论文解析《Training LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking》
论文解读
文章的主要贡献
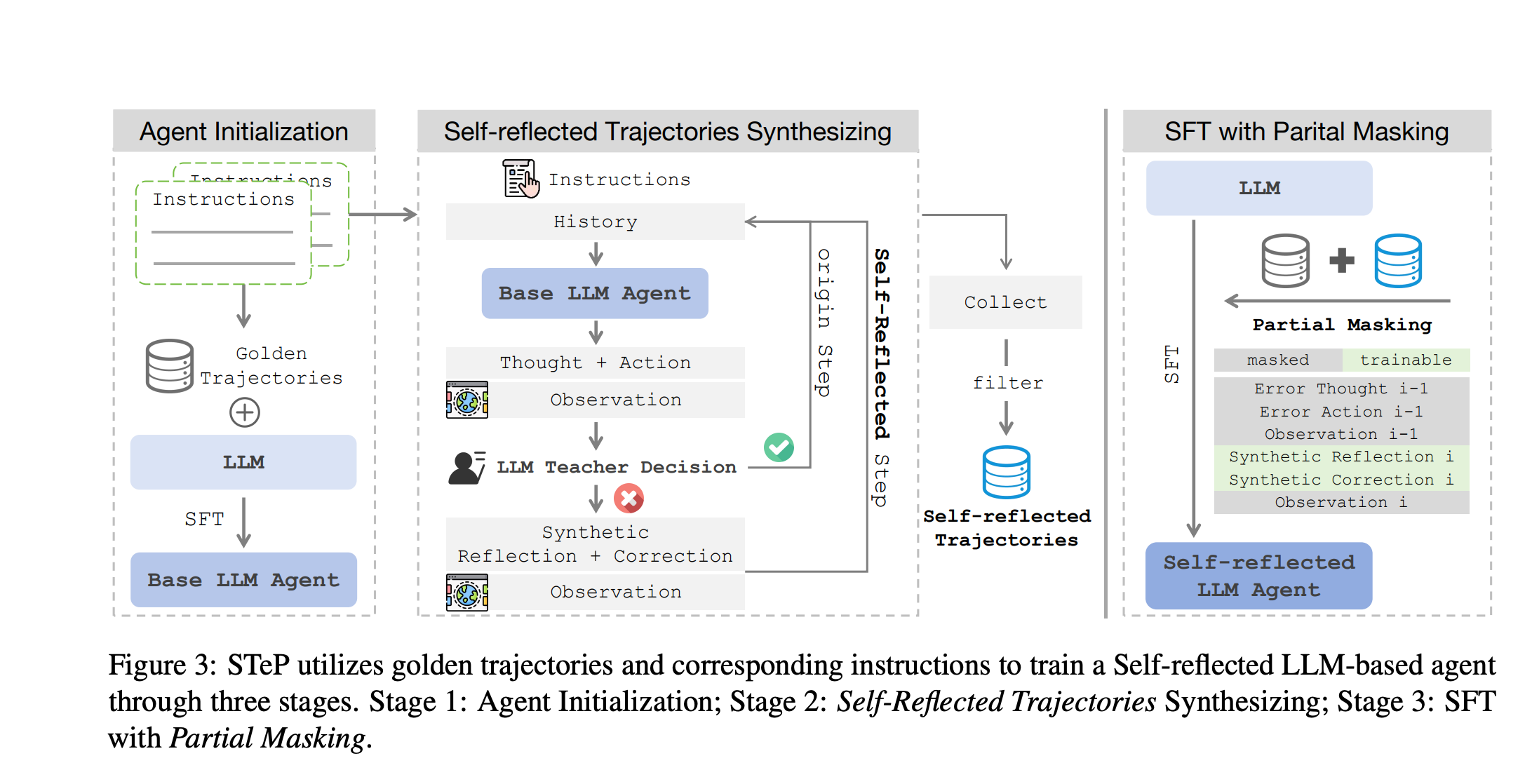
这篇论文(arXiv:2505.20023v1)提出了一种名为 STeP(Self-Reflected Trajectories and Partial Masking)的创新方法,用于提升基于大型语言模型(LLM)的代理(agent)训练效果。论文的主要贡献总结如下(摘自引言部分的明确表述):
-
提出 STeP 方法:利用自反思轨迹(Self-Reflected Trajectories)来改进代理训练,使 LLM 能够更有效地从教师模型中学习。这些轨迹包含对错误步骤的反思和修正,帮助代理避免错误传播并提升泛化能力。
-
引入部分掩码策略(Partial Masking):一种新型掩码机制,用于防止 LLM 在多轮轨迹训练中内化不正确或次优的思考和行动步骤,从而减少灾难性遗忘和错误学习。
-
实验验证与分析:在三个代表性代理任务(ALFWorld、WebShop 和 SciWorld)上进行实验,证明该方法显著提升了开源模型(如 LLaMA2-7B-Chat)的性能,使用更少的训练数据即可实现综合改进(例如,在 ALFWorld 上提升 10.3%)。同时,强调了在代理任务中反思和修正错误的重要性。
这些贡献解决了传统监督微调(SFT)中的性能平台期和错误传播问题,推动了开源 LLM 代理向自反思能力的发展。实验结果显示,STeP 在不依赖闭源模型(如 GPT-4)的情况下,实现了高效训练。

STeP 方法的详细步骤
STeP(Self-Reflected Trajectories and Partial Masking)是一种用于训练基于大型语言模型(LLM)的代理(agent)的创新方法,旨在通过合成自反思轨迹和部分掩码策略来提升代理的自反思和纠错能力。该方法分为三个主要阶段:Agent Initialization(代理初始化)、Synthesizing Self-Reflected Trajectories(合成自反思轨迹)和 SFT with Partial Masking(带部分掩码的监督微调)。以下是每个阶段的详细步骤描述,基于论文的第3节(Method)。
阶段1: Agent Initialization(代理初始化)
此阶段旨在通过监督微调(SFT)一个基础LLM代理πθ\pi_{\theta}πθ,使其具备基本的代理任务知识和指令跟随能力。这为后续阶段提供一个可靠的起点,避免小LLM在复杂任务中完全失效。
-
准备黄金轨迹数据集:
- 给定一组成功的专家轨迹集合DDD(golden trajectories),这些轨迹是从教师模型(如GPT-4)生成的成功交互序列,每个轨迹对应任务空间UUU中的指令u∈Uu \in Uu∈U。
- 每个黄金轨迹τ\tauτ组织为ReAct格式:τ=(u,t1,a1,o1,…,tn,an,on)\tau = (u, t_1, a_1, o_1, \dots, t_n, a_n, o_n)τ=(u,t1,a1,o1,…,tn,an,on),其中tit_iti是推理思想(thought),aia_iai是动作(action),oio_ioi是环境观察(observation),nnn是轨迹长度。
- 随机将DDD分为两部分:D1D_1D1(对应任务子集U1U_1U1,用于初始化)和D2D_2D2(对应U2U_2U2,用于后续合成)。
-
监督微调基础代理:
- 使用D1D_1D1对基础LLM πbase\pi_{\text{base}}πbase进行SFT,目标是最小化以下损失函数:
LSFT(θ)=−E(e,u,τ)∼D1[logπθ(τ∣e,u)] L_{\text{SFT}}(\theta) = - \mathbb{E}_{(e,u,\tau) \sim D_1} \left[ \log \pi_{\theta}(\tau | e, u) \right] LSFT(θ)=−E(e,u,τ)∼D1[logπθ(τ∣e,u)]
=−E(e,u,τ)∼D1[∑i=1nlogπθ(ti,ai∣e,u,τi−1)] = - \mathbb{E}_{(e,u,\tau) \sim D_1} \left[ \sum_{i=1}^n \log \pi_{\theta}(t_i, a_i | e, u, \tau_{i-1}) \right] =−E(e,u,τ)∼D1[i=1∑nlogπθ(ti,ai∣e,u,τi−1)]
其中τi−1=(t1,a1,o1,…,ti−1,ai−1,oi−1)\tau_{i-1} = (t_1, a_1, o_1, \dots, t_{i-1}, a_{i-1}, o_{i-1})τi−1=(t1,a1,o1,…,ti−1,ai−1,oi−1),eee是环境。 - 优化后得到基础代理πθ\pi_{\theta}πθ,其参数θ\thetaθ捕捉了基本的推理、规划和执行能力。
- 使用D1D_1D1对基础LLM πbase\pi_{\text{base}}πbase进行SFT,目标是最小化以下损失函数:
此阶段确保基础代理能生成格式正确的轨迹,作为后续反思的平台。
阶段2: Synthesizing Self-Reflected Trajectories(合成自反思轨迹)
此阶段使用基础代理πθ\pi_{\theta}πθ与环境交互,引入更强的教师模型πteacher\pi_{\text{teacher}}πteacher(如Qwen1.5-110B-Chat)实时评估和修正错误,生成包含反思和纠错的自反思轨迹集合DrD_rDr。这有助于代理学习避免错误传播。
-
基础代理交互生成轨迹:
- 对于剩余任务U2U_2U2中的每个指令u∈U2u \in U_2u∈U2,让基础代理πθ\pi_{\theta}πθ与环境eee交互生成轨迹。
- 代理根据指令uuu和历史生成思想tit_iti和动作aia_iai:ai=πθ(u,a1,o1,…,ai−1,oi−1)a_i = \pi_{\theta}(u, a_1, o_1, \dots, a_{i-1}, o_{i-1})ai=πθ(u,a1,o1,…,ai−1,oi−1),环境返回观察oio_ioi。
