小麦产量预测系统
系统采用前后端分离架构前端技术栈:Vue 3 + TypeScript(核心框架)、Ant Design Vue(UI 组件)、Tailwind CSS + DaisyUI(样式)、Vite(构建工具)、Pinia(状态管理)、Vue Router(路由)、Axios(请求)、ECharts(可视化)后端技术栈:Django 5.2.6(Web 框架)、DRF 3.14.0(API 开发)、Cha
在农业数字化转型背景下,小麦产量预测系统作为数据驱动农业的典型应用,不仅能为种植决策提供支撑,其技术实现方案也为计算机专业学生的毕设、实习项目提供了优质参考。
本文将围绕首页、数据浏览、模型训练、产量预测、数据导出五大核心模块,拆解每个模块背后的前端与后端技术栈支撑,无需涉及具体代码,聚焦 “功能 - 技术” 的对应逻辑与协同应用。
一、项目概述:技术栈全景图
系统采用前后端分离架构,前端负责五大模块的交互界面与数据可视化,后端处理业务逻辑、模型计算与数据存储,整体技术栈覆盖主流开发工具,为各模块实现提供支撑:
- 前端技术栈:Vue 3 + TypeScript(核心框架)、Ant Design Vue(UI 组件)、Tailwind CSS + DaisyUI(样式)、Vite(构建工具)、Pinia(状态管理)、Vue Router(路由)、Axios(请求)、ECharts(可视化)
- 后端技术栈:Django 5.2.6(Web 框架)、DRF 3.14.0(API 开发)、Channels 4.0.0(实时通信)、机器学习模型(预测核心)
- 数据与安全层:SQLite(数据库)、Redis(缓存)、JWT(认证)、RBAC(权限)
二、核心演示模块:技术栈拆解与实现逻辑
1. 首页模块:前端技术主导的交互入口
首页作为系统的 “门面”,需兼顾美观与加载效率,核心依赖前端技术栈的协同:
- 界面构建:基于 Vue 3 + TypeScript 搭建页面骨架,通过 Ant Design Vue 组件库快速实现导航栏、功能入口卡片、用户信息展示等 UI 元素,无需从零开发基础组件;
