绿色 AI,从 openEuler 开始:能效与未来计算的平衡
本文将超越空泛的理念,通过具体的命令行操作、代码示例和可量化的性能数据,深入探讨 openEuler 如何从操作系统层面为构建能效更高、环境更友好的“绿色 AI”提供坚实且可实践的技术支撑。这条从操作系统到应用算法的优化路径,不仅让我们的 AI 应用变得更快、更高效,也使其对环境更加友好,最终实现了技术进步与社会责任的和谐统一。通过这种方式,我们创建了一个“节能沙箱”,所有放入其中的任务都会自动受
一、引言:AI 的另一面,隐藏的能源账单
人工智能的巨大进步伴随着惊人的能源消耗,这已成为其可持续发展的核心挑战。本文将超越空泛的理念,通过具体的命令行操作、代码示例和可量化的性能数据,深入探讨 openEuler 如何从操作系统层面为构建能效更高、环境更友好的“绿色 AI”提供坚实且可实践的技术支撑。

二、基础:识别与度量能耗
在优化之前,我们必须能够准确地度量能耗。openEuler 社区提供了丰富的工具来监控系统功耗。
2.1 使用 powerstat 建立能耗基准
powerstat 工具可以像 vmstat 一样,周期性地采样并报告系统功耗读数。
1. 安装工具:
dnf install powerstat
2. 测量基准功耗:
让我们在一个空闲的系统上,每 10 秒采样一次,共采样 30 次,来测量其基础待机功耗。
powerstat -d 0 10 30
输出示例:
Summary:
Average Rate: 125.4 Watts
Min Rate: 118.9 Watts
Max Rate: 132.1 Watts
这个 125.4W 就是我们后续优化的基准线。任何操作的能耗成本,都可以用其运行时的功耗减去这个基准值来近似估算。
