NeurIPS 2025 | 快手联合南开提出情感树推理新方法,显著提升多模态大模型情感理解能力
你是否希望AI不仅能“看见”画面,更能“读懂”人心?传统方法在分析视频情感时,往往只能进行基础分类,难以理解复杂情感的动态变化。针对这一挑战,快手可灵团队与南开大学提出了创新解决方案——VidEmo,让AI首次实现“情智兼备”的情感推理。🧠 核心创新:像人一样“分步推理”研究团队提出了一个基于情感线索引导的树状推理框架。VidEmo不再试图一步到位,而是模拟人类的认知过程,分三个阶段层层递进:?
“情智兼备”是新一代人工智能迈向通用人工智能的重要方向。在人机交互中,从动态视频理解并预测人类复杂演变的情感是一项重要挑战,在安防、医疗等领域应用前景广阔。尽管现有方法在基础情感分类上表现良好,但难以有效建模情感的动态性与上下文依赖。当前视频大模型虽提供了新思路,却仍缺乏将面部线索融合为高层次情感表征的能力,难以实现兼具情感智能与理性可解释的预测。
针对这一瓶颈,快手可灵团队与南开大学计算机视觉实验室在「多模态视频情感理解」领域开展了创新研究,成功定位了现有多模态大模型在理解视频情感时的关键短板。提出了一种基于情感线索引导的推理框架,以分阶段的方式统一基础属性感知、表情分析与高层情感理解。
模型经过两个阶段的优化训练:第一阶段通过课程式情感学习注入情感知识,第二阶段则采用情感树强化学习提升情感推理能力。此外,研究团队构建了以情感为中心的细粒度数据集(Emo-CFG),210万条多样化的指令数据。该数据集涵盖了可解释的情感问答、细粒度描述及其对应的解释依据,为推动情感计算提供了关键资源。所提方法在15项人脸感知任务中表现出色,树立了新的性能标杆。目前,该研究成果已被NeurIPS2025录用,模型已开源。
[🔮论文标题] :
VidEmo:Affective-Tree Reasoning for Emotion-Centric Video Foundation Models
[📖 论文地址] :
https://arxiv.org/html/2511.02712
[📝 项目主页] :
https://zzcheng.top/VidEmo
