OpenCreator 完整玩法指南:一个人搞定 AI 电商视觉和品牌视频
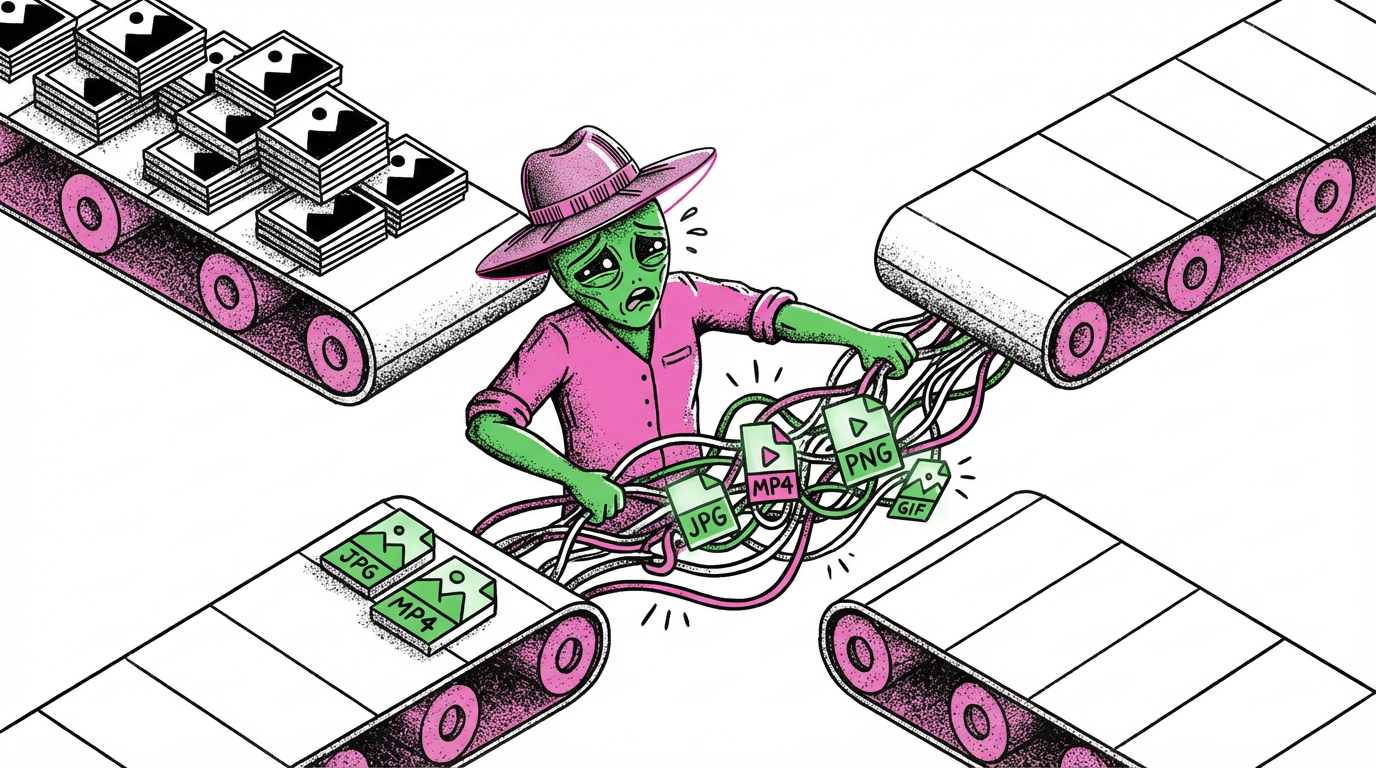
同样是给 100 个 SKU 做主图,用单点工具和用工作流的体验完全不一样。用单点工具的时候,每个 SKU 我都要:打开工具 A 上传产品图 → 等待生成 → 下载 → 打开工具 B 上传刚才的图 → 换背景 → 下载 → 打开工具 C → 再上传……一个 SKU 做完,光是等待和搬运就花了十几分钟。100 个 SKU 做下来,我感觉自己不是在创作,而是在做重复劳动。用工作流之后,我只需要把产品图
这两年,「工作流」「节点编排」「一键跑全流程」这样的 AI 创作工具越来越多。做图的、做视频的、做配音的,各有各的看家本领,但真正落到日常创作里,很多人还是会卡在一个问题上:到底该怎么把这些能力串成一条稳定、可复用的生产线?
这篇文章想做的事情很简单:不去罗列一大堆功能点,而是用几个完整的工作流,把「怎么想、怎么搭、怎么调」讲清楚。你可以把它理解成一篇「工作流使用说明」,重点放在思路和拆解方式上,而不是炫技。
这里我会用 OpenCreator 作为例子来演示,因为它把文本、图片、视频、音频这些能力都做成了可视化节点,比较适合讲解。但文章里的思路本身是通用的:只要你用的是支持工作流/节点编辑的工具,都可以照着这个方法去搭自己的链路。
什么是 AI 工作流,为什么它比单点工具更有用
先说一个让我印象很深的对比

同样是给 100 个 SKU 做主图,用单点工具和用工作流的体验完全不一样。
用单点工具的时候,每个 SKU 我都要:打开工具 A 上传产品图 → 等待生成 → 下载 → 打开工具 B 上传刚才的图 → 换背景 → 下载 → 打开工具 C → 再上传……一个 SKU 做完,光是等待和搬运就花了十几分钟。100 个 SKU 做下来,我感觉自己不是在创作,而是在做重复劳动。
用工作流之后,我只需要把产品图拖进去,点一下运行,剩下的事情系统自动完成。抠图、换背景、生成模特、调整光影,一条龙下来,我只需要在最后挑选满意的结果就行。
这就是工作流的核心价值:把「输入 → 处理 → 输出」的链路固化下来,上游的输出自动流向下游,不需要你手动搬运。第一次搭建可能要花点时间,但之后每次使用都是一键完成。
OpenCreator 是什么
简单说,OpenCreator 是一个多模态 AI 工作流编辑器。你可以在一个画布上,把文本、图片、视频、音频相关的 AI 能力像搭积木一样连接起来,组成一个完整的生产流程。
它不是某个单一功能的工具,而是一个让你自己设计生产线的平台。你可以用它做虚拟试穿、品牌广告、短视频、分镜脚本,甚至一些很奇怪的创意玩法。
接下来我会先介绍有哪些基础能力可以用,然后拆解几个实际的工作流案例。
有哪些基础能力可以用
在搭建工作流之前,你需要先了解有哪些「积木」可以用。我把它们分成几类来讲。
输入:你的素材从哪里来
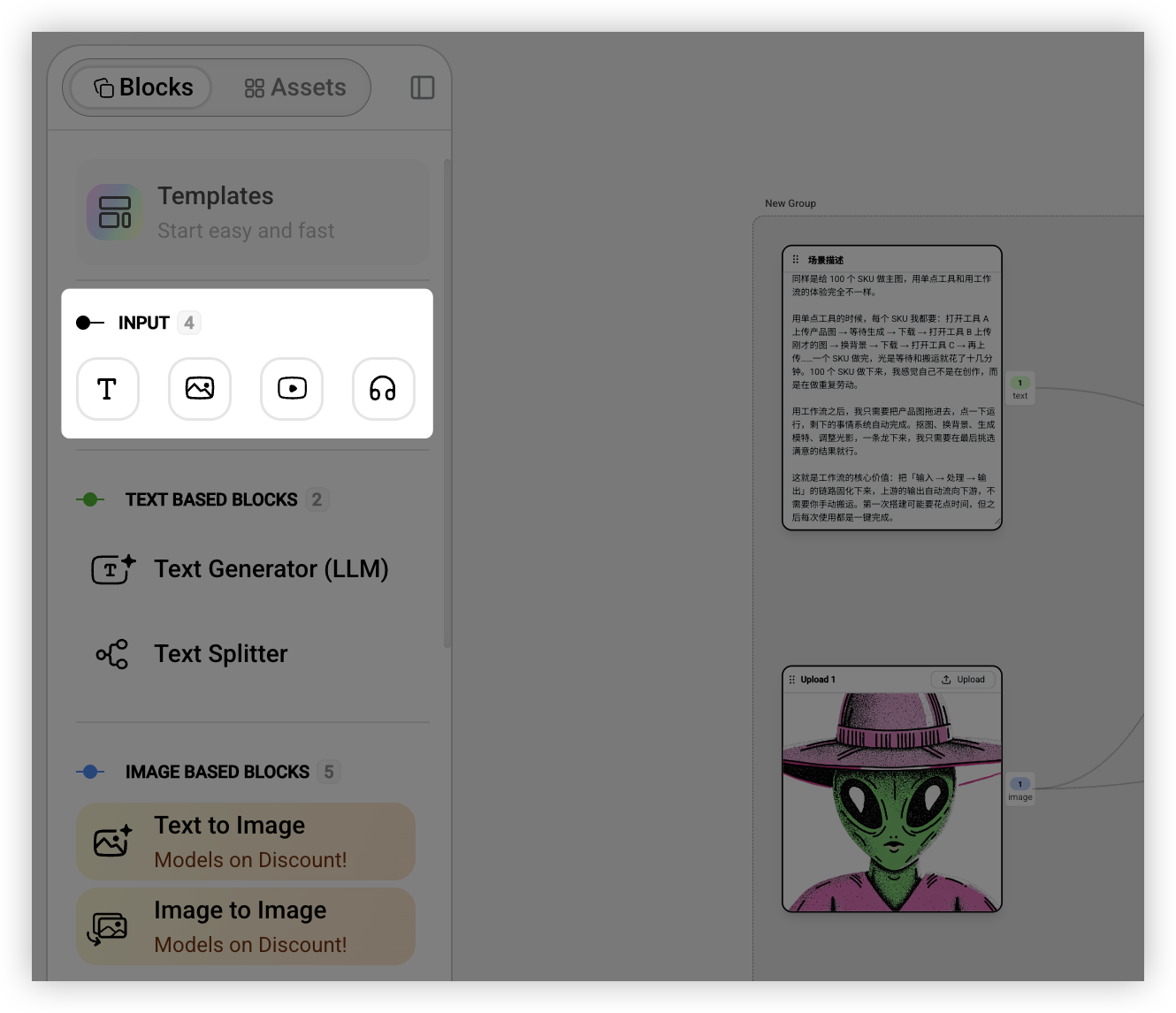
任何工作流都需要一个起点。你可以输入文字(比如广告文案、故事梗概)、图片(产品图、参考图)、视频或者音频。有个小细节我觉得挺方便:可以直接从桌面把文件拖进画布,系统会自动识别类型并创建对应的输入节点。
文本生成和处理
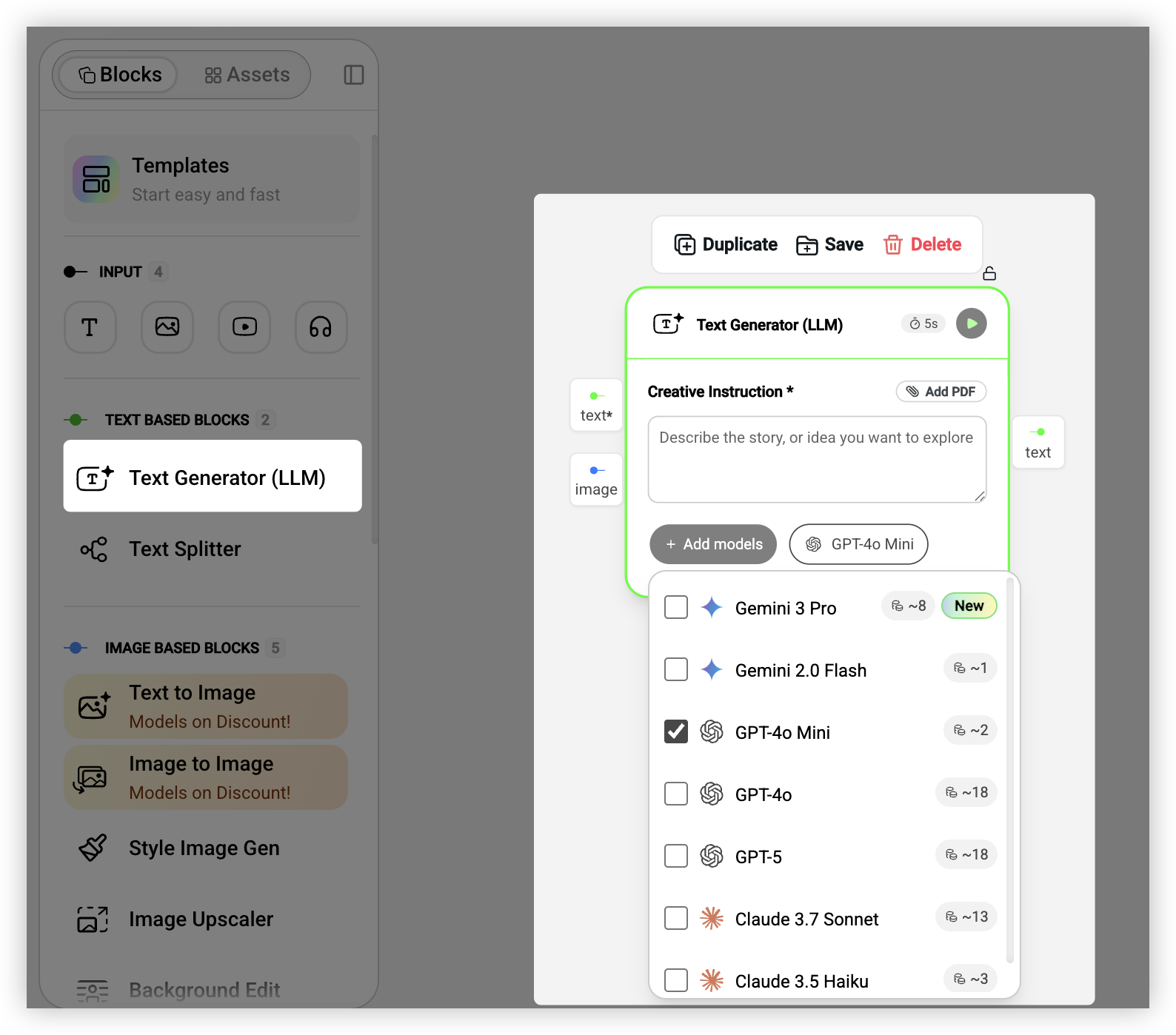
文本相关的能力主要有两个。一个是生成,把简短的想法扩写成完整的内容,比如输入「运动风格的服装广告」,输出一段完整的广告文案。另一个是拆分,把长文本切成多个短片段,这个在做分镜的时候特别有用。