- 样式优化:结合 Tailwind CSS 的原子化类名与 DaisyUI 的农业场景适配样式,快速调配首页色彩、间距与响应式布局(如 PC / 平板端适配),降低样式开发成本;
- 性能保障:使用 Vite 作为构建工具,首页启动时间从传统 Webpack 的分钟级缩短至秒级,首次加载时通过 Tree-shaking 剔除冗余代码,提升加载速度;
- 状态与路由:通过 Pinia 管理首页的用户登录状态(如显示 “已登录 / 未登录” 状态),Vue Router 控制首页到其他模块的跳转,未登录用户通过路由守卫禁止进入核心功能页。
2. 数据浏览模块:前后端协同的数据可视化
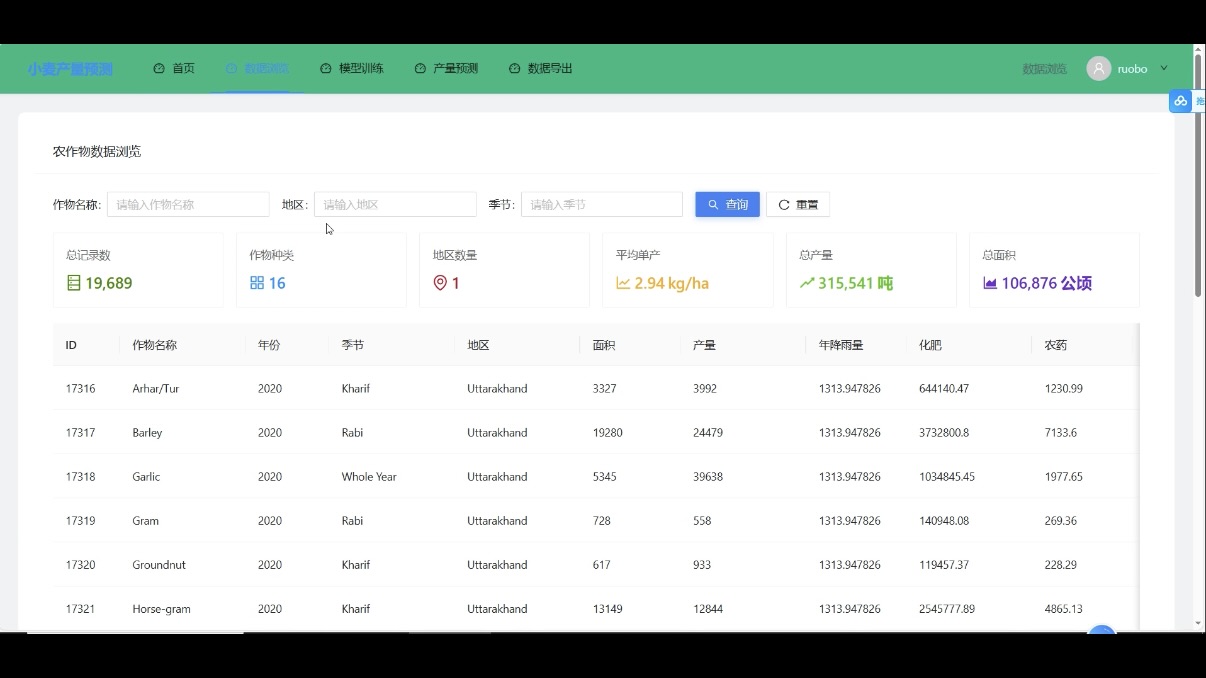
数据浏览模块需实现 “检测记录展示、统计分析、可视化呈现”,依赖前端可视化与后端数据接口的配合:
- 前端交互与可视化:
-
- 用 Ant Design Vue 的表格组件展示小麦检测记录(支持分页、筛选),用户可快速定位目标数据;
-
- 通过 ECharts 实现数据可视化,如产量趋势折线图、土壤肥力分布柱状图,hover 时显示详细数据(如某地块某季度产量),让数据规律更直观;
-
- 用 Pinia 管理数据浏览状态(如当前筛选条件、图表数据),切换筛选条件时无需重复请求后端,提升交互流畅性;
- 后端数据支撑:
-
- 基于 Django 5.2.6 + DRF 3.14.0 构建 RESTful API,提供 “检测记录列表查询”“统计数据聚合” 接口,前端通过 Axios 调用接口获取数据;
-
- 用 SQLite 存储检测记录的结构化数据(如地块 ID、检测时间、产量值),高频访问的统计数据(如年度总产量)通过 Redis 缓存,减少数据库查询压力;
-
- 通过 RBAC 权限控制,普通用户仅可浏览自己权限内的地块数据,管理员可查看所有数据。
- 通过 RBAC 权限控制,普通用户仅可浏览自己权限内的地块数据,管理员可查看所有数据。