一、研究背景
从动态视频中理解和预测人类情感[1]是计算机视觉领域日益重要的一项挑战,其在人机交互、监控系统和医疗健康等领域具有广泛的应用前景。尽管现有先进方法在基本情感分类任务上取得了显著成果,但在对复杂且不断演变的情感状态进行合理预测方面仍存在局限。这主要是由于情感本身具有动态性和上下文依赖性,因此需要模型具备高水平的情感智能,同时能够输出理性且可解释的预测结果。
近期,视频大模型(VideoLLMs)的兴起为这一领域提供了新的基础技术路线。然而,这些模型通常难以实现高层次的情感理解,因为它们感知的基础面部属性与复杂情感之间难以关联,存在语义鸿沟。即便是最先进的里程碑模型Gemini2.0,在细粒度情感分析任务中的准确率也仅为26.3%,凸显了该领域在性能上的差距以及进一步创新的迫切需求。
为应对这些挑战,本工作提出了VidEmo,一个基于树结构的新型情感线索引导推理框架,该框架集成了三个核心组件:基础属性感知、表情分析和高层次情感理解(参见图1)。在15项人脸感知任务中,VidEmo 超越了全部现有的开源视频大模型,包括之前最先进的基准模型Gemini 2.0(参见图2)。具体地,VidEmo 受到了近期推理工作的启发,这些模型在提供可解释依据方面表现出色,它们通过结合思考过程与模型操作来解决复杂任务。
本工作的研究发现,同样的推理过程可以应用于高层次的情感理解,通过引入分阶段思考,围绕属性感知、表情分析和情感理解构建结构化流程。本工作为VidEmo配备了课程式情感学习和情感树推理,在预训练和后训练阶段分别注入情感推理路径:
-
在预训练阶段,课程式情感学习逐步调整模型从基本面部属性到更复杂的情感状态。
-
在后训练阶段,情感树推理帮助模型使用层次结构细化其情感理解,确保情感反应既准确又可解释。
这种两阶段过程使得VidEmo能够有效地分析和推理动态视频数据中的情感。
此外,本工作还构建了一个以情感为中心的细粒度数据集Emo-CFG,专门设计用于情感理解任务的基础数据。Emo-CFG是一个包含210万条样本的大规模数据集,具有以情感为核心标签、严格的数据验证机制、高度多样性等特点,确保在广泛的情感上下文中实现全面且可靠的标注。通过丰富的标注信息和多样化的场景覆盖,Emo-CFG使VidEmo能够从情感推理路径中高效学习细粒度的情感理解能力。

