基于Qwen大模型的FFmpeg自动化智能剪辑运营架构
本文介绍了AI智能自动化剪辑应用案例,核心流程包括AI切片、IP视频运营分析、SOP运营管理和AI智能体优化。重点讲解了基于AutoClip工具的AI切片方案,涵盖环境部署、功能流程和常见问题处理。文章还详细阐述了视频数据分析方法(皮尔逊系数、PCA分析等)和短视频运营预测模型,提出四模块闭环系统架构,实现从内容生产到智能决策的全链路优化。该方案旨在解决短视频运营效率问题,通过AI技术赋能内容创作
目录
前言
已经很长时间没更新了,最近工作太忙,新的智能应用案例太多,本次就梳理AI智能自动化剪辑应用案例,主要核心流程:AI切片→IP视频运营综合分析→SOP运营管理策略→AI智能体,最终形成闭环,依靠智能体自动优化迭代。
一、基于Autoclip的AI切片工具
1、autoclip的使用介绍
关于该工具的使用,可以参考autoclip_mvp的github项目,该项目的地址:https://github.com/zhouxiaoka/autoclip_mvp
目前该初始版本已经停止维护,具体可以依照项目进行变更,目前我依然使用初始版本,并且基于初始的代码项目,可以适当进行修改,已试用不同的场景需求。如果有小白不太会改应用的部署和使用,包括后续可能会出现的BUG,我推荐使用Repomix,只需要获取该项目的URL地址,就可以自动解析出对应的markdown文档,通过AI也能快速掌握和学习。
1.1 环境部署
开发环境:
- Python 3.8+
- Node.js 16+
- AI服务API密钥(支持通义千问或硅基流动)
Docker部署:
- Docker 20.10+
- Docker Compose 2.0+
