人机共读:AI时代下阅读与写作的新可能
【摘要】探讨生成式AI对阅读与写作的重塑。分析AI在提升信息获取效率的同时,如何挑战人类的深度思考与原创能力,并提出人机协同下的新范式与应对策略。
【摘要】探讨生成式AI对阅读与写作的重塑。分析AI在提升信息获取效率的同时,如何挑战人类的深度思考与原创能力,并提出人机协同下的新范式与应对策略。

引言
生成式人工智能,特别是大型语言模型(LLM)的崛起,正以前所未有的深度和广度渗透到各个领域。它不再仅仅是效率工具,更像一个认知活动的参与者,直接介入了人类最核心的两项能力,阅读与写作。技术圈内对此讨论热烈。有人视其为颠覆性的生产力革命,有人则担忧它会钝化人类的思维锋芒。
这场变革的核心,并非简单的“机器换人”叙事。它关乎我们如何处理信息、如何构建知识体系、如何进行原创性表达。当一个能够访问并处理海量文本数据的“外部大脑”唾手可得时,我们传统的阅读习惯和写作流程受到了根本性的冲击。本文将从技术架构师的视角,剖析AI技术在阅读与写作领域的应用机制、内在局限,并探讨技术从业者与内容创作者应如何调整自身定位,构建一种全新的人机协同关系。这不仅是适应工具,更是重新定义我们在智能时代的核心价值。
一、范式迁移:AI技术如何重构阅读场域

传统的阅读是一个线性、沉浸且高度个人化的过程。我们通过文字与作者进行跨时空的思想交流。数字时代带来了非线性、碎片化的阅读体验。AI时代则引入了“计算性阅读”的新范式。机器不再只是呈现文本的媒介,它开始主动地“理解”、归纳和重组文本。
1.1 阅读辅助的技术栈解析
AI辅助阅读并非单一技术,而是一个由多种技术构成的复杂系统。理解其底层逻辑,是有效利用它的前提。
1.1.1 从关键词到语义向量的检索革命
传统的搜索引擎依赖关键词匹配(如BM25算法)。这种方式机械,无法理解用户的真实意图。现代AI阅读工具的核心是语义检索。
它的工作流程如下:
-
文本嵌入(Embedding):利用预训练的语言模型(如BERT、Sentence-Transformers)将文本(单词、句子、段落)转化为高维度的数学向量。这些向量在向量空间中的距离,代表了文本在语义上的相似度。
-
向量数据库(Vector Database):将海量文本的向量存储在专门的数据库中(如Milvus、Pinecone)。这类数据库优化了高维空间中的近似最近邻(ANN)搜索,能极快地找到与查询向量最相似的文本向量。
-
查询处理:用户输入自然语言查询后,系统同样将其转化为查询向量,然后在向量数据库中进行高效检索,返回语义最相关的结果。
这种变革意味着,机器不再是匹配字符串,而是在理解概念。你可以问“那些关于软件架构稳定性的原则”,系统会返回包含“熔断”、“幂等性”、“CAP理论”等关键词的文档,即使你的查询中并未出现这些词。
1.1.2 文本摘要的双重路径,抽取与生成
AI“读”完一本书并给出摘要,主要依赖两种技术路径。
-
抽取式摘要(Extractive Summarization):
-
机制:算法(如TextRank,类似PageRank)评估原文中每个句子的重要性,然后挑选出最重要的几个句子,按原文顺序组合成摘要。
-
特点:速度快,保证了信息的准确性,不会产生原文没有的内容。但摘要可能不够连贯,缺乏可读性。
-
应用:适合新闻聚合、快速提取文献核心观点的场景。
-
-
生成式摘要(Abstractive Summarization):
