【保姆级教程】AI Agent 终于有“持久记忆”了!Claude Code + MemMachine 全流程实战
MemMachine为AI助手装上"长期大脑":实战部署教程 摘要:本文详细介绍了如何通过MemMachine开源项目为AI助手(如ClaudeCode)添加持久化记忆功能。MemMachine作为一个独立服务,能够跨会话存储用户偏好、习惯等结构化信息,解决传统AI模型"七秒记忆"的痛点。文章包含完整的部署流程:从Docker安装、MCP协议接入,到实际测试
目录
在做 AI Agent 的这些日子里,我始终被一个问题困扰:模型越强、工具链越完善,但 Agent 却依旧像个"七秒记忆"的金鱼。只要你关闭对话框、上下文 token 一溢出,它立刻忘记你是谁、你喜欢什么、你昨天让它做了哪件事。对于任何需要长期跟踪、持续协作的场景而言,这几乎就是致命缺陷。

直到最近,我在 GitHub 上看到一个开源项目 —— MemMachine。
项目开源地址:https://github.com/MemMachine/MemMachine
然后我把 MemMachine 接入 Claude Code 的那一刻,我才第一次觉得 AI 助手真的“活”了。MemMachine 给 Agent 装上了一层独立于模型之外的"持久化大脑",不仅能跨会话记忆用户偏好,还能自动结构化信息、持续进化,而且可以本地部署、完全私有,不会随着模型切换而丢失。更惊喜的是,通过 MCP 协议,它能在 Claude Code 中做到即插即用,让你的 Agent 从第一天起就具备“越聊越懂你”的能力。
于是我决定把整套流程完整记录下来:从零部署 MemMachine,到通过 MCP 接入 Claude Code,再到实际写入用户偏好、跨会话成功调用记忆。整个过程比我想象中顺滑得多,而最终效果也远超预期——这是我迄今为止体验过最接近“真正 AI 助手”的一次实践。
1️⃣ 写在前面:为什么开始研究 AI 长期记忆?
为了验证 MemMachine 是否真的能改变 AI 的交互方式,我准备了一个非常现实、但同时又极度考验记忆系统的测试场景——让 Agent 记住用户的完整饮食偏好。
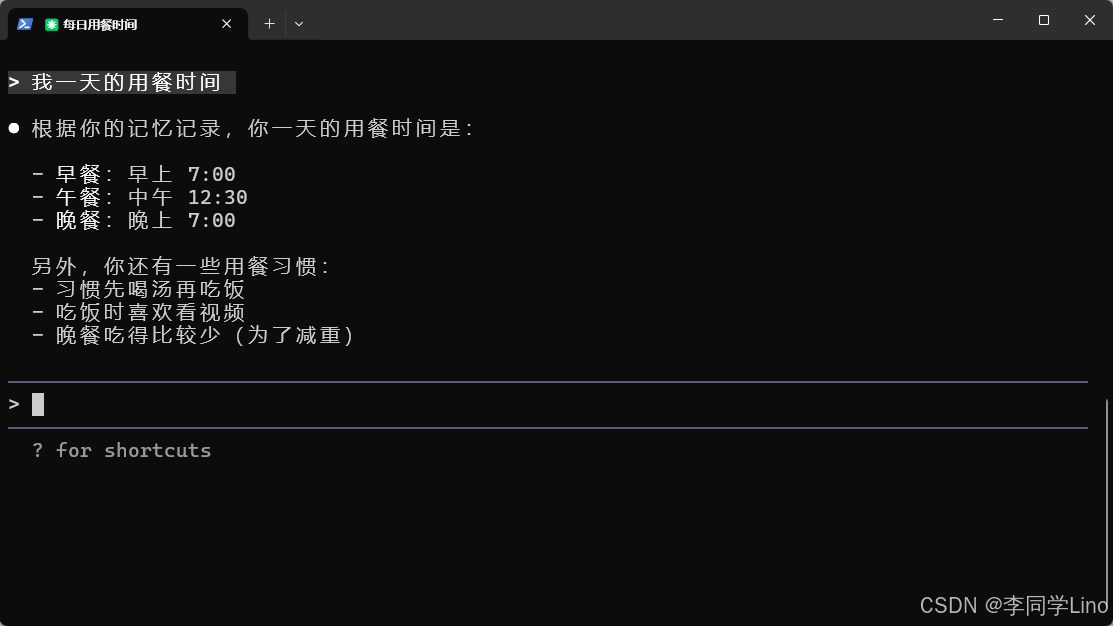
从喜好口味、忌口食材,到三餐作息、营养目标、减脂计划,我把一整段像现实生活中“第一次自我介绍”那样的信息交给了 Claude Code,让它通过 MemMachine 自动解析、提取并写入档案记忆。在传统的 LLM 中,这些内容通常会随着窗口关闭而消失,但这一次结果完全不同:当我隔天再次打开对话、随口问一句“今晚吃什么比较好?”它不仅记得我喜欢辣、不吃香菜、控制碳水,还能根据增肌目标反推蛋白质摄入建议——而这些信息,是在昨天的另一场会话里告诉它的。
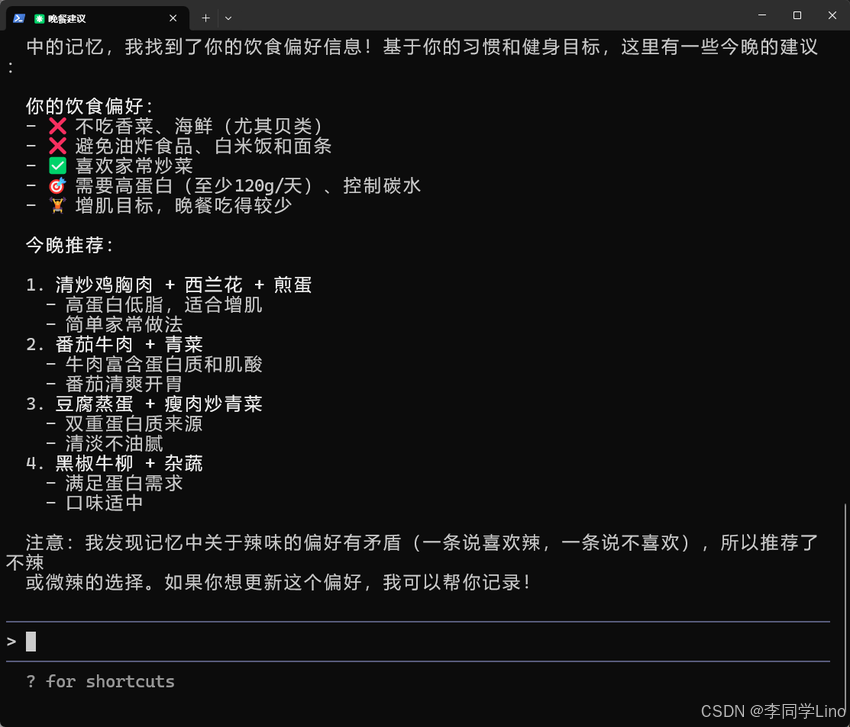
正因为这个体验如此震撼,我意识到:MemMachine 并不是 RAG 的替代品,而是 Agent 能否进入“长期协作”时代的真正分水岭。它让 AI 不再是即时回答工具,而是一个可以理解你、陪伴你、根据你持续变化的喜好主动调整行为的数字伙伴。而且,这一切都可以通过本地部署完成,隐私可控、架构简单,也不依赖任何特定模型。
接下来,我会把整个过程拆解成一套可完全复现的实战教程:从 MemMachine 的部署、到 MCP 接入、到 Claude Code 内的真实记忆写入,再到最终的跨会话查询,全部一步步带你搭建起来。如果你正在构建属于你的 AI Agent,这会是让它成长为“长期大脑”的最佳起点。
2️⃣ 什么是 MemMachine?
