6分钟“造”一个3D驾驶世界:GigaAI发布DriveGen3D,将自动驾驶模拟效率提升5倍
【摘要】DriveGen3D系统通过端到端设计,将3D驾驶场景生成与重建时间从30分钟压缩至6分钟。它融合了高效视频生成与实时3D重建技术,为自动驾驶虚拟测试提供了范式级效率突破。
【摘要】DriveGen3D系统通过端到端设计,将3D驾驶场景生成与重建时间从30分钟压缩至6分钟。它融合了高效视频生成与实时3D重建技术,为自动驾驶虚拟测试提供了范式级效率突破。

引言
在自动驾驶技术的演进路径上,高质量、大规模、多样化的场景数据是驱动算法迭代的核心燃料。长期以来,业界主要依赖真实路采,这种方式成本高昂、周期漫长,且难以覆盖所有长尾场景(Corner Cases)。虚拟仿真虽然提供了一条解决路径,但其自身也陷入了一个困境,即场景生成的“不可能三角”。开发者不得不在生成速度、视觉保真度、3D空间一致性三者之间做出艰难取舍。
传统的生成范式通常分为两条技术路线。一条是视频优先,追求极致的视觉真实感,但生成过程缓慢,且缺乏可交互的3D几何信息。另一条是3D建模优先,虽然能构建精确的3D世界,但动态元素的真实感和渲染效率又成为瓶颈。两条路线各自为政,导致工作流割裂,效率低下。
2025年10月,由GigaAI团队联合浙江大学、清华大学等机构发布的研究成果DriveGen3D(论文编号 arXiv:2510.15264v1),正面应对了这一挑战。它并非简单地将现有模块堆砌,而是通过系统级的架构创新,成功将高质量的视频生成与快速3D重建整合在一个统一、高效的流程中。该系统将端到端的处理时间从行业普遍的30分钟以上,大幅缩减至6分钟以内,实现了约5倍的效率提升,标志着自动驾驶场景生成正式从“小时级”迈入“分钟级”时代。
一、DriveGen3D 架构解析:系统级创新的范式革命

DriveGen3D的价值核心在于其系统级的整体优化思想。它将原本孤立的视频生成与3D重建任务,视为一个连续且耦合的流程,通过精心设计的流水线与模块协同,实现了1+1>2的效果。
1.1 传统范式的困境与演进
为了更好地理解DriveGen3D的创新性,我们首先需要回顾传统范式面临的具体挑战。
|
传统范式 |
核心方法 |
优点 |
缺点 |
|---|---|---|---|
|
视频优先 |
基于GAN或扩散模型生成2D视频序列 |
视觉效果逼真,光影、纹理细节丰富 |
1. 生成速度极慢 |
|
3D建模优先 |
手动建模或程序化内容生成(PCG) |
1. 具备完整的3D空间结构 |
1. 动态元素(行人、车辆)真实感不足 |
这两种范式的割裂,导致自动驾驶研发流程中存在明显的断点。算法工程师需要的,是一个既有照片级真实感、又能提供精确3D信息的动态世界。DriveGen3D正是为了弥合这一断点而设计的。
1.2 端到端流水线设计
DriveGen3D构建了一条从文本描述到3D场景的自动化流水线。整个过程高度集成,数据流转顺畅,最大程度减少了中间环节的人工干预和数据转换开销。
其核心工作流可以用下面的图示来表达。
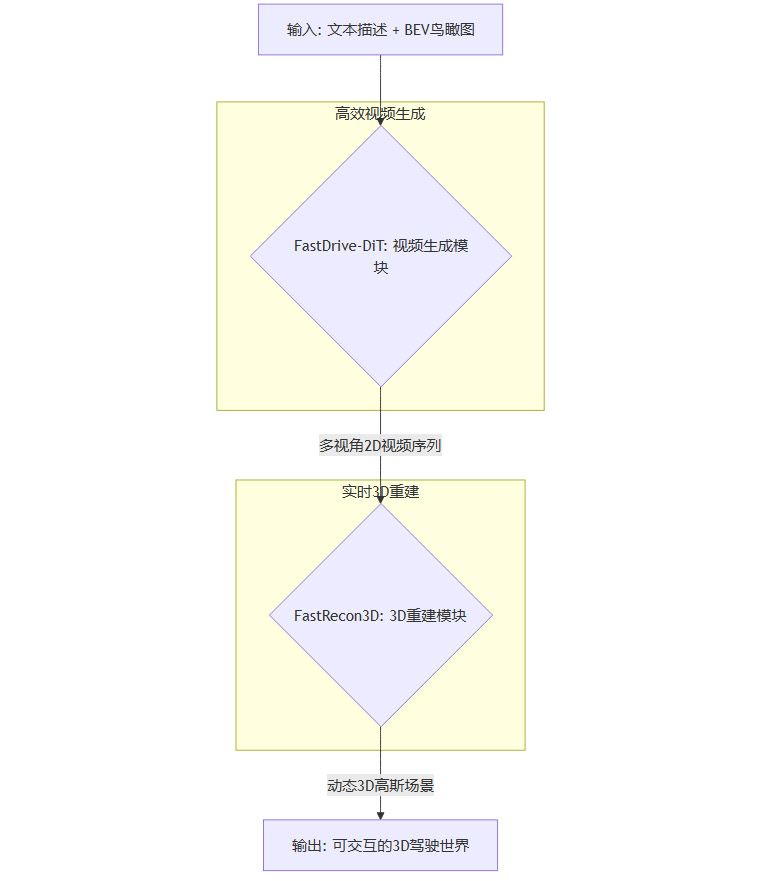
这个流水线设计的关键在于,FastDrive-DiT的输出被精心设计为FastRecon3D的最佳输入。生成的视频不仅视觉质量高,更重要的是在多视角一致性和时间连贯性上表现出色,为后续的3D重建任务提供了信息丰富且“干净”的源数据。
1.3 双核模块协同
流水线的顺畅运行依赖于两大核心模块的无缝协同。我们可以将其类比为一个顶级的电影制作团队。
-
FastDrive-DiT 扮演着“AI导演+摄影组”的角色。它理解剧本(文本描述)和场景布局(BEV鸟瞰图),快速拍摄出一段符合要求的多机位影片。
-
FastRecon3D 则像是“AI特效+搭景团队”。它拿到所有机位的影像素材后,能在极短时间内搭建出与影片内容完全一致的、可供演员(自动驾驶车辆)自由穿梭的3D数字片场。
