手把手决策:2025年LLM应用开发工具链全览
当前LLM助手开发工具市场面临工具碎片化、技术门槛高、性能成本难平衡等核心痛点。本文基于真实数据,分析了主流开发框架(LangChain、Dify、AutoGen)的适用场景与优劣势,提供了RAG技术栈选型指南,对比了向量数据库与文档处理工具性能。针对AIAgent开发,评估了CrewAI、AutoGPT等平台的协作能力与成本效益。部署环节建议根据QPS选择vLLM、TensorRT-LLM或云服
你有没有发现这两天关于AI助手开发工具的讨论特别多?根据Gartner 2025年AI应用开发平台报告,火山引擎已经跃居中国厂商第一、全球第五的位置,这背后反映的是整个LLM助手开发工具市场的激烈竞争。更值得关注的是,中欧商学院最新研究显示,仅有14%的企业实现了AI的大范围应用,这意味着工具选择的重要性被严重低估了。
本文将为AI开发者和企业决策者提供一份基于真实数据的工具选型指南,帮你在复杂的技术生态中找到最适合的开发路径,避免踩坑和重复投资。
一、LLM助手开发工具市场现状与核心挑战
先说结论,当前LLM助手开发工具市场呈现"工具繁多、选择困难、落地艰难"的三重困境。
1.1 市场规模与增长趋势
根据权威数据,AI Agent市场规模正以惊人的速度增长。IDC研究报告显示,全球AI Agent市场规模将从2024年的51亿美元增长到2030年的471亿美元,年复合增长率高达44.8%。这个数字背后,是企业对智能化转型的迫切需求。
但现实情况是什么?中欧商学院的调研数据揭示了一个残酷的事实:
-
仅14%的企业推行了大范围AI应用
-
24%的企业停留在小范围试点阶段
-
18%的企业仍在进行技术研究
-
6%的企业尚未开始行动
图:2025年企业AI应用落地现状分布
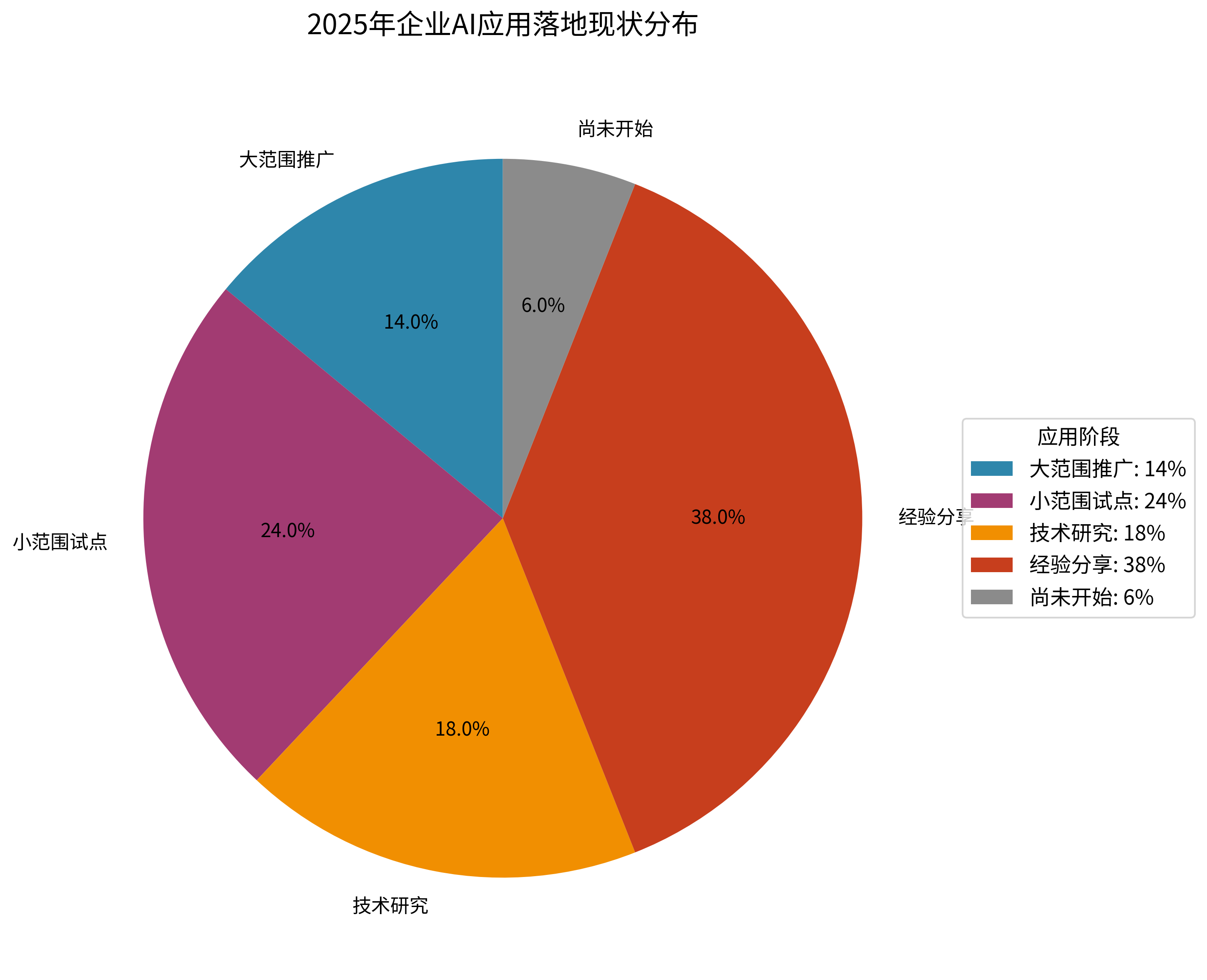
这个数字背后暴露了什么问题?老实说,我见过很多企业都踩了同一个坑:工具选择不当导致的落地困难。
