【每天一个AI小知识】:什么是自然语言处理?
摘要:自然语言处理(NLP)是人工智能的重要分支,使计算机能理解、生成人类语言并进行自然交互。文章系统介绍了NLP的发展历程(从规则方法到深度学习)、核心技术(词向量、Transformer架构等)、主要算法(Word2Vec、BERT、GPT等)及典型应用(智能助手、机器翻译等)。同时探讨了NLP面临的歧义性、数据稀疏性等挑战,并提出了相应解决方案。文章还包含NLP的代码实现示例和评估指标,最后

目录
8.3 使用Hugging Face Transformers实现预训练语言模型
一、小明的智能助手:从故事说起
小明最近买了一部新手机,手机上的智能助手让他惊叹不已。
"你好,帮我定一张明天去上海的高铁票。"小明对手机说。
手机立刻回应:"好的,小明。我为您查询到明天从北京到上海的高铁票,最早一班是6:30,最晚一班是22:00。您想要哪个时间段的?"
小明继续说:"给我定下午3点左右,二等座,靠窗的位置。"
手机很快回复:"已为您预订明天15:08的G103次列车,二等座,12车18A号靠窗座位。需要我帮您支付吗?"
整个过程没有按键操作,完全通过自然语言交流就完成了购票。小明不禁感叹:"现在的AI真厉害,居然能听懂我说的话,还能帮我办事!"
这个智能助手使用的核心技术就是自然语言处理(Natural Language Processing,简称NLP)。从智能客服到机器翻译,从语音助手到智能写作,自然语言处理已经渗透到我们生活的方方面面。那么,这项让计算机"听懂"人类语言的技术到底是如何工作的呢?
二、自然语言处理的基本概念
2.1 什么是自然语言处理?
自然语言处理是人工智能的一个重要分支,它研究如何让计算机理解和生成人类的自然语言(如中文、英文、日文等)。简单来说,自然语言处理的目标是:
- 让计算机理解人类的语言:能够读懂文本、听懂语音,理解其含义
- 让计算机生成人类的语言:能够写出通顺的文本、说出自然的语音
- 让计算机与人类进行自然的语言交互:能够像人类一样进行对话和交流
自然语言处理涉及计算机科学、语言学、数学等多个学科领域,是人工智能中最具挑战性的任务之一。
2.2 自然语言处理的核心任务
自然语言处理包含众多子任务,这些任务可以分为基础任务和应用任务两类:
2.2.1 基础任务