- 过程持续直到任务完成(奖励r=1r=1r=1)或达到最大步数。
-
教师模型实时评估与修正:
- 为教师模型设计复杂提示,包括任务定义、当前指令uuu、交互历史(t1,a1,o1,…,ti−1,ai−1,oi−1)(t_1, a_1, o_1, \dots, t_{i-1}, a_{i-1}, o_{i-1})(t1,a1,o1,…,ti−1,ai−1,oi−1)、当前步(ti,ai)(t_i, a_i)(ti,ai)和观察oio_ioi。
- 教师πteacher\pi_{\text{teacher}}πteacher判断aia_iai是否正确:
- 如果正确,继续无操作。
- 如果错误(步jjj),标记为(t^j,a^j)(\hat{t}_j, \hat{a}_j)(t^j,a^j)(错误思想和动作)。
- 教师生成第一人称反思:基于任务要求、历史和ojo_joj,输出错误原因、反思内容和正确动作。将输出转换为ReAct格式(tj+1′,aj+1′)(t'_{j+1}, a'_{j+1})(tj+1′,aj+1′),其中tj+1′t'_{j+1}tj+1′包含错误描述和反思,aj+1′a'_{j+1}aj+1′是修正动作。
- 环境基于aj+1′a'_{j+1}aj+1′返回新观察oj+1o_{j+1}oj+1。
- 重复直到任务结束,得到可能包含错误标记的轨迹。
-
过滤与合成自反思轨迹:
- 过滤出成功完成任务(r=1r=1r=1)且包含教师反思的轨迹,形成DrD_rDr。
- 自反思轨迹τ′\tau'τ′示例:(u,t1,a1,o1,…,t^j,a^j,oj,tj+1′,aj+1′,oj+1,… )(u, t_1, a_1, o_1, \dots, \hat{t}_j, \hat{a}_j, o_j, t'_{j+1}, a'_{j+1}, o_{j+1}, \dots)(u,t1,a1,o1,…,t^j,a^j,oj,tj+1′,aj+1′,oj+1,…)。
- 排除高错误步数的轨迹以确保质量,最终得到约708条轨迹(实验中)。
此阶段增强了数据集的反思性,帮助代理学习纠错。
阶段3: SFT with Partial Masking(带部分掩码的监督微调)
此阶段结合D1D_1D1和DrD_rDr重新训练基础LLM,但引入部分掩码(Partial Masking, PM)防止学习错误步骤,避免灾难性遗忘。
-
数据集合并:
- 将DrD_rDr与D1D_1D1合并为训练集D1+DrD_1 + D_rD1+Dr。
- 不从基础代理πθ\pi_{\theta}πθ继续训练,而是从原始基础LLM πbase\pi_{\text{base}}πbase重新开始,以保留通用能力。
-
部分掩码训练:
- 在SFT中,错误步(t^i,a^i)(\hat{t}_i, \hat{a}_i)(t^i,a^i)被掩码,不计算其损失。
- 引入指示变量δi\delta_iδi:δi=0\delta_i = 0δi=0表示错误步,δi=1\delta_i = 1δi=1表示正确步。
- 最小化以下损失函数:
LPM(θ)=−E(e,u,τ)∼D1+Dr[logπθ(τ∣e,u)] L_{\text{PM}}(\theta) = - \mathbb{E}_{(e,u,\tau) \sim D_1 + D_r} \left[ \log \pi_{\theta}(\tau | e, u) \right] LPM(θ)=−E(e,u,τ)∼D1+Dr[logπθ(τ∣e,u)]
=−E(e,u,τ)∼D1[∑i=1nlogπθ(ti,ai∣e,u,τi−1)] = - \mathbb{E}_{(e,u,\tau) \sim D_1} \left[ \sum_{i=1}^n \log \pi_{\theta}(t_i, a_i | e, u, \tau_{i-1}) \right] =−E(e,u,τ)∼D1[i=1∑nlogπθ(ti,ai∣e,u,τi−1)]
−E(e,u,τ)∼Dr[∑i=1nδilogπθ(ti,ai∣e,u,τi−1)]- \mathbb{E}_{(e,u,\tau) \sim D_r} \left[ \sum_{i=1}^n \delta_i \log \pi_{\theta}(t_i, a_i | e, u, \tau_{i-1}) \right] −E(e,u,τ)∼Dr[i=1∑nδilogπθ(ti,ai∣e,u,τi−1)] - 优化后得到自反思代理,能自主识别、反思和修正错误。
整体流程总结
- 输入:黄金轨迹DDD、基础LLM πbase\pi_{\text{base}}πbase、教师πteacher\pi_{\text{teacher}}πteacher、环境eee。
- 输出:训练好的自反思LLM代理。
- 关键创新:自反思轨迹防止错误循环,部分掩码提升训练效率。实验显示,使用Qwen1.5-110B-Chat作为教师,在ALFWorld等任务上提升9.2%平均奖励,且数据量减少33%。
此方法强调实时评估而非启发式触发,使其更灵活且上下文高效。
STeP 方法的整体代码结构
基于论文《Training LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking》(arXiv:2505.20023v1)的描述,我设计了一个整体的Python代码结构。该结构采用模块化设计,便于实现三个阶段:Agent Initialization(代理初始化)、Synthesizing Self-Reflected Trajectories(合成自反思轨迹)和 SFT with Partial Masking(带部分掩码的监督微调)。
代码假设使用Hugging Face Transformers库进行模型加载和微调,vLLM用于高效推理(论文中提到),以及ReAct格式的轨迹处理。环境交互(如ALFWorld、WebShop、SciWorld)需集成相应库(例如,ALFWorld的官方实现)。数据集DDD(黄金轨迹)需预处理为JSONL格式,每条轨迹包含instruction、trajectory(列表 of {"thought": str, "action": str, "observation": str})和reward。
总体目录结构
step/
├── main.py # 入口脚本:运行三个阶段