- AI服务API密钥(支持通义千问或硅基流动)
API的配置:
{
"dashscope_api_key": "your_api_key",
"siliconflow_api_key": "",
"api_provider": "dashscope",
"model_name": "qwen-max",
"siliconflow_model": "Qwen/Qwen2.5-72B-Instruct",
"chunk_size": 6000,
"min_score_threshold": 0.6,
"max_clips_per_collection": 5,
"default_browser": null
}手动启动项目(基于vscode编辑环境下)
需要启动后端和前端,启动后直接点击前端的登录地址http://localhost:3000/进入界面。
# 启动后端服务
source venv/bin/activate
python backend_server.py
# 新开终端,启动前端服务
cd frontend
npm run dev1.2 核心框架结构
目前我是使用vscode编辑和使用,前提是需要安装工具FFmpeg,这个核心工具是剪辑的前提,并且其逻辑就是调用Qwen大模型来识别视频字幕信息,基于视频内容进行归类,之后使用FFmpeg工具对应裁剪,最后输出对应内容的主题。
AI服务调用链:
字幕文本 → LLM分析 → 大纲 → 时间点 → 评分 → 标题 → 聚类 → 合集
│ │ │ │ │ │ │
└───→ 通义千问/硅基流动 ←──┘ └───────────┘文件处理流水线:
原始视频 → 分割切片 → 单独存储 → 合集合并 → 最终输出
│ │ │ │
