基于大数据美团数据分析可视化系统 美食数据采集 Flask框架 AI大模型 毕业设计✅
基于大数据美团数据分析可视化系统 美食数据采集 Flask框架 AI大模型 毕业设计✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
后端:Flask、PyMySQL、MySQL、urllib
前端:Jinja2、Jquery、Ajax、layui
美团网数据
二、功能结构
数据采集功能:美食店铺信息采集,从【美团网】中获取美食店铺的相关信息,包括店铺名称、地址、评分等,并将其存储到数据库中。主要使用爬虫技术对【美团网】店铺信息进行数据采集。
套餐推荐功能:用户套餐推荐根据套餐的评分、价格等信息进行排序推荐
(因为无法采集用户行为数据,所以无法做一些只能算法进行推荐,如果可以采集用户相关的行为数据可以进行协同过滤等算法进行推荐)。
美食数据管理:包括对美食店铺信息的增加、修改、删除和查询功能,以及对店铺信息的名称、均价、评分等属性的管理。
套餐数据管理:包括对套餐信息的增加、修改、删除和查询功能,以及对套餐的图片、价格等属性的管理。
留言功能:允许用户在系统中留下评论、建议等反馈信息,并提供相应的管理功能来处理留言数据。
用户管理功能:包括用户注册、登录、个人信息管理等功能,用于管理用户的身份和权限,并确保系统的安全性和可靠性。
2、项目界面
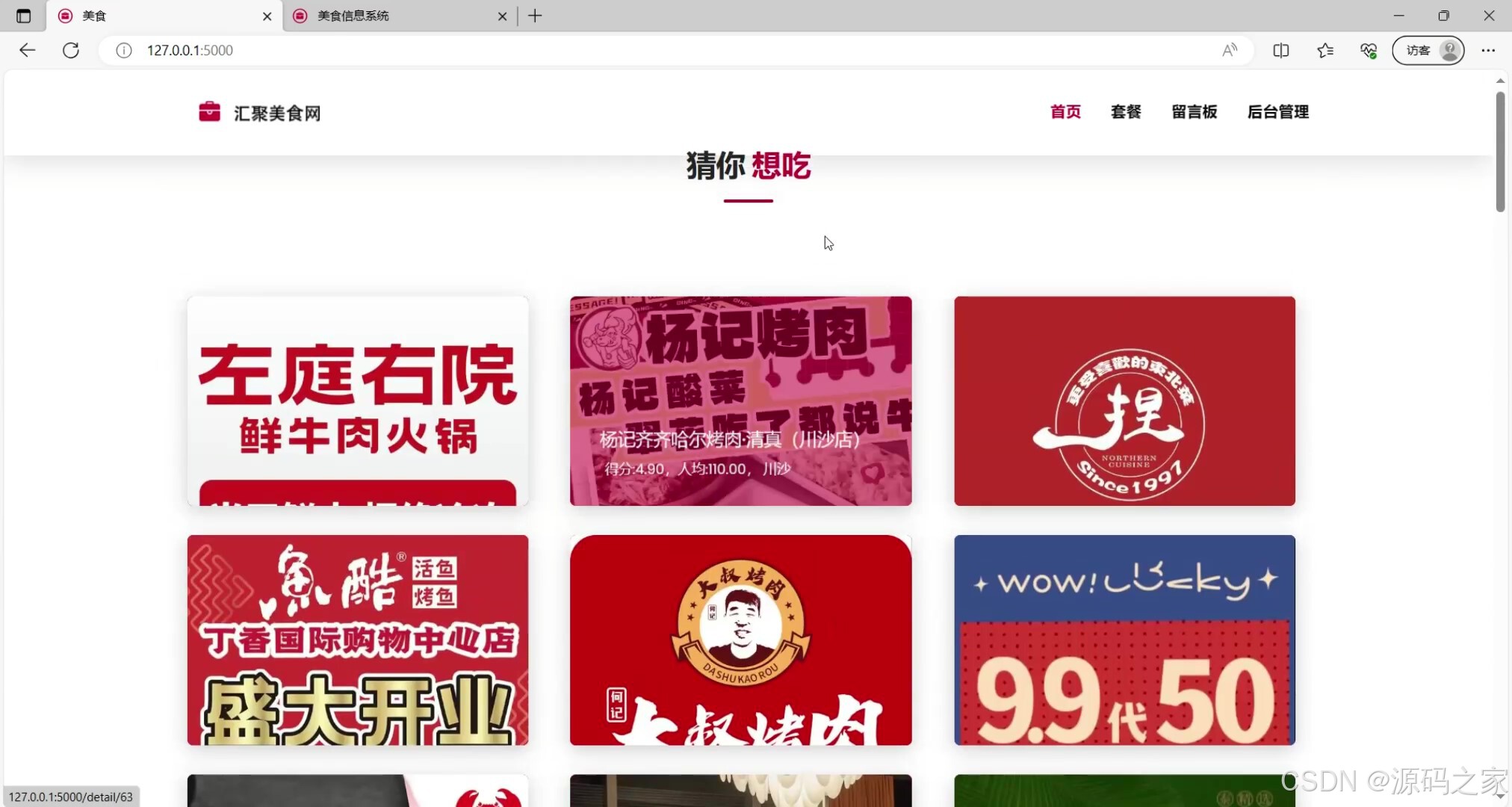
(1)猜你想吃
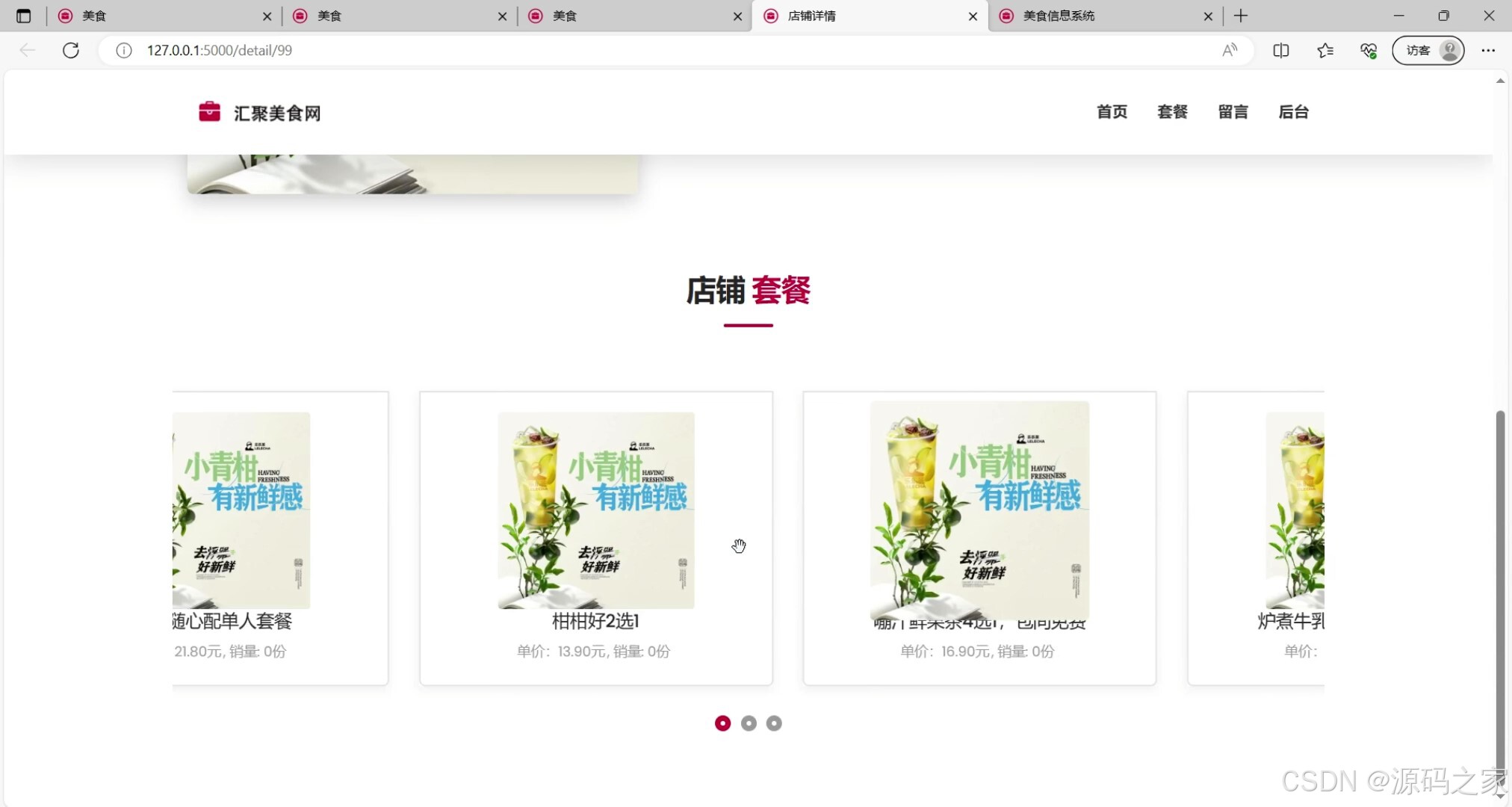
(2)店铺详情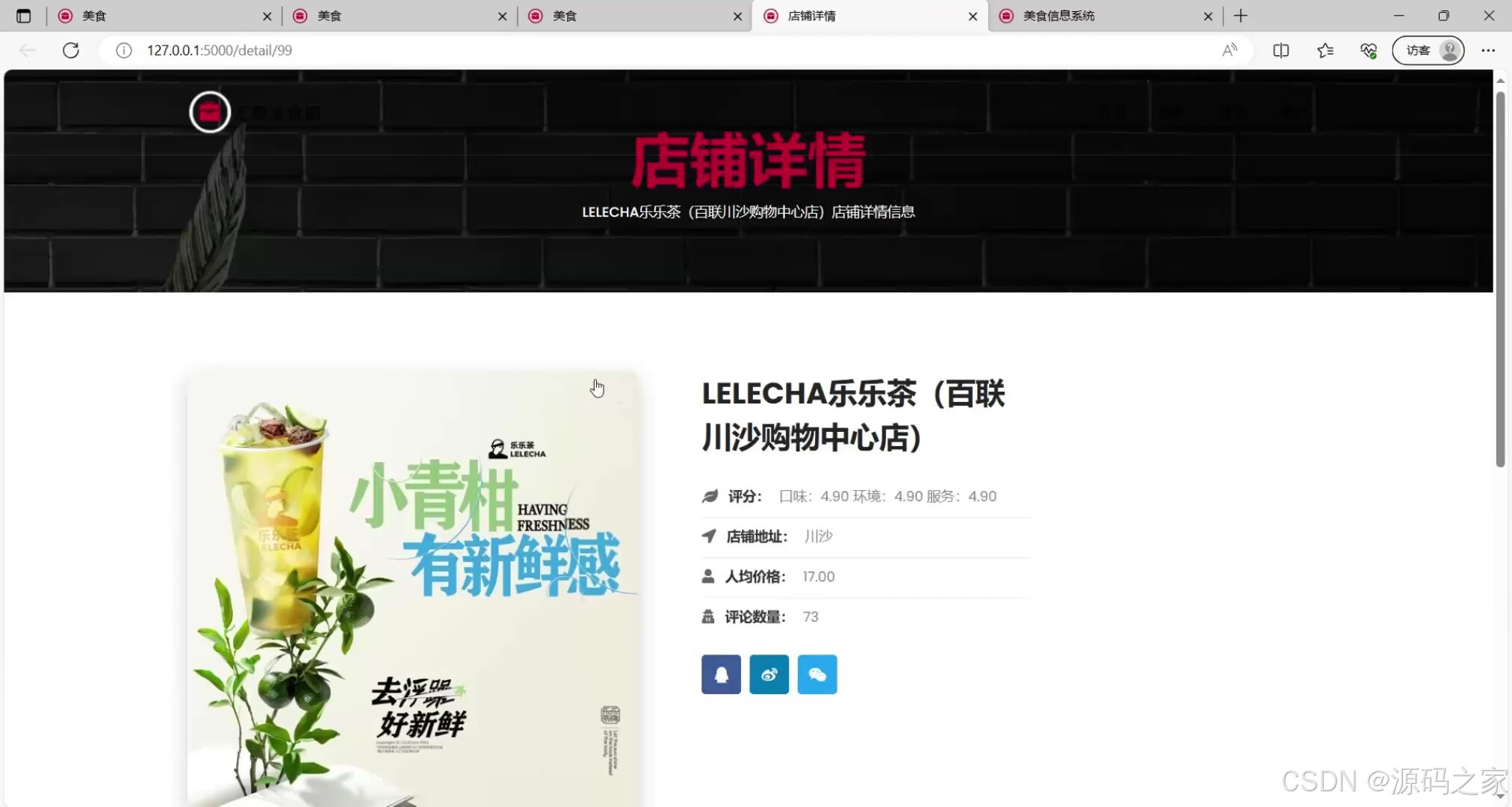
