【AI智能体】如何让小参数模型发挥出满血模型的效果
摘要:本文探讨了推理模型在专业领域的优势与局限,重点分析了智能体深度思考能力如何通过任务拆解和实时数据调用弥补传统模型的不足。通过万科债务问题的实测对比,验证了深度思考模式下小参数模型能接近满血大模型的输出质量,同时具备成本优势。研究指出,在任务拆解细致的前提下,模型参数量的差异对生成质量影响显著降低,为AI应用的性价比优化提供了实践路径。未来智能体拆解任务的方式有望在成本与质量间实现更好平衡。
文章目录
1. 深度思考介绍
在专业领域的实践中,推理模型已展现出不可替代的独特优势。其核心竞争力在于一套严谨的问题处理逻辑:首先对用户输入的需求进行精细化拆解,将复杂问题转化为多个可落地、可执行的子步骤;随后针对每个子步骤展开定向分析与精准解答,确保每个环节的处理质量与逻辑闭环;最后,模型会对所有子步骤的解答结果进行系统性汇总与整合,形成完整、连贯的最终解决方案。
凭借这种“拆解-执行-汇总”的严谨流程,推理模型即便面对简洁的提示词(Prompt),也能输出媲美非推理模型在复杂提示词驱动下的效果,为用户提供高效且精准的问题解决方案。不过需要明确的是,推理模型存在一个典型局限:在常规执行模式下,其推理过程具有“一气呵成”的特性——若将用户需求拆解为5个核心步骤,模型会按预设逻辑完成全流程推理,而不会针对单个步骤主动调用外部工具获取实时数据。这一特性使其在需要动态更新数据支撑的实时数据分析场景中,效果往往较为有限。
智能体的“深度思考能力”恰好能弥补这一短板,进一步强化全流程的动态数据获取与处理能力:对于非推理模型,智能体可主动发起任务拆解,模拟并实现推理模型的精细化分析过程,填补其在逻辑拆解层面的不足;对于推理模型,智能体能够为其每个执行步骤赋能,通过主动调用外部工具、对接实时数据源等方式,强化步骤级的实时数据获取与更新能力,破解其在实时分析场景中的应用瓶颈。
值得关注的是,在任务拆解足够细致的前提下,满血大模型(全参数大模型)与小参数大模型(轻量化大模型)在内容生成的核心质量与效果上,差异会显著降低。而小参数大模型凭借更低的部署成本、更高效的运行性能以及更灵活的适配能力,在高频次、轻量化的应用场景中反而更具优势——既能满足核心业务需求,又能有效控制研发与运维成本,具备更高的商业落地价值。
2. 实测验证
2.1. 测试验证话题
万科地产债务问题严重,你分析下万科能挺过去吗?
2.2 通义千问3-8B + 百度搜索
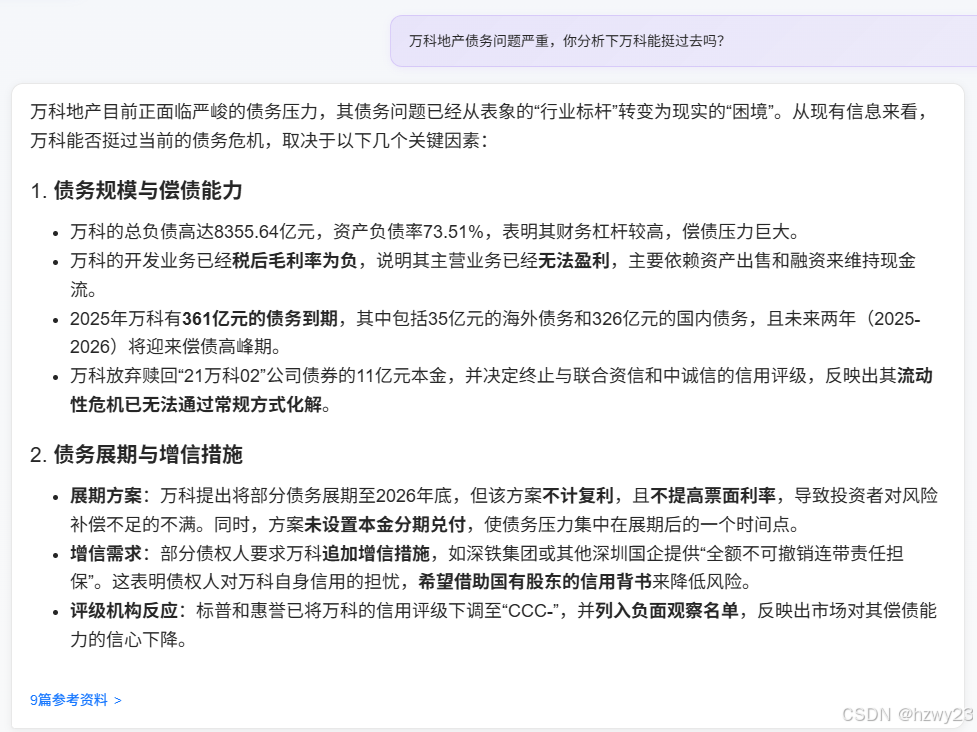
2.3 通义千问3-8B + 百度搜索 + 智能体深度思考

2.4. 百度文心一言4.5 Turbo
- 使用的工具:https://yiyan.baidu.com/
()
2.5 豆包大模型 + 深度思考
- 使用的工具:https://www.doubao.com

2.6 豆包大模型(未开启深度思考)
- 使用的工具: https://www.doubao.com

3. 总结
- 通常情况下,模型的参数量越大,其思考深度会更好,生成的内容详细程度越好
- 对于实时热点新闻数据,大模型需要借助工具获取最新数据才能比较准确的回答用户提出的问题
- 深度思考模式借助问题拆解,分步骤执行,每个步骤逐个解答(使用工具获取更多针对性数据回答)最终在生成的内容质量上可以向满血大模型看齐
- 未来随着AI应用的普及,成本与质量需要平衡时,通过智能体拆解任务逐个解答的方式,也能让低成本模型生成不亚于顶级模型的内容。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)