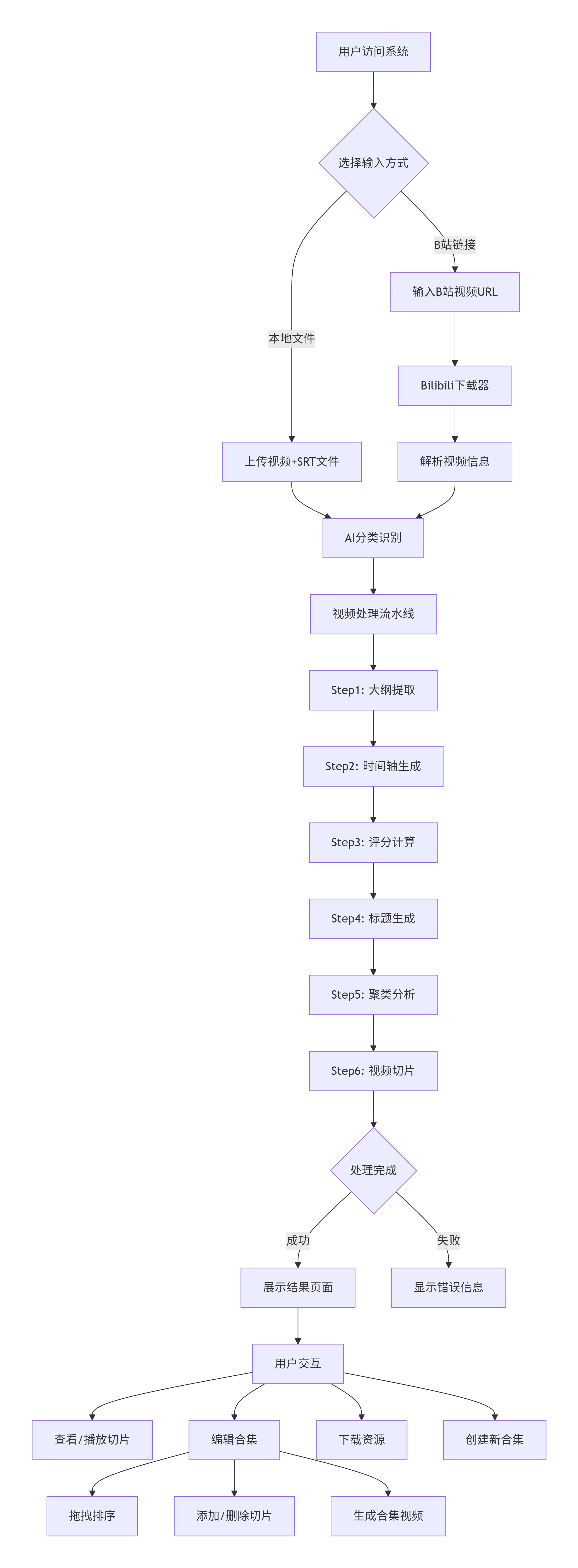
SRT文件 → 时间对齐 → 文本分析 → 智能推荐这个架构展示了AutoClip从视频输入到智能切片输出的完整流程,涵盖了用户交互、后台处理、AI分析和文件操作等多个维度
2、autoclip的功能流程
2.1 系统状态流程
用户操作 → 系统状态
-------------------
1. 上传文件 → pending
2. 开始处理 → processing
├─ Step1完成 → step1_completed
├─ Step2完成 → step2_completed
├─ Step3完成 → step3_completed
├─ Step4完成 → step4_completed
├─ Step5完成 → step5_completed
└─ Step6完成 → completed
3. 处理失败 → failed
4. 手动重试 → processing (重新开始)2.2 应用流程与核心时序图
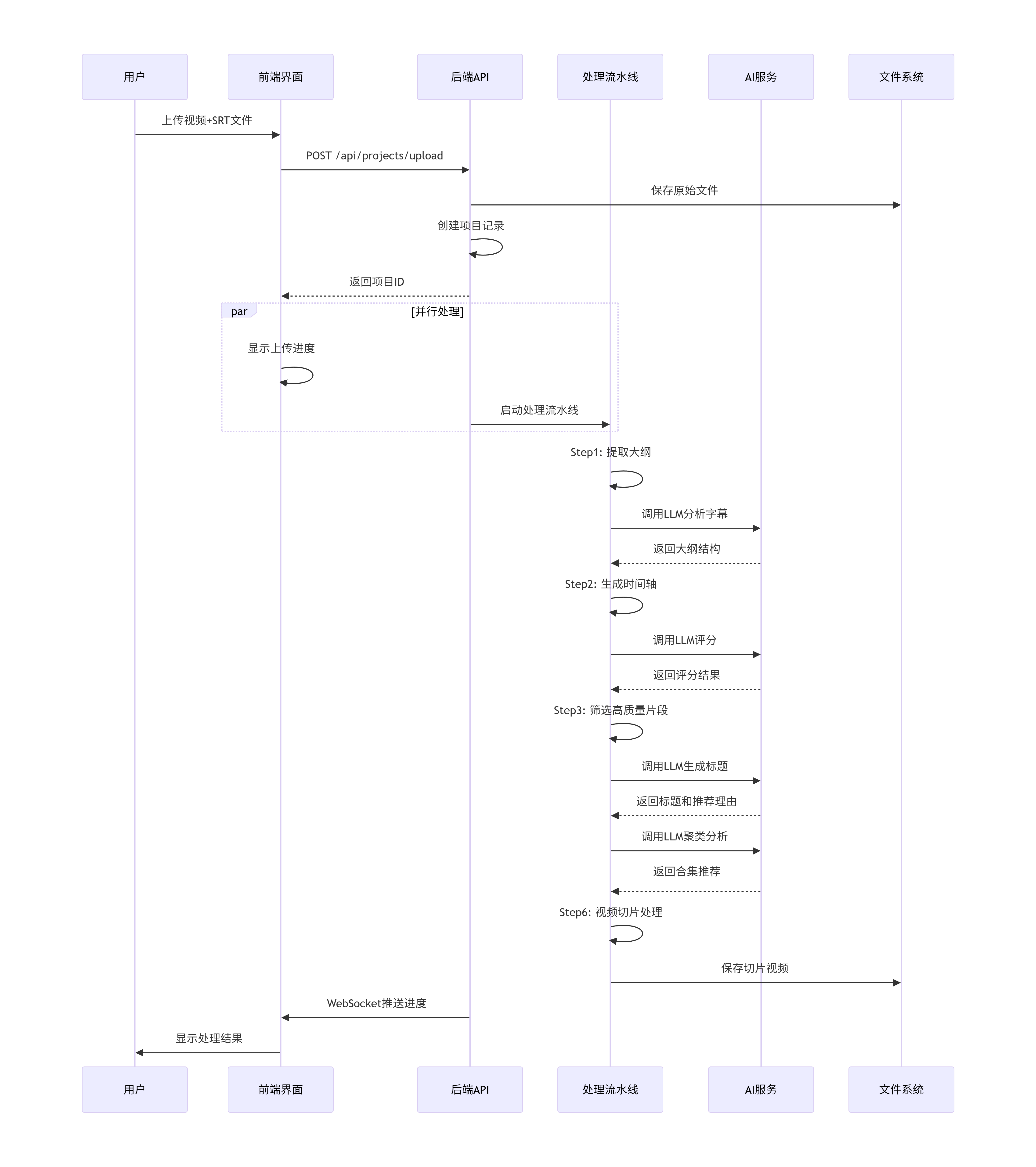
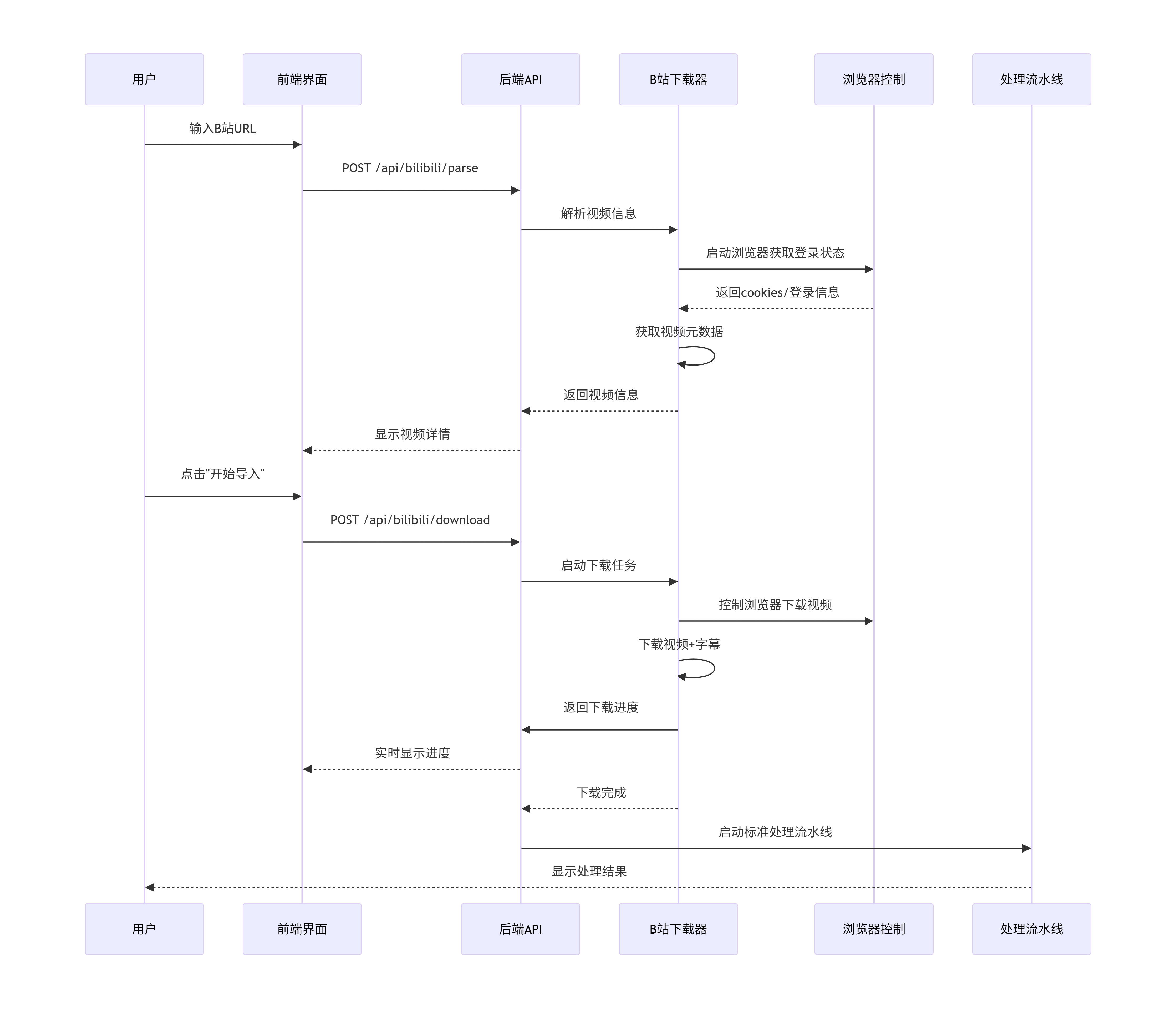

2.3 autoclip存在的相关问题
尽管按照步骤完成安装和环境部署,也不一定会成功运行,可能会存在一些其它BUG,例如导入视频文件和字幕文件后,中途出现剪辑失败,或者处理完成找不到对应的视频文件,这有可能是因为没有在目录下创建uploads文件,导致处理后的视频文件无法导出,所有这个问题也是研究半天才发现。
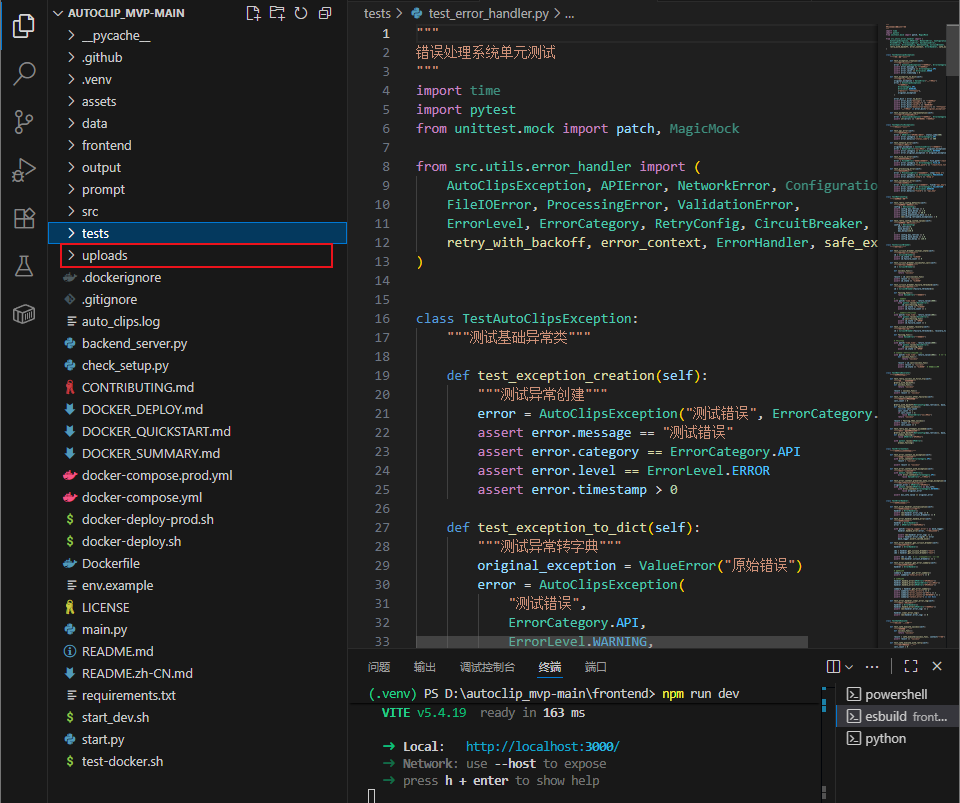
