LangChain 入门系列②:核心组件之 Model IO 快速入门指南
Model I/O 模块是与语言模型(LLMs)进行交互的核心组件,在整个框架中有着很重要的地位。
Model I/O介绍
Model I/O 模块是与语言模型(LLMs)进行交互的核心组件,在整个框架中有着很重要的地位。
所谓的Model I/O,包括输入提示(Format)、调用模型(Predict)、输出解析(Parse)。分别对应着 Prompt Template,Model和Output Parser
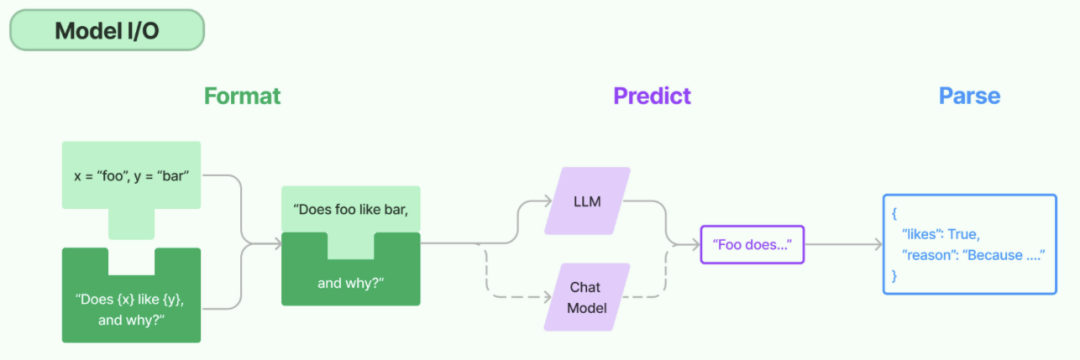
image
Model I/O之调用模型
LangChain作为一个“工具”,不提供任何 LLMs,而是依赖于第三方集成各种大模型。比如,将OpenAI、Anthropic、Hugging Face 、LlaMA、阿里Qwen、ChatGLM等平台的模型无缝接入到你的应用。
模型的不同分类方式
简单来说,就是⽤谁家的API以什么⽅式调⽤哪种类型的⼤模型
- 角度1:按照模型功能的不同
- 非对话模型(LLMs、Text Model)
- 对话模型(Chat Models)(推荐)
- 嵌入模型(Embedding Models)
- 角度2:模型调用时,几个重要参数的书写位置的不同
- 硬编码:写在代码文件中
- 使用环境变量
- 使用配置文件(推荐)
- 角度3:具体调用API
- OpenAI提供的API
- 其他大模型自家提供的API
- LangChain的统一方式调用API(推荐)
角度1出发:按照功能不同举例
类型1:LLMs(非对话模型)
LLMs,也叫Text Model、非对话模型,是许多语言模型应用程序的支柱。主要特点如下:
- 输入:接受
文本字符串或PromptValue对象 - 输出:总是返回
文本字符串
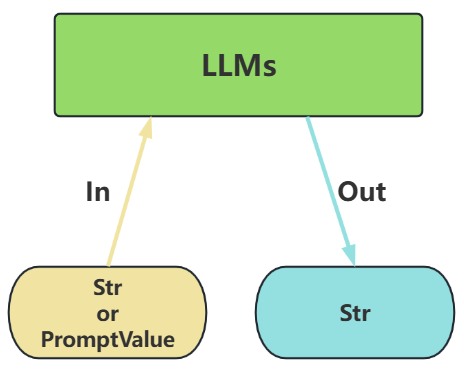
image
- 适用场景:仅需单次文本生成任务(如摘要生成、翻译、代码生成、单次问答)或对接不支持消息结构的旧模型(如部分本地部署模型)(
言外之意,优先推荐ChatModel) - 不支持多轮对话上下文。每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文本)。
- 局限性:无法处理角色分工或复杂对话逻辑。
举例:
import dotenvdotenv.load_dotenv()# 无需重复赋值,ChatOpenAI 会自动读取环境变量# os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")# os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")# 核心代码llm = OpenAI(model="glm-4.6")str_ = llm.invoke("写一首关于春天的诗") # 直接输入字符串print(str_)
输出:
content='\n好的,这是一首关于春天的现代诗,希望能捕捉到春天那份温柔、生机与希望。\n\n---\n\n**《春的来信》**\n\n不知是谁,悄悄叩响了窗,\n那是东风,带来了第一缕香。\n冰雪在檐下,悄然融化成响,\n沉睡的山野,正换上新装。\n\n柳丝垂下,一池碧绿的诗行,\n桃花燃起,漫山灼灼的霞光。\n燕子衔来,江南的湿润泥土,\n蜜蜂嗡嗡,酿着花蜜的甜香。\n\n孩童的笑语,追着纸鸢飞向远方,\n田埂的犁耙,翻开湿润的希望。\n人们收起,厚重的冬装与惆怅,\n把一颗心,交给这温柔的晴朗。\n\n啊,春天,你是一首未完的歌,\n每个音符,都蕴藏着蓬勃的生机。\n请允许我,将这份美好悄悄藏妥,\n在未来的路上,点亮一盏长明灯的回忆。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 2217, 'prompt_tokens': 10, 'total_tokens': 2227, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 4}}, 'model_name': 'glm-4.6', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run--5e9bd8e5-d100-4b11-8a92-ffe5f04c954a-0' usage_metadata={'input_tokens': 10, 'output_tokens': 2217, 'total_tokens': 2227, 'input_token_details': {'cache_read': 4}, 'output_token_details': {}}
类型2:Chat Models(对话模型)
ChatModels,也叫聊天模型、对话模型,底层使用LLMs。
大语言模型调用,以 ChatModel 为主!
主要特点如下:
- 输入:接收消息列表
List[BaseMessage]或PromptValue,每条消息需指定角色(如SystemMessage、HumanMessage、AIMessage) - 输出:总是返回带角色的
消息对象(BaseMessage子类),通常是AIMessage
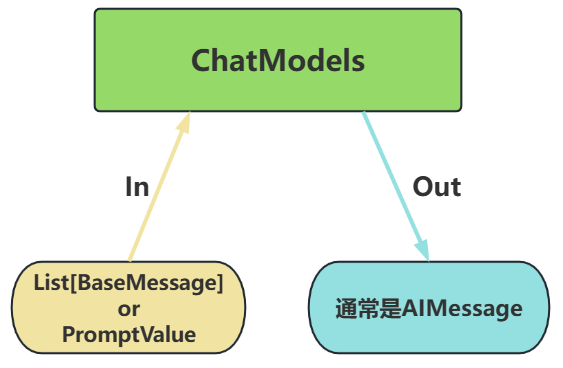
image
举例:
from langchain_openai import ChatOpenAIfrom langchain_core.messages import SystemMessage, HumanMessageimport dotenvdotenv.load_dotenv()# 核心代码chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))messages = [ SystemMessage(content="我是人工智能助手,我叫zxb"), HumanMessage(content="你好,我是小明,很高兴认识你")]response = chat_model.invoke(messages) # 输入消息列表print(type(response))print(response.content)
输出:
<class 'langchain_core.messages.ai.AIMessage'>小明你好!我也很高兴认识你。我是zxb,很高兴能为你服务。有什么想问的或者需要帮忙的,随时都可以告诉我。
类型3:Embedding Model(嵌入模型)
Embedding Model:也叫文本嵌入模型,这些模型将 文本 作为输入并返回 浮点数列表 ,也就是Embedding。
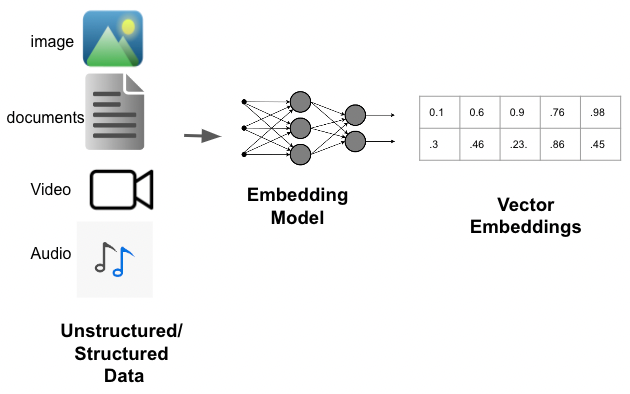
image
import osimport dotenvfrom langchain_openai import OpenAIEmbeddingsdotenv.load_dotenv()embeddings_model = OpenAIEmbeddings( model=os.getenv("LLM_EMBEDINGS_MODEL"))res1 = embeddings_model.embed_query('我是文档中的数据')print(res1)
角度2出发:参数位置不同举例
这里以 LangChain 的API为准,使用对话模型,进行测试。
模型调用的主要方法及参数
相关方法及属性:
OpenAI(...) / ChatOpenAI(...):创建一个模型对象(非对话类/对话类)model.invoke(xxx):执行调用,将用户输入发送给模型.content:提取模型返回的实际文本内容
模型调用函数使用时需初始化模型,并设置必要的参数。
-
必须设置的参数:
-
base_url:大模型 API 服务的根地址 -
api_key:用于身份验证的密钥,由大模型服务商(如 OpenAI、百度千帆)提供 -
model/model_name:指定要调用的具体大模型名称(如 gpt-4-turbo 、 ERNIE-3.5-8K 等) -
其它参数:
-
temperature:温度,控制生成文本的“随机性”,取值范围为0~1。 -
max_tokens:限制生成文本的最大长度,防止输出过长。
关于对话模型的Message(消息)
聊天模型,出了将字符串作为输入外,还可以使用 聊天消息 作为输入,并返回 聊天消息 作为输出。
LangChain有一些内置的消息类型:
🔥 SystemMessage :设定AI行为规则或背景信息。比如设定AI的初始状态、行为模式或对话的总体目标。比如“作为一个代码专家”,或者“返回json格式”。通常作为输入消息序列中的第一个传递。
🔥 HumanMessage:表示来自用户输入。比如“实现 一个快速排序方法”
🔥 AIMessage:存储AI回复的内容。这可以是文本,也可以是调用工具的请求
ChatMessage:可以自定义角色的通用消息类型
FunctionMessage/ToolMessage:函数调用/工具消息,用于函数调用结果的消息类
LangChain内置的消息类型举例
举例1
from langchain_core.messages import HumanMessage, SystemMessagemessages = [ SystemMessage(content="你是一位乐于助人的智能小助手"), HumanMessage(content="你好,请你介绍一下你自己")]print(messages)
举例2
from langchain_core.messages import HumanMessage, SystemMessage, AIMessagemessages = [ SystemMessage(content=['你是一个数学家,只会回答数学问题', '每次你都能给出详细的方案']), HumanMessage(content='1 + 2 * 3 = ?'), AIMessage(content="1 + 2 * 3的结果是7")]print(messages)
举例3
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage# 直接创建不同类型的消息systemMessage = SystemMessage( content="你是一个AI开发工程师", additional_kwargs={"tool": "invoke_tool()"})humanMessage = HumanMessage( content="你能开发哪些AI应用?")aiMessage = AIMessage( content="我能开发很多AI应用,比如聊天机器人,图像识别,自然语言处理等")messages = [systemMessage, humanMessage, aiMessage]print(messages)
举例4
