04章 程序流控制 - “Vega“ 7nm Instruction Set ArchitectureReference Guide
当多个wavefront在一个工作组中时,可以使用S_BARRIER指令强制每个wavefront等待,直到所有其他wavefront到达相同的指令;任何wavefront都可以使用S_ENDPGM提前终止,当剩余的活跃wave到达其屏障指令时,屏障被视为已满足。在这些情况下,程序必须插入S_WAITCNT指令,以确保在继续之前先前的操作已完成。着色器有三个计数器,跟踪已发出指令的进度。相同类型的
所有程序流控制均使用标量ALU指令进行编程。这包括循环、分支、子程序调用和陷阱。程序使用 SGPR 存储分支条件和循环计数器。常量可以直接从标量常量缓存获取到 SGPR 中。
4.1 程序控制
下表中的指令控制着色器程序的优先级和终止,并为陷阱处理程序提供支持。
表6 控制指令
| 指令 | 描述 |
|---|---|
| S_ENDPGM | 终止wavefront。可出现在内核中的任意位置,并可出现多次。 |
| S_ENDPGM_SAVED | 由于上下文保存而终止wavefront。可出现在内核中的任意位置,并可出现多次。 |
| S_NOP | 空操作;可在硬件中重复最多八次。 |
| S_TRAP | 跳转到陷阱处理程序。 |
| S_RFE | 从陷阱处理程序返回 |
| S_SETPRIO | 修改此 wavefront 的优先级:0=最低,3=最高。 |
| S_SLEEP | 使 wavefront 休眠64-960个时钟周期。 |
| S_SENDMSG | 向主机 CPU 发送消息(通常是中断)。 |
4.2 分支
使用以下标量 ALU 指令之一进行分支操作。
表7 分支指令
| 指令 | 描述 |
|---|---|
| S_BRANCH | 无条件地分支。【注,无条件跳转,goto之意】 |
| S_CBRANCH_<test> | 条件分支。仅当<test>为真时分支。测试条件包括VCCZ、VCCNZ、EXECZ、EXECNZ、SCCZ和SCCNZ。 |
| S_CBRANCH_CDBGSYS | 条件分支,如果 COND_DBG_SYS 状态位被设置则执行。【注,系统模式的条件调试指示器】 |
| S_CBRANCH_CDBGUSER | 条件分支,如果 COND_DBG_USER 状态位被设置则执行。【注,用户模式的条件调试指示器】 |
| S_CBRANCH_CDBGSYS_AND_USER | 条件分支,仅当 COND_DBG_SYS 和 COND_DBG_USER 都被设置时执行。 |
| S_SETPC | 直接从 SGPR 对 设置 PC。 |
| S_SWAPPC | 将当前 PC 与 SGPR对 中的地址交换。 |
| S_GETPC | 获取当前 PC 值(不引起分支)。 |
| S_CBRANCH_FORK和S_CBRANCH_JOIN | 复杂分支的条件分支。 |
| S_SETVSKIP | 设置一个位,使所有向量指令被忽略。是分支的有用替代方案。 |
| S_CALL_B64 | 跳转到子程序,并保存返回地址。SGPR对 = PC+4;PC=PC +4+SIMM16*4。 |
