YOLOv11 Object Detection System: Training & Modern GUI
YOLOv11目标检测系统提供完整的训练与现代化GUI解决方案。项目包含自动化训练流程(VOC→YOLO格式转换、数据集划分、模型训练)和基于PyQt5的清新简约推理界面。系统特色包括: 训练模块:自动处理VOC数据集,生成YOLO配置文件,一键启动训练 GUI模块:支持多格式图片导入,实时目标检测与交互式标记,按类别过滤结果 现代化界面:采用qt-material主题,提供悬停高亮、实时统计等交
YOLOv11 Object Detection System: Training & Modern GUI
本项目提供了一套完整的 YOLOv11 目标检测系统,包含:
- 🎯 自动化训练流程:VOC → YOLO 格式转换、数据集划分、模型训练
- 🎨 现代化推理界面:PyQt5 + qt-material 打造的清新简约 GUI
- 🚀 开箱即用:提供完整代码、详细文档和故障排查指南
📋 目录
项目简介
核心功能
🔧 训练模块 (train_pipeline.py)
自动化的数据处理和模型训练流程:
- 📁 自动扫描 VOC 格式 XML 注解文件
- 🔄 实时坐标转换:
(xmin, ymin, xmax, ymax)→(x_center, y_center, width, height) - 📊 自动化数据集划分(支持自定义训练/验证比例)
- ⚙️ 自动生成 YOLO 配置文件 (
voc2012.yaml) - 🎓 一键启动 YOLOv11 模型训练
🎨 GUI 模块 (modern_app.py)
现代化的推理展示界面:
- 🖼️ 支持多格式图片导入 (PNG, JPG, JPEG, BMP)
- 🎯 实时目标检测和标记
- 🏷️ 交互式检测框(悬停高亮、点击查看详情)
- 📈 实时统计面板(类别统计)
- 🔍 按类别过滤检测结果
- 🌈 清新莫兰迪配色方案
环境依赖
Python 版本要求
- Python 3.8+
安装依赖
# 1. 创建虚拟环境(可选)
python -m venv venv
source venv/bin/activate # Linux/Mac
# 或
venv\Scripts\activate # Windows
# 2. 升级 pip
pip install --upgrade pip
# 3. 安装核心依赖
pip install numpy>=1.21.0 pandas>=1.3.0 opencv-python>=4.5.0 scikit-learn>=1.0. 0 pillow>=8.3.0
# 4. 安装 YOLOv11
pip install ultralytics
# 5. 安装 GUI 依赖
pip install PyQt5>=5.15.0 qt-material>=2.14 qtawesome>=1.1.0
或者一条命令安装全部:
pip install numpy pandas opencv-python scikit-learn pillow ultralytics PyQt5 qt-material qtawesome
项目结构
yolov11-detection-system/
├── README.md # 本文档
├── train_pipeline.py # 训练模块(VOC→YOLO 转换 + 模型训练)
├── modern_app.py # GUI 推理模块
├── requirements.txt # 依赖列表
├── best. pt # 训练好的模型权重(需自行训练或下载)
└── data/
├── VOC2012/ # VOC 数据集目录
│ ├── Annotations/ # XML 标注文件
│ ├── JPEGImages/ # 图片文件
│ └── yolo_format/ # YOLO 格式输出目录
└── sample_images/ # 示例图片
Part 1: 数据预处理与模型训练
📌 核心流程
- 扫描 XML 文件 → 2. 解析标注信息 → 3. 坐标归一化 → 4. 数据集划分 → 5. 生成 YAML → 6. 启动训练
📖 使用说明
第一步:准备数据