背后可以选择不同的模型。GPT-4o 理解能力强但消耗 Credits 多,Gemini Flash 速度快价格便宜,Claude Sonnet 在长文本处理上表现不错。根据具体需求选就行。
图片生成和编辑
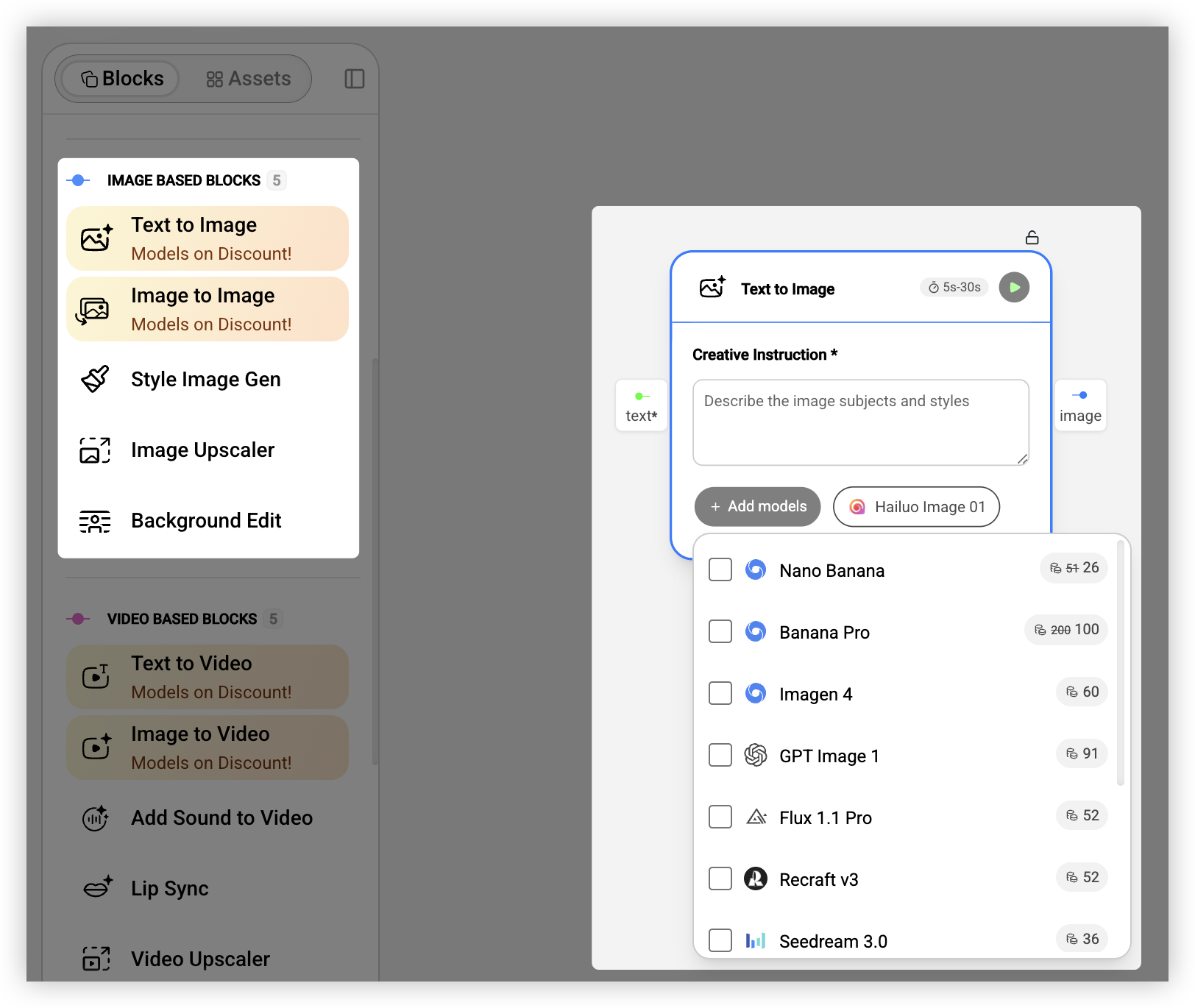
图片是电商和品牌营销场景里最核心的素材,所以这块的能力也最丰富。
文生图就是根据文字描述生成图片。目前效果最好的是 Google 的 Nano Banana Pro(也叫 Gemini 3 Pro Image),官方说它「专为专业资产生产和复杂指令设计,支持最高 4K 分辨率输出,具备高保真文字渲染能力,适合信息图、菜单、图表和营销素材」。我实际用下来确实觉得它在理解复杂提示词方面比其他模型强很多,而且可以同时输入最多 14 张参考图来控制生成结果。如果你需要快速迭代,可以用它的快速版 Nano Banana(基于 Gemini 2.5 Flash),速度更快但分辨率是 1024px。
图生图是以现有图片为基础,通过文字指令来修改它。比如「把背景换成咖啡馆」「把衣服颜色改成红色」。这个能力在虚拟试穿、产品换场景这些场景里用得特别多。图生图最强的也是 Nano Banana Pro(200 Credits/次),它有一个「思考模式」,会先生成中间的「思考图像」来优化构图,然后再输出最终结果。
还有背景编辑(替换或修改背景)、图片超分(放大并增强细节)、一键风格化(让多张图保持统一的视觉风格)这些能力,都是实际生产中经常会用到的。
视频生成和处理
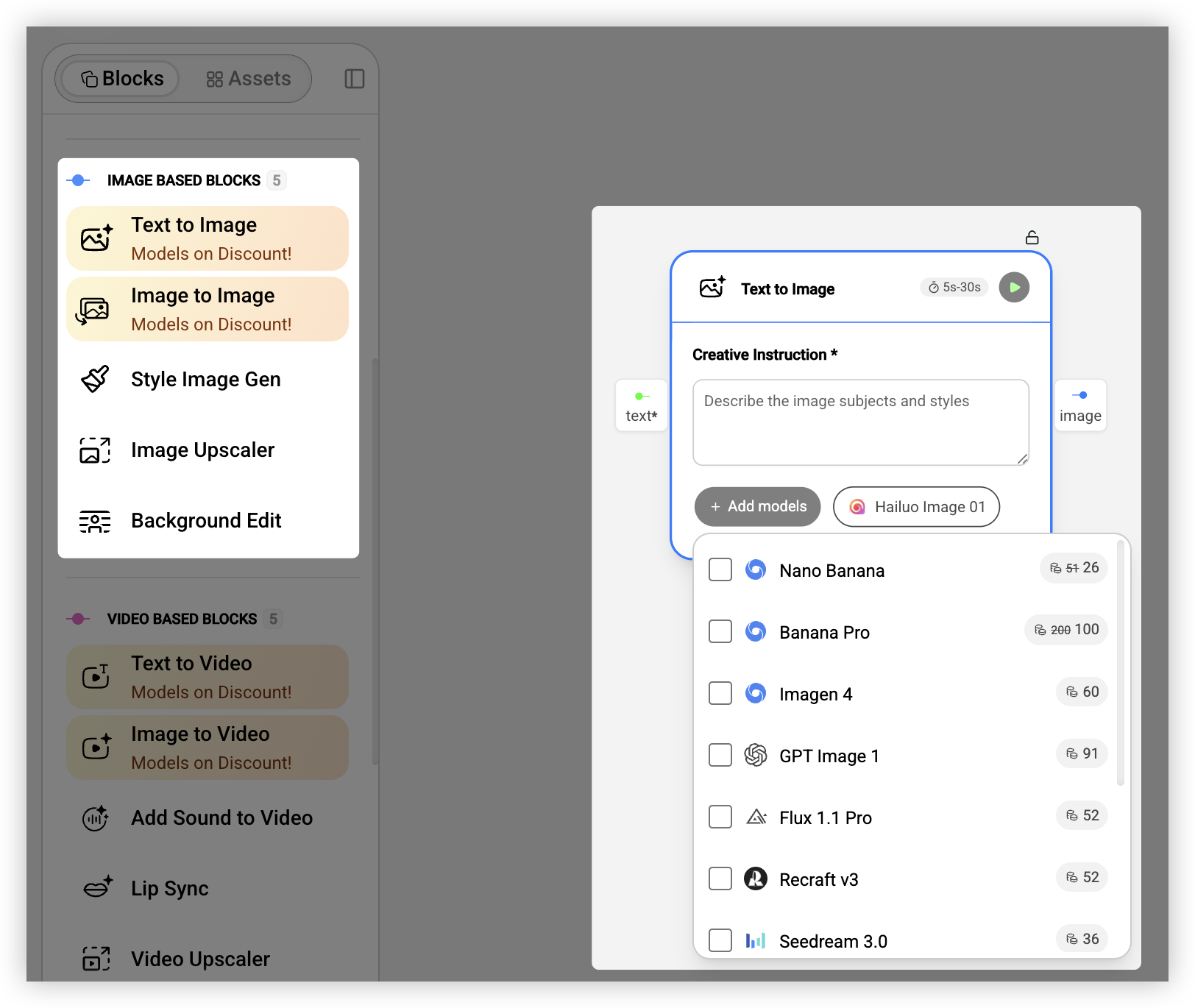
视频生成是这两年进步最快的领域。说实话,2023 年的时候我还觉得 AI 视频是个玩具,生成的东西抖动、变形,完全不能用。但现在的模型已经能生成相当不错的短视频了。
文生视频根据文字描述直接生成视频,适合做概念片、品牌故事。图生视频是我用得更多的,上传一张图片,让它「动起来」,比如产品 360 度旋转、人物微微转头眨眼。
视频模型的选择比图片更复杂,因为价格差异很大。目前最顶级的两个是 OpenAI 的 Sora 2 和 Google 的 Veo 3.1。Sora 2 的画质和物理准确性是目前最好的,一次生成要 960 Credits(约 $1.9),Pro 版本 4800 Credits(约 $9.6)可以输出 1080p。Veo 3.1 有个独特优势:可以同时生成视频和音频,官方定位是「Video, meet audio」,生成的视频自带音效甚至人物对话,Fast 版本 1440 Credits(约 $2.9),标准版 3200 Credits(约 $6.4)。如果预算有限,快手的 Kling 2.1 Pro 是个不错的选择,585 Credits(约 $1.2)就能生成质量不错的视频,官方说它「能够生成复杂的时空运动,模拟物理世界的特性」。
还有口型同步(让视频中的人物「说话」)、视频加音效、视频超分这些后处理能力。
音频生成
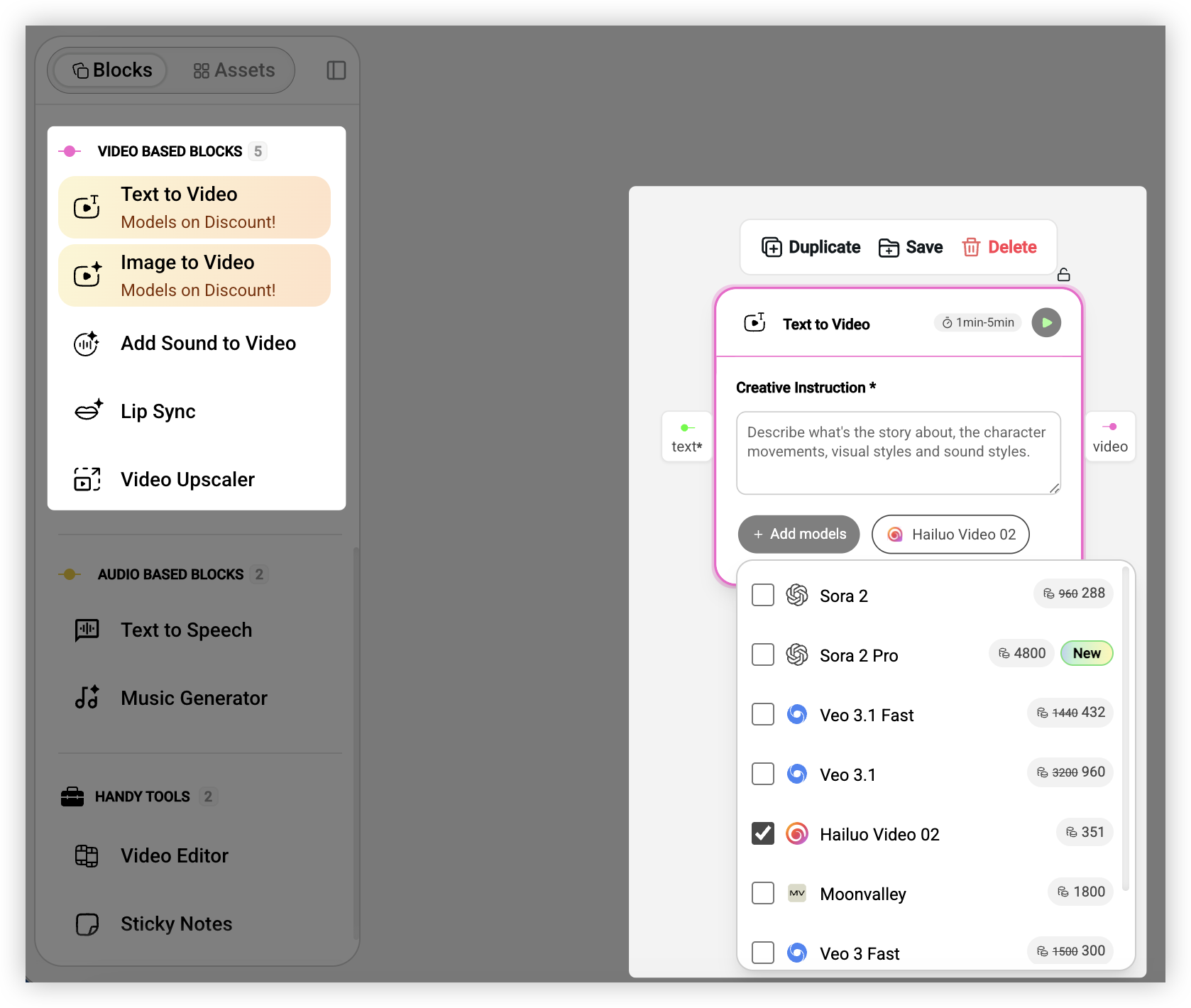
文字转语音可以把文本转成自然听感的配音,Fish Audio TTS 支持声音模仿,ElevenLabs v2 的对话感更强。音乐生成可以根据文字描述生成 BGM,还能选择只要伴奏不要人声。
组装和剪辑
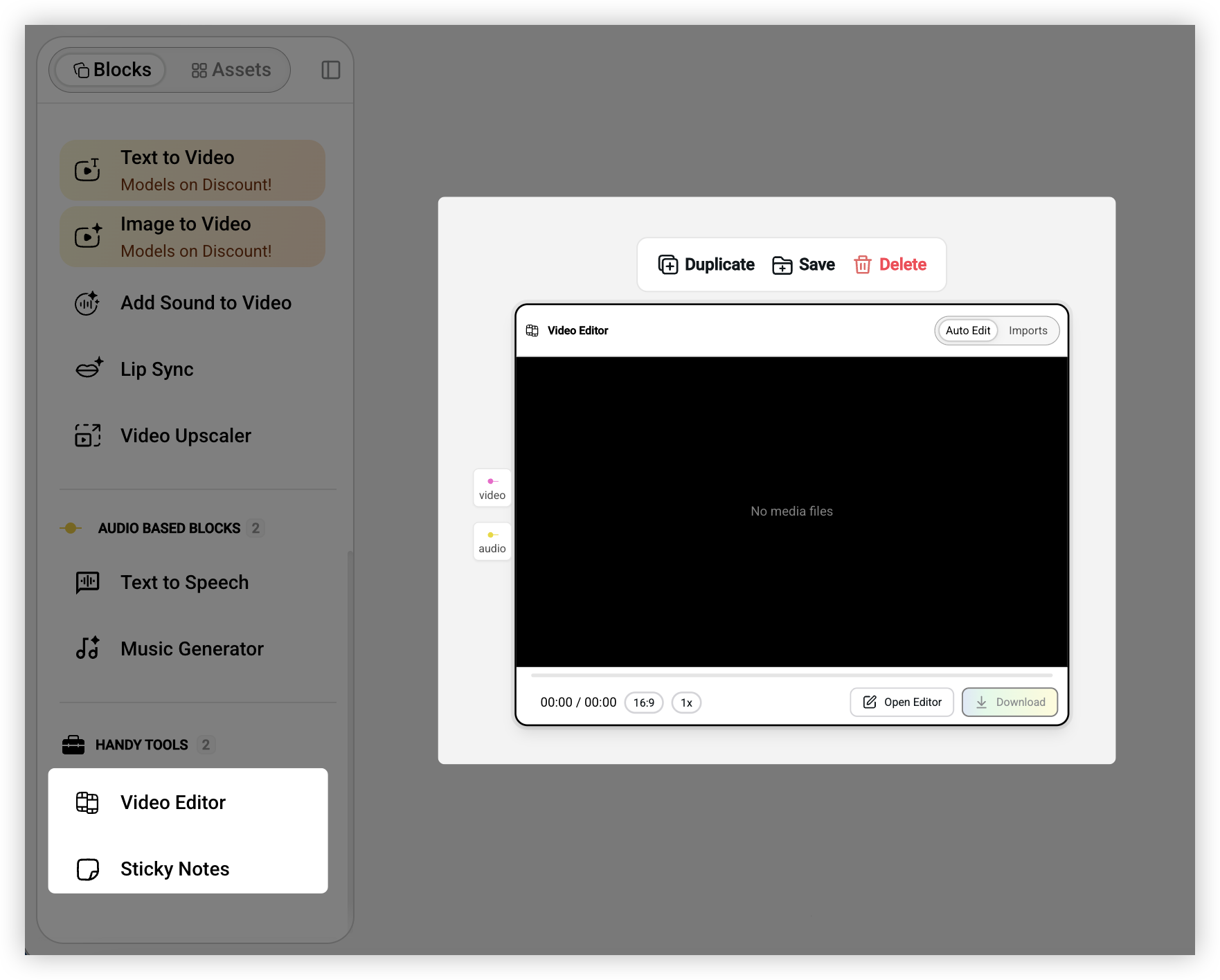
当你用前面这些能力生成了一堆素材之后,还需要把它们拼成完整的视频。Video Editor 会自动收集所有连入的素材,提供一个简化版的时间线编辑器,你可以拖拽调整顺序,也可以让系统自动编排。
工作流是怎么运行的
