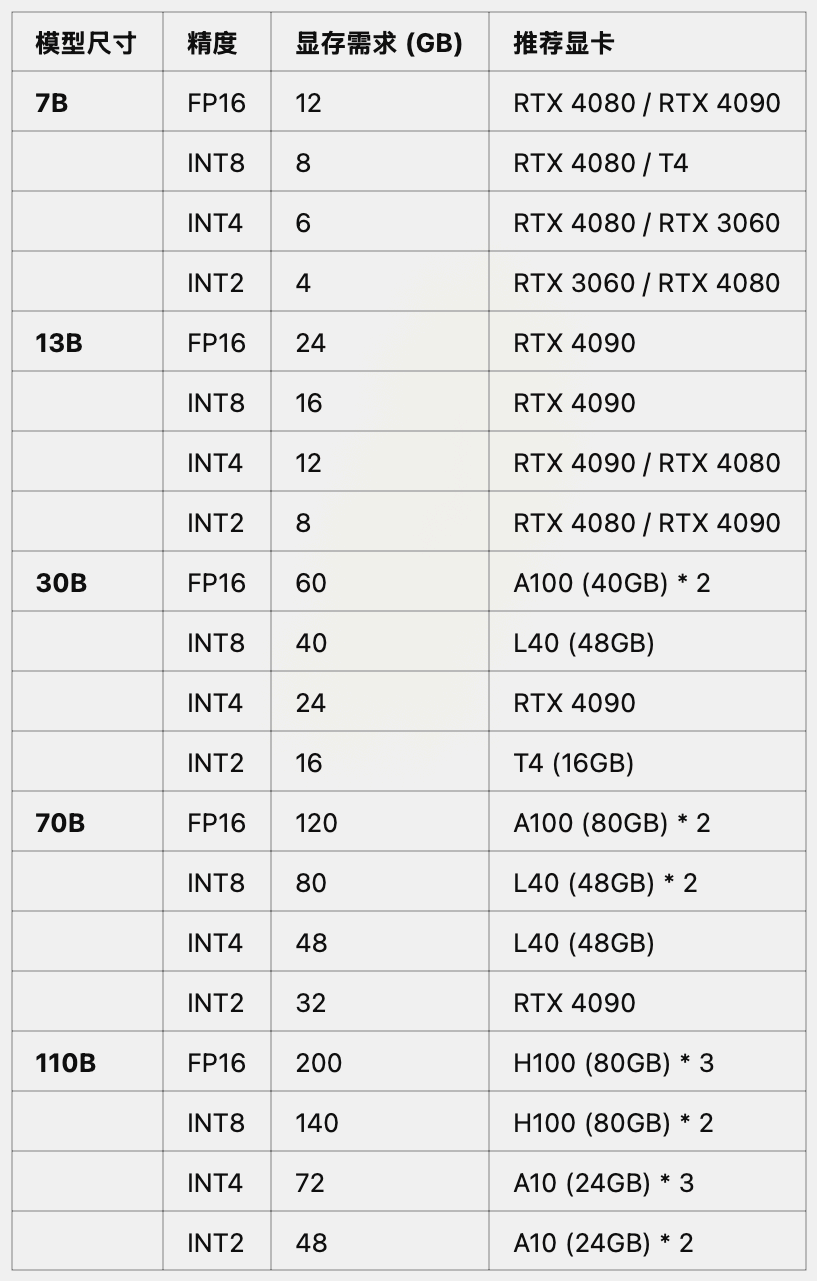
-
其中
RTX 4090可等价替换为RTX 3090; -
其中
A100可替换为A800(国内特供); -
其中
L40可替换为L20(国内特供);
