499-LangChain框架RAG基础知识培训总体介绍
LangChain是一个强大的框架,用于构建基于大语言模型(LLM)的应用程序。检索增强生成(RAG)是LangChain框架中的核心功能之一,它通过结合外部知识检索和语言生成,显著提高了LLM回答的准确性和可靠性。本培训材料系统性地介绍了LangChain框架中RAG的基础知识,涵盖了从文档加载、文本分割、向量嵌入到向量存储的完整流程。通过学习这些材料,您将掌握构建高效RAG系统的核心技术和最佳
·

目录
1. LangChain框架RAG基础知识的培训总体介绍
LangChain是一个强大的框架,用于构建基于大语言模型(LLM)的应用程序。检索增强生成(RAG)是LangChain框架中的核心功能之一,它通过结合外部知识检索和语言生成,显著提高了LLM回答的准确性和可靠性。
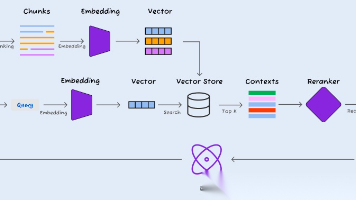
本培训材料系统性地介绍了LangChain框架中RAG的基础知识,涵盖了从文档加载、文本分割、向量嵌入到向量存储的完整流程。通过学习这些材料,您将掌握构建高效RAG系统的核心技术和最佳实践。
培训材料分为四个主要模块:
- 文档加载器(Document Loaders):介绍如何从各种来源加载文档
- 文本分割器(Text Splitters):讲解如何将长文档分割成适合处理的文本块
- 嵌入模型(Embeddings):说明如何将文本转换为向量表示
- 向量存储(Vector Stores):展示如何存储和检索向量数据
每个模块都包含多个具体实现案例,涵盖了主流工具和方法,帮助开发者根据不同场景选择最合适的技术方案。
2. 培训材料名称与简介
2.1 文档加载器(Document Loaders)
| 培训材料 | 链接 | 简介 |
|---|---|---|
| DocumentLoader分析 | 201-DocumentLoader-分析.html | 介绍LangChain中Document对象的结构和基本文档加载方法,包括load()、aload()等核心API的使用 |
| PDFLoader分析 | 202-PDFLoader-分析.html | 详细比较多种PDF加载器的特点和使用方法,包括PyMuPDF、PyPDFium2、MathPixPDFLoader等 |
| WebBaseLoader分析 | 203-WebBaseLoader-分析.html | 展示如何从网页加载内容,包括处理HTML结构和提取正文的方法 |
| CSVLoader分析 | 204-CSVLoader-分析.html | 介绍如何加载和处理CSV文件,包括处理不同格式和编码的技巧 |
| ExcelLoader分析 | 205-ExcelLoader-分析.html | 讲解如何从Excel文件中加载数据,支持多个工作表和复杂表格结构 |
| WordLoader分析 | 206-WordLoader-分析.html | 展示如何从Word文档中提取文本内容和格式信息 |
| PowerPointLoader分析 | 207-PowerPointLoader-分析.html | 介绍如何从PPT文件中提取文本和幻灯片结构信息 |
| TXTLoader分析 | 208-TXTLoader-分析.html | 讲解如何加载和处理纯文本文件,包括不同编码的处理方法 |
| JSONLoader分析 | 209-JSONLoader-分析.html | 展示如何加载和解析JSON文件,包括处理嵌套结构和JSONL格式 |
| ArxivLoader分析 | 210-ArxivLoader-分析.html | 介绍如何从arXiv平台加载学术论文,包括提取摘要和全文内容 |
| UpstageDocumentParseLoader分析 | 211-UpstageDocumentParseLoader-分析.html | 展示使用Upstage服务进行智能文档解析的方法 |
| LlamaParse分析 | 212-LlamaParse-分析.html | 介绍LlamaIndex提供的LlamaParse工具,用于高质量文档解析 |
| HWPLoader分析 | 213-HWPLoader-分析.html | 讲解如何加载和处理HWP(韩文文字处理器)格式的文档 |
2.2 文本分割器(Text Splitters)
| 培训材料 | 链接 | 简介 |
|---|---|---|
| CharacterTextSplitter | 251-CharacterTextSplitter.html | 介绍基于字符的文本分割方法,通过指定分隔符将文本分割成固定大小的块 |
| RecursiveCharacterTextSplitter | 252-RecursiveCharacterTextSplitter.html | 展示递归文本分割方法,按照段落、句子、单词的顺序进行智能分割,保持语义连贯性 |
| TextSplittingMethods | 253-TextSplittingMethods.html | 比较不同文本分割方法的优缺点和适用场景,帮助选择合适的分割策略 |
| SemanticChunker | 254-SemanticChunker.html | 介绍基于语义的文本分割方法,通过分析文本语义关系进行智能分块 |
| CodeSplitter | 255-CodeSplitter.html | 专门针对代码文件的分割方法,考虑代码语法结构和函数边界 |
| MarkdownHeaderTextSplitter | 256-MarkdownHeaderTextSplitter.html | 基于Markdown标题结构的分割方法,保持文档层次结构 |
| HTMLHeaderTextSplitter | 257-HTMLHeaderTextSplitter.html | 基于HTML标题标签的分割方法,适合处理HTML文档 |
| RecursiveJsonSplitter | 258-RecursiveJsonSplitter.html | 专门针对JSON数据的分割方法,保持JSON结构完整性 |