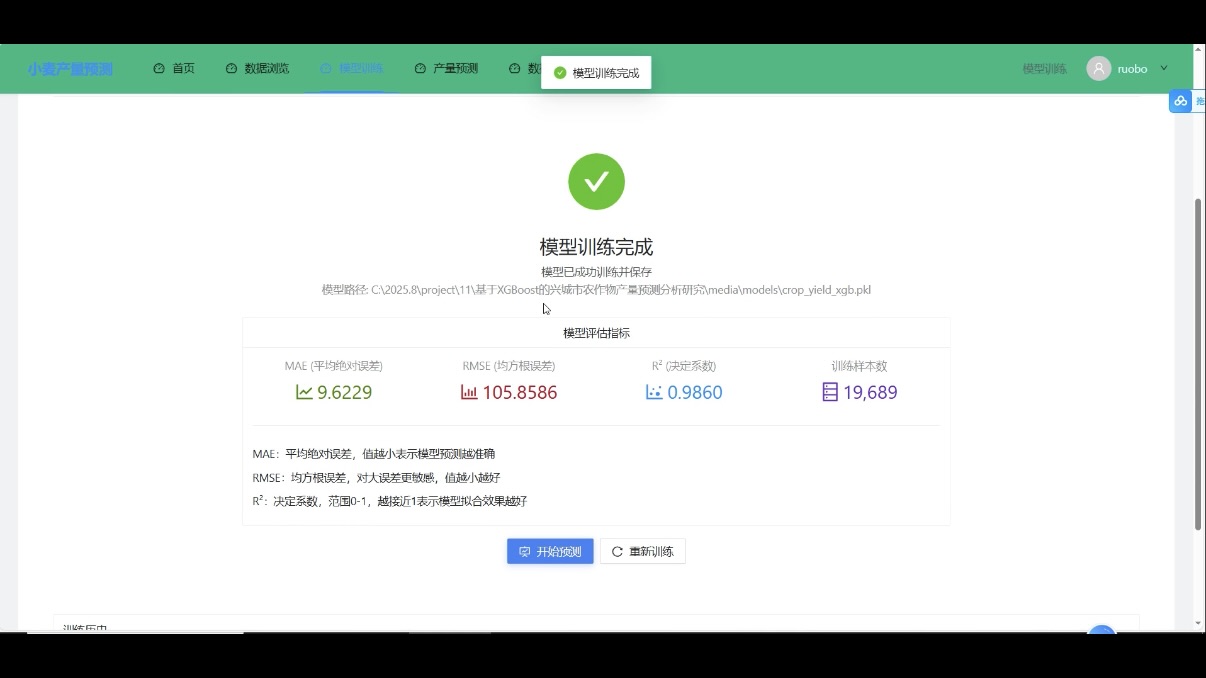
3. 模型训练模块:后端实时通信与计算核心
模型训练模块需实现 “训练参数设置、实时进度反馈、训练结果存储”,核心依赖后端技术栈的计算与通信能力:
- 前端交互:
-
- 用 Ant Design Vue 的表单组件收集训练参数(如历史数据时间段、模型迭代次数),提交按钮触发训练请求;
-
- 通过 Channels 集成的 WebSocket 与后端建立实时连接,接收训练进度(如 “已完成 30%/ 当前损失值 0.2”),并在页面实时展示;
- 后端核心逻辑:
-
- 以 Django 5.2.6 为基础,DRF 提供 “模型训练请求” 接口,接收前端传入的训练参数;
-
- 调用集成的机器学习模型(如随机森林、线性回归),基于 SQLite 中存储的历史产量、气候、土壤数据进行训练,训练中间参数(如每轮损失值)暂存至 Redis;
-
- 通过 Channels 实现 WebSocket 双向通信,训练进度更新时主动向前端推送数据,避免前端频繁轮询请求,提升实时性;
-
- 训练完成后,将模型文件与训练报告存储至 SQLite,供后续产量预测调用。
- 训练完成后,将模型文件与训练报告存储至 SQLite,供后续产量预测调用。
4. 产量预测模块:输入驱动的前后端联动
产量预测模块是核心功能,需实现 “参数输入、预测计算、结果展示”,突出 “输入信息即可预测” 的便捷性:
- 前端输入与结果展示:
-
- 用 Ant Design Vue 的表单组件设计预测参数输入界面(如光照时长、水分含量、土壤肥力等级),表单验证确保输入参数合法(如光照时长不小于 0);
-
- 提交参数后,通过 Axios 调用后端预测接口,等待预测结果时显示加载状态,结果返回后用卡片组件展示预测产量、置信度等信息;
- 后端预测逻辑:
-
- DRF 提供 “产量预测” 接口,接收前端传入的参数并进行格式校验;
-
- 加载模型训练模块生成的已训练模型,将输入参数代入模型计算预测产量;
-