MemMachine 可以简单理解为:一个独立于模型之外的“长期记忆服务”。它不负责生成内容,也不和你的 LLM 混在一起,它只做一件事——把用户的重要信息存下来、管起来、长期提供给 Agent 调用。
不同于传统把聊天记录塞进向量库的做法,MemMachine 会自动把信息拆成“事实”“偏好”“习惯”“事件”等结构化内容,并存到自己的数据库里。这样,不论你换模型、换会话、甚至隔一天再来,它都能让 Agent 恢复到正确的“理解用户的状态”。
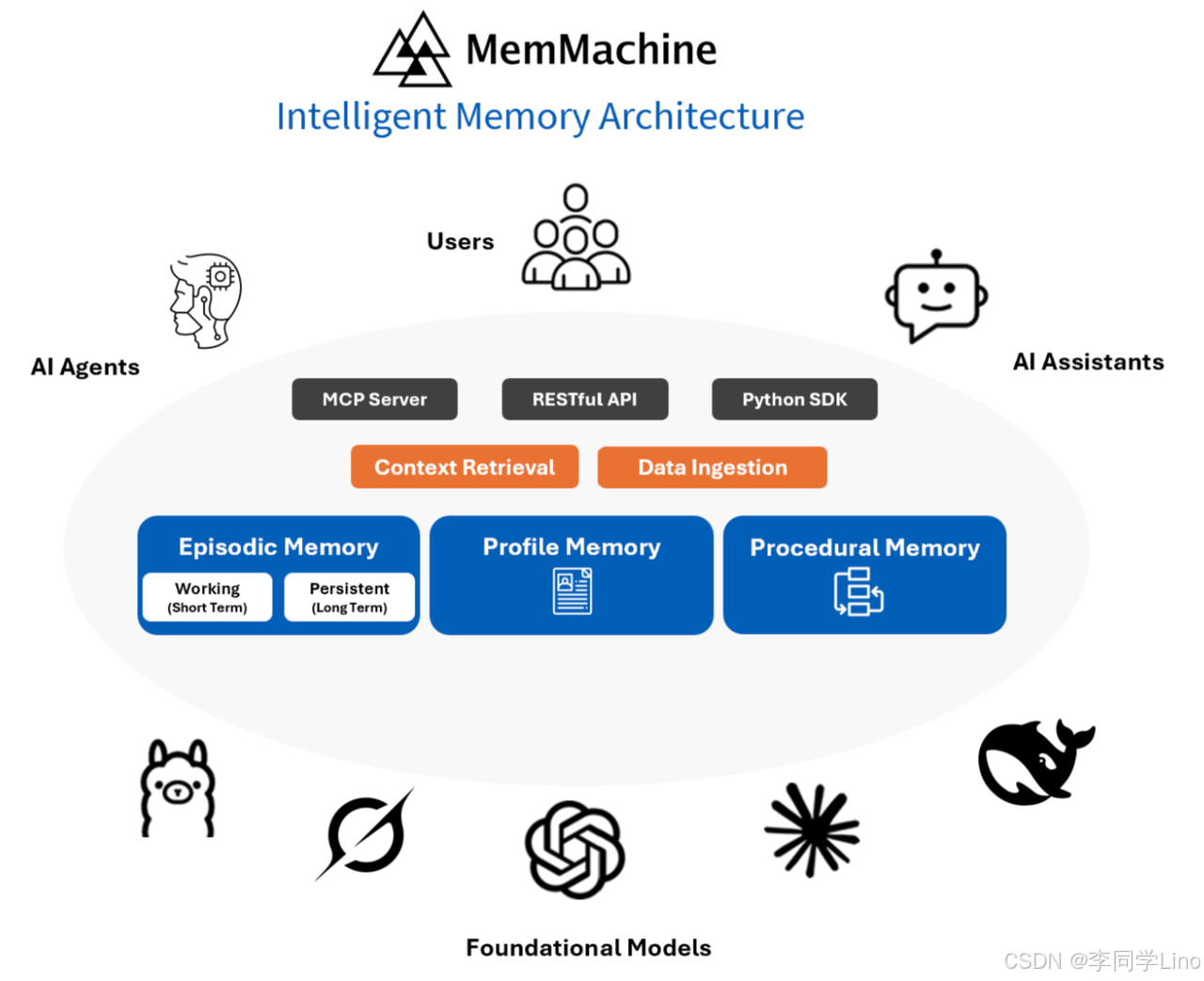
MemMachine 并不是一个“概念”,而是一个真正能 本地部署、直接运行、开箱即用 的开源服务。你只要把它跑起来,再通过 MCP 接进 Claude Code,你的 Agent 就立刻拥有跨会话、不丢失、不遗忘、可更新的长期大脑。
接下来,我们直接动手,从部署开始,把这个 “长期大脑” 装到你的 AI Agent 身上。
3️⃣ 部署安装 MemMachine(Docker 版)
MemMachine 是一个独立服务,需要你先把它在本地或服务器跑起来。部署非常简单,只要会用 Docker 就能在 3 分钟内启动。
步骤 1:准备 Docker
在部署 MemMachine 之前,你需要确保环境中已经安装:
-
Docker Engine
-
Docker Compose(v2 版本,已集成在 Docker Desktop 中)
这两个工具是整个服务运行的基础。
docker --version
docker compose version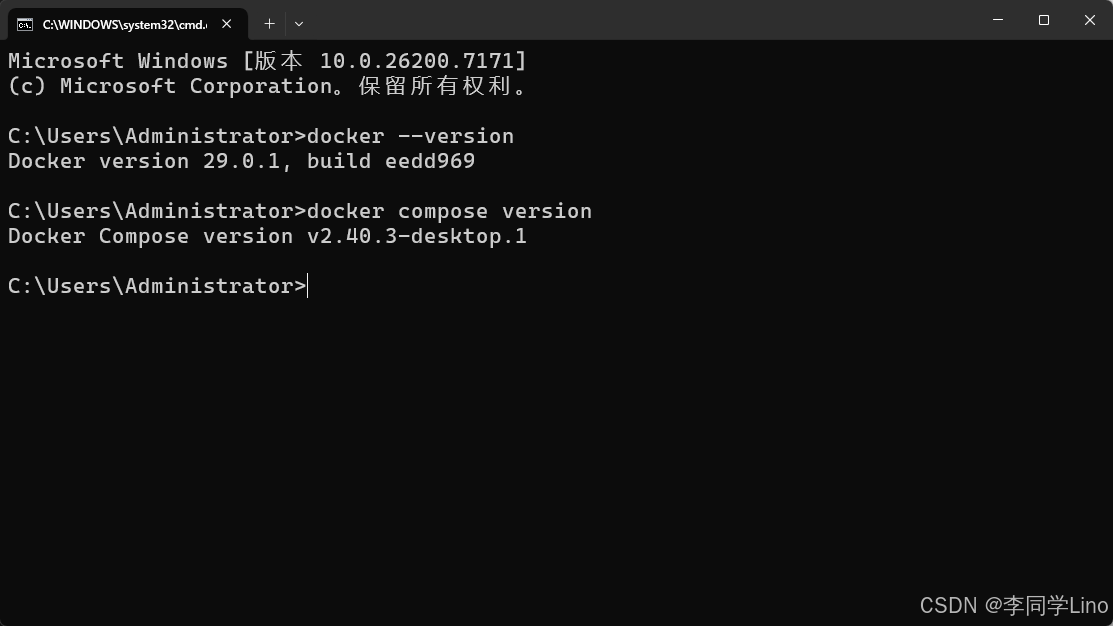
不过没关系,我这里有超详细的教程可参考安装 Docker :【2025 最新版】Win11 安装 Docker Desktop 超详细图文教程(小白也能学会)
步骤 2:准备 Claude Code
