多模态:模态表示、多模态融合、跨模态对齐
这三者共同构成了多模态AI的认知框架,让机器从“单感官专家”进化为“多感官通才”,向真正的通用人工智能迈进。:这两个向量虽然维度相同,但来自完全不同的“语义空间”,无法直接比较或结合。:学习到一个共享的语义空间,相似的语义无论来自哪种模态,都在此空间中靠近。:当模态、数据和模型规模达到临界点,出现跨模态的零样本、推理、创作能力。:如何将不同类型(模态)的原始数据,转化为机器可以理解和处理的。:没有
多模态AI:三大核心支柱
多模态人工智能旨在让机器像人类一样,通过多种感官(视觉、听觉、触觉等)协同理解世界。其核心架构建立在三大支柱之上:
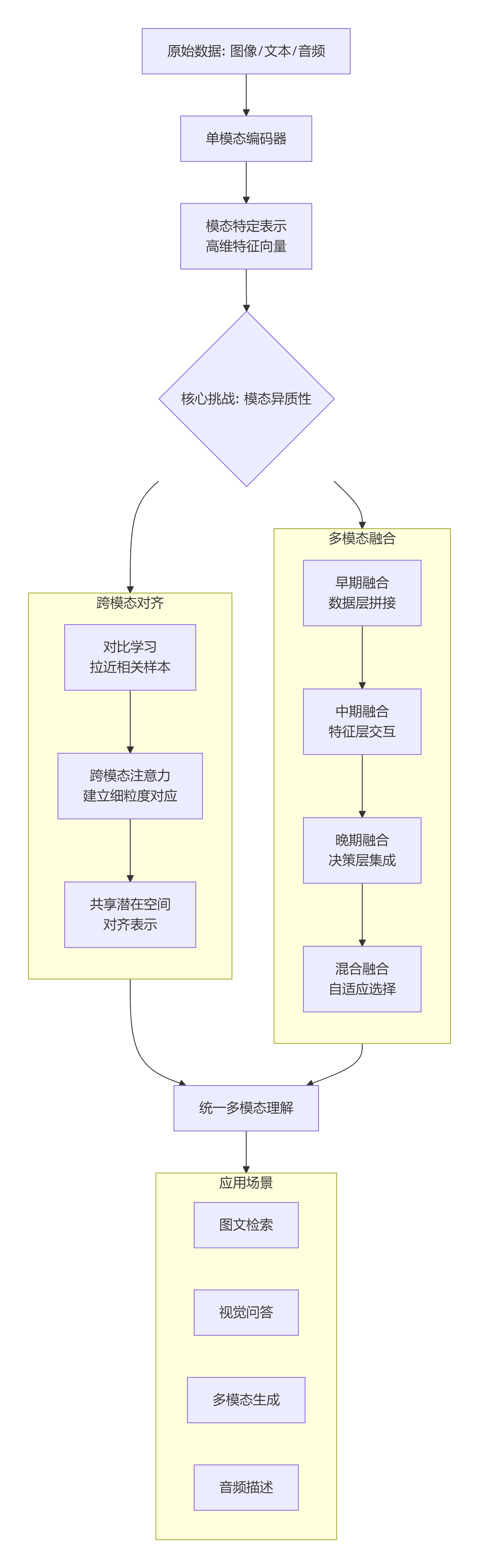
以下是这三大支柱的详细解析:
1. 模态表示:为每种感官建立“数字化身”
核心问题:如何将不同类型(模态)的原始数据,转化为机器可以理解和处理的统一数学表示(通常是高维向量)?
关键挑战:模态异质性
-
图像:像素矩阵,空间局部相关
-
文本:词序列,时间/逻辑顺序相关
-
音频:波形或频谱,时频特征相关
-
视频:图像序列+音频,时空混合
主流方法:
| 模态 | 代表性编码器 | 输出特征 | 特点 |
|---|---|---|---|
| 文本 | Transformer (BERT, GPT) | 768-4096维向量 | 捕获语义和上下文 |
| 图像 | CNN (ResNet) / ViT | 2048维特征图或序列 | 捕获空间层次特征 |
| 音频 | CNN (VGGish) / 频谱变换 | 128维梅尔频谱特征 | 捕获时频模式 |
| 视频 | 3D-CNN / 时空ViT | 时空特征序列 | 捕获运动和时序 |
示例:
-
一句“狗在跑” → BERT编码 → [0.23, -0.45, 0.87, ...] (768维)
-
一张狗跑步的图片 → ViT编码 → [0.12, 0.89, -0.34, ...] (768维)
此时的问题是:这两个向量虽然维度相同,但来自完全不同的“语义空间”,无法直接比较或结合。
2. 多模态融合:如何整合多种感官信息
核心问题:获得各个模态的表示后,如何将它们有效地结合起来,以获得比单一模态更全面、更准确的理解?