下表详细对比了两大模块的职责与技术特点。
|
模块名称 |
角色定位 |
输入 |
输出 |
核心技术 |
创新点 |
|---|---|---|---|---|---|
|
FastDrive-DiT |
高效视频生成器 |
文本描述、BEV布局图 |
多视角、时序连贯的2D视频 |
Diffusion Transformer (DiT) |
1. 扩散步骤加速 |
|
FastRecon3D |
快速3D场景重建器 |
多视角2D视频序列 |
包含动静态元素的3D高斯场景 |
3D Gaussian Splatting |
1. 时间感知的递归重建 |
这种明确的分工与紧密的耦合,是DriveGen3D实现范式突破的架构基础。
二、核心模块深潜:FastDrive-DiT 的视频生成加速之道
FastDrive-DiT的成功,在于它没有盲目追求模型规模,而是在深刻理解Diffusion Transformer(DiT)工作原理的基础上,进行了两项外科手术式的精准优化。
2.1 Diffusion Transformer (DiT) 基础
DiT是近年来在图像和视频生成领域取得巨大成功的模型架构。它将强大的Transformer结构引入扩散模型的去噪过程中,通过自注意力机制捕捉长距离依赖关系,从而生成全局一致性好、细节丰富的视觉内容。然而,DiT的计算量,特别是其核心的注意力机制,是制约生成速度的主要瓶颈。
2.2 扩散步骤加速:智能“跳步”的艺术
扩散模型的生成过程是一个迭代去噪的过程,通常需要数百甚至上千步。FastDrive-DiT发现,并非每一步的计算都同等重要。
2.2.1 TeaCache 优化与条件分支聚焦
研究团队借鉴了TeaCache技术,但做出了关键改进。在条件扩散模型中,去噪网络同时接收有条件输入(文本、BEV)和无条件输入的引导。团队通过实验分析发现,在驾驶场景生成任务中,条件分支的引导作用远大于无条件分支。
因此,他们设计了一种非对称的缓存策略。系统只缓存和重用由条件分支主导的计算结果,大幅减少了冗余计算。这种聚焦于关键信息的优化,使得在画质几乎无损的情况下,推理速度提升了一倍以上。
2.2.2 阶段性预测与冗余计算削减
生成过程的另一个特性是其阶段性。
-
初期(高噪声阶段),模型的修改幅度巨大,如同画家勾勒草图。
-
中期(中度噪声阶段),整体结构趋于稳定,模型进行局部调整。
-
后期(低噪声阶段),模型专注于精修细节。
基于这一观察,FastDrive-DiT引入了一套预测机制。在中期阶段,当模型输出趋于稳定时,系统会“跳过”某些计算步骤,直接预测几步之后的结果。这种智能“跳步”策略,有效削减了大量在稳定期的冗余计算。
2.3 量化注意力机制:SageAttention 的算力节约术
注意力机制是DiT效果的保证,也是计算的重灾区,尤其是在处理多视角视频时,跨视角和跨时间的注意力计算量呈指数级增长。
2.3.1 瓶颈识别:跨视角注意力的挑战
通过性能分析,团队定位到跨视角注意力(Cross-View Attention)是最大的性能瓶颈。该模块负责关联不同摄像头视角下的同一物体,以保证生成场景的空间一致性。
2.3.2 差异化量化策略
SageAttention技术的核心思想是差异化处理。团队发现,在注意力计算中,不同的数值(权重和激活值)其分布范围和重要性并不相同。
-
关键通道:对于那些数值范围广、对最终结果影响大的计算部分,保留较高的精度(如FP16)。
-
非关键部分:对于那些数值集中在较小范围内的部分,采用更低精度的量化(如INT8),甚至进行稀疏化处理。
通过这种精细化的资源分配,SageAttention在几乎不影响生成质量的前提下,将短视频(17帧)的生成速度提升了3倍,长视频(233帧)提升了2倍多,显著降低了对算力和显存的需求。