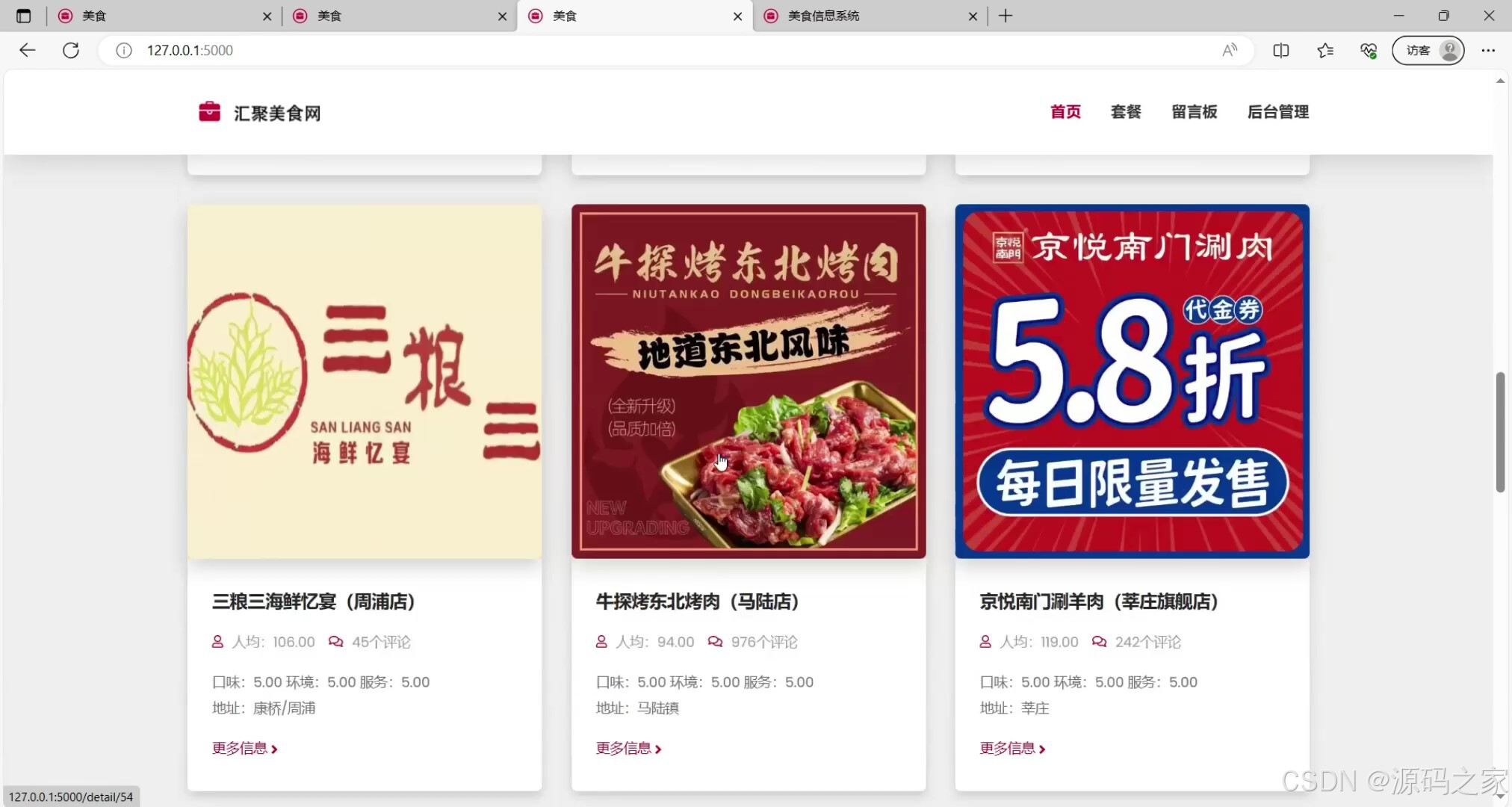
(3)店铺推荐
(4)店铺推荐2
(5)首页
(6)美食数据
(7)注册登录
(8)留言板
(9)美食采集
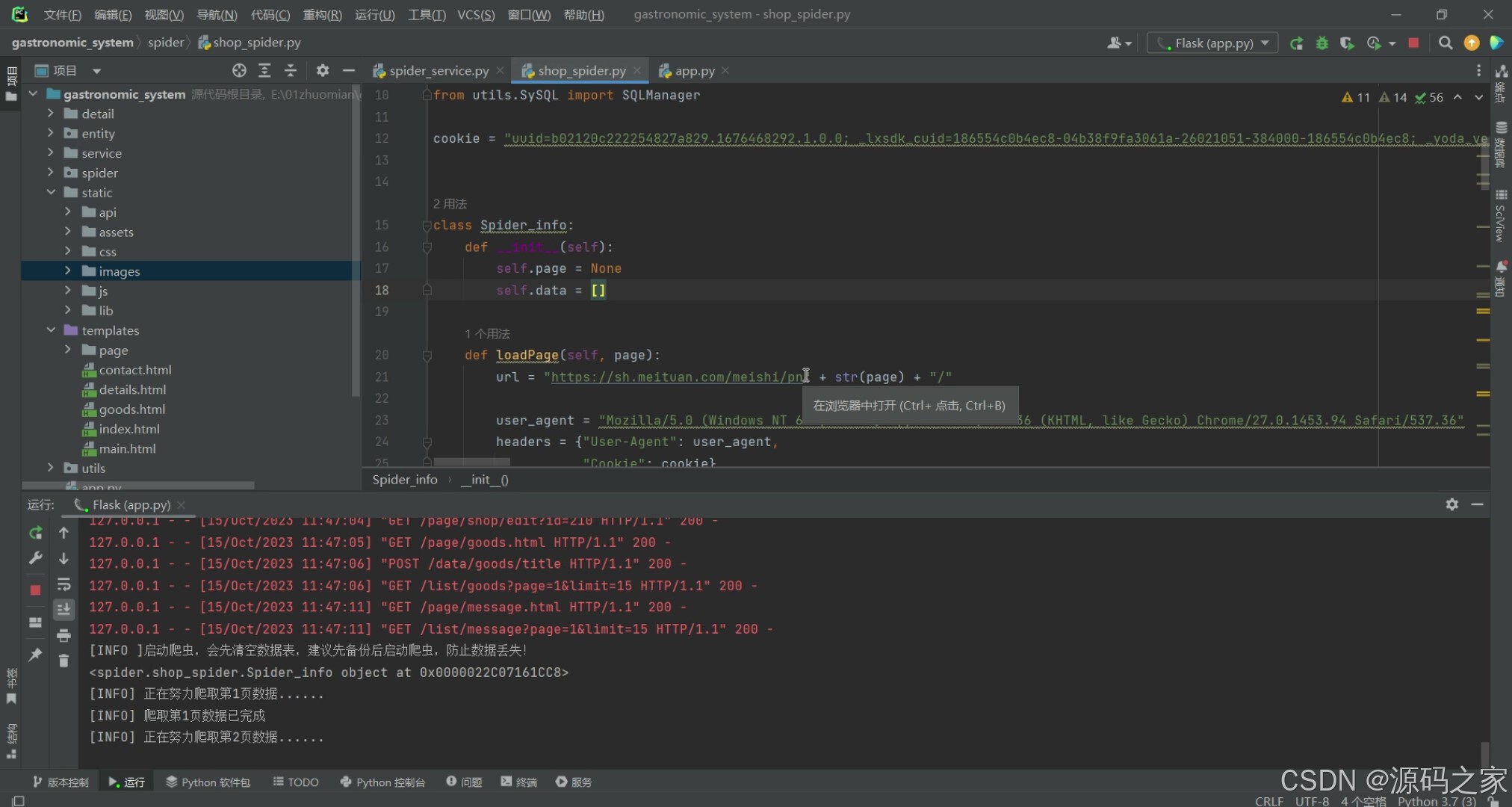
3、项目说明
摘 要
基于大数据的上海美食系统是一种以互联网和大数据技术为基础的美食推荐系统。该系统旨在为用户提供个性化、精准的美食推荐服务。它使用数据挖掘和自然语言处理技术,分析上海市美团网的美食评论和评价数据,从而为用户推荐最合适的上海美食。该系统的研究和实现对于上海美食文化的挖掘和传承有重要意义。通过挖掘大数据中的美食信息,可以深入了解上海美食的特色和品质,推动上海美食文化的传承和发展。同时,该系统的实现也为上海美食产业的发展提供了新的思路和方向,可以通过个性化的推荐服务和优化的用户体验,提高美食产业的竞争力和发展水平。在该系统的实现过程中,需要使用多种技术和方法。首先需要选择合适的爬虫框架,爬取上海美团网平台的数据。然后,使用数据挖掘和自然语言处理技术,对数据进行分析和处理,提取出有用的信息。最后,将处理好的数据存储到数据库中,并使用推荐算法和搜索引擎技术,为用户提供个性化、精准的美食推荐和搜索服务,而且研究显示出可喜的结果,个性化的食物推荐可以改善健康状况、减少食物浪费并提高可持续性。
该系统的实现需要充分考虑用户的需求和体验。为了提高用户的满意度和体验,系统需要不断更新和优化,不断提升推荐和搜索的精度和准确性。同时,系统还需要加强用户交互和反馈机制,让用户更好地参与到系统的开发和改进中。通过不断优化和改进,基于大数据的上海美食系统将为用户提供更加优质的美食选择和服务体验。
