代码知识库平台的构建:如何解构可视化代码并快速上手?
一些小总结,关于如何找代码+如何读懂代码,在AI时代基本都有了一些自动化的解决方案,对于cs+x的AI4S科研人员来说,是真正赶上了一个好时代
承接我的上一篇博客:LibInspector—为小白智能解析、阅读(几乎所有)Python工具库
以及参考我古早的几篇博客:
背景
如何构建一个基于AI的代码知识库平台,能够自动解析Git代码仓库,生成结构化的代码文档和项目见解,适用于新开发人员上手和技术文档标准化?
可以说,这个需求和(如何找到代码)是同等重要甚至是更加重要,
在很多交叉学科领域,比如说近年来的AI4S领域,
找代码是step1,找到之后完全读懂代码是step2,前者可以说是劳动密集/经验使然,但是后者我们(或者说现在这个AI时代)完全能够做到自动化!
那么试问,现在阻挡CS+X交叉领域的科研人员的还有什么壁垒呢?没有!至少客观上的壁垒基本上已经可以说是几乎完全没有了!剩下的就是你主观上的愿不愿意学罢了!
问题如标题所见(开源仓库/代码的可视化与快速上手),在开源社区和商业领域,确实存在几类工具试图解决这个问题,但它们的侧重点各有不同。在这里,我粗略将它们分为三类:传统静态分析可视化工具、AI 驱动的代码解释器(类似 DeepWiki),以及文档生成工具。
一,AI驱动的“代码库对话/百科”工具(最接近DeepWiki的概念)
这一类是最近几年随着LLM(GPT,Claude,Gemini等)爆发而出现,核心逻辑是将整个仓库Embedding化,然后允许用户提问或自动生成文档。
1,DeepWiki
这个就不用说了,最近一年左右最火以及最出圈的一个工具,我之前也写了几篇博客讲过这个;
官方网站链接,参考:
此外,开源社区还有一个给力的复现:
https://github.com/AsyncFuncAI/deepwiki-open


该开源开发大佬,还有几个类似韵味的仓库:
其实这些都是LLM驱动的,实际用法:像什么和文献对话、和仓库对话,大家这几年用LLM都非常熟悉,基本生态形式没有变过。
使用方式很简单,就是简单地输入repo的地址,就可以生成文档分析+交互与文档进行对话分析。
我这里随便抓取了一个仓库为例,比较热门的仓库都会index收集到DeepWiki中,比较小众的仓库则需要自己index,需要自己的邮箱+大概2~10分钟左右就可以index好。
顺带一提以防有人不知道Github仓库把域名里的 com 改成 pm 就可以直接跳转到DeepWiki对该仓库生成的文档
一般已经index好的仓库都会归档记录,再下一次就不需要另外index了,就可以直接在官方数据库中查询了。
如果要下载index好的仓库wiki,建议搭配插件使用,比如说我常用的一个wiki转换为markdown文件的插件:
https://github.com/zxmfke/deepwiki-md-chrome-extension
转换成功之后,就可以将这个wiki的页面保存为markdown格式下载下来,
我以自己转换的一个例子,效果如下:
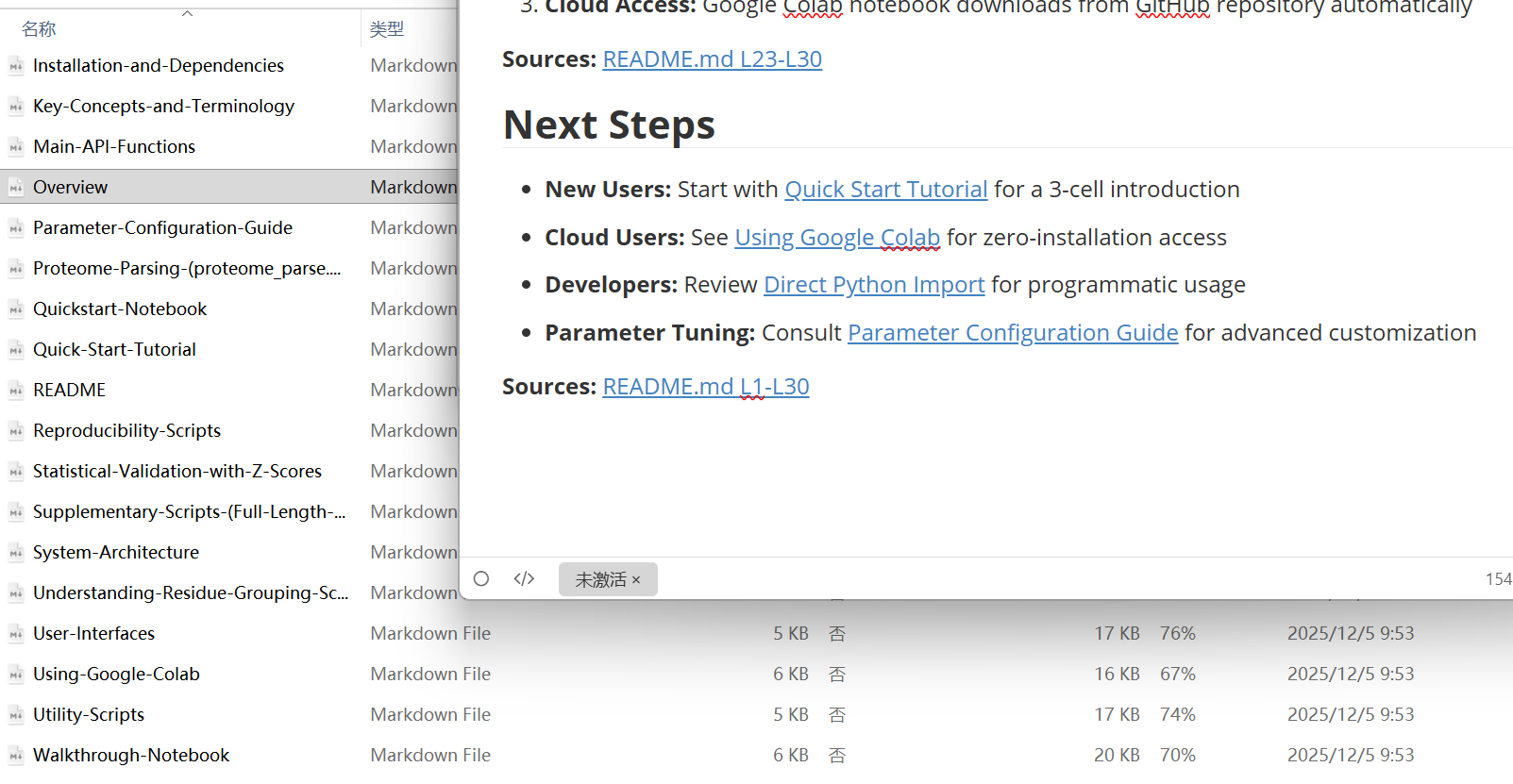
基本上就是每一页page都转换为md文件,格式基本保持不变,但是要注意文件顺序可能会乱,所以建议是保留一个原wiki的snap快照,或者是自己的索引index,方便后期快速还原恢复。
至于为什么是markdown格式,其实md格式非常有用,你可以将其作为原始一手资料再放到LLM中作为prompt(这很重要)。
1,大纲目录
左上角标注着该仓库index的时间,比如说这一个仓库,就是我最近index的,原本是没有记录的,时间还是不久前
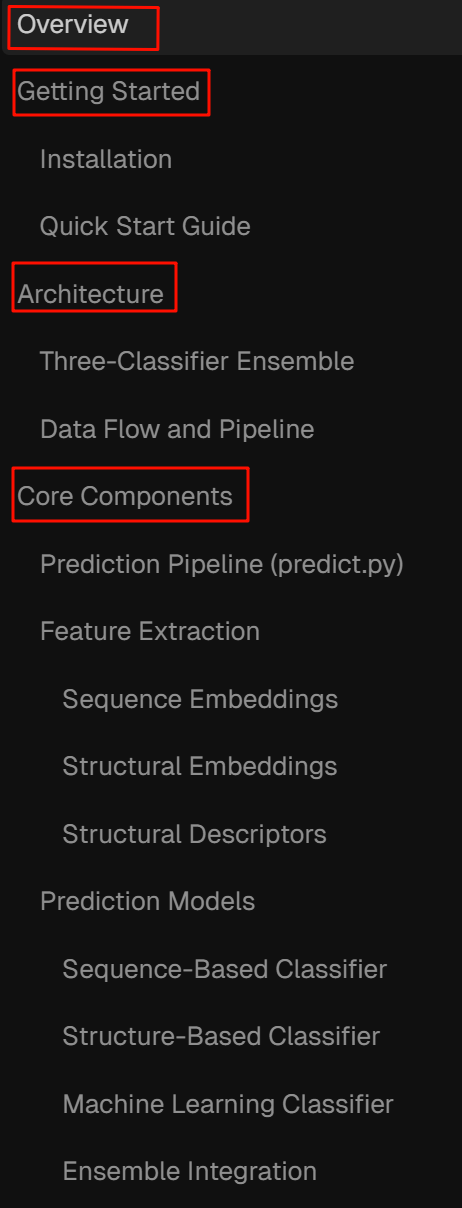
左边侧边栏的目录就是该仓库index之后生成的wiki百科目录:
我这里index生成的逻辑大概就是:
概述(overview)-快速上手-仓库代码/model架构-model模块-数据结构-输入输出格式-依赖-数据集-声明,
可以看到,是非常完善的,而且实测不同仓库index之后生成的目录是不一致的,也就是每一个wiki百科各自按照自己内容有自己的特色。