图1: VidEmo的输入与输出示例。除了提供基础属性感知与表情分析的工具集(上),VidEmo还拓展了认知能力,能够生成具有可解释依据的细粒度情感描述(下)。

图2: 结果概览。本工作的最佳模型在15 项人脸感知任务中均展现出优越性能。
二、Emo-CFG: 以情感为中心的细粒度视频数据集
Emo-CFG数据集旨在推动对视频中动态情感的理解。受训练情感推理模型对高质量、以情感为中心的数据需求的驱动,Emo-CFG针对多样化的情感、可靠的标注以及严格的验证等关键挑战进行了专门设计。本工作在图3和图4中展示了Emo-CFG的数据构建流程与统计信息。
2.1 数据来源与元信息
数据收集始于高质量的视频数据集。数据来源包括来自头部、半身和全身人像的17个数据集。通过使用多种类型的数据,确保从整体视角理解视觉与情感数据中的细微差异。此外,保留了每段视频的元信息,包括人脸边界框、视频时长、视频分辨率和视频帧率。
2.2 Caption & QA 指令数据标注
采用两类主要数据源进行标注:大规模无标注数据集用于覆盖广泛场景,以及小规模全标注数据集用于确保精度。对于已标注数据集,使用GPT-4o生成指令对,并构建多种模板形式,包括选择题、开放式问答和短句描述。对于无标注数据集,采用一种因果式情感推理策略,以逐阶段、序列化的方式生成标签。
具体来说,给定一段视频,首先利用当前最先进的Gemini 2.0模型,提示其按顺序生成关于属性、表情和情感的细粒度Caption数据。随后,使用GPT-4o生成针对视频不同方面的QA对。通过整合这些属性与表情标签,能够准确推断出潜在的情感状态,从而实现对情感状态的细致且丰富的理解。
2.3 Caption − R & QA − R 归因依据数据标注
在指令数据的基础上,进一步探索低级属性与高级情感之间的关系。引导模型对情感线索背后的理性依据进行自我反思,即 和。这一过程不仅通过揭示情感表达背后的原因增强了模型的可解释性,也为提升模型的推理能力提供了关键训练阶段。
