RL和RLHF框架超详细解析
传统的机器学习范式,智能体通过与环境交互,根据奖励信号学习最优策略。RL的一个特殊应用,专门用于训练大语言模型,奖励信号来源于人类的偏好反馈。: RLHF = RL + Reward Model(学习人类偏好)另外,传统RL的状态:是具体的环境状态(- Atari游戏: 84x84像素图像- 机器人: 关节角度向量 )动作是明确的控制指令 (-游戏: {上, 下, 左, 右} - 机器人: 每个关
1. 概述
RL (Reinforcement Learning - 强化学习)
传统的机器学习范式,智能体通过与环境交互,根据奖励信号学习最优策略。
RLHF (Reinforcement Learning from Human Feedback - 基于人类反馈的强化学习)
RL的一个特殊应用,专门用于训练大语言模型,奖励信号来源于人类的偏好反馈。
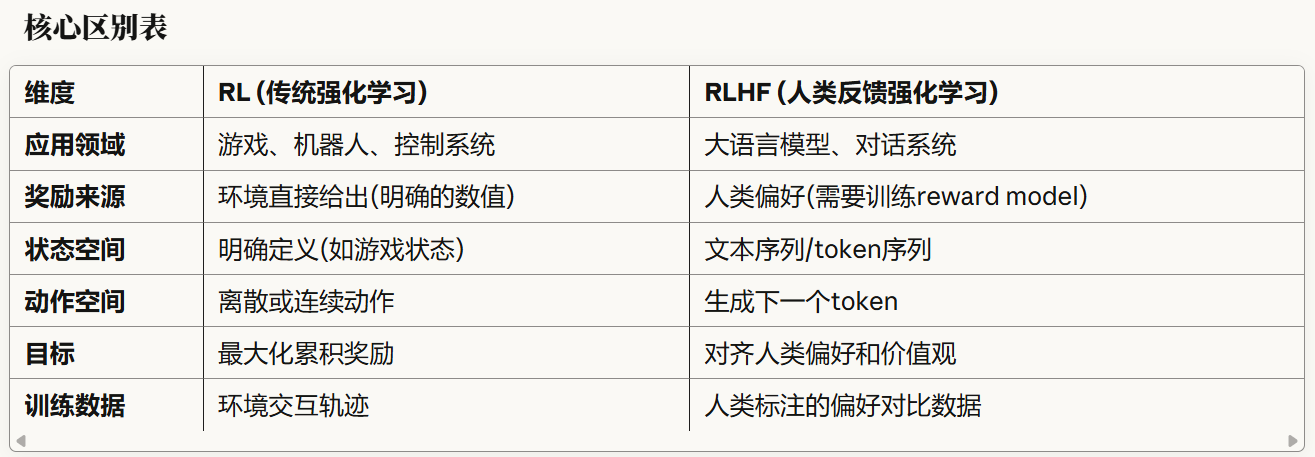
可以看出,RL奖励直接来自环境,而RLHF需要奖励模型:
# 收集有限的人类偏好对比数据
human_data = [
("prompt1", "回答A更好"),
("prompt2", "回答B更好"),
...