-
机制:基于Seq2Seq架构(如T5、BART、GPT系列)的模型,先通过编码器(Encoder)“理解”全文的语义,然后由解码器(Decoder)用模型自己的“语言”重新生成一段全新的、更简洁的文本来表达核心思想。
-
特点:摘要连贯、流畅,可读性强。但存在“信息幻觉”(Hallucination)的风险,可能生成与原文不符的内容。
-
应用:适合生成报告摘要、内容简介等对可读性要求高的场景。
-
下表对比了两种摘要技术的关键差异。
|
特性维度 |
抽取式摘要 |
生成式摘要 |
|---|---|---|
|
核心机制 |
句子打分与筛选 |
语义理解与文本重构 |
|
模型代表 |
TextRank, LexRank |
T5, BART, GPT |
|
优点 |
忠于原文、速度快、无幻觉 |
连贯性好、可读性强、更简洁 |
|
缺点 |
连贯性差、可能冗余 |
可能产生幻觉、计算成本高 |
|
适用场景 |
文献速览、新闻聚合 |
报告生成、内容创作 |
1.1.3 RAG,让AI“带着书本”回答问题
大型语言模型本身存在知识截止日期和信息幻觉的问题。**检索增强生成(Retrieval-Augmented Generation, RAG)**架构是解决这一问题的关键技术。它将检索系统与生成模型结合,让AI能基于给定的、最新的、权威的资料库进行回答。
RAG的工作流可以用下面的流程图表示:
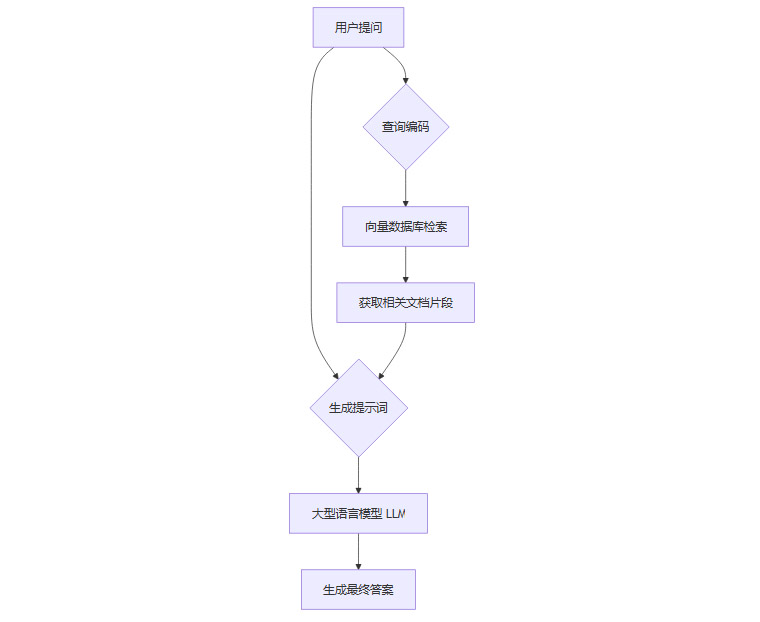
这个流程的本质是,在回答问题前,先帮AI“开卷查书”。它将LLM从一个封闭的“知识库”变成了一个开放的“信息处理引擎”,极大提升了回答的准确性和时效性。这是目前构建企业级知识库、智能客服、AI文档助手的核心架构。
1.2 阅读角色的转变,从乘客到船长
AI技术带来了阅读效率的飞跃,但也伴随着新的风险。作家蓝继红的比喻非常精准,我们不能做被动接受信息的“乘客”,而要做主动驾驭信息的“船长”。
1.2.1 算法推荐与“信息茧房”的技术根源
个性化推荐系统通过分析你的历史行为(点击、停留、收藏)来预测你的兴趣,并推送相关内容。这背后是协同过滤、内容推荐等算法。
-
协同过滤(Collaborative Filtering):“物以类聚,人以群分”。找到与你品味相似的用户,将他们喜欢而你没看过的内容推荐给你。
-
内容推荐(Content-based Filtering):分析你喜欢的内容本身的特征(标签、分类、关键词),然后推荐具有相似特征的其他内容。
这些算法的优化目标通常是最大化用户参与度(Engagement),如点击率或观看时长。这导致系统倾向于推送你已经感兴趣或认同的内容,久而久之,你的信息摄入渠道会越来越窄,形成**“信息茧房”。作为“船长”,我们需要有意识地进行“探索性阅读”**,主动寻找算法推荐范围之外的信息,以维持认知广度。
1.2.2 从深度阅读到“查询式”阅读的认知降级风险
AI工具擅长提供“标准答案”。当你习惯于向AI提问并获得直接答案时,传统的深度阅读过程可能被短路。深度阅读不仅仅是获取信息,它还训练了我们的多种高级认知能力。
-
逻辑推理能力:跟随作者的论证过程,理解其前提、逻辑链和结论。
-
批判性思维:质疑作者的观点,寻找论证的漏洞,形成自己的判断。
-