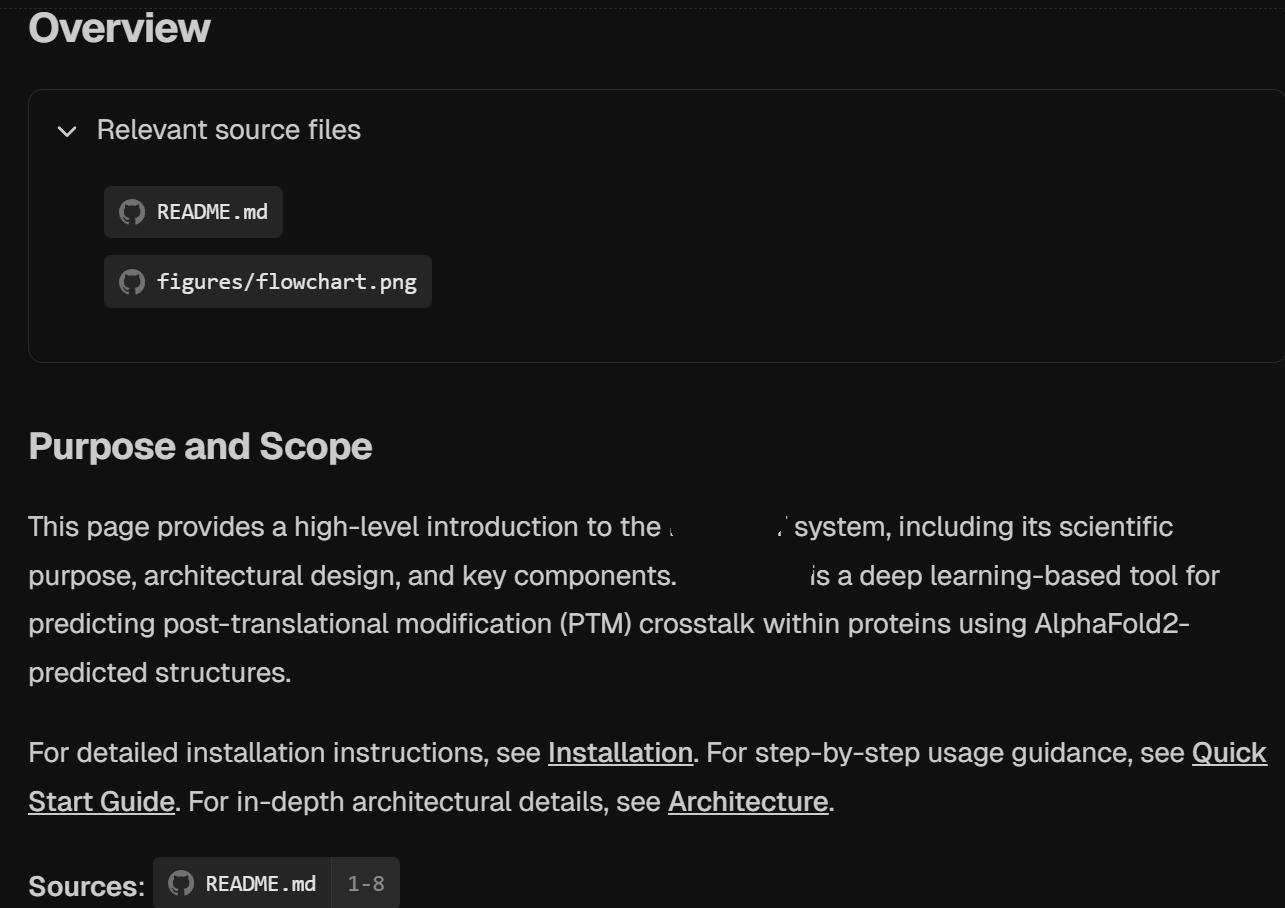
2,Overview
首先是概述,我们可以看到对于每一段推理生成内容,deepwiki都会给出推理的依据,
比如说下面原仓库的“purpose and scope”,底下会标注source是参考原仓库的README.md的1-8行左右推断生成的。
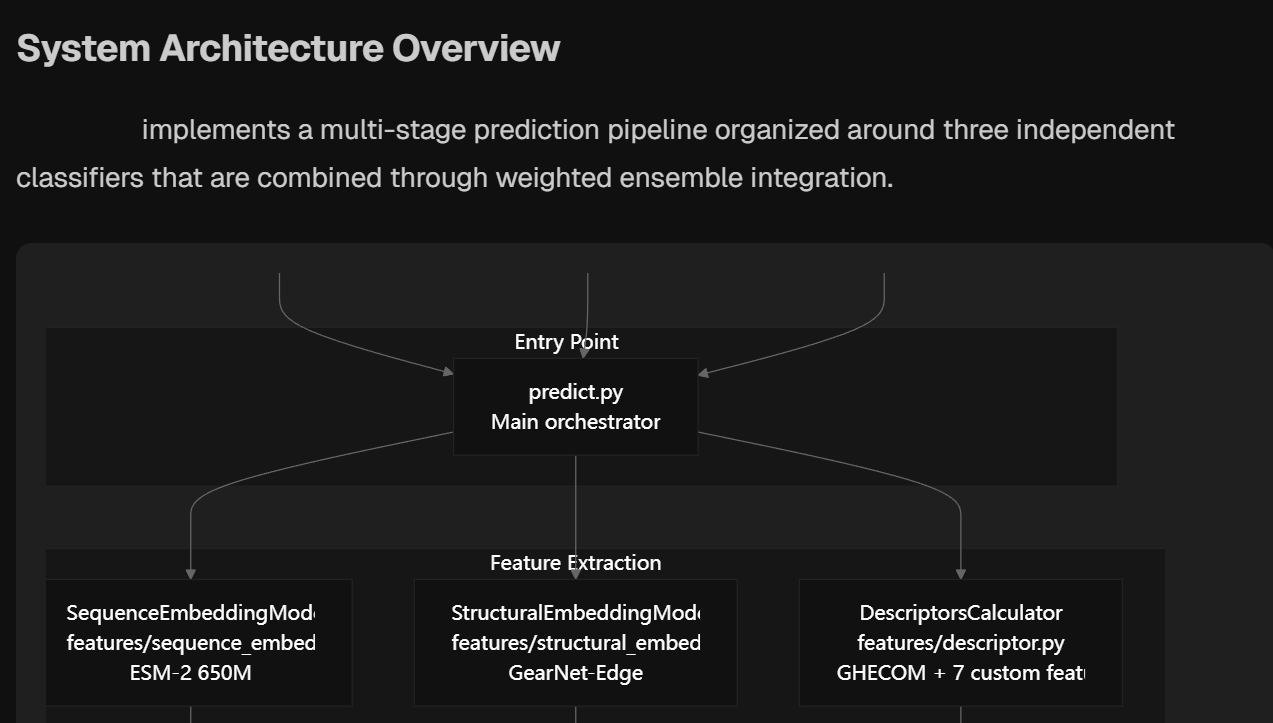
然后是系统架构分析:
这些流程图整理得比较好,但是有些显示不全会被截断,而且实测没法保存下载(不是图片格式,只能截图了)
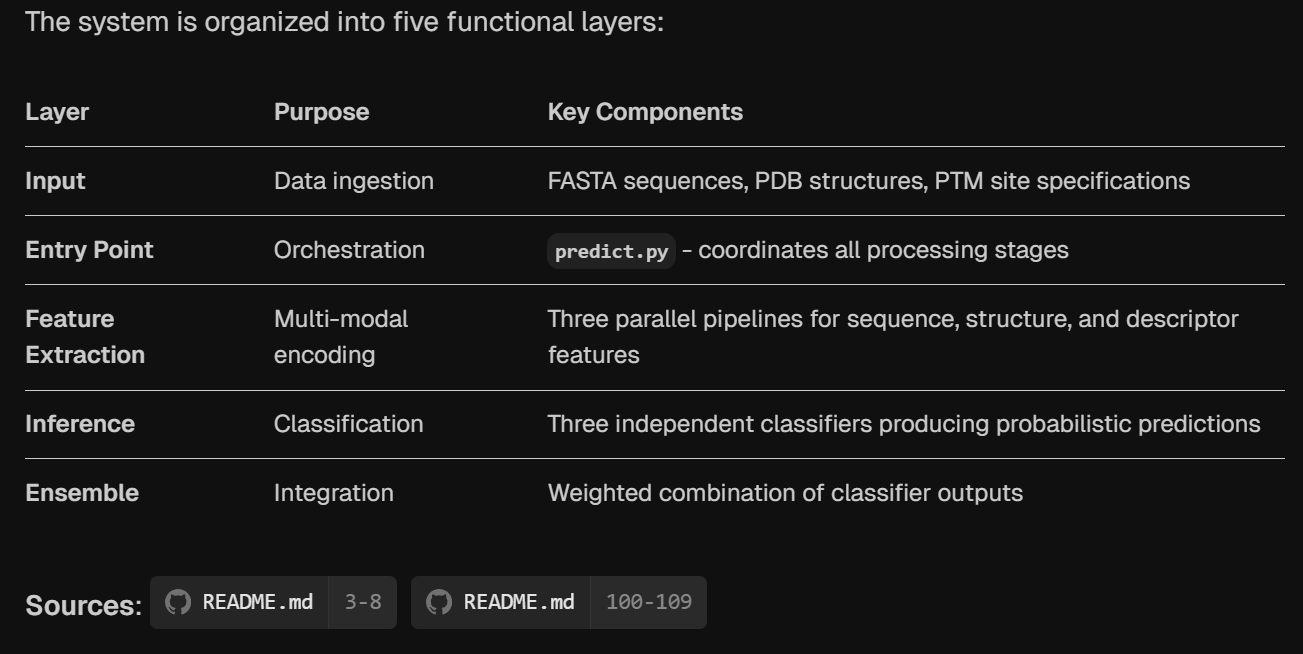
然后是各个核心模块的代码入口mapping,这个比较重要,可以让我们知道每一个模块具体对应仓库中的哪个代码文件的哪几行,入口在哪,函数是什么,实现的功能如何对应,这个对于复现非常有用!