from langchain_core.messages import ( AIMessage, HumanMessage, SystemMessage, ChatMessage)# 创建不同类型的消息system_message = SystemMessage(content="你是一个专业的数据科学家")human_message = HumanMessage(content="解释一下随机森林算法")ai_message = AIMessage(content="随机森林是一种集成学习方法...")custom_message = ChatMessage(role="analyst", content="补充一点关于超参数调优的信息")print(system_message.content)print(human_message.content)print(ai_message.content)print(custom_message.content)
举例5:结合大模型使用
import osimport dotenvfrom langchain_core.messages import SystemMessage, HumanMessagefrom langchain_openai import ChatOpenAIdotenv.load_dotenv()chat_model = ChatOpenAI( model=os.getenv("LLM_MODEL"))# 组成消息列表messages = [ SystemMessage(content="你是一个擅长人工智能相关学科的专家"), HumanMessage(content="请解释一下什么是机器学习?")]response = chat_model.invoke(messages)print(response.content)print(type(response))
关于多轮对话与上下文记忆
import dotenvfrom langchain_openai import ChatOpenAIdotenv.load_dotenv()chat_model = ChatOpenAI( model = os.getenv("LLM_MODEL"))
测试1
from langchain_core.messages import SystemMessage, HumanMessagesys_message = SystemMessage( content="我是一个人工智能的助手,我的名字叫小智",)human_message = HumanMessage(content="猫王是一只猫吗?")messages = [sys_message, human_message]# 调用大模型,传入messagesresponse = chat_model.invoke(messages)print(response.content)response1 = chat_model.invoke([sys_message, HumanMessage(content="你叫什么名字?")])print(response1.content)
测试2
from langchain_core.messages import SystemMessagesys_message = SystemMessage(content="我是一个人工智能的助手,我的名字叫小智")human_message = HumanMessage(content="猫王是一只猫吗?")human_message1 = HumanMessage(content="你叫什么名字?")messages = [sys_message, human_message, human_message1]# 调用大模型,传入messagesresponse = chat_model.invoke(messages)print(response.content)
测试3
from langchain_core.messages import SystemMessage, HumanMessagesys_message = SystemMessage( content="我是一个人工智能的助手,我的名字叫小智",)human_message = HumanMessage(content="猫王是一只猫吗?")sys_message1 = SystemMessage( content="我可以做很多事情,有需要就找我吧",)human_message1 = HumanMessage(content="你叫什么名字?")messages = [sys_message, human_message,sys_message1,human_message1]#调用大模型,传入messagesresponse = chat_model.invoke(messages)print(response.content)
测试4
from langchain_core.messages import SystemMessage, HumanMessage# 第1组sys_message = SystemMessage( content="我是一个人工智能的助手,我的名字叫小智",)human_message = HumanMessage(content="猫王是一只猫吗?")messages = [sys_message, human_message]# 第2组sys_message1 = SystemMessage( content="我可以做很多事情,有需要就找我吧",)human_message1 = HumanMessage(content="你叫什么名字?")messages1 = [sys_message1,human_message1]#调用大模型,传入messagesresponse = chat_model.invoke(messages)print(response.content)response = chat_model.invoke(messages1)print(response.content)
测试5
from langchain_core.messages import SystemMessage, HumanMessage, AIMessagemessages = [ SystemMessage(content="我是一个人工智能助手,我的名字叫小智"), HumanMessage(content="人工智能英文怎么说?"), AIMessage(content="AI"), HumanMessage(content="你叫什么名字"),]messages1 = [ SystemMessage(content="我是一个人工智能助手,我的名字叫小智"), HumanMessage(content="很高兴认识你"), AIMessage(content="我也很高兴认识你"), HumanMessage(content="你叫什么名字"),]messages2 = [ SystemMessage(content="我是一个人工智能助手,我的名字叫小智"), HumanMessage(content="人工智能英文怎么说?"), AIMessage(content="AI"), HumanMessage(content="你叫什么名字"),]chat_model.invoke(messages2)
关于模型调用的方法
为了尽可能简化自定义链的创建,我们实现了一个"Runnable"协议。许多LangChain组件实现了 Runnable 协议,包括聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
Runnable 定义的公共的调用方法如下:
invoke: 处理单条输入,等待LLM完全推理完成后再返回调用结果stream: 流式响应,逐字输出LLM的响应结果batch: 处理批量输入
这些也有相应的异步方法,应该与 asyncio 的 await 语法一起使用以实现并发:
astream: 异步流式响应ainvoke: 异步处理单条输入abatch: 异步处理批量输入astream_log: 异步流式返回中间步骤,以及最终响应astream_events: (测试版)异步流式返回链中发生的事件(在 langchain-core 0.1.14 中引入)
流式输出与非流式输出
在Langchain中,语言模型的输出分为了两种主要的模式:流式输出与非流式输出。
关于流式和非流式:流式响应[^1]
非流式输出
举例1
import osimport dotenvfrom langchain_core.messages import HumanMessagefrom langchain_openai import ChatOpenAIdotenv.load_dotenv()# 初始化大模型chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))# 创建消息messages = [HumanMessage(content="你好,请介绍一下自己")]# 非流式调用LLM获取响应response = chat_model.invoke(messages)# 打印响应内容print(response)
content='\n你好!我是GLM,由智谱AI开发的大语言模型。我致力于通过自然语言处理技术为用户提供信息和帮助,回答问题、参与对话,并在各种知识领域提供支持。\n\n我的训练涉及大量文本数据,让我能够理解和生成人类语言,同时持续学习和更新以提升能力。请注意,虽然我努力提供准确信息,但可能并非完全无误。\n\n有什么我能帮你解答的问题或你想了解的话题吗?我很乐意继续我们的对话!' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 362, 'prompt_tokens': 10, 'total_tokens': 372, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 4}}, 'model_name': 'glm-4.6', 'system_fingerprint': None, 'id': '20251202095426e1db3344f12c4e65', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--52093b3e-a04e-4a02-a722-b76bd7499734-0' usage_metadata={'input_tokens': 10, 'output_tokens': 362, 'total_tokens': 372, 'input_token_details': {'cache_read': 4}, 'output_token_details': {}}
举例2
import osimport dotenvfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIdotenv.load_dotenv()# 初始化大模型chat_model = ChatOpenAI(model=os.getenv('LLM_MODEL'))# 支持三个消息作为输入messages = [ SystemMessage(content="你是一位乐于助人的助手。你叫zxb"), HumanMessage(content="你是谁?")]response = chat_model.invoke(messages)print(response.content)
你好!我叫zxb。我是一个人工智能助手,也可以理解为一个大型语言模型。我的主要任务是根据你的指令,为你提供信息和帮助。无论是回答问题、撰写文案、翻译语言,还是陪你聊天,我都会尽力做到最好。总之,我是一个乐于助人、随时为你服务的AI伙伴。很高兴能与你交流!有什么可以帮你的吗?