系统性思考:将书中的知识点与自己已有的知识体系关联、整合,构建更完整的认知框架。
过度依赖“查询式”阅读,可能导致这些能力的萎缩。我们得到的只是孤立的知识点,而非成体系的智慧。因此,将AI作为“快读”的辅助工具,用于快速建立知识框架是可行的。但对于核心、复杂的领域,带有批判性和反思的“慢读”依然不可或缺。
二、代码与诗,生成式AI在写作中的能力边界

生成式AI在内容创作领域的应用,引发了最广泛的讨论。从生成代码、撰写邮件到模仿名家风格进行文学创作,其能力令人惊叹。然而,深入分析其工作原理后,我们会发现它清晰的能力边界。
2.1 AI写作的技术实现与应用场景
LLM的写作能力,本质上是一种基于概率的序列生成。它通过学习海量文本数据,掌握了语言的统计规律。当你给出一个提示词(Prompt),它会预测下一个最可能出现的词(Token),然后将这个新生成的词加入输入序列,再预测下一个,如此循环,直到生成完整的段落。
Transformer架构是这一切的核心,其**自注意力机制(Self-Attention)**允许模型在生成每个词时,都能权衡输入序列中所有词的重要性,从而捕捉长距离的语义依赖关系,生成逻辑连贯的文本。
基于此,AI写作工具在多个场景中展现出巨大价值。
|
应用场景 |
技术要点 |
对创作者的价值 |
|---|---|---|
|
内容初始化 |
根据关键词或大纲生成初稿 |
克服“空白页恐惧”,快速搭建内容框架 |
|
文本润色与改写 |
调整语气、风格,优化表达 |
提升文案专业度与可读性,适应不同发布渠道 |
|
知识检索与整合 |
快速查找资料并整理成文 |
替代繁琐的资料搜集工作,聚焦于观点提炼 |
|
代码生成与辅助 |
根据自然语言描述生成代码片段 |
提升开发效率,降低特定功能实现的技术门槛 |
|
多语言翻译 |
基于NMT(神经机器翻译)模型 |
快速实现内容的跨语言传播 |
2.2 模式化与原创性的根本矛盾
青年作家毕啸南的经历,精准地描绘了人类创作者与AI互动的心路历程,从最初的惊叹,到发现其模式化倾向,再到最终回归自我。这种模式化的根源,深植于AI的技术原理之中。
2.2.1 统计规律的“囚徒”
LLM的生成过程是一个寻找最大概率路径的过程。它倾向于生成在训练数据中最常见、最“平均”的表达方式。这导致其产出内容虽然流畅,但往往缺乏个性和惊喜。它能模仿汪曾祺的笔触,因为它学习了足够多汪曾祺的文本,并抓住了其语言模式。但它无法创造出下一个汪曾祺,因为它无法拥有汪曾祺的生活经历、情感积淀和对世界的独特感知。
AI永远在已知的思想库里做排列组合,而真正的创造力在于突破已知的边界,实现从0到1的飞跃。
2.2.2 缺乏“肉身体验”的符号空转
文学和深度写作的根基,是作者与真实世界的互动。作家刘亮程“拿起镰刀”的比喻,触及了AI创作的另一个根本局限,符号接地(Symbol Grounding)问题。
-
人类:我们语言中的词汇,如“湿漉漉”、“温暖”、“沉重”,都与我们的视觉、触觉、情感等多模态感官体验深度绑定。当我们写下这些词时,背后是真实的生活经验在支撑。
-
AI:AI处理的“湿漉漉”,只是一个与其他词汇(如“雨天”、“眼泪”、“清晨”)在统计上高度相关的符号。它不理解这个词背后的物理感受和情感色彩。
因此,AI可以写出“她的眼睛湿漉漉的”,但它无法创造出“她的眼睛像东南亚热带雨林的早晨那样湿漉漉的”这种源于个人独特感知和联想的比喻。AI的创作是基于数据的二次加工,是符号在虚拟世界的空转。而人类的创作,源于身体在真实世界中的行走、触摸与感受。