- 预测结果通过接口返回前端,同时将 “输入参数 + 预测结果” 存储至 SQLite,便于后续追溯与数据导出;
-
- 用 JWT 验证请求合法性,确保只有已登录用户可调用预测接口,避免非法请求。
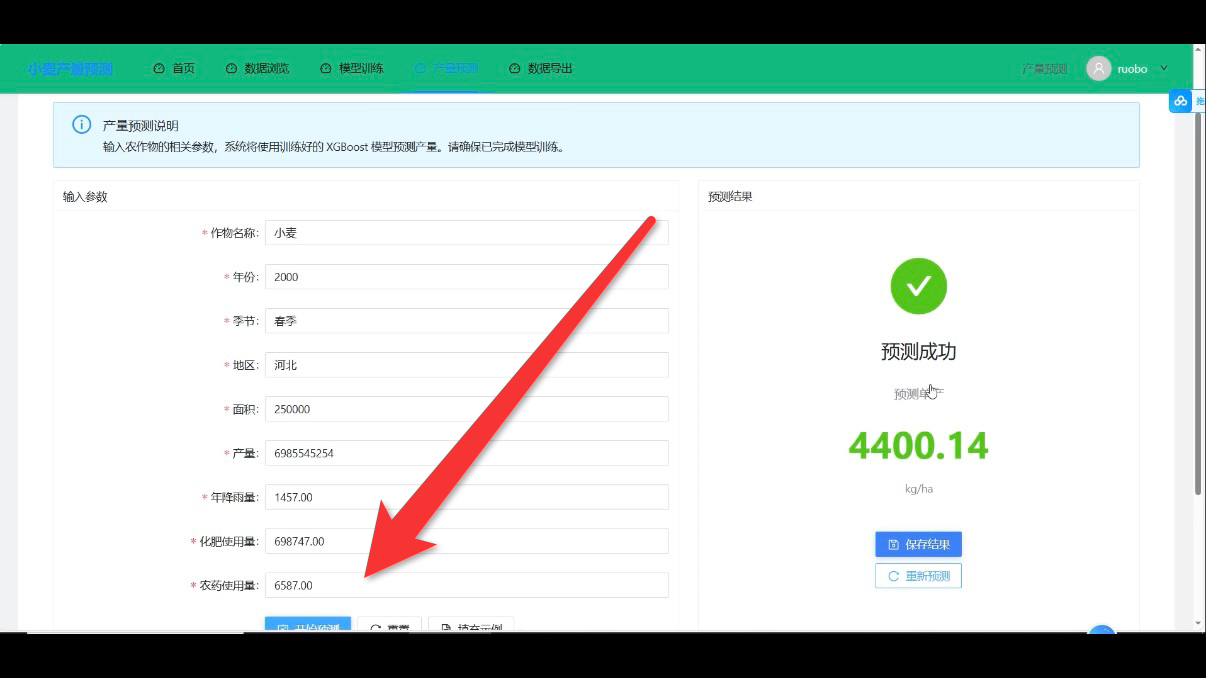
- 用 JWT 验证请求合法性,确保只有已登录用户可调用预测接口,避免非法请求。
5. 数据导出模块:前后端协同的文件生成
数据导出模块需实现 “选中数据 / 预测结果导出为 Excel”,依赖后端文件处理与前端下载逻辑:
- 前端操作与下载:
-
- 在数据浏览 / 产量预测页面添加 “导出” 按钮,用户选中目标数据(如某时间段检测记录、某批次预测结果)后触发导出请求;
-
- Axios 调用后端导出接口,接收后端返回的 Excel 文件流,通过浏览器 API 实现自动下载(无需跳转新页面);
- 后端文件生成与数据处理:
-
- DRF 接口接收导出请求与筛选条件,从 SQLite 中查询目标数据,通过 Python 的 Excel 处理库(如 openpyxl)生成 Excel 文件;
-
- 导出完成后,将文件流通过接口返回前端,同时记录导出日志(如导出用户、导出时间、数据量)至 SQLite,便于系统管理;
-
- 大文件导出时通过 Redis 记录导出进度,避免前端长时间等待无反馈。
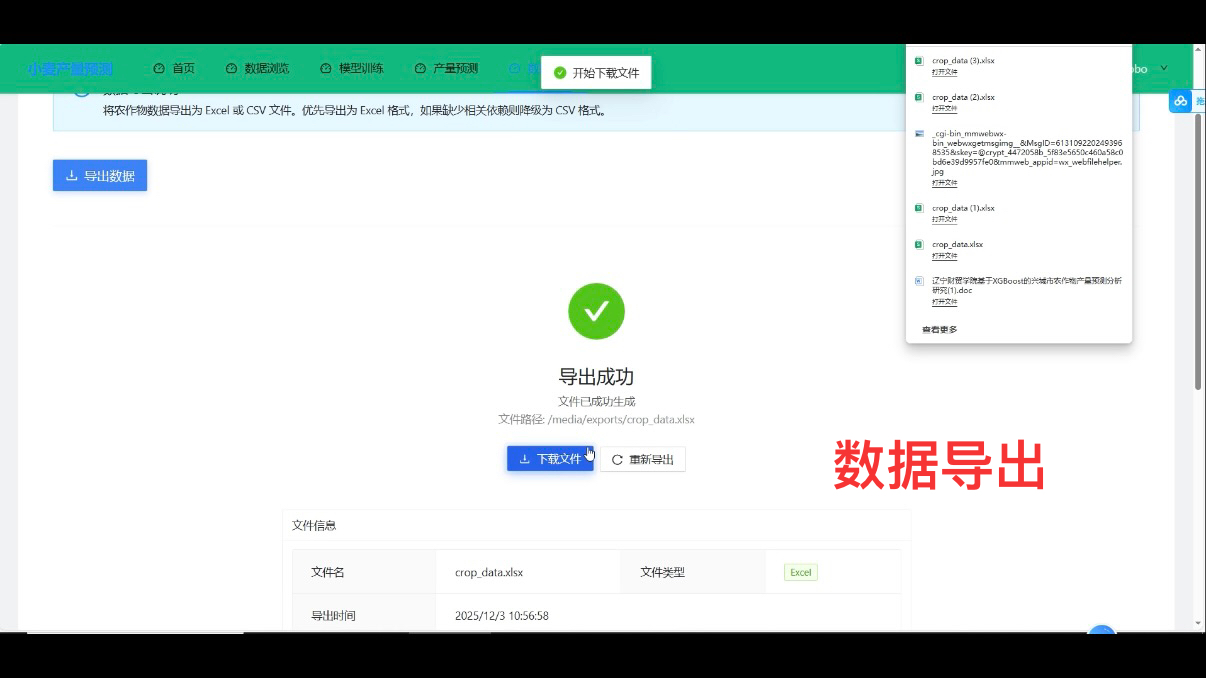
- 大文件导出时通过 Redis 记录导出进度,避免前端长时间等待无反馈。
三、架构设计:支撑五大模块的底层逻辑
五大模块的稳定运行,依赖 “模块化设计” 与 “前后端分离” 的架构支撑:
- 模块化设计:
-
- 前端按模块拆分代码(如home(首页)、data-view(数据浏览)、model-train(模型训练)等文件夹),每个模块独立封装组件、状态与路由,新增功能(如 “历史预测记录”)时仅需开发对应模块,无需修改现有代码;
-