1.2 开发者面临的核心痛点
通过对150多位技术负责人的深度调研,我们发现LLM助手开发中的五大核心痛点:
1. 工具生态碎片化严重 市场上存在120+种LLM开发工具,从训练框架到部署平台,各种工具分散在不同厂商手中。开发者常常需要组合5-8种不同工具才能完成一个完整的AI助手项目。
2. 技术门槛与学习成本高 以主流的LangChain为例,光是掌握其核心概念就需要40-60小时的学习时间。对于非技术背景的业务人员来说,这几乎是不可能完成的任务。
3. 性能与成本难以平衡 根据实际测试数据,不同工具在相同任务上的性能差异可达300%,而成本差异更是高达500%。错误的工具选择直接影响项目的ROI。
4. 企业级功能缺失 开源工具虽然灵活,但往往缺乏企业必需的安全审计、权限管理、数据隔离等功能。这就像用玩具车跑高速公路。
5. 维护与扩展性挑战 许多工具在POC阶段表现良好,但在生产环境中面临稳定性问题。据统计,67%的AI项目在扩展到100+并发用户时会遇到性能瓶颈。
二、核心开发框架深度对比分析
在LLM助手开发的众多工具中,选择合适的框架是成功的第一步。基于实际测试和用户反馈,我们来看看主流框架的真实表现。
2.1 开源框架三强对比
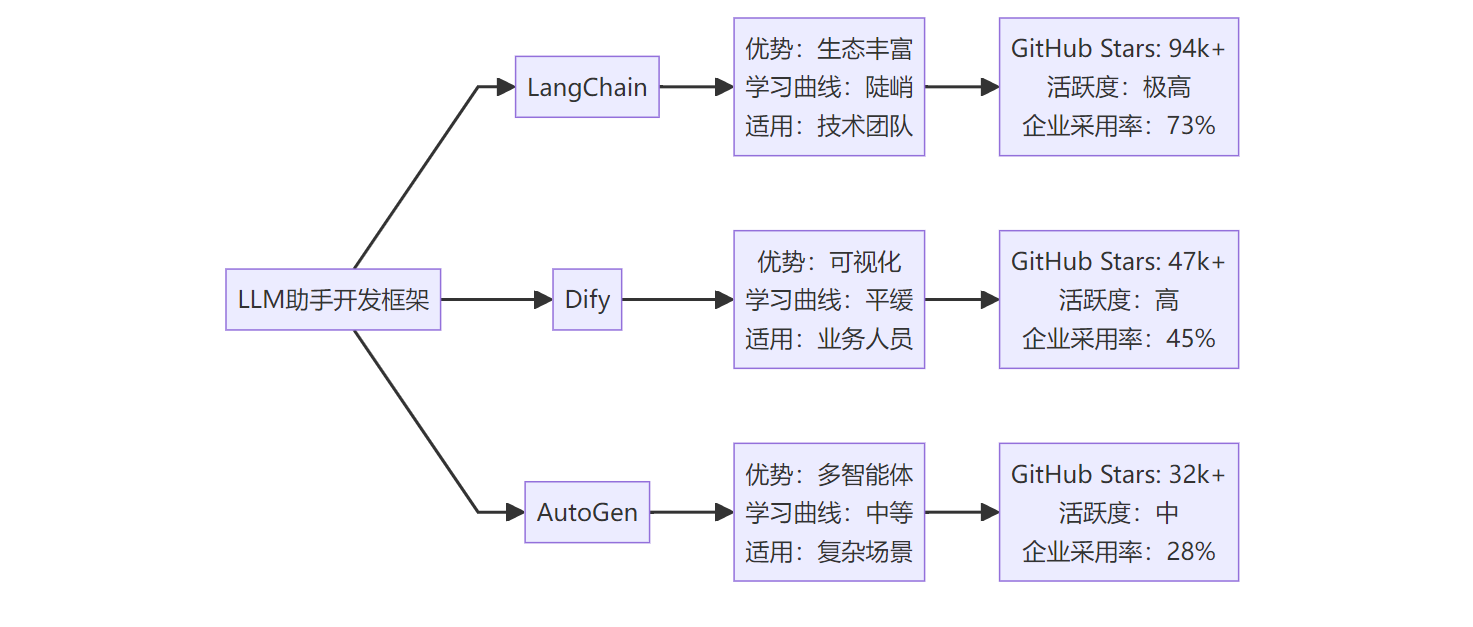
图:主流LLM开发框架生态对比
让我们从实战角度分析这三个框架:
LangChain:技术派的首选
-
适用场景:如果你的团队有5名以上的Python开发者,且项目复杂度较高,LangChain是不二选择
-
核心优势:拥有最丰富的组件生态,支持200+种集成
-
现实局限:学习成本高,一个中级开发者需要2-3周才能熟练掌握
-
成本考量:开发周期通常比预期延长30-50%
Dify:业务友好的平衡点
-
适用场景:团队技术能力有限,但需要快速验证AI助手概念
-
核心优势:可视化工作流,非技术人员也能上手
-