了解了有哪些能力之后,下一步是理解它们怎么串起来。
节点和连线
工作流本质上就是一个流程图:每个能力是一个节点,节点之间用连线传递数据。你从一个节点的输出端口拖一条线到另一个节点的输入端口,数据就会自动流过去。系统会校验连线是否合法,比如图片输出不能直接连到文本输入。
运行和调试
搭建好之后点「Run」,系统会按顺序依次执行各个节点。有几个功能我觉得很实用:可以暂停和继续,可以只重新运行某个节点而不是从头开始,也可以只测试某一段链路。每个节点都有状态显示,一眼就能看出进行到哪里了。
结果历史
这是我觉得设计得比较好的一个地方:每个节点的结果历史会被保存下来,而不是被覆盖。你可以多次运行同一个节点,然后在结果面板里浏览、对比,选择最满意的那个。选中的结果会被下游节点继续使用。
这种设计鼓励你多试几次。AI 生成本来就有随机性,同样的提示词可能产生不同的结果,多试几次往往能找到更好的。
新手怎么快速上手
如果你是第一次用工作流工具,可能会觉得有点不知道从哪里开始。OpenCreator 提供了一套 Tutorials(教程模板),专门帮助新手理解各个能力怎么用。

这些教程模板都很简单,通常只有 2-3 个节点,但能让你快速理解某个能力的输入输出是什么。比如:
Text to Image 教你怎么用文字生成图片,只有一个文本输入和一个图片生成节点,跑一遍就能理解文生图的基本流程。
Image to Video 教你怎么把静态图片变成动态视频,同样是最简单的两个节点,但能让你直观感受到图生视频的效果。
Multi References 教你怎么用多张参考图来控制生成结果,这个在需要保持风格一致的时候很有用。
Subject Consistency 和 Style Consistency 分别教你怎么保持主体一致性和风格一致性,这两个是做系列图的时候经常会遇到的问题。
Lip Sync 教你怎么让视频中的人物「说话」,口型和音频同步。
Background Remove & Edit 教你怎么抠图和换背景。
Draw to Edit 教你怎么用涂抹的方式指定要编辑的区域。
我的建议是:先把这些教程模板都跑一遍,每个花 5 分钟,大概半小时就能对所有基础能力有个直观的认识。然后再去看更复杂的工作流,就不会觉得那么难理解了。
几个实际的工作流拆解
理论讲完了,来看几个实际的例子。
我是怎么用 AI 做Virtual Try-on(虚拟试穿)的
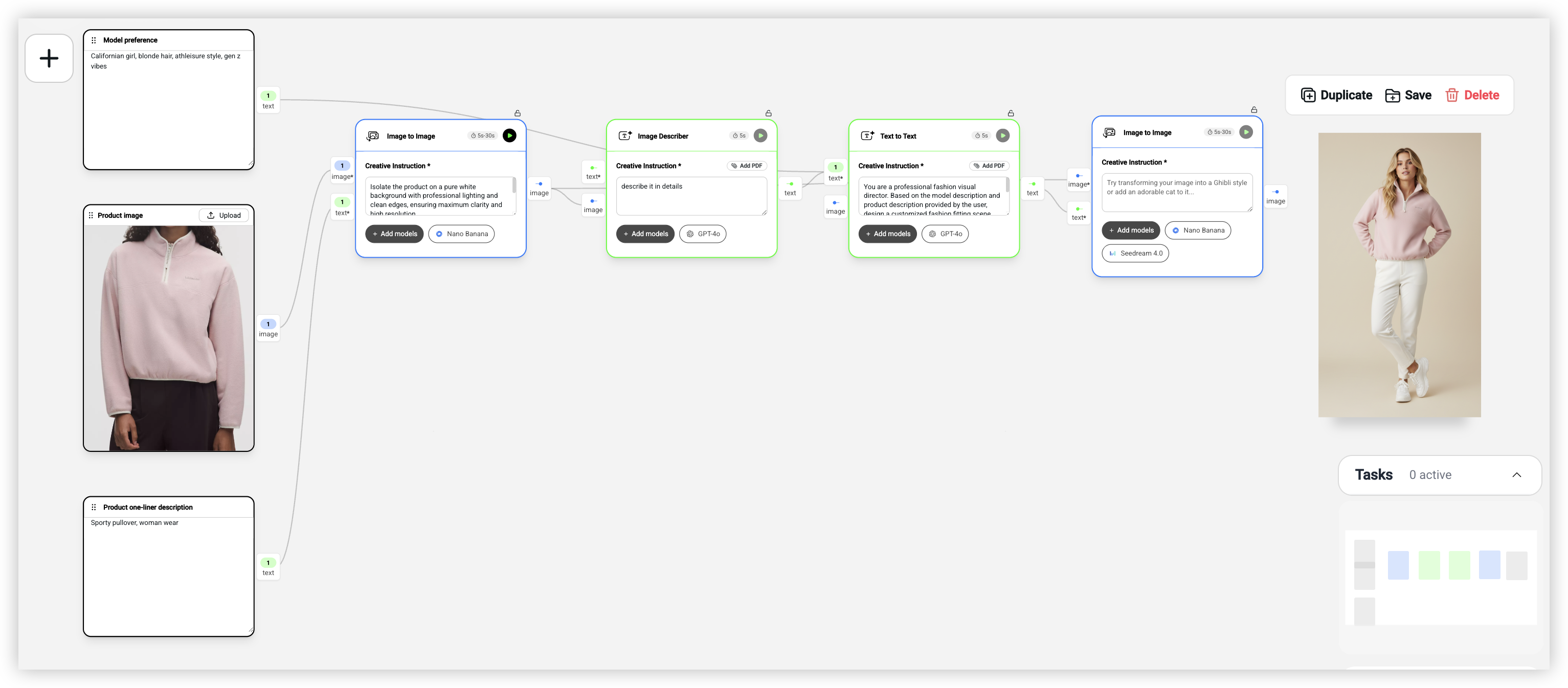
这是我用得最多的一个工作流,也是服装电商最刚需的场景之一。
要解决的问题:手上有一件衣服的平铺图,想要生成模特穿着这件衣服的上身图。传统做法是请模特拍摄,成本高、周期长。
这个工作流有 7 个节点:
首先是三个输入。第一个上传服装平铺图,比如一件运动卫衣的产品图。第二个输入你想要的模特风格,比如「Californian girl, blonde hair, athleisure style, gen z vibes」(大概意思是:加州女孩、金发、运动休闲风、Z 世代气质)。第三个输入产品的简短描述,比如「Sporty pullover, woman wear」(一件运动风女款套头卫衣)。
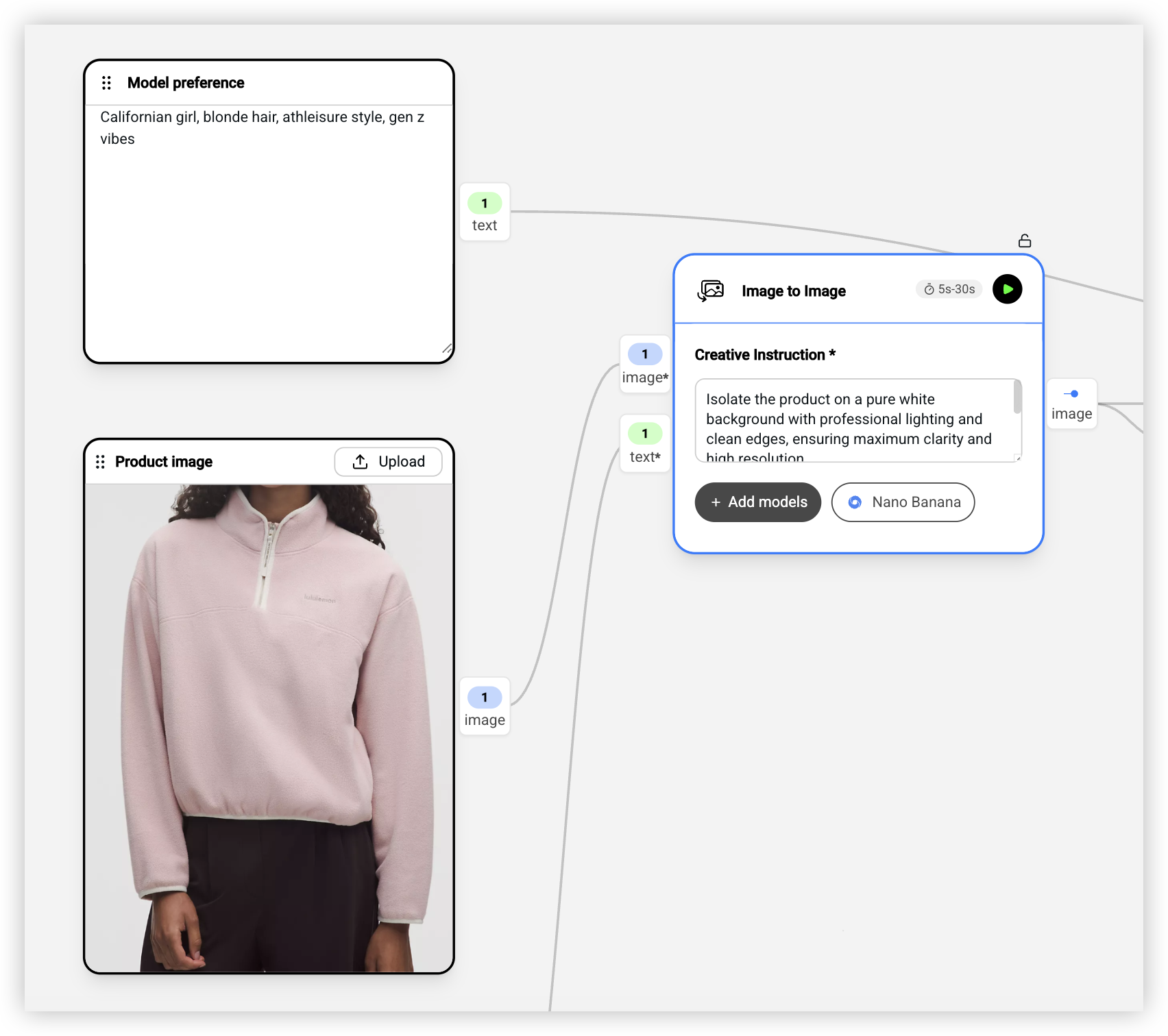
然后是第一个处理节点 Image to Image,用 Nano Banana Pro 模型把图片处理成干净的白底产品图,确保后续生成的时候 AI 能准确识别产品轮廓。