- 分词(Tokenization):将连续的文本分割成有意义的单词或词语(如中文分词:"我爱自然语言处理" → "我/爱/自然语言处理")
- 词性标注(Part-of-Speech Tagging):为每个单词标注其词性(如名词、动词、形容词等)
- 命名实体识别(Named Entity Recognition):识别文本中的命名实体(如人名、地名、组织机构名等)
- 句法分析(Parsing):分析句子的语法结构(如主谓宾关系)
- 语义分析(Semantic Analysis):理解文本的语义内容(如句子的含义、情感倾向等)
2.2.2 应用任务
- 文本分类(Text Classification):将文本分类到预定义的类别(如垃圾邮件检测、新闻分类等)
- 情感分析(Sentiment Analysis):分析文本的情感倾向(如正面、负面、中性)
- 机器翻译(Machine Translation):将一种语言的文本翻译成另一种语言(如谷歌翻译)
- 问答系统(Question Answering):回答用户提出的问题(如百度知道、Siri)
- 对话系统(Dialogue System):与用户进行自然语言对话(如智能客服、语音助手)
- 文本生成(Text Generation):自动生成文本内容(如智能写作、诗歌生成)
- 信息检索(Information Retrieval):根据用户的查询需求,从大量文本中检索相关信息(如搜索引擎)
2.3 自然语言处理与相关技术的关系
自然语言处理与其他人工智能技术密切相关:
| 技术名称 | 核心功能 | 与NLP的关系 |
|---|---|---|
| 语音识别 | 将语音转换为文本 | NLP的输入之一(语音NLP) |
| 语音合成 | 将文本转换为语音 | NLP的输出之一 |
| 知识图谱 | 结构化的知识表示 | 为NLP提供知识支持 |
| 机器学习 | 从数据中学习模式 | NLP的核心技术手段 |
| 深度学习 | 模拟人脑的神经网络 | 推动NLP技术的重大突破 |
| 计算机视觉 | 理解图像和视频 | 与NLP结合实现多模态处理 |
三、自然语言处理的发展历史
自然语言处理的发展可以追溯到20世纪50年代,至今已有70多年的历史。它的发展大致可以分为以下几个阶段:
3.1 萌芽期(1950s-1960s):逻辑推理时代