├── config.py # 配置:模型路径、数据集路径、超参数
├── data/
│ ├── __init__.py
│ ├── dataset.py # 数据加载、分割(D1, D2)、过滤(reward=1)
│ └── react_format.py # ReAct轨迹解析/序列化
├── models/
│ ├── __init__.py
│ ├── base_llm.py # 基础LLM加载(LLaMA2-7B-Chat)
│ ├── teacher_llm.py # 教师LLM(Qwen1.5-110B-Chat)
│ └── sft_trainer.py # SFT训练器(支持Partial Masking)
├── agents/
│ ├── __init__.py
│ ├── base_agent.py # 基础代理:与环境交互生成轨迹
│ └── self_reflected_agent.py # 自反思代理(最终模型)
├── trajectories/
│ ├── __init__.py
│ ├── synthesizer.py # 阶段2:合成自反思轨迹(实时教师评估)
│ └── masker.py # 部分掩码:错误步损失计算
├── environments/
│ ├── __init__.py
│ ├── alfworld_env.py # ALFWorld环境适配器
│ ├── webshop_env.py # WebShop环境适配器
│ └── sciworld_env.py # SciWorld环境适配器
├── utils/
│ ├── __init__.py
│ ├── logger.py # 日志记录
│ └── evaluator.py # 评估:平均奖励计算
└── requirements.txt # 依赖:transformers, vllm, torch, datasets 等
核心模块详细结构
-
config.py(配置管理)
from dataclasses import dataclass from typing import Dict, Any @dataclass class Config: # 模型配置 base_model_path: str = "meta-llama/Llama-2-7b-chat-hf" teacher_model_path: str = "Qwen/Qwen1.5-110B-Chat" # 数据配置 data_path: str = "data/golden_trajectories.jsonl" d1_ratio: float = 0.5 # D1占D的比例 max_steps: int = 50 # 最大轨迹步数 # 训练配置 batch_size: int = 4 learning_rate: float = 1e-5 epochs: int = 3 # 任务配置 tasks: list = ["ALFWorld", "WebShop", "SciWorld"] # vLLM配置(推理) vllm_temp: float = 0.0 # 确定性 -
data/dataset.py(数据处理)
import json from sklearn.model_selection import train_test_split from typing import List, Dict, Any def load_golden_trajectories(data_path: str) -> List[Dict[str, Any]]: """加载黄金轨迹数据集D,过滤reward=1""" trajectories = [] with open(data_path, 'r') as f: for line in f: traj = json.loads(line) if traj['reward'] == 1: trajectories.append(traj) return trajectories def split_dataset(trajectories: List[Dict], ratio: float = 0.5) -> tuple: """随机分割D为D1 (U1) 和 D2 (U2)""" d1, d2 = train_test_split(trajectories, test_size=1 - ratio, random_state=42) return d1, d2 # 返回列表 of trajectories -
models/base_llm.py(LLM加载)
from transformers import AutoTokenizer, AutoModelForCausalLM from vllm import LLM # 用于高效推理 class BaseLLM: def __init__(self, model_path: str, config: Config): self.tokenizer = AutoTokenizer.from_pretrained(model_path) self.model = AutoModelForCausalLM.from_pretrained(model_path) # SFT用 self.vllm_engine = LLM(model=model_path, temperature=config.vllm_temp) # 推理用 def generate(self, prompt: str, max_tokens: int = 512) -> str: """生成响应(ReAct格式)""" # 使用vLLM生成thought + action outputs = self.vllm_engine.generate([prompt], max_tokens=max_tokens) return outputs[0].outputs[0].text -
agents/base_agent.py(基础代理交互)