接下来是 Text Generator,用 GPT-4o 详细描述这件衣服的特征,输出类似「A sporty pullover with ribbed cuffs, relaxed fit, in heather grey color…」这样的描述(大概意思是:一件带罗纹袖口、宽松版型、浅灰色的运动卫衣)。
然后是 Text Generator,这是整个工作流的核心。它接收模特风格描述和产品描述,用 GPT-4o 生成一段完整的视觉场景描述。提示词大意是:「你是一个专业的时尚视觉总监,根据模特描述和产品描述,设计一个定制的时尚试穿场景,描述模特的姿势、表情、配饰、灯光氛围,确保产品是主角。」
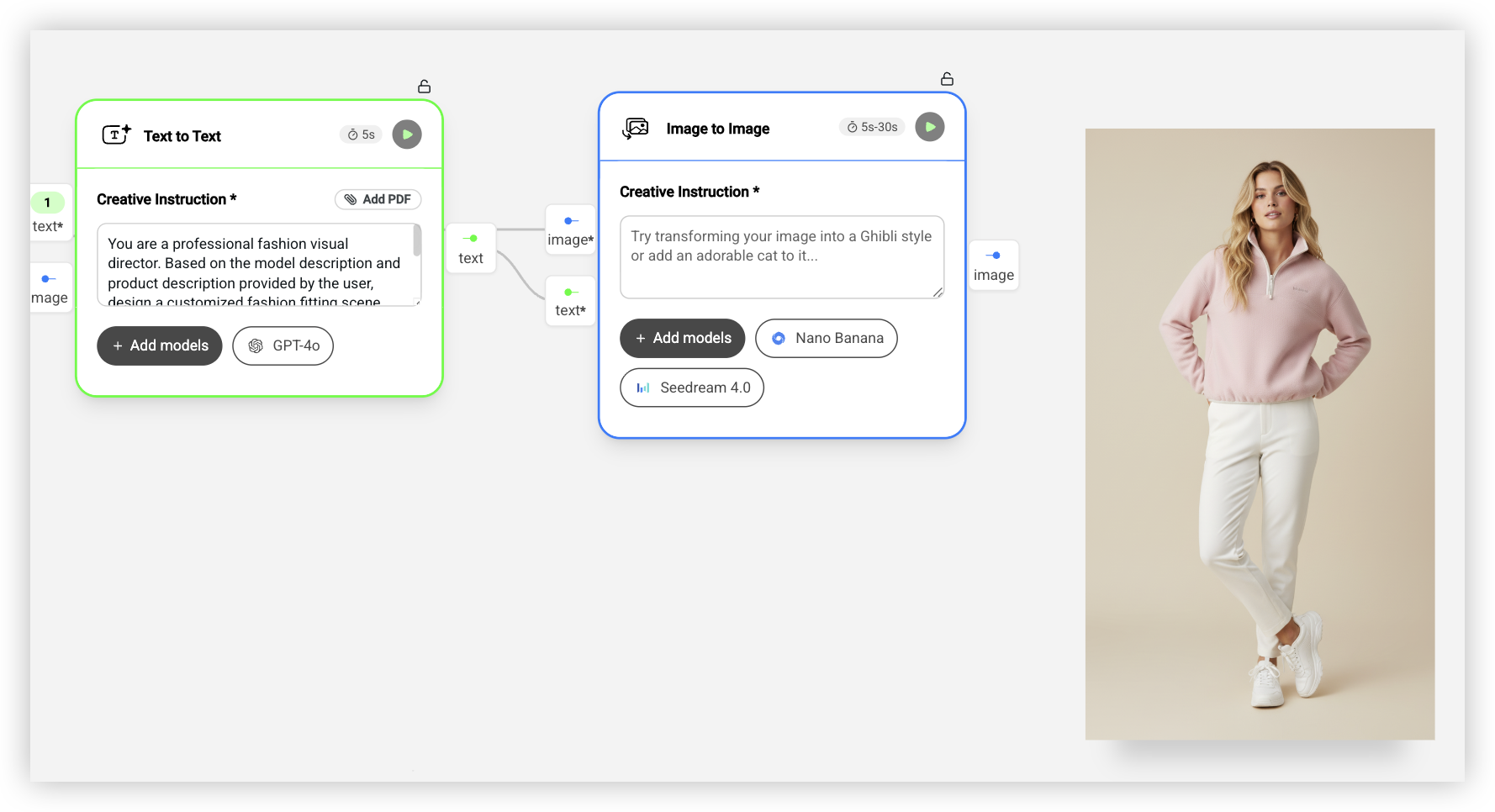
最后是另一个 Image to Image,接收白底产品图和场景描述,用 Nano Banana Pro 生成最终的模特上身图。这个模型的「思考模式」会先理解产品和场景的关系,然后再生成图片,效果比其他模型好很多。
为什么这样设计:这个工作流不是直接让 AI「把衣服穿到模特身上」,而是先让 AI 理解产品,再让 AI 设计场景,最后才生成图片。分步骤的方式比一步到位效果好很多,而且每一步都可以单独调试。
用 AI 生成Character Model Sheet(角色设定图)
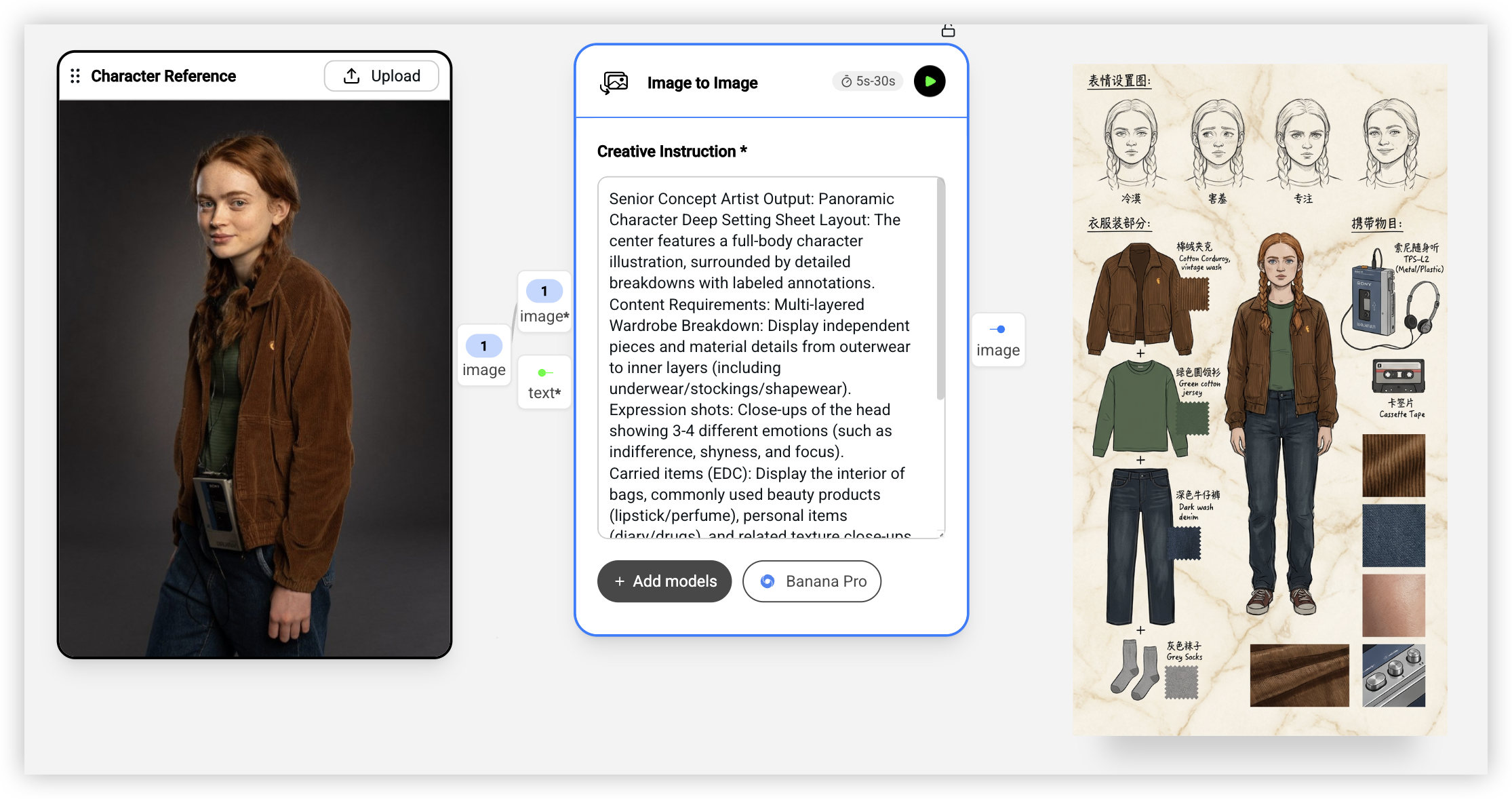
这个工作流特别适合做 IP 设计、游戏角色、漫画人物的设定图。
要解决的问题:你有一个角色的基础形象,想要生成一张完整的角色设定图(Character Model Sheet),包括全身图、表情变化、服装细节、随身物品等。
这个工作流只有 2 个核心节点:
输入是一张角色参考图,可以是你之前生成的角色图,也可以是手绘的草稿。
然后是一个 Image to Image 节点,用 Nano Banana Pro 模型,提示词是一段很详细的设定图要求:「高级概念艺术家输出:全景角色深度设定图。布局:中心是全身角色插画,周围是带标注的细节分解。内容要求:多层服装分解(从外套到内衬的独立展示和材质细节)、表情特写(3-4 种不同情绪)、随身物品(包内物品、常用美妆产品、个人物品)、材质特写(布料褶皱、皮肤纹理、小物件光泽)。风格:高质量 2D 概念草图设计,干净线条,米色/大理石纹纸背景,配中英文手写注释。」
输出就是一张完整的角色设定图,中心是角色全身像,周围是各种细节分解和标注。
这个工作流的巧妙之处在于,它把原本需要概念艺术家花几个小时甚至几天才能完成的工作,压缩到了几分钟。当然,AI 生成的设定图可能需要一些人工调整,但作为初稿或者快速迭代来说已经非常够用了。
不请 KOL 也能做 UGC Promo Video(UGC 推广视频)
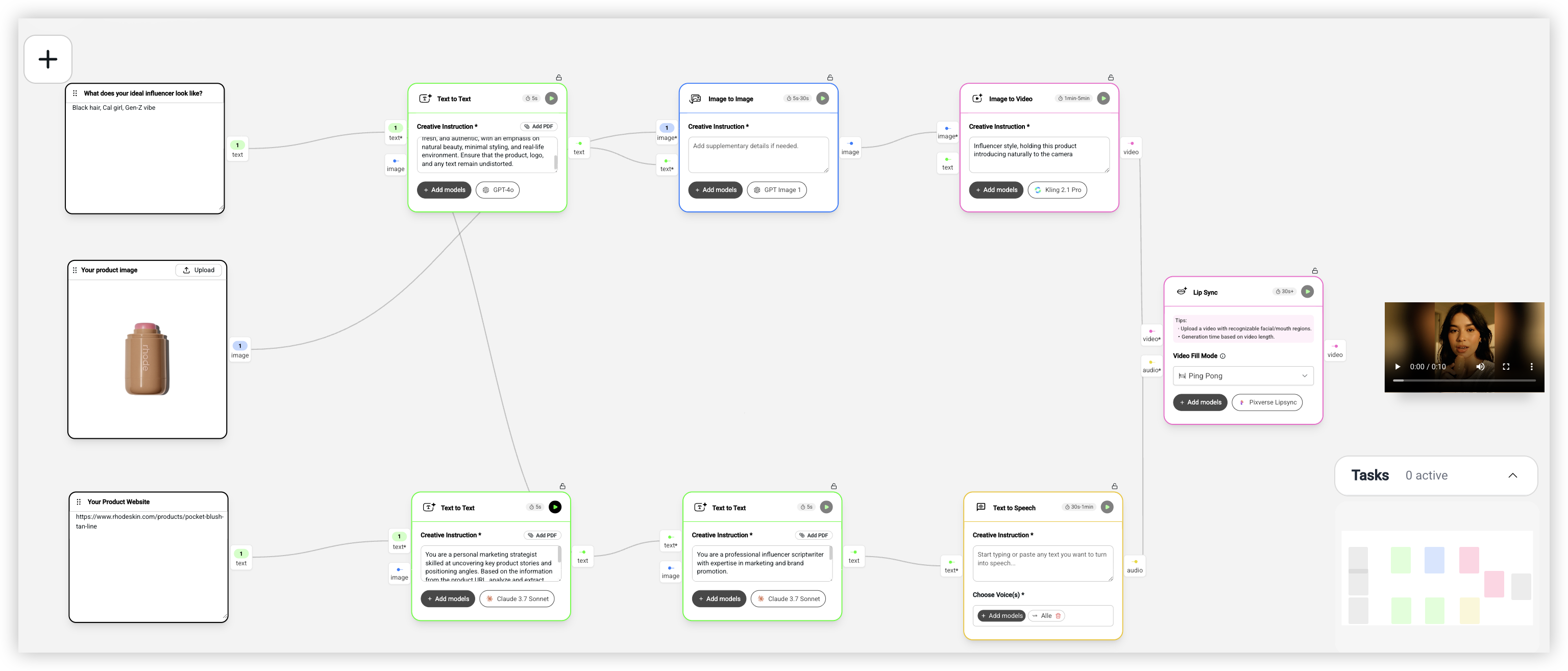
这个工作流解决的是一个很实际的问题:想要 UGC 风格的推广视频,但找不到合适的 KOL,或者成本太高。
这个工作流有 10 个节点,分成两条并行的链路:
第一条链路生成视觉内容。输入是你想要的网红形象描述(比如「Black hair, Cal girl, Gen-Z vibe」——黑发、加州女孩、Z 世代氛围的网红形象)和产品图。Text Generator 用 GPT-4o 把这些信息整合成一段完整的视觉描述,大意是「自拍视角的自然风网红,手持产品靠近脸部,柔和日光,温馨房间,黄金时段光晕,休闲亲密的 UGC(用户生成内容)美学」。然后 Image to Image 用 GPT Image 1 生成网红手持产品的图片。最后 Image to Video 用 Kling 2.1 Pro 让这张图动起来,提示词是「网红风格,自然地向镜头介绍这个产品」。