举例3
import osimport dotenvfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIdotenv.load_dotenv()# 初始化大模型chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))messages = [ SystemMessage(content="你是一位乐于助人的助手。你叫zxb"), HumanMessage(content="你是谁?")]response = chat_model(messages) # 特别的写法print(response.content)
C:\Users\zxb\AppData\Local\Temp\ipykernel_57944\1329286193.py:14: LangChainDeprecationWarning: The method `BaseChatModel.__call__` was deprecated in langchain-core 0.1.7 and will be removed in 1.0. Use :meth:`~invoke` instead. response = chat_model(messages) # 特别的写法你好,我是zxb。我是一位乐于助人的助手。
流式输出
import osimport dotenvfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIdotenv.load_dotenv()# 初始化大模型chat_model = ChatOpenAI( model=os.getenv("LLM_MODEL"), streaming=True)# 创建消息messages = [HumanMessage(content="你好,请介绍一下自己"), SystemMessage(content="你是一位乐于助人的助手。你叫zxb")]# 流式调用LLM获取响应print("开始流式输出:")for chunk in chat_model.stream(messages): # 逐字打印内容块 print(chunk.content, end="", flush=True)print("\n流式输出结束")
批量调用
import osimport dotenvfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIdotenv.load_dotenv()# 初始化大模型chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))messages1 = [ SystemMessage(content="你是一位乐于助人的智能小助手"), HumanMessage(content="请帮我介绍一下什么是机器学习")]messages2 = [ SystemMessage(content="你是一位乐于助人的智能小助手"), HumanMessage(content="请帮我介绍一下什么是AIGC")]messages3 = [ SystemMessage(content="你是一位乐于助人的智能小助手"), HumanMessage(content="请帮我介绍一下什么是大模型技术")]messages = [messages1, messages2, messages3]# 调用batchresponse = chat_model.batch(messages)print(response)
[AIMessage(content='\n你好!当然可以!很高兴为你介绍机器学习这个非常有趣和重要的领域。\n\n我会用一个通俗的比喻开始,然后再深入一些细节,让你能轻松理解。\n\n---\n\n### 一、最核心的比喻:像人类一样“从经验中学习”\n\n想象一下,我们是如何学会识别猫的?\n\n没有人给我们一本《猫的几何学公式大全》或者《猫的像素构成指南》。相反,我们是看了很多很多猫的图片、视频,或者亲自摸过、喂过之后,大脑就潜移默化地形成了一种“猫”的概念。\n\n下次再看到一个毛茸茸、有胡须、叫声是“喵”的动物时,我们就能很快认出:“哦,这是一只猫。”\n\n**机器学习做的就是类似的事情。**\n\n它不是让程序员写下死板的规则(比如“如果动物有毛、有四条腿、有尖耳朵,它就是猫”),而是**给计算机海量的“数据”(经验),然后让算法(学习的方法)自己去发现数据中的规律和模式。**\n\n当训练完成后,这个模型就能像我们一样,对新的、没见过的数据做出判断或预测。\n\n---\n\n### 二、更正式一点的说法\n\n机器学习是人工智能(AI)的一个核心分支。它的经典定义是:\n\n> “一个计算机程序被认为可以从经验中学习,就是指它能够处理某些任务,随着处理数量的增加,任务的性能也会随之提高。”\n\n简单来说,机器学习就是:\n**利用算法,分析数据,从中学习,然后对真实世界中的未知数据进行预测或决策。**\n\n这里的关键要素是:\n* **数据**:学习的“养料”或“教材”。\n* **算法**:学习的“方法”或“模型结构”。\n* **模型**:学习后得到的“成果”,它内化了从数据中学到的规律。\n\n---\n\n### 三、机器学习是怎么工作的?\n\n一个典型的机器学习流程大致如下:\n\n1. **准备数据**:收集与问题相关的数据。比如,要识别垃圾邮件,就需要收集大量的邮件,并标记好哪些是“垃圾邮件”,哪些是“正常邮件”。这就像准备学生的课本和练习册。\n2. **选择模型**:根据要解决的问题,选择一个合适的算法(比如决策树、神经网络等)。这就像为学生选择一种学习方法。\n3. **训练模型**:把准备好的数据“喂”给算法进行学习。算法会不断调整自己的内部参数,努力让预测结果和真实标签之间的误差最小。这个过程就像学生在做练习题,并对答案,不断订正错题,提高成绩。\n4. **评估与预测**:用一些模型没见过的新数据来测试它的学习成果,看看它表现怎么样。如果表现良好,就可以把它部署到实际应用中,去处理真实世界的数据了。这就像学生参加毕业考试,合格后就能上岗工作。\n\n---\n\n### 四、机器学习的主要类型\n\n根据学习方式(特别是数据是否带有“答案”)的不同,机器学习主要分为三大类:\n\n#### 1. 监督学习\n* **特点**:给机器的数据是**带有标签**的,就像有老师监督着学习一样。我们告诉机器每个数据的正确答案是什么。\n* **比喻**:拿着带图片和单词的闪卡教孩子认字。\n* **常见应用**:\n * **分类**:预测一个类别(如:垃圾邮件识别、图片里是猫还是狗、客户是否会流失)。\n * **回归**:预测一个连续的数值(如:根据房屋面积和位置预测房价、根据历史数据预测明天股票的价格)。\n\n#### 2. 无监督学习\n* **特点**:给机器的数据**没有标签**,需要机器自己去找出数据中的结构和关系。\n* **比喻**:给你一大堆混杂的乐高积木,让你自己去分门别类(比如按颜色、按形状)。\n* **常见应用**:\n * **聚类**:将相似的数据点分到一组(如:用户分群,将购买行为相似的用户分为一类,以便精准营销)。\n * **降维**:在保留主要信息的前提下,减少数据的复杂度。\n\n#### 3. 强化学习\n* **特点**:没有现成的数据,而是让模型在一个**环境**中不断地**尝试**。模型做出一个动作,环境会给出一个**奖励**或**惩罚**,模型的目标是学会一套策略,以获得最多的长期奖励。\n* **比喻**:训练宠物。当它做出正确的动作(比如坐下)时,就给它零食(奖励);做错了就不给。慢慢地,它就学会了哪些行为会得到好处。\n* **常见应用**:\n * **游戏AI**:AlphaGo下围棋就是最经典的例子。\n * **自动驾驶**:车辆在模拟环境中不断学习如何应对各种路况。\n * **机器人控制**:学习如何抓取物体。\n\n---\n\n### 五、我们身边的机器学习例子\n\n其实,机器学习已经渗透到我们生活的方方面面:\n\n* **视频和音乐推荐**:抖音、B站、Netflix、Spotify会根据你的观看/收听历史,推荐你可能喜欢的内容。\n* **商品推荐**:淘宝、亚马逊会给你推荐“猜你喜欢”的商品。\n* **垃圾邮件过滤器**:你的邮箱自动把垃圾邮件扔进垃圾箱。\n* **语音助手**:Siri、小爱同学能听懂你的话并做出回应。\n* **人脸识别**:手机解锁、门禁系统、照片自动 tagging。\n* **智能输入法**:预测你接下来想输入的词语。\n\n---\n\n### 总结\n\n总而言之,**机器学习不是一门玄学,而是一套让计算机从数据中自动发现规律、并利用这些规律进行预测和决策的科学方法。** 它的核心是“学习”而非“编程”,这使得我们能够解决许多传统方法难以处理的复杂问题,是当今科技发展的核心驱动力之一。\n\n希望这个解释对你有帮助!如果你对某个特定方面(比如深度学习、某个具体应用)感兴趣,我们可以继续深入聊聊!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 2409, 'prompt_tokens': 21, 'total_tokens': 2430, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 4}}, 'model_name': 'glm-4.6', 'system_fingerprint': None, 'id': '2025120210340205e904fe44764738', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--2dea8341-cc0e-4b4b-976b-758dff0a5ced-0', usage_metadata={'input_tokens': 21, 'output_tokens': 2409, 'total_tokens': 2430, 'input_token_details': {'cache_read': 4}, 'output_token_details': {}}), AIMessage(content='\n你好!很高兴为你介绍AIGC,这绝对是当前最热门和影响深远的技术之一。\n\n我会用一个简单易懂的方式,为你全方位地拆解这个概念。\n\n---\n\n### 一、AIGC是什么?\n\n**AIGC** 全称是 **AI-Generated Content**,中文翻译为 **“人工智能生成内容”**。\n\n简单来说,**AIGC就是利用人工智能技术,自动生成各种类型的内容**。你可以把它想象成一个“超级数字创作者”或“全能创意助手”,你只需要给它指令(比如一段文字描述),它就能帮你创作出文章、图片、音乐、代码,甚至视频。\n\n**和传统AI的区别:**\n以前的AI更多是“分析型”的,比如识别图片里的猫、判断邮件是不是垃圾邮件。而AIGC是“创造型”的,它不是在分析已有的东西,而是在**创造全新的、过去不存在的东西**。\n\n---\n\n### 二、AIGC是如何工作的?\n\n虽然背后的技术很复杂,但我们可以用一个简单的比喻来理解:\n\n**就像一个博览群书的学生。**\n\n1. **“学习”阶段(训练):** 科学家们用一个叫做**“大模型”**的庞大AI系统,给它“喂”海量的数据,比如互联网上几乎所有的文本、图片、代码、乐谱等。\n2. **“理解”阶段(学习模式):** 在这个过程中,AIGC并不死记硬背,而是学习这些数据中的**模式、规律、风格和逻辑**。比如,它学会了什么样的词语组合通顺,什么样的光影关系是真实的,什么样的代码结构是高效的。\n3. **“创作”阶段(生成):** 当你给它一个指令时(例如,“画一只在月球上喝咖啡的宇航员”),它会调用所有学到的知识,将这些元素(宇航员、月球、咖啡)以一种符合逻辑和美感的方式重新组合,最终“创作”出一个全新的作品。