在将 MemMachine 与 Claude Code 集成之前,你需要先在本地正确安装并配置 Claude Code 环境。Claude Code 并不是 VSCode 默认提供的功能,它依赖:Node.js 18+和Git。
可参考这份教程来安装:【保姆级教程】Win11 下从零部署 Claude Code:本地环境配置 + VSCode 可视化界面全流程指南
检查本机 Node 版本:
node -v
Claude Code 部分功能需要依赖 Git,例如代码模板初始化、版本控制等。
检查本机 Git 版本:
git --version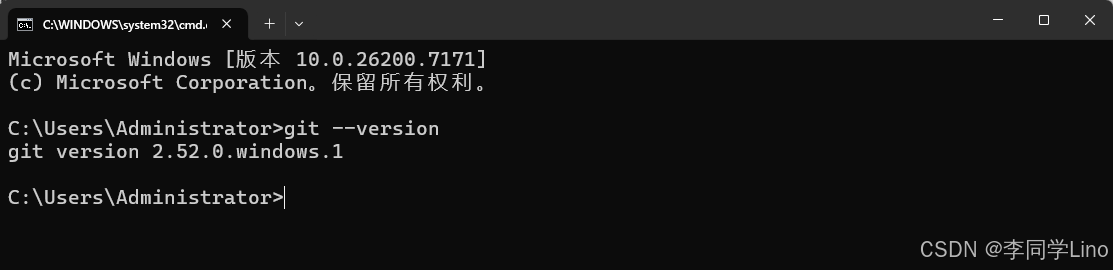
Claude Code 提供命令行工具,必须提前安装,若已经安装好可验证安装:
claude --version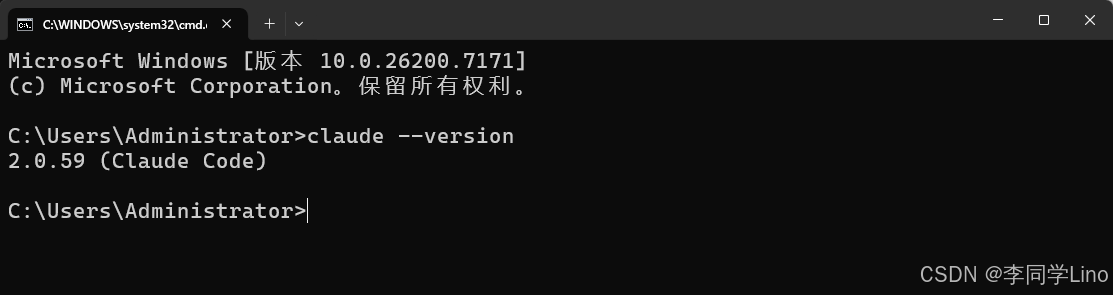
步骤 3:本地部署MemMachine
官方提供了多种方式的部署方法,这里推荐使用Docker来部署,非常简单的。
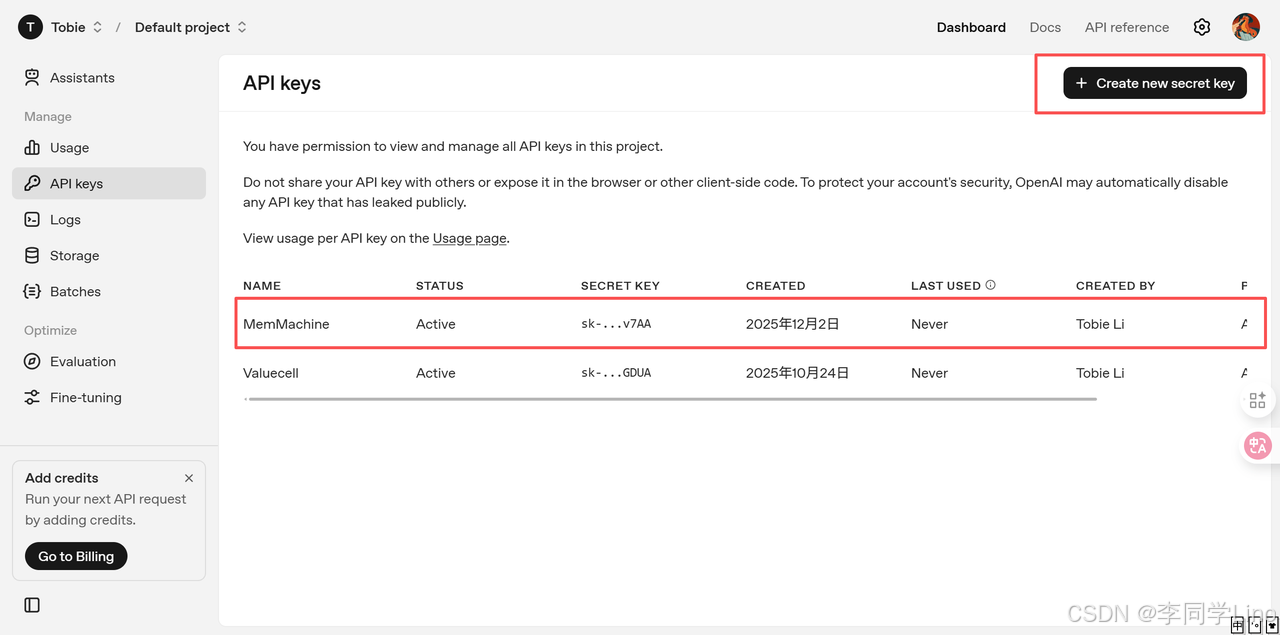
首先得准备好一个OpenAI的APIKey(当然也可以魔改成国内api_key,后面会讲到,提供必要的源码),我们可以来到OpenAI的API平台上 https://platform.openai.com/api-keys,点击创建APIKey,就可以得到一个sk开头的API了,不过记得查看有没有额度哟~
如果API也有了,我们就可以正式开始部署了。接着我们需要创建一个文件夹,这里创建了一个MemMachine文件夹,比如我的路径如下:“D:\Open_Source_Project\MemMachine”
打开Powershell,输入以下命令:
$latestRelease = Invoke-RestMethod -Uri "https://api.github.com/repos/MemMachine/MemMachine/releases/latest"; `