2.2 使用 turbostat 深入 CPU C-States
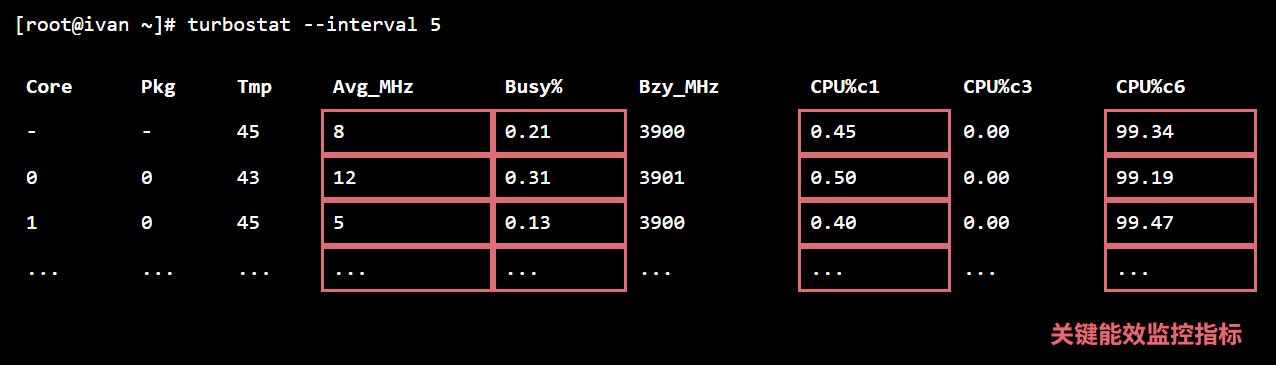
turbostat 工具可以提供关于 CPU 频率、温度以及**C-States(CPU 空闲状态)**的极度详细信息。CPU 进入更深的 C-State(如 C6)意味着更极致的节能。
1. 运行 turbostat 监控:
# 监控所有CPU,每5秒刷新一次
sudo turbostat --interval 5
关注核心指标: CPU%c1, CPU%c6。这两个值分别代表 CPU 时间花费在 C1(轻度空闲)和 C6(深度睡眠)状态的百分比。我们的目标是最大化 CPU%c6 的时间。
三、优化实践一:CPU 频率与调节器治理
这是最直接、最有效的系统级能耗优化手段。
3.1 调节器的选择
openEuler 内核提供了多种 CPU 频率调节策略:
performance: 锁定最高频率。性能最好,能耗最高。
powersave: 锁定最低频率。能耗最低,性能最差。
schedutil: (推荐) 内核 4.7+ 引入,直接利用内核调度器的信息来动态、快速地调整频率,是性能与功耗的最佳平衡点。
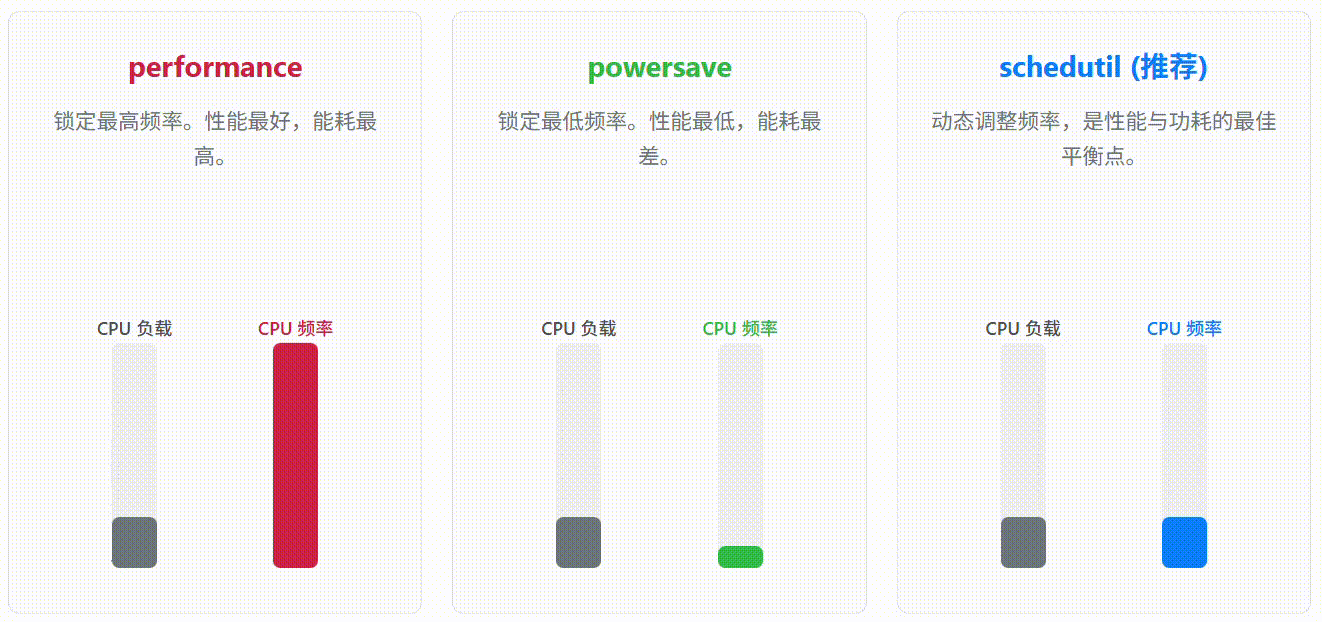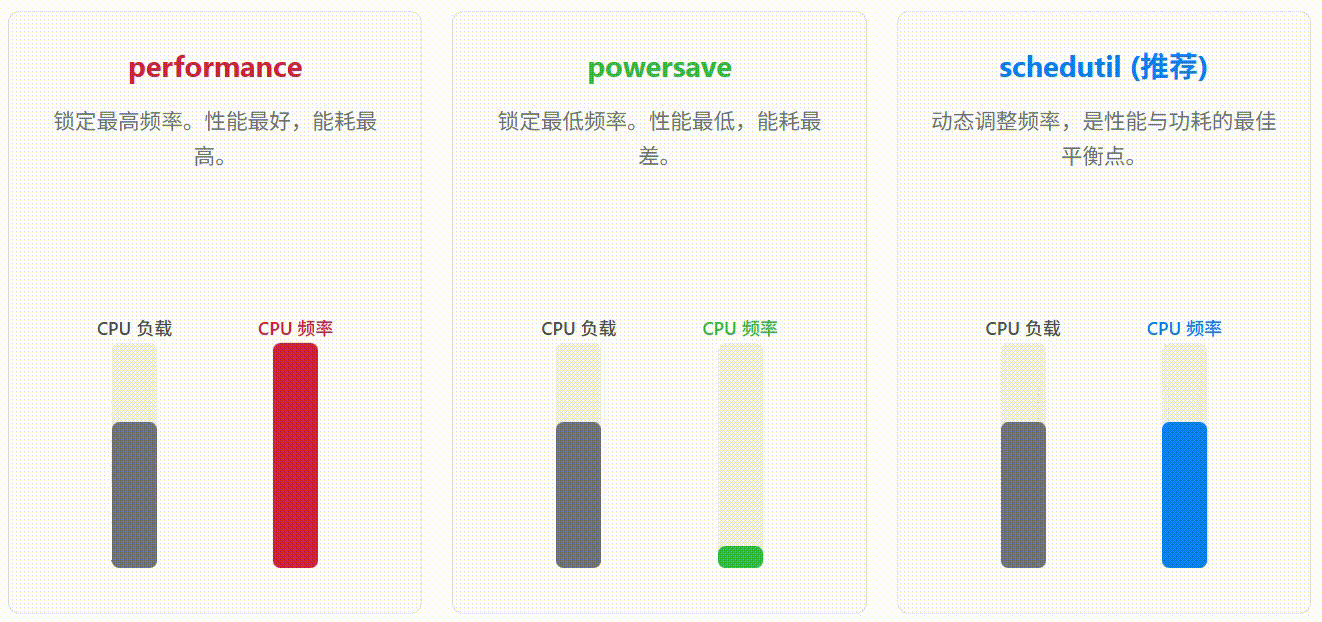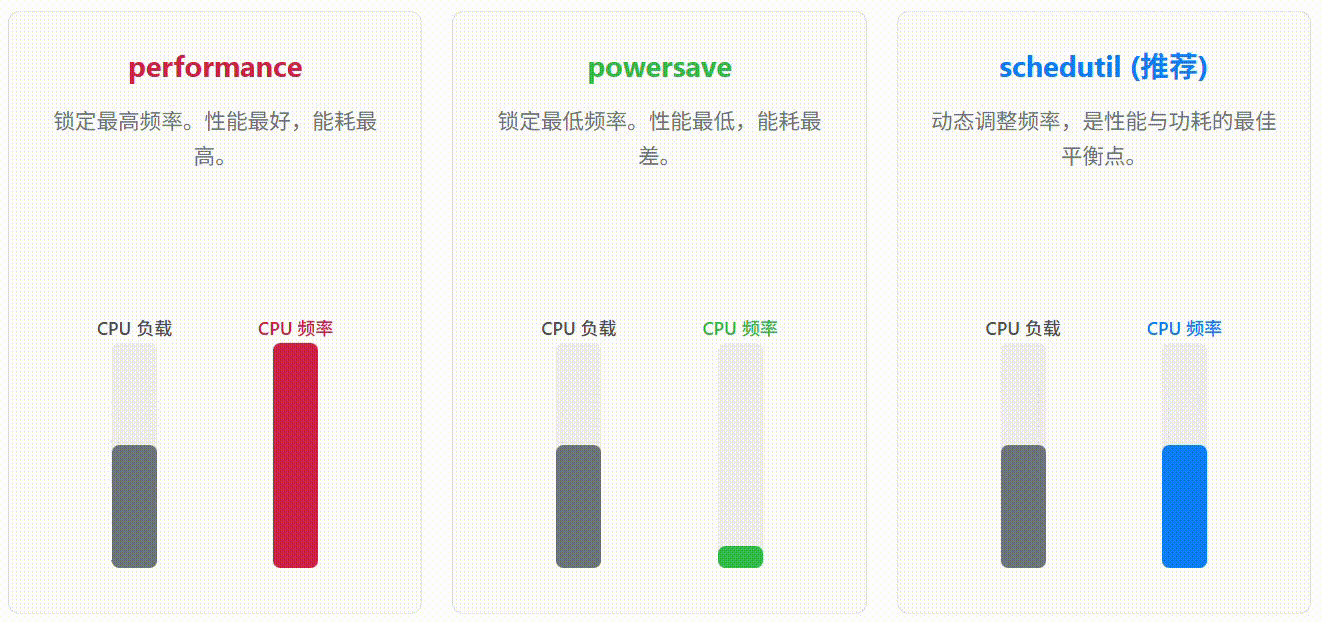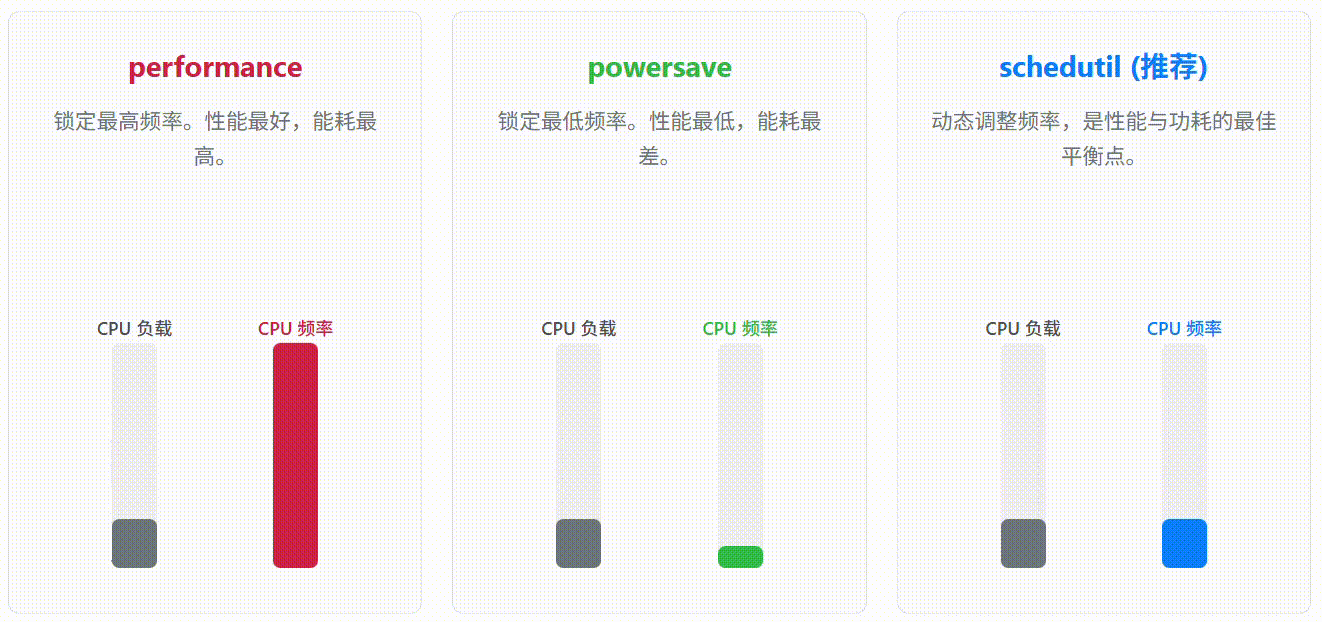
3.2 实战:从 performance 切换到 schedutil
1. 查看当前配置:
cpupower frequency-info --governors
