联邦学习入门及案例实现
医院想联合训练 “癌症诊断模型”,但不能共享患者病历(隐私保护);银行想优化 “反欺诈系统”,却不能泄露客户交易数据(合规要求);电商想做 “个性化推荐”,但各平台数据互不互通(数据孤岛);我们想享受智能推荐、精准医疗的便利,却又害怕自己的照片、聊天记录等隐私数据被上传到陌生的服务器。联邦学习(Federated Learning)就是解决这个矛盾的 “魔法”—— 它让多个机构 / 设备在不共享原
文章目录
前言
现实场景中,往往有这样的矛盾:
- 医院想联合训练 “癌症诊断模型”,但不能共享患者病历(隐私保护);
- 银行想优化 “反欺诈系统”,却不能泄露客户交易数据(合规要求);
- 电商想做 “个性化推荐”,但各平台数据互不互通(数据孤岛);
- 我们想享受智能推荐、精准医疗的便利,却又害怕自己的照片、聊天记录等隐私数据被上传到陌生的服务器。
联邦学习(Federated Learning)就是解决这个矛盾的 “魔法”—— 它让多个机构 / 设备在不共享原始数据的前提下,一起训练出更聪明的 AI 模型。核心原则只有 6 个字:数据不动,模型动 。本篇博客旨在介绍联邦学习的基本概念以及工作流程,适用于初学者。
1.联邦学习的定义
联邦学习不仅仅是一种算法,更是一种 “以数据为中心”的机器学习范式 和 “分布式系统”。其核心目标是在多个持有本地数据的客户端(Client)之间,通过协作训练一个高质量的全局模型(Global Model),同时严格保证原始数据不离开本地。
一个标准的联邦学习系统通常包含以下关键角色:
- 服务器: 负责全局模型的初始化、客户端选择、模型聚合与分发。它是协调者。
- 客户端: 持有本地私有数据,负责在本地数据集上执行模型训练,并计算模型更新。
- 全局模型: 最终期望获得的、融合了所有客户端知识共享的中央模型。
2.工作流程
联邦学习的核心是 “分散训练 + 集中聚合”,简化成 4 步循环,如下图所示: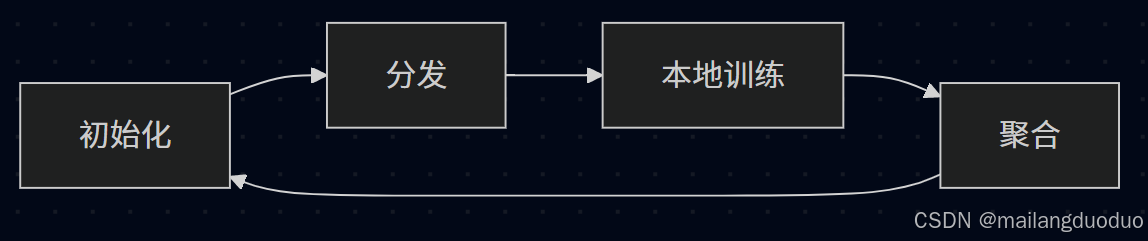
下面以训练识别癌症的神经网络任务为例对上图过程进行阐述:
- 初始化:中央服务器制定“基础模型”及识别癌症的神经网络框架;
- 分发:服务器从所有参与者即医院中,随机挑选一小部分,并把当前的初始模型发送给它们。当然此处也可以分发给所有医院。
- 本地训练:每家医院用自己的病历数据(不上传)训练模型,得到"本地优化参数”(比如调整后的神经网络权重);
- 聚合:服务器收集所有本地参数,用一种特殊的算法(比如联邦平均算法)将它们融合在一起,形成一个更强大、更全面的“全局模型更新”。
- 循环往复: 服务器用这个更新后的全局模型,替换掉旧的模型。然后,重复第2步到第4步。经过多轮这样的迭代,模型会变得越来越聪明、越来越精准。
3.联邦学习的分类
根据参与方的数据特点,联邦学习主要分 3 类:
横向联邦学习: 客户端间数据特征重叠多,但样本重叠少。例如,两家银行的用户群体不同(样本不同),但业务特征相似(都有存款、消费等特征)。这是最常见的形式。
纵向联邦学习: 客户端间样本重叠多,但特征重叠少。例如,同一城市的银行和电商,用户群体高度重叠(样本相同),但拥有的用户特征不同(金融特征 vs. 消费特征)。这通常需要加密实体对齐等更复杂的技术。
联邦迁移学习: 客户端间样本和特征重叠都很少,尝试利用迁移学习来提升模型效果。
4.小案例
本案例主要实现基于MNIST的手写数字识别联邦学习,使用联邦平均算法。
4.1环境配置
这里需要安装一个基础的深度学习框架——pytorch和轻量化联邦学习工具pysyft。
这里切记不要先安装pytorch,直接按照下列指令安装即可
- 创建虚拟环境
conda create -n pysyft python=3.9
- 激活环境
conda activate pysyft
- 安装syft
pip install syft==0.8.4
这里选择的是syft==0.8.4版本,与之匹配的pytorch版本可以选择torch==1.13.1
4. 安装适配版本的pytorch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
你也可以选择其他版本的,和对应的syft版本匹配即可。
4.2代码部分
本案例使用较为简单的多层感知机实现对MNIST数据集的十分类。
4.2.1 数据集加载
首先对MNIST数据集进行下载,该数据集已内置在torchvision.datasets中,因此可以直接使用接口函数进行下载,并通过参数transform进行预处理操作,代码如下:
def load_dataset():
transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transforms)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transforms)
print("数据集加载完成")
return trainset, testset
4.2.2多层感知机模型结构
因为模型输入是1×28×28的图片大小,输出是分类标签,因此模型最终的输出是10个节点,中间的节点数原则上可以任意,不过一般为2的幂次。这类定义如下网络结构:
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 输入:28x28=784维
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10) # 输出:10类(0-9)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = x.view(-1, 28 * 28) # 展平图像
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
4.2.3 拆分数据集
- 加载数据集,可以直接调用之前编写的函数;
- 创建联邦节点:这部分不同版本的
syft可能有所不同 - 拆分数据集模拟本地私有数据
# 1. 加载数据集
trainset, testset = load_dataset()
# 2. 创建联邦节点(去掉初始化参数,用列表+名称标识)
alice = sy.Domain()
bob = sy.Domain()
charlie = sy.Domain()
server = sy.Domain()
clients = [alice, bob, charlie]
client_names = ["alice", "bob", "charlie"] # 用名称列表标识客户端
# 3. 拆分训练集到各客户端(模拟本地私有数据)
dataset_size = len(trainset)
split_sizes = [dataset_size // 3, dataset_size // 3, dataset_size - 2 * (dataset_size // 3)]
client_datasets = random_split(trainset, split_sizes)