$tarballUrl = $latestRelease.tarball_url; `
$destination = "MemMachine"; `
if (Test-Path $destination) { Remove-Item $destination -Recurse -Force }; `
New-Item -ItemType Directory -Force -Path $destination; `
Invoke-WebRequest -Uri $tarballUrl -OutFile "MemMachine-latest.tar.gz"; `
tar -xzf "MemMachine-latest.tar.gz" -C $destination --strip-components=1; `
Set-Location $destination; `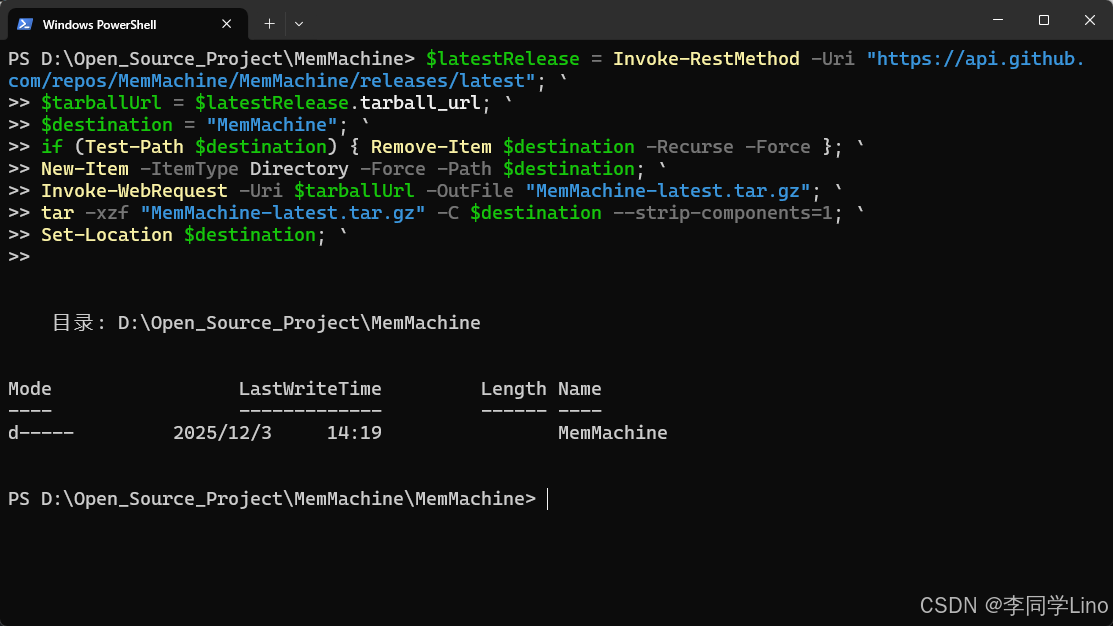
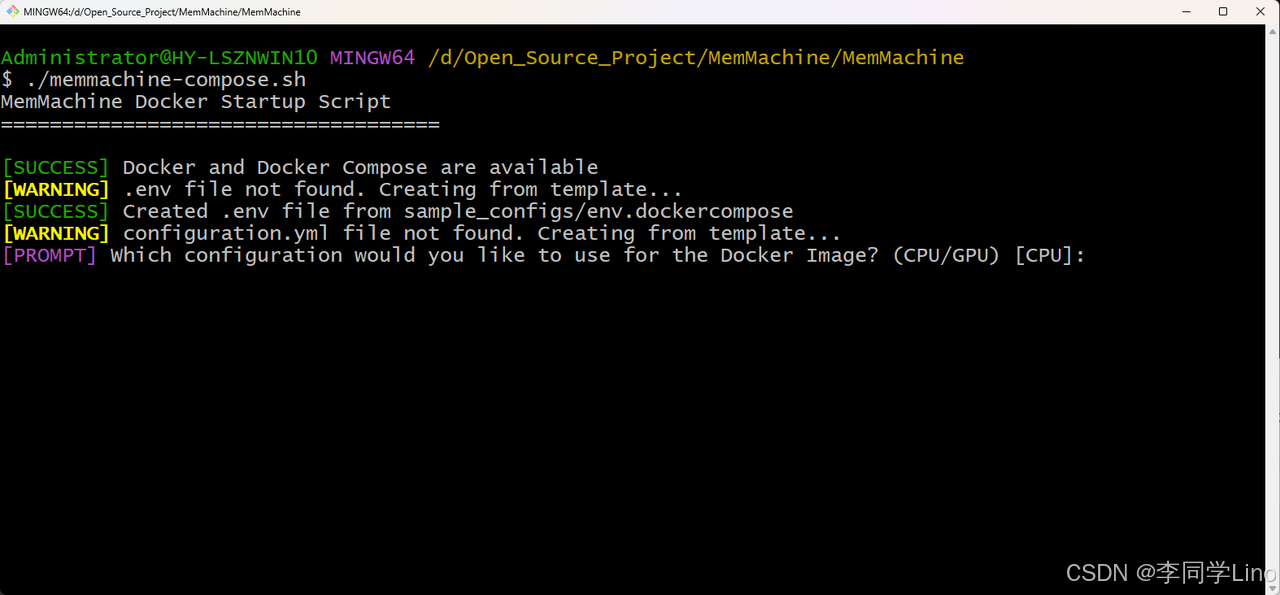
进入到这个目录下:“D:\Open_Source_Project\MemMachine\MemMachine”,打开Git Bash,运行以下命令:
./memmachine-compose.sh第一步:选择Docker是哪种配置的(CPU/GPU),我们使用默认的CPU就行。
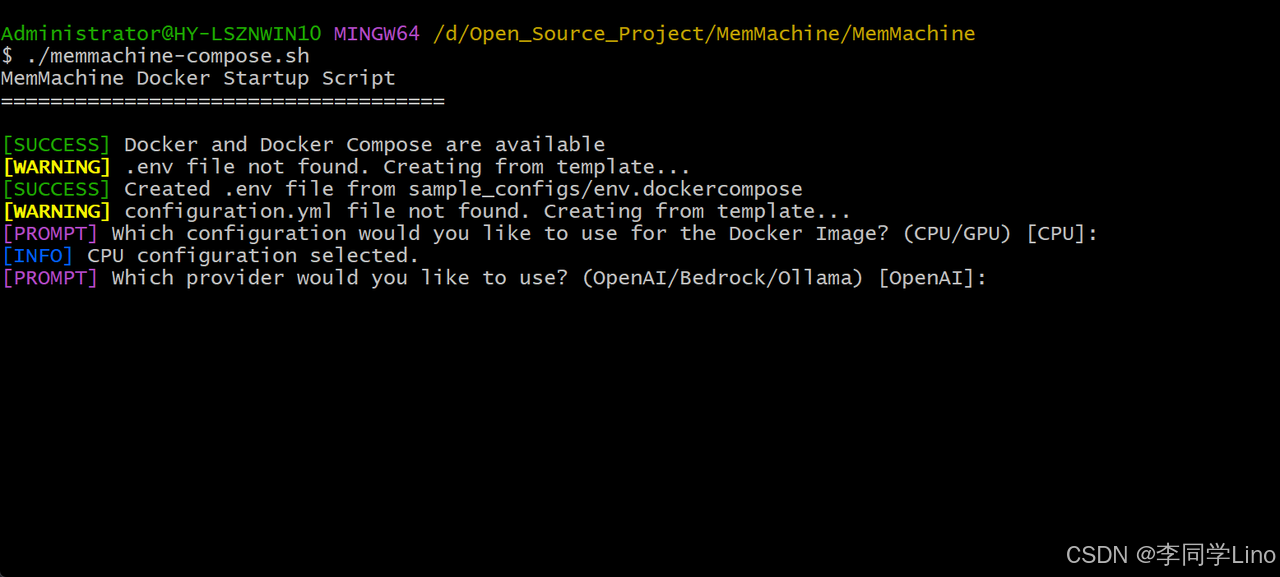
第二步:使用哪个模型供应商,我们默认使用OpenAI就行。
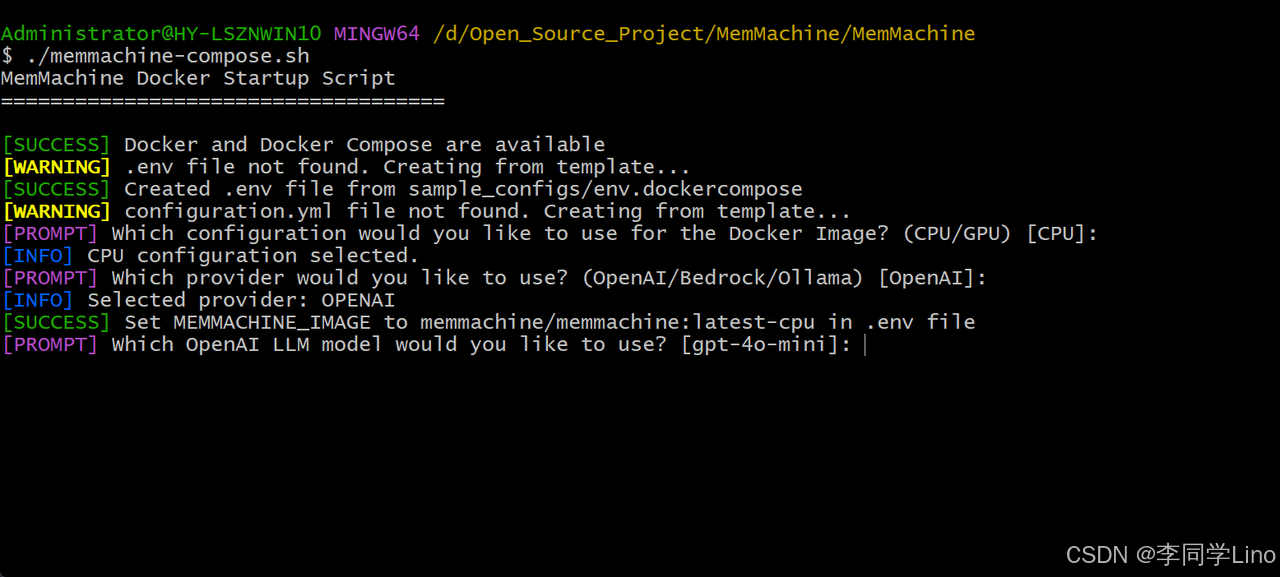
第三步,使用OpenAI的什么模型,我们也是默认[gpt-4o-mini]的就行了。
第四步,embedding模型也同样,默认即可。
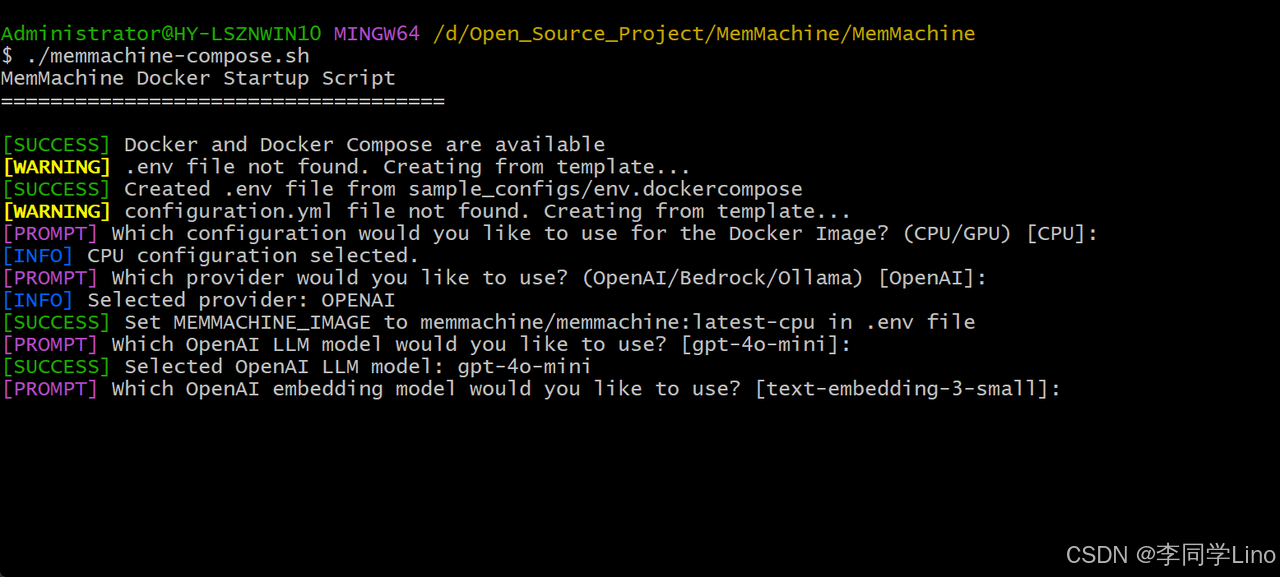
第五步,这样需要设置API Key,输入Y并填写好刚刚创建好的APIKey就可以了。