对于条件分支,分支条件可由标量或向量操作确定。标量比较操作设置标量条件码(SCC【注,1bit】),然后可用作条件分支条件。向量比较操作设置 VCC 掩码【注,64bits,一个按线程分布的位掩码;保存向量比较操作的结果 】,然后可使用 VCCZ 或 VCCNZ 来确定分支。
4.3 工作组
工作组是在同一计算单元(CU)上运行的 wavefront 【注,warp】的集合,可以同步和共享数据。最多 16 个 wavefront(1024个 work-items )可以组合成一个 workgroup。当多个 wavefront 在一个工作组中时,可以使用 S_BARRIER 指令强制每个 wavefront 等待【注,__syncthreads(),block 层别的同步】,直到所有其他 wavefront 到达相同的指令;然后所有 wavefront 继续执行。任何 wavefront 都可以使用 S_ENDPGM 提前终止,当剩余的活跃 waves 到达其屏障指令时,屏障被视为已满足【注,剩余的 VS 活跃的waves,是等价关系么?是否存在剩余但不活跃的 waves 呢?】。
4.4 数据依赖解析
着色器硬件解析大多数数据依赖,但少数情况必须由着色器程序明确处理。在这些情况下,程序必须插入 S_WAITCNT 指令,以确保在继续之前先前的操作已完成。
着色器有三个计数器,跟踪已发出指令的进度。S_WAITCNT等待这些计数器的值达到或低于指定值后才继续执行。
这允许着色器编写者调度长延迟指令、执行不相关的工作,并指定何时需要长延迟操作的结果。
给定类型的指令按顺序返回,但不同类型的指令可以乱序完成。例如,GDS和LDS指令都使用LGKM_cnt,但它们可以乱序返回。
-
VM_CNT:向量内存计数。
确定内存读取何时已将数据返回到VGPR,或内存写入何时已完成。-
每次发出向量内存读取或写入(MIMG、MUBUF或MTBUF格式)指令时递增。
-
读取时当数据已写回VGPR时递减,写入时当数据已写入L2缓存时递减。
排序:内存读取和写入按发出顺序返回,包括混合读取和写入。
-
-
LGKM_CNT:(LDS、GDS、(K)常量、(M)消息)确定这些低延迟指令何时已完成。
-
每次发出的LDS或GDS指令递增1,标量内存读取按Dword计数递增。例如,s_memtime计为s_load_dwordx2。
-
LDS/GDS读取或带返回的原子操作当数据已返回到VGPR时递减1。
-
每个S_SENDMSG发出时递增1。消息发出时递减1。
-
LDS/GDS写入当数据已写入LDS/GDS时递减1。
-
从数据缓存(SMEM)返回的每个Dword递减1。
排序:-
不同类型的指令乱序返回。
-
相同类型的指令按发出顺序返回,除了标量内存读取,它们可以乱序返回(在这种情况下只有S_WAITCNT 0是唯一合法值)。
-
-
-
EXP_CNT:VGPR导出计数。
确定数据何时已从VGPR读出并发送到GDS,此时可以安全地覆盖该VGPR的内容。-
当从wavefront缓冲区发出Export/GDS指令时递增。
-
导出/GDS当导出指令的最后一个周期被授予并执行时递减(VGPR读出)。
排序:-
导出仅在每种导出类型(颜色/空、位置、参数缓存)内保持顺序。
-
-
4.5 手动插入的等待状态(NOPs)
硬件不检查以下依赖关系;必须通过插入NOP或独立指令来解析它们。
表8 需要软件插入的等待状态
| 第一条指令 | 第二条指令 | 等待周期 | 备注 |