]
# 训练Reward Model学习人类偏好模式
reward_model.train(human_data)
# 之后可以自动给任意回答打分
score = reward_model(prompt, any_response)核心理解: RLHF = RL + Reward Model(学习人类偏好)
另外,传统RL的状态:是具体的环境状态(- Atari游戏: 84x84像素图像 - 机器人: 关节角度向量 )动作是明确的控制指令 (-游戏: {上, 下, 左, 右} - 机器人: 每个关节的力矩值)
而RLHF的状态是当前生成的token序列 (- [今天, 天气, 很] ← 当前状态), 动作:是选择下一个token (- 词表中的任意token (如50000个选项) - 选择"好" → [今天, 天气, 很, 好])
2. RL
一个智能体它采取行动给环境,环境给他新的奖励和新的状态,这个智能体根据他所受的奖励和新的状态,来采取下一步的行动形成一个闭环,这就是强化学习。
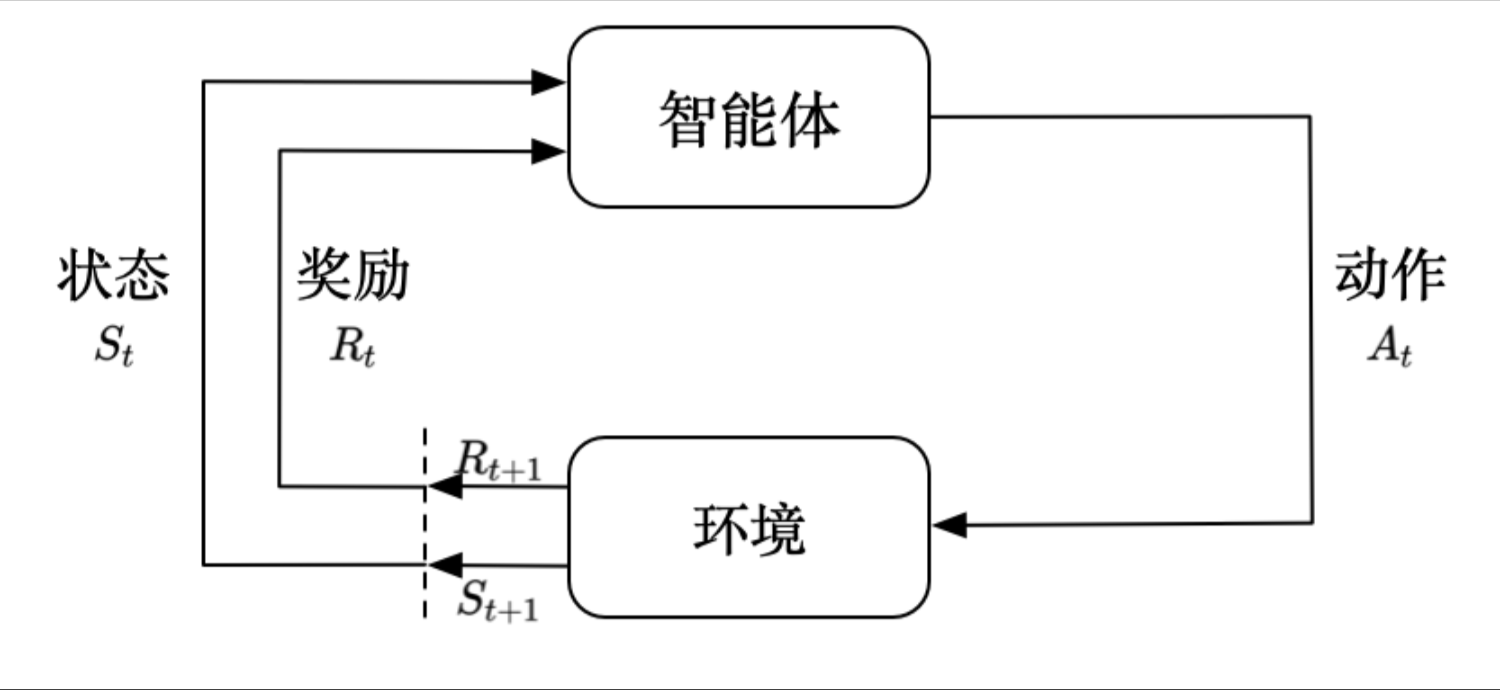
# 传统RL伪代码
for episode in episodes:
state = env.reset()
while not done:
action = policy(state) # 智能体选择动作
next_state, reward, done = env.step(action) # 环境给出明确奖励
# 奖励是明确的数值
# 比如: +1(得分), -1(失败), +10(胜利)
update_policy(state, action, reward)
state = next_state3. RLHF
RLHF (训练ChatGPT):
第一阶段: 监督微调 (SFT)
├─ 人类标注高质量示例
└─ 训练基础模型
第二阶段: 训练奖励模型 (Reward Model)
├─ 人类标注偏好对比数据
│ (给定prompt,比较回答A vs 回答B,哪个更好)
├─ 训练Reward Model学习人类偏好
└─ Reward Model可以给任意回答打分
第三阶段: 强化学习优化 (RL/GRPO/PPO)
