大模型基础理论-BPE/DeepNorm/FlashAttention/GQA/RoPE
大模型基础理论介绍:1.BPE分词2.DeepNorm3.FlashAttention4.GQA5.RoPE
这个系列讲述大模型相关的一些基础算法,首先要对大模型去魅,它并不是一种横空出世的新结构,而是在基于过往Transformer模型结构之上,结合大规模预训练预料+自监督/强化学习对齐人类输出偏好的一种模型,与以往我们使用的Faster RNN、GRU等深度学习模型没有本质上的区别。
在阅读之前先了解一下我们输入给大模型的一句话,比如“今天天气真好啊”,是如何被大模型处理的。
1)对于“今天天气真好啊”进行分词,分词会将一句话分解为具有最小语义单元的序列,“今天天气真好啊”可能被分割为“[今天,天气,真好啊]”,序列中的每个元素,我们称之为一个token,大多数人只关注大模型结构本身,其实分词才是整个大模型处理的开始,分词结果的好坏会直接影响大模型处理能力的上限,从直观上来讲,中文分词的规则就肯定不同于英文分词,如何让分词算法能够尽可能保证分割出来的每个序列元素都包含确定的语义?如何解决没见过词语的分词识别?这些都是一个分词算法要考虑的事情,我们将某种分词算法在某个语料上得到的具体分词结果叫词表,对于大模型要处理的语言,比如中文、英文等,都会预先通过分词算法在训练语料上建立一个词表,这样每个词语会对应一个唯一词表ID,构建完词表后,对于输入的一句话就可以使用最长贪心匹配进行分词,假设根据某种分词算法预先构建的词表是:
|
词表ID |
词语 |
|
0 |
我 |
|
1 |
今天 |
|
2 |
天气 |
|
3 |
真好啊 |
对于输入的“今天天气真好啊”,采取最长贪心匹配,查找最长的、存在于词表中的词语,作为分词结果,流程如下:
“今天天气真好啊”是否在词表中->否
“今天天气真好”是否在词表中->否
“今天天气真”是否在词表中->否
“今天天气”是否在词表中->否
“今天天”是否在词表中->否
“今天”是否在词表中->是,切取出“今天”,产生一个分词结果
对于剩下的“天气真好啊”继续上面的流程,最终得到分词结果:
[今天、天气、真好啊]
敏锐的人一定会问:
① 为什么要从整个句子开始分割,而不从第一个字开始
② 如此遍历非常耗时,有没有更快的分词流程
这些问题会放在后续“大模型面试常见问题”中进行说明
2)“今天天气真好啊”已经被分词为“[今天,天气,真好啊]”,查找对应的词表ID,“今天天气真好啊”对应[1,2,3]这个词表ID向量
3)将[1,2,3]词表向量输入到大模型嵌入层(准确说是查找大模型嵌入层),得到词表向量对应的嵌入矩阵表示W,W是3行d列的一个矩阵,d是词嵌入向量的维度,是人工预先设置的,一般为4096、512等,嵌入层的意义是将词语从词表向量空间映射到统一的语义空间中,便于大模型进行接下来的处理。嵌入层具体的数值是随着大模型训练而得到的,初始化为随机值。一定要注意嵌入层的大小是<词表大小,词嵌入向量长度>,嵌入层中的参数训练完之后,每一行就是词表ID对应的词嵌入向量,所以输入[1,2,3]是获取第1行、2行、3行的向量,组合起来形成它对应的嵌入矩阵表示,是一种基于查找的映射,而不是像其它模型层一样是通过矩阵乘法得到的
4)现在“今天天气真好啊”->[今天,天气,真好啊]->[1,2,3]->W(3行d列词嵌入矩阵),大模型会开始利用自己的Transformer结构对W进行特征提取,最终也会输出一个3行d列的矩阵H,只不过H现在每一行表示对应位置词语的上下文特征提取信息,取出H的最后一行h,将h反向投影到词表大小维度(一般这个反向投影矩阵就是嵌入层矩阵的转置),反向投影结果中,每个位置就是大模型预测出来的“今天天气真好啊”这句话下一个词语的概率,找概率最大位置所对应的词表中的词语,就是大模型对于这句话的输出(这种输出方法叫Greedy Search,为了避免大模型的复读机问题,会使用Beam Search、Top K等,这个后续再说),将大模型的输出和“今天天气真好啊”结合,再输入到大模型中,重复1)~4)过程循环,直到大模型输出结束标志(人工预先在训练时候规定的,比如<EOS>等),大模型对于“今天天气真好啊”的回答完毕。
那么结合以上流程就有几个关键性的问题:
① 如何设计分词算法,使得分词效果更好、更准
② 如何设计大模型的Transformer架构,让它特征提取能力更强,如何训练大模型,让它更准
③ 如何让大模型的输出更加符合我们人类的预期。比如两个正常人类对话。“今天天气真好啊”的回应一般为“是啊,比昨天暖和”、“对啊,要不我们出去走走”,而肯定不会是“你去死吧”、“跟我有关系吗”等
一 BPE分词
BPE分词算法可以说是大模型的标配了,现有大模型分词都是在BPE分词思想的基础上进行改进的,原论文《Neural Machine Translation of Rare Words with Subword Units》中的算法描述如下:

BPE解决未登录词(分词算法在语料上进行分词时没见到过的词语)问题效果很好,会提升大模型对稀有词和新词的泛化能力,其核心思想是:通过迭代合并语料中最频繁出现的相邻符号对,逐步地构建一个固定大小的子词词典。BPE被广泛应用于GPT系列等主流大语言模型中。BPE的词典构建过程是一个自底向上、贪心迭代合并的过程。以下是详细步骤:
步骤1:预处理语料-将每个单词按字符拆分,并在词尾添加特殊结束符(如<w>),以保留词语的边界信息。
示例:
“low” → l o w<w>
“lower” → l o w e r<w>
步骤2:初始化基础词典-词典初始化为包含所有语料库中出现的单个字符(包括预先设置的特殊字符,如步骤1中设置的<w>)。
步骤3:统计所有相邻字符对的出现频率,迭代合并最高频出现的字符对,重复操作,直到词典达到预设大小(如 30,000):
示例:
找出当前语料中频率最高的相邻符号对(如 'o' + 'w')。
将该符号对合并为一个新子词单元(如 'ow')。
在整个语料中用新单元‘ow’替换所有‘ o w ’。
更新词典和符号对频率统计。
步骤 4:生成最终词典与分词规则-最终词典包含原始字符 + 所有合并生成的子词。
二 DeepNorm
我们知道深度学习如果模型层数更多,一般效果会更好,ResNet解决了如何训练更深卷积神经网络的问题,DeepNorm要解决的问题是如何训练更深的Transformer。
那么首先要问的问题就是:究竟是什么阻碍了训练更深层的Transformer?是像ResNet发现的那样,梯度更新的问题阻碍了训练更深层Transformer吗?
DeepNorm作者通过实验发现并不是梯度爆炸的问题,而是模型更新过大阻碍了构建更深层的Transformer。
在Transformer模型结构中,存在两种层归一化(Layer Normalization, LN)方式:Pre-LN,Post-LN。
什么是LN

Pre-LN和Post-LN的区别

Post-LN计算公式为:

先对输入x进行注意力提取(Attention)/前馈神经网络变换(FFN),然后和自身进行残差连接,最后进行LN,最初Transforer使用的就是这种方式。
而Pre-LN计算公式为:
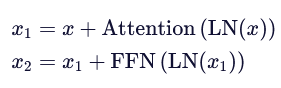
先对输入进行LN,然后再进行注意力提取、前馈神经网络变换、残差连接操作。
Pre-LN因为先对输入进行LN,相比于Post-LN训练会更稳定,而Post-LN是在获取到所有信息之后再进行LN,大部分信息被保留,相比于Pre-LN性能更高。
DeepNorm通过构建“模型更新幅度”估计的计算方法,分析了不同Transformer结构模型更新幅度的上界,这样就可以通过调整相应参数,控制Transformer的更新幅度:



基于以上分析提出了一种新的LN方式-DeepNorm

DeepNorm利用α放大残差连接输入、β缩小Tranformer层的输出,达到减小模型更新幅度的效果,从而可以训练更深的Transformer。
三 FlashAttention
DeepNorm解决的是训练更深的Transformer,FlashAttention解决的是如何让Transformer的输入更长,也就是处理更长的输入序列。
那么还是一样的问个问题,为什么Transformer无法处理过长的输入序列?
在标准的Transformer中,注意力计算的复杂度和输入序列的平方成正比