在剪辑过程中需要留意运行日志,有可能会出现运行中途失败跳过现象或者无法进行,有以下几种情况会出现:
- 视频内容过大,时长超2小时(尽量控制在1.5小时左右),任务超时会自动跳过,出现剪辑视频不全。
- 视频字幕内容里有敏感词信息,导致API调用的数据被拦截,无法有效回传,任务失败自动跳过。
- 视频文件过大或者格式不正确。
以上问题可以进行调整,由于该程序是按照每30分钟进行切割,所以视频过长时容易超时,同时30分钟也会加重任务量,可以在step1_completed代码里修改时长。
# 2. 基于时间智能分块
chunks = self.text_processor.chunk_srt_data(srt_data, interval_minutes=30)
logger.info(f"文本已按~30分钟/块切分,共{len(chunks)}个块")将原本30分钟修改到20分钟,也会加快任务进程,避免超时,但是这样也会出现视频切片质量下降问题,导致视频主题不全,需要根据场景适当调整。

关于优化视频的脚本,后续我会上传代码,该脚本的功能是批量处理口播视频间隔,调整音量,过滤敏感词,输出短视频内容的主题说明书,方便运营人员发布参考。
二、IP视频运营综合分析
1、视频号的数据导出与分析
1.1 数据处理
根据任务要求,可以导出近半年或者一个月的视频数据,包含视频号的播放量数据,单视频的动态数据,用户画像等,基于这些数据,可以通过deepseek、qwen、豆包等进行处理。由于数据量的问题,经常会出现数据处理不准确,也可以借助第三方Excel工具,列如:ChatExcel-AI表格处理与数据分析
对于这些数据,我主要对总播放量,公域播放量,私域播放量,用户画像进行数据分析,单视频动态数据可以用来分析内容质量,也可以下载每一个视频进行内容解析。这里我采用的方法如下:
1.1.1 皮尔逊相关系数分析
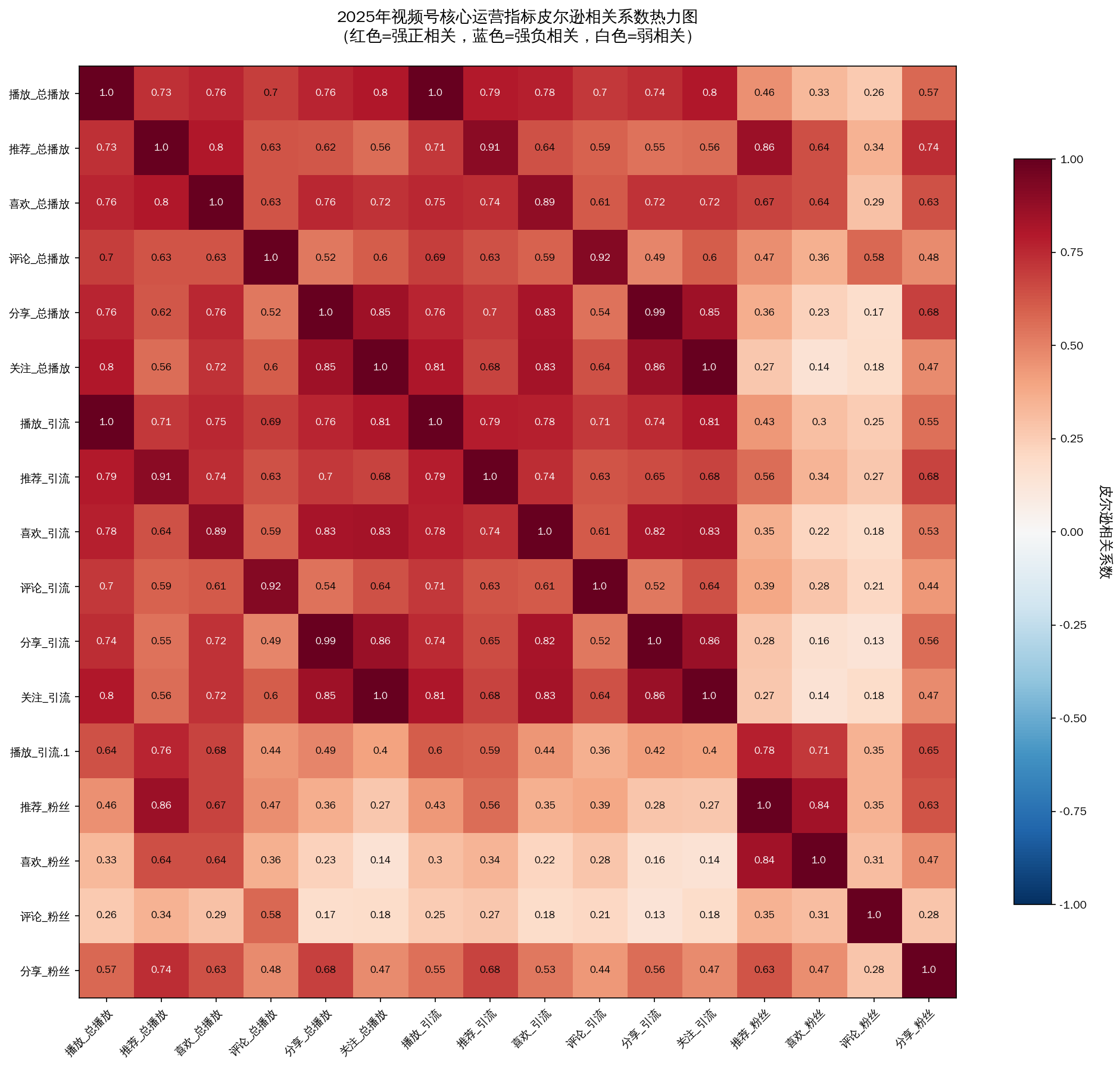
1.1.2 PCA分析
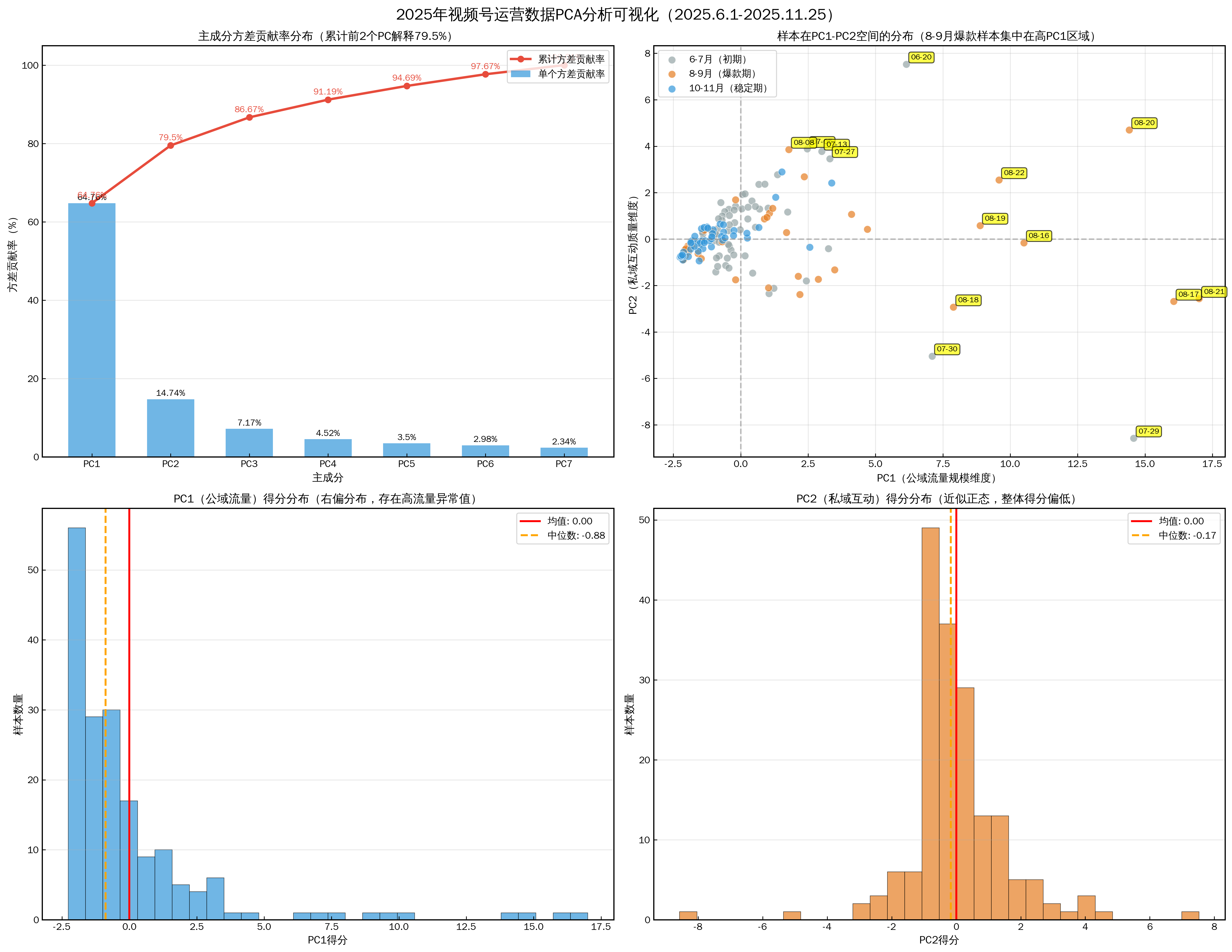
1.1.3线性回归分析
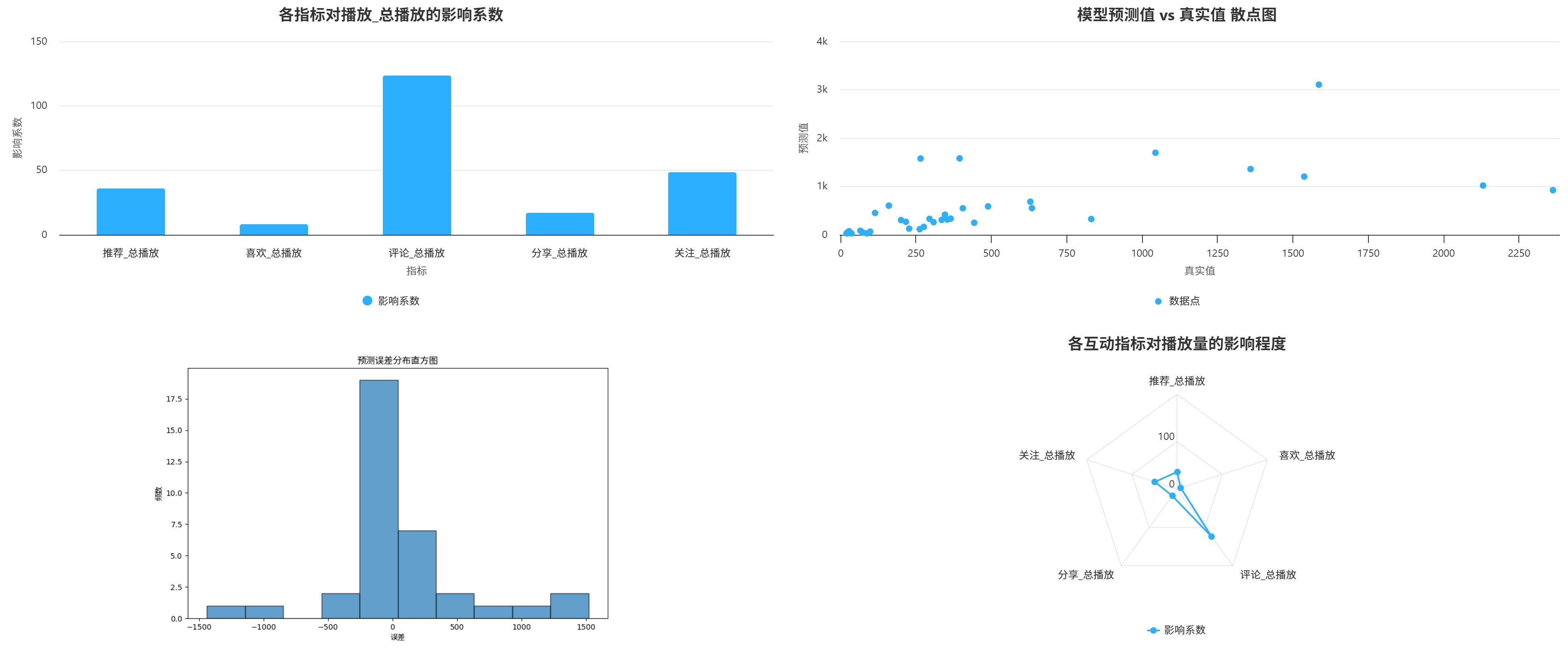
1.1.4 K-means聚类分析
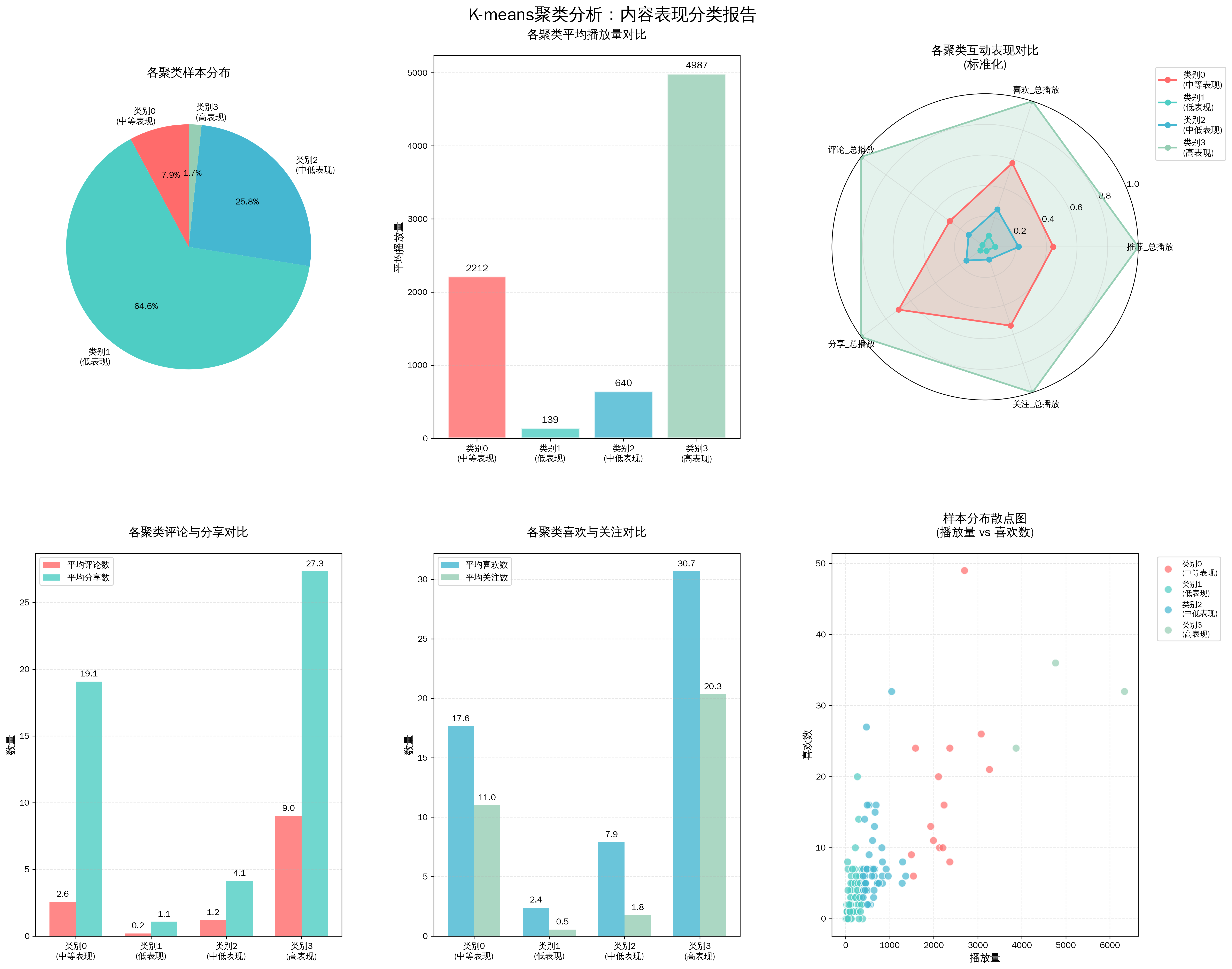
1.1.5爆款与低效内容特征对比分析
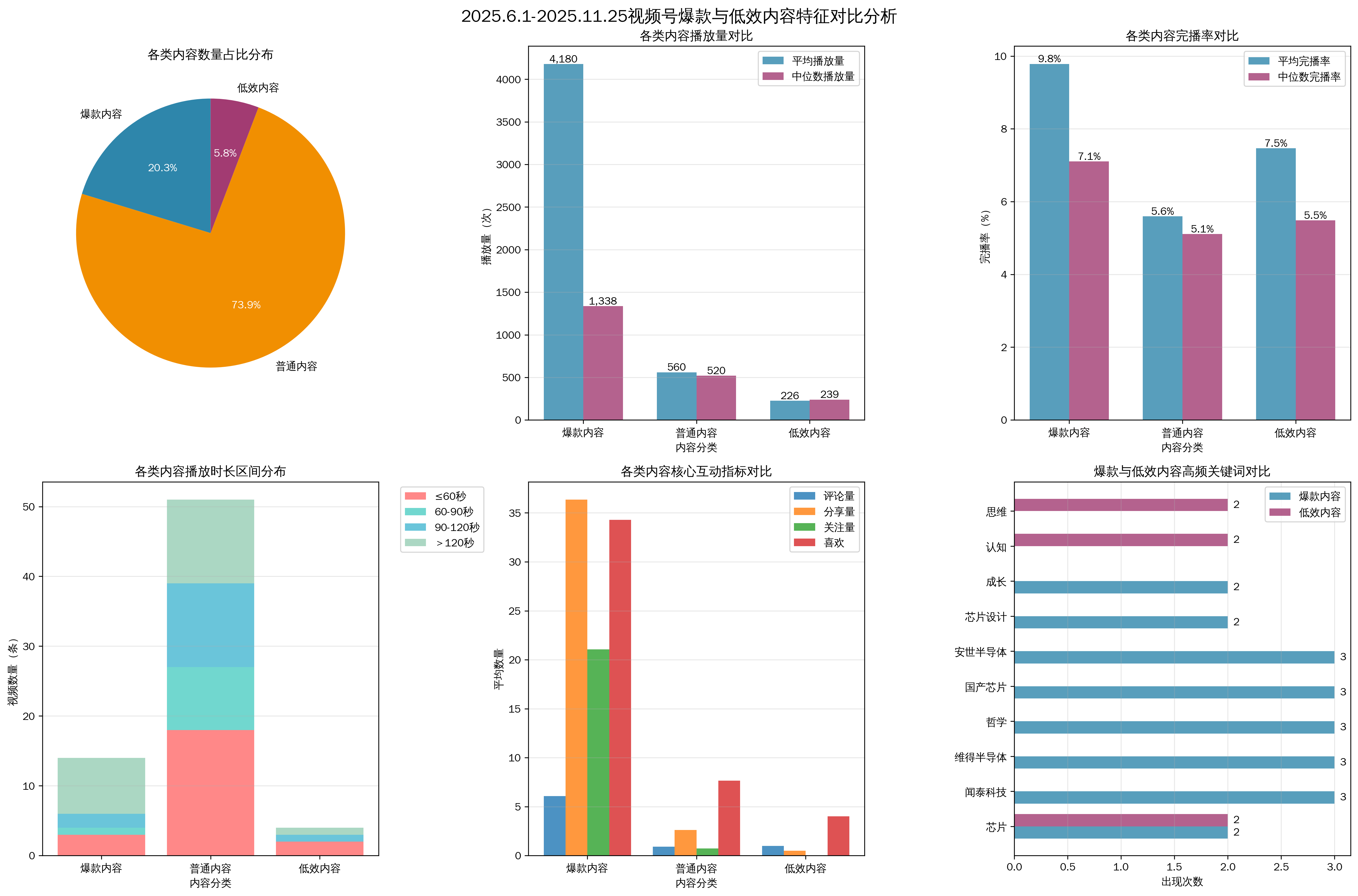
2、短视频SOP运营管理策略
最后根据数据形成完整的报告,可以使用豆包输出完整的SOP运营Word文档,为此该数据已经完成处理分析,同时形成报告,最后依据该数据和报告文档,制定对应的视频运营管理策略,逐步优化后续的视频制作或优化,提高团队的整体质量和效率。
由于目前处于测试阶段,AI的关键还是在于应用层次,只有正式运用,在结合数据反馈来调节和优化。根据我之前的工作情况来看,AI切片可以覆盖大部分类别的视频剪辑。特别在口播类上,如果文案和表达可以更精炼和专业,后续在切片上输出的视频质量就会更高。
以目前高质量的短视频运营来看,矩阵类别是非常需要切片,例如电商行业,教培行业,直播等,通常一个完整的视频运营团队是包含策划、文案、拍摄剪辑、运营、同时也需要数据分析。
团队分工与协助:
|
角色 |
核心职责 |
协作节点 |
|
内容策划 |
选题决策、主题规划、预测模型α值初步确定 |
前期规划阶段 |
|
文案师 |
脚本撰写、互动设计、转化引导植入 |
内容创作阶段 |
|