├─ LLM生成多个候选回答
├─ Reward Model给每个回答打分 ← 这里用的RL
├─ 根据分数更新LLM策略
└─ 让LLM生成更符合人类偏好的回答# RLHF伪代码
# 阶段1: 训练Reward Model (关键!)
for prompt, (response_good, response_bad) in human_preference_data:
score_good = reward_model(prompt, response_good)
score_bad = reward_model(prompt, response_bad)
loss = -log(sigmoid(score_good - score_bad)) # 偏好学习
update_reward_model(loss)
# 阶段2: 用RL优化LLM
for prompt in training_data:
# 生成多个候选
responses = llm.generate(prompt, n=4) # Rollout
# Reward Model打分 (替代环境奖励)
rewards = [reward_model(prompt, r) for r in responses]
# RL优化 (PPO/GRPO)
update_llm_policy(responses, rewards)4.GRPO流程

1. 预处理阶段 (Preprocessing)
- 准备训练数据集,包括文本和图像
- 对数据进行清洗、格式化
- 图像处理:调整大小、归一化
- 文本tokenization
- 构建数据加载器
2. 训练阶段 (Training)
这是主循环,包含多个子步骤:
a) Roll 阶段 (Rollout/采样阶段)
- 使用当前策略模型对训练数据进行推理
- 生成多个响应候选 (比如每个prompt生成4-8个不同的回答)
- 这个过程叫"rollout"因为模型在"展开"生成可能的轨迹
b) Reward 计算阶段
- 对生成的所有候选响应计算奖励分数
- 可能使用reward model或其他评价标准
- 在GRPO中,通过组内比较计算相对优势
c) 策略更新阶段(Policy Update)
- 根据reward信号更新模型参数
- GRPO使用组相对优势来优化策略
- 使用梯度下降更新模型权重
3. 测试/验证阶段 (Testing/Validation)
- 在训练过程中定期评估模型性能
- 使用独立的验证集
- 计算各种指标(准确率、奖励均值等)
4. 推理阶段 (Inference)
- 训练完成后,使用最终模型进行预测
- 也在训练的roll阶段中使用
- 生成最终的输出结果
5. 采用vllm推理框架的多模态大模型
整体流程:
├─ 预处理阶段
│ ├─ 图像预处理 (PIL/torchvision)
│ ├─ 文本tokenization (transformers)
│ └─ 构建多模态数据batch
│
├─ 训练阶段 (循环迭代)
│ │
│ ├─ Roll/Rollout阶段 ← ★ vLLM主要在这里! ★
│ │ ├─ 输入: 多模态prompt (图像+文本)
│ │ ├─ vLLM推理引擎:
│ │ │ ├─ 视觉编码器处理图像
│ │ │ ├─ LLM处理文本+视觉token
│ │ │ └─ 批量生成多个候选响应
│ │ └─ 输出: N个候选回答
│ │
│ ├─ Reward计算阶段
│ │ └─ 对vLLM生成的候选打分
│ │
│ ├─ GRPO优化阶段
│ │ ├─ 计算loss (基于reward)
│ │ ├─ 反向传播 (PyTorch/DeepSpeed)
│ │ └─ 更新Qwen2.5-VL模型权重
│ │
│ └─ 测试阶段
│ └─ 也可能用vLLM快速评估
│
└─ 最终推理阶段
└─ vLLM部署推理服务其中vllm主要用途:Rollout阶段的快速推理
# 伪代码示例
for epoch in training_epochs:
for batch in dataloader:
# ===== vLLM在这里工作 =====
# 输入: 多模态数据
images = batch['images'] # [B, C, H, W]
prompts = batch['prompts'] # ["描述这张图", ...]
