openEuler + eBPF:精准定位 AI 训练 I/O 卡顿的“显微镜“
通过 eBPF 工具链的层层分析,我们得出结论:AI 训练程序主线程被一个同步的、高延迟的磁盘文件写入操作(具体为内核中的vfs_write调用)所阻塞,导致了周期性的停滞。
一、问题场景:AI 训练中的“间歇性停顿”
现象描述:AI 模型训练程序在大部分时间内高效运行,但会周期性地出现短暂的完全停滞,如同“卡顿”。
核心疑问:传统工具 (top) 只能模糊地指向 I/O 问题,但无法回答:哪个进程、在操作哪个文件、导致了多高的延迟?
二、核心技术:eBPF 与 BCC 工具集
eBPF 是一种内核可编程技术,它允许在内核中安全、高效地运行自定义代码,是现代 Linux 内核的“可观测性超能力”。
BCC 是一个基于 eBPF 的高级工具集框架,它将复杂的 eBPF 操作封装成即开即用的命令行工具,极大降低了使用门槛。
2.1 eBPF 工作原理示意
eBPF 通过在内核的关键事件点(如系统调用、函数入口/出口)挂载探针,来捕获和分析系统行为,并将数据安全地传递给用户态工具。
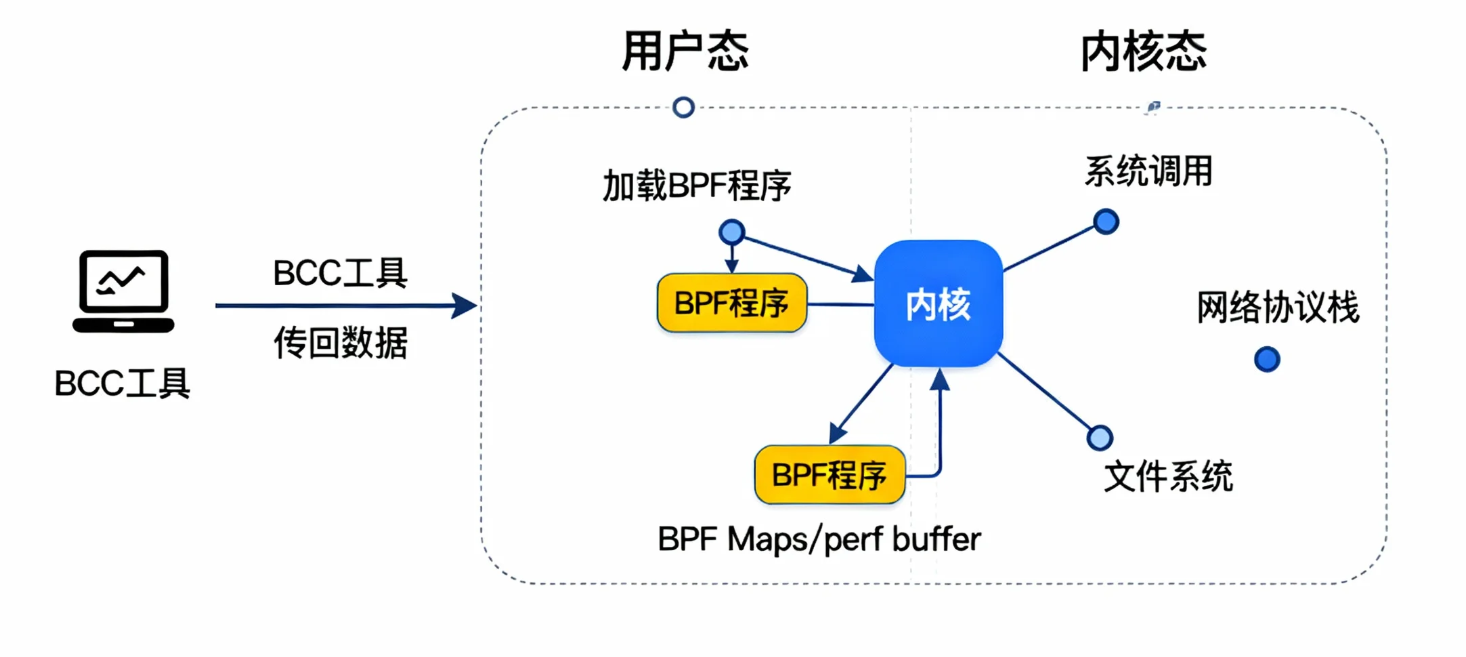