\n\n---\n\n### 三、AIGC能做什么?(主要应用领域)\n\nAIGC的能力已经渗透到我们生活和工作的方方面面,主要包括:\n\n| 领域 | 具体应用 | 知名工具举例 |\n| :--- | :--- | :--- |\n| **🖋️ 文本生成** | 写文章、邮件、广告文案、诗歌、剧本、翻译、总结报告 | **ChatGPT**、文心一言、Claude |\n| **🎨 图像生成** | 根据文字描述创作画作、设计Logo、生成海报、修改图片 | **Midjourney**、Stable Diffusion、DALL-E |\n| **💻 代码生成** | 自动编写代码、修复Bug、解释代码功能、将一种编程语言翻译成另一种 | **GitHub Copilot**、CodeWhisperer |\n| **🎵 音频生成** | 创作背景音乐、生成歌曲、模拟特定人声说话(TTS)、声音克隆 | Suno AI, Udio |\n| **🎬 视频生成** | 根据文字或图片生成短视频、制作动画、智能剪辑 | Sora, Runway, Pika Labs |\n| **🎮 3D与虚拟世界** | 创建3D模型、游戏场景、虚拟数字人、虚拟主播 | ... (快速发展中) |\n\n---\n\n### 四、为什么AIGC如此重要?\n\nAIGC不仅仅是个酷炫的玩具,它正在引发一场深刻的革命:\n\n1. **极大地提升生产效率:** 过去需要几天完成的文案、设计图、代码,现在可能几分钟就能搞定。\n2. **降低创作门槛:** 即使你没有学过画画或编程,也能通过AIGC工具创造出令人惊艳的作品,让创意得以实现。\n3. **激发无限创意:** AIGC能提供人类意想不到的创意和组合,成为艺术家、设计师和科学家的灵感来源。\n4. **重塑行业格局:** 从市场营销、媒体娱乐到软件开发、教育培训,几乎所有行业都在被AIGC改变。\n\n---\n\n### 五、AIGC面临的挑战与风险\n\n任何强大的技术都有其两面性,AIGC也不例外:\n\n* **版权与知识产权:** AIGC生成的内容版权归谁?训练数据的版权问题如何解决?\n* **信息真实性:** 可能被用来制造虚假信息(深度伪造),混淆视听。\n* **伦理与偏见:** AI可能学习并放大训练数据中存在的社会偏见。\n* **就业冲击:** 一些依赖内容创作的岗位可能会受到冲击。\n* **数据安全与隐私:** 用户输入的指令可能会被用于模型训练,存在隐私泄露风险。\n\n---\n\n### 总结\n\n你可以把AIGC看作一个**全新的“生产力工具”**,就像互联网和个人电脑一样。它不是要完全取代人类,而是要成为我们的“**创意副驾驶**”或“**智能杠杆**”。\n\n学会理解和善用AIGC,将能极大地释放你的创造力和工作效率,让你在未来竞争中占据优势。\n\n希望这个介绍对你有帮助!如果你对某个具体方面感兴趣,比如想聊聊某个工具,或者想知道怎么用它来解决实际问题,随时可以再问我哦!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 2267, 'prompt_tokens': 22, 'total_tokens': 2289, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 6}}, 'model_name': 'glm-4.6', 'system_fingerprint': None, 'id': '2025120210340277fec5208ecf492b', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--8dc6f162-5fec-4e69-b556-db131d56e45c-0', usage_metadata={'input_tokens': 22, 'output_tokens': 2267, 'total_tokens': 2289, 'input_token_details': {'cache_read': 6}, 'output_token_details': {}}), AIMessage(content='\n好的,没问题!很高兴能为你介绍这个激动人心的话题。我会用一个尽可能通俗易懂的方式来为你讲解什么是“大模型技术”。\n\n### 一句话概括\n**大模型技术,就像给计算机喂读了全世界几乎所有的书籍、网页、图片和知识,让它拥有一个超级大脑,从而能够像人一样理解、思考、推理和创造。**\n\n---\n\n下面我们来展开聊聊:\n\n### 1. “大”在哪里?\n\n我们通常说的“大模型”,全称是“大规模预训练模型”。它的“大”主要体现在三个方面:\n\n**a. 巨大的参数规模**\n* **什么是参数?** 你可以把参数想象成大脑中的神经元连接点。模型参数越多,代表它的“脑容量”越大,能够记忆和学习的知识就越复杂。\n* **规模有多大?** 早期的AI模型可能有几百万、几千万个参数。而现在的大模型,参数规模动辄是**百亿、千亿,甚至上万亿**!这个数量级的飞跃是能力的根本来源。\n\n**b. 海量的训练数据**\n* **训练数据是什么?** 就是我们给AI学习的“教材”。这个教材包罗万象,几乎包含了整个互联网上的文本、书籍、代码、图片、音视频等等。\n* **数据有多海量?** 像是GPT-4这样的模型,其训练数据量是以PB(1PB = 1024TB)来计算的。它读了人类有史以来大量的知识,所以才能“上知天文,下知地理”。\n\n**c. 强大的通用能力**\n* 因为“脑容量”大,看的书多,大模型出现了一种神奇的现象,叫做**“涌现能力”**。意思是当规模突破某个临界点后,它突然学会了很多没有被“刻意”去教它的能力,比如:\n * **推理能力**:能根据已知信息进行逻辑推断。\n * **代码能力**:能看懂、编写和调试代码。\n * **创作能力**:能写诗、写小说、写剧本。\n * **多语言翻译**:能轻松在几十种语言间互译。\n* 一个大模型就能解决成百上千种不同的任务,不像以前的AI模型,通常只能做一件特定的事(比如一个专门下棋的AI,你让它翻译就不行了)。所以,它是**通用人工智能(AGI)**的雏形。\n\n### 2. 它是如何工作的?\n\n用一个简单的比喻来说,大模型最核心的工作机制是**“文字接龙”**或者说**“预测下一个词”**。\n\n1. **你输入一个问题(提示)**:“今天天气怎么样,适合出门吗?”\n2. **模型开始计算**:它会根据自己庞大的知识库(也就是那亿万个参数),计算在你这句话之后,最有可能出现的词是什么。\n3. **生成第一个词**:它可能会判断出“查询”或“看”是概率最高的词,于是先生成“查询”。\n4. **循环往复**:然后,它把“今天天气怎么样,适合出门吗?查询”作为新的输入,继续预测下一个最可能的词,可能是“一下”、“天气”。\n5. **最终形成完整回答**:通过这样一次又一次地预测下一个词,最终它就能组织出一段通顺、合理且符合逻辑的回答,比如:“查询一下,今天你所在的地区是晴天,气温25度,微风,非常适合出门散步。”\n\n**正是这个看似简单的“预测下一个词”的机制,在海量数据和巨大参数的加持下,表现出了惊人的智能。**\n\n### 3. 大模型技术能做什么?(应用场景)\n\n大模型技术正在像水和电一样,渗透到我们生活和工作的方方面面:\n\n* **智能助手 & 聊天机器人**:就像你现在和我(AI助手)的对话。苹果的Siri、小米的小爱同学等也在深度集成大模型,变得越来越聪明。\n* **内容创作**:\n * **文本**:写邮件、写报告、写营销文案、写代码、写剧本、写诗。\n * **图像**:根据文字描述生成精美图片(如Midjourney, Stable Diffusion)。\n * **音视频**:生成语音、音乐,甚至剪辑视频。\n* **信息处理与分析**:快速总结长篇报告、提取关键信息、分析客户反馈的情感倾向。\n* **垂直行业应用**:\n * **科研**:帮助科学家发现新药、研究蛋白质结构(如AlphaFold)。\n * **教育**:打造个性化学习辅导老师。\n * **医疗**:辅助医生进行诊断、分析病历。\n * **工业**:优化生产流程、预测设备故障。\n\n### 4. 面临的挑战与未来\n\n当然,大模型技术并非完美,它也面临着一些挑战:\n\n* **“幻觉”问题**:有时会一本正经地胡说八道,编造不存在的“事实”。\n* **偏见问题**:训练数据中如果存在偏见,模型也会学会并放大这些偏见。\n* **成本高昂**:训练和运行一个大模型需要巨大的算力(昂贵的GPU)和能源消耗。\n* **安全与隐私**:如何确保模型不被恶意利用,如何保护用户输入的隐私数据。\n\n**未来,大模型技术的发展方向可能包括:**\n\n* **多模态融合**:更无缝地理解和处理文本、图像、声音、视频等多种信息。\n* **更强的推理能力**:从“懂知识”向“会思考”迈进。\n* **模型小型化**:让强大的模型也能在手机、汽车等端侧设备上高效运行。\n* **个性化与定制**:为每个人、每个企业打造专属的AI模型。\n\n---\n\n**总结一下:**\n\n大模型技术是AI发展史上的一个里程碑,它通过“暴力美学”(海量数据+巨大算力)实现了智能的质变。它不是一个简单的程序,更像是一个全新的、能理解和创造信息的“智能引擎”。我们正处在一个由大模型技术驱动的全新时代的开端,它将深刻地改变我们的工作、生活和与世界的交互方式。\n\n希望这个介绍对你有帮助!如果还有其他问题,随时可以问我哦!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 2480, 'prompt_tokens': 22, 'total_tokens': 2502, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 4}}, 'model_name': 'glm-4.6', 'system_fingerprint': None, 'id': '2025120210340259cabc05084b4e6a', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--8ef9eaaf-5aac-4d0c-b5a3-3d185b97370b-0', usage_metadata={'input_tokens': 22, 'output_tokens': 2480, 'total_tokens': 2502, 'input_token_details': {'cache_read': 4}, 'output_token_details': {}})]
Model I/O之Prompt Template
Prompt Template,通过模板管理大模型的输入
介绍与分类
Prompt Template 是LangChain中的一个概念,接收用户输入,返回一个传递给LLM的信息(即提示词prompt)。
在应用开发中,固定的提示词限制了模型的灵活性和适用范围。所以,prompt template 是一个模板化的字符串,你可以将变量插入到模板中,从而创建出不同的提示。调用时:
- 以
字典作为输入,其中每个键代表要填充的提示模板中的变量。 - 输出一个
PromptValue。这个 PromptValue 可以传递给 LLM 或 ChatModel,并且还可以转换为字符串或消息列表。
有几种不同类型的提示模板:
PromptTemplate:LLM提示模板,用于生成字符串提示。它使用 Python 的字符串来模板提示。ChatPromptTemplate:聊天提示模板,用于组合各种角色的消息模板,传入聊天模型。XxxMessagePromptTemplate:消息模板词模板,包括:SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate、ChatMessagePromptTemplate等FewShotPromptTemplate:样本提示词模板,通过示例来教模型如何回答PipelinePrompt:管道提示词模板,用于把几个提示词组合在一起使用。- 自定义模板 :允许基于其它模板类来定制自己的提示词模板。