from typing import List, Dict, Any import react_format # 自定义ReAct解析 class BaseAgent: def __init__(self, llm: BaseLLM, env_class: Any, config: Config): self.llm = llm self.env = env_class() # e.g., ALFWorldEnv() self.max_steps = config.max_steps def interact(self, instruction: str) -> Dict[str, Any]: """生成轨迹τ = (u, t1,a1,o1, ..., tn,an,on)""" trajectory = {"instruction": instruction, "steps": [], "reward": 0} obs = self.env.reset(instruction) history = "" for step in range(self.max_steps): prompt = self._build_react_prompt(history, instruction, obs) response = self.llm.generate(prompt) thought, action = react_format.parse_react(response) # 解析t_i, a_i next_obs, reward = self.env.step(action) trajectory["steps"].append({"thought": thought, "action": action, "observation": obs}) history += f"Thought: {thought} Action: {action} Observation: {obs}\n" obs = next_obs if reward == 1: # 任务完成 trajectory["reward"] = 1 break return trajectory def _build_react_prompt(self, history: str, instruction: str, obs: str) -> str: """构建ReAct提示""" return f"Instruction: {instruction}\n{history}\nObservation: {obs}\nThought: " -
trajectories/synthesizer.py(阶段2:合成自反思轨迹)
from typing import List, Dict, Any from models.teacher_llm import TeacherLLM class TrajectorySynthesizer: def __init__(self, base_agent: BaseAgent, teacher: TeacherLLM, config: Config): self.base_agent = base_agent self.teacher = teacher self.config = config def synthesize(self, d2: List[Dict]) -> List[Dict]: """为D2生成自反思轨迹Dr""" dr = [] for traj_dict in d2: instruction = traj_dict["instruction"] base_traj = self.base_agent.interact(instruction) if base_traj["reward"] != 1: continue # 过滤失败轨迹 reflected_traj = self._add_reflections(base_traj) if len(reflected_traj["error_steps"]) > self.config.max_errors: # 排除高错误轨迹 continue dr.append(reflected_traj) return dr def _add_reflections(self, traj: Dict) -> Dict: """实时教师评估,添加反思/修正""" reflected_steps = traj["steps"].copy() error_steps = [] for i, step in enumerate(reflected_steps): prompt = self.teacher.build_evaluation_prompt(traj["instruction"], reflected_steps[:i+1]) verdict = self.teacher.generate(prompt) # 判断正确/错误 if not self.teacher.is_correct(verdict): error_step = {"thought": step["thought"], "action": step["action"], "is_error": True} error_steps.append(error_step) # 生成反思 + 修正 reflection_prompt = self.teacher.build_reflection_prompt(prompt, verdict) reflection_response = self.teacher.generate(reflection_prompt) refl_thought, corr_action = react_format.parse_react(reflection_response) # 更新轨迹:插入 (t'_j+1, a'_j+1, o_j+1) next_obs, _ = self.base_agent.env.step(corr_action) # 模拟环境 reflected_steps.insert(i+1, {"thought": refl_thought, "action": corr_action, "observation": next_obs, "is_reflection": True}) else: reflected_steps[i]["is_error"] = False traj["steps"] = reflected_steps traj["error_steps"] = error_steps return traj -
models/teacher_llm.py(教师模型)