2.4 Critic 数据验证:投票机制
为应对情感数据因主观性带来的模糊,采用基于委员会投票的数据验证策略。使用三个异构的VideoLLMs构成一个评审委员会,用于验证数据的正确性并输出Critic条目,包括数据的错误方面及修改建议。通过验证的数据将被保留,未通过验证的数据则根据建议修正重新改写。此外,还从描述数据中提取不同维度信息,并将其拆分为多个QA对,以确保与问答流程的一致性。
2.5 Emo-CFG数据统计
图4展示了Emo-CFG数据集的关键统计数据。在(a)中,数据分类体系将数据集划分为三项主要的人脸感知任务:情感智能、表情分析和属性感知,涵盖了广泛的人脸特征与情感属性。(b)的数据分布图展示了不同数据集中人脸区域比例与视频时长的分布情况,体现了Emo-CFG所包含视频数据的多样性和丰富性。(c)的标注分布包括了人脸视角(头部、半身、全身)和视频长度的构成,并附有词云图,突出了最常出现的标注关键词,如中性、人脸和表情。(d)的数据统计对比显示,与其他情感和视频数据集相比,Emo-CFG提供了更丰富的标注类型和标签维度,包括细粒度情感标签、归因依据以及全面的视频信息,使其成为以情感为中心的研究中独特且宝贵的资源。
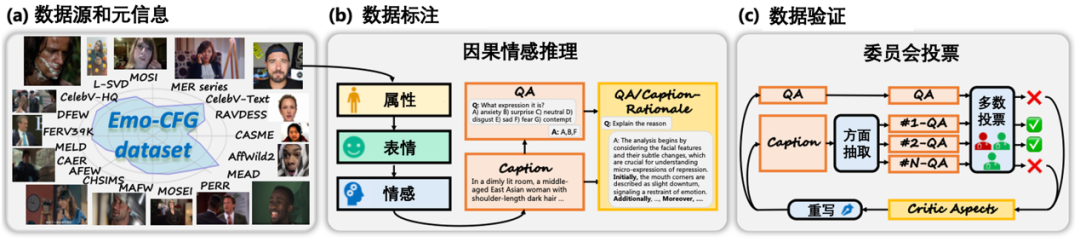
图3: Emo-CFG 数据集的数据构建流程
(a)数据来源,涵盖来自17个不同数据集的素材。(b)数据标注步骤示意图,展示了从原始视频到结构化标注的全过程。(c)数据验证循环,人工审核与模型辅助质检相结合的迭代验证机制。
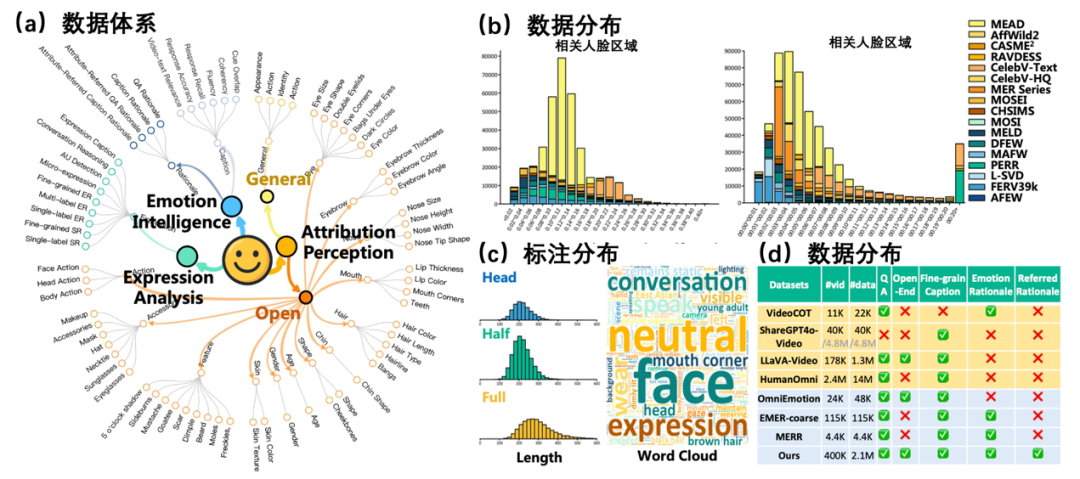
图4:Emo-CFG数据集的统计概览
(a)来自三类人脸感知任务的数据分类体系。(b)视频数据在时间和空间维度上的分布情况。(c)数据标签的分布与示例,涵盖属性、表情和情感等多个层面。(d)与其他情感和视频数据集的对比,展示Emo-CFG在标注丰富性和任务多样性方面的优势。
三、VidEmo视频情感基础模型