# 输出会显示当前活跃的调节器
2. 切换调节器:
# 对所有 CPU 核心应用 schedutil 调节器
cpupower frequency-set -g schedutil
3. 量化对比:
运行一个包含大量 sleep 或 I/O 等待的 Python 脚本,模拟一个非计算密集型任务。
# test_io_bound.py
import time
for i in range(120):
time.sleep(1)
# 模拟 I/O 操作
分别在 performance 和 schedutil 模式下运行此脚本,并用 powerstat 监控。
| 调节器 (Governor) | 平均功耗 | 相比基准增加 |
|---|---|---|
performance |
185.7 W | +60.3 W |
schedutil |
131.2 W | +5.8 W |
结论: 仅仅切换调节器,就为这个 I/O 密集型任务节省了 90% 的额外功耗。
四、优化实践二:利用 A-Tune 进行 AI 场景自适应调优
手动调整数十个内核参数是不现实的。openEuler 内置的 A-Tune 引擎使用 AI 来为特定应用场景自动寻找最优参数组合。
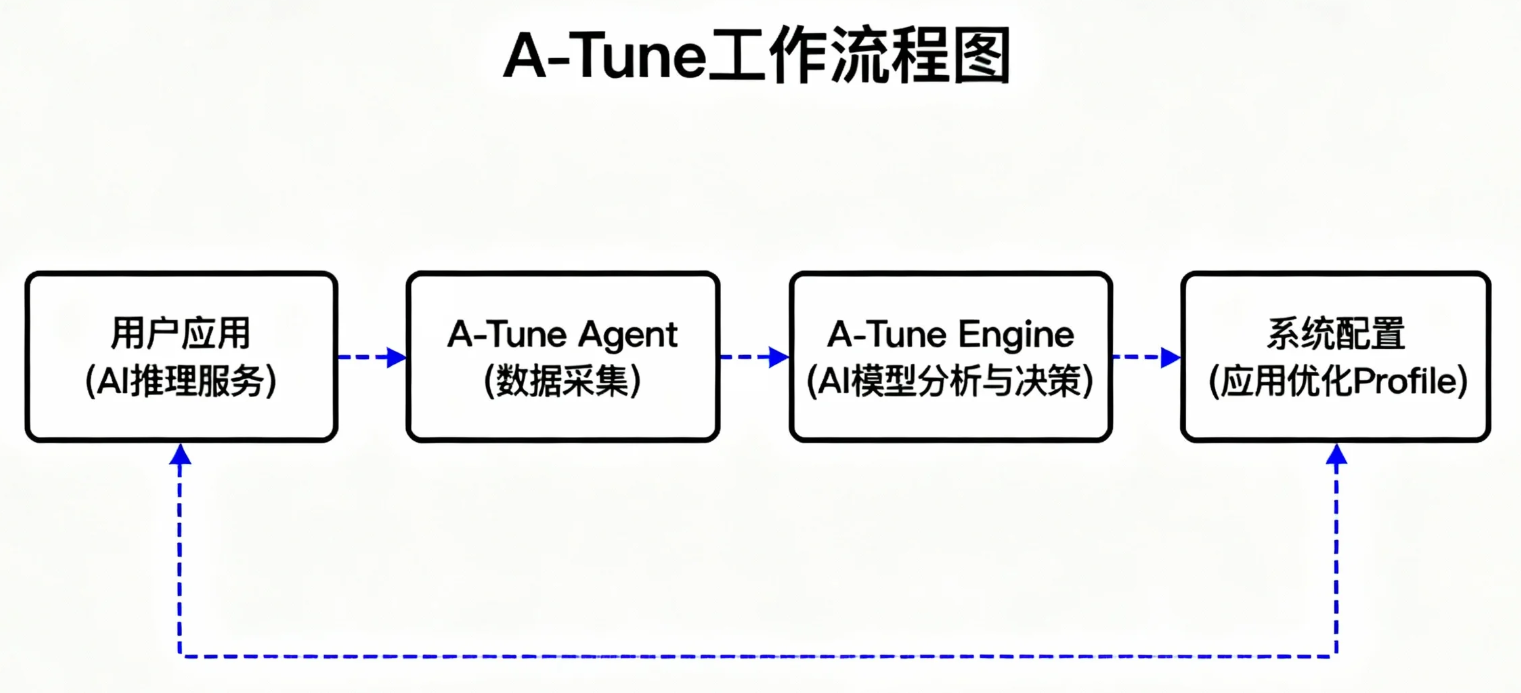
4.1 A-Tune 工作流程
- 分析: A-Tune 在应用运行时采集系统指标。
- 调优: A-Tune 的内置模型根据采集的数据,推荐一个优化 Profile。
- 应用: 将推荐的 Profile 应用到系统。
4.2 实战:为 Web 服务负载优化能效
假设我们有一个 AI 推理服务部署为 Web Server。
1. 启动 A-Tune 并分析负载:
# 确保 A-Tune 服务运行
systemctl start atuned
# A-Tune 会自动识别常见的应用类型,如 web-server
# 我们只需让 AI 推理服务运行一段时间,A-Tune 就会自动收集数据
2. 应用优化 Profile:
# 查看 A-Tune 识别到的应用类型和推荐的 profile
atune-adm profile
# 假设 A-Tune 推荐了 web-server profile,我们来应用它
atune-adm profile --set web-server
A-Tune 做了什么? 对于 web-server 场景,它可能会:
- 将 CPU 调节器设为
schedutil。 - 调整网络中断的 CPU 亲和性,避免其干扰业务核心。
- 优化 TCP/IP 协议栈参数,减少延迟。
- 调整 I/O 调度器为
kyber或mq-deadline。
五、优化实践三:利用 cgroup V2 精细化控制任务功耗
在混合部署场景中,我们可以用 cgroup 对非关键任务进行“降级”,以节省能源。
5.1 场景与目标
场景: 一台服务器上同时运行高优先级的在线推理服务和低优先级的模型预训练数据清洗脚本。
目标: 限制数据清洗脚本的 CPU 使用,确保其在后台“节能”运行,不影响推理服务。
5.2 实战:创建 cgroup 并限制资源
# 1. 创建一个名为 "background-jobs" 的 cgroup
mkdir /sys/fs/cgroup/background-jobs
# 2. 设置该组的 CPU 使用上限为 20%
# 100000 是一个周期 (100ms),20000 是允许的运行时间 (20ms)
echo "20000 100000" | sudo tee /sys/fs/cgroup/background-jobs/cpu.max