第二条链路生成音频内容。输入是产品网站链接。第一个 Text Generator 用 Claude 3.7 Sonnet 从网站提取品牌名和产品特点。第二个 Text Generator 把这些信息写成一段自然的 UGC 风格口播脚本,100-200 字。然后 Text to Speech 用 Fish Audio TTS 或 ElevenLabs v2 把脚本转成配音。
最后是 Lip Sync 节点,把视频和音频合在一起,让视频中的人物嘴型和配音同步。

输出就是一个完整的 UGC 风格推广视频:一个看起来很自然的网红,手持你的产品,用很自然的语气在介绍。
这个工作流的价值在于,它把原本需要找 KOL、谈合作、拍摄、剪辑的整个流程,压缩成了一个自动化的工作流。当然,AI 生成的「网红」和真人还是有差距的,但对于快速测试、小预算推广来说,已经是一个很好的选择了。
用 AI 生成偶像 MV 和音乐视频
这是我觉得最有意思的一类工作流。如果你是音乐人、独立艺术家,或者只是想玩玩创意视频,这两个工作流能让你在没有任何拍摄设备的情况下做出电影感的视频。
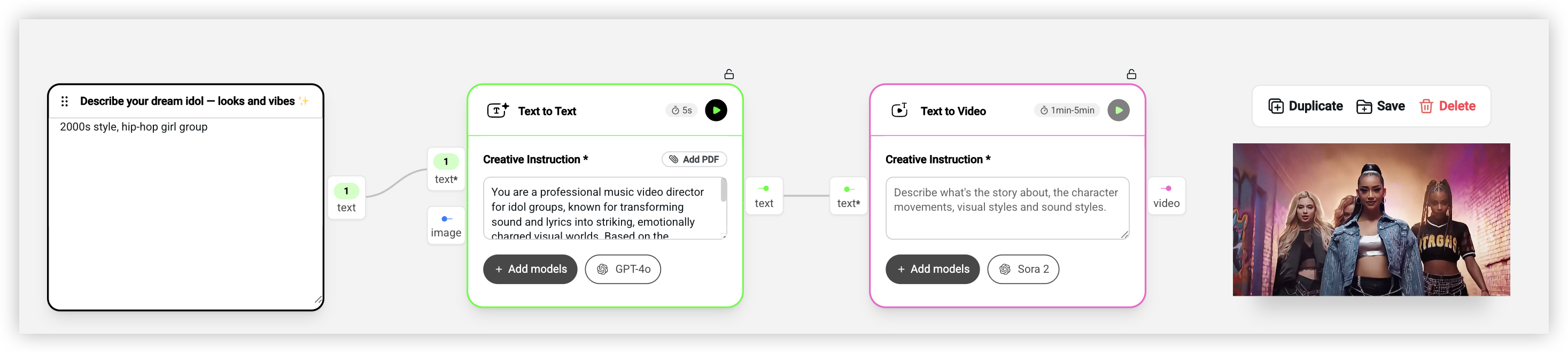
Sora 2 x Idols:一句话生成偶像 MV 片段
这个工作流只有 3 个节点,但效果很惊艳。输入是一句对偶像风格的描述,比如「2000s style, hip-hop girl group」或者「K-pop boy band, futuristic concept」(比如 2000 年代嘻哈女团,或者未来感十足的 K-pop 男团风格)。
Text Generator 用 GPT-4o 把这句话扩写成一段完整的 MV 预告描述。提示词很有意思,它让 AI 扮演一个「专业的偶像团 MV 导演」,要求描述偶像的外貌、化妆、发型、表情、团体互动、视觉风格、服装、编舞、场景设计、色彩和灯光。输出是一段 250 字以内的电影感叙述,读起来像是在看一个 15-20 秒的 MV 预告。
然后 Text to Video 用 Sora 2 把这段描述直接生成视频。Sora 2 在生成人物动作和表情方面是目前最好的,生成的偶像看起来真的像是在表演。
Lyrics to MV(歌词转 MV):歌词转完整 MV
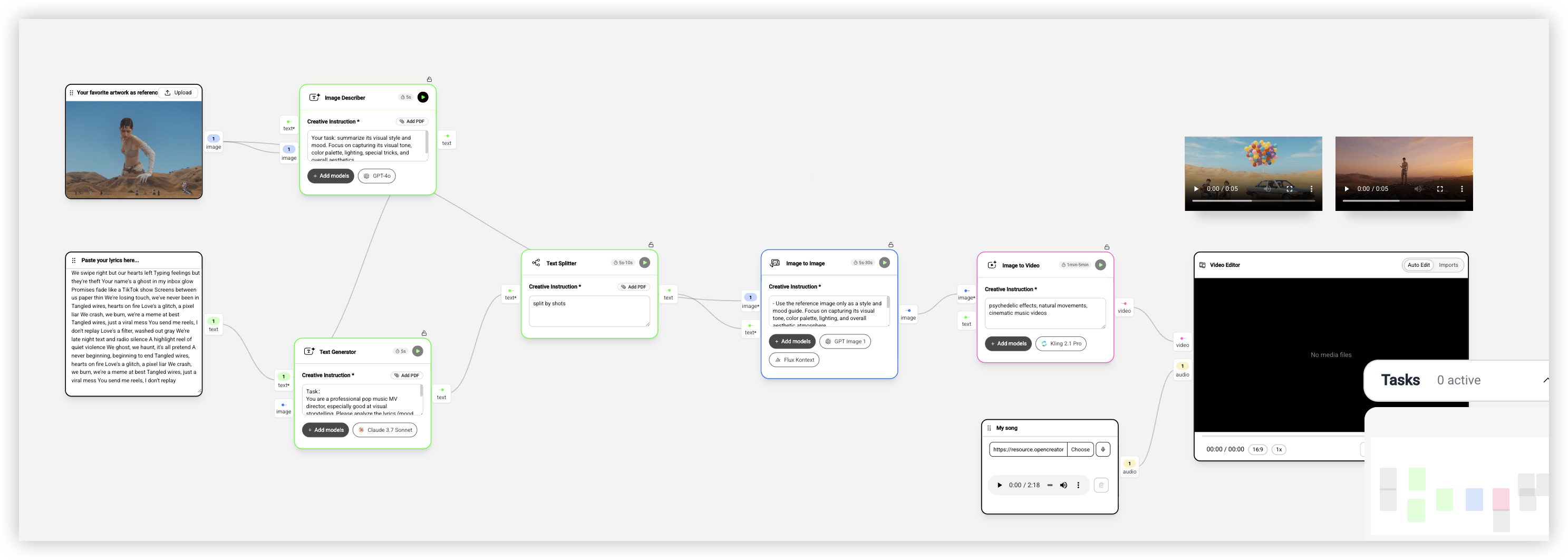
这个工作流更复杂一些,有 8 个节点,但能生成一整支完整的 MV。
输入有两个:一个是你的歌词,另一个是一张参考图(你喜欢的视觉风格)。还有一个音频输入,用来上传你的歌曲。
工作流分成两条链路。第一条处理视觉风格:Text Generator 用 GPT-4o 分析参考图的视觉风格、色彩、灯光、特殊技巧和整体美学。第二条处理内容:另一个 Text Generator 用 Claude 3.7 Sonnet 分析歌词的情绪、主题、表达,然后创作 15 个视觉关键镜头,每个镜头都是一段完整的场景描述,大约 2000 字。
Text Splitter 把这 15 个镜头拆分开。然后 Image to Image 用 GPT Image 1 或 Flux Kontext,结合参考图的风格和每个镜头的描述,生成 15 张分镜图。提示词强调「只用参考图作为风格和氛围指南,不要复制其中的具体元素」。
Image to Video 用 Kling 2.1 Pro 把每张分镜图变成 5 秒的视频片段,提示词是「psychedelic effects, natural movements, cinematic music videos」(大致意思是:迷幻特效、自然动作、电影感 MV)。
最后 Video Editor 把所有视频片段和音频组装在一起,加上标题文字,输出一支完整的 MV。