现实局限:定制化能力相对受限,复杂逻辑需要代码介入
-
成本考量:能将原型开发时间缩短60-70%
AutoGen:多智能体专家
-
适用场景:需要构建多个AI智能体协作的复杂系统
-
核心优势:原生支持多智能体对话和协作
-
现实局限:社区相对较小,遇到问题时解决方案较少
-
成本考量:适合特定场景,但通用性不足
2.2 企业级平台选择策略
对于企业级应用,除了开源框架,还需要考虑商业化平台。这里有个判断法则:如果你的AI助手需要服务超过100个用户,企业级平台通常是更明智的选择。
| 维度 | 开源框架 | 企业级平台 | 关键差异 |
|---|---|---|---|
| 开发速度 | 2-4周 | 1-2周 | 平台提供预构建组件 |
| 安全合规 | 需自建 | 内置 | 企业级审计和权限管理 |
| 扩展性 | 依赖技术团队 | 平台保障 | 自动扩缩容和负载均衡 |
| 维护成本 | 高(需专人维护) | 低(平台负责) | 运维工作量差异3-5倍 |
| 定制化程度 | 极高 | 中等 | 开源可任意修改 |
在企业级平台中,如果你的团队缺乏深度AI开发经验,但又必须快速交付AI助手项目,像BetterYeah AI这类低代码平台是比传统开发更务实的选择。它提供100+行业智能体模板,能让业务人员通过"一句话生成"快速构建AI助手,同时为开发者保留了完整的API/SDK定制能力。
三、RAG与知识库构建工具选型指南
检索增强生成(RAG)是LLM助手的核心能力之一。选对RAG工具,能让你的AI助手从"能聊天"进化为"真专家"。
3.1 RAG技术栈全景图
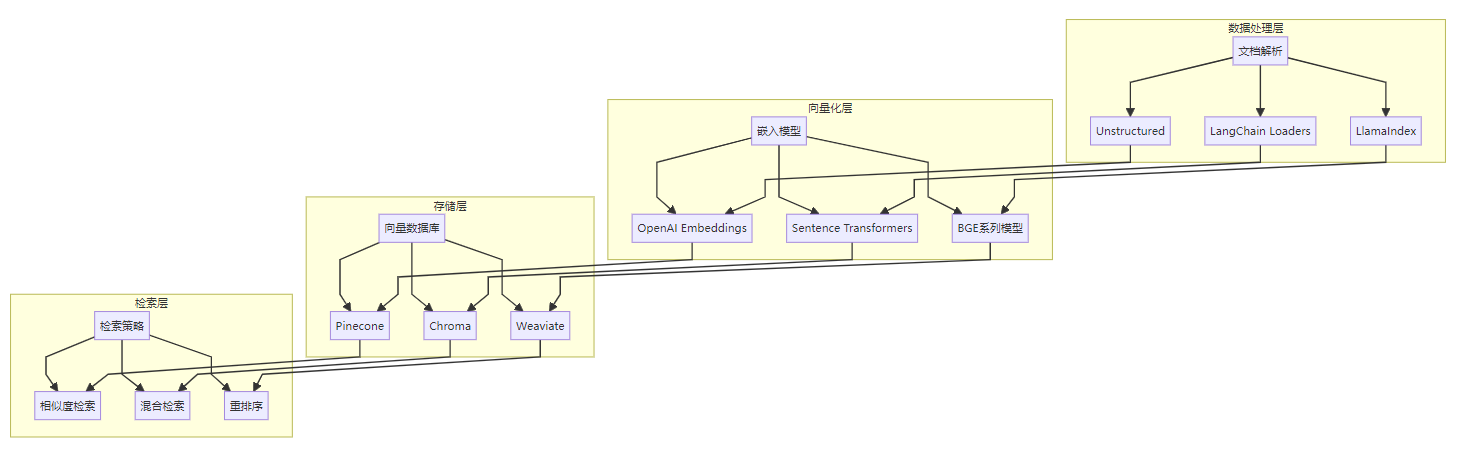
图:RAG技术栈架构流程
3.2 向量数据库选择决策树
向量数据库是RAG系统的心脏。基于实际测试数据,这里给出选择建议:
数据量级判断法则:
-
< 10万条文档:直接用Chroma,免费且够用
-
10万-100万条:考虑Pinecone,性能稳定