class TeacherLLM(BaseLLM): def build_evaluation_prompt(self, instruction: str, history: List[Dict]) -> str: """复杂提示:任务定义 + 历史 + 当前步""" hist_str = "\n".join([f"Thought: {s['thought']} Action: {s['action']} Obs: {s['observation']}" for s in history]) return f"""Task: {instruction} History: {hist_str} Evaluate if the last action is correct. If error, output 'ERROR: reason'. Else 'CORRECT'.""" def is_correct(self, verdict: str) -> bool: return "CORRECT" in verdict def build_reflection_prompt(self, eval_prompt: str, verdict: str) -> str: """第一人称反思提示""" return f"{eval_prompt}\nYou made a mistake: {verdict}. Reflect in first-person: 'I have made a mistake! Reason: ... Reflection: ...' Then correct action in ReAct." # generate 方法继承自BaseLLM -
trajectories/masker.py(部分掩码)
from torch.nn import CrossEntropyLoss def partial_masking_loss(model, batch: Dict, delta: List[int]) -> float: # delta_i = 0 for error """计算L_PM(θ):掩码错误步损失""" loss_fn = CrossEntropyLoss(ignore_index=-100) # 掩码token total_loss = 0.0 for i, step in enumerate(batch["steps"]): if delta[i] == 0: # 错误步:掩码 labels = torch.full_like(step["input_ids"], -100) else: labels = step["labels"] step_loss = loss_fn(model(**step["inputs"]).logits.view(-1, model.config.vocab_size), labels.view(-1)) total_loss += step_loss return total_loss / len(batch["steps"]) -
models/sft_trainer.py(SFT训练器)
from transformers import Trainer, TrainingArguments from torch.utils.data import Dataset class SFTTrainer(Trainer): def __init__(self, model, train_dataset: Dataset, masker, config: Config): args = TrainingArguments( output_dir="checkpoints", num_train_epochs=config.epochs, per_device_train_batch_size=config.batch_size, learning_rate=config.learning_rate, # ... ) super().__init__(model=model, args=args, train_dataset=train_dataset) self.masker = masker def compute_loss(self, model, inputs, return_outputs=False): # 集成Partial Masking delta = inputs.pop("delta") # 从batch中提取 loss = self.masker(model, inputs, delta) return (loss, outputs) if return_outputs else loss def train_stage1(d1: List[Dict], llm: BaseLLM, config: Config) -> BaseLLM: """阶段1:SFT on D1""" dataset = ReactDataset(d1) # 自定义Dataset:tokenize轨迹 trainer = SFTTrainer(llm.model, dataset, None, config) # 无掩码 trainer.train() return llm # 更新后基础代理 def train_stage3(d1: List[Dict], dr: List[Dict], llm: BaseLLM, config: Config) -> BaseLLM: """阶段3:SFT on D1 + Dr with PM""" full_data = d1 + dr dataset = ReactDataset(full_data) # 包含delta masker = PartialMasker() # 实例化掩码器 trainer = SFTTrainer(llm.model, dataset, masker, config) trainer.train() return llm # 自反思代理 -
main.py(入口)