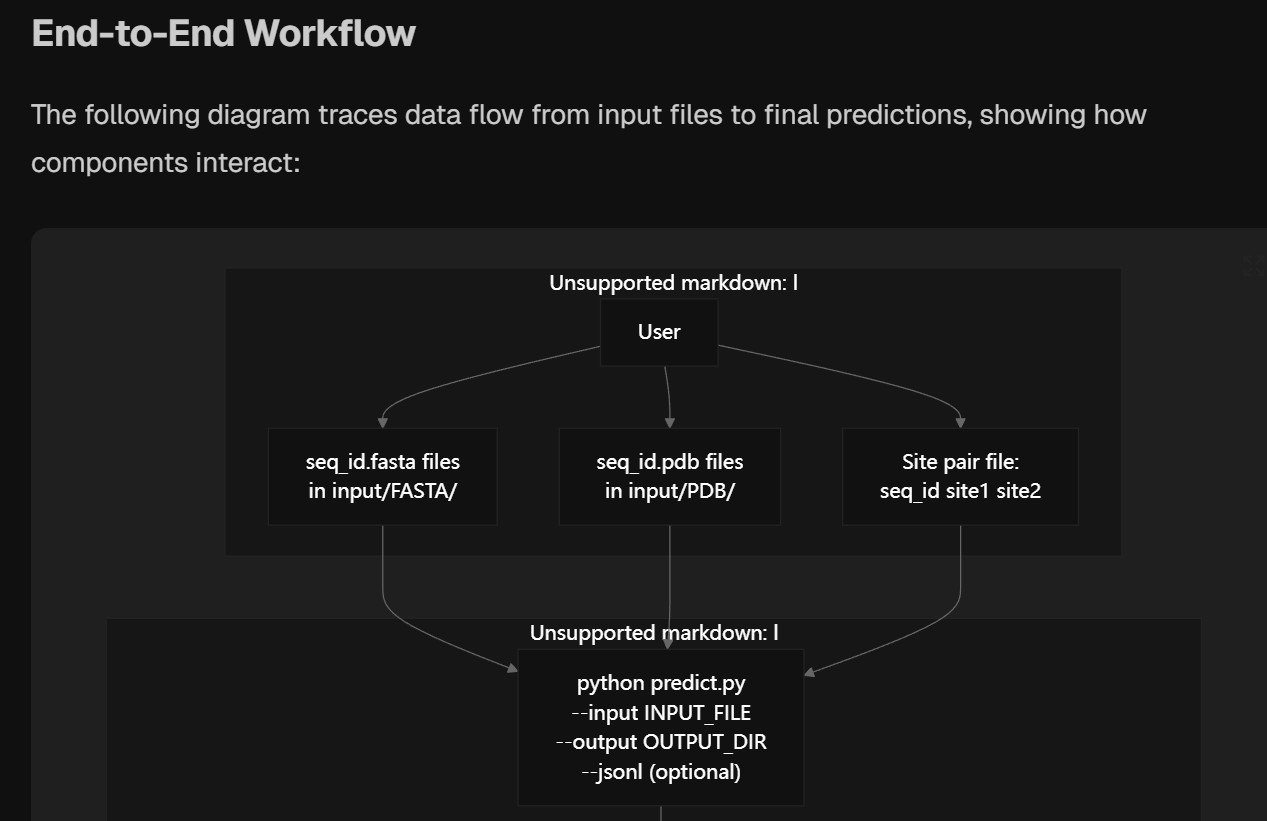
还有端到端的数据分析流程:就是data是如何flow或者说如何在整个框架下被处理出来的:

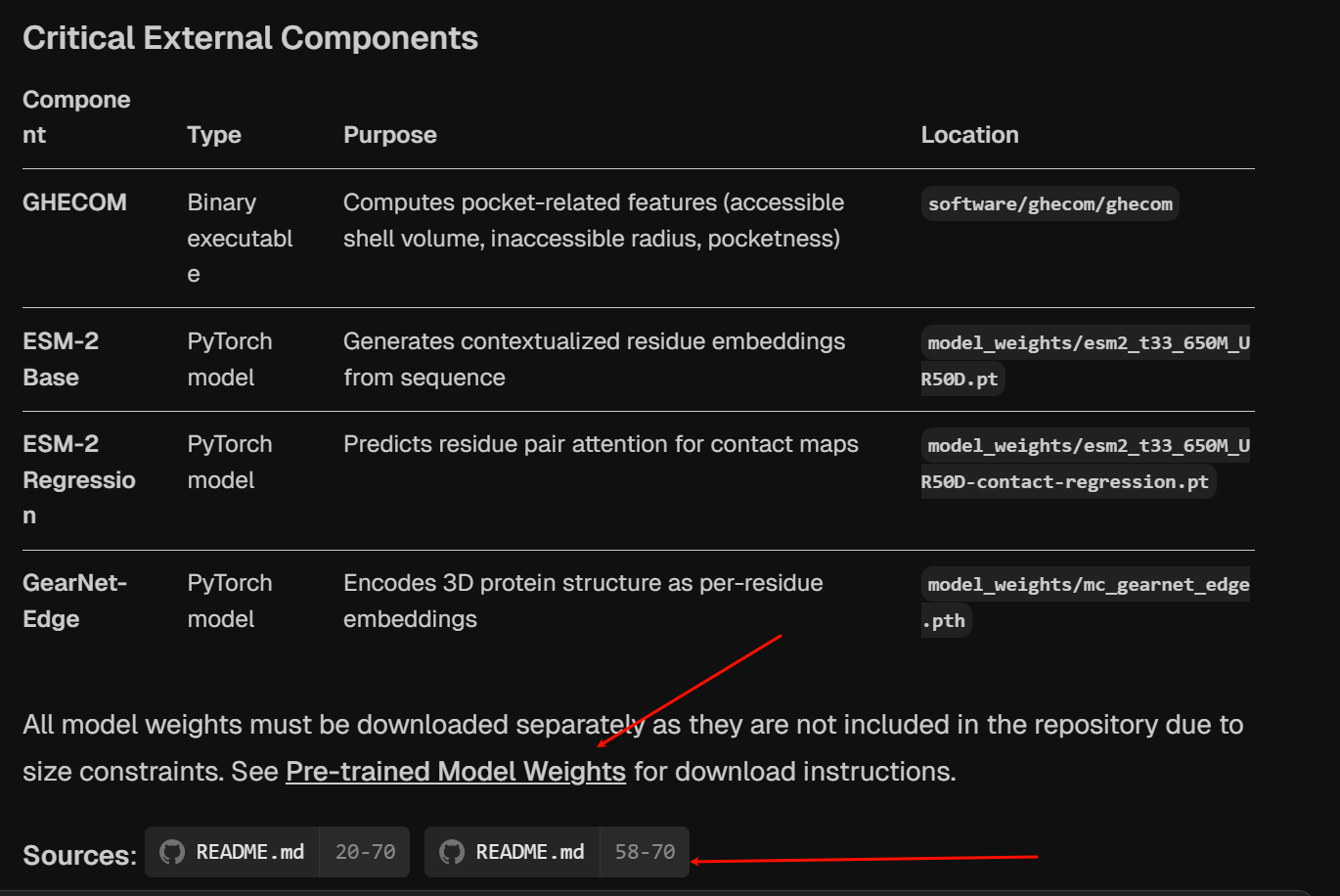
一些比较重要的外部依赖也会列出来:

另外注意:除了最底下github列出的推理来源是链接到原始github仓库外,有下划线的内容则是链接到wiki内部其他的页面,而不是原始仓库。
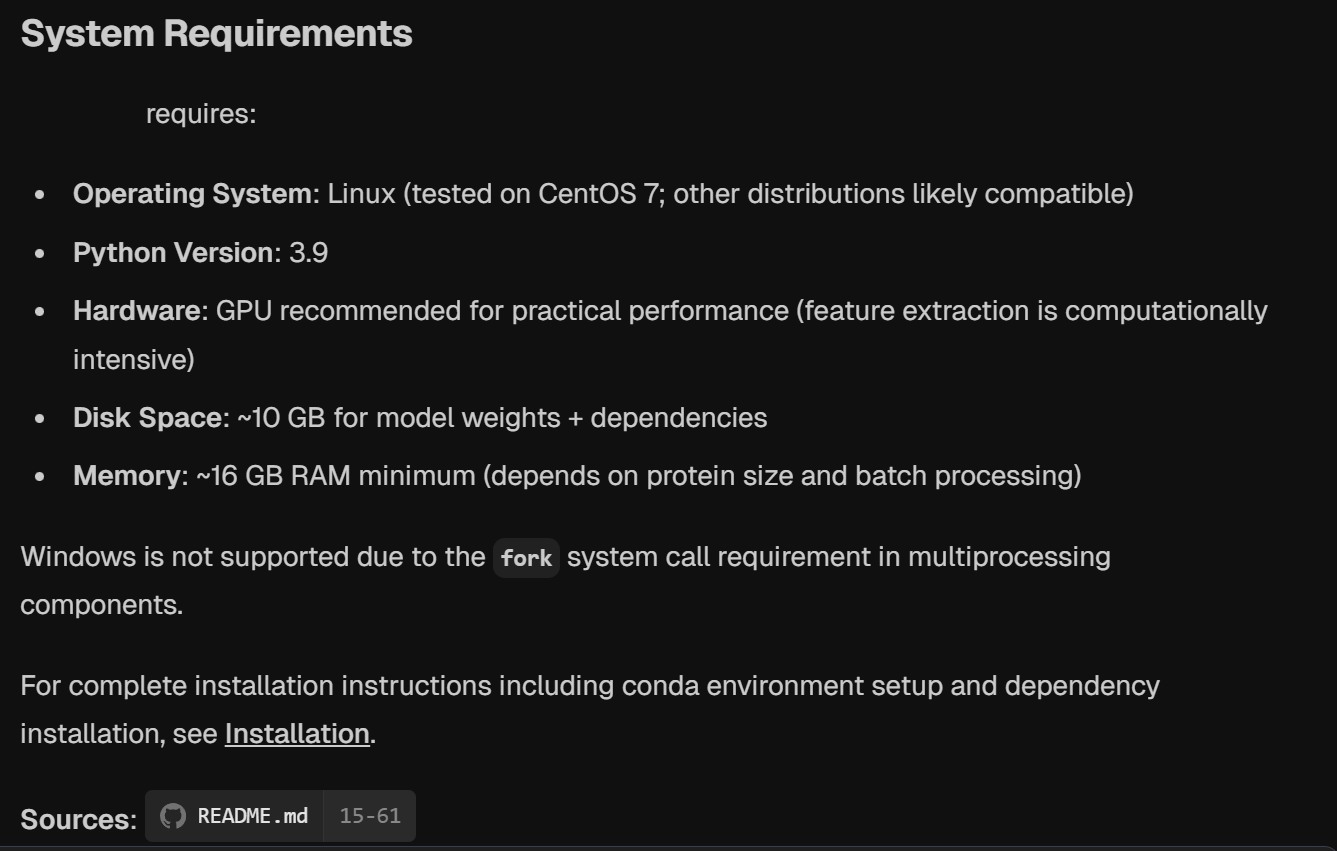
硬件需求:
3,MCP
官方的MCP服务器,参考:https://docs.devin.ai/work-with-devin/deepwiki-mcp
另外一个非官方的MCP服务,参考:https://github.com/regenrek/deepwiki-mcp
仔细看,就能够知道这个能够拿来干什么用了:

2,Zread.ai
界面参考:https://zread.ai/
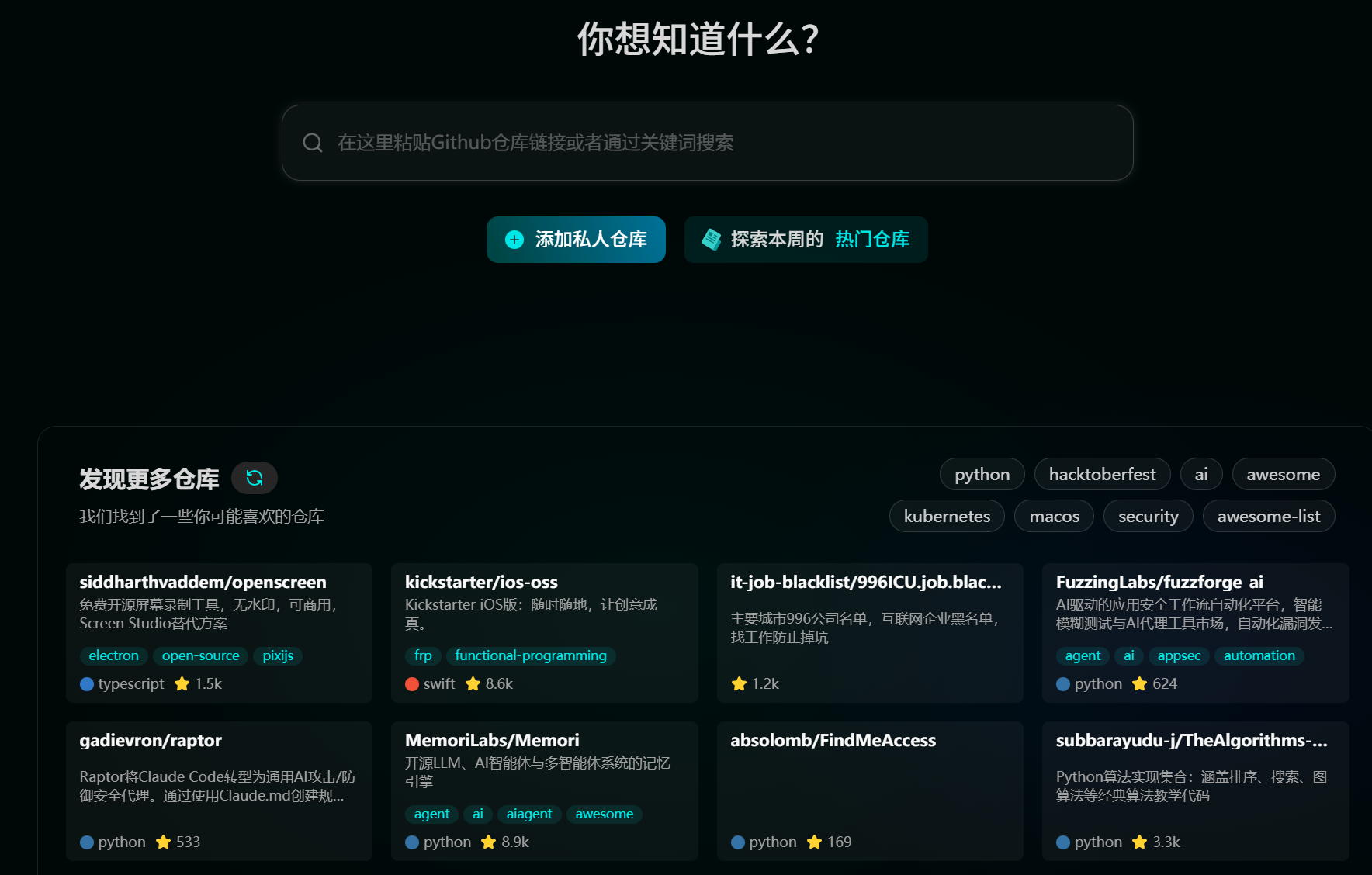
Zread.AI 的功能类似于 Cognition 推出的 DeepWiki,优点是支持中文(划重点),目前已经索引了大部分热门开源项目,冷门代码仓库可以申请发起索引。
具体来说,用户只需粘贴一个 GitHub 链接,该工具即可生成清晰的项目结构和易于遵循的指南。Zread.AI 还推出了一个名为 “Buzz” 的特色功能,该功能能够首次聚合展示来自社区的真实洞察,包括相关的 commits、issues 和新闻。
下面我以实际例子展开叙述:
我用中文(划重点)搜diffusion扩散模型,随便点了第一个index的仓库
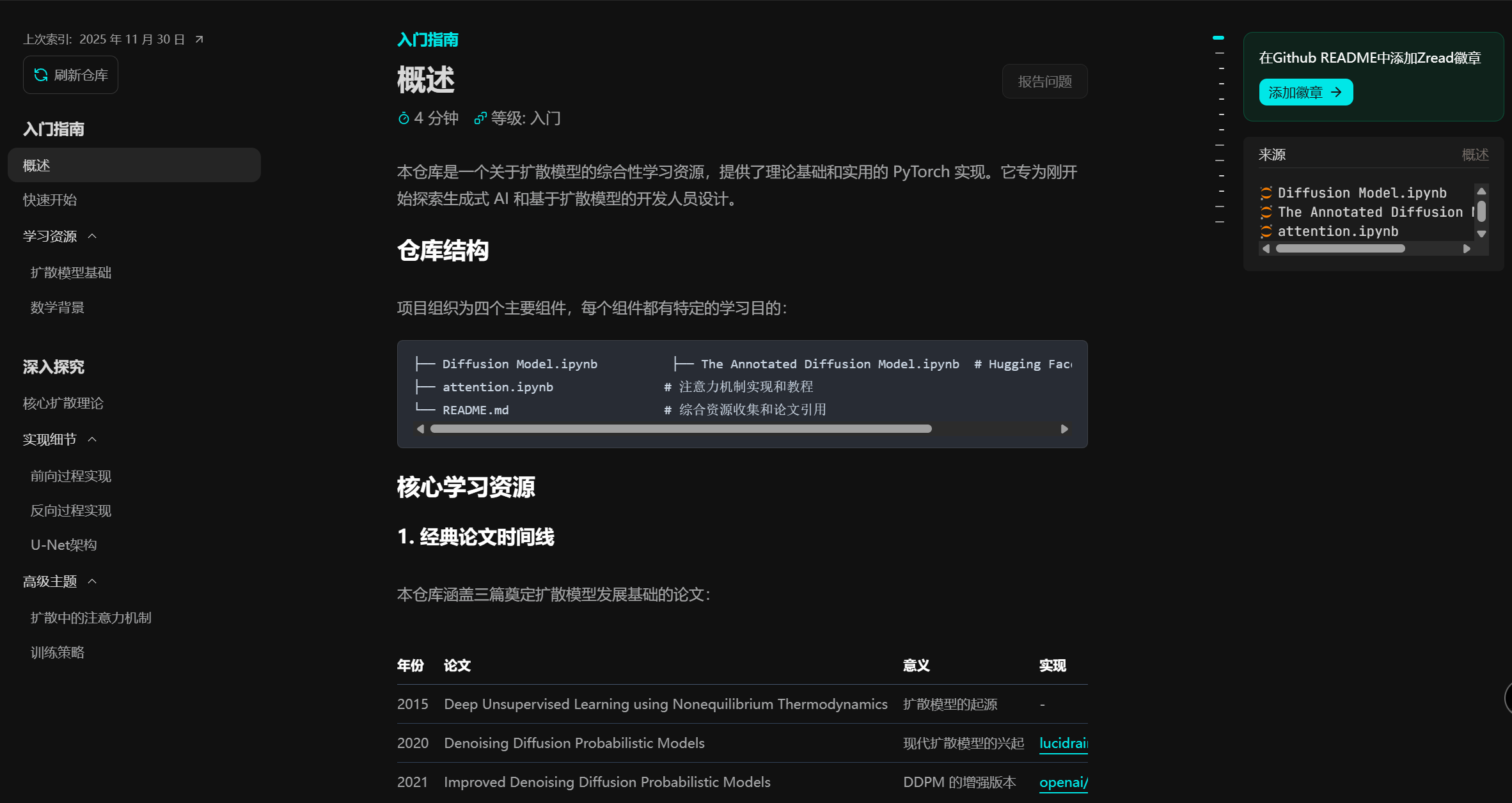
格式排版上还行:
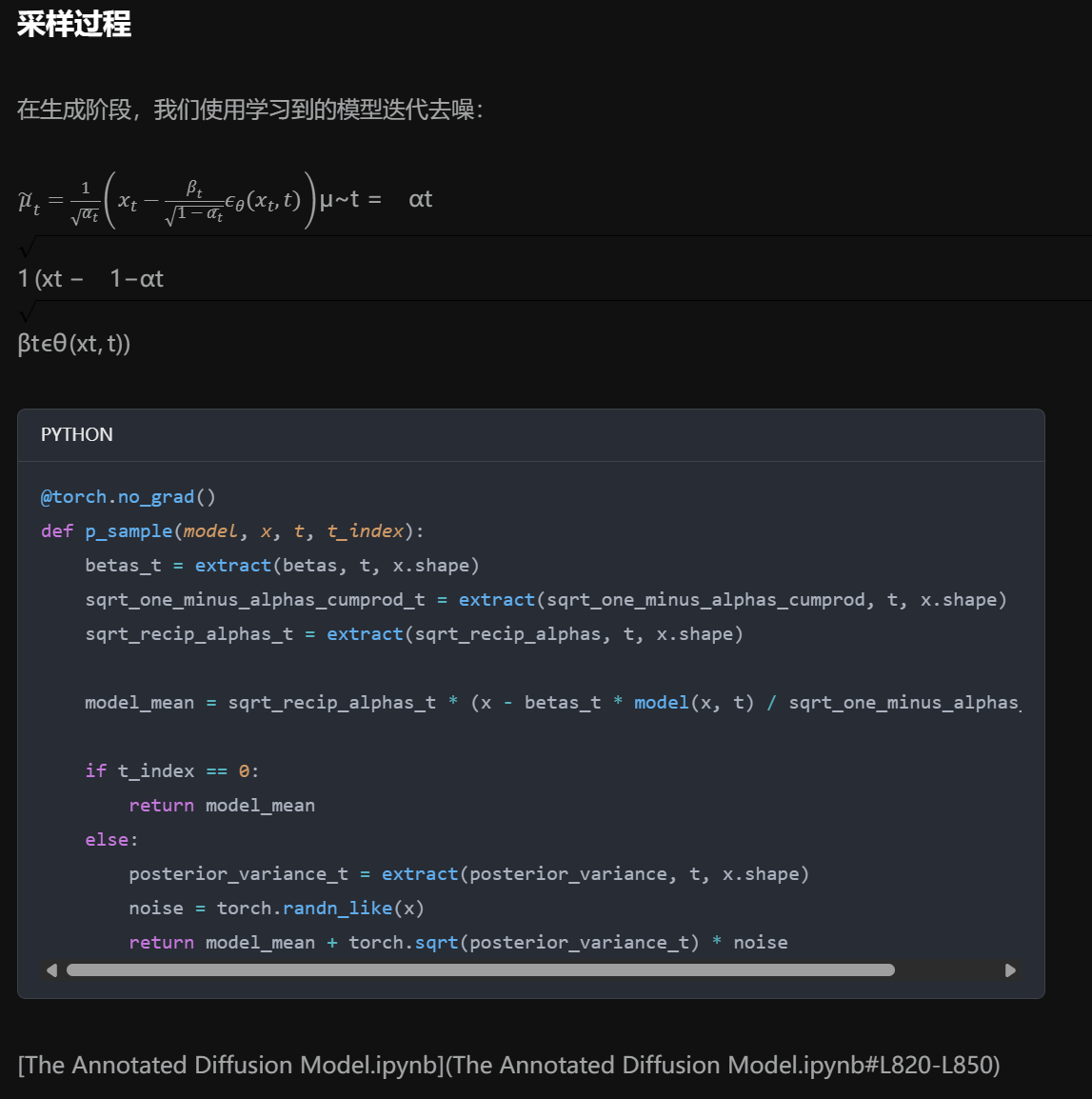
其实说了那么多,最关键的一点在于它支持中文(划重点),如果真的是一个很大的项目,我用DeepWiki生成几十页的英文技术文档看,其实也是比较吃力的,
但是用Zread能够生成中文解析文档,至少对于新手而言上手比较方便一点,至少是省去了部分翻译的时间。
比如说下面的这个Google的AlphaFold3,我就可以完全用中文去看
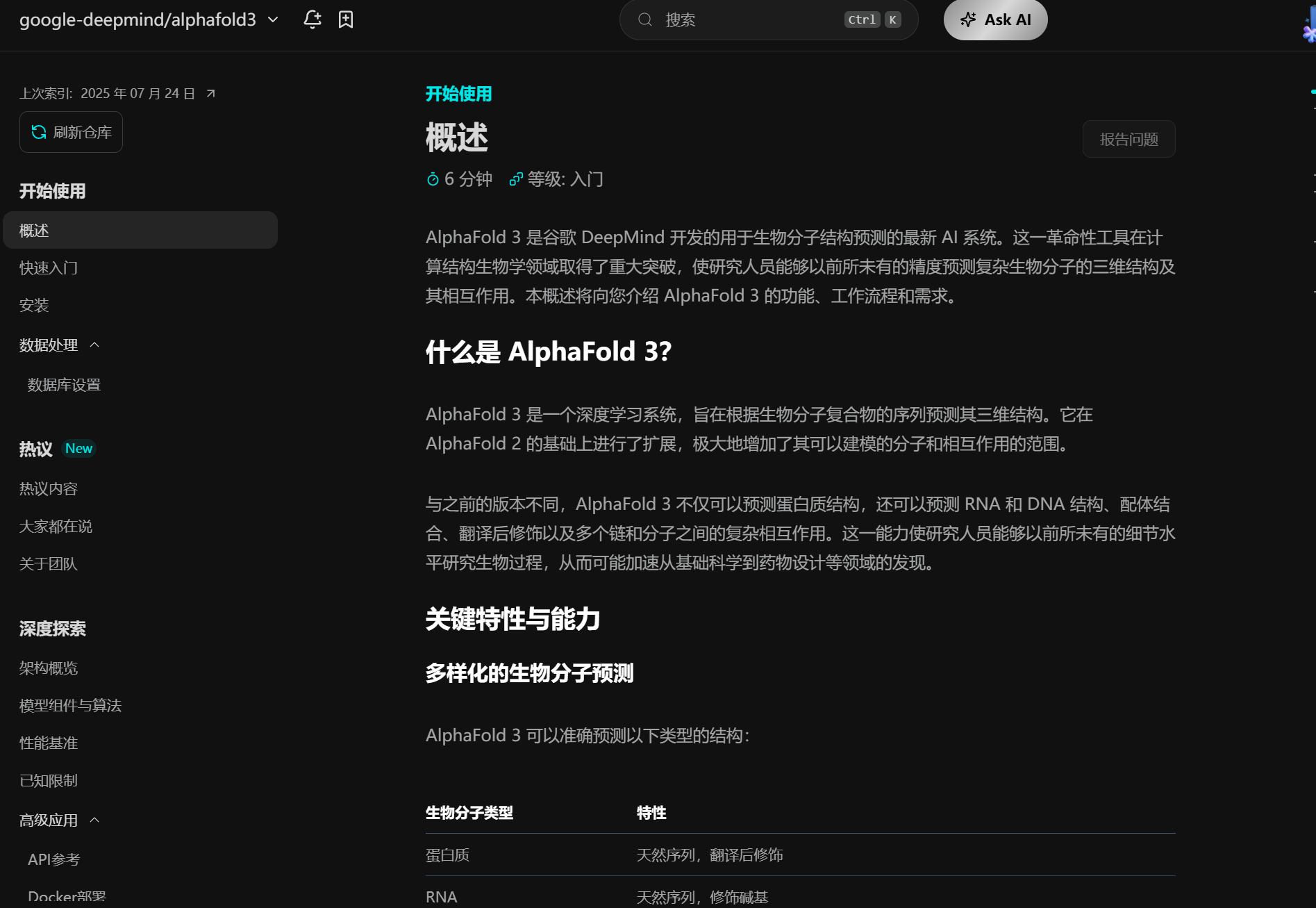
同样的,对于没有index的小众仓库或者是私人仓库,
也能够进行index定制解析:
3,Tutorial-Codebase-Knowledge
参考官网链接:https://code2tutorial.com/
官方github仓库链接:https://github.com/The-Pocket/PocketFlow-Tutorial-Codebase-Knowledge