具体使用:PromptTemplate
PromptTemplate类,用于快速构建包含变量的提示词模板,并通过传入不同的参数值生成自定义的提示词。
两种实例化方式
方式1:使用构造方法
举例1:
from langchain.prompts import PromptTemplate# 自定义模板:描述主题的应用template = PromptTemplate( template="请简要描述{topic}的应用", input_variables=["topic"])print(template)# 使用模板生成提示词prompt_1 = template.format(topic = "机器学习")prompt_2 = template.format(topic = "自然语言处理")print("提示词1:", prompt_1)print("提示词2:", prompt_2)
input_variables=['topic'] input_types={} partial_variables={} template='请简要描述{topic}的应用'提示词1: 请简要描述机器学习的应用提示词2: 请简要描述自然语言处理的应用
举例2:定义多变量模板
from langchain.prompts import PromptTemplate# 定义多变量模板template = PromptTemplate( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。", input_variables=["product", "aspect1", "aspect2"])# 使用模板生成提示词prompt_1 = template.format(product="智能手机", aspect1="电池续航", aspect2="拍照质量")prompt_2 = template.format(product="MacBook Pro", aspect1="屏幕尺寸", aspect2="价格")print("提示词1:", prompt_1)print("提示词2:", prompt_2)
提示词1: 请评价智能手机的优缺点,包括电池续航和拍照质量。提示词2: 请评价MacBook Pro的优缺点,包括屏幕尺寸和价格。
方式2:调用from_template()
举例1:
from langchain.prompts import PromptTemplateprompt_template = PromptTemplate.from_template( "请给我一个关于{topic}的{type}解释")prompt = prompt_template.format(topic="量子力学", type="详情")print(prompt)
请给我一个关于量子力学的详情解释
举例2:模板支持任意数量的变量,包括不含变量:
# 1.导入相关的包from langchain_core.prompts import PromptTemplate# 2. 定义提示词模板对象text = """Tell me a joke"""prompt_template = PromptTemplate.from_template(text)# 3. 默认使用f-string进行格式化(返回格式化好的字符串)prompt = prompt_template.format()print(prompt)
两种新的结构形式
形式1:部分提示词模版
在生成prompt前就已经提前初始化部分的提示词,实际进一步导入模版的时候只导入除已初始化的变量
即可。
举例1:
方式1:实例化过程中使用partial_variables变量
from langchain.prompts import PromptTemplatetemplate = PromptTemplate( template="{foo}{bar}", input_variables=["foo", "bar"], partial_variables={"foo": "hello"})prompt = template.format(bar="world")print(prompt)
helloworld
方式2:使用 PromptTemplate.partial() 方法创建部分提示模板
from langchain.prompts import PromptTemplatetemplate = PromptTemplate( template="{foo}{bar}", input_variables=["foo", "bar"])partial_template = template.partial(foo="hello")prompt = partial_template.format(bar="world")print(prompt)
helloworld
举例2:
from langchain_core.prompts import PromptTemplate# 完整模板full_template = """你是一个{role},请用{style}风格回答:问题:{question}答案:"""# 预填充角色和风格partial_template = PromptTemplate.from_template(full_template).partial( role="资深厨师", style="专业但幽默")# 只需要提供剩余变量print(partial_template.format(question="如何煎牛排?"))
你是一个资深厨师,请用作业但幽默风格回答:问题:如何煎牛排?答案:
举例3:
from langchain_core.prompts import PromptTemplateprompt_template = PromptTemplate.from_template( template = "请评价{product}的优缺点,包括{aspect1}和{aspect2}。", partial_variables={"aspect1": "电池", "aspect2": "屏幕"})prompt = prompt_template.format(product="笔记本电脑")print(prompt)
请评价笔记本电脑的优缺点,包括电池和屏幕。
形式2:组合提示词(了解)
from langchain_core.prompts import PromptTemplatetemplate = ( PromptTemplate.from_template("Tell me a joke about {topic}") + ", make it funny" + "\n\nand in {language}")prompt = template.format(topic="sports", language="spanish")print(prompt)
Tell me a joke about sports, make it funnyand in spanish
format() 与 invoke()
- 只要对象是RunnableSerializable接口类型,都可以使用
invoke(),替换前面使用format()的调用方式。 format(),返回值为字符串类型;invoke(),返回值为PromptValue类型,接着调用to_string()返回字符串。
举例1:
from langchain_core.prompts import PromptTemplate# 定义提示词模板对象prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}.")# 默认使用f-string格式化prompt_template.invoke({"adjective": "funny", "content": "chickens"})
StringPromptValue(text='Tell me a funny joke about chickens.')
举例2:
from langchain_core.prompts import PromptTemplate# 使用初始化进行实例化prompt = PromptTemplate( input_variables=["adjective", "content"], template="Tell me a {adjective} joke about {content}")# PromptTemplate底层是RunnableSerializable接口 所以可以直接使用invoke()调用prompt.invoke({"adjective": "funny", "content": "chickens"})
StringPromptValue(text='Tell me a funny joke about chickens')
举例3:
from langchain_core.prompts import PromptTemplateprompt_template = ( PromptTemplate.from_template("Tell me a joke about {topic}") + ", make it funny" + " and in {language}")prompt = prompt_template.invoke({"topic": "sports", "language": "spanish"})print(prompt)
text='Tell me a joke about sports, make it funny and in spanish'
结合LLM调用
Prompt 与大模型结合。
from langchain_core.prompts import PromptTemplatefrom langchain_openai import ChatOpenAIimport dotenvimport osdotenv.load_dotenv()llm = ChatOpenAI(model=os.getenv("LLM_MODEL"))prompt_template = PromptTemplate.from_template( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。")product = input("请输入产品名称:")aspect1 = input("请输入第一个评价项:")aspect2 = input("请输入第二个评价项:")prompt = prompt_template.format(product=product, aspect1=aspect1, aspect2=aspect2)print(type(prompt))# llm.invoke(prompt)for chunk in llm.stream(prompt): print(chunk.content, end="", flush=True)
