如何确保生成式AI的质量与可靠性
《AIGC时代软件测试工程师实践指南》探讨了生成式AI为测试领域带来的全新挑战。文章提出构建多层次质量评估体系,覆盖功能、性能、安全维度,创新性地引入基于Spec的验证和众包评估方法。同时强调全生命周期质量管控,从开发阶段的数据审计到运营持续监控。测试工程师需转型掌握提示词工程、伦理风险评估等新技能,从"质量守门员"升级为"价值共创者"。文章指出,建立标准化
——面向软件测试工程师的实践指南
引言:AIGC测试的时代挑战
随着ChatGPT、Midjourney等生成式AI模型加速渗透各行各业,其输出结果的不可预测性正成为企业落地的最大风险点。与传统软件测试不同,AIGC测试需要应对非确定性输出、伦理边界模糊、动态演化风险三重挑战。2025年的今天,测试工程师需要建立全新的质量观,从代码正确性验证转向认知合理性评估。
一、构建多层次质量评估体系
1.1 基础功能维度
-
内容准确性测试:通过知识库比对、事实核查API验证生成内容的客观正确性
-
指令遵循度评估:构建提示词-预期响应配对数据集,量化模型执行复杂指令的能力
-
格式合规检查:自动化验证JSON/XML等结构化输出的语法规范性与完整性
1.2 性能与安全维度
-
抗提示注入测试:设计对抗性提示词探测模型安全机制漏洞
-
输出稳定性监控:相同输入多次执行的方差分析,识别模型不确定性风险
-
资源消耗基准:建立token消耗、响应延迟、并发吞吐等性能基线
二、创新测试方法论实践
2.1 基于Spec的预期验证
# 示例:电商摘要生成测试用例 def test_product_summary_generation(): input_prompt = "概括iPhone 16 Pro的三大核心卖点" output = ai_model.generate(input_prompt) assert contains_technical_spec(output) # 包含技术参数 assert comparison_free(output) # 无竞品对比 assert length_between(output, 50, 200) # 长度控制
2.2 众包评估与专家评审结合
-
建立覆盖语言学、伦理学、领域专家的标注团队
-
设计五级质量评分卡(1-5分制):事实准确度、语言流畅度、逻辑连贯性、安全性、实用性
-
采用Krippendorff's Alpha系数确保评分者间信度 > 0.8
三、全生命周期质量管控
3.1 开发阶段质量控制
-
数据质量审计:训练数据偏见检测、版权合规筛查、数据代表性评估
-
模型验证基准:在MMLU、HELM等标准基准测试外,构建领域专属评估集
-
红队测试:组建专项团队模拟恶意攻击场景,提前暴露模型脆弱性
3.2 运营阶段持续监控
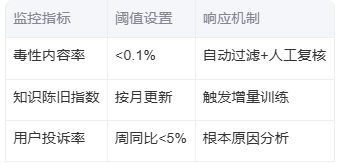
四、测试工程师的能力转型
-
提示词工程专业化:掌握链式思考、少样本学习等高级技巧
-
评估指标体系设计:平衡自动化指标与人工评估的资源配置
-
伦理风险评估能力:识别歧视性输出、隐私泄露等潜在风险
-
跨领域知识积累:拓展心理学、语言学等认知科学知识
结语
生成式AI的质量保障不是简单的缺陷排查,而是构建可预测、可信赖、可持续的智能系统。测试团队需要从传统的“质量守门员”转型为“价值共创者”,通过建立标准化的评估框架、自动化的监控体系、专业化的测试方法,确保AIGC技术在实际业务场景中的可靠落地。随着AI监管法规逐步完善,提前布局质量保障体系的企业将在合规性与用户体验方面获得显著竞争优势。、
精选文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献117条内容
已为社区贡献117条内容

所有评论(0)