摄像/剪辑师 |
拍摄制作、时长控制、字幕封面优化 |
内容创作阶段 |
|
内容主管 |
内容审核、质量分级、优化方向决策 |
内容创作、优化迭代阶段 |
|
运营专员 |
发布设置、互动运营、私域转化、日度监测 |
发布运营、运营跟进、数据监测阶段 |
|
数据分析师 |
数据统计、周度报告、模型参数更新 |
数据监测阶段 |
|
运营负责人 |
整体目标把控、跨部门协调、月度复盘决策 |
优化迭代阶段 |
三、AI智能体的建立与优化
1、阿里云平台智能体创建
这里智能体的建立可以采用多种方式,列如本地部署智能体,基于阿里云、基于第三方平台等等,搭配知识库,打造专业用于解决短视频运营的智能体,关于本地部署智能体也可以参考我之前的文章:基于Ollama于D盘安装deepseek-r1到11343漏洞问题_11343端口-CSDN博客
因为之前的工作已经完成,所有对于智能体的搭建和调参也非常重要,这个过程需要大量数据去验证,目前我只做了半年基于视频号的数据分析,所以得出的分析和评估不是非常准确。
2、短视频运营的核心预测模型
基于现在的人工和时间来说,一两个人是很难来运行这么庞大的架构,包括短视频的运营也一样,在没有团队初期,进行分析和预测是非常必要的,这能有效在短视频运营时做出更好的决策,列如在追求数量时,质量会下降,所以要在保证质量平衡基础上规划好剪辑的数量和时间,避免人力和时间的浪费同时,也能保证短视频的有效运营。
模型的核心定位是适用于长期决策与效果评估,整合「人力约束、剪辑质量、平台规则」三大固定变量,仅通过调整「质量投入占比(α)」即可快速预测播放效果,简洁易操作。
2.1 基础变量与固定参数:
|
变量/参数 |
符号 |
取值/范围 |
含义说明 |
|