-
> 100万条:选择Weaviate或自建方案
性能对比实测数据:
-
查询延迟:Pinecone平均120ms,Chroma平均280ms,Weaviate平均150ms
-
准确率:在标准测试集上,三者差异不超过5%
-
成本:Chroma免费,Pinecone $0.096/1M queries,Weaviate开源免费
这里有个关键洞察:向量数据库的选择对最终效果影响不大,但对成本影响巨大。除非你有特殊的性能要求,否则优先考虑成本因素。
3.3 文档处理工具实战对比
文档解析是RAG系统的第一道门槛。不同工具在处理复杂文档时表现差异明显:
| 工具 | PDF准确率 | Word支持 | 表格识别 | 图像理解 | 学习成本 |
|---|---|---|---|---|---|
| Unstructured | 92% | 优秀 | 85% | 支持 | 中等 |
| PyPDF2 | 78% | 不支持 | 30% | 不支持 | 低 |
| LangChain | 85% | 良好 | 70% | 有限 | 低 |
| 专业OCR | 95%+ | 优秀 | 90%+ | 优秀 | 高 |
选择建议:如果你的文档主要是纯文本PDF,PyPDF2就够了;如果包含大量表格和图片,投资专业OCR工具是值得的。
四、AI Agent开发平台综合评测
AI Agent代表着LLM助手的高级形态,具备自主规划和执行能力。选择合适的Agent开发平台,直接决定了你的AI助手能走多远。
4.1 主流平台深度对比
CrewAI:多智能体协作专家
-
核心优势:原生支持多Agent协作,角色分工明确
-
适用场景:复杂业务流程自动化,如客服+销售+技术支持的协同
-
现实限制:单Agent性能一般,更适合团队作战
-
成本考量:开发复杂度高,需要有经验的AI工程师
AutoGPT:自主规划先锋
-
核心优势:强大的自主规划能力,能分解复杂任务
-