为了开发一系列以情感为中心的视频基础模型,提出了一套全面的工具包,用于预训练、后训练和推理,如图5所示。通过结构化的预训练过程注入情感知识,随后进行后训练以增强模型的推理能力。最终,在推理阶段,模型能够有效生成情感输出,利用所学习到的属性、表情和情感。

图5:VidEmo的训练流程图
3.1 预训练:课程情感学习
为了向基础模型中注入情感知识,采用课程情感学习逐步调整基础模型。训练分为三个阶段:I) 属性调整,II) 表情调整,III) 情感调整。预训练专注于整理数据,平衡情感任务的难度同时解决困惑度问题。在每个阶段,都精心整理数据,确保情感相关的任务逐渐增加复杂性。从简单的属性开始,并逐步转向更复杂的表情和情感,确保模型建立对情感的强大基础理解,这有助于在整个过程中更平滑地注入情感知识。
3.2 后训练:通过混合情感树奖励的强化学习
基于已注入情感知识的基础模型,进入后训练阶段探索情感推理路径。最近的强化学习技术在推理方面展示了强大的能力,GRPO由于其简单性和有效性而受到广泛关注。这使得GRPO 成为工作的理想起点。正式地说,设为查询,GRPO 从旧策略模型πθ中采样一组输出,数量为,并通过最大化以下目标来训练策略模型:
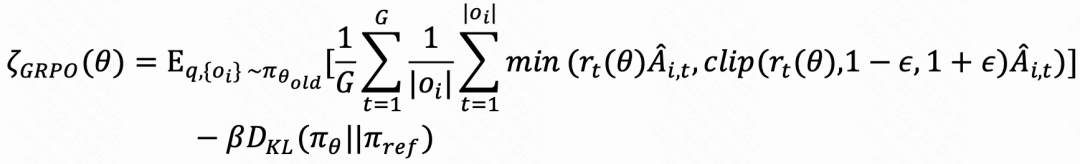
其中是基于组内相对奖励的优势值,ϵ和β分别是KL惩罚系数和剪裁阈值,而πθ , πθ , π分别是当前、旧和参考策略模型。
基于规则的QA奖励。
模型根据预定义的准确率和F1分数规则评估其响应情感相关查询的能力。评估任务包括分类(单标签、多标签)、细粒度分类、微表情检测和动作单元(AU) 检测。
基于模型的短描述奖励。
对于动作、外观和情感的短描述,使用一个生成奖励模型来评分模型生成的描述的质量。
基于情感树的细粒度描述奖励。
为了评估模型进行结构化情感推理的能力,引入了一个基于细粒度描述构建的层次情感树的奖励机制。给定生成的描述,首先将其解析为三个语义层次上的方面-项目对:属性(),表达(ε) 和情感()。这些元素被组织成三层情感树,其中每个节点代表提取的项目,有向边编码基于理由的依赖关系——即,
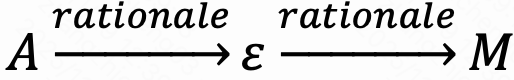