质量投入占比(决策变量) |
α |
0≤α≤0.5 |
0=纯追数量,0.5=人力承载上限(单视频剪辑≤2.4小时) |
|
日均剪辑总时间(固定人力) |
T日 |
1.32小时/天 |
基于当前人力反推,可根据人力增减调整 |
|
单视频最低剪辑时长 |
t0 |
1.2小时/条 |
无额外质量投入时的基础剪辑耗时 |
|
平台连续发布奖励系数 |
K |
1.3(稳定发布≥20天)/ 0.7(断更≥7天) |
根据账号发布稳定性切换 |
|
质量边际效益系数 |
β |
118 |
基于11月数据拟合,α每提升0.1,单视频播放量增加约118次 |
|
最低单视频播放量 |
Ymin |
368次/条 |
纯数量无质量时的基础流量,基于500低平均值 |
2.2 三大核心预测公式
以下是我基于之前的数据分析拟合的公式,可以借鉴参考,用于短视频运营的拟合和预测,方便后续工作中提供决策参考。
1. 日均发布数量预测(N:条/天)
- 完整公式:
含义:质量投入越高,单条剪辑耗时越长,日均发布数量越少。
2. 单视频平均播放量预测(Y:次/条)
- 完整公式:
- 含义:质量投入(主题适配、互动设计、字幕优化)越高,单视频播放量越高。
3. 任意周期累计总播放量预测(S:次)
- 完整公式:
- 含义:整合周期长度、发布数量、播放质量,直接预测总效果。
四、整体的架构
1、四模块闭环系统详解

模块1:AI智能切片模块
-
输入:原始视频素材 + SRT字幕
-
处理:基于大模型的智能识别与精准切割
-
输出:优化后的可发布视频片段
-
特色:AI驱动的自动化内容处理流水线
模块2:IP视频运营综合分析模块
-
功能:多平台数据采集与深度分析
-
分析方法:
-
相关性分析(皮尔逊系数)
-