本地自己部署的话挺简单的,因为LLM最大的难点还是在消费上,只有钱到位够烧,其余都是小事

我随便拿一个仓库来测试一下
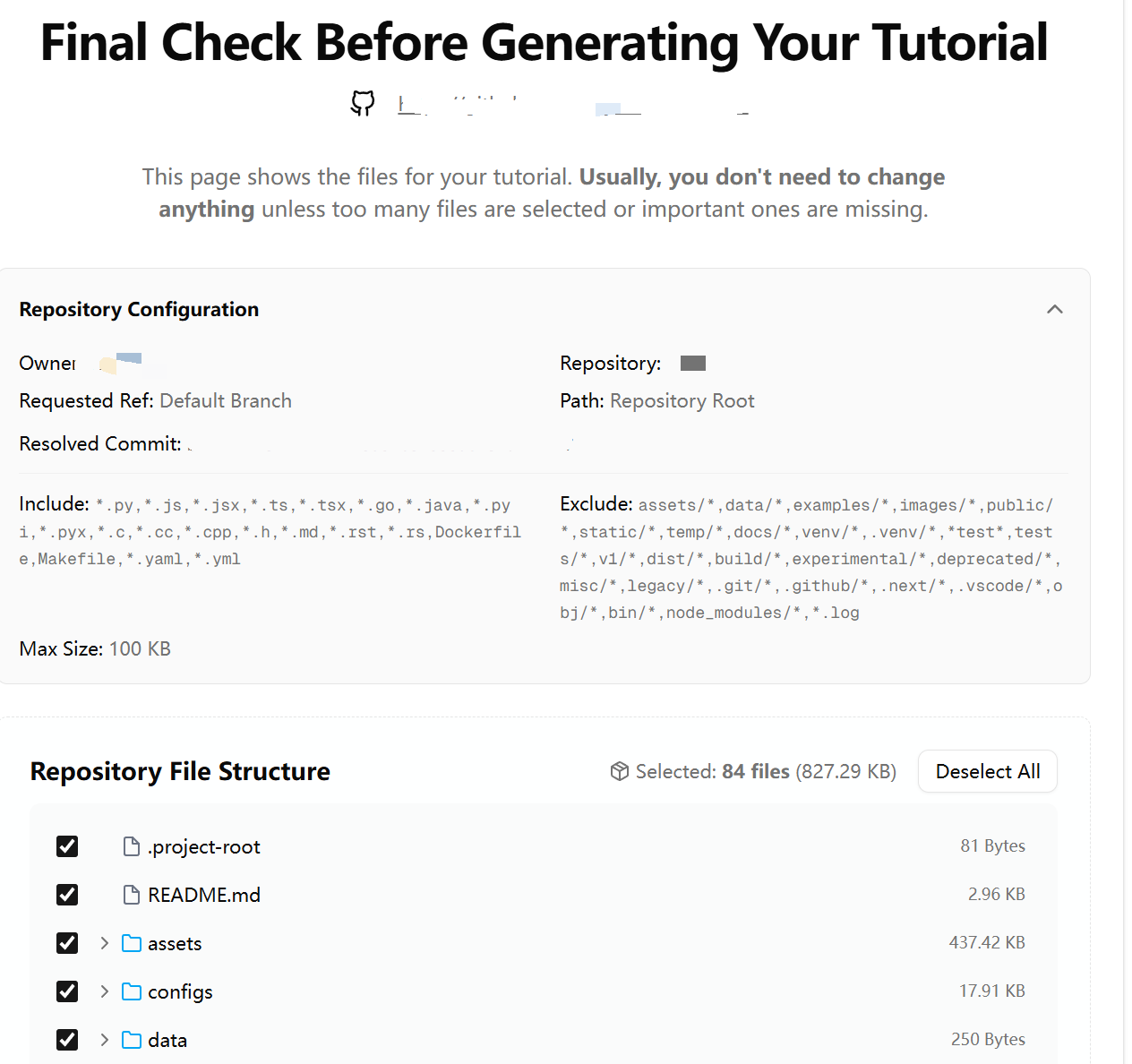
大概就是选取仓库中的代码文件,真的生成一份文档,
问题是我试了好几次,结果总是生成的过程中报错:

3,为什么这里我不提那些纯AI agent工具:真实的背后
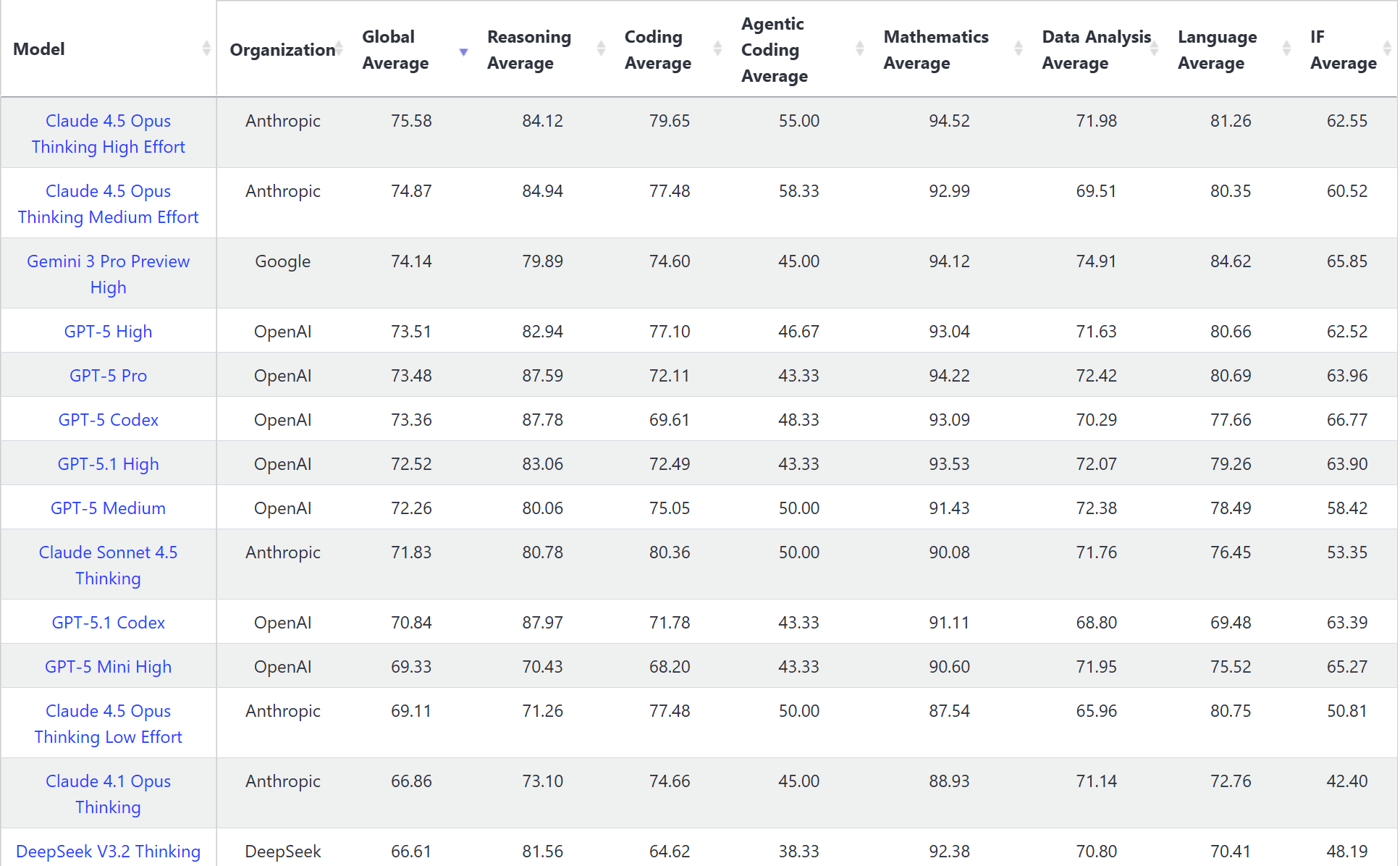
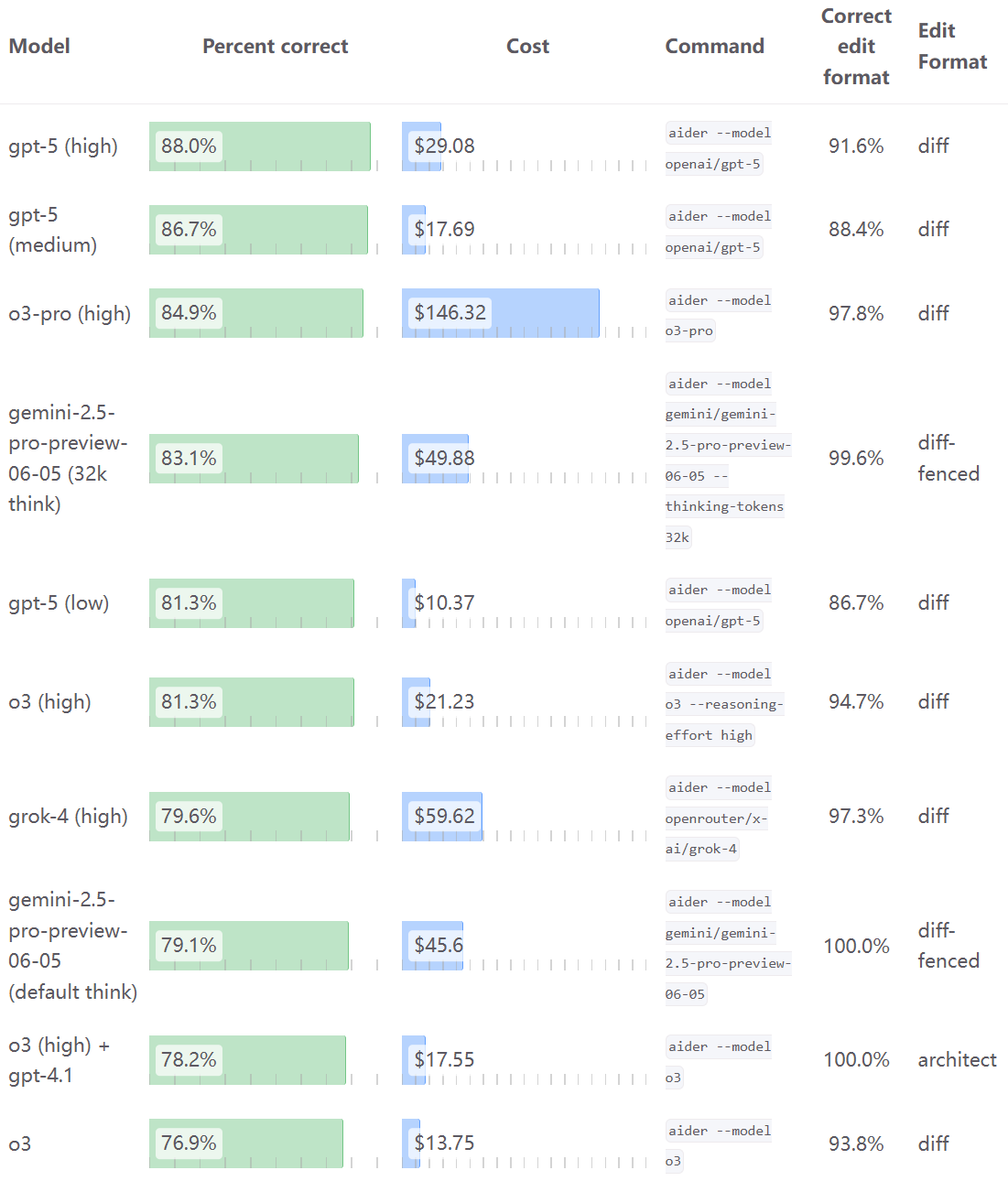
纯粹的LLM就太多了,大家可以自己去搜各种LeaderBoard(像我经常使用并查看的有https://livebench.ai/#/、https://aider.chat/docs/leaderboards/),各大厂家都有自己对应的大模型,国内外都有。
形式上不说了,IDE、vscode extension、网页、API、命令行CLI等等等等。
Roo Code、Cursor、类似的还有windsurf,Augument code,以及老一辈的Copilot,kilo code的vscode插件。
CLI命令行的形式最近比较火,当然没有桌面的话自然就是CLI,首选claude code和codex,Google也有CLI工具。
AI编程最大的问题就是它有未知的需求不问你,而是自己瞎猜,导致你debug很痛苦,一定要用AI的话千万要注意它能否搜索访问你整个工作目录。
代码任务首先考虑推理模型,即DeepSeek R1,Claude 3.7 thinking,GPT o3 o4之类的(这里举例,是我在2025年5月份左右的一个回答,现在当然有很多新model了,但是还是注意推理模型优先)。