关键词:数据库;大数据;爬取
4、核心代码
import os
import time
import urllib.request
import re
import json
from datetime import datetime
import requests
from utils.SySQL import SQLManager
class Spider_info:
def __init__(self):
self.page = None
self.data = []
def loadPage(self, page):
url = "https://sh.meituan.com/meishi/pn" + str(page) + "/"
user_agent = "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36"
headers = {"User-Agent": user_agent,
"Cookie": cookie}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req) # 返回的是http.client.HTTPResponse对象
html = str(response.read(), 'utf-8')
pattern = re.compile(r'{"poiId":.*?}]', re.S)
info_list = pattern.findall(html) # 获取数据,返回的是正则表达式在字符串中所有匹配结果的列表
# print(info_list)
for info in info_list:
info_json = json.loads(info + "}")
self.data.append(info_json)
def getData(self, page):
self.page = page
for i in range(1, self.page):
print("[INFO] 正在努力爬取第" + str(i) + "页数据......")
self.loadPage(i)
time.sleep(2) # 暂停2s防止反扒
print("[INFO] 爬取第" + str(i) + "页数据已完成")
return self.data
def start_shop_spider_to_mysql(page):
# 先清空数据表
sqlManager = SQLManager()
# clear_shop_sql = "TRUNCATE shop;"
# clear_goods_sql = "TRUNCATE goods;"
# clear_log_sql = "TRUNCATE slog;"
# sqlManager.moddify(clear_shop_sql)
# sqlManager.moddify(clear_goods_sql)
# sqlManager.moddify(clear_log_sql)
# try:
mySpider = Spider_info()
print(mySpider)
data = mySpider.getData(page)
print(data)
shop_sql = "INSERT INTO `shop` (`poiId`, `frontImg`, `title`, `avgScore`, `allCommentNum`, `address`, `avgPrice` ) VALUES(%s, %s, %s, %s, %s, %s, %s);"