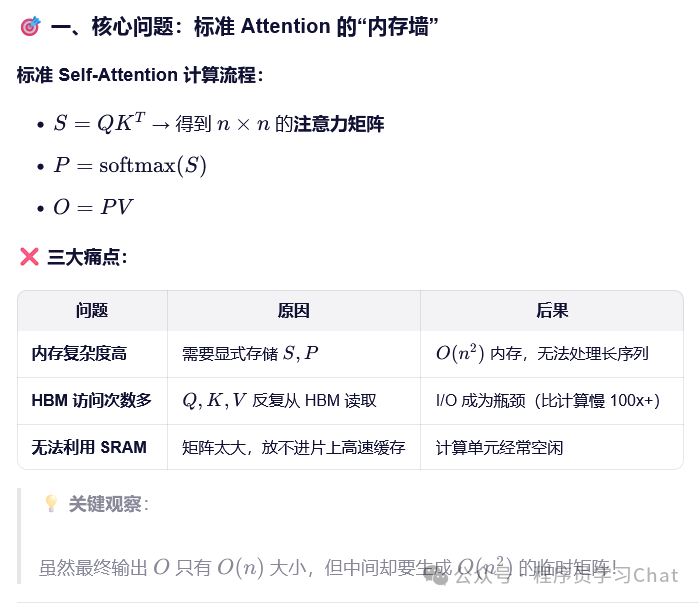

FlashAttention将注意力计算进行分块,利用GPU高速片内缓存(SRAM)进行每一分块注意力的计算,最后进行整体汇总,得到最终的结果,避免对GPU显存(HBM)的读写,加速计算时间。但是分块计算注意力有个障碍,注意力权重SoftMax操作需要看到完整QKT的一整行才能得到最终结果,但是现在对Q、K分块计算后,看到的只是一整行中的一部分,得到的SoftMax结果不准,所以论文中提出了一种适配分块注意力计算的增量式SoftMax计算方法
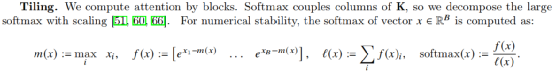

简单解释一下上面的增量SoftMax计算过程:


可能乍看的时候会看不懂,但是一定要强迫自己理解,因为增量SoftMax就是理解FlashAttention分块计算的核心,理解增量SoftMax的关键点是:

这是高中数学指数函数性质的内容,但却是理解FlashAttention的核心。
FlashAttention整体流程如下:

看着很复杂,但整体分为三部分:
1)将Q、K、V沿着行的方向分割为指定的块数,这个步骤体现的是分块
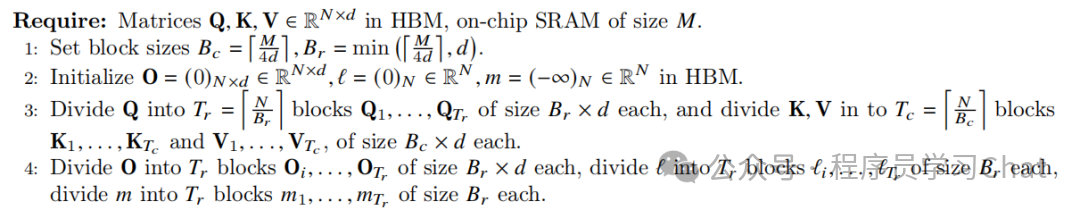
2)计算每块的注意力结果,增量更新注意力权重SoftMax,这个步骤是上面所说的核心
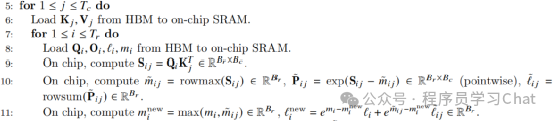
3)更新注意力输出结果,更新增量SoftMax中需要维护的全局最大值和整体归一化分母
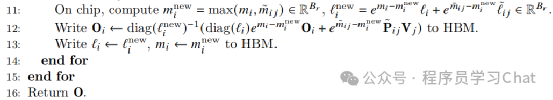
对于步骤3)的理解要注意diag()表示对角阵,对角阵和一个矩阵进行乘法,相当于矩阵每一行除以对角阵对应行的对角元素,可以自己手动推导一下。
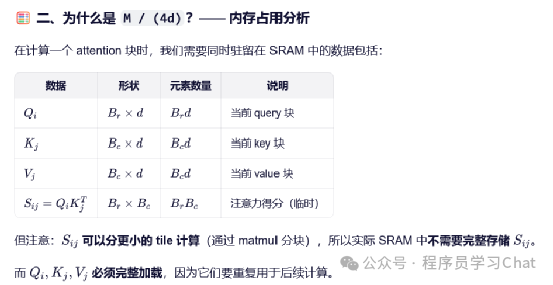
那么FlashAttention中的分块大小是如何计算出来的呢?在论文中