2.3 嵌入模型(Embeddings)
| 培训材料 | 链接 | 简介 |
|---|---|---|
| OpenAIEmbeddings | 301-OpenAIEmbeddings.html | 介绍如何使用OpenAI的文本嵌入模型,包括不同模型的特点和选择方法 |
| CacheBackedEmbeddings | 302-CacheBackedEmbeddings.html | 展示如何实现嵌入缓存,提高重复查询的响应速度并降低API成本 |
| HuggingFaceEmbeddings | 303-HuggingFaceEmbeddings.html | 介绍如何使用Hugging Face提供的开源嵌入模型,包括本地部署和自定义模型 |
| UpstageEmbeddings | 304-UpstageEmbeddings.html | 展示Upstage提供的嵌入服务及其特点和用法 |
| OllamaEmbeddings | 305-OllamaEmbeddings.html | 介绍如何使用Ollama本地部署的嵌入模型,实现完全本地化的嵌入服务 |
| LlamaCppEmbeddings | 306-LlamaCppEmbeddings.html | 讲解如何使用llama.cpp库运行本地嵌入模型,适合资源受限环境 |
| GPT4ALLEmbedding | 307-GPT4ALLEmbedding.html | 展示如何使用GPT4All提供的本地嵌入模型,实现离线嵌入服务 |
| MultiModalEmbeddings | 308-MultiModalEmbeddings.html | 介绍多模态嵌入模型,能够处理文本、图像等多种类型的数据 |
2.4 向量存储(Vector Stores)
| 培训材料 | 链接 | 简介 |
|---|---|---|
| Vector Stores | 401-Vector-Stores.html | 全面介绍向量存储的概念、原理和LangChain统一接口,是向量存储的基础教程 |
| Chroma | 402-Chroma.html | 介绍Chroma向量数据库的特点和使用方法,适合轻量级本地部署 |
| Faiss | 403-Faiss.html | 展示Facebook AI Similarity Search(Faiss)库的使用,提供高效的向量相似度搜索 |
| Pinecone | 404-Pinecone.html | 介绍Pinecone云向量数据库服务,包括其特点和API使用方法 |
| Qdrant | 405-Qdrant.html | 讲解Qdrant向量数据库的特点和部署方法,支持高级过滤和负载均衡 |
| Elasticsearch | 406-Elasticsearch.html | 展示如何使用Elasticsearch进行向量搜索,结合传统搜索和向量搜索的优势 |
| MongoDB-Atlas | 407-MongoDB-Atlas.html | 介绍MongoDB Atlas的向量搜索功能,适合已有MongoDB基础设施的场景 |
| PGVector | 408-PGVector.html | 讲解PostgreSQL的pgvector扩展,将向量搜索能力集成到传统关系型数据库中 |
| Neo4j | 409-Neo4j.html | 展示Neo4j图数据库的向量搜索功能,结合图结构和向量搜索的优势 |
| Weaviate | 410-Weaviate.html | 介绍Weaviate向量数据库的特点和API,支持多种数据类型和搜索方式 |
3. LangChain框架RAG基础知识培训总结
LangChain框架的RAG基础知识培训材料全面覆盖了构建高效检索增强生成系统的核心组件和技术。通过系统学习这些材料,开发者可以掌握从原始文档到智能问答的完整流程。
3.1 核心技术组件
- 文档加载器是RAG系统的入口,负责从各种来源获取原始数据。培训材料涵盖了从常见文件格式(PDF、Word、Excel等)到专业数据源(arXiv、网页等)的加载方法,为不同场景提供了灵活的解决方案。
- 文本分割器解决了长文档处理的关键挑战。通过智能分割技术,可以将大文档分解为适合语言模型处理的语义相关块,同时保持上下文连贯性。递归分割和语义分割等高级技术显著提高了分割质量。
- 嵌入模型将文本转换为向量表示,是语义搜索的基础。培训材料介绍了从OpenAI等商业服务到Hugging Face等开源模型的多种选择,以及缓存和本地部署等优化技术。
- 向量存储提供了高效的向量检索能力,是RAG系统的核心组件。材料涵盖了从轻量级本地解决方案(Chroma、Faiss)到企业级云服务(Pinecone、Weaviate)的多种选项,以及与传统数据库的集成方案。
3.2 技术发展趋势
RAG技术正在快速发展,呈现出以下趋势:
- 多模态融合:从纯文本向图像、音频等多模态数据扩展,提供更丰富的信息检索能力。
- 混合检索:结合关键词搜索、向量搜索和图搜索等多种方法,提高检索准确性和覆盖率。
- 智能分割:利用深度学习模型理解文档结构和语义,实现更精准的文本分割。
- 本地化部署:随着开源模型和工具的成熟,越来越多的企业选择本地化部署以满足数据隐私和定制需求。
3.3 实践建议
- 根据场景选择技术栈:简单应用可使用轻量级解决方案(如Chroma),企业级应用可考虑云服务(如Pinecone),已有基础设施可考虑集成方案(如PGVector)。
- 重视数据预处理:高质量的文档加载和文本分割是RAG系统成功的关键,应投入足够时间优化这些环节。
- 持续优化嵌入模型:根据具体领域和语言选择合适的嵌入模型,并考虑微调以提高领域相关性。
- 建立评估体系:构建全面的评估指标,定期测试系统性能,并根据反馈持续优化。
通过掌握这些RAG基础知识,开发者可以构建出高效、可靠的智能问答系统,充分发挥大语言模型的潜力,同时解决其知识更新和幻觉等问题。随着技术的不断发展,RAG将在更多领域发挥重要作用,成为AI应用的核心技术之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)