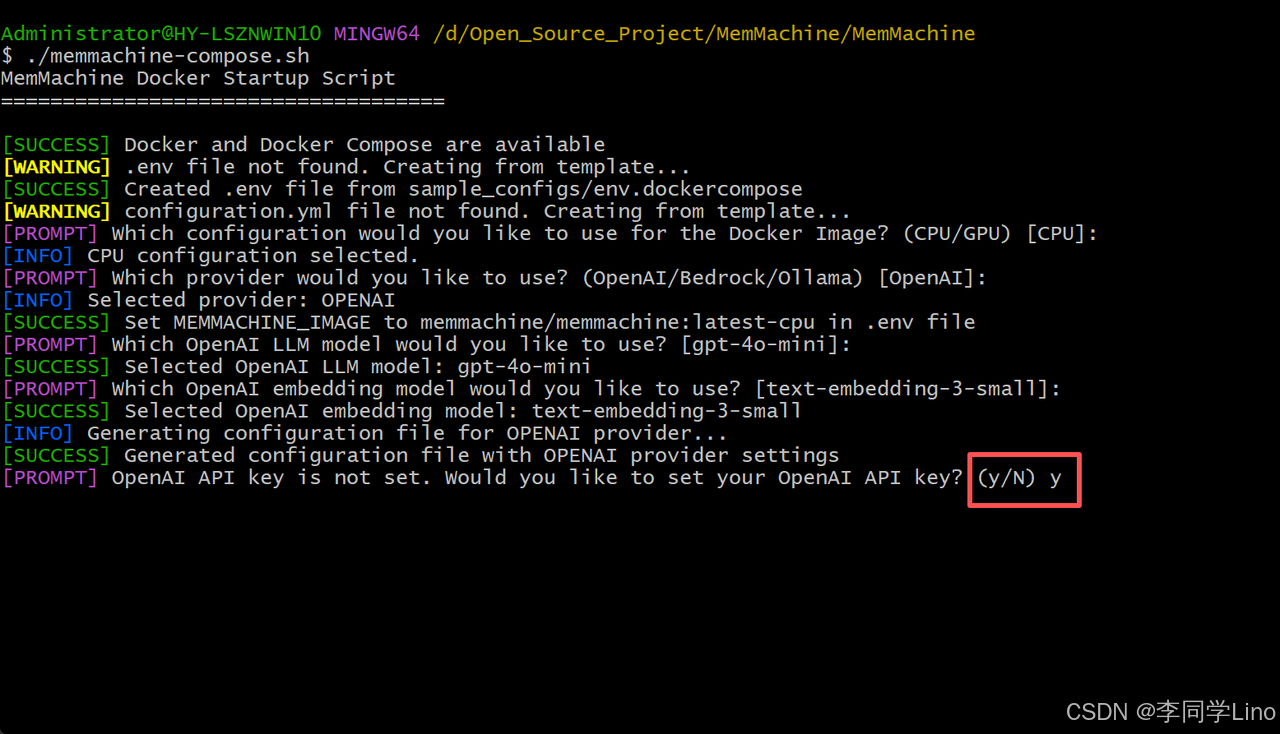
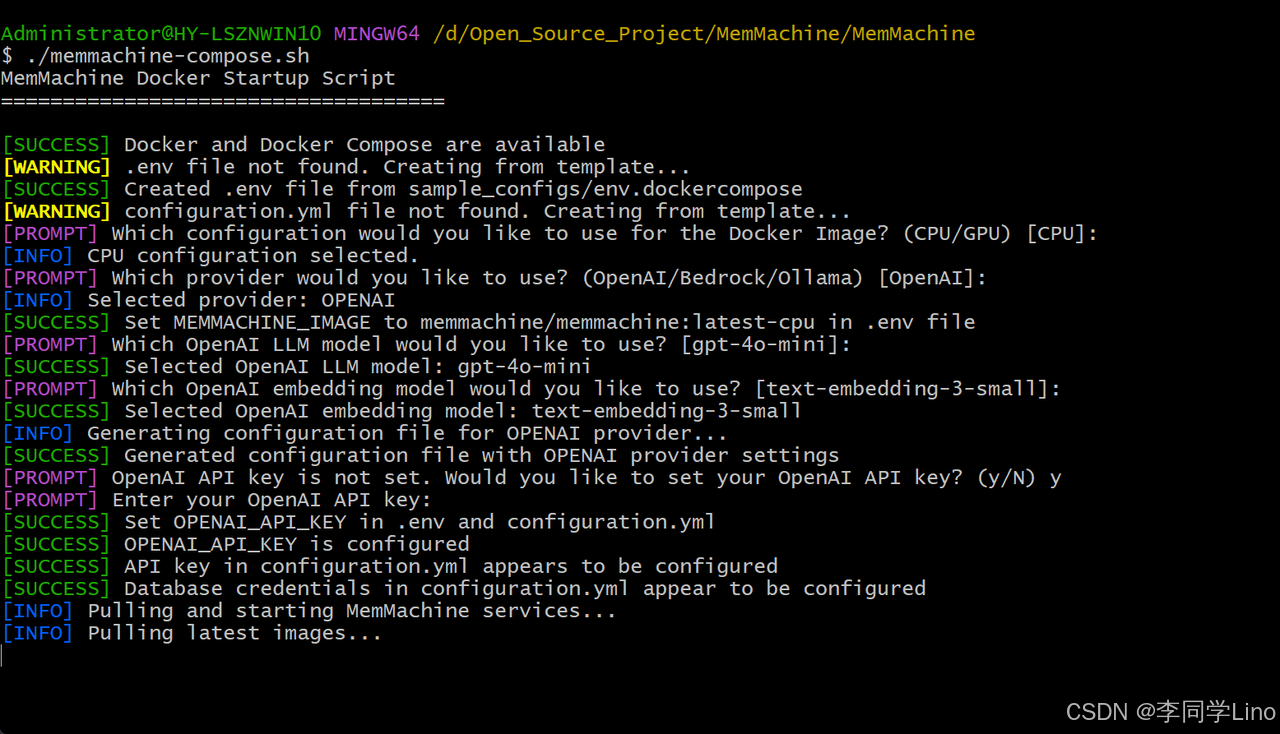
最后一步呢,只需要等待它自行安装完成。
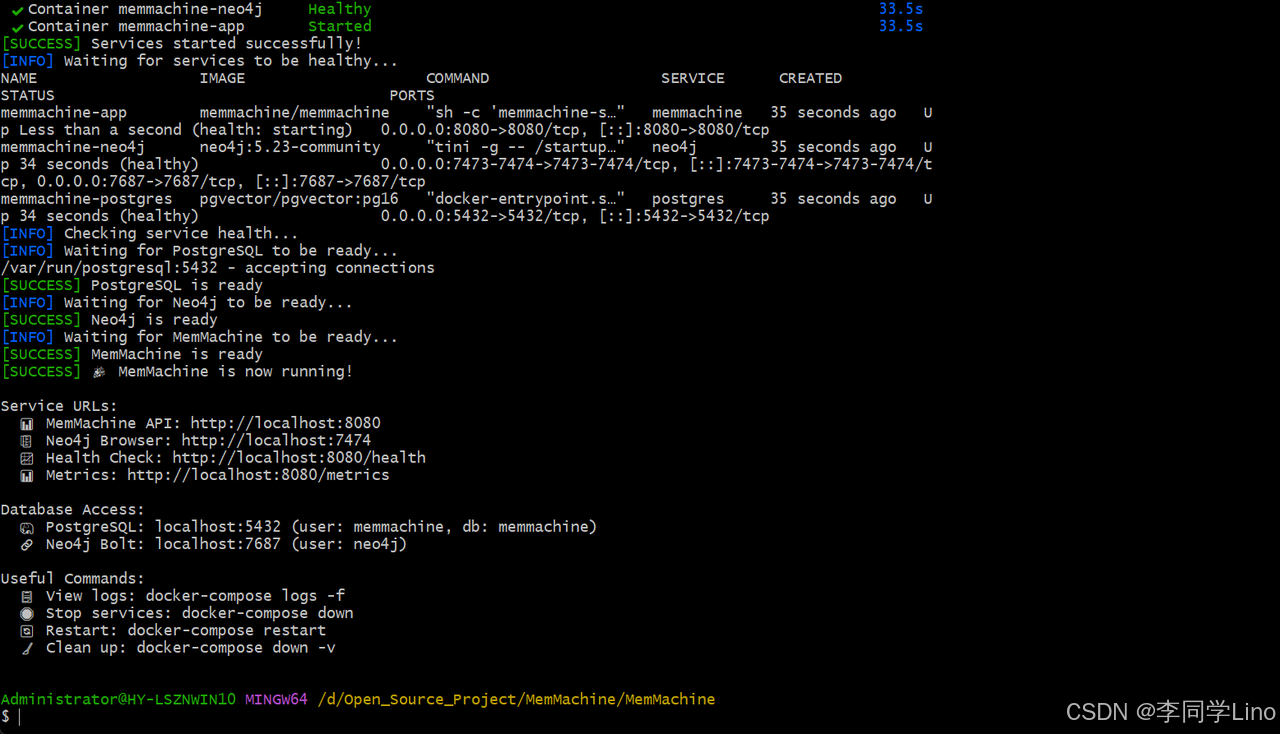
在命令行中输入这个命令,检查一下是否安装成功。
curl -v http://localhost:8080/health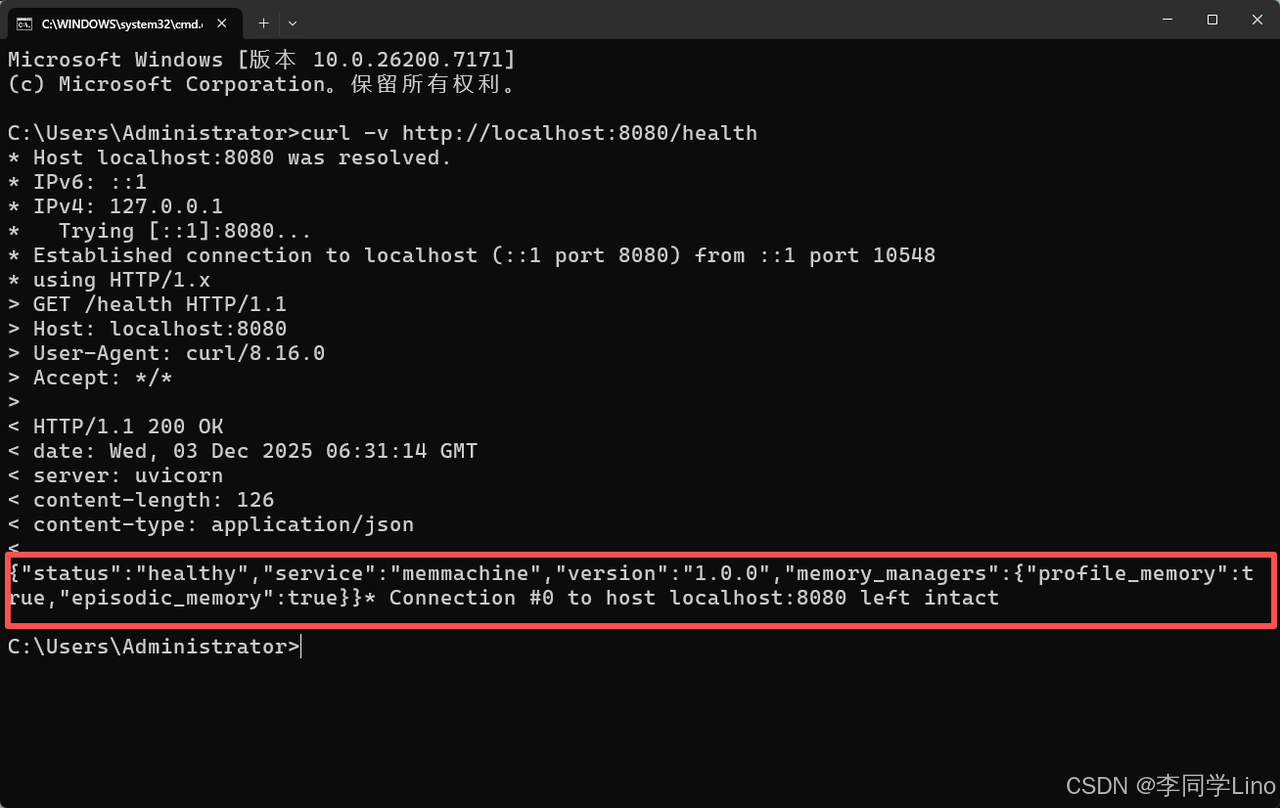
如果返回:{"status": "healthy"},说明 MemMachine 安装成功!
步骤 4:接入 Claude Code
这是关键步骤,也是很多人卡住的地方。
Claude Code 的所有插件、记忆层、外部工具都必须通过 MCP(Model Context Protocol) 接入。MemMachine 官方提供了标准的 MCP 服务端。
在原本的文件夹:“D:\Open_Source_Project\MemMachine”目录下创建一个“.mcp.json”文件,复制以下代码到这个文件中。
{
"mcpServers": {
"memmachine": {
"command": "docker",
"args": [
"exec",
"-i",
"memmachine-app",
"/app/.venv/bin/memmachine-mcp-stdio"
],
"env": {
"MEMORY_CONFIG": "/app/configuration.yml",
"MM_USER_ID": "your-username",
"PYTHONUNBUFFERED": "1"
}
}
}
}然后进入到命令行中进行测试。
claude进入到Claude界面中,输入“/mcp”,可以看到,MemMachine已经记录到了Claude里面了。
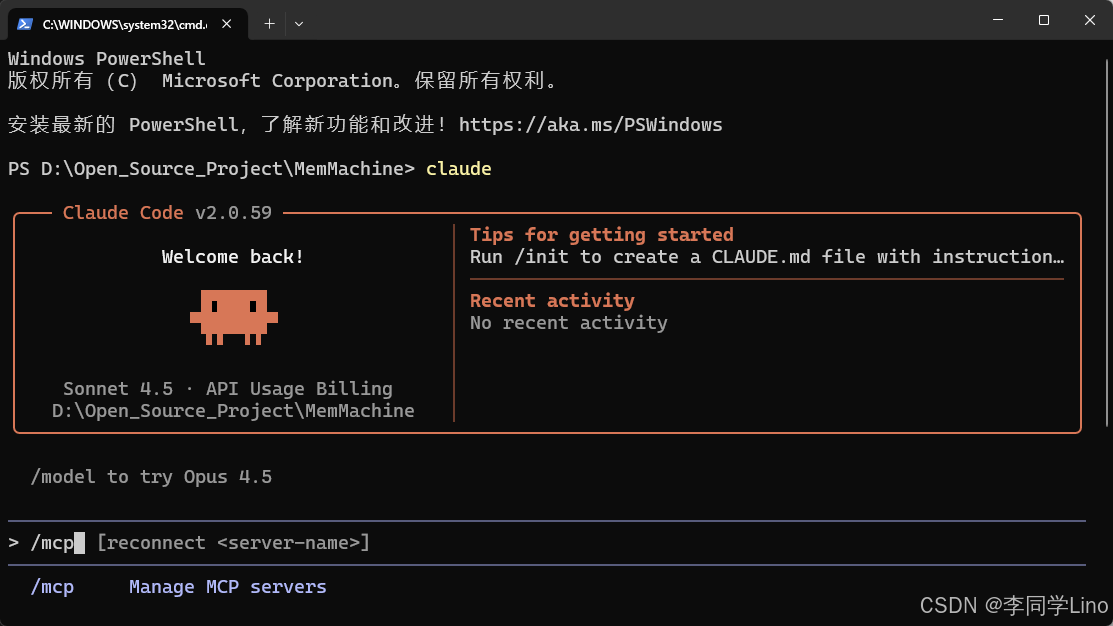
