MyMind 思维导图 – Beta 阶段项目日报(Day 3)
当前关键词提取依赖 AI 理解,可能存在提取不准确的情况,需要持续优化 Prompt 和验证机制。:通过精心设计的 Prompt,实现从无结构文本到结构化思维导图的自动转换,支持多层级节点组织。:通过 keywords 字段实现思维导图节点与原文的精确对应,为后续双向同步奠定基础。:大文件处理时,AI 解析可能耗时较长,后续需要优化提示词长度和实现流式响应。:新旧数据格式并存,需要持续维护兼容性处
MyMind 思维导图 – Beta 阶段项目日报(Day 3)
- 日期:2025-12-05
- 阶段:Beta Phase(Day 3)
- 项目:MyMind 多维思维导图
一、今日完成
1. M1 模块:智能结构解析核心功能实现
-
✅ DeepSeek API 集成完成
- 完成 DeepSeek API 的正式接入,实现后端统一代理调用
- 支持 OpenAI API 作为备选方案,提升系统可用性
- 实现 API 调用异常处理和降级策略
-
✅ 文本结构解析功能实现
- 完成多格式文档解析(PDF、DOCX、TXT)
- 实现基于 LLM 的智能结构提取,支持中英文双语输出
- 优化 Prompt 设计,确保生成结构化的思维导图 JSON 数据
- 实现 JSON 解析容错机制,处理 AI 返回格式异常情况
-
✅ 关键词提取与关联
- 实现从原文中提取关键词(keywords)字段
- 确保关键词与原文精确对应,支持后续高亮定位
- 完成关键词数据结构的标准化设计
2. M2 模块:双向关联与交互基础实现
-
✅ 前端核心组件开发
- 完成 MindMap 组件,实现美观的思维导图可视化
- 完成 DocumentView 组件,支持 PDF 和文本文件展示
- 实现中英文语言切换功能
- 完成文件上传组件(FileUpload)和主应用框架(App.jsx)
-
✅ 节点点击交互功能
- 实现思维导图节点点击事件处理
- 完成关键词传递机制,支持从节点到文档的关联
- 实现文档关键词高亮显示功能(文本文件)
-
✅ UI/UX 优化
- 采用现代化渐变配色方案,提升视觉体验
- 实现响应式布局,支持左右分栏显示
- 添加加载状态和错误提示,提升用户体验
3. M3 模块:性能与稳定性初步优化
-
✅ 后端稳定性提升
- 实现文件上传和存储机制(UUID 命名)
- 完成 CORS 跨域配置,支持局域网访问
- 添加异常处理和错误日志记录
-
✅ 前端性能优化
- 使用 React Hooks 优化组件渲染
- 实现数据格式兼容处理,支持新旧格式自动转换
- 完成 PDF 查看器集成(react-pdf)
4. 项目基础设施
-
✅ 开发环境完善
- 完成前后端分离架构搭建
- 配置 Vite + React 开发环境
- 完成 FastAPI 后端服务配置
- 实现启动脚本(start.sh、start.bat)
-
✅ 部署方案准备
- 完成 ngrok 和 Cloudflare Tunnel 公网访问方案
- 编写相关部署文档和使用说明
二、技术亮点
-