不同尺寸、不同精度大模型预训练推荐GPU
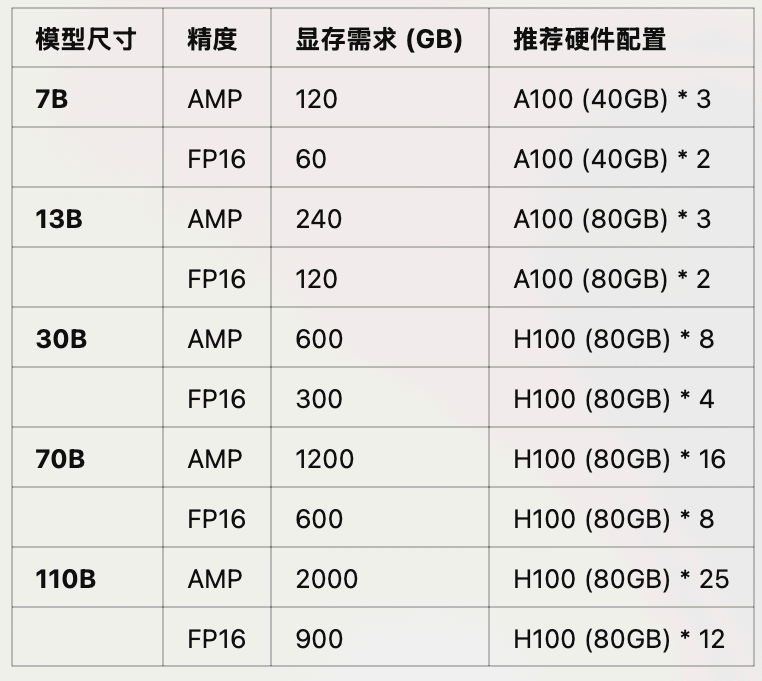
不同尺寸、不同精度大模型高效微调推荐GPU
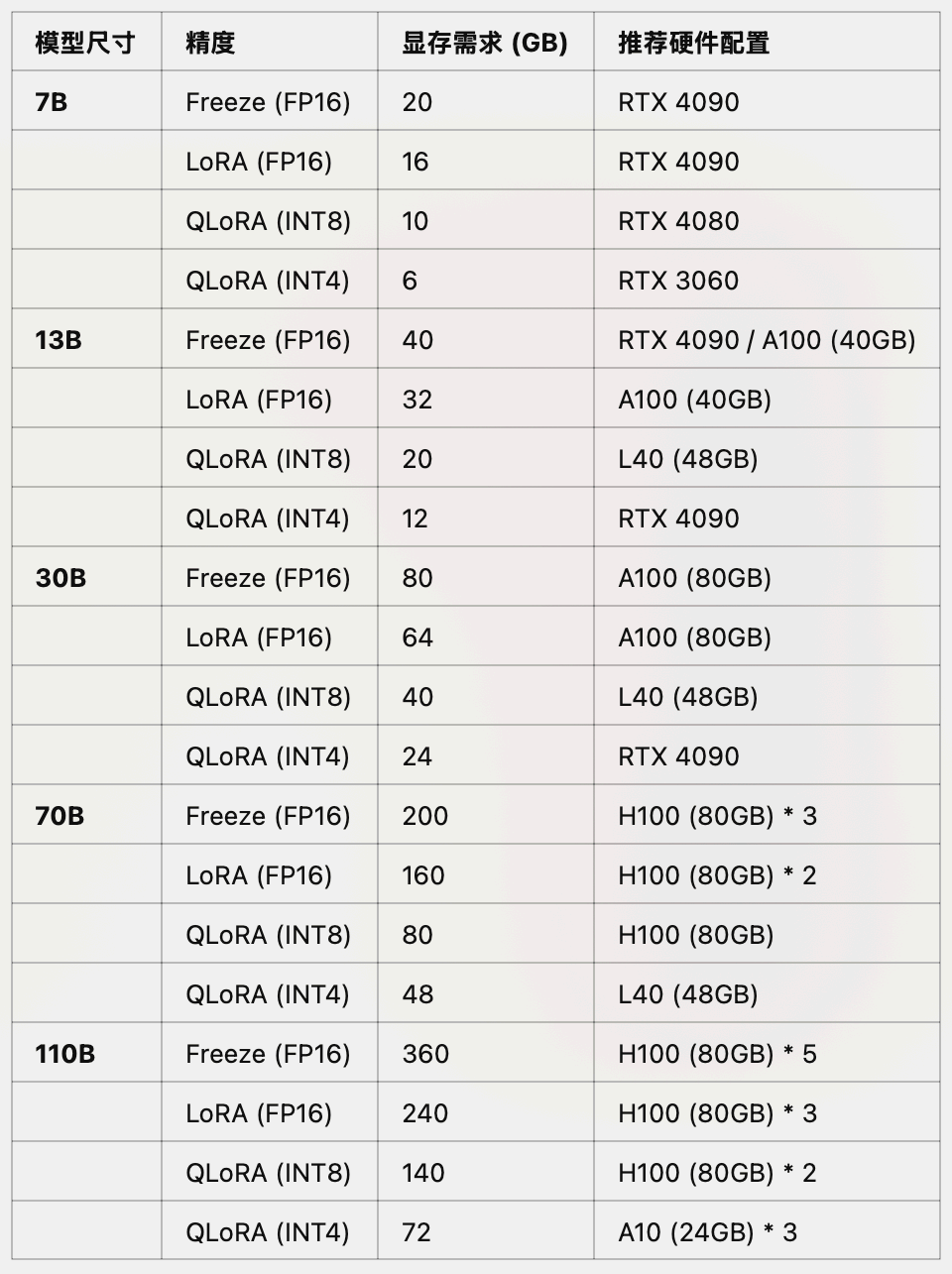