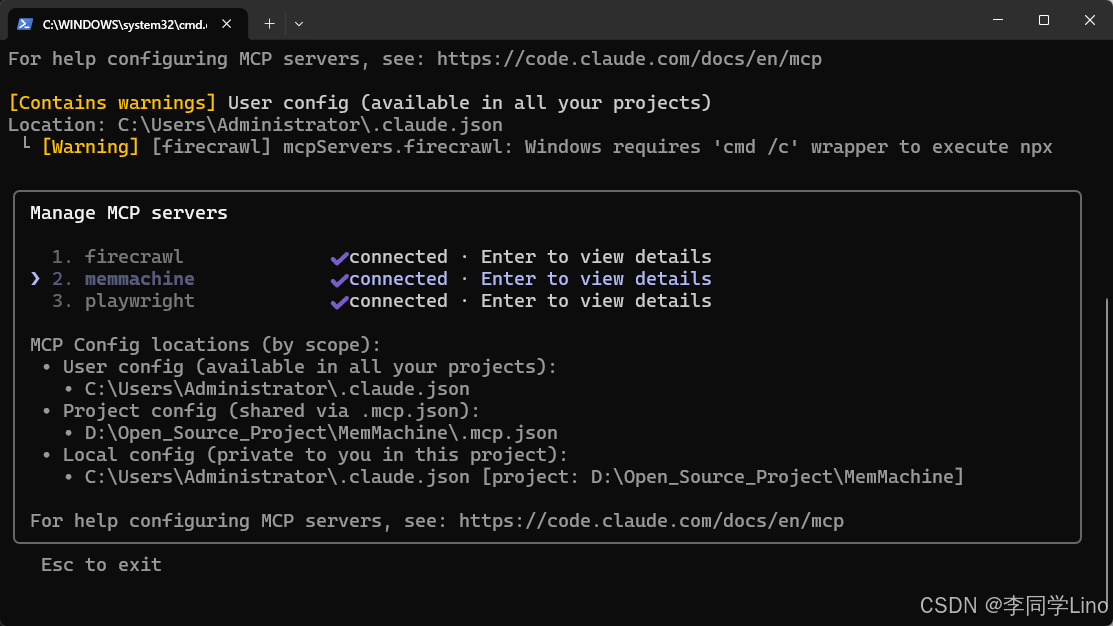
步骤 5:将“饮食习惯”写入记忆并读取
接下来,我们要进行整个流程中最关键的实战演示:让 Claude 将一段真实的用户信息写入 MemMachine,并在下一次会话中成功取回这些长期记忆。这将直接验证 MemMachine 是否真正具备跨会话记忆能力,也验证 Claude Code 是否能通过 MCP 正确读写长期档案。
为了测试,我们会让 Claude 记住一段典型的“用户档案信息”,包含饮食偏好、忌口、三餐作息、生活习惯以及健康目标等内容——这些信息非常适合用来展示 MemMachine 的结构化记忆能力。下面这段话,就是我们将发送给 Claude,让它写入长期记忆的示例文本:
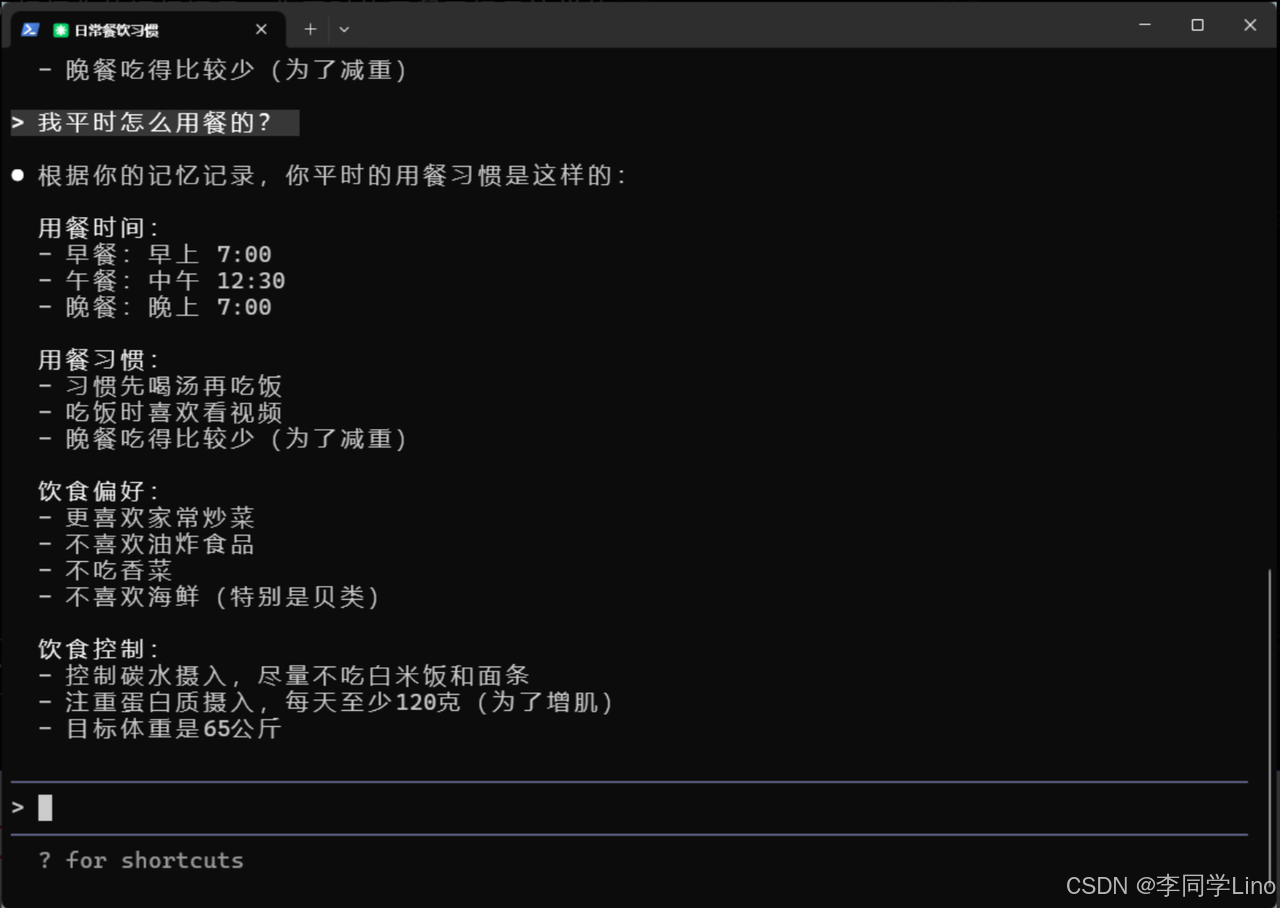
“您好,请记住我的饮食习惯,其中,我喜欢吃辣的,尤其是川菜和湘菜。我不吃香菜,也不喜欢海鲜,特别是贝类。我更喜欢家常炒菜,不喜欢油炸食品。我通常早上7点吃早餐,中午12点半午餐,晚上7点晚餐。我习惯先喝汤再吃饭,吃饭时喜欢看视频。我在控制碳水摄入,尽量不吃白米饭和面条。我的目标是增肌,需要多摄入蛋白质,每天至少120克。我想减到65公斤,所以晚餐吃得比较少。就这些了,记住一下。”
发送后,Claude 会自动调用 MemMachine,将这些内容拆解成“偏好”“禁忌”“作息”“营养目标”等结构化字段,并写入 Profile Memory。稍后我们会关闭会话,再通过一个新的对话验证,这些信息是否真的被长期记住并能被智能调用。
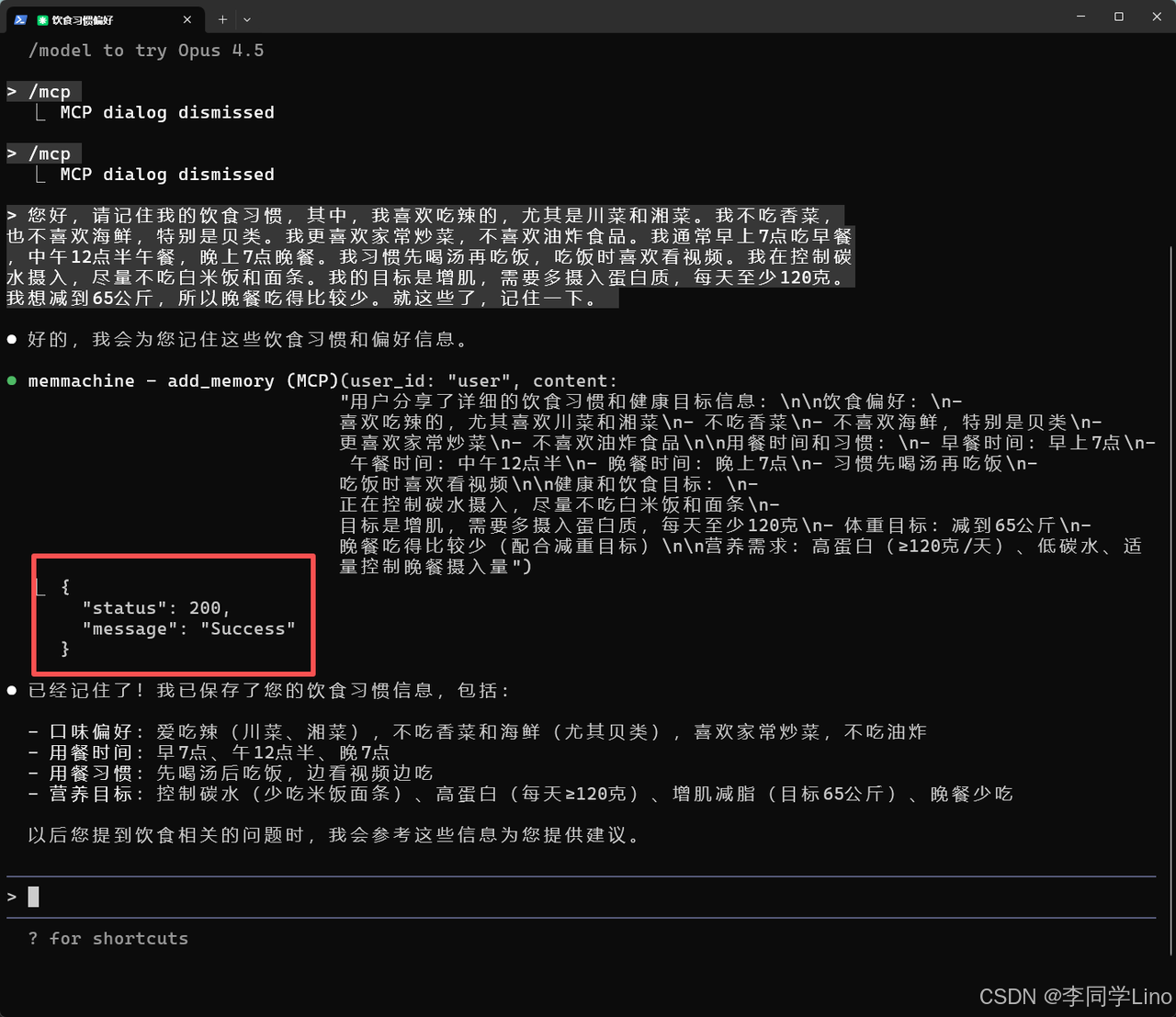
然后我们关掉这个终端命令,重新打开一个,又进行提问。比如:我一天的用餐时间
4️⃣ 魔改成中转 API 配置
有些同学可能会遇到一个常见问题:“我没有 OpenAI 的 API Key,那还能用 MemMachine 吗?”