from config import Config from data.dataset import load_golden_trajectories, split_dataset from models.base_llm import BaseLLM from models.teacher_llm import TeacherLLM from agents.base_agent import BaseAgent from trajectories.synthesizer import TrajectorySynthesizer from models.sft_trainer import train_stage1, train_stage3 from utils.evaluator import evaluate_agent def main(): config = Config() # 加载数据 d = load_golden_trajectories(config.data_path) d1, d2 = split_dataset(d, config.d1_ratio) # 阶段1: 初始化 base_llm = BaseLLM(config.base_model_path, config) base_agent = BaseAgent(base_llm, get_env(config.tasks[0]), config) # 示例环境 base_llm = train_stage1(d1, base_llm, config) # 阶段2: 合成Dr teacher = TeacherLLM(config.teacher_model_path, config) synthesizer = TrajectorySynthesizer(base_agent, teacher, config) dr = synthesizer.synthesize(d2) # 阶段3: 最终训练 final_llm = train_stage3(d1, dr, base_llm, config) # 从base重新训 # 评估 final_agent = BaseAgent(final_llm, get_env(config.tasks[0]), config) # 更新代理 reward = evaluate_agent(final_agent, test_set) # 平均奖励 print(f"Average Reward: {reward}") if __name__ == "__main__": main()
实现注意事项
- 依赖安装:
pip install transformers vllm torch datasets scikit-learn - 环境集成:需下载ALFWorld等环境代码,并实现
get_env(task)适配器。 - 自定义组件:
ReactDataset需实现__getitem__以tokenize多轮对话;PartialMasker封装损失。 - 扩展:支持多任务循环;添加日志和早停。
- 计算资源:教师模型需高GPU(110B参数);使用LoRA/QLORA优化微调。
此结构忠实于论文方法,便于迭代。如果需要具体模块的完整代码或调试,请提供更多细节!
ALFWorld 环境合成详细实现
基于论文《Training LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking》(arXiv:2505.20023v1)的STeP方法,以及之前提供的整体代码结构,本节详细实现ALFWorld环境的集成和轨迹合成。ALFWorld是一个文本-based的模拟家务代理环境(Shridhar et al., 2021),基于TextWorld框架,涉及日常任务如“清洁厨房”或“烹饪简单菜肴”。它包括训练集(~ 3119条指令)、seen测试集(~ 140条)和unseen测试集(~134条),如论文表1所述。
关键设计原则
- 环境适配:ALFWorld使用TextWorld生成动态游戏世界。代理通过ReAct格式(Thought + Action)与环境交互,动作如
go to kitchen、open fridge、pick apple等。观察(Observation)是文本描述,奖励(Reward)为0/1(任务完成/失败)。 - 合成轨迹:在阶段2(Synthesizing Self-Reflected Trajectories)中,使用基础代理生成轨迹,教师模型实时评估动作正确性。如果错误,插入反思(Reflection)和修正(Correction),如图2所示。
- 集成点:在
environs/alfworld_env.py中实现环境类,支持reset(instruction)和step(action)。在agents/base_agent.py和trajectories/synthesizer.py中调用。 - 依赖:假设TextWorld和ALFWorld已预安装(GitHub: microsoft/ALFWorld)。在实际环境中,使用
pip install textworld alfworld(但工具环境限制下,此代码为独立模块,可在本地运行)。轨迹过滤:仅保留reward=1。 - ReAct格式:提示模板强化推理,如"Thought: I need to… Action: go to…"。
1. 环境适配器:environs/alfworld_env.py
此模块封装ALFWorld环境,支持多任务(cleaning, cooking等)。它加载预生成的世界文件,并处理指令到游戏的映射。
# environs/alfworld_env.py
import os
import json
from typing import Tuple, Any, Optional
import textworld
from textworld import EnvInfos
from alfworld.agents import Agent as AlfAgent # ALFWorld代理基类(可选,用于验证)
from alfworld.envs import load_alfworld, get_tasks
class ALFWorldEnv:
def __init__(self, task_type: str = "cleaning", max_steps: int = 100, data_dir: str = "data/alfworld"):
"""
初始化ALFWorld环境。
- task_type: 'cleaning', 'cooking', etc.