- 后端按业务拆分为 “user”(用户)、“data”(数据)、“model”(模型)、“export”(导出)等 APP,每个 APP 独立包含模型、视图与序列化器,模块间通过接口通信,降低耦合度;
- 前后端分离优势:
-
- 前端与后端通过 RESTful API 交互,可独立开发(如前端开发首页时,后端同步开发数据接口),并行提升效率;
-
- 部署时前端可部署至 CDN(如阿里云 CDN),提升静态资源加载速度;后端可部署至云服务器,支持水平扩展(如模型训练请求增多时增加服务器节点);
-
- 技术栈可灵活替换(如前端后续替换为 React,后端替换为 Spring Boot),只需保持 API 格式一致,降低重构成本。
四、总结:模块与技术栈的匹配思路
小麦产量预测系统的五大演示模块,其技术选型始终围绕 “功能需求→技术匹配→效率优化” 展开:
- 功能驱动技术:首页需快速加载→选 Vite;数据浏览需可视化→选 ECharts;模型训练需实时反馈→选 Channels;每个模块的技术栈均为 “解决该模块核心痛点” 服务;
- 前后端协同:前端负责 “用户看得见的交互”(如输入、展示、导航),后端负责 “用户看不见的计算与存储”(如模型训练、数据查询),通过 API 与 WebSocket 实现高效联动;
- 可复用性:该模块 - 技术的匹配逻辑可迁移至其他项目(如工业数据监测的 “数据浏览→可视化”、环境预测的 “模型训练→实时反馈”),为计算机专业学生提供 “功能落地→技术选型” 的参考模板。
对于毕设或实习项目而言,这种 “先明确核心功能模块,再针对性选择技术栈” 的思路,能避免 “为用技术而用技术” 的误区,让项目既具备技术深度,又能解决实际需求。
赫兹威客官方交流群
赫兹威客官方交流群
赫兹威客官方交流群
https://qm.qq.com/q/ToiE4c056U![]() https://qm.qq.com/q/ToiE4c056U
https://qm.qq.com/q/ToiE4c056U

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)