这个工作流的价值在于,它把传统 MV 制作的整个流程(分镜、拍摄、后期、剥辑)压缩成了一个自动化的工作流。当然,生成的 MV 和真实拍摄还是有差距的,但作为创意预览、概念验证或者独立音乐人的低成本方案,已经非常够用了。
还能用 AI 做什么
除了上面详细拆解的这几个,其实 AI 能做的事情比大多数人想象的要多得多。我把 OpenCreator 模板库里的工作流按场景分类整理了一下:
电商场景
除了前面讲的虚拟试穿,还有很多实用的工作流。**商品换背景可以把白底产品图放到任何场景里,比如咖啡馆、客厅、户外。商品重新打光可以调整产品图的光影效果,让产品看起来更有质感。图案提取可以从产品图中提取花纹、图案,用于设计延展。珠宝手模/耳模展示可以生成珠宝佩戴在手上或耳朵上的效果图。护肤品/化妆品电商图套装**可以一次性生成一套统一风格的产品图。
品牌广告
**时尚大片可以生成杂志风格的品牌形象图。一致性角色广告可以让同一个 AI 生成的角色出现在多个场景里,保持形象统一。品牌标志材质化可以把你的 Logo 变成各种材质效果,比如金属、木头、霜化玻璃。户外广告牌**可以把你的广告素材放到各种户外场景里预览效果。
社交媒体推广
除了 UGC 推广视频,还有 ASMR 推广(生成带音效的产品展示视频)、背景特效(给人物视频加上炫酷的背景效果)、商品花卉特效(产品周围绩放花瓣)、商品爆炸特效(产品爆炸分解的视觉效果)。这些都是在社交媒体上很吸睛的内容形式。
影视和音乐
除了 MV 生成,还有 分镜脚本生成器(输入故事梅概,自动生成分镜图)、剧本转影片(输入剧本,生成视频)、草图转影片(输入手绘分镜,生成视频)、专辑封面、电影海报。
创意玩法
还有一些纯粹好玩的工作流,比如 3D 人偶设计(把人物照片变成 3D 手办风格)、3D 角色渲染、动物奥运会(生成动物参加各种运动的视频)、POV 泄露片段(生成类似片场偷拍风格的视频)。
这些工作流在 OpenCreator 的模板库里都能找到,可以直接使用,也可以在它们的基础上修改。
一些实用的技巧

模型怎么选
我的经验是:探索阶段用便宜的快速模型,确认效果之后再换高质量模型。
比如做图片生成,我会先用 Nano Banana(51 Credits,约 $0.1)或 Gemini 2.0 Flash(12 Credits)快速跑几个版本,看看提示词对不对、方向对不对。确认没问题之后,再换 Nano Banana Pro(200 Credits,约 $0.4)生成最终版本。
视频生成也是类似的。先用 Kling 2.1 Pro(585 Credits,约 $1.2)测试,确认效果之后再用 Sora 2(960 Credits)或 Veo 3.1 生成最终版本。如果你是订阅用户,这些顶级模型还有 50%-70% 的折扣。
有些模型有特定的优势。Nano Banana Pro 在复杂指令理解和文字渲染方面最强,做需要精确控制的商业素材首选这个。Veo 3.1 可以同时生成视频和音频,需要带音效的视频就优先用这个。Ideogram 3.0 的文字渲染能力也不错,如果你需要在图片里加文字可以试试。
提示词怎么写
几个原则:具体比抽象好,「穿白色连衣裙的亚洲女性,站在海边,阳光明媚」比「一个好看的女人」效果好得多;描述你想要的,而不是你不想要的,AI 对否定词的理解不太好;可以参考摄影术语,比如 soft lighting、shallow depth of field、golden hour,这些 AI 理解得比较准确。
做视频的时候,要描述动作和变化。「镜头缓缓推进」「人物转身微笑」「水面泛起涟漪」这种动态描述,比静态描述效果好。