client_sizes = [len(ds) for ds in client_datasets] # 各客户端数据量(用于加权聚合)
4.2.4模型训练
初始化全局模型,客户端加载全局模型参数,本地训练5轮后,与其他客户端进行联邦聚合,将参数传递给全局模型,此时就完成了一轮联邦学习训练过程,之后可以使用测试集进行验证当前模型的泛化性能。
# 初始化全局模型
global_model = SimpleMLP()
print("\n===== 开始联邦训练 =====")
# 联邦训练主循环
global_epochs = 10 # 全局训练轮次
local_epochs = 5 # 每个客户端本地训练轮次
for global_epoch in range(global_epochs):
print(f"\n--- 全局轮次 {global_epoch + 1}/{global_epochs} ---")
# 客户端本地训练
client_models = []
for i in range(len(clients)):
# 复制全局模型到当前客户端
client_model = SimpleMLP()
client_model.load_state_dict(global_model.state_dict())
# 客户端本地训练(传名称标识)
trained_model = local_train(
client_names[i],
client_model,
client_datasets[i],
epochs=local_epochs
)
client_models.append(trained_model)
# 服务器聚合模型
global_model = fed_avg(global_model, client_models, client_sizes)
# 评估当前全局模型
test_loss, test_acc = evaluate_model(global_model, testset)
print(f"全局模型评估 - 测试损失:{test_loss:.4f},测试准确率:{test_acc:.2f}%")
4.2.5 自定义函数体
上述训练过程中使用了自定义函数体local_train、fed_avg、evaluate_model这里提供该部分函数体的代码如下:
# 客户端本地训练函数
def local_train(client_name, model, dataset, epochs=2, lr=0.001):
"""单个客户端的本地训练"""
model.train()
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
total_loss = 0.0
for epoch in range(epochs):
for data, target in dataloader:
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
total_loss += loss.item() * data.size(0)
avg_loss = total_loss / len(dataset)
print(f"客户端 {client_name} 训练完成,平均损失:{avg_loss:.4f}")
return model
# 联邦聚合函数(FedAvg算法)
def fed_avg(global_model, client_models, client_sizes):
"""加权平均聚合客户端模型参数"""
aggregated_params = {}
total_size = sum(client_sizes)
# 遍历模型的每一层参数
for param_name in global_model.state_dict().keys():
# 按客户端数据量加权求和
param_sum = sum(
client_models[i].state_dict()[param_name] * (client_sizes[i] / total_size)
for i in range(len(client_models))
)
aggregated_params[param_name] = param_sum
# 更新全局模型
global_model.load_state_dict(aggregated_params)
return global_model
# 模型评估函数
def evaluate_model(model, testset):
"""评估模型在测试集上的准确率"""
model.eval()
criterion = nn.CrossEntropyLoss()
dataloader = DataLoader(testset, batch_size=100, shuffle=False)
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data, target in dataloader:
outputs = model(data)
loss = criterion(outputs, target)
total_loss += loss.item() * data.size(0)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
avg_loss = total_loss / len(testset)
accuracy = 100 * correct / total
return avg_loss, accuracy
4.2.6模型保存
torch.save(global_model.state_dict(), "federated_mnist_mlp.pth")
print("\n===== 联邦训练完成 =====")
print("最终模型已保存为:federated_mnist_mlp.pth")
5.完整代码及运行结果
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import random_split, DataLoader
import syft as sy
def load_dataset():
transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transforms)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transforms)
print("数据集加载完成")
return trainset, testset
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 输入:28x28=784维
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10) # 输出:10类(0-9)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = x.view(-1, 28 * 28) # 展平图像