主成分分析(PCA降维)
-
线性回归预测
-
K-means聚类分组
-
-
产出:数据驱动的运营洞察
模块3:SOP运营管理策略模块
-
输入:数据分析结论
-
处理:策略制定与标准化
-
输出:可复用的运营流程模板
-
目标:建立系统化、标准化的运营体系
模块4:AI智能体模块
-
基础:知识库构建与整合
-
核心:智能体训练与部署
-
功能:自动化决策与执行
-
目标:形成自学习、自优化的智能系统
2、闭环优化机制
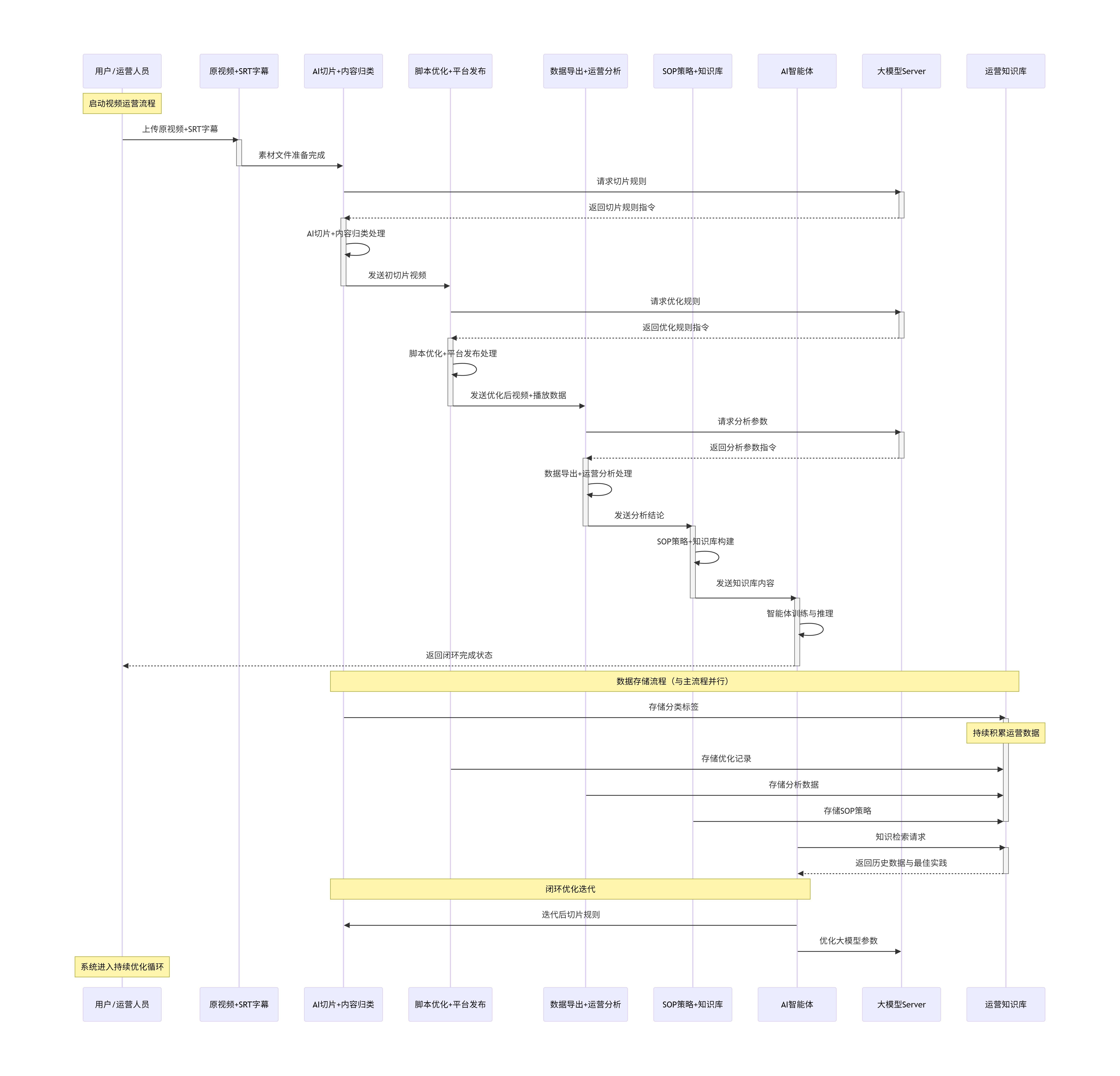
双向反馈通道
-
正向流:AI切片 → 发布运营 → 数据分析 → SOP策略 → AI智能体
-
反向流:AI智能体 → SOP策略 → 数据分析 → AI切片
-
交叉流:各模块之间的直接交互与优化
数据知识库作用
-
统一存储:集中管理运营数据与策略知识
-
知识检索:支持智能体的快速决策
-
历史追溯:记录完整的优化迭代过程
-
版本控制:管理不同版本的策略与模型
系统优势
-
自学习能力:随着数据积累,系统不断优化
-
自适应调整:根据效果反馈自动调整参数
-
规模化复制:成功模式可快速应用到新IP
-
全链路优化:从内容生产到运营分析的全流程优化
-
智能决策支持:AI智能体提供数据驱动的决策建议
总结
关于该模型的探索与应用,持续将近4个月,初期是为了赋能短视频运营,解决因人员不足导致短视频运营效率问题,目前还在持续优化中,也在寻求更高效的方法,希望志同道合的人士可以一起探讨,也可关注视频号AICDragon,在AI领域探索更好的应用,为个人、团队、企业赋能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)