这一阶段的自然语言处理主要依赖人工编写的规则和逻辑推理:
- 1950年:图灵提出著名的"图灵测试",用于判断机器是否具有智能
- 1954年:IBM实现了世界上第一个机器翻译系统,将俄文翻译成英文
- 1956年:人工智能概念在达特茅斯会议上正式提出,自然语言处理成为人工智能的重要研究方向
- 1960年:乔姆斯基提出转换生成语法,为自然语言处理提供了语言学理论基础
3.2 发展期(1970s-1980s):基于规则的方法
这一阶段的自然语言处理主要采用基于规则的方法:
- 语言学家和计算机科学家合作,手工编写大量的语法规则和语义规则
- 开发了一批基于规则的自然语言处理系统,如SHRDLU(一个可以理解自然语言指令的机器人系统)
- 由于规则的复杂性和语言的多样性,基于规则的方法很快遇到了瓶颈
3.3 过渡期(1990s):统计方法的兴起
随着计算机性能的提升和语料库的建立,统计方法开始应用于自然语言处理:
- 1993年:IBM提出基于统计的机器翻译模型(IBM Model 1-5),开创了统计机器翻译的先河
- 1995年:隐马尔可夫模型(HMM)被广泛应用于词性标注、命名实体识别等任务
- 1997年:SVM(支持向量机)等机器学习算法开始应用于文本分类任务
3.4 繁荣期(2000s):机器学习时代
机器学习技术的快速发展推动了自然语言处理的繁荣:
- 2001年:神经语言模型(Neural Language Model)提出,开始将神经网络应用于自然语言处理
- 2003年:条件随机场(CRF)被广泛应用于序列标注任务
- 2006年:深度学习概念提出,为自然语言处理的突破性发展奠定了基础
- 2009年:Google推出基于统计的神经机器翻译系统,大幅提高了翻译质量
3.5 爆发期(2010s至今):深度学习时代
深度学习技术的应用带来了自然语言处理的爆发式发展:
- 2013年:Word2Vec提出,通过神经网络将单词表示为低维向量,解决了传统词袋模型的局限性
- 2014年:Seq2Seq模型提出,为机器翻译、文本生成等任务提供了统一的框架
- 2017年:Google提出Transformer模型,彻底改变了自然语言处理的技术路线
- 2018年:BERT(Bidirectional Encoder Representations from Transformers)提出,在11个NLP任务上取得了突破性的性能