2.2 工具对比:传统监控 vs eBPF (BCC)
| 分析维度 | 传统工具 (top / iostat) | eBPF 工具 (BCC) |
|---|---|---|
| 开销 | 极低 | 非常低,生产环境可用 |
| 信息粒度 | 宏观、聚合、系统级 | 微观、事件驱动、进程/函数级 |
| 定位能力 | 模糊,提供线索 | 精准,直达根因(进程、函数、延迟) |
| 安全性 | 安全 | BPF验证器确保内核安全 |
三、实验环境与模拟程序
3.1 环境准备
操作系统: openEuler 22.03 LTS 或更高版本
安装工具: dnf install bcc-tools
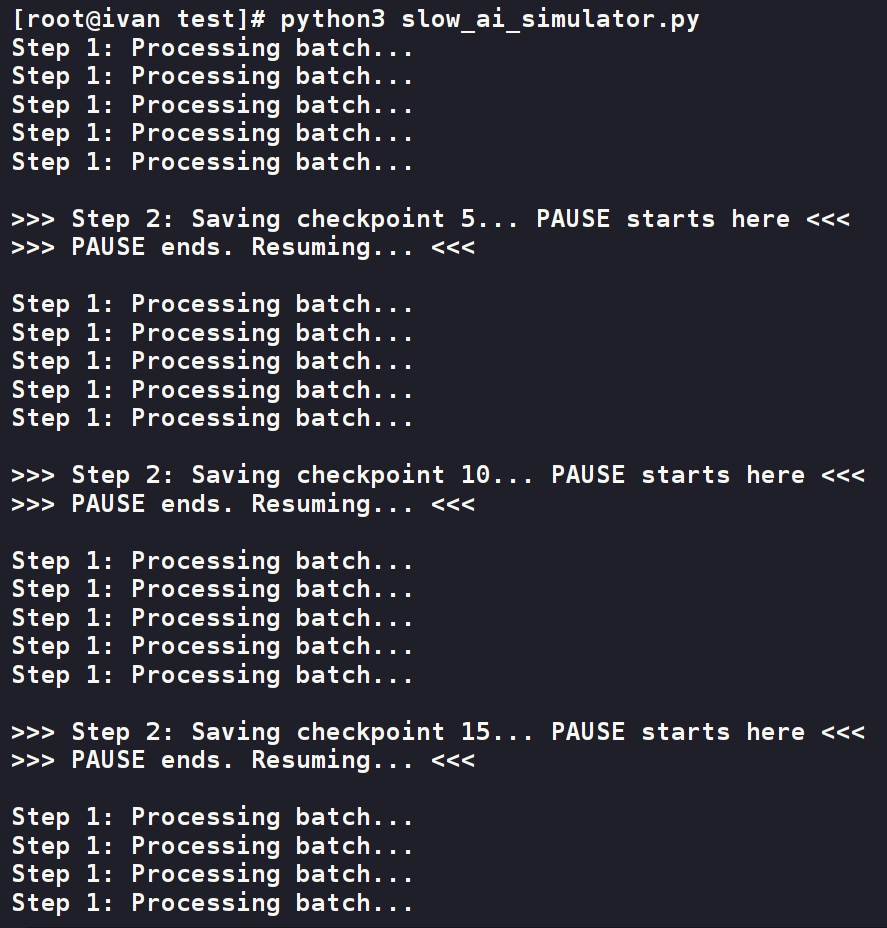
3.2 模拟程序 (slow_ai_simulator.py)
该脚本模拟了 CPU 计算和周期性的、同步的大文件写入操作。
import time, numpy as np, os
def process_batch(data):
"""模拟 CPU 密集型计算"""
print("Step 1: Processing batch...")