这是多模态AI的核心决策机制,决定了信息整合的时机和方式。
四大融合策略
| 融合类型 | 融合时机 | 实现方式 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|---|
| 早期融合 | 数据/特征层 | 直接拼接原始数据或浅层特征 | 保留原始信息,允许深度交互 | 受模态异质性干扰大 | 模态同步性好的场景(如音视频) |
| 中期融合 | 中间表示层 | 通过注意力、跨模态变换器交互 | 平衡交互与特异性,灵活性高 | 架构复杂,计算成本高 | 主流选择,如视觉问答 |
| 晚期融合 | 决策/输出层 | 各自处理,最后融合结果(投票、加权) | 容错性强,模块化 | 错过早期交互机会 | 模态质量不一的场景 |
| 混合融合 | 多个层次 | 组合上述多种方式 | 发挥各自优势,鲁棒性强 | 极其复杂,难训练 | 复杂任务(如自动驾驶) |
关键技术:跨模态注意力机制
这是中期融合的灵魂。它允许一个模态的表示动态地“关注”另一个模态的相关部分。
示例(视觉问答):
-
问题:“图中红色的物体是什么?”
-
文本注意力:聚焦于“红色”
-
视觉注意力:在图像中寻找红色区域
-
交互:文本向量指导视觉注意力的分配,视觉特征反过来修正文本理解
3. 跨模态对齐:建立模态间的“共同语义空间”
核心问题:不同模态的表示在语义上如何对应?如何确保“狗的图片”和“狗的文字描述”在向量空间中接近?
这是多模态理解的基础前提,没有对齐,融合就是盲目的。
三大对齐范式
| 对齐类型 | 核心思想 | 关键技术 | 示例 |
|---|---|---|---|
| 实例级对齐 | 整个样本对应 | 对比学习(CLIP) | 图片-标题对互相匹配 |
| 区域-词级对齐 | 局部元素对应 | 跨模态注意力 | 图像区域←→描述词语 |
| 隐式语义对齐 | 概念空间对应 | 共享潜在空间学习 | “快乐”的情感←→笑脸图片 |
关键技术详解
1. 对比学习(如CLIP)
-
核心:拉近匹配的图文对,推远不匹配的对
-
损失函数:InfoNCE Loss
-
效果:学习到一个共享的语义空间,相似的语义无论来自哪种模态,都在此空间中靠近
2. 跨模态注意力对齐
-
学习一个对齐矩阵,显示标注哪个词对应哪个图像区域
-
常用于图像描述生成、视觉 grounding 任务
3. 三元组损失
-
让锚点样本与正样本(相同语义)更近,与负样本(不同语义)更远
-
公式:
L = max(0, d(锚点,正样本) - d(锚点,负样本) + margin)
三者的协同关系
实际上,这三个支柱是紧密交织、相互依赖的:
-
表示是基础:好的单模态表示能极大简化对齐和融合的难度。
-
对齐是桥梁:没有良好的跨模态对齐,融合就像在混合不同语言的不相关词汇。
-
融合是目标:最终目的是通过有效的融合做出更好的决策。
现代统一架构:多模态Transformer
以 ViLBERT、LXMERT、UNITER 为代表的模型,将这三大支柱统一在一个框架中:
-
输入层:各模态分别编码(表示)
-
交叉注意力层:模态间相互查询、对齐
-
融合编码层:深度融合,生成联合表示
-
任务头:针对下游任务微调
而像 GPT-4V、Flamingo 等多模态大模型,更进一步:
-
统一表示:将图像分割为patches,与文本tokens同等处理
-
统一对齐:通过海量数据自监督学习,隐式对齐
-
统一融合:通过超大规模Transformer自然融合
应用示例:图文检索系统
-
表示:图像用ViT编码,文本用BERT编码
-
对齐:通过对比学习训练,使相关图文在共享空间中接近
-
融合:查询时,将文本查询映射到共享空间,寻找最近的图像向量
-
输出:返回最相关的图像
未来趋势
-
更统一的表示:一切模态皆tokens(图像patches、音频片段、文本词元)
-
更智能的对齐:从显式监督对齐 → 自监督隐式对齐
-
更灵活的融合:从固定融合策略 → 动态路由、可学习的融合机制
-
涌现能力:当模态、数据和模型规模达到临界点,出现跨模态的零样本、推理、创作能力
总结
-
模态表示:解决“如何数字化”问题,为每种感官建立数字化身
-
跨模态对齐:解决“如何对应”问题,建立模态间的语义桥梁
-
多模态融合:解决“如何整合”问题,像人脑一样综合判断
这三者共同构成了多模态AI的认知框架,让机器从“单感官专家”进化为“多感官通才”,向真正的通用人工智能迈进。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)