- 2020年:GPT-3提出,拥有1750亿参数,能够生成高质量的文本内容
- 2022年至今:ChatGPT、GPT-4等大语言模型的出现,标志着自然语言处理进入了大模型时代
四、自然语言处理的核心技术原理
4.1 词的表示:从离散到连续
在自然语言处理中,首先需要将文本转换为计算机可以处理的数值形式。词的表示方法经历了从离散表示到连续表示的发展:
4.1.1 离散表示
- 词袋模型(Bag of Words):将文本表示为单词的集合,不考虑单词的顺序
- TF-IDF(Term Frequency-Inverse Document Frequency):根据单词在文档中的频率和在语料库中的逆文档频率来计算单词的权重
- one-hot编码:将每个单词表示为一个只有一个元素为1,其余元素为0的向量
离散表示的缺点是无法捕捉单词之间的语义关系,且容易出现维度灾难。
4.1.2 连续表示
- Word2Vec:通过神经网络将单词表示为低维向量,语义相似的单词在向量空间中距离较近
- GloVe:结合了全局统计信息和局部上下文信息的词向量表示方法
- FastText:将单词表示为字符n-gram的向量之和,能够处理未登录词
- ELMo:基于双向LSTM的上下文相关的词向量表示方法
- BERT:基于Transformer的深度双向语言模型,能够生成上下文相关的词向量
4.2 序列建模:处理文本的顺序性
文本是一种序列数据,具有顺序性。序列建模是自然语言处理的核心技术之一:
4.2.1 RNN与LSTM
- 循环神经网络(RNN):能够处理序列数据,通过隐藏状态保存上下文信息
- 长短期记忆网络(LSTM):解决了RNN的长期依赖问题,能够更好地捕捉长距离的上下文信息
- 门控循环单元(GRU):LSTM的简化版本,参数更少,训练速度更快
4.2.2 Transformer
Transformer是2017年Google提出的一种基于自注意力机制的神经网络模型,它彻底改变了自然语言处理的技术路线:
核心组件:
- 自注意力机制(Self-Attention):能够捕捉序列中任意两个位置之间的依赖关系
- 多头注意力(Multi-Head Attention):通过多个注意力头捕捉不同维度的语义信息
