用深度强化学习攻克电力系统控制难题
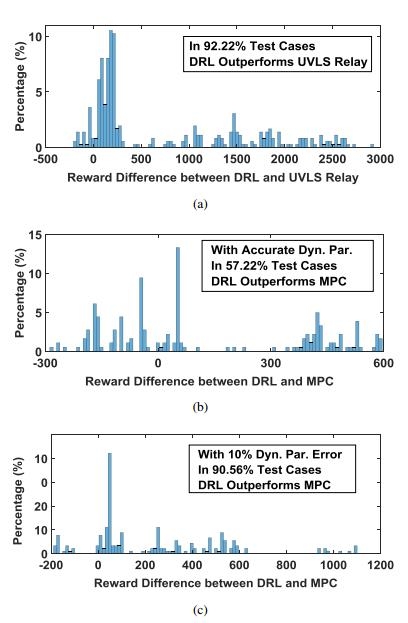
深度强化学习方法来解决电力系统的控制和决策问题 源代码利用InterPSS仿真平台作为电力系统模拟器。开发了一个与OpenAI兼容的电网动态仿真环境,用于开发、测试和基准测试电网控制的强化学习算法。电力系统应急控制,控制方案采用深度强化学习(DRL)高维特征提取和非线性泛化能力。提出了基于DRL的发电机动态制动和欠压减载应急控制方案,所开发的DRL方法鲁棒性对不同仿真场景,模型参数的不确定性和噪声
深度强化学习方法来解决电力系统的控制和决策问题 源代码 利用InterPSS仿真平台作为电力系统模拟器。 开发了一个与OpenAI兼容的电网动态仿真环境,用于开发、测试和基准测试电网控制的强化学习算法。 电力系统应急控制,控制方案采用深度强化学习(DRL)高维特征提取和非线性泛化能力。 提出了基于DRL的发电机动态制动和欠压减载应急控制方案,所开发的DRL方法鲁棒性对不同仿真场景,模型参数的不确定性和噪声无论是双区四机系统还是IEEE 39节点系统有良好的性能和鲁棒性。 利用深度强化学习(DRL)的高维特征提取和非线性泛化能力,开发了新的自适应应急控制方案。 辅助电力系统控制的DRL算法的开发和基准测试。 详细介绍了发电机动态制动和低压减载应急控制方案。 研究了发展的DRL方法对不同仿真场景、模型参数不确定性和观测噪声的鲁棒性。 在两领域,四机系统和IEEE 39总线系统中进行,证明了所提方案的优异性能和鲁棒性。
在电力系统这个复杂且关键的领域,控制与决策问题一直是研究重点。今天咱们来聊聊如何借助深度强化学习方法来巧妙解决这些难题,并且会穿插一些源代码和分析,让大家更好理解。
一、仿真平台选择 - InterPSS
咱们选用InterPSS仿真平台作为电力系统模拟器。这就好比搭建了一个虚拟的电力系统实验室,能为我们后续的研究提供基础环境。为啥选它呢?它在电力系统仿真方面有着强大的功能和广泛的认可度。
二、电网动态仿真环境开发
开发一个与OpenAI兼容的电网动态仿真环境是关键一步。这个环境简直就是强化学习算法的“练兵场”,用于开发、测试和基准测试电网控制的强化学习算法。就像为我们即将训练的“智能控制战士”打造了一个完美的训练基地。
这里简单说下代码实现的思路(以下代码仅为示意简化版):
# 导入相关库
import interpss
from gym import Env
from gym.spaces import Box
import numpy as np
# 自定义电网环境类
class PowerGridEnv(Env):
def __init__(self):
# 初始化InterPSS相关设置
self.interpss_system = interpss.initialize_system()
# 定义状态空间和动作空间
self.observation_space = Box(low = -np.inf, high = np.inf, shape=(state_dim,))
self.action_space = Box(low = -1, high = 1, shape=(action_dim,))
def step(self, action):
# 根据动作更新InterPSS系统状态
self.interpss_system.apply_action(action)
next_state = self.interpss_system.get_state()
reward = self.calculate_reward()
done = self.is_done()
return next_state, reward, done, {}