# vLLM批量生成候选
candidates = vllm_engine.generate(
prompts=prompts,
images=images, # 多模态输入
n=4, # 每个prompt生成4个候选
temperature=0.7
)
# 输出: [B, 4, seq_len] 的候选响应
# ===== vLLM工作结束 =====
# 计算reward
rewards = reward_model(candidates)
# GRPO更新模型 (使用PyTorch)
loss = compute_grpo_loss(candidates, rewards)
loss.backward()
optimizer.step()输入输出流:
# vLLM处理多模态的流程
vLLM推理过程:
1. 图像输入 → Vision Encoder (如ViT)
└─ 输出: 图像token embeddings
2. 文本输入 → Text Tokenizer
└─ 输出: 文本token ids
3. 融合 → Qwen2.5-VL主模型
├─ 拼接图像token和文本token
└─ Transformer处理
4. 生成 → LLM解码
└─ 输出: 生成的文本响应
6. 基于verl框架的流程:
veRL框架结构:
┌─────────────────────────────────────┐
│ veRL Coordinator │ ← 总控制器
│ (管理整个RLHF训练流程) │
└─────────────────────────────────────┘
│
├─→ Actor Pool (策略模型池)
│ ├─ Ray Workers
│ └─ vLLM Engine ← vLLM在这里
│
├─→ Critic Pool (评价模型池)
│ └─ Reward Model Workers
│
└─→ Trainer (参数更新)
├─ FSDP分布式训练
└─ GRPO/PPO优化器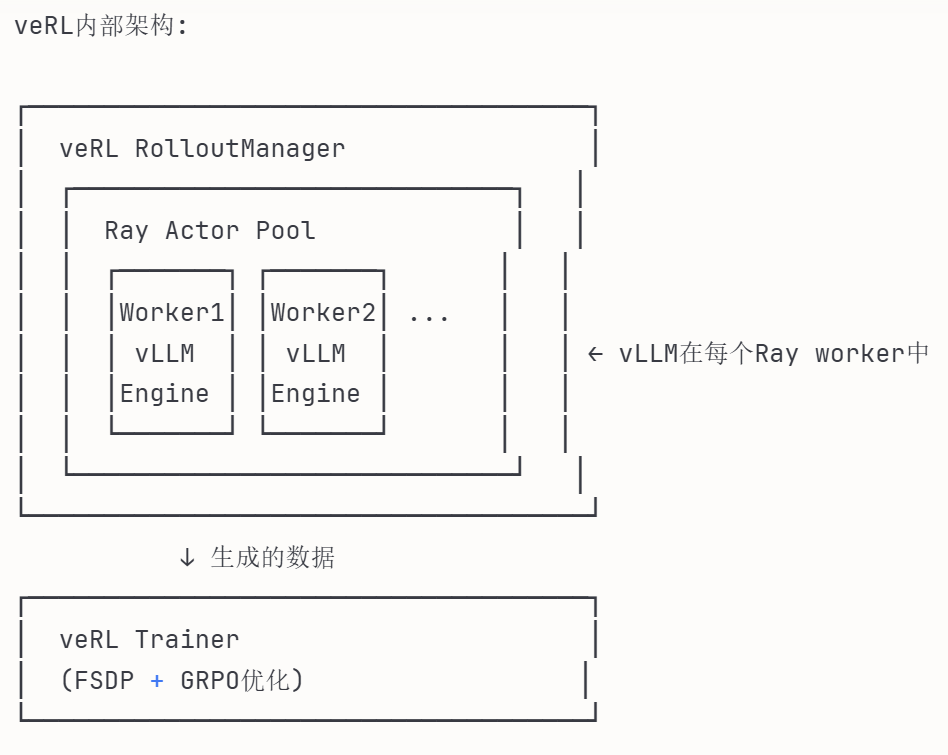
7.实例:在mmsearch-r1中:
流程:
- 预处理: 加载parquet数据,处理图像和文本
- 训练: 使用Ray + vLLM进行分布式训练
- Roll: vLLM执行快速批量推理生成候选
- Reward: 计算生成质量的奖励信号
- GRPO: 根据组相对奖励更新Qwen2.5-VL模型
- 测试: 定期在验证集上评估
关键点: Roll和推理本质上是同一个操作(模型生成),但在不同阶段有不同目的:
- 训练中的roll是为了采样和学习
- 最终推理是为了实际应用
├─ Ray: 分布式训练协调
│ ├─ 管理多个GPU节点
│ └─ 分发数据和任务
│
├─ vLLM: Rollout推理引擎
│ ├─ 接收Ray分发的batch
│ ├─ 在A800 GPU上快速推理
│ └─ 生成候选响应返回
│
└─ PyTorch/FSDP: 训练后端
├─ 接收vLLM生成的数据
├─ 计算GRPO loss
└─ 更新Qwen2.5-VL参数
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)