结果不满意怎么办
先判断问题在哪:是方向不对,还是质量不够。
方向不对就调整提示词,更具体地描述你想要的效果。质量不够就换更高质量的模型,或者调整生成参数。
还有一个办法是使用参考图。如果文字描述不清楚,提供一张参考图,让 AI 理解你想要的风格。
另外,多试几次是正常的。AI 生成有随机性,同样的提示词可能产生不同的结果。我的习惯是先快速生成 5-10 个版本,从里面选出最好的 2-3 个,再针对这几个做微调。
进阶技巧:让工作流更聪明
用了一段时间之后,我发现有一些技巧可以让工作流的效果更好,这些技巧在其他工作流工具(比如 ComfyUI、Dify)的社区里也经常被提到。

双路复用:同一张图既做描述又做参考
这是我觉得最实用的一个技巧。当你有一张参考图的时候,可以让它同时走两条路:一条路送给 Text Generator(文本生成)节点,让 AI 用文字描述这张图的风格、色彩、构图;另一条路直接连到后面的 Image to Image(图生图)节点作为视觉参考。
这样做的好处是:前面的文本生成节点在写提示词的时候,能「看到」原始图片的风格描述,写出来的提示词会更贴合你想要的效果;后面的图生图节点又能直接参考原始图片的视觉特征。两条路协同工作,比单独用文字描述或单独用图片参考效果都好。
举个例子:你想生成一系列统一风格的产品图。先上传一张你喜欢的风格参考图,让第一个 Text Generator 输出「柔和的自然光,浅米色背景,极简构图,产品居中,轻微的阴影」这样的描述。这段描述会被送到第二个 Text Generator,和你的产品描述一起生成完整的提示词。同时,原始参考图也会被送到 Image to Image 节点。最终生成的图片既符合文字描述的要求,又保持了参考图的视觉风格。
并行分支:同时尝试多个方向

工作流支持从一个节点分出多条并行的分支。比如你不确定用哪种风格,可以让同一个输入同时走「写实风格」和「插画风格」两条分支,一次运行就能看到两种效果的对比。
这个技巧在探索阶段特别有用。与其一个个试,不如一次性跑多个方向,然后从结果里挑选最好的。
迭代优化:用输出反哺输入

AI 生成的结果不一定一次就完美,但可以把它作为下一轮的输入继续优化。比如第一次生成的图片构图不错但细节不够,可以把这张图再送进工作流,用更具体的提示词要求 AI 优化细节。
这种「生成 → 评估 → 再生成」的循环,在专业的 AI 工作流里很常见。每一轮迭代都能让结果更接近你想要的效果。
拆解复杂任务:分步骤比一步到位效果好

如果你想生成一个很复杂的画面,比如「一个穿着红色连衣裙的女孩站在樱花树下,手里拿着一本书,背景是日落的天空」,直接用一个提示词生成可能效果不好。更好的做法是拆解成多个步骤:先生成人物,再生成背景,最后合成在一起。
这也是为什么前面介绍的那些工作流都有好几个节点,而不是一个节点搞定所有事情。分步骤的方式让每一步都可以单独调试,最终效果更可控。
成本大概是多少

OpenCreator 用 Credits 计费,1 Credit 大约等于 $0.002(约 ¥0.014)。不同模型消耗差异很大,从文本生成的 1-18 Credits 到视频生成的 960-4800 Credits 都有。
先说几个常用模型的价格:Nano Banana Pro 图生图 200 Credits(约 $0.4/¥2.8),Sora 2 视频生成 960 Credits(约 $1.9/¥14),Veo 3.1 Fast 1440 Credits(约 $2.9/¥21),Kling 2.1 Pro 585 Credits(约 $1.2/¥8.4)。