当然,我们其实要的是API,
如果你真的需要,其实充会员、开销这些是完全值得的,
渠道也有很多,虚拟卡、yeka、wildcard。
优惠的话,有
# 注意: 更新数据为2025.4, 仅供参考!
Grok:数据分享计划,充值5$送150$
GitHub copilot:学生包,无限使用Claude3.7(thinking),gpt o1,o4 mini,4.1,gemini2.5pro
OpenAI:学生包(指月订阅!)
Claude:申请学生开发者,可以送50$(需要可用区域的edu邮箱,sjtu.edu.cn不行)
Update:被薅秃力,已经结束了
0521 update: 新的500$,参加Claude安全红队
Gemini:AI studio免费
火山引擎:注册送deepseek额度,可以通过邀请增加
硅基流动:和火山引擎类似,但是送的是余额,可以在任何模型上使用
- Agene coding的最佳实践,可以参考:https://www.anthropic.com/engineering/claude-code-best-practices
- 关于MCP,感兴趣的可以去看看,不过比较烧token,当然如果你觉得没用,说明你可能不需要这个,一般的比较万金油的就是sequential thinking。通俗地说,MCP协议就像是现在日常使用的USB协议,让AI和外部工具之间可以方便地传输数据和指令。
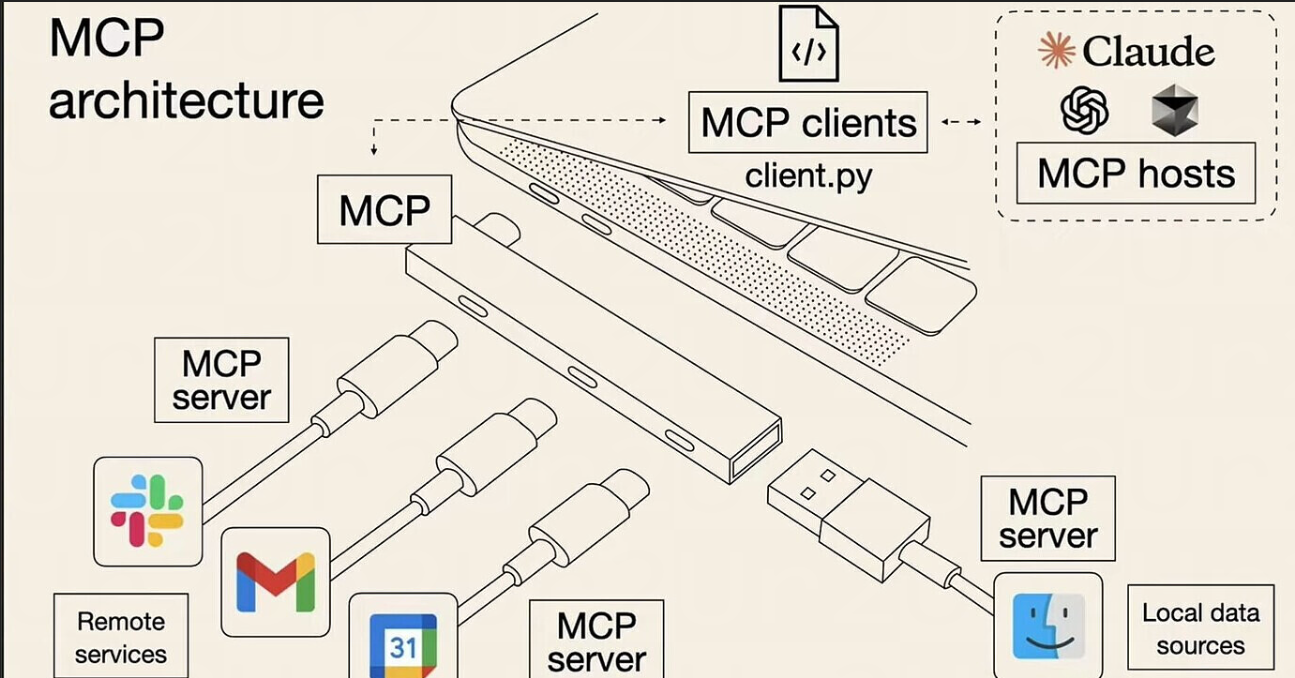