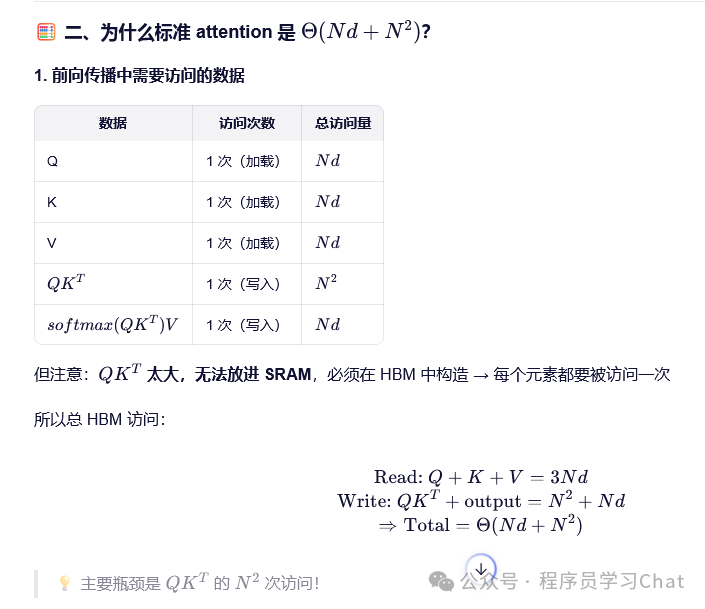
FlashAttention相比于普通Attention的访问显存效率对比如下:



四 GQA
FlashAttention从GPU显存、片内缓存高效利用的角度实现了注意力机制的高效计算,而GQA则从注意力计算方式的角度,重新思考注意力机制。

标准的多头注意力(MHA)无论是训练还是推理都非常吃显存,改进的多查询注意力(MQA)虽然不吃显存,但是效果较差

论文中对MHA、MQA、GQA的对比如下图所示
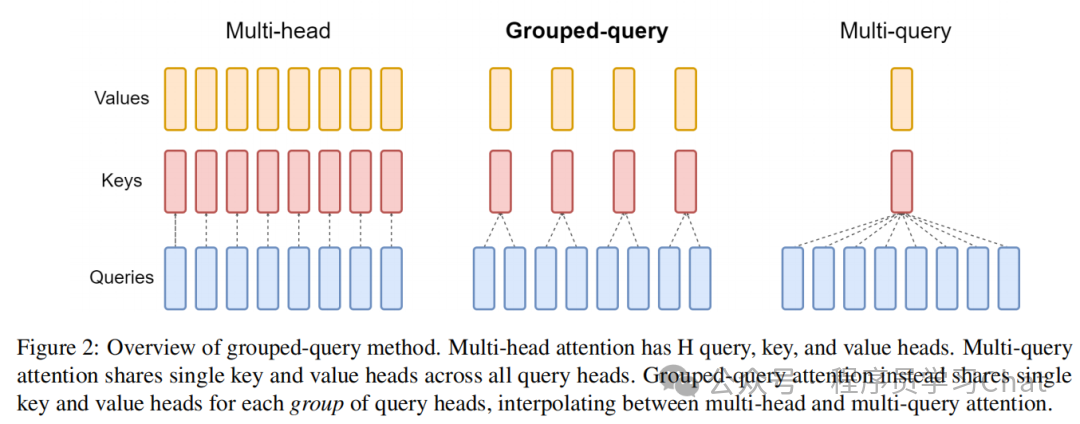
简单理解就是将传统多头注意力中的Q进行分组,每组共用一个K、V,这个共用的K、V是原对应的K、V求均值而得到的
五 RoPE
RoPE是一种位置编码策略,大模型中的位置编码(Positional Encoding) 是 Transformer 架构的核心组件之一,用于向模型注入 输入token 的顺序信息(因为原始 Attention 机制本身是置换不变的)。随着大模型向超长上下文(如 128K、1M tokens)演进,位置编码的设计成为了影响模型性能的关键因素。