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 客户端本地训练函数
def local_train(client_name, model, dataset, epochs=2, lr=0.001):
"""单个客户端的本地训练"""
model.train()
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
total_loss = 0.0
for epoch in range(epochs):
for data, target in dataloader:
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
total_loss += loss.item() * data.size(0)
avg_loss = total_loss / len(dataset)
print(f"客户端 {client_name} 训练完成,平均损失:{avg_loss:.4f}")
return model
# 联邦聚合函数(FedAvg算法)
def fed_avg(global_model, client_models, client_sizes):
"""加权平均聚合客户端模型参数"""
aggregated_params = {}
total_size = sum(client_sizes)
# 遍历模型的每一层参数
for param_name in global_model.state_dict().keys():
# 按客户端数据量加权求和
param_sum = sum(
client_models[i].state_dict()[param_name] * (client_sizes[i] / total_size)
for i in range(len(client_models))
)
aggregated_params[param_name] = param_sum
# 更新全局模型
global_model.load_state_dict(aggregated_params)
return global_model
# 模型评估函数
def evaluate_model(model, testset):
"""评估模型在测试集上的准确率"""
model.eval()
criterion = nn.CrossEntropyLoss()
dataloader = DataLoader(testset, batch_size=100, shuffle=False)
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data, target in dataloader:
outputs = model(data)
loss = criterion(outputs, target)
total_loss += loss.item() * data.size(0)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
avg_loss = total_loss / len(testset)
accuracy = 100 * correct / total
return avg_loss, accuracy
if __name__ == '__main__':
# 1. 加载数据集
trainset, testset = load_dataset()
# 2. 创建联邦节点(去掉初始化参数,用列表+名称标识)
alice = sy.Domain()
bob = sy.Domain()
charlie = sy.Domain()
server = sy.Domain()
clients = [alice, bob, charlie]
client_names = ["alice", "bob", "charlie"] # 用名称列表标识客户端
# 3. 拆分训练集到各客户端(模拟本地私有数据)
dataset_size = len(trainset)
split_sizes = [dataset_size // 3, dataset_size // 3, dataset_size - 2 * (dataset_size // 3)]
client_datasets = random_split(trainset, split_sizes)
client_sizes = [len(ds) for ds in client_datasets] # 各客户端数据量(用于加权聚合)
# 4. 初始化全局模型
global_model = SimpleMLP()
print("\n===== 开始联邦训练 =====")
# 5. 联邦训练主循环
global_epochs = 10 # 全局训练轮次
local_epochs = 5 # 每个客户端本地训练轮次
for global_epoch in range(global_epochs):
print(f"\n--- 全局轮次 {global_epoch + 1}/{global_epochs} ---")
# 客户端本地训练
client_models = []
for i in range(len(clients)):
# 复制全局模型到当前客户端
client_model = SimpleMLP()
client_model.load_state_dict(global_model.state_dict())
# 客户端本地训练(传名称标识)
trained_model = local_train(
client_names[i],
client_model,
client_datasets[i],
epochs=local_epochs
)
client_models.append(trained_model)
# 服务器聚合模型
global_model = fed_avg(global_model, client_models, client_sizes)
# 评估当前全局模型
test_loss, test_acc = evaluate_model(global_model, testset)
print(f"全局模型评估 - 测试损失:{test_loss:.4f},测试准确率:{test_acc:.2f}%")
# 6. 保存最终模型
torch.save(global_model.state_dict(), "federated_mnist_mlp.pth")
print("\n===== 联邦训练完成 =====")
print("最终模型已保存为:federated_mnist_mlp.pth")
运行结果:
结语
本案例通过实现MNIST数据集的分类案例进行代码层面的入门介绍联邦学习,希望能够对你有所帮助!
如有疑问,欢迎评论区留言!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)