ai(一)下载,部署使用模型
关于本地跑通大模型,这里提供三种思路:
1.下载模型+vllm部署
(vllm 暂不支持windows,需用Ubuntu 22.04 或 24.04或者在 WSL 中安装 NVIDIA 驱动)
2.ollama 下载运行(支持windows)
3.Model Gallery 云上部署
1.1 模型下载
modelscope或者huggingface都提供开源的模型下载;
选择模型库——搜索想下载的模型——点击下载模型——按照右边教程配置——安装库后下载模型
git下载一般是要参与模型的开发,查看提交日志可选;
sdk下载和命令行下载差不多,选择哪个取决于你是在写脚本(用 SDK)还是在终端手动操作(用命令行);
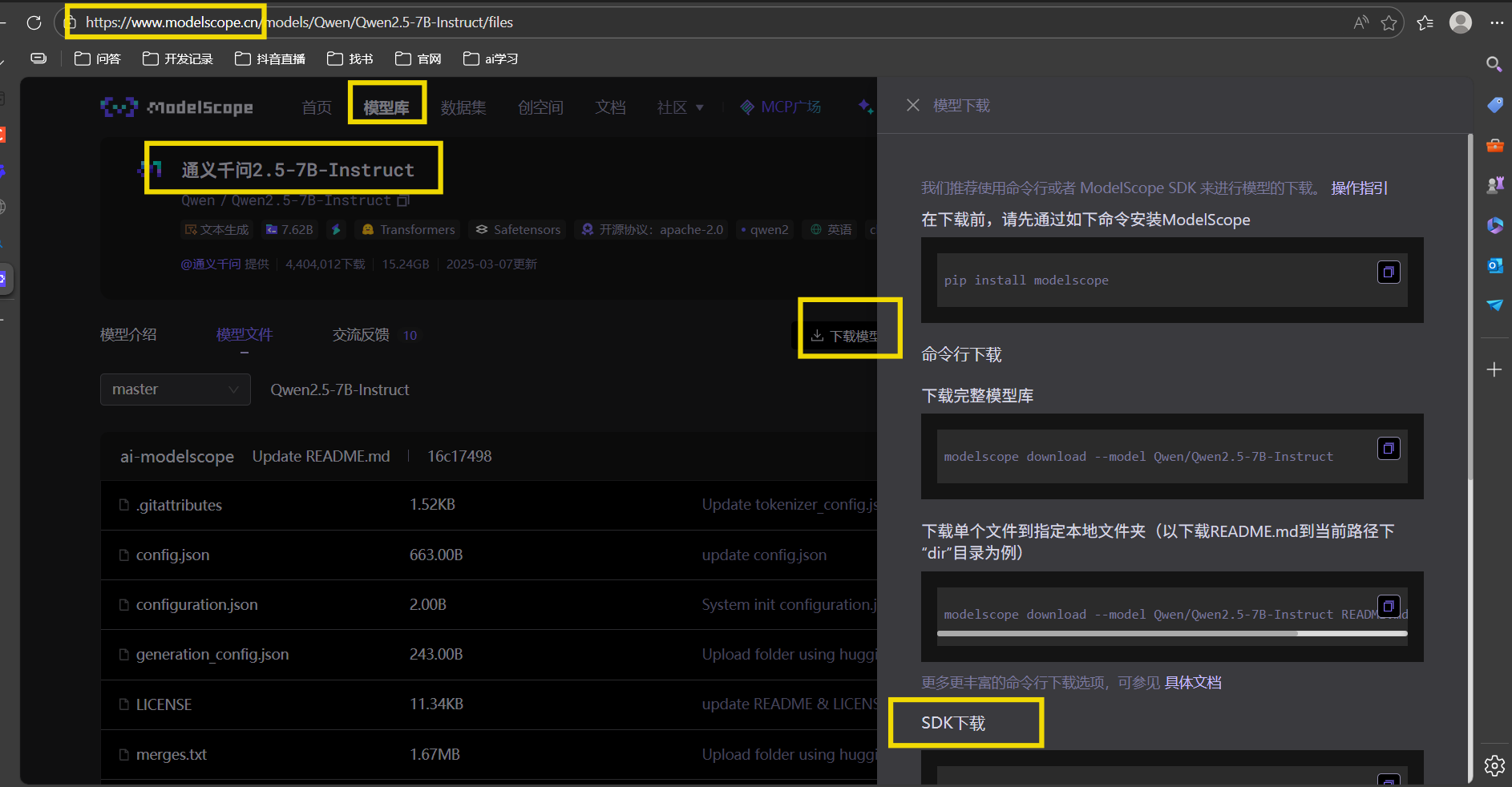
前面两个大家应该都会,这里讲一下sdk下载:
第一种方式:
1.新建一个文本 名称为:download_model.py # 注:后缀不是.txt
2.download_model.py里写上sdk内容,这里有官网的和我改写后的脚本,两种选一种就行,都可以的:
2.1 官网的sdk:
-------------------------------------
# download_model.py
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct')
print("模型已下载到:", model_dir)
------------------------------------
保存,在当前目录下打开终端运行命令:python download_model.py
2.2 改写后的sdk:
-------------------------------------
# download_model.py
import sys
from modelscope import snapshot_download
def main():
if len(sys.argv) != 2:
print("用法: python download_model.py <model_id>")
print("示例: python download_model.py Qwen/Qwen2.5-7B-Instruct")
sys.exit(1)
model_id = sys.argv[1]
print(f"正在下载模型: {model_id}")
try:
local_dir = snapshot_download(model_id)
print(f"✅ 模型已成功下载到: {local_dir}")
except Exception as e:
print(f"❌ 下载失败: {e}")
sys.exit(1)
if __name__ == "__main__":
main()
--------------------------------------
保存,在当前目录下打开终端运行命令:python download_model.py Qwen/Qwen2.5-7B-Instruct
如果要下载其他模型,把 python download_model.py <model_id> 里的模型替换即可;
比如:python download_model.py deepseek-ai/DeepSeek-R1
-------------------------------------------------------------
第二种方式:
终端运行python 再输入sdk命令即可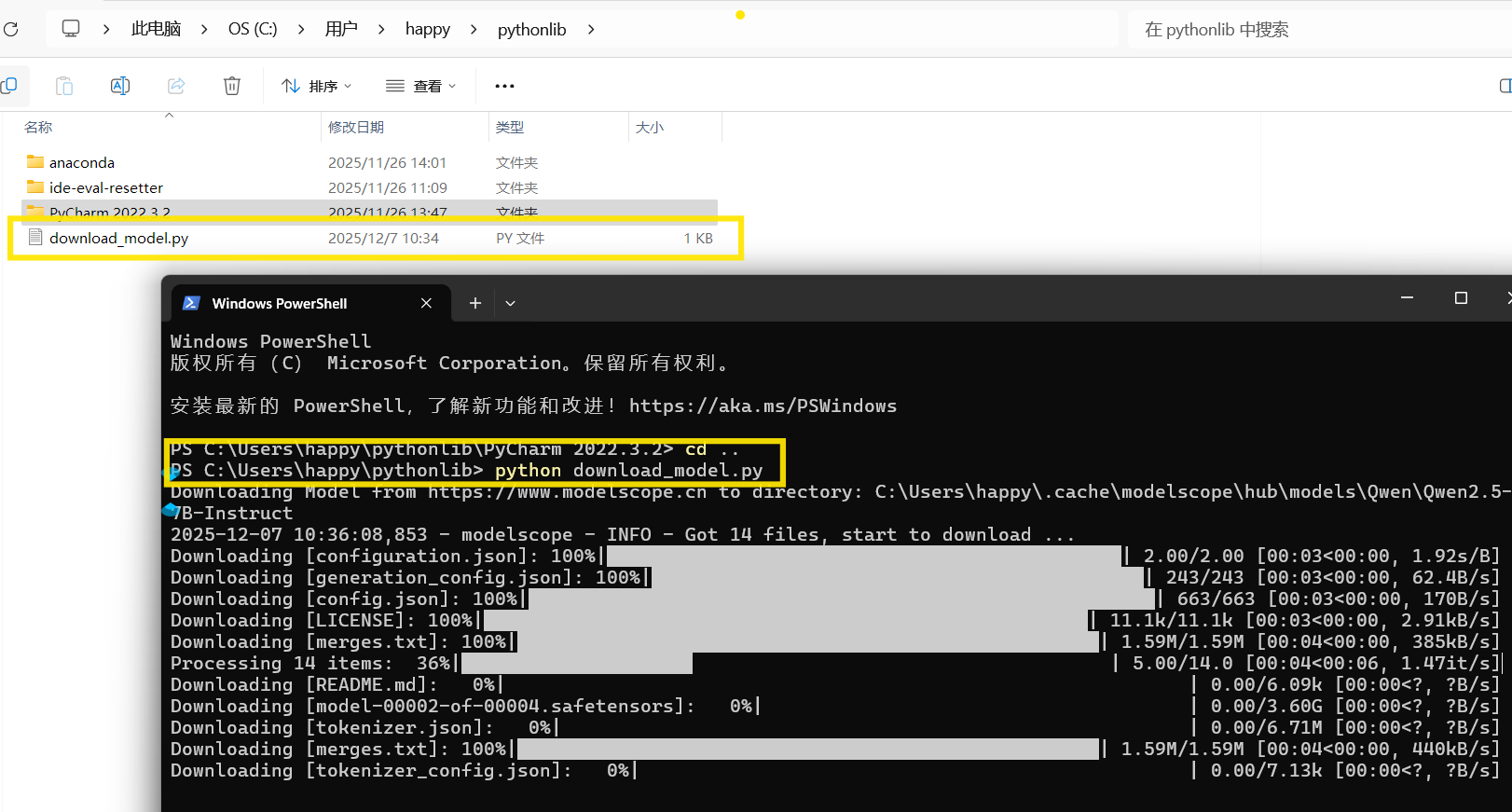

1.2 vLLM部署。
linux或者mac:安装conda,配置环境后,安装vLLM,把模型路径填充好,启动即可:
# 创建虚拟环境
conda create -n vllm python=3.10 -y
conda activate vllm
# 安装vLLM
pip install vllm
#设置环境变量 本地启动 /path/to/model是本地模型路径
export VLLM_USE_MODELSCOPE=True
vllm serve /path/to/model --port 8000
windows:安装WSL...这里就不演示了,我后续会用Linux系统开发,这里不搞了,有需要的自己去问ai。