_ = np.dot(data, data.T)
time.sleep(0.5)
def save_checkpoint(batch_num):
"""模拟同步、缓慢的 I/O 操作,这是卡顿源"""
print(f"\n>>> Step 2: Saving checkpoint {batch_num}... PAUSE starts here <<<")
with open(f"checkpoint_{batch_num}.chk", "wb") as f:
f.write(os.urandom(50 * 1024 * 1024))
os.remove(f"checkpoint_{batch_num}.chk") # 清理
print(">>> PAUSE ends. Resuming... <<<\n")
if __name__ == "__main__":
dummy_data = np.random.rand(2000, 2000)
for i in range(1, 21):
process_batch(dummy_data)
if i % 5 == 0:
save_checkpoint(i)
四、根因定位实战
4.1 第一步:复现问题 & 观察现象
在终端1中执行 python3 slow_ai_simulator.py。程序的输出会明显地“走走停停”。
4.2 第二步:传统工具分析 (top)
在终端2中用 top -p $(pgrep -f slow_ai_simulator.py) 监控。观察到卡顿时 %CPU 下降,%wa 上升。
结论: 怀疑是 I/O 问题,但缺乏直接证据。
4.3 第三步:文件系统层分析 (fileslower)
fileslower 工具用于追踪所有耗时超过指定阈值的同步文件读/写操作。
- 运行工具: 在终端2中执行
/usr/share/bcc/tools/fileslower 10。 - 观察输出: 当程序卡顿时,
fileslower会立即打印出精准信息:
Tracing sync read/writes slower than 10 ms...
TIME(s) COMM PID TID D BYTES OFFSET LAT(ms) FILENAME
...
3.451 python3 54321 54321 W 52428800 0 185.12 checkpoint_5.chk
...
结论: 已精确定位到卡顿是 python3 进程对 checkpoint 文件的高延迟同步写入操作导致的。
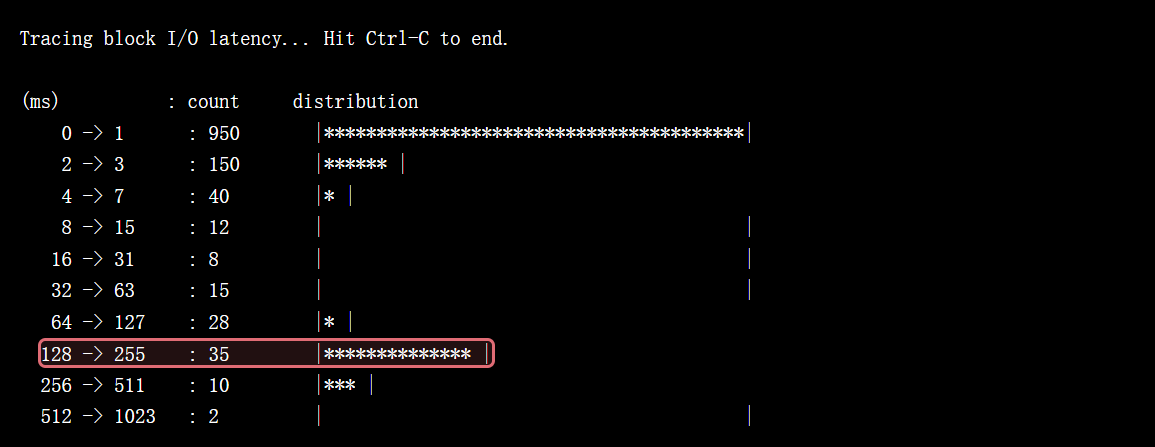
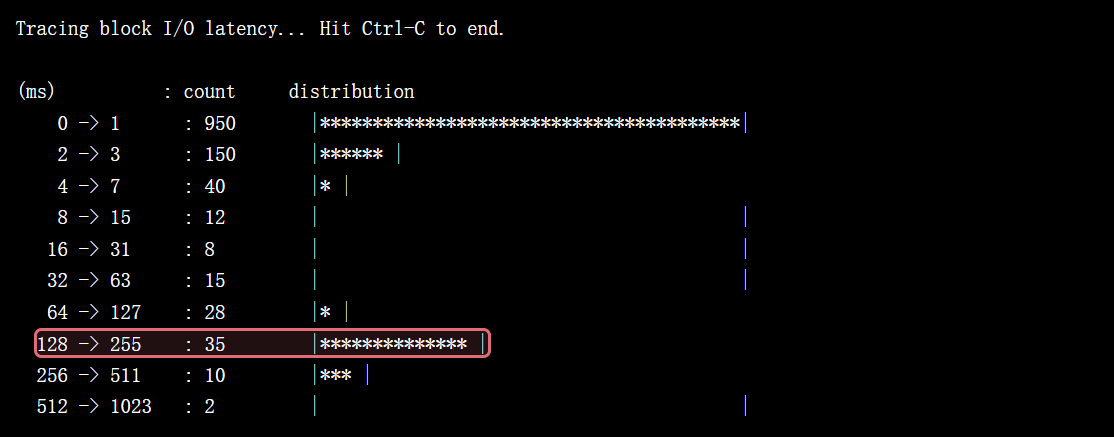