以虚拟试穿工作流为例,用 Nano Banana Pro 跑一次大概需要 250-300 Credits(约 $0.5-0.6)。如果你有 100 个 SKU,全部跑一遍大约需要 25,000-30,000 Credits,换算成美金大概 $50-60。对比请模特拍摄动辄上万的成本,这个价格基本可以忽略不计。
OpenCreator 有三档订阅:Starter $19/月(7,000 Credits)、Creator $49/月(24,000 Credits)、Pro $199/月(100,000 Credits)。订阅用户在使用顶级模型时有折扣:Creator 用户用 Sora 2、Veo 3.1 打 5 折,用 Nano Banana Pro 打 7 折;Pro 用户用 Sora 2、Veo 3.1 打 3 折,用 Nano Banana Pro 打 5 折。
算一笔账:如果你是 Pro 用户,用 Sora 2 生成视频只需要 288 Credits(960 × 0.3),100,000 Credits 可以生成 347 条视频,平均每条不到 $0.6。这个成本对于商业内容生产来说已经非常低了。
年付还能再省一笔。Creator 年付 $294(相当于 $24.5/月),Pro 年付 $1,194(相当于 $99.5/月),基本是月付价格的一半。
这个工具适合谁用

说实话,工作流工具不是所有人都需要的。如果你只是偶尔用 AI 生成一两张图,用豆包或者 ge就够了,没必要学一个新工具。但如果你有以下这些需求,工作流工具能帮你省很多时间:
电商运营:需要批量生成产品图、模特图、场景图。手上有几十上百个 SKU,一个个做太慢,工作流可以让你一次设置、批量生产。
品牌营销:需要快速产出短视频、广告素材。从创意到成品的周期要求很短,工作流可以把多个步骤串起来,减少中间的等待和搬运。
内容创作者:需要保持稳定的内容产出节奏。工作流可以把你的创作流程标准化,每次只需要换输入素材,其他步骤自动完成。
设计师和创意人员:需要快速验证创意想法。工作流可以让你在几分钟内看到一个想法的视觉效果,而不是花几个小时手动制作。
怎么开始

OpenCreator 可以直接在浏览器里用,不需要安装任何东西。注册账号之后会有一些免费的 Credits 可以试用,足够你跑几个模板感受一下。
我建议的上手路径是这样的:
第一步,先跑几个 Tutorials 教程模板。这些模板都很简单,每个只有 2-3 个节点,但能让你快速理解各个能力怎么用。Text to Image、Image to Video、Lip Sync 这几个先跑一遍,大概 15 分钟就能对基础能力有个直观认识。
第二步,找一个和你需求相关的工作流模板。比如你是做服装电商的,就试试虚拟试穿;你是做品牌营销的,就试试 UGC 推广视频。先用模板跑通,再根据自己的需求调整。
第三步,尝试自己搭建一个简单的工作流。从两三个节点开始,比如「文本输入 → 图片生成 → 图片超分」这样的简单链路。搭建的过程中你会对节点之间的连接方式有更深的理解。
不要一上来就想搭建很复杂的工作流。先从简单的开始,逐步增加复杂度。
写在最后
回顾一下这篇文章的核心观点。
工作流思维比单点工具更重要。AI 工具会不断更新换代,但「把能力串联起来」的思维方式是通用的。今天你用 OpenCreator,明天可能用其他工具,但工作流的设计思路是一样的。
不要追求一次完美。AI 生成有随机性,多试几次是正常的。工作流的设计也是迭代的,先跑通再优化。
最好的学习方式还是动手做。打开 OpenCreator,从一个模板开始吧。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)