当然可以。我们完全可以把模型调用切换为国产的阿里云 API,只需要对 MemMachine 的代码和配置做一点“小魔改”,就能顺利跑起来。接下来我会一步步带你完成这项修改。
第一步,我们需要进入 MemMachine 项目目录,找到 configuration.yml 文件,并对其中的模型配置进行调整。参考示例如下:
logging:
path: /tmp/memory_log
level: info # | debug | error
long_term_memory:
derivative_deriver: sentence
metadata_prefix: ""
embedder: openai_embedder
reranker: my_reranker_id
vector_graph_store: my_storage_id
SessionDB:
uri: sqlitetest.db
Model:
gpt:
model_vendor: openai-compatible
model: "gpt-5.1"
api_key: "sk-xxx" # 替换为您的实际API密钥
base_url: "https://linoapi.com.cn/v1"
storage:
profile_storage:
vendor_name: postgres
host: postgres
port: 5432
user: memmachine
db_name: memmachine
password: memmachine_password
profile_memory:
llm_model: gpt
embedding_model: openai_embedder
database: profile_storage
prompt: profile_prompt
sessionMemory:
model_name: gpt
message_capacity: 500
max_message_length: 16000
max_token_num: 8000
embedder:
openai_embedder:
provider: openai
config:
model_vendor: openai
model_name: "text-embedding-ada-002" # 根据您的平台支持的embedding模型调整
model: "text-embedding-ada-002" # 根据您的平台支持的embedding模型调整
api_key: "sk-xxx" # 替换为您的实际API密钥
base_url: "https://linoapi.com.cn/v1"
dimensions: 1536
reranker:
my_reranker_id:
provider: "rrf-hybrid"
config:
reranker_ids:
- id_ranker_id
- bm_ranker_id
id_ranker_id:
provider: "identity"
bm_ranker_id:
provider: "bm25"
aws_reranker_id:
provider: "amazon-bedrock"
config:
region: "us-west-2"
aws_access_key_id: <AWS_ACCESS_KEY_ID>
aws_secret_access_key: <AWS_SECRET_ACCESS_KEY>
model_id: "amazon.rerank-v1:0"
prompt:
profile: profile_prompt
vector_graph_store:
my_storage_id:
provider: neo4j
config:
uri: "bolt://neo4j:7687"
username: neo4j
password: neo4j_password在修改 configuration.yml 时,请特别注意其中的这一项:api_key: "sk-xxx",这里的 sk-xxx 必须替换成你自己的真实 API Key,否则 MemMachine 将无法正常调用模型服务。修改完成后记得保存文件,并重新启动服务以使配置生效。
在配置 MemMachine 的模型服务之前,我们需要先在中转 API 平台申请一个可用的 API Key,用于替代 OpenAI 的原生 Key。只需要简单几步,即可完成授权与配置。
首先前往平台注册或登录账号:👉 https://linoapi.com.cn/register?aff=sJ68
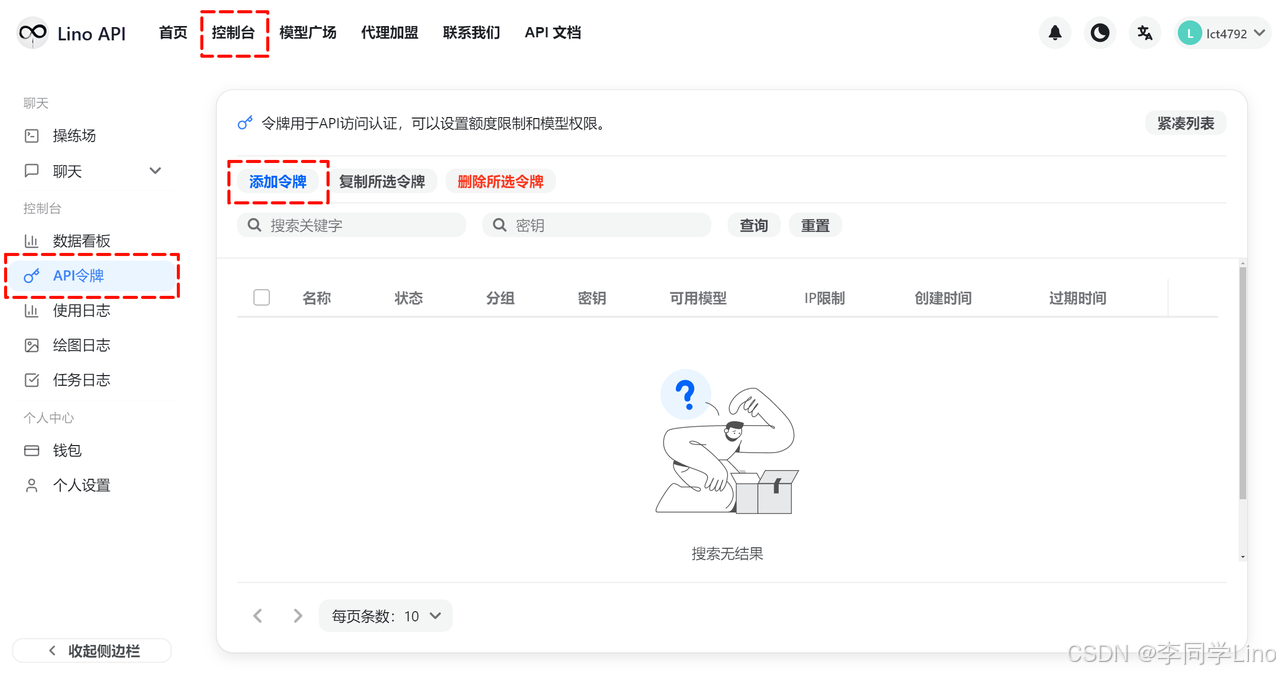
进入控制台后,在顶部导航栏选择 「控制台」,然后在左侧菜单中找到 「API 令牌」。点击 「添加令牌」 即可创建一个新的 API Key。
创建令牌时,“名称”可以随意填写,例如我填写的是 MemMachine。 “分组”建议选择 优质官转OpenAI,接着我们会在 MemMachine 的配置文件中填写模型名称,中转平台会根据模型自动路由到正确的接口。
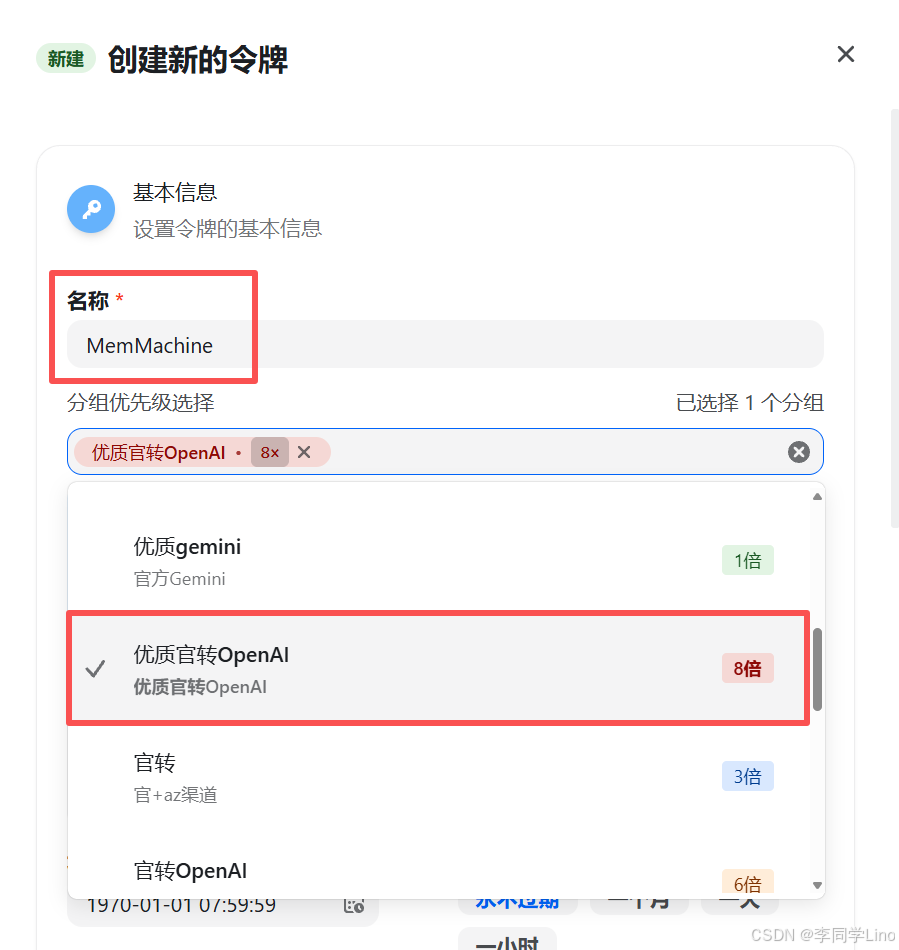
你还可以为这个令牌设置额度限制,例如设置 50 元 作为上限,确保 MemMachine 的调用不会意外消耗过多费用。如果你希望不限额度,也可以选择无限制。但无论哪种方式,请记得在 「钱包」 中充值,否则 API 将无法调用。
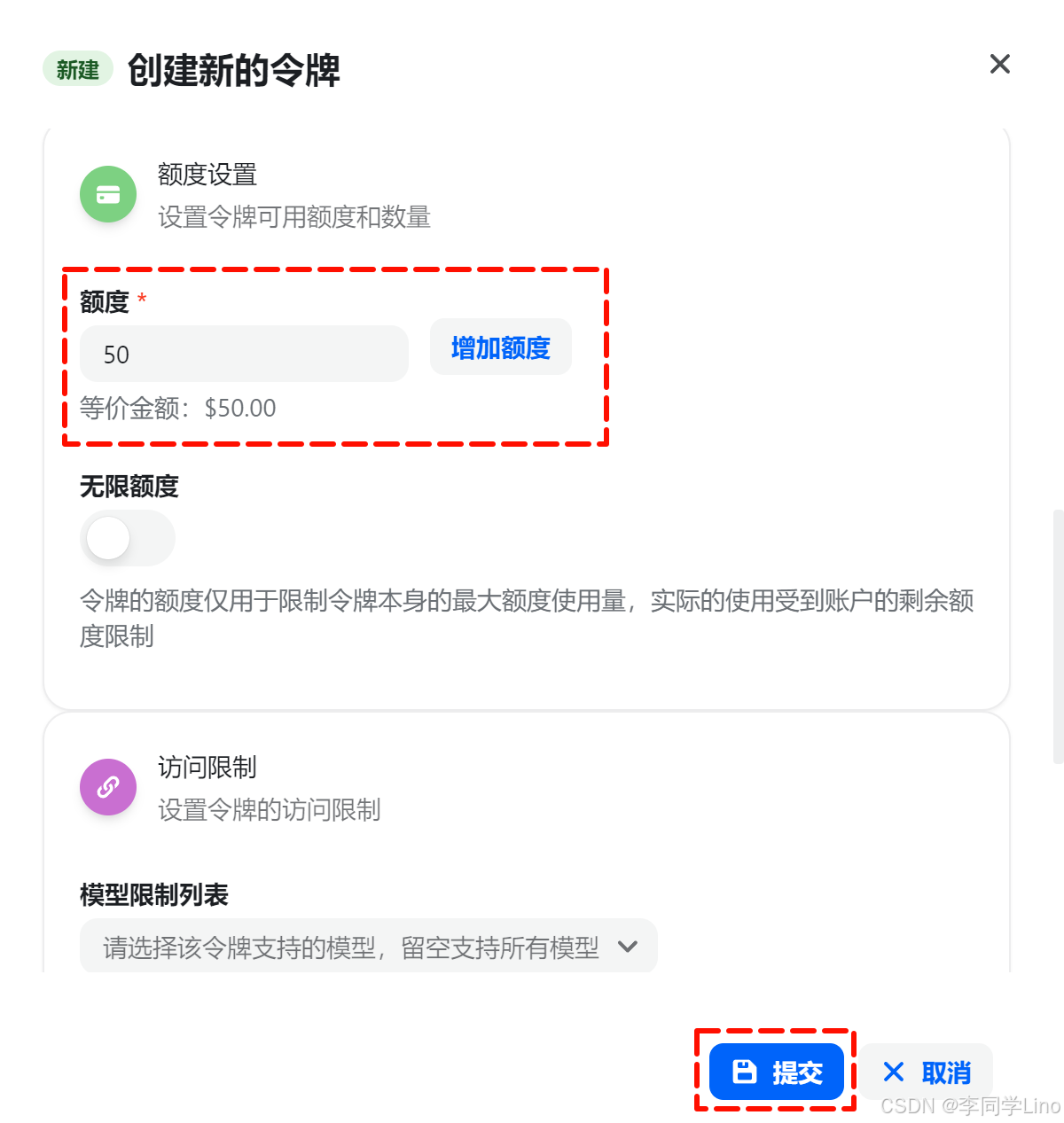
创建完成后,系统会生成一个 API Key。把这个 Key 复制下来,稍后我们需要把它写入 MemMachine 项目的配置文件中。
在 MemMachine 中使用中转 API 时,一般填写以下两项内容:
-
Base URL:
https://linoapi.com.cn/v1 -
api_key:复制你刚生成的 Key,例如:
sk-xxxxxx