2.3 路径依赖与思维能力的“外包”风险
长期依赖AI进行写作,可能会导致一种**“思维外包”**。当我们遇到描述困难、逻辑卡壳时,第一反应是求助于AI,而不是通过更深入的思考和观察去突破瓶颈。
这个过程类似于过度依赖计算器而导致心算能力下降。写作不仅仅是文字输出,它更是一种强迫我们整理思路、深化思考的过程。在反复推敲词句、调整结构的过程中,我们对问题的理解会变得更加清晰和深刻。
毕啸南最终选择清除所有AI工具,回归自主阅读与思考,正是对这种风险的警觉。设置“无AI写作区”,定期进行不借助任何工具的独立创作,是保持思维敏锐度和原创性的必要训练。
三、人机协同,智能时代的创作者进化论

面对AI带来的冲击,创作者的出路并非对抗,而是进化。我们需要重新定义自己的角色,将AI视为一个强大的认知增强工具,构建一种高效、健康的人机协同工作流。
3.1 重新定位,从执行者到“创意架构师”
在人机协同的模式下,创作者的核心价值链正在发生迁移。过去,我们的大量时间消耗在信息搜集、内容撰写、文字润色等执行层面。现在,这些工作可以被AI高效地分担。创作者需要将更多精力投入到价值链的更高层。
创作者价值链迁移模型
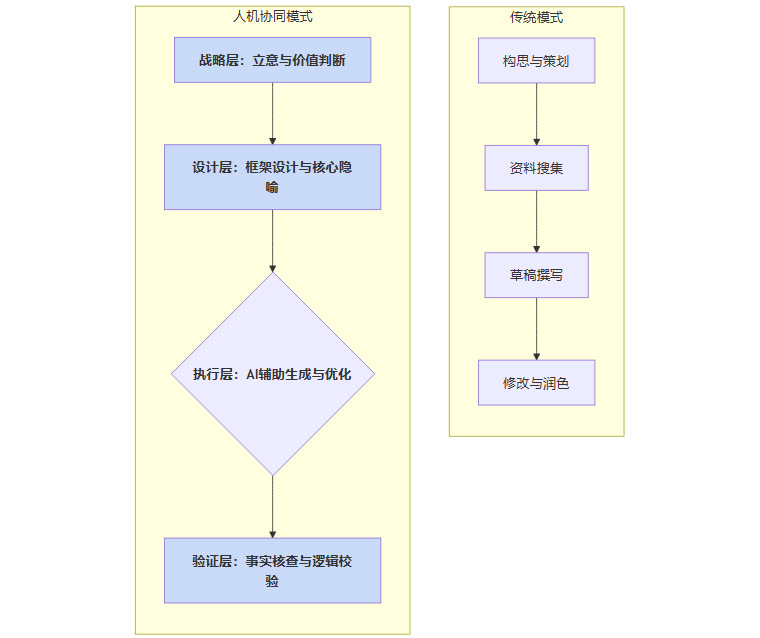
在这个新模型中,人类的核心职责变为:
-
战略层:确定创作的核心立意、价值观和目标受众。这是AI无法替代的,因为它涉及人类的意图和情感。
-
设计层:设计内容的整体架构、逻辑流程和关键的创意点(如核心比喻、故事原型)。这是展现思想深度和原创性的关键。
-
验证层:对AI生成的内容进行严格的事实核查、逻辑校验和伦理审查。成为最终质量的把关人。
人类的角色从一个“全栈写手”转变为一个**“创意架构师”或“内容产品经理”**。我们负责提出问题、定义方向、设计蓝图,并将AI作为实现蓝图的高效施工队。
3.2 掌握新接口,Prompt工程的艺术与科学
与AI高效协作的关键,在于掌握新的交互语言,提示词工程(Prompt Engineering)。一个好的Prompt,如同一个清晰的需求文档,能引导AI生成更符合预期的内容。
3.2.1 高质量Prompt的核心要素
一个结构化的Prompt通常包含以下几个要素。
-
角色(Role):为AI设定一个身份。例如,“你是一位资深的软件架构师”。
-
指令(Instruction):明确、具体地描述任务。例如,“请为以下Java代码添加详细的注释”。
-
上下文(Context):提供必要的背景信息。例如,“这段代码用于实现一个基于Redis的分布式锁”。
-
示例(Few-shot):给出1-2个输入输出的范例,让AI更好地理解你的要求和格式。
-
输出格式(Format):指定输出的形式。例如,“请以Markdown表格的形式返回结果”。
3.2.2 从简单指令到思维链(Chain-of-Thought)
对于复杂任务,简单的指令往往效果不佳。**思维链(Chain-of-Thought, CoT)**提示法通过引导AI“一步一步地思考”,能显著提升其在推理、计算等任务上的表现。
示例对比:
-
简单Prompt:
问题:一个团队有5个程序员,每个人每天能写800行代码。一个项目需要12万行代码。需要多少天完成?