RoPE的想法是在注意力内积计算过程中直接引入序列的相对位置关系,而不是通过人为添加到序列的信息强行进行规定,论文原意如下




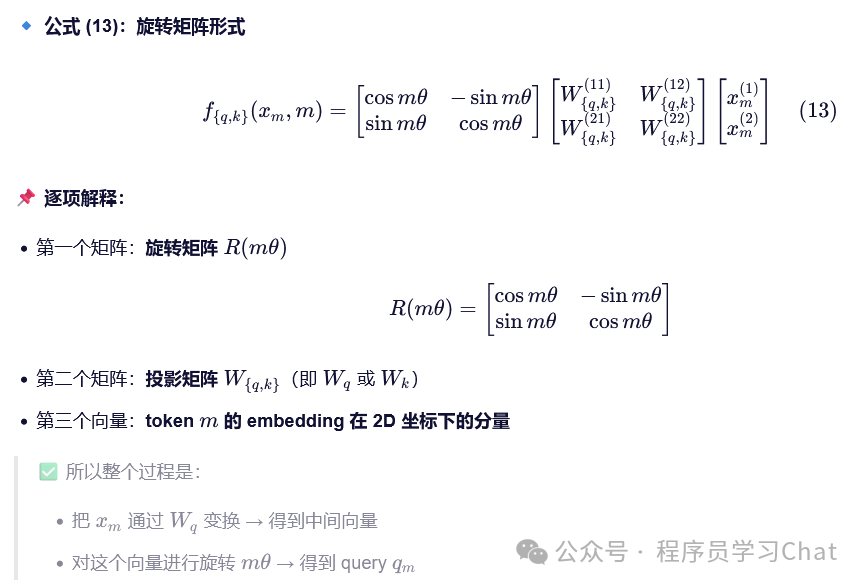


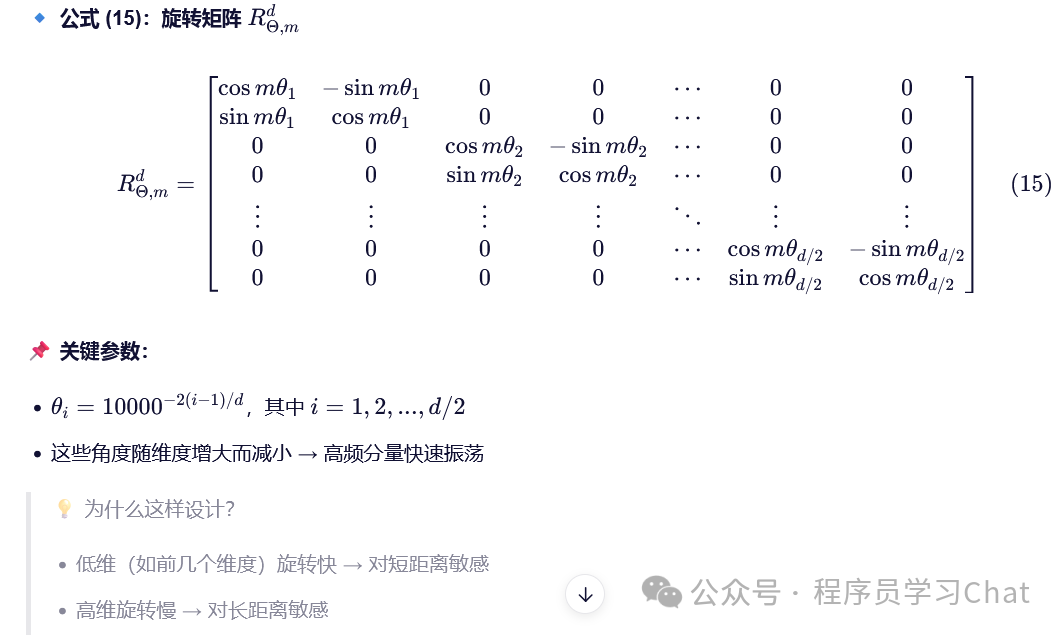

在具体的工程实现中,注意到旋转矩阵是稀疏的,所以序列旋转过程可以简化

RoPE同样也是大模型标配的位置编码方式。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 33
33 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)