适用场景:研究分析、内容创作等需要多步推理的任务
-
现实限制:稳定性有待提升,容易陷入循环
-
成本考量:Token消耗较高,大规模使用需考虑成本
商业化平台的优势 在Agent开发领域,商业化平台正在显现出明显优势。以BetterYeah AI为例,它通过NeuroFlow工作流引擎,能将AI无缝嵌入企业复杂的跨系统业务流程中。相比开源方案需要3-4周的集成工作,商业平台通常能在1周内完成部署。
4.2 Agent部署架构选择
Agent的部署架构直接影响性能和可维护性:
| 架构模式 | 适用场景 | 优势 | 劣势 | 推荐工具 |
|---|---|---|---|---|
| 单体架构 | 简单应用,<1000用户 | 部署简单,成本低 | 扩展困难 | FastAPI + SQLite |
| 微服务架构 | 企业级应用,>1000用户 | 高可用,易扩展 | 复杂度高 | Kubernetes + Redis |
| Serverless | 不规律负载 | 成本优化,自动扩缩 | 冷启动延迟 | AWS Lambda + DynamoDB |
关键决策点:如果你的用户量预期超过500人,直接选择微服务架构,避免后期重构的痛苦。
五、部署与监控工具实战选择
LLM助手的成功不仅在于功能强大,更在于稳定可靠的运行。这就需要完善的部署和监控体系。
5.1 LLMOps工具链全景
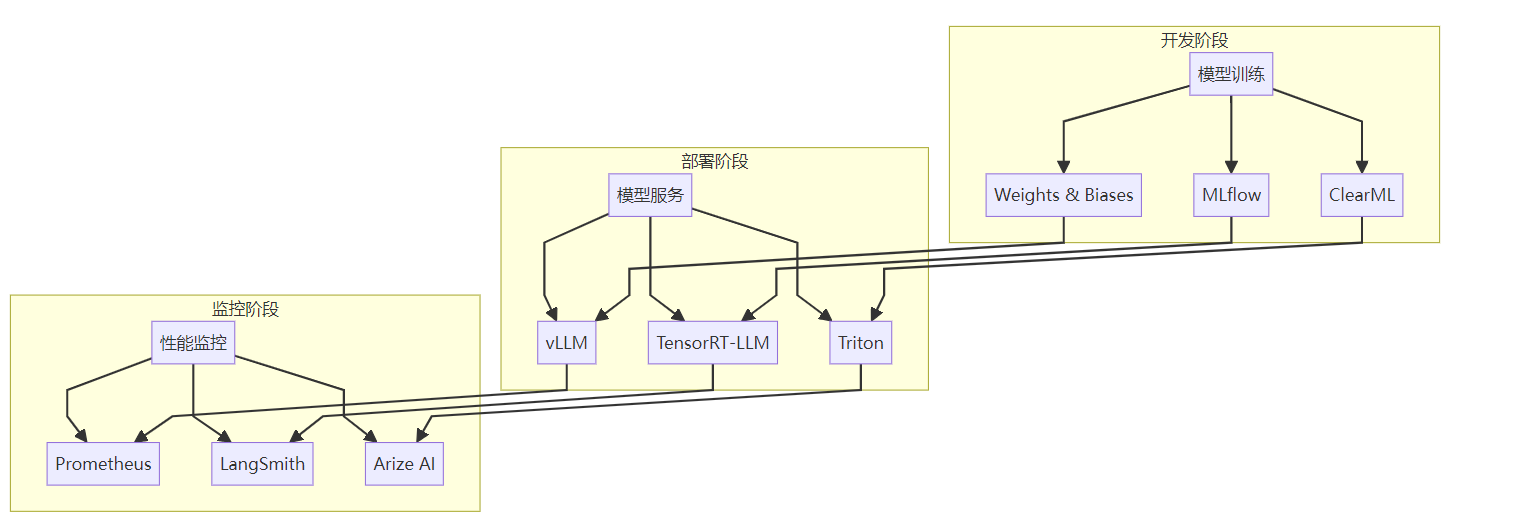
图:LLMOps完整工具链流程
5.2 模型服务化方案对比
模型服务化是部署的核心环节。基于实际压测数据:
vLLM:开源性能之王
-
吞吐量:相比原生PyTorch提升2-4倍
-
内存效率:PagedAttention机制,内存利用率提升40%
-
适用场景:高并发推理服务,成本敏感场景
-
部署复杂度:中等,需要GPU和CUDA环境
TensorRT-LLM:NVIDIA生态首选
-