回到这个标题,为什么我不提具体的LLM,因为代码库的可视化此处实际上是一个古老问题的新解。

DeepWiki之类工具最重要的始终是LLM的能力,而静态的AST抽象语法树分析其实是已经比较成熟了,


参考:https://shuiyuan.sjtu.edu.cn/t/topic/367224/415
https://ayanami1314.github.io/blog/code-search&code-embedding
二,文档生成工具
其实这一类工具,相比我上面归纳列出的一,区别在于有没有对话,也就是chat的差异,因为基本上文档生成也大多是使用LLM的。但问题基本上在于它虽然生成了很多补充资料、比较丰富,但本质上还是相当于扩充了你的阅读语料库,只不过是让你接触的能够便于你理解代码的阅读资料多了、复杂了,更丰富了,有更多的入口可以分析,但是在解读、以及点对点的解析上,基本上是没有的,还是得你自己来
1,Greptile(商业化)
参考官方链接:https://www.greptile.com/


对于本篇博客而言,重点在于下面的“文档增强”

从本质上,就像数据增强一样,你把一个图像反转、放大缩小,或者是改一下灰度像素之类,做的所谓增强,只不过是在训练数据稀少的情况下,为神经网络的输入数据增加了一点数据量级上的提升,类比之下数据多了学还是得自学。
但是总体上是闭源,且主要作为 API 服务,不是本地运行的工具,商业化、团队使用为主。
2,Bloop.ai(已归档)
一个基于 Rust 开发的代码搜索和导航工具,集成了 GPT-4。它会下载仓库,建立语义索引,允许你用自然语言搜索代码逻辑。
非常强调“理解”代码,而不仅仅是搜索文本。
官方github仓库链接:https://github.com/BloopAI/bloop

从设计理念上看其实是挺先进的:
可惜的是已经归档了,网页链接也不再提供服务了

3,Mintlify(有vscode插件)
官网参考:https://www.mintlify.com/
有中文文档:https://www.mintlify.com/docs/zh/quickstart
为你的 Java/Python/TS 等函数生成结构清晰、语义到位、开发友好的专业文档注释
本质上是一个API文档部署工具,只不过是能够用于解析代码逻辑。
它是 VS Code / JetBrains 系 IDE 中的 AI 文档自动生成工具,能识别你当前的函数、类、模块,一键生成英文注释、JSDoc、JavaDoc、Python Docstring,甚至可以输出完整的 API 说明文档页面。


而且有vscode插件,是可以集成到我们的编程工作流中的:
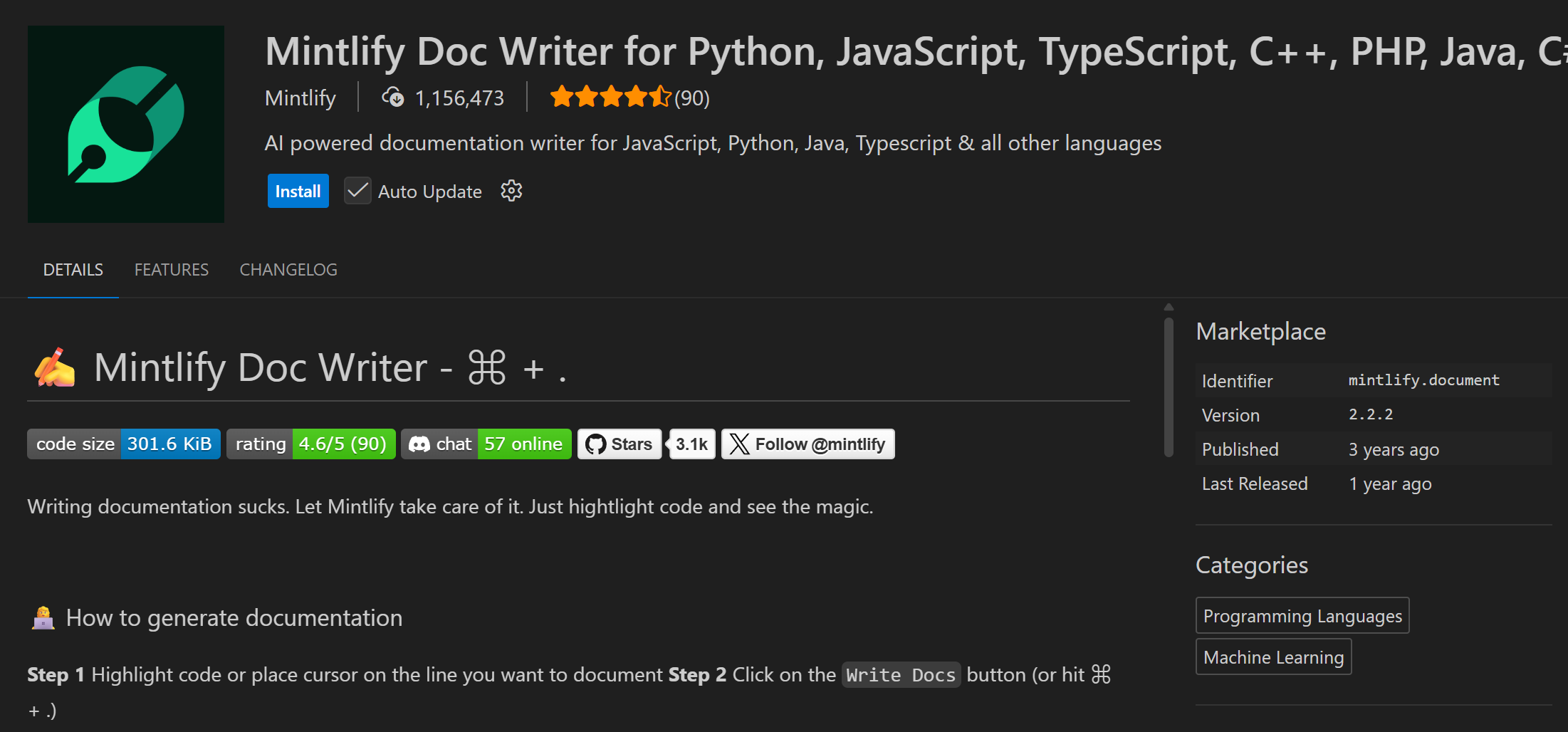
总的来说:不仅仅是提取 docstring,还会试图理解函数逻辑来写解释,实现了“为新手生成友好文档”的目标。
4,Glarity / Sourcegraph Cody
Glarity:
https://github.com/sparticleinc/chatgpt-google-summary-extension