<class 'str'>好的,这是一个对现代智能手机的全面评价,涵盖了其通用优缺点,并重点分析了AI赋能和AI语音助手的特定方面。---### **对现代智能手机的综合评价**智能手机已经从简单的通讯工具,演变成了我们生活中不可或缺的“数字中枢”。它集通讯、信息、娱乐、工作、支付等功能于一身,而近年来人工智能(AI)的深度赋能,更是极大地提升了其能力边界,但同时也带来了新的挑战。---### **一、 手机的总体优缺点**#### **优点**1. **极致的便捷性与连接性:** 随时随地与世界保持连接。通过电话、短信、社交媒体、即时通讯工具,人与人之间的沟通变得前所未有的简单高效。2. **强大的信息获取能力:** 整个互联网尽在指尖。无论是学习新知识、查询资料、阅读新闻,还是观看教学视频,手机都是最直接的入口。3. **高效的生产力工具:** 邮件、日历、云文档、视频会议等应用让移动办公成为可能。你可以随时随地处理工作,大大提高了灵活性和效率。4. **丰富的娱乐体验:** 高清屏幕、立体声扬声器、强大的图形处理能力,使其成为绝佳的游戏机、电影院和音乐播放器。5. **全能的生活助手:** 移动支付、地图导航、在线购物、外卖点餐、打车出行……手机几乎渗透到现代生活的每一个角落,极大地简化了日常事务。6. **出色的影像记录能力:** 多摄像头系统、计算摄影技术的进步,让普通人也能轻松拍出高质量的照片和视频,记录生活中的精彩瞬间。#### **缺点**1. **健康隐患:** * **视力问题:** 长时间盯着小屏幕容易导致眼干、眼疲劳和近视加深。 * **颈椎问题:** 低头姿势是颈椎病的诱因之一。 * **睡眠干扰:** 屏幕发出的蓝光会抑制褪黑素分泌,影响睡眠质量。 * **心理问题:** 信息过载、社交攀比可能导致焦虑和抑郁。2. **信息过载与成瘾性:** 无休止的通知推送、算法推荐的信息流,容易让人陷入“数字沉迷”,消耗大量时间精力,难以专注。3. **隐私与安全风险:** 手机存储了大量个人敏感信息(照片、联系人、位置、支付信息等),一旦被黑客攻击或数据被滥用,后果不堪设想。App过度索权也是普遍问题。4. **高昂的成本:** 高端旗舰手机价格不菲,加上配套的套餐、配件、维修费用,是一笔不小的开支。5. **数字鸿沟:** 对于老年人等群体,复杂的操作和学习成本可能使他们被隔绝在数字世界之外。6. **环境影响:** 手机的生产、运输和废弃处理过程都伴随着能源消耗和环境污染问题。---### **二、 AI赋能的优缺点**AI不是手机的某个单一功能,而是一种底层能力,它让手机从“执行命令”的工具,向“理解用户”的智能伙伴进化。#### **AI赋能的优点**1. **智能摄影与影像优化:** * **场景识别:** AI能自动识别风景、人像、美食等场景,并调整最佳拍摄参数。 * **人像模式:** 通过AI算法精准抠图,实现单反级的背景虚化效果。 * **夜景模式/超级HDR:** AI通过多帧合成和降噪技术,在暗光环境下也能拍出清晰明亮的照片。2. **系统性能与功耗优化:** * **智能调度:** AI学习用户的使用习惯,预测你将要打开的应用,提前分配CPU、内存资源,让系统运行更流畅。 * **智能省电:** AI根据使用场景,智能调节后台应用活动和网络连接,有效延长续航。3. **高度个性化的体验:** * **内容推荐:** 新闻、音乐、视频App利用AI算法为你推荐你可能感兴趣的内容。 * **智慧功能:** 如“负一屏”的信息聚合,能根据你的日程、航班、快递等信息,主动呈现卡片提醒。4. **打破语言壁垒:** * **实时翻译:** AI可以实现语音、文字甚至相机取景框内的实时翻译,让跨语言交流变得轻松。5. **提升输入与沟通效率:** * **智能输入法:** AI提供更精准的联想词、整句预测和纠错功能。 * **邮件/信息智能回复:** AI可以根据邮件内容,生成快速回复建议。#### **AI赋能的缺点**1. **加剧的隐私担忧:** AI的“智能”建立在海量数据分析之上。你的位置、行为、偏好等数据被持续收集和分析,这引发了关于数据所有权和滥用的严重担忧。2. **算法偏见与信息茧房:** 个性化推荐在带来便利的同时,也可能让你只看到自己想看的信息,视野变窄,形成“信息茧房”,甚至可能被算法引导至极端或偏见的内容。3. **决策过程的“黑箱”问题:** AI的决策过程往往不透明。当它做出一个奇怪的推荐或决定时,用户很难理解背后的原因,缺乏控制感和信任感。4. **潜在的功耗增加:** 复杂的AI计算需要消耗额外的电力,尽管芯片在能效上不断进步,但在某些场景下,AI功能仍是耗电大户。---### **三、 AI语音助手的优缺点**AI语音助手(如Siri、GoogleAssistant、小爱同学等)是AI赋能最直观的体现之一。#### **AI语音助手的优点**1. **解放双手,提升可访问性:** 在开车、做饭、运动等不便用手操作的场景下,语音控制是唯一的安全选择。对视障或肢体不便的用户来说,这是极大的福音。2. **快速的信息查询与任务执行:** “今天天气怎么样?”“设置一个明天早上7点的闹钟”“打电话给妈妈”。这些简单的指令比手动操作快得多。3. **智能家居的控制中枢:** 语音助手可以轻松控制家中的智能灯光、空调、窗帘、音箱等设备,是构建智能家居生态的核心。4. **便捷的日程与提醒管理:** 通过语音快速创建日程、设置提醒事项,高效管理个人时间。#### **AI语音助手的缺点**1. **理解与识别的局限性:** 尽管进步巨大,但在嘈杂环境下、面对复杂指令或口音、方言时,语音助手的识别率和理解准确率仍然有待提高。对话体验远不如人与人之间自然。2. **严重的隐私顾虑:** 语音助手通常需要“始终在线”监听唤醒词,这引发了用户对于日常对话是否被“偷听”和录音数据是否被滥用的担忧。3. **对网络连接的强依赖:** 大部分复杂的语音处理都需要在云端完成,没有网络或网络不佳时,其功能会大打折扣。4. **交互体验的“机械感”:** 缺乏真正的情感理解和上下文连贯性,多轮对话能力弱,交互过程常常显得生硬和“笨拙”。---### **总结**现代智能手机是一把典型的“双刃剑”。* **从积极层面看**,它以前所未有的方式提升了我们的生活、工作和娱乐效率,而AI的加入更是如虎添翼,使其变得更“聪明”、更“懂你”,成为强大的个人助理。* **从消极层面看**,它也带来了健康、隐私、成瘾等一系列社会问题。AI在赋能的同时,也加深了数据隐私的困境和算法的潜在风险。最终,手机的价值取决于我们如何使用它。**关键在于成为工具的主人,而非被其奴役。** 我们需要培养健康的数字使用习惯,关注个人隐私设置,并理性看待AI带来的便利与风险,这样才能最大限度地发挥其正面价值,同时规避其潜在的危害。
插入消息列表:MessagesPlaceholder
使用场景:多轮对话系统存储历史消息以及Agent的中间步骤处理此功能非常有用。
举例1:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.messages import HumanMessagefrom langchain_openai import ChatOpenAIimport dotenvimport osdotenv.load_dotenv()llm = ChatOpenAI(model=os.getenv("LLM_MODEL"))prompt_template = ChatPromptTemplate.from_messages([ ("system", "You are a helpful assistant"), MessagesPlaceholder("msgs")])# prompt_template.format_messages(msgs=[HumanMessage(content="hi!")])message = prompt_template.format_messages(msgs=[HumanMessage(content="hi!")])# for chunk in llm.stream(message):# print(chunk.content, end="", flush=True)print(message)
[SystemMessage(content='You are a helpful assistant', additional_kwargs={}, response_metadata={}), HumanMessage(content='hi!', additional_kwargs={}, response_metadata={})]
举例2:存储对话历史内容
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.messages import AIMessagefrom langchain_openai import ChatOpenAIimport dotenvimport osdotenv.load_dotenv()llm = ChatOpenAI(model=os.getenv("LLM_MODEL"))prompt = ChatPromptTemplate.from_messages( [ ("system", "You are helpful assistant."), MessagesPlaceholder("history"), ("human", "{question}") ])msg = prompt.format_messages( history=[HumanMessage(content="1+2*3=?"), AIMessage(content="1+2*3=7")], question="我刚才的问题是什么?")print(msg)print(llm.invoke(msg))
[SystemMessage(content='You are helpful assistant.', additional_kwargs={}, response_metadata={}), HumanMessage(content='1+2*3=?', additional_kwargs={}, response_metadata={}), AIMessage(content='1+2*3=7', additional_kwargs={}, response_metadata={}), HumanMessage(content='我刚才的问题是什么?', additional_kwargs={}, response_metadata={})]------content='\n您刚才的问题是:1+2*3=?' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 333, 'prompt_tokens': 37, 'total_tokens': 370, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 6}}, 'model_name': 'glm-4.6', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run--65ba9739-b647-4caf-b0dd-6eeaa7fb9463-0' usage_metadata={'input_tokens': 37, 'output_tokens': 333, 'total_tokens': 370, 'input_token_details': {'cache_read': 6}, 'output_token_details': {}}
举例3:
from langchain_core.prompts import (ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate)from langchain_core.messages import SystemMessage# 定义消息模板prompt = ChatPromptTemplate( [ SystemMessagePromptTemplate.from_template("你是{role}"), MessagesPlaceholder(variable_name="intermediate_steps"), HumanMessagePromptTemplate.from_template("{query}") ])# 定义消息对象intermediate = [ SystemMessage(name="search", content="厦门: 晴, 25℃")]# 格式化聊天消息提示词模板prompt.format_messages( role="天气预报员", intermediate_steps=intermediate, query="厦门天气怎么样?")