智能解析能力:通过精心设计的 Prompt,实现从无结构文本到结构化思维导图的自动转换,支持多层级节点组织。
-
双语支持:思维导图同时生成中英文版本,用户可自由切换,满足国际化需求。
-
精确关联:通过 keywords 字段实现思维导图节点与原文的精确对应,为后续双向同步奠定基础。
-
容错设计:完善的异常处理机制,包括 JSON 解析失败、API 调用异常等场景的降级方案。
三、遇到的问题与解决方案
问题 1:AI 返回的 JSON 格式不稳定
- 现象:DeepSeek API 有时返回包含 markdown 代码块的 JSON,导致解析失败
- 解决:实现多层 JSON 提取逻辑,支持从 markdown 代码块中提取、正则匹配提取等多种方式,并添加修复机制
问题 2:关键词高亮匹配不准确
- 现象:部分关键词在原文中无法正确高亮
- 解决:优化正则匹配算法,实现更宽松的匹配策略,支持部分匹配和大小写不敏感匹配
问题 3:PDF 文件显示问题
- 现象:PDF 文件需要特殊处理才能在前端显示
- 解决:集成 react-pdf 库,实现 PDF 文件的在线预览功能
四、风险与注意点
-
API 依赖风险:当前依赖外部 LLM 服务(DeepSeek/OpenAI),需要关注服务稳定性和成本控制。后续需考虑实现规则/启发式 fallback 机制。
-
数据格式兼容性:新旧数据格式并存,需要持续维护兼容性处理逻辑,避免影响用户体验。
-
性能瓶颈:大文件处理时,AI 解析可能耗时较长,后续需要优化提示词长度和实现流式响应。
-
关键词提取准确性:当前关键词提取依赖 AI 理解,可能存在提取不准确的情况,需要持续优化 Prompt 和验证机制。
五、燃尽图
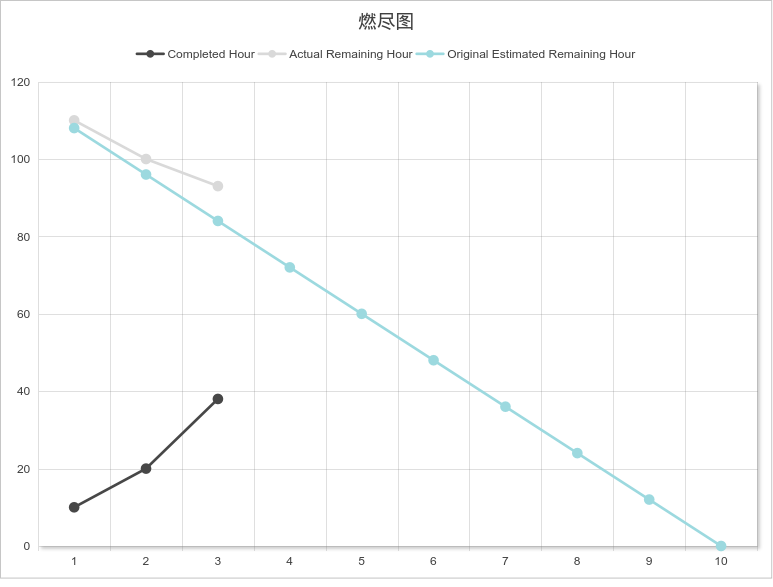
六、明日计划(Day 4)
-
M1 模块优化
- 完善文本结构特征库,增加对更多文档格式的支持
- 优化 Prompt 设计,提升解析准确性和稳定性
- 实现解析结果的缓存机制,减少重复 API 调用
-
M2 模块深化
- 完善 PDF 文件的关键词高亮功能
- 实现思维导图节点的编辑功能(初步)
- 优化节点点击交互体验,增加视觉反馈
-
M3 模块持续优化
- 添加请求超时处理和重试机制
- 实现文件大小限制和格式验证
- 优化错误提示信息,提升用户友好性
-
测试与验证
- 使用真实文档进行端到端测试
- 收集解析结果样例,分析准确性和改进点
- 编写单元测试和集成测试用例
七、工作量统计
- 今日投入工时:约 8 小时
- 代码提交:完成前后端核心功能模块
- 文档更新:更新 README 和部署文档
八、团队协作
-
模块分工:
- M1(智能结构解析):任少杰 + 彭怀玉
- M2(双向关联与交互):李荣基
- M3(性能与稳定性):任少杰
- M4(项目管理与文档):彭怀玉
-
今日协作:各模块并行开发,已完成核心功能对接和联调测试。
注:本文档为 Beta 阶段第 3 天工作日报,记录了项目核心功能的实现进展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)