修改完成后保存,并重启 MemMachine,即可让其使用中转 API 平台作为模型服务来源。
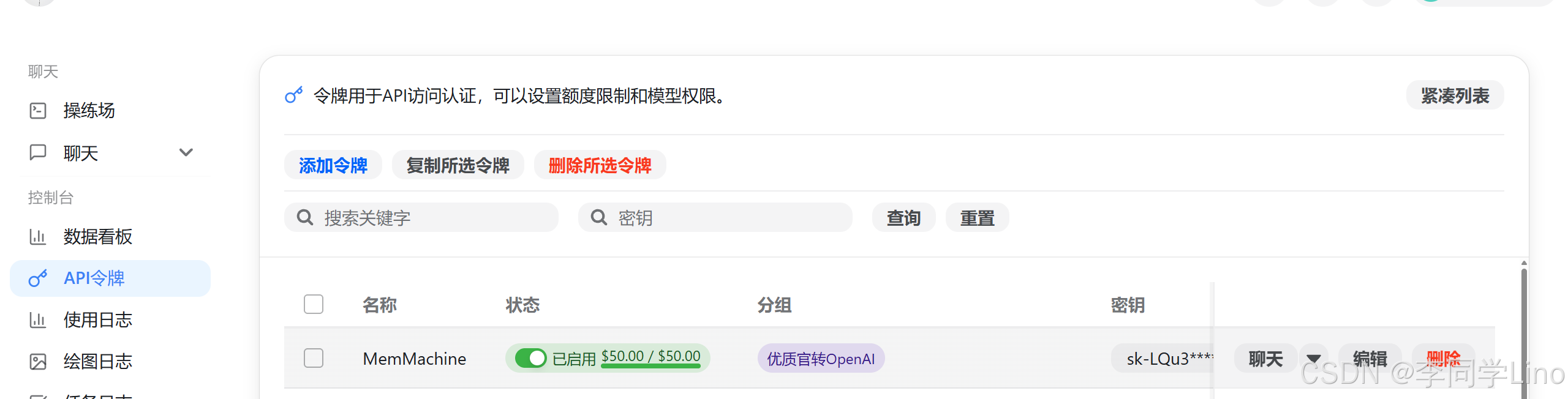
在调整完 configuration.yml 之后,记得同时修改项目根目录下的 .env 环境变量文件。其中最关键的是这一项:OPENAI_API_KEY=sk-xxx,请务必将 sk-xxx 替换成你实际使用的 API Key,否则 MemMachine 在调用模型时会因为认证失败而无法正常运行。修改完成后保存文件,再重新启动服务即可。
# =============================================================================
# PostgreSQL / pgvector Database Configuration
# =============================================================================
POSTGRES_HOST=postgres
POSTGRES_PORT=5432
POSTGRES_USER=memmachine
POSTGRES_PASSWORD=memmachine_password
POSTGRES_DB=memmachine
# =============================================================================
# Neo4j Database Configuration
# =============================================================================
NEO4J_HOST=neo4j
NEO4J_PORT=7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=neo4j_password
NEO4J_HTTP_PORT=7474
NEO4J_HTTPS_PORT=7473
# =============================================================================
# MemMachine Configuration
# =============================================================================
MEMORY_CONFIG=configuration.yml
MCP_BASE_URL=http://memmachine:8080
GATEWAY_URL=http://localhost:8080
FAST_MCP_LOG_LEVEL=INFO
# =============================================================================
# OpenAI / LinoAPI Configuration
# =============================================================================
# GPT-5.1 LLM 和 Embedding 模型都使用这一把 key
OPENAI_API_KEY=sk-xxx # 替换为您的实际API密钥
# 您的API中转平台基础URL
OPENAI_BASE_URL=https://linoapi.com.cn/v1
# =============================================================================
# MemMachine Optional Settings
# =============================================================================
LOG_LEVEL=INFO
MEMORY_SERVER_PORT=8080
# 数据库连接池
DB_POOL_SIZE=10
DB_MAX_OVERFLOW=20
# 镜像版本
MEMMACHINE_IMAGE=memmachine/memmachine:latest-cpu在修改完配置文件和环境变量后,一定要重新构建并启动 MemMachine 服务,使最新的配置生效。请进入项目目录:D:\Open_Source_Project\MemMachine\MemMachine,然后依次运行以下两条命令:
docker-compose down
docker-compose up -d --build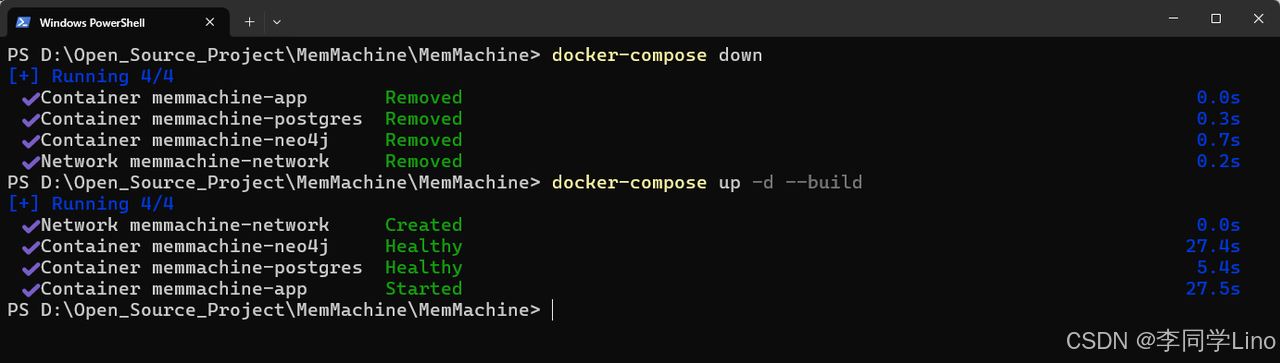
第一条命令会停止并卸载旧的容器,第二条命令会在重新构建镜像后以后台方式启动服务。完成重启后,你的 MemMachine 就已经加载了新的模型配置,这时就可以打开 Claude,开始愉快地体验带“长期记忆”的智能体啦!
5️⃣ 写在最后
至此,我们已经完整地为 Claude Code 装上了真正意义上的“长期大脑”:MemMachine 不仅让 AI 具备跨会话记忆能力,更让它能够随着你的使用不断学习、更新和完善自己。从部署、配置、接入 MCP,到写入用户的信息并在下一次对话中成功取回,这套流程跑通之后,你会明显感受到——AI 已经从一个“即时回答工具”,升级成了一个真正会“记住你”的智能助手。
希望这篇教程能帮你顺利完成安装与集成,也期待你把它应用在自己的项目里。如果文章对你有帮助,欢迎收藏、转发,也可以在评论区交流你的体验与遇到的问题,我们一起把 AI Agent 做得更聪明、更持久、更强大。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)