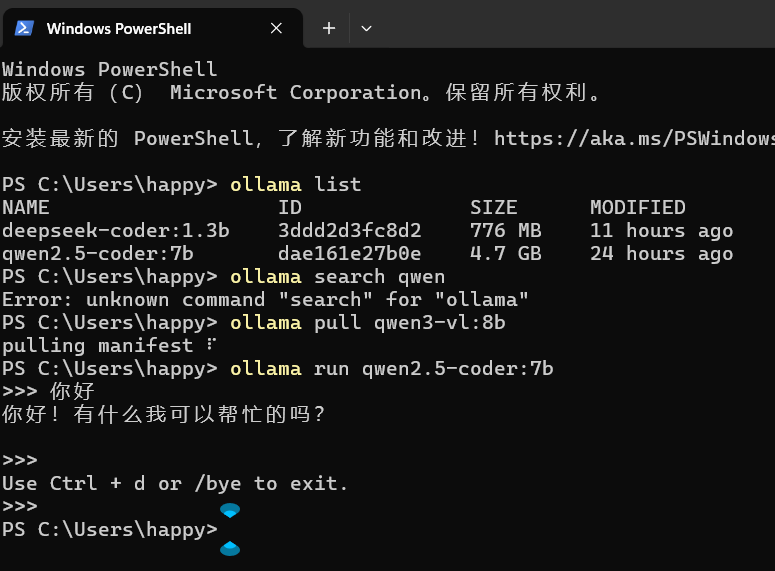
2. ollama
很多时候,在github或者其他地方下载模型后,本地部署运行模型,会发现要下载很多依赖包,这些依赖包要么手动一个一个下载,要么写一个脚本下载全部依赖,而且总是出现依赖缺失的情况,很耗时间,这里推荐ollama ,简化部署模型,下载后即可使用;
官网选择对应操作系统,下载ollama:https://ollama.com/download
双击exe运行下载/解压下载;
管理员身份运行:ollama serve
在进行下载模型和使用模型时,都要保持这个终端服务是开启的;
查看官方支持的模型有哪些,确定自己需要的模型名称;
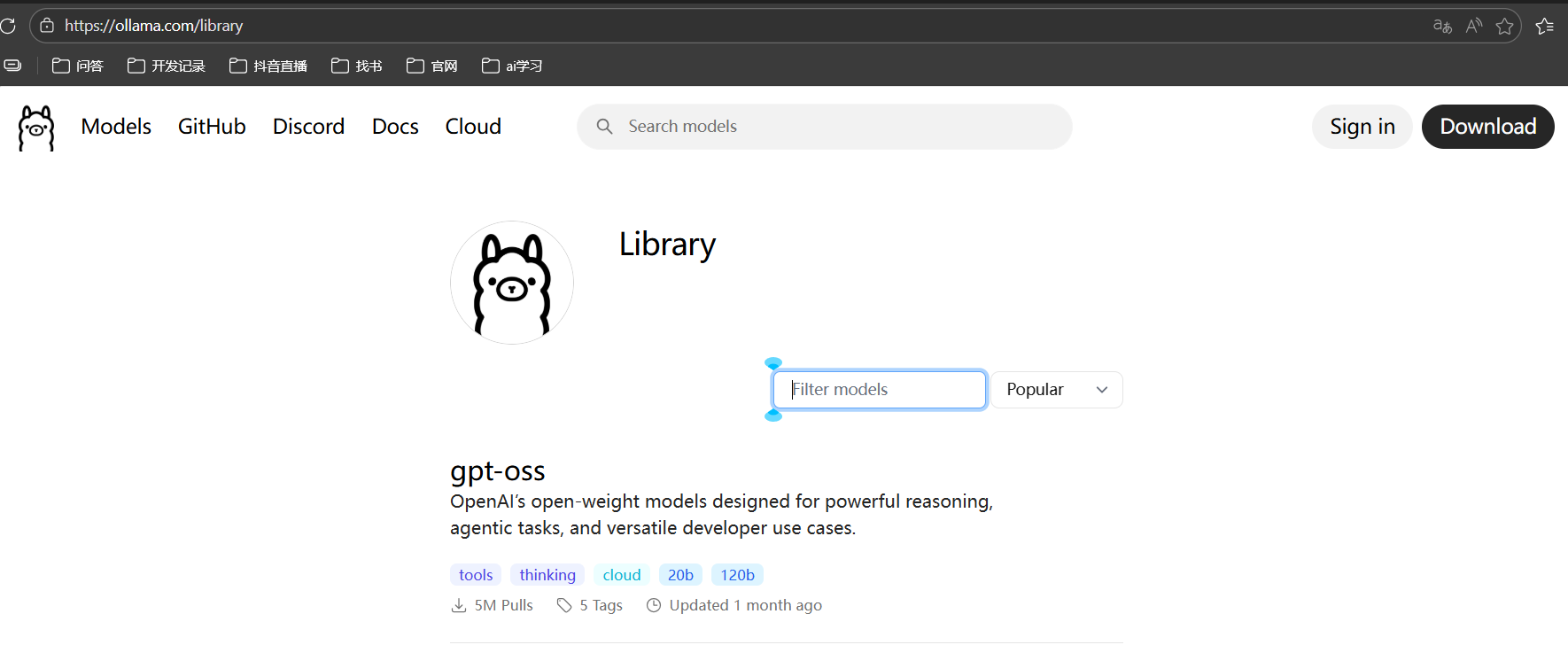
另起一个窗口,运行下载: ollama pull <model_name>
删除的话用:ollama rm <model_name>
下载后运行:ollama run <model_name>