- 位置编码(Positional Encoding):为序列添加位置信息,解决Transformer无法处理顺序信息的问题
- 前馈神经网络(Feed-Forward Network):对每个位置的表示进行非线性变换
- 残差连接(Residual Connection):缓解梯度消失问题,加速模型训练
- 层归一化(Layer Normalization):稳定模型训练,加速收敛
Transformer的优势在于能够并行处理序列数据,且能够捕捉长距离的上下文信息,成为当前自然语言处理的主流模型架构。
4.3 预训练语言模型:大模型时代
预训练语言模型是当前自然语言处理领域的核心技术,它通过在大规模语料库上进行预训练,然后在下游任务上进行微调,取得了突破性的性能:
主要类型:
- 编码器模型:如BERT、RoBERTa、ALBERT等,擅长理解类任务(如文本分类、命名实体识别等)
- 解码器模型:如GPT、GPT-2、GPT-3等,擅长生成类任务(如文本生成、对话等)
- 编码器-解码器模型:如T5、BART等,同时擅长理解和生成类任务(如机器翻译、文本摘要等)
预训练目标:
- 掩码语言模型(MLM):随机掩盖文本中的部分单词,然后让模型预测被掩盖的单词(如BERT)
- 自回归语言模型(Auto-Regressive LM):让模型根据前面的单词预测下一个单词(如GPT)
- 去噪自编码器(Denoising Autoencoder):对输入文本进行随机扰动,然后让模型恢复原始文本(如BART)
五、自然语言处理的主要算法
5.1 Word2Vec:词向量的经典之作
Word2Vec是Google在2013年提出的一种词向量表示方法,它通过神经网络将单词映射到低维向量空间。
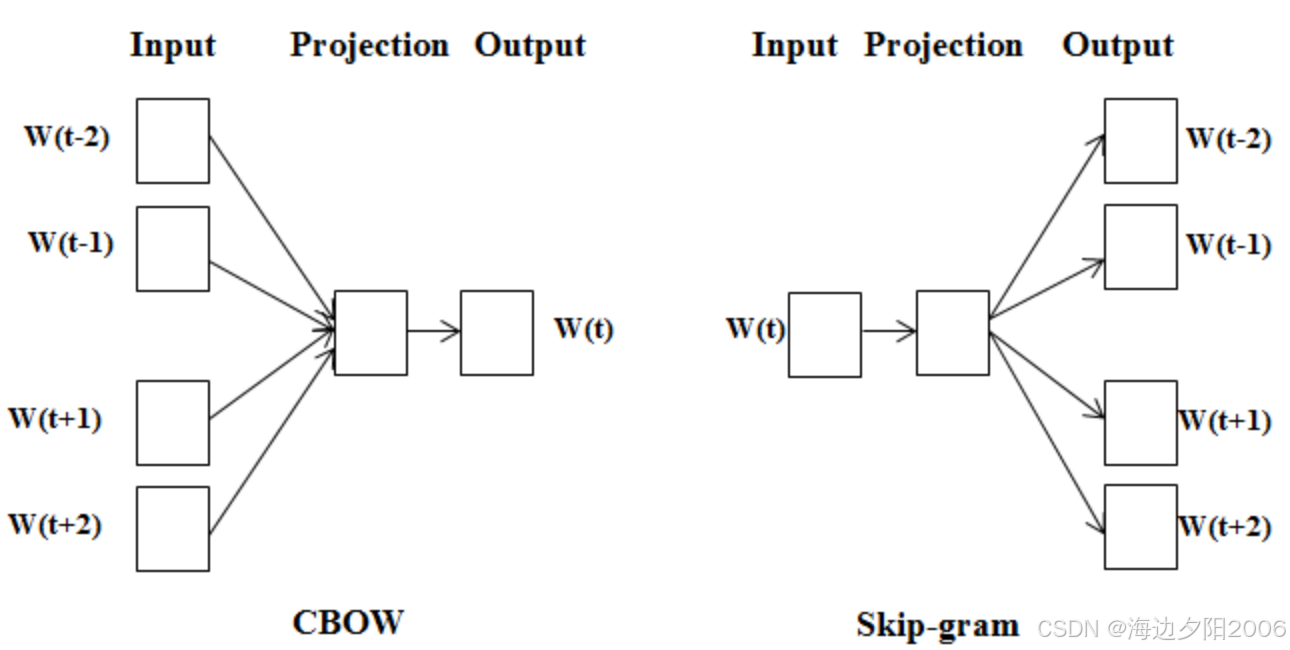
技术特点:
- 采用两种模型结构:CBOW(Continuous Bag-of-Words)和Skip-gram
- CBOW模型:根据上下文预测中心词
- Skip-gram模型:根据中心词预测上下文
- 能够捕捉单词之间的语义关系(如king - man + woman = queen)
应用场景:文本分类、情感分析、信息检索等
5.2 BERT:双向语言模型的革命
BERT是Google在2018年提出的一种基于Transformer的深度双向语言模型。