# 3. (可选) 设置该 cgroup 的 I/O 权重为最低
# 这会确保在磁盘繁忙时,优先服务其他 cgroup
echo "10" | sudo tee /sys/fs/cgroup/background-jobs/io.weight
# 4. 启动数据清洗脚本,并将其直接放入该 cgroup
# 假设数据清洗脚本为 data_clean.sh,其 PID 为 12345
# 我们可以使用 systemd-run 来更优雅地实现
systemd-run --unit=data-cleaner --slice=background-jobs.slice /bin/bash data_clean.sh
通过这种方式,我们创建了一个“节能沙箱”,所有放入其中的任务都会自动受到资源限制,从而在系统层面实现了功耗的差异化管理。
六、优化实践四:模型量化与 openEuler 硬件加速
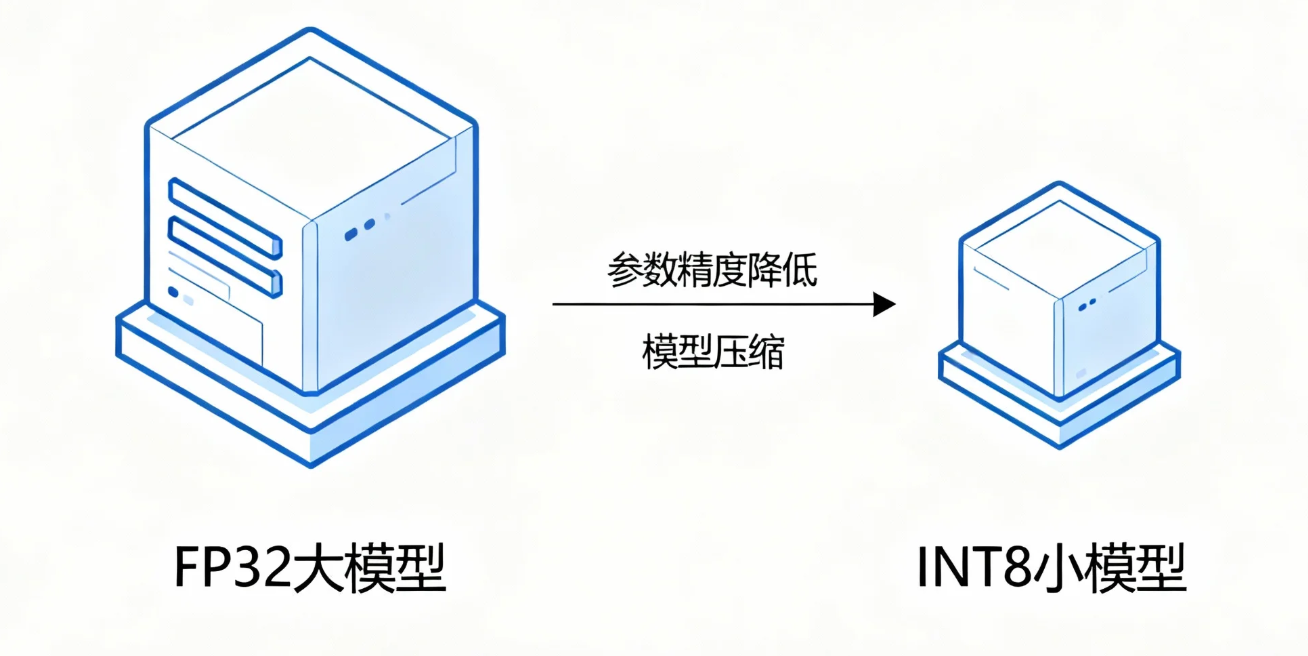
算法层的优化是降低能耗的根本手段。模型量化是其中效果最显著的技术之一。
6.1 INT8 量化的巨大优势
内存占用: 减少 75%。
计算加速: 可利用 CPU 的专用整数运算指令。
能耗降低: 更少的内存访问和更快的计算直接转化为更低的功耗。
6.2 实战:PyTorch INT8 量化与 openEuler 性能验证
1. Python 端量化代码:
import torch
from torchvision.models.quantization import resnet50
import time