ctrl+d 可退出
你也可以创建自己自定义的模型:
ollama create my-model -f ./Modelfile
ollama run my-model
Modelfile内容举例:
FROM qwen:7b
PARAMETER temperature 0.7
SYSTEM "你是一个AI助手。"
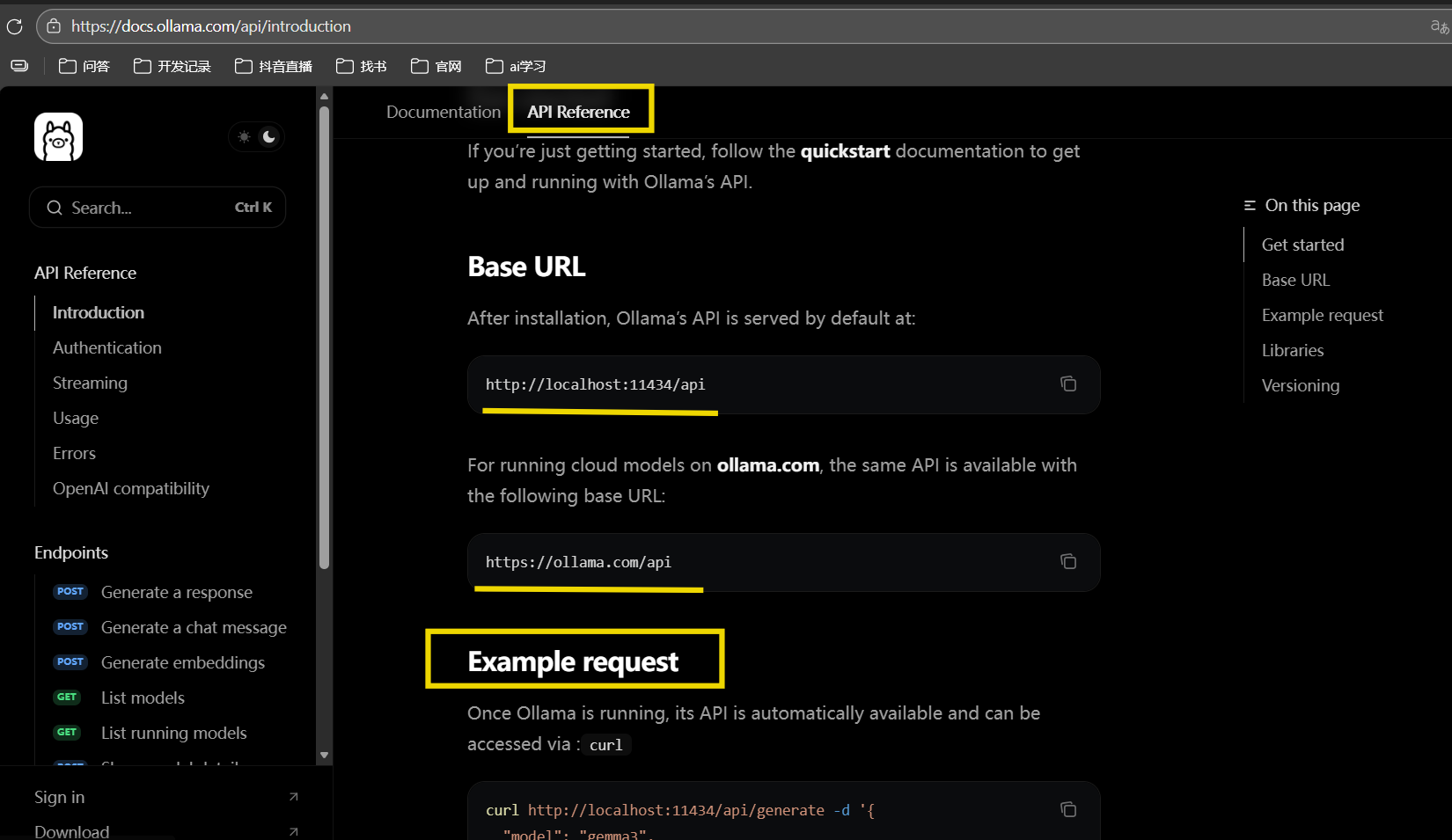
可以在项目里集成ollama的模型,ollama提供api接口被调用;
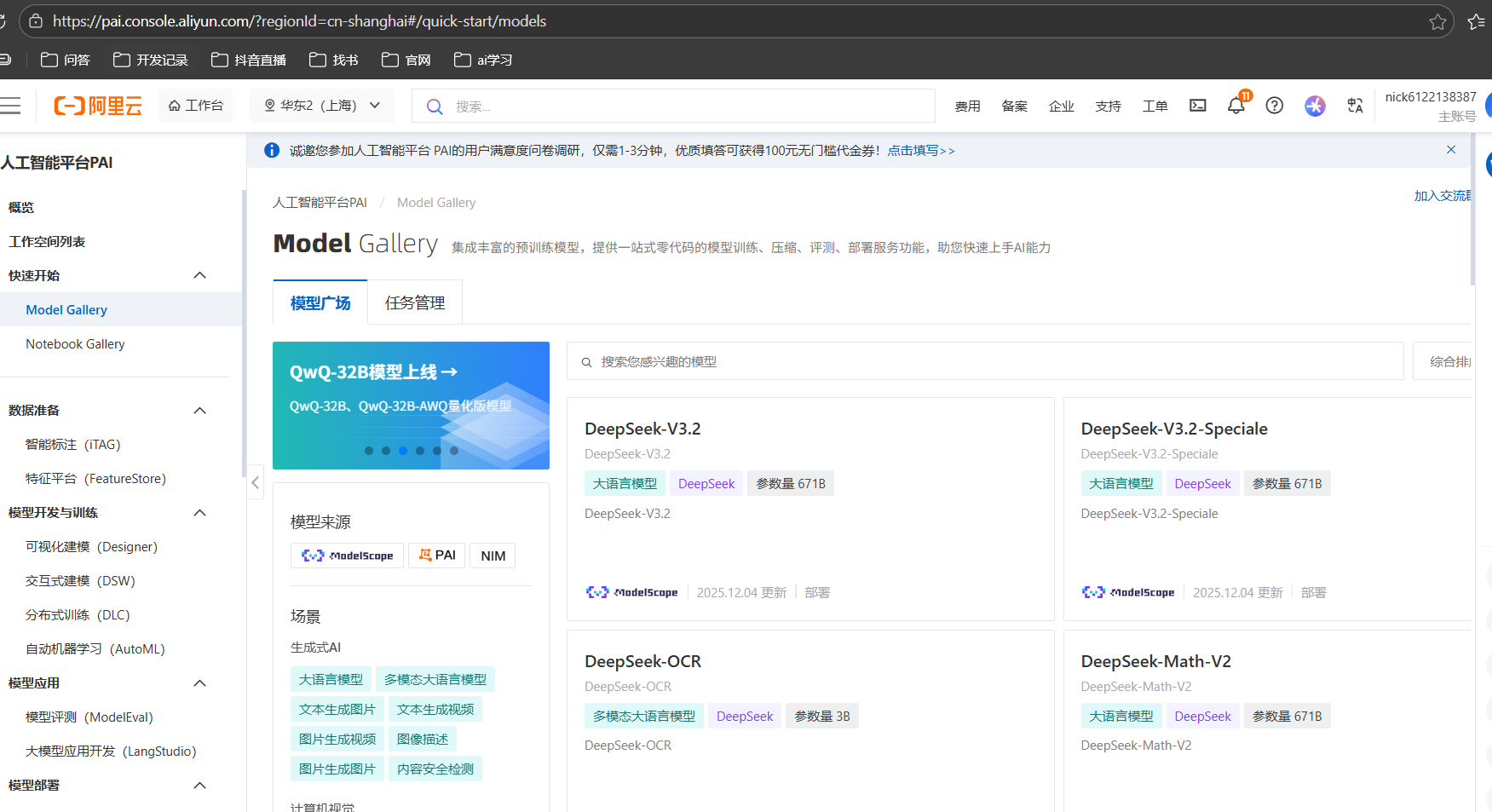
3. Model Gallery
前面两个使用ai模型,都要下载到本地很麻烦,那么Model Gallery可以直接完成模型的云上部署,本地项目里可api调用,网上可直接进行使用,但是部署和训练都是要收费的,有预算可以试试,没有预算,就考虑上面两种方式,本地部署一定要保证内存足够。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)