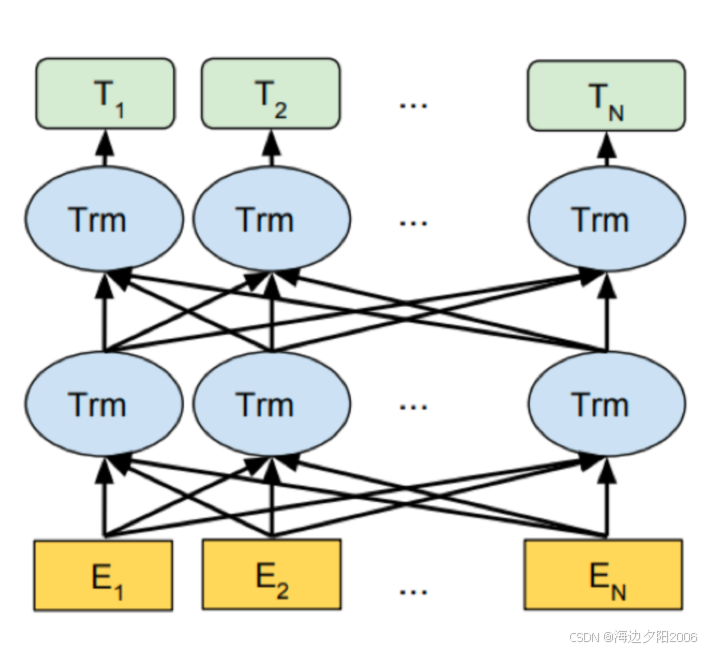
技术特点:
- 采用掩码语言模型(MLM)作为预训练目标
- 能够同时利用左右上下文信息,生成更准确的词向量表示
- 在11个NLP任务上取得了突破性的性能
- 有多种变体,如BERT-base(110M参数)和BERT-large(340M参数)
应用场景:问答系统、命名实体识别、文本分类等
5.3 GPT:生成式预训练Transformer
GPT是OpenAI在2018年提出的一种基于Transformer的生成式预训练语言模型。
技术特点:
- 采用自回归语言模型作为预训练目标
- 能够生成连贯、自然的文本内容
- 模型规模不断扩大:GPT-1(117M参数)→ GPT-2(1.5B参数)→ GPT-3(175B参数)→ GPT-4(参数规模未公开)
- 支持零样本学习和少样本学习
应用场景:文本生成、对话系统、创意写作等
5.4 Transformer:自然语言处理的新范式
Transformer是Google在2017年提出的一种基于自注意力机制的神经网络模型。
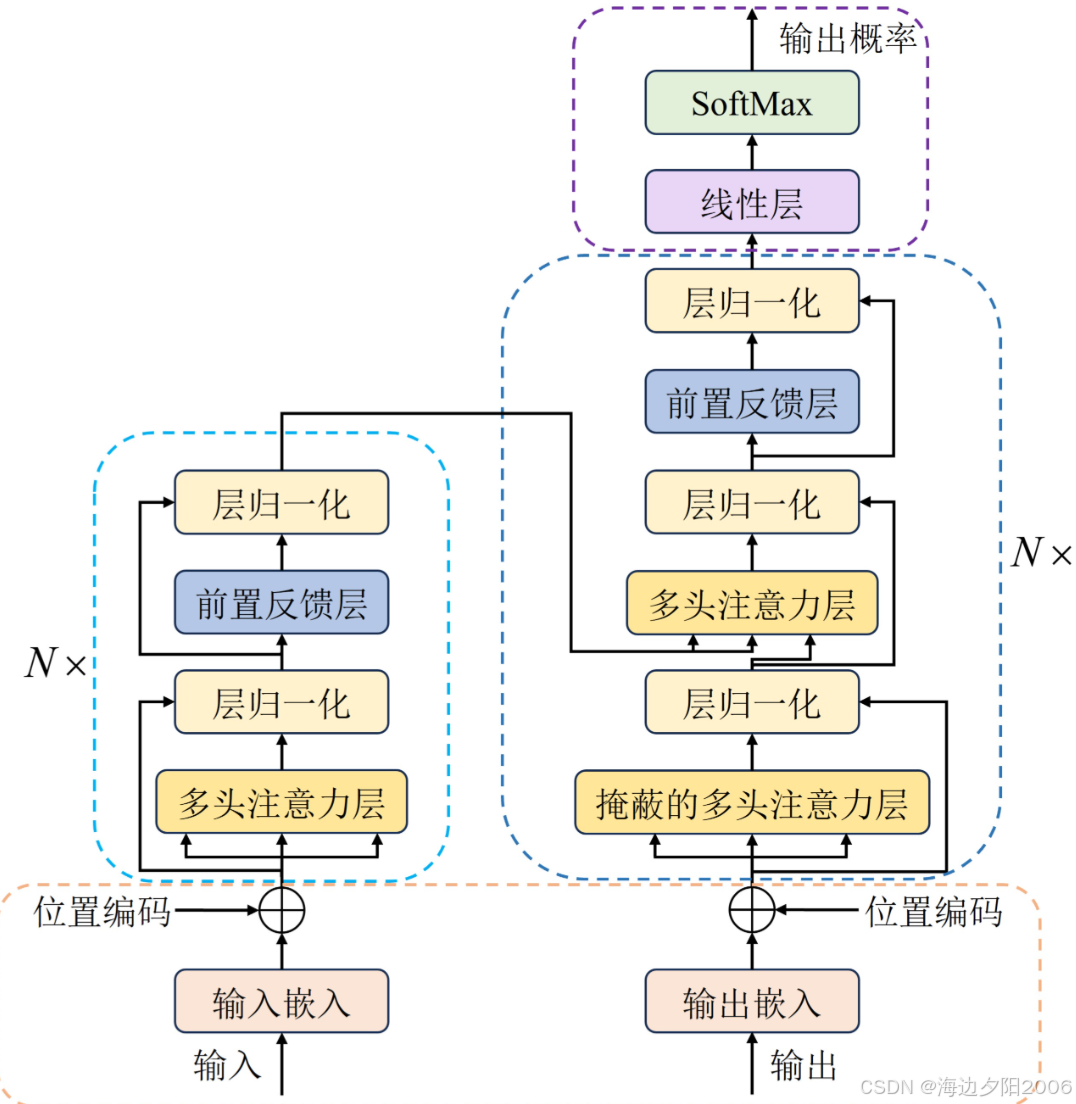
技术特点:
- 完全基于自注意力机制,不使用RNN或CNN
- 能够并行处理序列数据,训练速度更快
- 能够捕捉长距离的上下文信息
- 成为当前自然语言处理的主流模型架构
应用场景:机器翻译、文本摘要、问答系统等
5.5 T5:统一的文本到文本框架
T5是Google在2020年提出的一种统一的文本到文本框架,它将所有NLP任务都转换为文本生成任务。
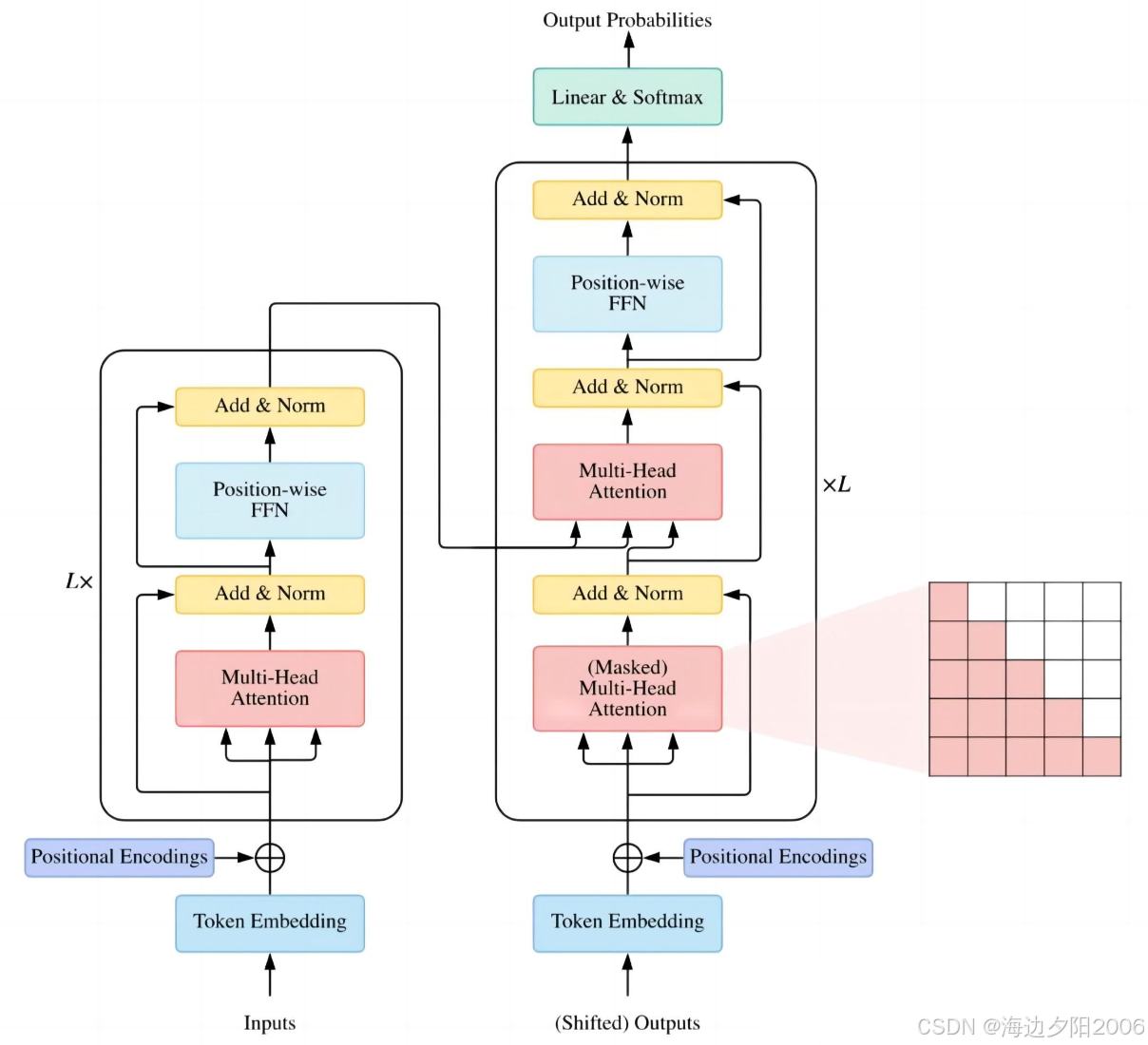
技术特点:
- 采用"Text-to-Text"的统一框架,将所有NLP任务都转换为文本生成任务
- 预训练目标是去噪自编码器,对输入文本进行随机扰动,然后让模型恢复原始文本
- 在多种NLP任务上取得了优异的性能
应用场景:机器翻译、文本摘要、问答系统、文本分类等
六、自然语言处理的工作流程
我们了解一下自然语言处理的一般工作流程,如下所示:
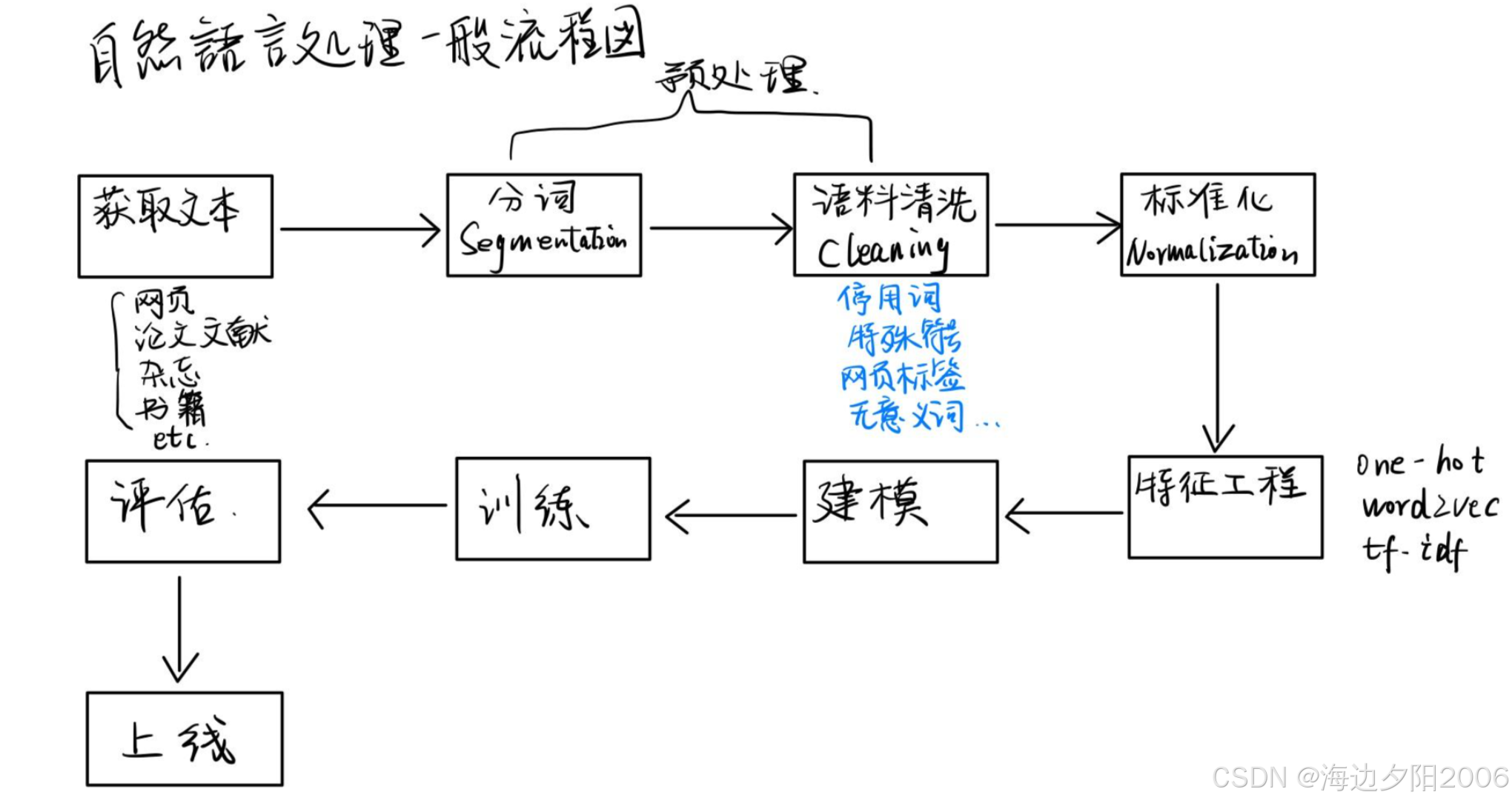
让我们以智能客服为例,详细了解自然语言处理的完整工作流程:
- 用户输入:用户通过文本或语音输入问题(如"我的订单什么时候发货?")