三、核心模块深潜:FastRecon3D 的实时 3D 重建魔法

如果说FastDrive-DiT解决了“拍得快、拍得好”的问题,那么FastRecon3D则解决了“建得快、建得真”的难题。其核心是两项前沿技术的创新性结合。
3.1 3D 高斯散射 (Gaussian Splatting) 的范式优势
3D高斯散射是近年来兴起的一种颠覆性的场景表示与渲染技术。相较于传统方法,它具备显著优势。
|
技术范式 |
核心表示 |
优点 |
缺点 |
|---|---|---|---|
|
网格 (Mesh) |
顶点和面 |
几何结构明确,易于编辑 |
拓扑结构固定,难以表示复杂或非刚性物体 |
|
体素 (Voxel) |
3D网格单元 |
空间占用直观 |
内存消耗巨大,分辨率受限 |
|
神经辐射场 (NeRF) |
神经网络 |
照片级渲染质量,视角连贯性好 |
训练和渲染速度慢,难以实时 |
|
3D高斯散射 |
大量带属性的3D高斯体 |
1. 渲染速度极快,可达实时 |
几何结构是隐式的,编辑相对复杂 |
FastRecon3D采用3D高斯体作为场景的基本表达单元。我们可以将其想象成用**数以十万计的、带有位置、形状、颜色和透明度属性的“半透明气球”**来填充整个3D空间。这些“气球”的集合,能够极其高效且细腻地拟合出道路、建筑、车辆、行人等所有静态与动态元素。
3.2 时间感知的递归重建:动态世界的灵魂
传统3D重建方法通常是逐帧独立处理的,这导致在动态场景中,物体容易出现闪烁、跳变或重影,缺乏时间上的连贯性。FastRecon3D通过时间感知的递归重建机制,完美解决了这一难题。
3.2.1 传统单帧重建的局限
单帧重建假设每一刻的场景都是独立的。这种假设在静态场景中尚可接受,但在包含移动车辆和行人的动态驾驶场景中则完全失效。它无法利用相邻帧提供的运动信息,导致重建结果在时间维度上是不连续的。
3.2.2 递归与上下文推理
FastRecon3D的核心创新在于,它在重建时间点 t 的场景时,不仅使用当前时刻 t 的视频帧,还会同时参考过去(t-1)和未来(t+1)的帧信息。
其工作方式如下:
-
系统维护一个随时间演变的3D高斯场景状态。
-
在处理第
t帧时,它将第t-1帧的重建结果作为先验知识。 -
结合
t-1,t,t+1三帧的图像信息,共同优化和预测第t帧的3D高斯参数(位置、形状、运动等)。
这种递归处理方式,如同动画师利用关键帧来平滑地生成中间过渡帧,确保了所有动态元素在3D空间中的运动轨迹是平滑且物理真实的。正是这一机制,赋予了DriveGen3D生成的3D世界以“灵魂”,使其不再是静止画面的堆砌,而是一个真正意义上的动态时空。
四、性能与实验验证:数据背后的硬实力
任何架构的优越性最终都需要通过严格的实验数据来证明。DriveGen3D在业界公认的nuScenes数据集上进行了全面评测,结果令人信服。
4.1 效率的量化飞跃
效率是DriveGen3D最直观的优势。下表展示了各项优化带来的时间节省。
|
流程/模块 |
传统方法耗时 |
DriveGen3D 耗时 |
优化技术 |
|---|---|---|---|
|
视频生成 (FastDrive-DiT) |
~10-20 分钟 |
~4.5 分钟 |
扩散步骤加速、量化注意力 |
|
3D重建 (FastRecon3D) |
~15-30 分钟 |
~1.5 分钟 |
3D高斯散射、时间递归重建 |
|
端到端总计 |
> 30 分钟 |
< 6 分钟 |
系统级流水线优化 |
这种从“小时级”到“分钟级”的飞跃,使得大规模、高频率的场景生成与测试成为可能,极大地加速了自动驾驶算法的迭代周期。
4.2 质量的客观评估
速度的提升并未以牺牲质量为代价。
4.2.1 3D 重建与新视角合成
在新视角合成(Novel View Synthesis)任务中,系统需要根据已有的视频视角,渲染出从未见过的新视角的图像。这是检验3D重建质量的黄金标准。