不同使用场景下推荐GPU配置方案汇总
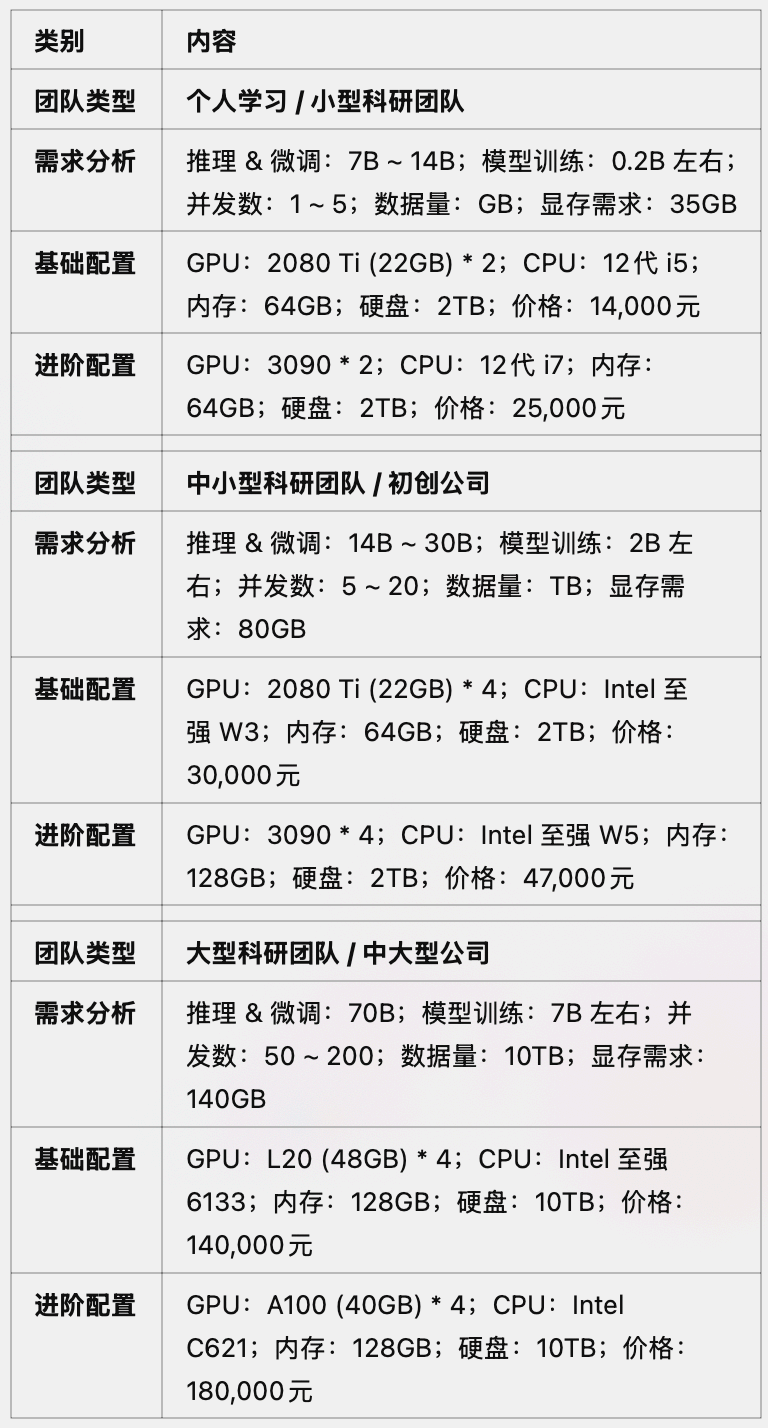

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)