- 语音识别(可选):如果用户通过语音输入,将语音转换为文本
- 文本预处理:对输入文本进行清洗、分词等预处理操作
- 意图识别:识别用户的意图(如查询订单状态)
- 实体识别:识别文本中的关键信息(如订单号、商品名称等)
- 查询处理:根据用户意图和实体信息,查询相关数据(如从数据库中查询订单状态)
- 回复生成:根据查询结果生成自然语言回复(如"您的订单#123456预计明天发货")
- 语音合成(可选):如果需要语音回复,将文本转换为语音
- 结果输出:将回复发送给用户
七、自然语言处理的应用场景
自然语言处理技术已经广泛应用于各个领域,让我们看看它的主要应用场景:
7.1 智能助手
- 语音助手:如Siri、Google Assistant、小爱同学等,能够通过语音与用户交互
- 聊天机器人:如ChatGPT、豆包、文心一言等,能够进行自然语言对话
- 智能客服:替代人工客服,处理用户的常见问题
7.2 内容创作
- 智能写作:自动生成新闻、报告、广告文案等
- 诗歌生成:自动生成诗歌、散文等文学作品
- 代码生成:根据自然语言描述自动生成代码(如GitHub Copilot)
7.3 信息检索
- 搜索引擎:如Google、百度等,根据用户的查询需求检索相关信息
- 推荐系统:根据用户的兴趣和行为推荐相关内容
- 信息抽取:从大量文本中抽取结构化的信息(如从新闻中抽取事件、人物、时间等)
7.4 机器翻译
- 在线翻译:如谷歌翻译、百度翻译等,支持多种语言之间的互译
- 实时翻译:如同声传译设备,支持会议、演讲等场景的实时翻译
- 本地化:将软件、游戏等内容翻译成不同语言
7.5 金融领域
- 情感分析:分析市场新闻、社交媒体等文本的情感倾向,预测市场走势
- 风险评估:分析用户的信用报告、社交媒体等信息,评估信用风险
- 智能投顾:根据用户的风险偏好和财务状况,提供个性化的投资建议
7.6 医疗领域
- 医疗文本分析:分析电子病历、医学文献等文本,辅助医生诊断
- 药物研发:分析大量的医学文献和实验数据,加速药物研发过程
- 健康问答:回答用户的健康问题,提供健康咨询服务
7.7 法律领域
- 法律文本分析:分析法律法规、法院判决等文本,辅助律师办案
- 合同审查:自动审查合同中的风险条款,提高审查效率
- 法律问答:回答用户的法律问题,提供法律咨询服务
7.8 教育领域
- 智能辅导:根据学生的学习情况,提供个性化的学习辅导
- 自动评分:自动批改学生的作业、作文等
- 知识问答:回答学生的学习问题,辅助学习
八、自然语言处理的代码实现
8.1 使用NLTK实现基础NLP任务
NLTK是Python中最常用的自然语言处理库之一,它提供了丰富的NLP工具和语料库。
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 下载必要的资源
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
# 示例文本
text = "Natural Language Processing is a fascinating field of artificial intelligence. It helps computers understand and generate human language."
# 分句
sentences = sent_tokenize(text)
print("分句结果:", sentences)
# 分词
words = word_tokenize(text)
print("分词结果:", words)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_words = [word for word in words if word.lower() not in stop_words]
print("去除停用词后:", filtered_words)
# 词形还原
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word) for word in filtered_words]
print("词形还原后:", lemmatized_words)
8.2 使用spaCy实现高级NLP任务
spaCy是一个工业级的自然语言处理库,它提供了高效的NLP工具和预训练模型。
import spacy
# 加载预训练模型
nlp = spacy.load('en_core_web_sm')
# 示例文本
text = "Apple Inc. was founded by Steve Jobs in Cupertino, California in 1976. It is now one of the largest technology companies in the world."
# 处理文本
doc = nlp(text)
# 命名实体识别
print("命名实体识别结果:")
for ent in doc.ents:
print(f"实体:{ent.text},类型:{ent.label_}")
# 词性标注
print("\n词性标注结果:")
for token in doc:
print(f"单词:{token.text},词性:{token.pos_},依存关系:{token.dep_}")
# 句法分析
print("\n句法分析结果:")
for token in doc:
if token.dep_ == 'ROOT':
print(f"核心动词:{token.text}")
for child in token.children:
print(f" - {child.dep_}:{child.text}")
8.3 使用Hugging Face Transformers实现预训练语言模型
Hugging Face Transformers是一个流行的NLP库,它提供了大量预训练语言模型的实现。
from transformers import pipeline
# 文本分类
classifier = pipeline("text-classification", model="distilbert-base-uncased-finetuned-sst-2-english")
result = classifier("I love natural language processing!")
print("文本分类结果:", result)
# 命名实体识别
ner = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english")
result = ner("Apple Inc. was founded by Steve Jobs in Cupertino, California.")
print("\n命名实体识别结果:", result)
# 问答系统
question_answerer = pipeline("question-answering", model="distilbert-base-cased-distilled-squad")
context = "Natural Language Processing is a field of artificial intelligence that focuses on the interaction between computers and humans through natural language."
question = "What is Natural Language Processing?"