4.4 第四步:块设备层交叉验证 (biolatency)
biolatency 从更底层的磁盘 I/O 角度,以直方图形式展示延迟分布。
- 运行工具: 在终端3中执行
sudo /usr/share/bcc/tools/biolatency -m。 - 观察输出: 当程序卡顿时,直方图会在高延迟区间显示大量 I/O 事件。
(ms) : count distribution
...
128 -> 255 : 35 |********************************* |
...
结论: 从硬件层面证实了高延迟 I/O 的存在,与 fileslower 的发现吻合。
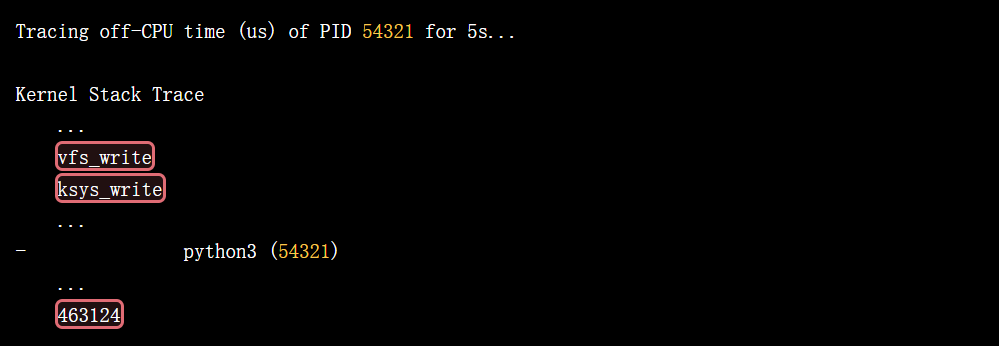
4.5 第五步:深入内核堆栈,探究阻塞根源 (offcputime)
offcputime 工具可以追踪进程的离 CPU (Off-CPU) 事件,并展示导致其睡眠/阻塞的内核调用栈。这能告诉我们程序为什么在等待。
- 运行工具:
/usr/share/bcc/tools/offcputime.py -p $(pgrep -f slow_ai_simulator.py) 5(对目标进程采样5秒)。 - 观察输出:
Tracing off-CPU time (us) of PID 54321 for 5s...
Kernel Stack Trace
...
vfs_write
ksys_write
...
- python3 (54321)
...
463124
结论: 内核堆栈清晰地显示,进程的绝大部分离 CPU 时间都消耗在了文件系统的写入调用 (vfs_write -> ksys_write) 上。
五、结论与优化方案
5.1 根因总结
通过 eBPF 工具链的层层分析,我们得出结论:AI 训练程序主线程被一个同步的、高延迟的磁盘文件写入操作(具体为内核中的 vfs_write 调用)所阻塞,导致了周期性的停滞。
5.2 优化方案
- I/O 异步化 (推荐): 将文件写入操作移至独立的后台线程或进程中执行。
- 应用层缓冲: 先将数据快速写入内存,再由后台任务异步刷写到磁盘。
- 硬件升级: 将磁盘升级为高性能的 NVMe SSD。
5.3 优化方案可视化

如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持“超节点”场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 31
31 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)