|---|---|---|---|
| S_SETREG <*> | S_GETREG <相同寄存器> | 2 | |
| S_SETREG <*> | S_SETREG <相同寄存器> | 2 | |
| SET_VSKIP | S_GETREG MODE | 2 | 从MODE读取VSKIP。 |
| S_SETREG MODE.vskip | 任何向量操作 | 2 | 需要两个nop或非向量指令。 |
| 设置VCC或EXEC的VALU | 使用EXECZ或VCCZ作为数据源的VALU | 5 | |
| 写入SGPR/VCC的VALU(readlane、cmp、add/sub、div_scale) | 使用该SGPR/VCC作为通道选择的V_{READ,WRITE}LANE | 4 | |
| 写入VCC的VALU(包括v_div_scale) | V_DIV_FMAS | 4 | |
| FLAT_STORE_X3 FLAT_STORE_X4 FLAT_ATOMIC_{F}CMPSWAP_X2 BUFFER_STORE_DWORD_X3 BUFFER_STORE_DWORD_X4 BUFFER_STORE_FORMAT_XYZ BUFFER_STORE_FORMAT_XYZW BUFFER_ATOMIC_{F}CMPSWAP_X2 IMAGE_STORE_* > 64 bits IMAGE_ATOMIC_{F}CMPSWAP > + 64bits |
从这些指令写入持有写入数据的VGPR。 | 1 | 使用SGPR作为"offset"的BUFFER_STORE_操作不需要任何等待状态。设置超过两个DMASK位的IMAGE_STORE_和IMAGE_{F}CMPSWAP*操作需要这一个等待状态。使用256位T#的操作不需要等待状态。 |
| 写入SGPR的VALU | 读取该SGPR的VMEM | 5 | 硬件假设这里没有依赖关系。如果VALU写入VMEM使用的SGPR,用户必须添加五个等待状态。 |
| 写入M0的SALU | GDS、S_SENDMSG或S_TTRACE_DATA | 1 | |
| 写入VGPR的VALU | 读取该VGPR的VALU DPP | 2 | |
| 写入EXEC的VALU | VALU DPP操作 | 5 | ALU不将EXEC转发到DPP。 |
| VCC的混合使用:别名vs SGPR# v_readlane, v_readfirstlane v_cmp v_addi/u v_sub_i/u v_div_scale*(写入vcc) |
将VCC作为常量读取的VALU(不作为进位输入,进位输入为0等待状态)。 | 1 | VCC可以通过名称或通过持有VCC的逻辑SGPR访问。数据依赖检查逻辑不理解这些是相同的寄存器,并且不防止竞争。 |
| S_SETREG TRAPSTS | RFE、RFE_restore | 1 | |
| 写入M0的SALU | LDS "add-TID"指令、buffer_store_LDS_dword、带有LDS=1的scratch或global、VINTERP或LDS_direct | 1 | |
| 写入M0的SALU | S_MOVEREL | 1 |
4.6 任意发散控制流
在GCN架构中,条件分支通过以下方式之一处理:
-