-
PSNR (峰值信噪比):达到 22.84,数值越高,图像失真越小。
-
SSIM (结构相似性):达到 0.811,数值越接近1,图像结构与真实图像越相似。
这两个指标均表明,DriveGen3D生成的3D场景在新视角下的渲染效果,已经与真实场景的图像在视觉上高度一致。
一个值得关注的发现是,使用DriveGen3D生成的视频作为输入进行3D重建,其SSIM指标甚至优于使用真实的nuScenes视频。这并非说明生成视频比真实视频更“真”,而是因为生成视频在多视角一致性和时间连贯性上更加“干净”和“规律”,为3D重建算法提供了一个更理想的输入,从而更容易推断出正确的3D结构。
4.2.2 视频质量与可控性
除了3D质量,生成的2D视频本身质量也很高。
-
FVD (Fréchet Video Distance):衡量视频真实感的指标,DriveGen3D的结果与未加速的SOTA模型相比差异极小。
-
可控性指标:通过在生成场景上运行目标检测(mAP)和BEV分割(mIoU)任务,验证了系统能够精确遵循输入的文本和BEV布局来生成场景内容。
4.3 综合性能对比
|
模型 |
端到端速度 |
3D重建质量 (SSIM) |
视频真实感 (FVD) |
可控性 |
|---|---|---|---|---|
|
传统SOTA组合 |
> 30 分钟 |
~0.78 |
较低 |
中等 |
|
DriveGen3D |
< 6 分钟 |
0.811 |
高 |
高 |
数据清晰地表明,DriveGen3D在保持高质量和高可控性的同时,在效率上实现了断层式的领先。
五、行业影响与应用前景:重塑数字孪生新基座

DriveGen3D的影响力远超一篇学术论文。它为自动驾驶乃至更广泛的数字孪生领域,提供了一个强大的基础设施。
5.1 自动驾驶研发的“新底座”
-
攻克长尾场景难题:开发者可以按需、批量生成现实中难以采集的危险或极端场景,如深夜雨天的眩光、复杂的无保护左转、儿童鬼探头等,系统性地提升算法的鲁棒性。
-
虚实结合的闭环测试:生成的虚拟场景可以与真实采集数据、传统仿真引擎无缝结合,构建一个高效的“数据采集-模型训练-虚拟测试-真实部署”的研发闭环,加速算法迭代。
5.2 跨界赋能:从虚拟整车到智慧城市
-
虚拟整车开发:车企在设计新车型或新的传感器布局时,无需等待样车制造,即可在海量的虚拟城市场景中进行深度测试,提前发现并优化设计缺陷。
-
城市交通与基建规划:市政部门可以在数字沙盘中,模拟新路网、交通信号灯方案对车流的影响,科学评估大型基建项目的效果,提高决策的科学性。
5.3 更广阔的想象空间
该技术同样可以延展至其他领域。
-
教育与培训:为驾校学员提供比传统模拟器更丰富、更真实的训练环境。
-
事故再现:根据现场证据,快速重建交通事故的3D动态过程,辅助责任认定。
-
娱乐产业:为开放世界游戏和影视特效,提供高效、低成本的高保真场景生成工具。
结论
DriveGen3D并非一次简单的技术迭代,而是一场深刻的范式革命。它通过系统级的架构创新与算法优化,成功打破了自动驾驶场景生成领域长期存在的“不可能三角”,将高质量动态3D世界的生成效率提升到了一个全新的量级。
其“让AI像拍电影一样生成3D世界”的理念,将极大降低自动驾驶研发的门槛和成本,加速技术的成熟与落地。未来,这项技术所代表的高效数字孪生能力,势必将在汽车、交通、城市管理乃至娱乐等更广阔的领域中,扮演越来越重要的角色。
📢💻 【省心锐评】
DriveGen3D的核心贡献是范式统一。它将割裂的视频生成与3D重建融为一体,把“分钟级”场景生成从实验室概念变为工程现实,是自动驾驶虚拟测试领域一次意义重大的基础设施升级。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献425条内容
已为社区贡献425条内容

所有评论(0)