[SystemMessage(content='你是天气预报员', additional_kwargs={}, response_metadata={}), SystemMessage(content='厦门: 晴, 25℃', additional_kwargs={}, response_metadata={}, name='search'), HumanMessage(content='厦门天气怎么样?', additional_kwargs={}, response_metadata={})]
具体使用:少量样本示例的提示词模板
使用说明
在构建prompt时,可以通过构建一个少量示例列表去进一步格式化prompt,这是一种简单但强大的指导生成的方式,在某些情况下可以显著提高模型性能。
少量示例提示模板可以由一组示例或一个负责从定义的集合中选择一部分示例的示例选择器构建。
- 前者:使用FewShotPromptTemplate或FewShotChatMessagePromptTemplate
- 后者:使用Example selectors(示例选择器)
每个示例的结构都是一个字典,其中键是输入变量,值是输入变量的值
体会:zeroshot(零样本学习)会导致低质量回答
FewShotPromptTemplate的使用
举例1:
from langchain.prompts.few_shot import FewShotPromptTemplate# 创建示例集合examples = [ {"input": "北京天气怎么样", "output": "北京市"}, {"input": "南京下雨吗", "output": "南京市"}, {"input": "武汉热吗", "output": "武汉市"}]# 创建PromptTemplate示例example_prompt = PromptTemplate.from_template( template="input: {input}\nOutput:{output}")# 创建FewShotPromptTemplate实例prompt = FewShotPromptTemplate( examples=examples, example_prompt=example_prompt, suffix="input: {input}\nOutput:", # 要放在示例后面的提示模板字符串 input_variables=["input"] # 传入的变量)# 调用prompt = prompt.invoke({"input": "长沙多少度?"})print(prompt)
text='input: 北京天气怎么样\nOutput:北京市\n\ninput: 南京下雨吗\nOutput:南京市\n\ninput: 武汉热吗\nOutput:武汉市\n\ninput: 长沙多少度?\nOutput:'
结合LLM使用:
import osimport dotenvfrom langchain_openai import ChatOpenAIfrom langchain.prompts import PromptTemplatefrom langchain.prompts.few_shot import FewShotPromptTemplatedotenv.load_dotenv()llm = ChatOpenAI(model=os.getenv("LLM_MODEL"), temperature=0.4)# 创建示例集合examples = [ {"input": "北京天气怎么样", "output": "北京市"}, {"input": "南京下雨吗", "output": "南京市"}, {"input": "武汉热吗", "output": "武汉市"}]# 创建PromptTemplate示例example_prompt = PromptTemplate.from_template( template="input: {input}\nOutput:{output}")# 创建FewShotPromptTemplate实例prompt = FewShotPromptTemplate( examples=examples, example_prompt=example_prompt, suffix="input: {input}\nOutput:", # 要放在示例后面的提示模板字符串 input_variables=["input"] # 传入的变量)# 调用prompt = prompt.invoke({"input": "长沙多少度?"})res = llm.invoke(prompt)print(res.content)
长沙市
举例2:
import osimport dotenvfrom langchain_openai import ChatOpenAIfrom langchain.prompts import PromptTemplatefrom langchain.prompts.few_shot import FewShotPromptTemplate# 创建提示模板,配置一个提示模板,将一个示例格式化为字符串prompt_template = "你是一个数字专家,算式:{input} 值:{output} 使用:{description}"# 这是一个提示模板,用于设置每个示例的格式prompt_sample = PromptTemplate.from_template(prompt_template)# 提供示例examples = [ {"input": "2+2", "output": "4", "description": "加法运算"}, {"input": "5-2", "output": "3", "description": "减法运算"},]# 创建一个FewShotPromptTemplate对象prompt = FewShotPromptTemplate( examples=examples, example_prompt=prompt_sample, suffix="你是一个数学家,算式:{input} 值:{output}", input_variables=["input", "output"])print(prompt.invoke({"input": "2*5", "output": "10"}))print("*"*20)# 初始化大模型,然后调用dotenv.load_dotenv()llm = ChatOpenAI(model=os.getenv("LLM_MODEL"))result = llm.invoke(prompt.invoke({"input": "2*5", "output": "10"}))print(result.content)
FewShotChatMessagePromptTemplate的使用
除了FewShotPromptTemplate之外,FewShotChatMessagePromptTemplate是专门为聊天对话场景设计的少样本(few-shot)提示模板,它继承自 FewShotPromptTemplate,但针对聊天消息的格式进行了优化。
特点:
- 自动将示例格式化为聊天消息( HumanMessage/ AIMessage 等)
- 输出结构化聊天消息( List[BaseMessage] )
- 保留对话轮次结构
举例1:基本结构
from langchain.prompts import ( FewShotChatMessagePromptTemplate, ChatPromptTemplate)# 示例消息格式examples = [ {"input": "1+1等于几?", "output": "1+1=等于2"}, {"input": "法国的首都是?", "output": "巴黎"}]# 定义示例的消息格式提示词模板msg_example_prompt = ChatPromptTemplate.from_messages([ ("human", "{input}"), ("ai", "{output}")])# 定义FewShotChatMessagePromptTemplate对象few_shot_prompt = FewShotChatMessagePromptTemplate( example_prompt=msg_example_prompt, examples=examples)# 输出格式化后的消息print(few_shot_prompt.format())
Human: 1+1等于几?AI: 1+1=等于2Human: 法国的首都是?AI: 巴黎
Example selectors(示例选择器)
前面FewShotPromptTemplate的特点是,无论输入什么问题,都会包含全部示例。在实际开发中,我们可以根据当前输入,使用示例选择器,从大量候选示例中选取最相关的示例子集。
- 使用的好处:避免盲目传递所有示例,减少 token 消耗的同时,还可以提升输出效果。
- 示例选择策略:语义相似选择、长度选择、最大边际相关示例选择等
语义相似选择:通过余弦相似度等度量方式评估语义相关性,选择与输入问题最相似的 k 个示例。长度选择:根据输入文本的长度,从候选示例中筛选出长度最匹配的示例。增强模型对文本结构的理解。比语义相似度计算更轻量,适合对响应速度要求高的场景。最大边际相关示例选择:优先选择与输入问题语义相似的示例;同时,通过惩罚机制避免返回同质化的内容
举例1
安装向量数据库
Chroma(通常简称 chromadb)的开源向量数据库(Vector Database)。
pip install chromadb
代码
# 导入相关包import osfrom langchain_community.vectorstores import Chromafrom langchain_core.example_selectors import SemanticSimilarityExampleSelectorimport dotenvfrom langchain_openai import OpenAIEmbeddingsdotenv.load_dotenv()# 定义嵌入模型embeddings_model = OpenAIEmbeddings( model=os.getenv("LLM_EMBEDINGS_MODEL"))# 定义示例组examples = [ { "question": "谁活得更久,穆罕默德·阿里还是艾伦·图灵?", "answer": """接下来还需要问什么问题吗?追问:穆罕默德·阿里去世时多大年纪?中间答案:穆罕默德·阿里去世时享年74岁。""", }, { "question": "craigslist的创始人是什么时候出生的?", "answer": """接下来还需要问什么问题吗?追问:谁是craigslist的创始人?中级答案:Craigslist是由克雷格·纽马克创立的。""", }, { "question": "谁是乔治·华盛顿的外祖父?", "answer": """接下来还需要问什么问题吗?追问:谁是乔治·华盛顿的母亲?中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿。""", }, { "question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?", "answer": """接下来还需要问什么问题吗?追问:《大白鲨》的导演是谁?中级答案:《大白鲨》的导演是史蒂文·斯皮尔伯格。""", },]# 定义示例选择器example_selector = SemanticSimilarityExampleSelector.from_examples( # 可供选择的示例列表 examples, # 用于生成嵌入的嵌入类,用于衡量语义相似性 embeddings_model, # 这是用于存储嵌入并进行相似性搜索的VectorStore类 Chroma, # 这是要生成的示例数量 k = 1)# 选择与输入最相似的示例question = "《大白鲨》的导演是?"selected_examples = example_selector.select_examples({"question": question})print(f"与输入最相似的示例:{selected_examples}")
与输入最相似的示例:[{'answer': '\n接下来还需要问什么问题吗?\n追问:《大白鲨》的导演是谁?\n中级答案:《大白鲨》的导演是史蒂文·斯皮尔伯格。\n', 'question': '《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?'}]
举例2:结合 FewShotPromptTemplate 使用
安装FAISS
pip install faiss-cpu
代码
import osimport dotenvfrom langchain_community.vectorstores import FAISSfrom langchain_core.example_selectors import SemanticSimilarityExampleSelectorfrom langchain_core.prompts import FewShotPromptTemplate, PromptTemplatefrom langchain_openai import OpenAIEmbeddingsdotenv.load_dotenv()# 定义示例提示词模板example_prompt = PromptTemplate.from_template( template="Input: {input}\nOutput: {output}")# 创建一个示例提示词模板examples = [ {"input": "高兴", "output": "悲伤"}, {"input": "喜欢", "output": "不喜欢"}, {"input": "爱", "output": "讨厌"}, {"input": "依恋", "output": "排斥"}, # 新增:情感类 {"input": "思念", "output": "遗忘"}, # 新增:情感类 {"input": "爱慕", "output": "憎恶"}, # 新增:情感类 {"input": "高", "output": "低"}, {"input": "好", "output": "坏"}, {"input": "精力充沛", "output": "懒惰"}, {"input": "成功", "output": "失败"}, {"input": "强", "output": "弱"},]# 定义嵌入模型embeddings_model = OpenAIEmbeddings( model=os.getenv("LLM_EMBEDINGS_MODEL"))# 创建语义相似性示例选择器example_selector = SemanticSimilarityExampleSelector.from_examples( examples, embeddings_model, FAISS, k=1)# 定义小样本提示词模板similar_prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix="给出每个词组的反义词", suffix="Input: {word}\nOutput:", input_variables=["word"])input_var = input("请输入一个词:")response = similar_prompt.invoke({"word": input_var})print(response.text)
从文档中加载Prompt
一方面,将想要设定prompt所支持的格式保存为JSON或者YAML格式文件。
另一方面,通过读取指定路径的格式化文件,获取相应的prompt。
目的与使用场景:
- 为了便于共享、存储和加强对prompt的版本控制。
- 当我们的prompt模板数据较大时,我们可以使用外部导入的方式进行管理和维护。
yaml格式提示词
asset下创建yaml文件:prompt.yaml
_type: "prompt"input_variables: ["name", "what"]template: "请给{name}讲一个关于{what}的故事"
代码:
from langchain_core.prompts import load_promptfrom dotenv import load_dotenvload_dotenv()prompt = load_prompt("asset/prompt.yml", encoding="utf-8")print(prompt.format(name="年轻人", what="恐怖"))
请给年轻人讲一个关于恐怖的故事
json格式提示词
asset下创建json文件:prompt.json
from langchain_core.prompts import load_promptfrom dotenv import load_dotenvload_dotenv()prompt = load_prompt("asset/prompt.json", encoding="utf-8")print(prompt.format(name="年轻人", what="恐怖"))
请给年轻人讲一个关于恐怖的故事