只不过是any webpage,可以用在github网页上
Sourcegraph Cody:
参考链接:https://sourcegraph.com/github.com/sourcegraph/cody
https://github.com/sourcegraph/cody-public-snapshot
更像是写代码的插件,不像是解析代码文档的,而且也已经归档了
三,传统静态分析可视化工具
传统的 Python 结构可视化工具 (类似 LibInspector 的图表功能),关于我开发的LibInspector,
可以参考我之前的博客:LibInspector—为小白智能解析、阅读(几乎所有)Python工具库
工具下载链接:https://github.com/MaybeBio/LibInspector (欢迎给仓库PR,给开发人员提issue!)
这一类工具主要基于 AST(静态)或 Trace(动态)来生成图表,不依赖大模型,结果精确但可能比较难看或杂乱。
但是也正是因为不依赖大模型,所以安装配置相比前面的要更加方便,更像是小型化、轻便的toolkit,当然在智能解析上比较死板,结果比不上大模型助力的分析工具。
1,Pydeps(基于静态分析生成 Python 模块依赖图)
github链接,参考:https://github.com/thebjorn/pydeps
详细的文档参考:https://pydeps.readthedocs.io/en/latest/
大致可以对应LibInspector的“Dependency Graph”功能,但是图表往往非常巨大且难以交互,缺乏逻辑流(Flowchart)。
2,PyCallGraph(仓库已归档)
通过运行代码(动态追踪)生成函数调用图,
github仓库链接:https://github.com/gak/pycallgraph?tab=readme-ov-file
源仓库已经归档,但是有依然在维护的分支:

事实上,经过调查之后,我看到了好几个还在活跃的分支,
https://github.com/daneads/pycallgraph2
https://github.com/Lewiscowles1986/py-call-graph

总而言之,分析功能大致可以对应上LibInspector的动态分析部分,但是生成的图表缺乏层级和重点,我们需要算法来筛选核心,LibInspector很难说做到算法筛选核心,但是至少有一个尝试,通过简单的调用计算节点出入度等。
3,Sourcetrail(同样已经停止维护,但是曾经是标杆)
官方github链接:https://github.com/CoatiSoftware/Sourcetrail
一样已经归档了,
数据流可视化比较清晰:
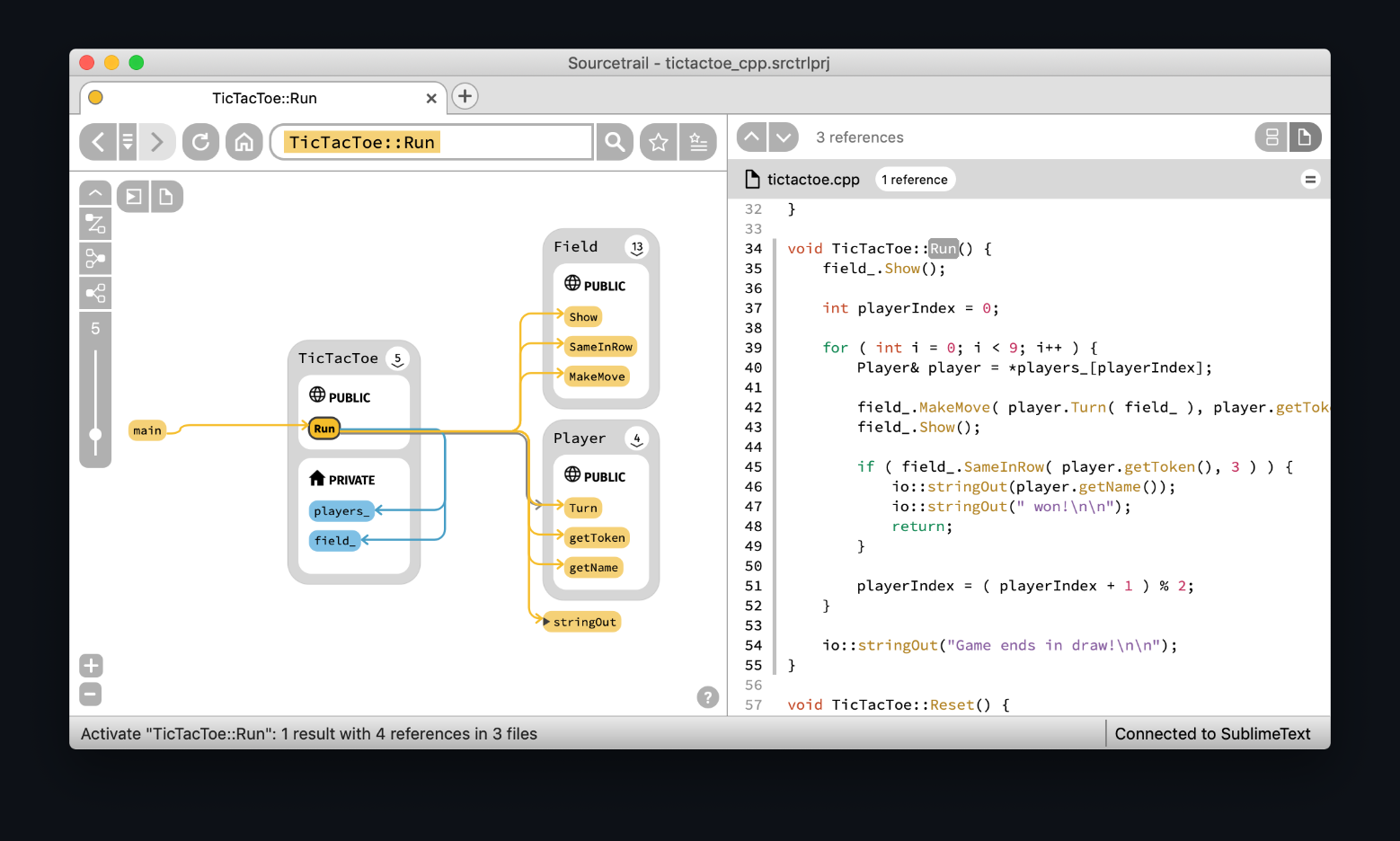
甚至维基百科都有专门的条目来讲这个在软件可视化领域影响重大的项目:
https://en.wikipedia.org/wiki/Sourcetrail



4,GitHub 上的开源“竞品”或类似项目
这个讲起来就很多了,类似Auto-README / GPT-Readme等等,专门搜能够搜到一大把。
有很多类似名字的项目,通过读取代码自动生成 README.md,而生成README本身其实也算是给我们理解代码提供了一个入口,不能不说是解构作用。
局限性在于通常只看文件结构,很少深入到函数级别的调用流。
类似的静态分析工具还有pyan等等,基于静态分析的 Python 调用图生成器,比 Pydeps 更细粒度,能画出函数之间的调用,但不支持动态特性。
其实涉及到debug、数据结构和算法可视化分析的,也有不少是做软件可视化的,都有这部分的工具。
四,一些临时的讨论
之前讨论的,我说的工具 (LibInspector) 的独特生态位,
虽然上面有很多工具,但 LibInspector 的设计哲学依然有其独特的不可替代性:
- “Trinity” 混合模式:
- 大多数工具要么纯静态(Pydeps, Pyan),无法处理 Python 的动态特性(如装饰器、元类);要么纯动态(PyCallGraph),需要跑通整个程序。
- 我的工具结合了 Import (动态) 和 AST (静态),这是一个非常务实的中间路线。
- 针对“科学计算/AI4S”的优化:
- 比如说
numpy,pandas,BioPython。这些库大量使用 C 扩展和动态属性,纯静态分析工具对它们基本失效。LibInspector 的动态加载机制在这里是杀手锏(也许)。
- 比如说
- 网络节点依赖分析的降噪算法:
- 这是大多数可视化工具最缺少的。生成的图往往因为节点太多而不可读。引入算法来识别“核心模块”并隐藏“噪音”,是让工具从“玩具”变成“实用工具”的关键。当然,目前我还没有太多的想法。
- 本地化与隐私:
- Greptile 或 Mintlify 需要把代码传给第三方服务器。LibInspector 是本地运行的,对于私有仓库或敏感科研代码更安全(相对)。
事实上,正是因为当初想要找而一时半会没找到开源的、本地运行的、结合了“动态+静态+算法降噪”且专门生成交互式 可视化文件报告的 Python 工具,所以才搞了个小玩具出来。
我正在构建的工具,或者说这个LibInspector雏形,实际上是在传统的静态分析器和昂贵的 AI 代码助手之间,寻找一个轻量级、低成本、高可用的平衡点。如果能结合 LLM (比如调用本地 Ollama 或 OpenAI API) 来为生成的图表自动撰写一段文字总结,那就真的是“有点用处的而不是小玩具的工具”了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)