AI(可能出错):120000 / 800 = 150天。 -
CoT Prompt:
问题:一个团队有5个程序员,每个人每天能写800行代码。一个项目需要12万行代码。需要多少天完成?
请一步一步地思考并解答。
AI(更可能正确):-
首先,计算整个团队每天能写多少行代码。5个程序员 * 800行/人 = 4000行/天。
-
然后,用项目总代码行数除以团队每天的产出。120000行 / 4000行/天 = 30天。
-
所以,需要30天完成。
-
掌握Prompt工程,意味着我们从一个被动的工具使用者,变成了一个能主动、精准地驾驭AI能力的“驯兽师”。
3.3 守护“蛙皮”,坚守不可计算的人文价值
在技术浪潮中,我们更需要清醒地认识到哪些是不可被技术替代的。作家叶舟引用的“蛙皮”故事,是一个深刻的隐喻。“蛙皮”代表了那些原始、本真、或许并不“高效”但至关重要的人类品质,正直、爱心、同理心、羞耻感。
这些品质是优秀文学的根基,也是构建可信、负责任技术系统的基石。在AI时代,坚守这些价值尤为重要。
-
对于写作者:意味着要持续地从真实生活中汲取养分,用带有体温的文字去触动人心。你的个人经历、情感挣扎、独特思考,是你最宝贵的“数据集”,也是AI无法复制的护城河。
-
对于技术开发者:意味着在设计算法和系统时,必须注入人文关怀和伦理考量。要警惕技术带来的偏见、歧视和信息茧房,确保技术的发展服务于人的福祉,而非仅仅追求效率指标。
将生活经验视为我们最大的、私有的、不可复制的数据集,并从中提炼出独特的洞察,这是我们在AI时代保持创造力核心竞争力的不二法门。
结论
AI技术正以一种结构性的力量,重塑阅读与写作这两项基本的人类活动。它既是效率倍增器,也是认知惰化剂;既是创作的得力助手,也可能成为原创性的枷锁。面对这场变革,回避和恐慌都无济于事。
正确的姿态是主动拥抱、深度理解、审慎利用。作为技术从业者和创作者,我们需要:
-
深入理解AI的技术原理与边界,不做盲目的使用者。
-
将AI整合进工作流,重新定位自身价值,从执行者向“创意架构师”进化。
-
刻意训练和保护我们独特的、基于真实体验的原创能力,警惕思维外包的风险。
-
坚守不可被量化的人文精神,让技术始终服务于人的成长与表达。
未来不属于AI,也不属于固步自封的人类。它属于那些能够与AI高效协同,并最终驾驭AI来放大自身智慧与创造力的人。在这场人机共读、共写的宏大叙事中,我们每个人都是主角。
📢💻 【省心锐评】
AI是认知的外骨骼,而非大脑的替代品。善用其力,可助我们攀登新的智慧高峰;过度依赖,则可能导致思维肌肉的萎缩。关键在于,操作外骨骼的,永远是人类自己。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献425条内容
已为社区贡献425条内容

所有评论(0)