def reset(self):
# 重置InterPSS系统到初始状态
self.interpss_system.reset()
return self.interpss_system.get_state()分析:在这段代码里,我们首先导入了InterPSS库以及OpenAI Gym相关库。然后定义了一个PowerGridEnv类,继承自Env。在init函数里初始化了InterPSS系统,并定义了状态空间和动作空间。step函数根据传入的动作更新系统状态,计算奖励并判断是否结束。reset函数则是将系统重置到初始状态,这是强化学习环境很基础的结构。
三、深度强化学习在应急控制中的应用
电力系统应急控制是重中之重,而深度强化学习(DRL)的高维特征提取和非线性泛化能力在这里就派上大用场了。我们提出了基于DRL的发电机动态制动和欠压减载应急控制方案。
比如说发电机动态制动,代码可能类似这样(同样是简化示意):
# 假设这里已经有训练好的DRL模型
def dynamic_braking_control(state, model):
action = model.predict(state)
# 根据动作调整发电机相关参数
if action > 0:
# 增加制动电阻等操作
adjust_braking_resistance(action)
else:
# 减少制动电阻等操作
adjust_braking_resistance(-action)
return action分析:这段代码接收系统状态和训练好的DRL模型,模型根据状态预测出动作,然后根据动作对发电机的制动电阻等进行调整,从而实现动态制动控制。
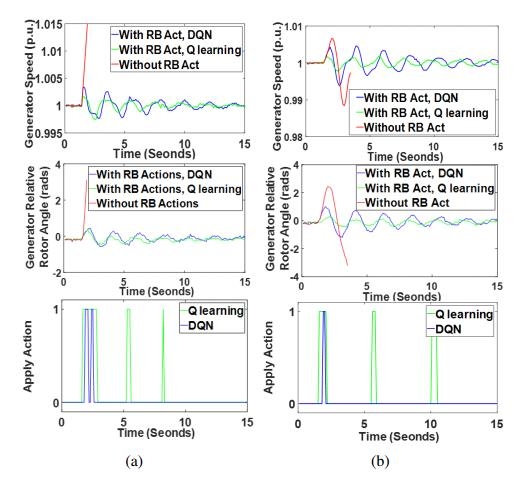
欠压减载应急控制方案也类似,通过DRL模型预测动作来决定是否切除部分负荷以应对欠压情况。
四、方案的鲁棒性研究
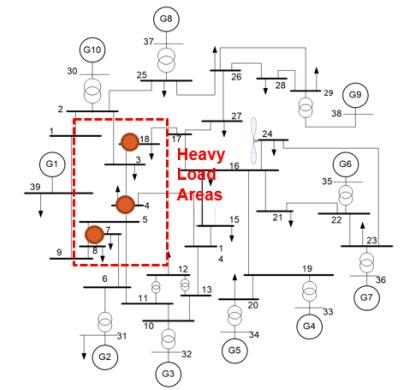
我们还着重研究了发展的DRL方法对不同仿真场景、模型参数不确定性和观测噪声的鲁棒性。在双区四机系统和IEEE 39节点系统中进行的实验证明了所提方案的优异性能和鲁棒性。不管系统参数怎么变,噪声如何干扰,我们的DRL控制方案都能保持良好的控制效果。
在实际研究中,我们会对不同场景下的参数进行调整,然后观察控制方案的表现,就像这样:
# 不同仿真场景测试
scenarios = ['scenario1','scenario2','scenario3']
for scenario in scenarios:
env = PowerGridEnv(scenario)
state = env.reset()
total_reward = 0
for _ in range(max_steps):
action = dynamic_braking_control(state, model)
state, reward, done, _ = env.step(action)
total_reward += reward
if done:
break
print(f"Scenario {scenario} total reward: {total_reward}")分析:这段代码遍历不同的仿真场景,在每个场景下初始化环境,通过循环让系统执行动作并记录奖励,最后输出每个场景下的总奖励,以此来评估不同场景下控制方案的性能。
深度强化学习在电力系统控制和决策问题上展现出了巨大的潜力,通过精心打造的仿真环境和巧妙设计的控制方案,我们能更好地保障电力系统的稳定运行。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)