Model I/O之Output Parsers
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望model可以返回更直观、更格式化的内容,以确保应用能够顺利进行后续的逻辑处理。此时,LangChain提供的输出解析器就派上用场了
输出解析器的分类
| 输出解析器类名 | 核心功能描述 |
|---|---|
| StrOutputParser | 基础字符串解析器,直接将 LLM 输出作为字符串返回 |
| JsonOutputParser | JSON 格式解析器,确保 LLM 输出符合特定 JSON 对象格式并完成解析 |
| XMLOutputParser | XML 格式解析器,支持从 LLM 输出中提取符合 XML 规范的结构化结果 |
| CommaSeparatedListOutputParser | CSV 风格解析器,将 LLM 以逗号分隔的输出转换为列表形式返回 |
| DatetimeOutputParser | 日期时间解析器,专门用于将 LLM 输出解析为标准日期时间格式 |
| EnumOutputParser | 枚举解析器,将 LLM 输出匹配并解析为预定义的枚举值集合中的某一个 |
| StructuredOutputParser | 结构化数据解析器,将非结构化文本转换为预定义格式的结构化数据(如字典) |
| OutputFixingParser | 输出修复解析器,自动检测并修正格式错误的输出,确保转换为正确的结构化数据(如 JSON) |
| RetryOutputParser | 重试解析器,当主解析器(如 JSONOutputParser)解析失败时,调用 LLM 修正错误后重新解析 |
具体解析器的使用
字符串解析器StrOutputParser
StrOutputParser 简单地将任何输入转换为字符串。它是一个简单的解析器,从结果中提取content字段
举例:将一个对话模型的输出结果,解析为字符串输出
import osfrom dotenv import load_dotenvfrom langchain_core.messages import SystemMessage, HumanMessagefrom langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAIload_dotenv()chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))messages = [ SystemMessage(content="将一下内容从英文翻译成中文"), HumanMessage(content="I love programming.")]result = chat_model.invoke(messages)print(type(result))print(result)parser = StrOutputParser()# 使用parser处理model返回的结果response = parser.invoke(result)print(type(response))print(response)
JSON解析器JsonOutputParse
JsonOutputParser,即JSON输出解析器,是一种用于将大模型的自由文本输出转换为结构化JSON数据的工具。
适合场景:特别适用于需要严格结构化输出的场景,比如 API 调用、数据存储或下游任务处理。
实现方式
- 方式1:用户自己通过提示词指明返回Json格式
- 方式2:借助JsonOutputParser的 get_format_instructions() ,生成格式说明,指导模型输出JSON结构
举例1:
# 方式1result = chat_model.invoke(chat_prompt_template.format_messages( role="人工智能专家", question="人工智能用英文怎么说?问题用q表示,答案用a表示,返回一个JSON格式"))print(result)print(type(result))res = parser.invoke(result)print(res)# 方式2print("="*50,end="")print("方式2开始", end="")print("="*50)chain = chat_prompt_template | chat_model | parserres = chain.invoke({"role": "人工智能专家", "question": "人工智能用英文怎么说?问题用q表示,答案用a表示,返回一个JSON格式"})print(res)
F:\env\Python\anaconda3\python.exe "F:\Project\JetbrainsProjects\PycharmProject\LangChain-tutorial\chapter02-Model IO\JSON解析器JsonOutputParse-举例1.py" F:\software\code_tool\jetbrains\PyCharm Professional\plugins\python-ce\helpers\pycharm_display\datalore\display\supported_data_type.py:6: UserWarning: The NumPy module was reloaded (imported a second time). This can in some cases result in small but subtle issues and is discouraged. import numpycontent='```json\n{\n "q": "人工智能用英文怎么说?",\n "a": "Artificial Intelligence"\n}\n```' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 26, 'prompt_tokens': 43, 'total_tokens': 69, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 0, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': None}, 'model_name': 'Qwen/Qwen3-8B', 'system_fingerprint': '', 'finish_reason': 'stop', 'logprobs': None} id='run--62796ba3-40ec-429b-ba8e-e39e3ca431fa-0' usage_metadata={'input_tokens': 43, 'output_tokens': 26, 'total_tokens': 69, 'input_token_details': {}, 'output_token_details': {'reasoning': 0}}<class 'langchain_core.messages.ai.AIMessage'>{'q': '人工智能用英文怎么说?', 'a': 'Artificial Intelligence'}==================================================方式2开始=================================================={'q': '人工智能用英文怎么说?', 'a': 'Artificial Intelligence'}
XML解析器XMLOutputParser
XMLOutputParser,将模型的自由文本输出转换为可编程处理的 XML 数据。
如何实现:在PromptTemplate中指定 XML 格式要求,让模型返回<tag>content</tag>形式的数
据。
注意:
XMLOutputParser不会直接将模型的输出保持为原始XML字符串,而是会解析XML并转换成Python字典 (或类似结构化的数据)。目的是为了方便程序后续处理数据,而不是单纯保留XML格式。
举例1:不使用XMLOutputParser,通过大模型的能力,返回xml格式数据
import osfrom dotenv import load_dotenvfrom langchain_core.output_parsers import XMLOutputParserfrom langchain_openai import ChatOpenAIload_dotenv()chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))output_parser = XMLOutputParser()# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据format_instructions = output_parser.get_format_instructions()print(format_instructions)# 测试模型的xml解析效果actor_query = "生成汤姆·汉克斯的简短电影记录和信息等"output = chat_model.invoke(f"""{actor_query}请将影片附在<movie></movie>标签中""")print(type(output))print(output.content)
举例2:XMLOutputParser 的使用
import osfrom dotenv import load_dotenvfrom langchain_core.output_parsers import XMLOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_openai import ChatOpenAIload_dotenv()# 初始化语言模型chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))# 测试模型的xml解析效果actor_query="生成汤姆·汉克斯的简短电影记录,使用中文回复"# 定义XMLOutputParser对象parser = XMLOutputParser()# 定义提示词模板对象prompt_template = PromptTemplate.from_template("{query}\n{format_instructions}")prompt_template1 = prompt_template.partial(format_instructions=parser.get_format_instructions())response = chat_model.invoke(prompt_template1.format_prompt(query=actor_query))print(response.content)
<?xml version="1.0" encoding="UTF-8"?><actor_profile> <basic_info> <name_cn>汤姆·汉克斯</name_cn> <name_en>Tom Hanks</name_en> <birthdate>1956年7月9日</birthdate> <nationality>美国</nationality> <occupation>演员、导演、制片人</occupation> </basic_info> <summary> 汤姆·汉克斯是美国最著名、最受尊敬的演员之一。他的职业生涯跨越数十年,以其在喜剧和正剧中的多才多艺而闻名,并常常塑造出温暖、正直且深入人心的“普通人”英雄形象。 </summary> <filmography> <film> <title_cn>飞越未来</title_cn> <title_en>Big</title_en> <year>1988</year> </film> <film> <title_cn>费城故事</title_cn> <title_en>Philadelphia</title_en> <year>1993</year> </film> <film> <title_cn>阿甘正传</title_cn> <title_en>Forrest Gump</title_en> <year>1994</year> </film> <film> <title_cn>阿波罗13号</title_cn> <title_en>Apollo 13</title_en> <year>1995</year> </film> <film> <title_cn>拯救大兵瑞恩</title_cn> <title_en>Saving Private Ryan</title_en> <year>1998</year> </film> <film> <title_cn>荒岛余生</title_cn> <title_en>Cast Away</title_en> <year>2000</year> </film> <film> <title_cn>猫鼠游戏</title_cn> <title_en>Catch Me If You Can</title_en> <year>2002</year> </film> <film> <title_cn>幸福终点站</title_cn> <title_en>The Terminal</title_en> <year>2004</year> </film> <film> <title_cn>船长菲利普斯</title_cn> <title_en>Captain Phillips</title_en> <year>2013</year> </film> </filmography> <awards> <award> <description>他是历史上仅有的两位连续两年(1993、1994)获得奥斯卡最佳男主角奖的演员之一,获奖作品分别为《费城故事》和《阿甘正传》。</description> </award> </awards> <legacy> 因其真诚、朴实的形象和出色的演技,汤姆·汉克斯被誉为“美国的爸爸”,是美国文化的重要符号之一。 </legacy></actor_profile>
列表解析器CommaSeparatedListOutputParser
列表解析器:利用此解析器可以将模型的文本响应转换为一个用逗号分隔的列表(List[str]) 。
举例1:
from langchain_core.output_parsers import CommaSeparatedListOutputParseroutput_parser = CommaSeparatedListOutputParser()# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据format_instructions = output_parser.get_format_instructions()print(format_instructions)messages = "大象,猩猩,狮子"result = output_parser.parse(messages)print(result)print(type(result))
Your response should be a list of comma separated values, eg: `foo, bar, baz` or `foo,bar,baz`['大象', '猩猩', '狮子']<class 'list'>
举例2:
import osfrom dotenv import load_dotenvfrom langchain_core.output_parsers import CommaSeparatedListOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_openai import ChatOpenAIload_dotenv()chat_model = ChatOpenAI(model=os.getenv("LLM_MODEL"))# 创建解析器output_parser = CommaSeparatedListOutputParser()# 创建LangChain提示模板chat_prompt = PromptTemplate.from_template( "生成5个关于{text}的列表.\n\n{format_instructions}", partial_variables={"format_instructions": output_parser.get_format_instructions() })# 将提示和模型合并 调用chain = chat_prompt | chat_model | output_parserres = chain.invoke({"text": "电影"})print(res)print(type(res))
['IMDb Top 250高分电影', '奥斯卡历届最佳影片', '宫崎骏的动画电影', '烧脑悬疑片推荐', '让人泪崩的催泪电影']<class 'list'>
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献448条内容
已为社区贡献448条内容

所有评论(0)