将预测树 与从人工标注描述解析的真实树进行比较,使用树编辑距离来量化将一棵树转换为另一棵树所需的最小编辑操作(插入、删除、替换)数量。最终奖励R 使用指数衰减计算树距离:
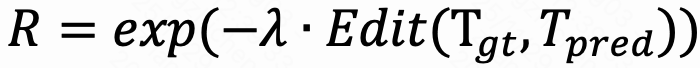
其中λ > 0 是控制奖励对树差异敏感性的缩放因子。这种公式鼓励模型不仅在内容上准确,而且在结构上可解释,符合人类对情感理解的推理模式。
3.3 推理:高层次情感理解的推理
VidEmo采用分阶段训练,可以顺利与基于搜索的推理策略相结合。具体来说,采用一种层次化的、基于搜索的推理方法,将情感理解分解为三个层次:属性感知、表情分析和情感推断。在每个层次上,策略模型采样多个候选输出,并通过奖励引导的评分机制选择最佳输出,形成自底向上的推理轨迹。
四、实验结果
4.1 性能提升:
-
人脸属性感知能力:如表1所示,VidEmo在Emo-CFG数据集的14项人脸属性感知任务上的性能展现出明显优势。
-
表情分析能力: 如表2所示,VidEmo在Emo-CFG数据集的11项表情分析任务上的性能也得到显著提升。
-
细粒度情感理解:在情感理解任务中,涵盖指令遵循、语言流畅性、响应准确性及视频-文本相关性等维度。VidEmo平均得分优于包括所有先前模型。
-
情感分类能力:在公开视频情感分类数据集DFEW和MAFW中,VidEmo依然取得了最好的结果。
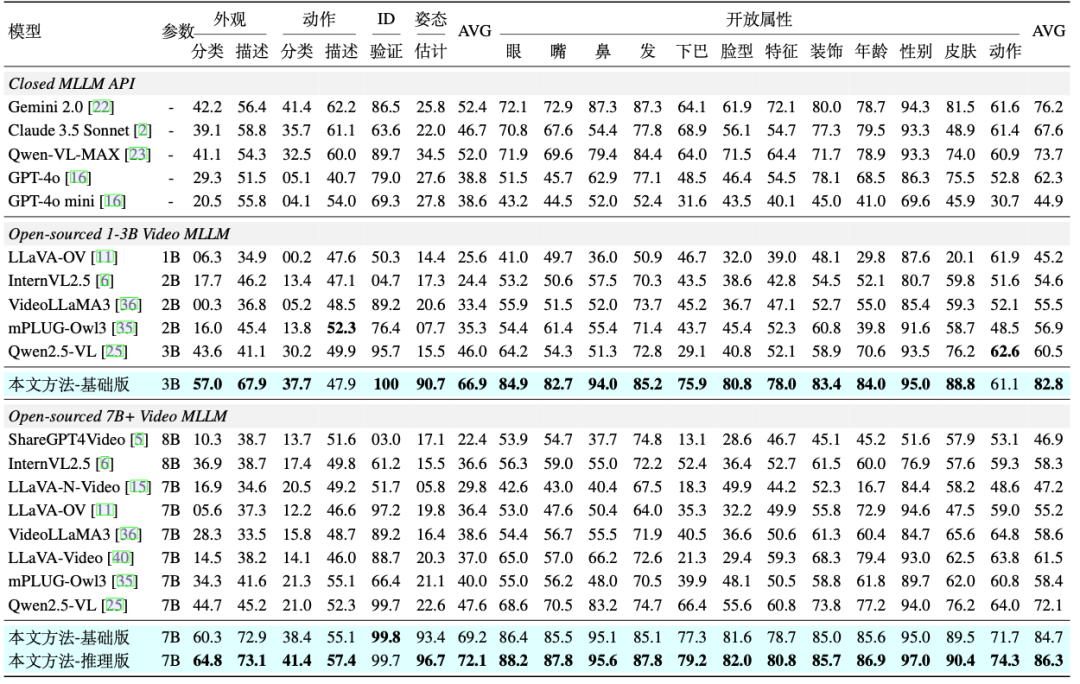
表1: 在Emo-CFG数据集的14 项人脸属性感知任务上与18个主流视频大模型的对比结果,包括6项闭集属性感知任务和12项开集属性感知任务。
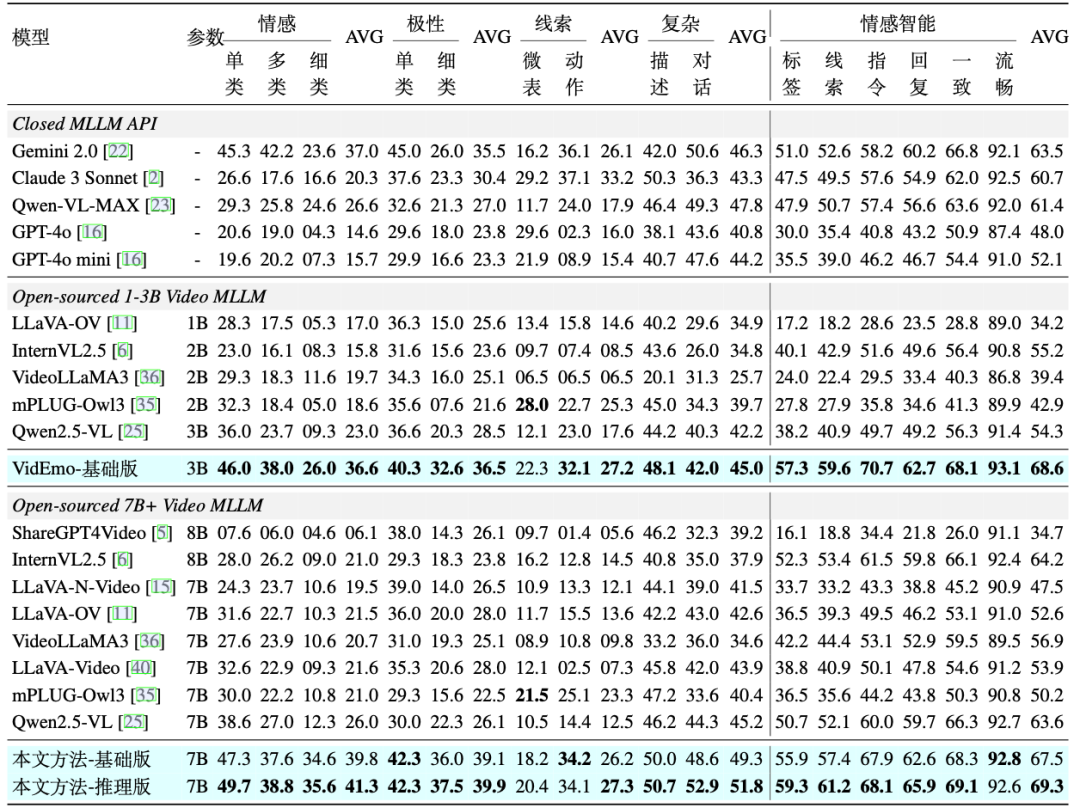
表2: 在Emo-CFG数据集的11项表情分析任务与6项细粒度情感理解任务上与18个主流视频大模型的对比结果。
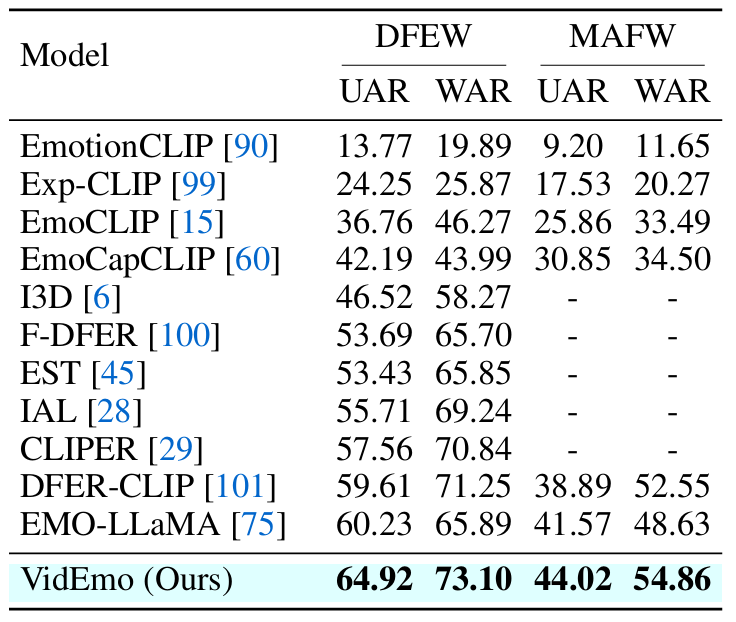
表3: 在DFEW和MAFW数据集的表情分类的对比结果。
4.2 可视化:
图6展示了模型在三个关键方面的可视化结果:属性感知、表情分析和情感理解。
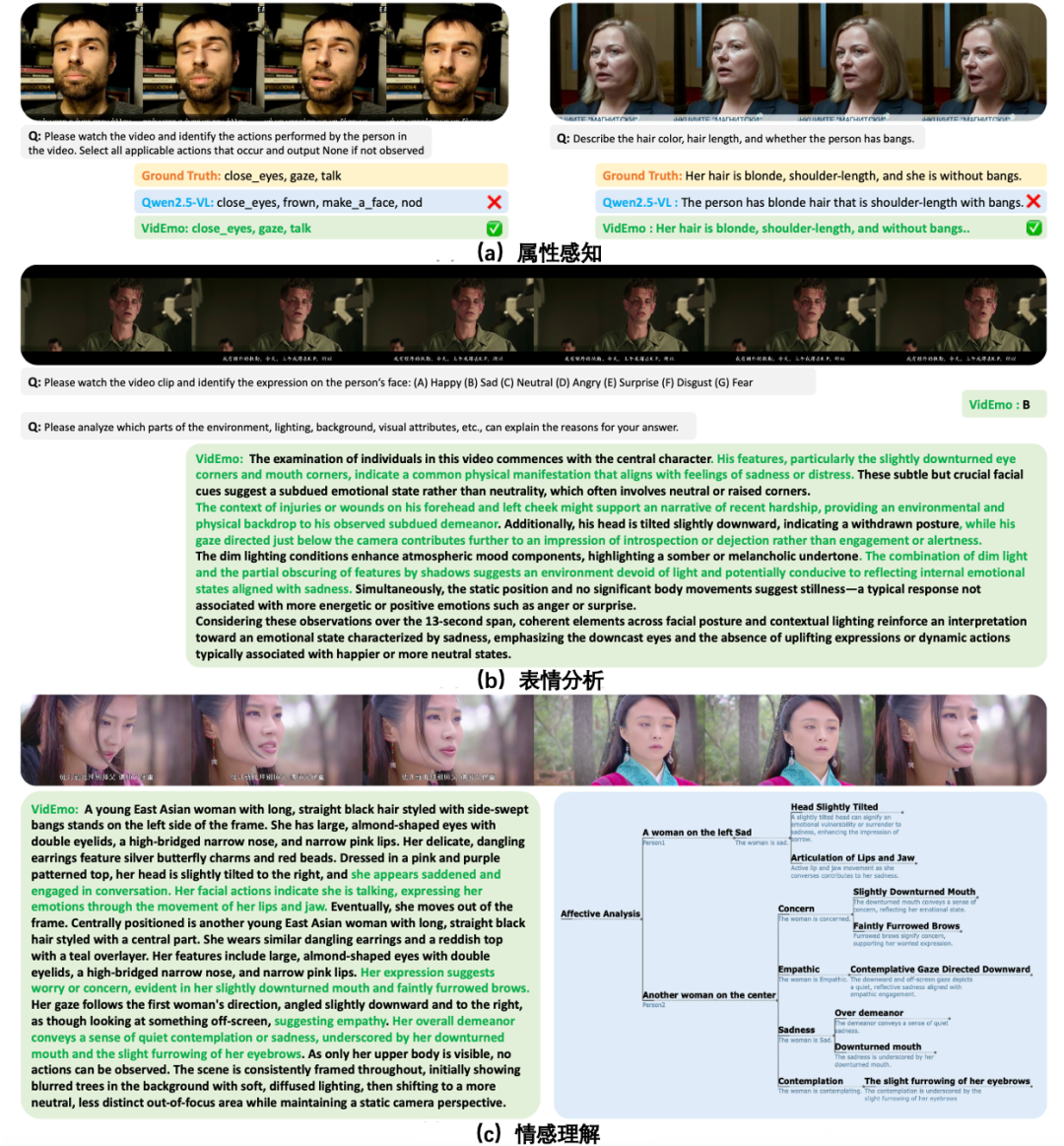
图6: 属性感知、表情分析与情感理解的可视化结果
-
属性感知:模型能够准确识别面部属性,如发色、发长以及是否有刘海,并通过与真实标签的对比清晰地展示了验证结果。例如,模型正确识别出某人的头发为金色、及肩长度,并区分了是否有刘海的存在。
-
表情分析:模型能够分析细微的面部表情,识别诸如眼神下垂、头部姿势等特征。正如图中第二部分所示,这些面部和上下文线索(如光照和身体动作)为理解人物的情感状态(如悲伤或沉思)提供了重要依据。
-
情感理解:通过整合面部特征与上下文线索,模型对情感状态进行了详细的解读。例如,在图的最后一部分中,模型识别出一种沉思的情感状态,其依据包括略微倾斜的头部、皱起的眉头以及细微的眼神变化。
[🎯 3B模型]:
https://huggingface.co/KlingTeam/VidEmo-3B
[🎯 7B模型]:
https://huggingface.co/KlingTeam/VidEmo-7B
[📖 数据地址]:
https://huggingface.co/datasets/KlingTeam/Emo-CFG
[📝 代码地址]:
https://github.com/KlingTeam/VidEmo
[🔮 相关工作]:
https://github.com/nku-zhichengzhang/Awesome-emotion_llm_and_mllm
参考文献:
[1]Sicheng Zhao, Guoli Jia, Jufeng Yang, Guiguang Ding, Kurt Keutzer. Emotion recognition from multiple modalities: Fundamentals and methodologies. IEEE Signal Processing Magazine, 38(6): 59-73, 2021.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)