# 确保你的 VOC 数据集结构如下:
# VOC2012/
# ├── Annotations/ (XML 文件)
# └── JPEGImages/ (图片文件)
第二步:修改路径
编辑 train_pipeline.py,修改第 14 行:
BASE_PATH = "你的VOC数据集路径" # 例如: "D:/datasets/VOC2012"
第三步:运行训练
python train_pipeline.py
Part 2: 现代化推理 GUI
🎨 界面特色
| 特性 | 说明 |
|---|---|
| 🌈 清新主题 | Light Teal qt-material 主题 + 白色卡片式布局 |
| 🖱️ 交互优化 | 检测框悬停高亮、点击查看详情 |
| 📊 实时统计 | 类别统计面板自动更新 |
| 🔍 类别过滤 | 按类别显示/隐藏检测结果 |
| 🎯 矢量图标 | FontAwesome 图标美化 UI |
应用演示
应用主界面示例
下图展示了现代化识别系统的主界面,清新的 Light Teal 主题、卡片式布局和直观的操作面板一目了然:
界面说明:
- 📸 左侧画布:显示加载的图片,支持鼠标拖拽平移、滚轮缩放
- 🎯 检测框:彩色矩形框标注检测目标,显示类别和置信度
- 🎨 右侧控制面板:
- “选择图片” 按钮:导入新图片
- “开始检测” 按钮:执行目标检测
- “类别筛选”:按类别显示/隐藏检测结果
- “检测统计”:实时显示各类别检测数量
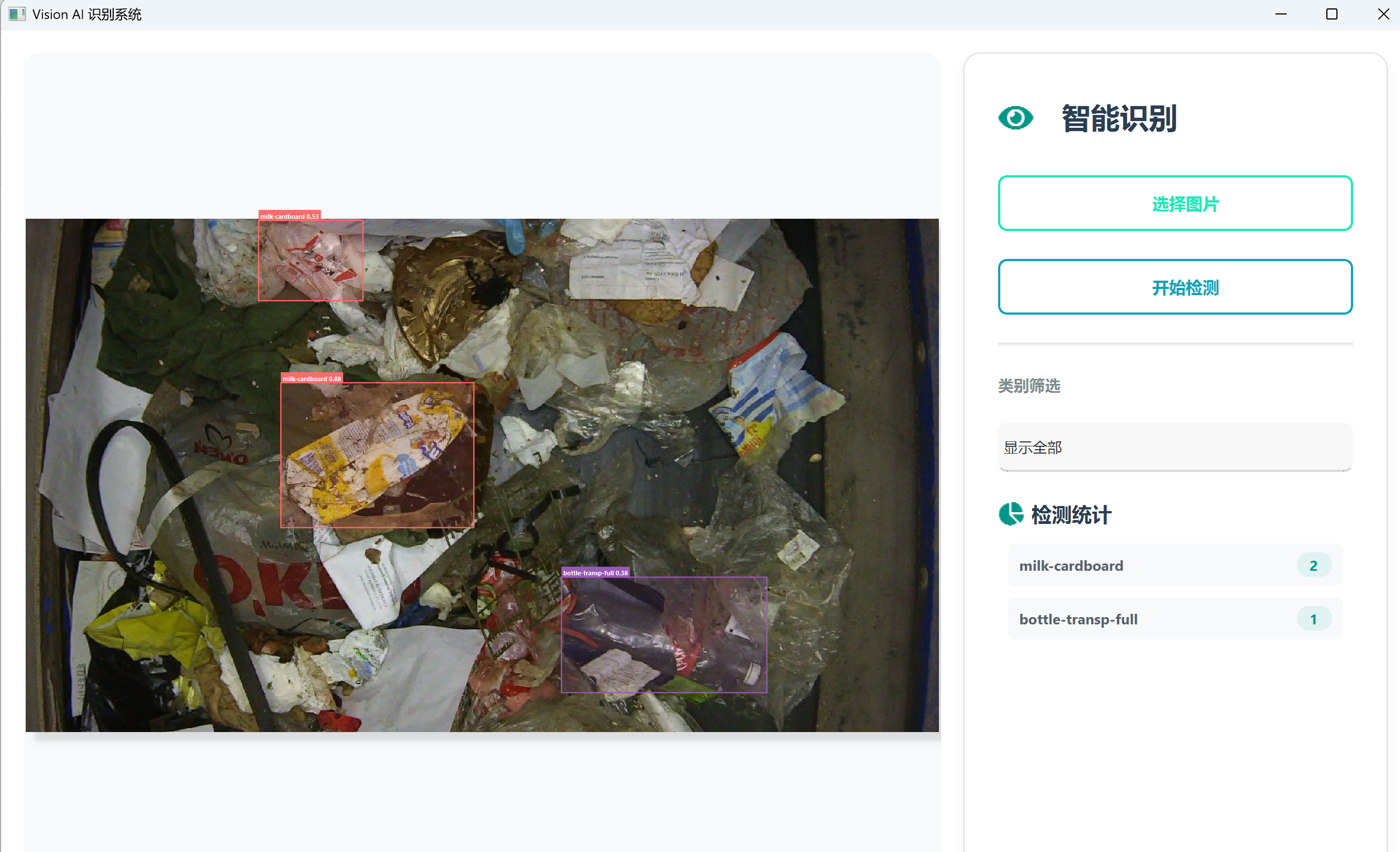
检测结果可视化示例
下图展示了在垃圾分类数据上的实时检测效果,不同类型的垃圾用不同颜色的边框高亮标注,并显示对应的类别名称和置信度值:

检测特性:
- ✅ 多目标检测:同时检测图像中的多个对象
- 🎯 精确定位:边框紧密环绕目标
- 📊 置信度显示:每个检测框上方显示类别和置信度
- 🌈 彩色区分:不同类别使用不同颜色便于区分
快速开始
方式一:快速演示(不需要训练)
# 1. 克隆/下载项目
git clone https://github.com/JohnMonroe4470/yolov11-detection-system.git
cd yolov11-detection-system
# 2. 安装依赖
pip install -r requirements.txt
# 3. 下载预训练模型
# 自动下载:运行时如果没有 best.pt,会自动使用 yolo11s.pt
# 4. 运行推理 GUI
python modern_app.py
方式二:完整流程(从数据训练到推理)
# 1-2 同上
# 3. 准备 VOC 数据集
# 修改 train_pipeline.py 中的 BASE_PATH 为你的数据集路径
# 4. 训练模型
python train_pipeline.py
# 5. 推理
python modern_app. py
故障排查
❌ 问题 1: TypeError: setPen() 报错
错误消息:
TypeError: setPen(self, pen: Union[QPen, Union[QColor, Qt.GlobalColor]]):
argument 1 has unexpected type 'PenStyle'
原因: 代码中使用 Qt.NoPen 直接作为参数,但 QPen() 需要一个 QPen 对象。
解决方案:
# ❌ 错误
self.text_bg. setPen(Qt.NoPen)
# ✅ 正确
self.text_bg.setPen(QPen(Qt.NoPen))
修复位置: modern_app.py 第 79 行
❌ 问题 2: qt. svg 资源加载警告
警告信息:
qt.svg: Cannot open file 'D:/path/icon:/active/downarrow.svg'
原因: qt-material 库在 Windows 上的已知路径拼接 Bug。
影响: 无实质影响,仅控制台输出,界面功能正常。
处理方法:
- ✅ 方法 1:忽略警告(推荐)- 不影响使用
- 方法 2:在脚本前添加环境变量过滤(高级)
import os
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = ''
❌ 问题 3: 模型加载失败
错误信息:
FileNotFoundError: [Errno 2] No such file or directory: './best.pt'
原因: 找不到训练好的模型文件。
解决方案:
# 方法 1:指定完整路径
self.model = YOLO("D:/your_path/best.pt")
# 方法 2:使用预训练模型
self.model = YOLO("yolo11s.pt") # 自动下载
# 方法 3:指定本地下载的模型
self.model = YOLO("yolo11m.pt") # yolo11n/s/m/l/x 可选
❌ 问题 4: 数据集转换失败
症状: 运行 train_pipeline.py 后没有生成 YOLO 格式文件。
排查步骤:
- 检查路径:
import os
BASE_PATH = "F:/archive(11)/VOC2012"
print(os.path.exists(os.path.join(BASE_PATH, "Annotations"))) # 应输出 True
print(os.path. exists(os.path.join(BASE_PATH, "JPEGImages"))) # 应输出 True
- 检查 XML 文件:
ls F:/archive(11)/VOC2012/Annotations/*. xml # Linux/Mac
dir F:\archive(11)\VOC2012\Annotations\*.xml # Windows
- 运行调试版本:
# 在 train_pipeline.py 主函数中添加
XML_FILES = [...]
print(f"Found {len(XML_FILES)} XML files")
if len(XML_FILES) > 0:
print(f"First file: {XML_FILES[0]}")
常见问题
Q1: 为什么检测速度这么慢?
A:
- 🐢 使用了
batch=1的设置(节省显存),可改为batch=16或更大 - 🖥️ 使用 CPU 推理,建议使用 GPU(CUDA)
- 📦 模型太大,可使用
yolo11n.pt(nano 版本) 替代
建议修改:
model. train(
batch=8, # 增加批次大小
device=0 # 使用 GPU
)
Q2: 如何训练自己的数据集?
A:
- 准备 VOC 格式的标注数据(XML 文件)
- 修改
train_pipeline.py中的BASE_PATH - 运行
python train_pipeline.py - 等待训练完成
Q3: 检测框样式可以自定义吗?
A: 当然可以!修改 modern_app.py 中的:
# 修改检测框颜色(第 263 行)
COLORS = [
"#FF6B6B", "#4ECDC4", "#45B7D1", # 添加更多颜色
# ...
]
# 修改框线宽度(第 79 行)
pen = QPen(QColor(color), 2. 5) # 改为需要的宽度
# 修改框填充透明度(第 76 行)
c.setAlpha(40) # 改为 0-255 之间的值
Q4: 支持实时摄像头检测吗?
A: 当前版本仅支持图片检测。添加摄像头支持可参考以下代码:
import cv2
def camera_inference(self):
cap = cv2. VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret: break
results = self.model. predict(frame)
# 处理检测结果...
cv2.imshow('Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2. destroyAllWindows()
贡献指南
欢迎提交 Issue 和 Pull Request!
许可证
本项目采用 MIT License 开源许可证。详见 LICENSE 文件。
联系方式
- 📧 Email: [1561363371@qq.com]
致谢
感谢以下开源项目的支持:
最后更新时间: 2025-12-05
当前版本: v1. 0.0

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)