result = question_answerer(question=question, context=context)
print("\n问答系统结果:")
print(f"答案:{result['answer']}")
print(f"置信度:{result['score']:.4f}")
# 文本生成
generator = pipeline("text-generation", model="gpt2")
result = generator("Natural Language Processing is", max_length=50, num_return_sequences=1)
print("\n文本生成结果:", result[0]['generated_text'])
8.4 使用PyTorch实现简单的RNN模型
import torch
import torch.nn as nn
import torch.optim as optim
# 定义RNN模型
class SimpleRNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(SimpleRNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
embedded = self.embedding(x)
output, hidden = self.rnn(embedded)
output = self.fc(output[:, -1, :]) # 取最后一个时间步的输出
return output
# 示例用法
# 假设我们有以下参数
vocab_size = 1000
embedding_dim = 100
hidden_dim = 256
output_dim = 2 # 二分类任务
# 创建模型
model = SimpleRNN(vocab_size, embedding_dim, hidden_dim, output_dim)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 示例输入(batch_size=2, sequence_length=5)
input = torch.randint(0, vocab_size, (2, 5))
# 前向传播
output = model(input)
print("模型输出形状:", output.shape) # 应该是(2, 2)
九、自然语言处理的评估指标
9.1 文本分类
- 准确率(Accuracy):正确分类的样本数占总样本数的比例
- 精确率(Precision):预测为正类的样本中实际为正类的比例
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例
- F1值:精确率和召回率的调和平均数
- ROC曲线和AUC值:评估二分类模型的性能
9.2 机器翻译
- BLEU(Bilingual Evaluation Understudy):比较机器翻译结果与参考翻译的相似度
- METEOR(Metric for Evaluation of Translation with Explicit ORdering):考虑同义词、词干等因素的翻译质量评估指标
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation):主要用于评估自动摘要和机器翻译的质量
9.3 语言模型
- 困惑度(Perplexity):衡量语言模型预测文本的能力,困惑度越低,模型性能越好
- 困惑度的计算公式:PPL = 2^(-(1/N) * Σ log2 P(w_i | w_1, w_2, ..., w_{i-1}))
9.4 序列标注
- 精确率(Precision):预测正确的标签数占总预测标签数的比例
- 召回率(Recall):预测正确的标签数占总真实标签数的比例
- F1值:精确率和召回率的调和平均数
- CoNLL分数:专门用于命名实体识别等序列标注任务的评估指标
十、自然语言处理的挑战与解决方案
10.1 挑战一:歧义性
问题:自然语言存在大量的歧义(如"我看见他拿着望远镜"可以理解为"我用望远镜看见他"或"我看见他,他拿着望远镜")。
解决方案:
- 利用上下文信息消除歧义
- 引入外部知识(如知识图谱)
- 采用深度学习模型,通过大规模语料库学习歧义消除的模式
10.2 挑战二:多义性
问题:同一个单词可能有多种含义(如"bank"可以表示银行或河岸)。
解决方案:
- 词义消歧(Word Sense Disambiguation)技术
- 基于上下文的词向量表示(如BERT)
- 利用词典和语料库中的语义信息
10.3 挑战三:数据稀疏性
问题:自然语言中的很多单词和短语出现频率很低,导致模型难以学习到它们的表示。
解决方案:
- 数据增强技术(如回译、同义词替换等)
- 迁移学习和预训练语言模型
- 利用外部语料库和知识源
10.4 挑战四:上下文理解
问题:理解文本需要考虑长期依赖关系和复杂的上下文信息。
解决方案:
- 采用递归神经网络(RNN)、长短期记忆网络(LSTM)等模型
- 使用Transformer模型,通过自注意力机制捕捉长距离依赖
- 引入记忆网络和注意力机制
10.5 挑战五:常识推理
问题:自然语言理解需要常识知识,但计算机缺乏人类的常识。
解决方案:
- 构建大规模知识图谱(如ConceptNet、DBpedia等)
- 开发常识推理模型
- 利用大规模预训练语言模型学习隐含的常识知识
10.6 挑战六:伦理与偏见
问题:自然语言处理模型可能会学习到训练数据中的偏见,导致生成有偏见的内容。
解决方案:
- 构建公平、无偏见的训练数据集
- 开发去偏见的模型训练方法
- 引入伦理审查机制
- 提高模型的透明度和可解释性
十一、自然语言处理的哲学思考
11.1 语言与思维的关系
语言是思维的载体,自然语言处理技术的发展让我们重新思考语言与思维的关系。计算机是否能够通过理解语言而获得思维能力?这是一个哲学上的重要问题。
11.2 机器智能与人类智能
自然语言处理技术的发展让机器能够生成越来越自然的文本,甚至在某些任务上超过人类。这是否意味着机器正在获得人类智能?机器智能与人类智能的本质区别是什么?
11.3 技术与人类的关系
自然语言处理技术的发展给人类带来了便利,但也带来了挑战。我们应该如何看待技术与人类的关系?技术应该是人类的工具,还是会反过来控制人类?
11.4 伦理与道德
自然语言处理技术的应用涉及到伦理与道德问题,如隐私保护、公平性、偏见等。我们应该如何确保技术的发展符合伦理道德规范?
十二、结语
自然语言处理技术的发展,让计算机从"听不懂"人类语言到能够"理解"和"生成"人类语言,这是人工智能领域的重大突破。从早期的基于规则的方法到现在的大语言模型,自然语言处理技术经历了从量变到质变的过程。
自然语言处理技术不仅给我们的生活带来了便利,也深刻地改变了我们与计算机的交互方式。然而,任何技术都是一把双刃剑,自然语言处理也不例外。在享受技术便利的同时,我们也需要关注它带来的挑战,如伦理问题、偏见问题、隐私问题等。
随着技术的不断发展,自然语言处理将在未来发挥更加重要的作用。让我们一起期待自然语言处理技术带来的更多惊喜和变革!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)