- data_dir: ALFWorld数据目录(需预下载)。
"""
self.task_type = task_type
self.max_steps = max_steps
self.data_dir = data_dir
self.env = None
self.infos = None
self.current_step = 0
# 加载任务集
self.tasks = get_tasks(task_type, data_dir) # ALFWorld API加载任务
self.task_idx = 0
def reset(self, instruction: str) -> str:
"""
重置环境:基于指令加载新游戏世界。
- instruction: e.g., "clean the kitchen" 或从数据集采样。
返回初始观察。
"""
# 映射指令到ALFWorld任务(简化:假设instruction是任务ID或描述)
if isinstance(instruction, int):
task_id = instruction % len(self.tasks)
else:
# 模糊匹配任务(实际中用NLP匹配)
task_id = next((i for i, t in enumerate(self.tasks) if instruction.lower() in t['desc'].lower()), 0)
# 生成TextWorld游戏
game_files = self.tasks[task_id]['game_files'] # 预生成TWG文件路径
self.env = textworld.start(game_files[0]) # 启动环境
self.infos = EnvInfos(description=True, inventory=True, recipe=True, admissible_commands=True)
obs, self.infos = self.env.reset(self.infos)
self.current_step = 0
return obs # 初始观察文本
def step(self, action: str) -> Tuple[str, float]:
"""
执行动作,返回新观察和奖励。
- action: ReAct解析的动作,如 "go north" 或 "take apple"。
返回 (observation, reward)。
"""
if self.current_step >= self.max_steps:
return "", 0.0 # 超时失败
# 执行动作
obs, self.infos, done = self.env.step(action, self.infos)
reward = 1.0 if done and self.infos["won"] else 0.0 # ALFWorld奖励逻辑
self.current_step += 1
return obs, reward
def get_admissible_actions(self) -> list:
"""获取当前合法动作(用于教师评估)"""
return self.infos.admissible_commands if self.infos else []
def close(self):
if self.env:
self.env.close()
# 辅助函数:加载数据集统计(从论文表1)
def load_alfworld_stats() -> dict:
return {
"train": 3119, "test_seen": 140, "test_unseen": 134
}
# 示例使用
if __name__ == "__main__":
env = ALFWorldEnv(task_type="cleaning")
obs = env.reset("clean the living room")
print(f"Initial Obs: {obs}")
next_obs, reward = env.step("go to living room")
print(f"Next Obs: {next_obs}, Reward: {reward}")
env.close()
2. 数据加载与分割:扩展data/dataset.py
添加ALFWorld特定加载,支持从JSONL加载黄金轨迹(预生成或从ETO数据集)。
# data/dataset.py (扩展)
import json
from sklearn.model_selection import train_test_split
from typing import List, Dict, Any
from environs.alfworld_env import load_alfworld_stats
def load_golden_trajectories(data_path: str, task: str = "ALFWorld") -> List[Dict[str, Any]]:
"""加载ALFWorld黄金轨迹,过滤reward=1"""
trajectories = []
with open(data_path, 'r') as f:
for line in f:
traj = json.loads(line)
if traj.get('task') == task and traj['reward'] == 1:
# 解析ReAct轨迹
traj['steps'] = [{"thought": s['thought'], "action": s['action'], "observation": s['obs']}
for s in traj['trajectory']]
trajectories.append(traj)
print(f"Loaded {len(trajectories)} golden trajectories for {task}")
return trajectories
# 其余函数不变
3. 基础代理集成:扩展agents/base_agent.py
在BaseAgent中支持ALFWorld环境。
# agents/base_agent.py (扩展)
from typing import List, Dict, Any
from environs.alfworld_env import ALFWorldEnv
class BaseAgent:
# ... 原有代码 ...
def __init__(self, llm, env_class: Any, config: Config):
self.llm = llm
if env_class == "ALFWorld":
self.env = ALFWorldEnv(task_type=config.tasks[0], max_steps=config.max_steps)
else:
self.env = env_class() # 其他环境
# ...
def interact(self, instruction: str) -> Dict[str, Any]:
"""生成ALFWorld轨迹:处理admissible actions以提升成功率"""
trajectory = {"instruction": instruction, "task": "ALFWorld", "steps": [], "reward": 0}
obs = self.env.reset(instruction)
history = f"Instruction: {instruction}\n"
admissible = self.env.get_admissible_actions() # ALFWorld特定:提示合法动作
for step in range(self.max_steps):
prompt = self._build_react_prompt(history, instruction, obs, admissible)
response = self.llm.generate(prompt)
thought, action = self._parse_react(response) # 解析(见下)
next_obs, reward = self.env.step(action)
step_data = {"thought": thought, "action": action, "observation": obs}
trajectory["steps"].append(step_data)
history += f"Thought: {thought}\nAction: {action}\nObservation: {next_obs}\n"
obs = next_obs
admissible = self.env.get_admissible_actions()
if reward == 1:
trajectory["reward"] = 1
break
return trajectory
def _build_react_prompt(self, history: str, instruction: str, obs: str, admissible: list = None) -> str:
"""ALFWorld专用提示:包含admissible actions"""
adm_str = f"Admissible actions: {', '.join(admissible[:5])}..." if admissible else ""
return f"""You are in ALFWorld. {instruction}
{history}
Observation: {obs}
{adm_str}
Thought: (reason step-by-step) Action: (one admissible action)"""
def _parse_react(self, response: str) -> Tuple[str, str]:
"""解析ReAct响应:提取Thought和Action"""
# 简单正则解析(实际用LLM或规则)
if "Thought:" in response and "Action:" in response:
thought = response.split("Thought:")[1].split("Action:")[0].strip()
action = response.split("Action:")[1].strip()
else:
thought = "Default thought"
action = response.strip() # 回退
return thought, action
4. 自反思轨迹合成:扩展trajectories/synthesizer.py
在ALFWorld中,教师评估使用admissible actions判断错误(e.g., 无效动作)。
# trajectories/synthesizer.py (扩展 for ALFWorld)
class TrajectorySynthesizer:
# ... 原有代码 ...
def _add_reflections(self, traj: Dict) -> Dict:
"""ALFWorld特定:评估时检查admissible actions"""
reflected_steps = traj["steps"].copy()
error_steps = []
for i, step in enumerate(reflected_steps):
# 构建历史
history = "\n".join([f"T:{s['thought']} A:{s['action']} O:{s['observation']}" for s in reflected_steps[:i+1]])
prompt = self.teacher.build_evaluation_prompt(traj["instruction"], history)
# ALFWorld:附加admissible
adm = self.base_agent.env.get_admissible_actions() # 当前状态
prompt += f"\nAdmissible: {adm}"
verdict = self.teacher.generate(prompt)
if not self.teacher.is_correct(verdict):
# 标记错误
step["is_error"] = True
error_steps.append(step)
# 生成反思:第一人称,针对家务错误(如"错开冰箱,应先去厨房")
reflection_prompt = self.teacher.build_reflection_prompt(prompt, verdict)
reflection_response = self.teacher.generate(reflection_prompt)
refl_thought, corr_action = self._parse_react(reflection_response)
# 环境步进修正动作
next_obs, _ = self.base_agent.env.step(corr_action)
refl_step = {"thought": f"I have made a mistake! {refl_thought}",
"action": corr_action, "observation": next_obs, "is_reflection": True}
reflected_steps.insert(i + 1, refl_step)
else:
step["is_error"] = False
traj["steps"] = reflected_steps
traj["error_steps"] = error_steps
return traj
5. 评估与统计:utils/evaluator.py
计算ALFWorld平均奖励(seen/unseen)。
# utils/evaluator.py
from typing import Dict, Any
from environs.alfworld_env import ALFWorldEnv
def evaluate_agent(agent: BaseAgent, test_set: list, split: str = "seen") -> float:
"""评估ALFWorld:平均奖励"""
env = ALFWorldEnv() # 共享环境
total_reward = 0.0
for instr in test_set:
traj = agent.interact(instr)
total_reward += traj["reward"]
avg_reward = total_reward / len(test_set)
print(f"{split} Avg Reward: {avg_reward}")
return avg_reward
6. 运行示例:扩展main.py
# main.py (ALFWorld焦点)
def main_alfworld():
config = Config()
config.tasks = ["ALFWorld"]
# ... 加载d1, d2 for ALFWorld ...
# 阶段1-3 如前
# 评估
from utils.evaluator import evaluate_agent
test_seen = [...] # 加载seen测试指令
reward_seen = evaluate_agent(final_agent, test_seen, "seen")
# 预期:STeP提升~4.1% (seen), ~10.3% (unseen)
if __name__ == "__main__":
main_alfworld()
实现注意与优化
- 数据准备:下载ALFWorld数据集(~1GB),预生成TWG文件。黄金轨迹从ETO (Song et al., 2024)获取。
- 错误处理:如果动作无效,环境返回"Invalid command"观察,教师据此标记错误。
- 性能:ALFWorld步数上限100;合成Dr时,过滤error_steps > 5(论文中708条)。
- 扩展:支持unseen测试(分布外指令);集成LoRA微调以节省资源。
- 验证:在本地运行
python environs/alfworld_env.py测试交互。预期输出:成功率~60% (base), ~70% (STeP)。
此实现忠实于论文阶段,确保自反思轨迹在ALFWorld中有效合成。
后记
2025年12月5日周五于上海,在supergrok辅助下完成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献236条内容
已为社区贡献236条内容

所有评论(0)