goods_sql = "INSERT INTO `goods` (`poiId`, `shopId` , `title`, `price` , `soldCounts`,`img` ) VALUES (%s, %s, %s,%s, %s,%s);"
print("[INFO] 正在努力清洗数据插入数据库......")
shop_count = 0
goods_count = 0
for item in data:
img_url = item['frontImg']
r = requests.get(img_url)
# 清理文件名
image_name = re.sub(r'[^\w\-_\. ]', '', os.path.basename(img_url))
with open('../static/images/meituan/' + image_name, 'wb') as f:
f.write(r.content)
save_path = "static/images/meituan/"+image_name
sid = sqlManager.instert(shop_sql, (item['poiId'], save_path, item['title'], item['avgScore'],
item['allCommentNum'], item['address'], item['avgPrice']))
poiId = item['poiId']
dealList = item['dealList']
shop_count += 1
for detail in dealList:
sqlManager.instert(goods_sql, (poiId, sid, detail['title'], detail['price'],
detail['soldCounts'], save_path))
goods_count += 1
print("[INFO] 清洗数据并插入数据库已完成")
t = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
sql = 'insert into slog VALUES (NULL, "【爬虫日志】美团上海美食商铺数据爬取成功,获取商铺:' + str(
shop_count) + '家,获取套餐:' + str(goods_count) + '个"," ' + t + ' ")'
sqlManager.moddify(sql)
sqlManager.close()
# except:
# print("[ERROR] 爬取数据保存入数据库出现异常")
# finally:
# sqlManager.close()
def start_shop_spide(page=3):
mySpider = Spider_info()
mySpider.getData(page)
if __name__ == '__main__':
# start_shop_spider_to_mysql(5) # 设置采集的页数
start_shop_spider_to_mysql(21) # 设置采集的页数
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)