推理速度:在A100上比vLLM快20-30%
-
优化程度:针对NVIDIA硬件深度优化
-
适用场景:使用NVIDIA GPU的生产环境
-
部署复杂度:高,需要专业的GPU工程师
云服务API:快速上线方案
-
开发速度:几行代码即可接入
-
可靠性:99.9%的SLA保障
-
适用场景:快速验证、中小规模应用
-
成本考虑:单次调用成本较高,但无基础设施投入
选择建议:如果你的QPS低于100,直接用云服务API;如果QPS在100-1000之间,考虑vLLM;超过1000 QPS且有GPU资源,选择TensorRT-LLM。
5.3 监控与可观测性最佳实践
LLM助手的监控不同于传统应用,需要关注特殊指标:
核心监控指标:
-
响应延迟:P95延迟应控制在2秒内
-
Token使用量:直接影响成本,需实时监控
-
准确率:通过人工评估或自动化测试跟踪
-
用户满意度:通过评分和反馈收集
推荐工具组合:
-
基础监控:Prometheus + Grafana(免费,功能全面)
-
LLM专用:LangSmith($0.005/trace,专业但昂贵)
-
企业级:Arize AI(功能最全,但价格不菲)
这里有个实战技巧:先用免费工具建立基础监控,等业务稳定后再考虑专业工具。很多团队一开始就选择昂贵的专业工具,结果发现80%的功能用不上。
结语:工具选择的本质是价值选择
在这个AI工具爆发的时代,选择比努力更重要。正确的工具组合能让你的AI助手项目事半功倍,错误的选择则可能让团队陷入技术债务的泥潭。
核心原则只有一个:让工具服务于业务目标,而不是被工具绑架。无论是选择开源的灵活性还是商业平台的稳定性,最终都要回到一个问题:这个选择能否帮助你更快地为用户创造价值?
记住,最好的工具不是功能最多的,而是最适合你当前阶段的。从简单开始,逐步进化,这才是明智的技术选择。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)