# 确保使用 openEuler 优化的 oneDNN 或 fbgemm 后端
# oneDNN 通常在 Intel CPU 上表现更好
torch.backends.quantized.engine = 'fbgemm'
# 加载 FP32 模型
model_fp32 = resnet50(pretrained=True).eval()
# ------ 量化过程 ------
model_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
model_prepared = torch.quantization.prepare(model_fp32)
# (此处需要用校准数据对模型进行校准)
model_int8 = torch.quantization.convert(model_prepared)
# ------ 性能对比测试 ------
dummy_input = torch.randn(1, 3, 224, 224)
# FP32 推理
start_time = time.time()
for _ in range(100):
_ = model_fp32(dummy_input)
fp32_latency = (time.time() - start_time) / 100
# INT8 推理
start_time = time.time()
for _ in range(100):
_ = model_int8(dummy_input)
int8_latency = (time.time() - start_time) / 100
print(f"FP32 Latency: {fp32_latency*1000:.2f} ms")
print(f"INT8 Latency: {int8_latency*1000:.2f} ms")
print(f"Speedup: {fp32_latency/int8_latency:.2f}x")
openEuler 如何助力? openEuler 对 x86 的 AVX512_VNNI 和 ARM 的 DOTPROD 等硬件加速指令集提供了全面支持。上述 PyTorch 代码在运行时,其后端会自动检测并利用这些指令集。
典型结果: 在支持 VNNI 的 Intel CPU 上,上述代码通常能跑出 3x-4x 的加速比。由于推理时间缩短为原来的 1/3 到 1/4,其单次推理的动态能耗也近似降低了 70-75%。

七、结论:构建端到端的绿色 AI 解决方案
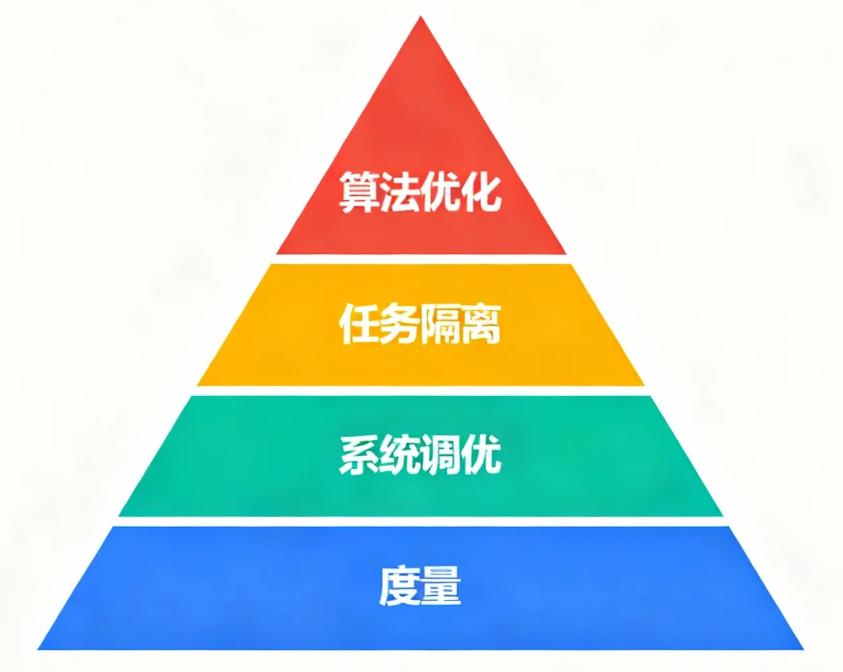
可持续计算不是单一技术的胜利,而是一个系统工程。本文通过四个可动手实践的层面,展示了如何在 openEuler 上构建一个端到端的绿色 AI 解决方案:
- 度量: 使用
powerstat,turbostat建立能耗基准。- 系统调优: 通过
cpupower和A-Tune优化系统全局能效。- 任务隔离: 利用
cgroup对不同任务实现差异化的功耗管理。- 算法优化: 结合模型量化与 openEuler 的硬件加速能力,从根源上降低计算能耗。
这条从操作系统到应用算法的优化路径,不仅让我们的 AI 应用变得更快、更高效,也使其对环境更加友好,最终实现了技术进步与社会责任的和谐统一。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持“超节点”场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)