S_CBRANCH:这种情况用于简单的控制流,其中是否执行分支基于先前的比较操作。这是条件分支最常见的方法。
-
S_CBRANCH_I/G_FORK和S_CBRANCH_JOIN:这种方法用于复杂的、不可简化的控制流图,在本节其余部分描述。这种方法在简单流控制上的性能低于S_CBRANCH;仅在必要时使用。
条件分支(CBR)图被分组为自包含的代码块,由入口点的FORK和出口点的JOIN表示。着色器编译器必须将这些指令添加到代码中。此方法使用六层深的堆栈,每个fork/join块需要三个SGPR。Fork/Join块可以分层嵌套到任意深度(受SGPR要求限制);它们也可以与其他条件流控制或计算跳转共存。
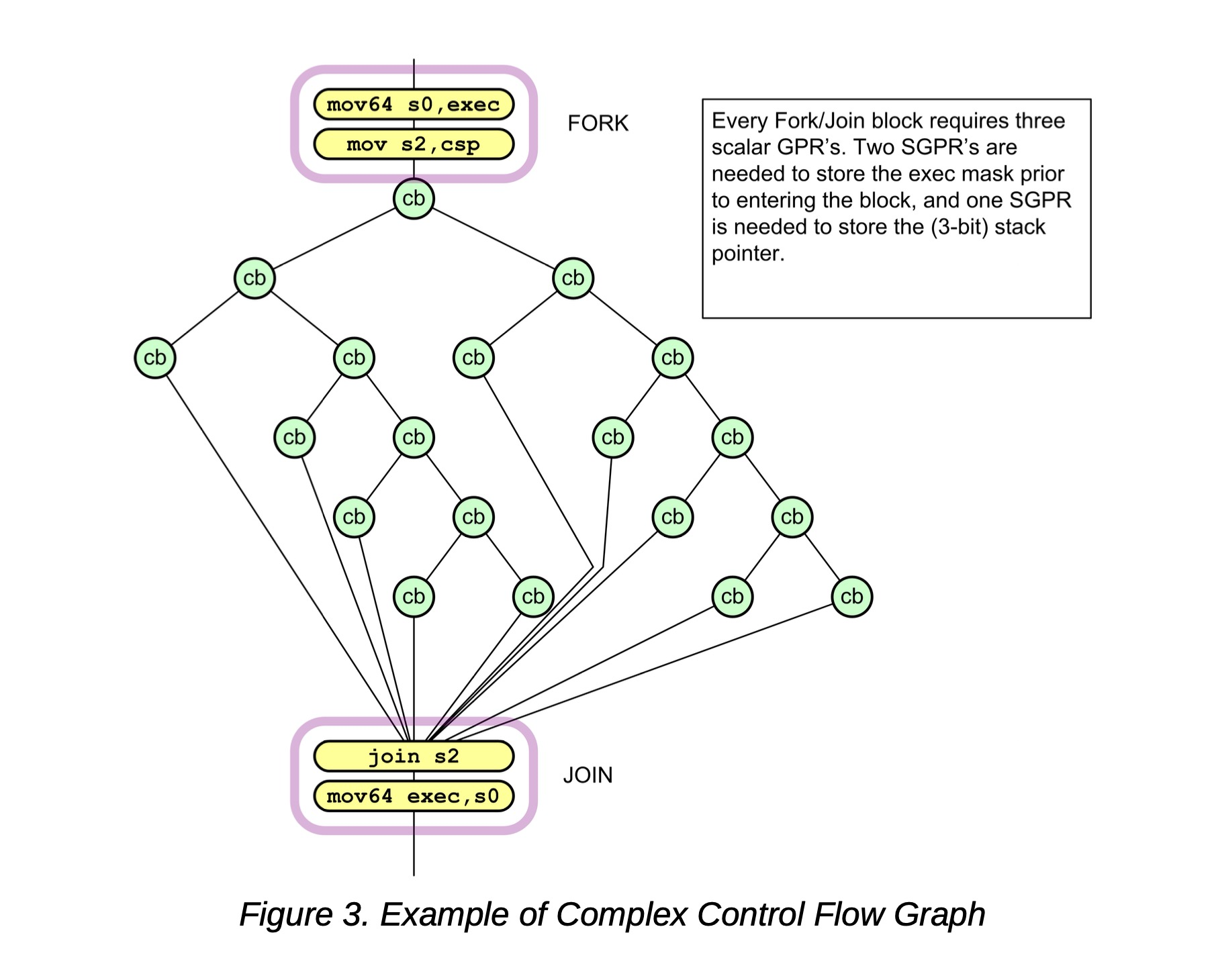
每个wavefront的寄存器要求:
-
CSP [2:0] - 控制堆栈指针。
-
六个堆栈条目,每个128位,存储在SGPR中:{ exec[63:0], PC[47:2] }
此方法比较64个线程中有多少沿着PASS路径而不是FAIL路径;然后,它首先选择线程数较少的路径。这意味着最多50%的线程是活跃的,这将必要的堆栈深度限制为Log₂64 = 6。
以下伪代码显示CBRANCH Fork和Join操作的详细信息。
asm
S_CBRANCH_G_FORK arg0, arg1
// arg1是一个SGPR对,持有64位(48位)目标地址
S_CBRANCH_I_FORK arg0, #target_addr_offset[17:2]
// target_addr_offset: 16位有符号立即偏移量
// PC: 在此伪代码中指向cbranch_*_fork指令
mask_pass = SGPR[arg0] & exec
mask_fail = ~SGPR[arg0] & exec
if (mask_pass == exec)
I_FORK: PC += 4 + target_addr_offset
G_FORK: PC = SGPR[arg1]
else if (mask_fail == exec)
PC += 4
else if (bitcount(mask_fail) < bitcount(mask_pass))
exec = mask_fail
I_FORK: SGPR[CSP*4] = { (pc + 4 + target_addr_offset), mask_pass }
G_FORK: SGPR[CSP*4] = { SGPR[arg1], mask_pass }
CSP++
PC += 4
else
exec = mask_pass
SGPR[CSP*4] = { (pc+4), mask_fail }
CSP++
I_FORK: PC += 4 + target_addr_offset
G_FORK: PC = SGPR[arg1]
S_CBRANCH_JOIN arg0
if (CSP == SGPR[arg0]) // SGPR[arg0]持有FORK开始时的CSP值
PC += 4 // 这是第二次JOIN:继续执行程序
else
CSP-- // 这是第一次JOIN:跳转到其他FORK路径
{PC, EXEC} = SGPR[CSP*4] // 从4个连续的SGPR读取128位
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)